Amazon EMR - Hands On Demo
Create a Sample Data CSV File.
1. Launch AWS Cloud Shell in us-east-1 region.
2. Copy and paste the following code.
cat > data.csv << EOF
UserID,PurchaseAmount,Date
1,100,2023-01-01
1,120,2023-01-02
1,130,2023-01-03
2,150,2023-01-04
2,160,2023-01-05
2,170,2023-01-06
3,100,2023-01-07
3,110,2023-01-08
3,90,2023-01-09
4,200,2023-01-10
4,210,2023-01-11
4,220,2023-01-12
5,150,2023-01-13
5,160,2023-01-14
5,170,2023-01-15
6,100,2023-01-16
6,130,2023-01-17
6,140,2023-01-18
7,110,2023-01-19
7,120,2023-01-20
7,130,2023-01-21
8,200,2023-01-22
8,210,2023-01-23
8,220,2023-01-24
9,150,2023-01-25
9,160,2023-01-26
9,170,2023-01-27
10,100,2023-01-28
10,110,2023-01-29
10,120,2023-01-30
1,140,2023-01-31
1,150,2023-02-01
2,180,2023-02-02
2,190,2023-02-03
3,120,2023-02-04
3,130,2023-02-05
4,230,2023-02-06
4,240,2023-02-07
5,180,2023-02-08
5,190,2023-02-09
EOF
Create EC2 Key Pair to logon to EC2 Machine Later On.
Copy and paste the following code.
aws ec2 create-key-pair \
--key-name emr-key-pair \
--key-type rsa \
--key-format pem \
--query "KeyMaterial" \
--output text > emr-key-pair.pemCreate S3 Bucket to store Sample Data.
Copy and paste the following code.
AWS_PAGER=""
RANDOMNUM=$RANDOM
BUCKET_NAME="emrdemo-$RANDOMNUM"
aws s3api create-bucket \
--bucket $BUCKET_NAME \
--region us-east-1Copy Sample Data to S3 Bucket.
Copy and paste the following code.
# Copy data.csv to the S3 bucket
aws s3 cp data.csv s3://$BUCKET_NAME/data.csvCreate a dedicated VPC to host your EMR Cluster shown as below - part 1
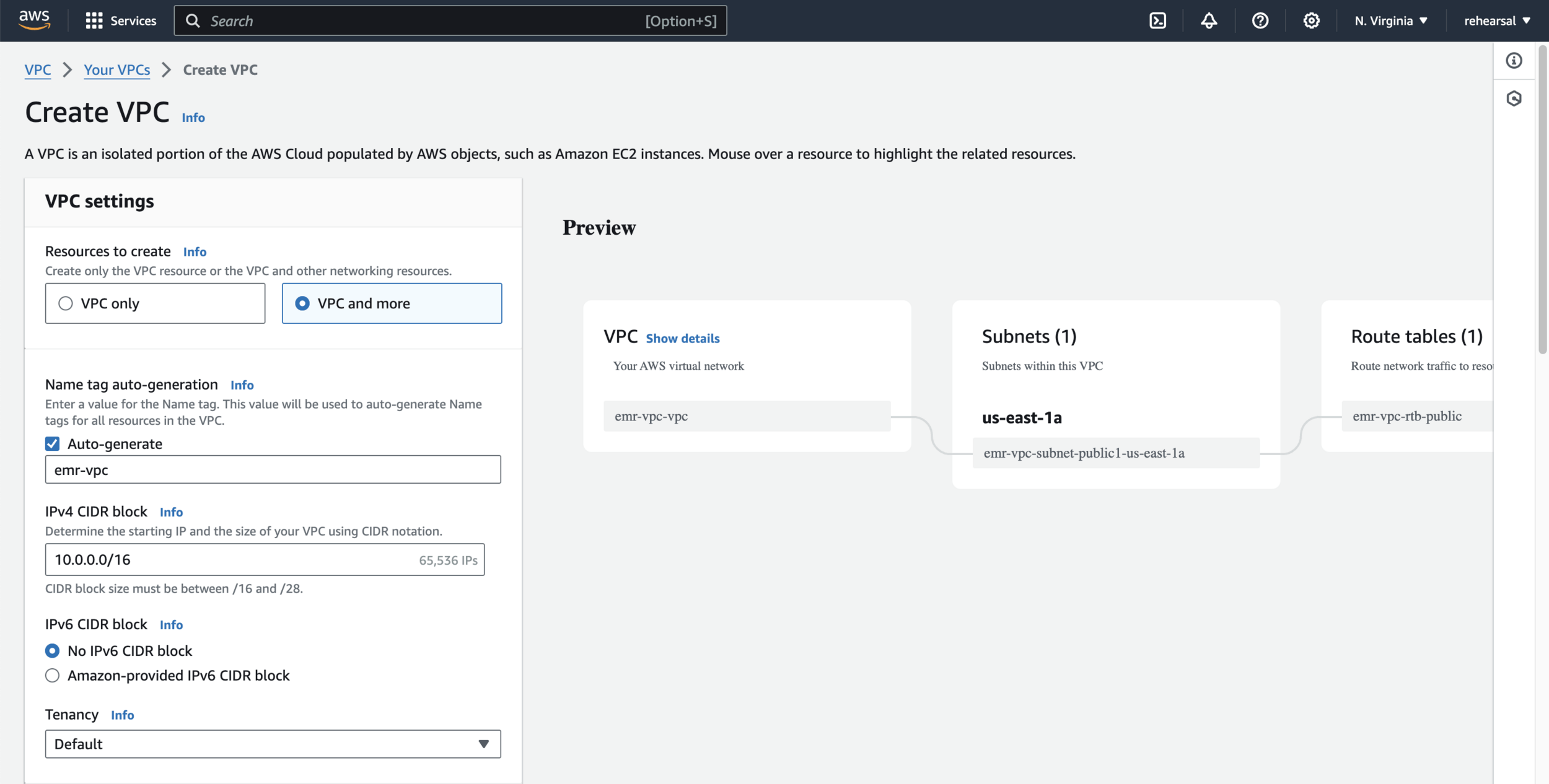
Create a dedicated VPC to host your EMR Cluster shown as below - part 2
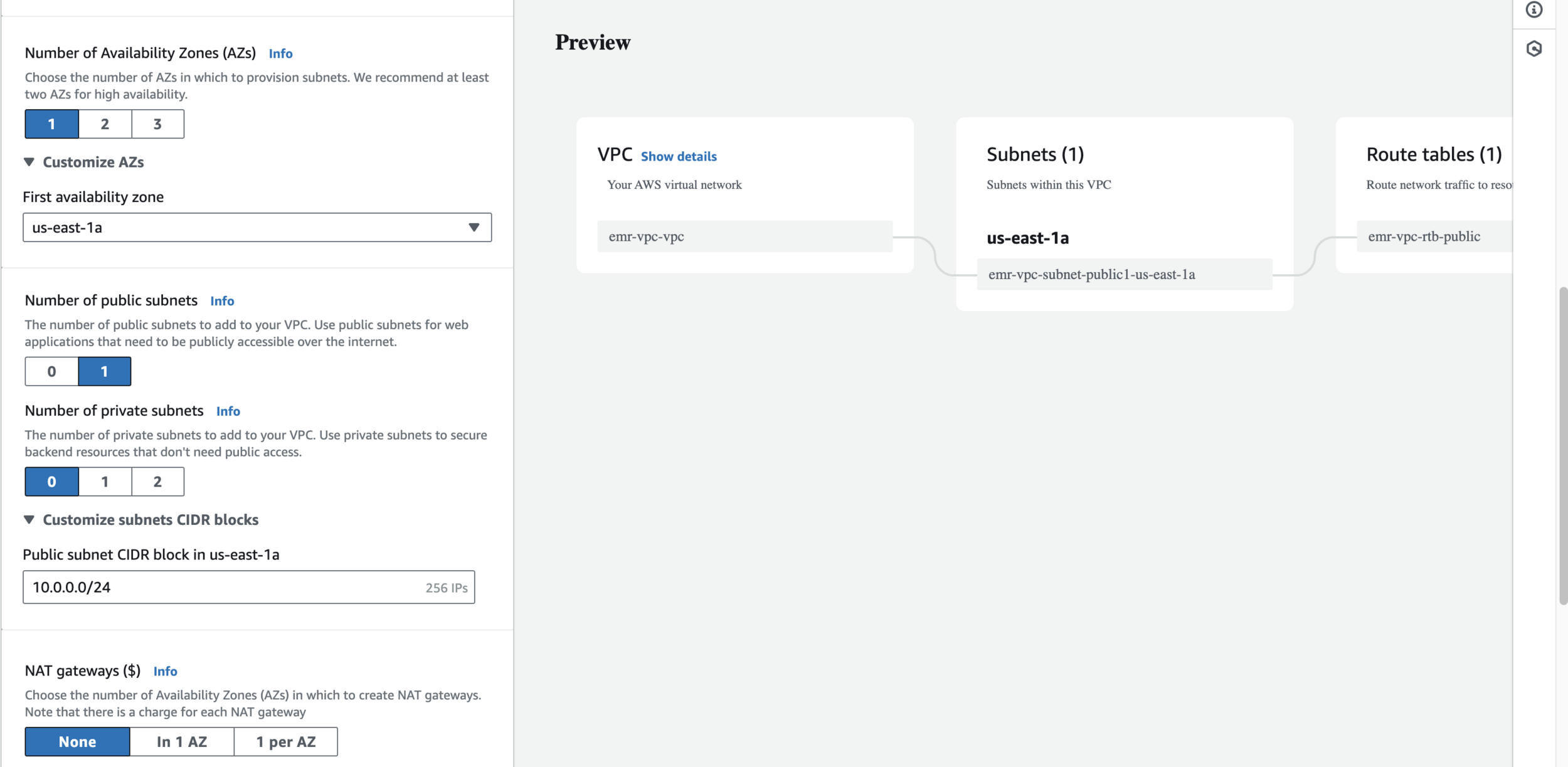
Create a dedicated VPC to host your EMR Cluster shown as below - part 3
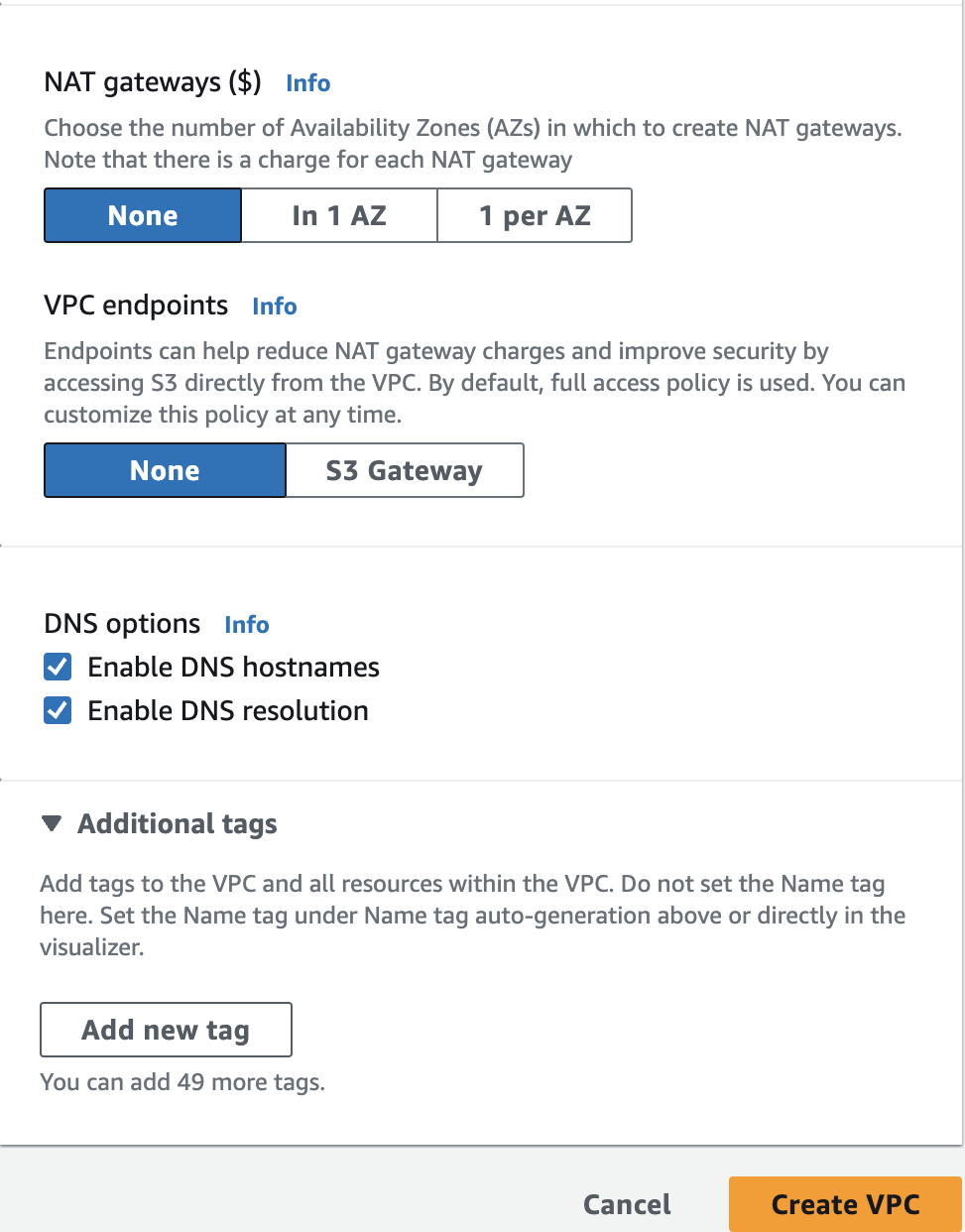

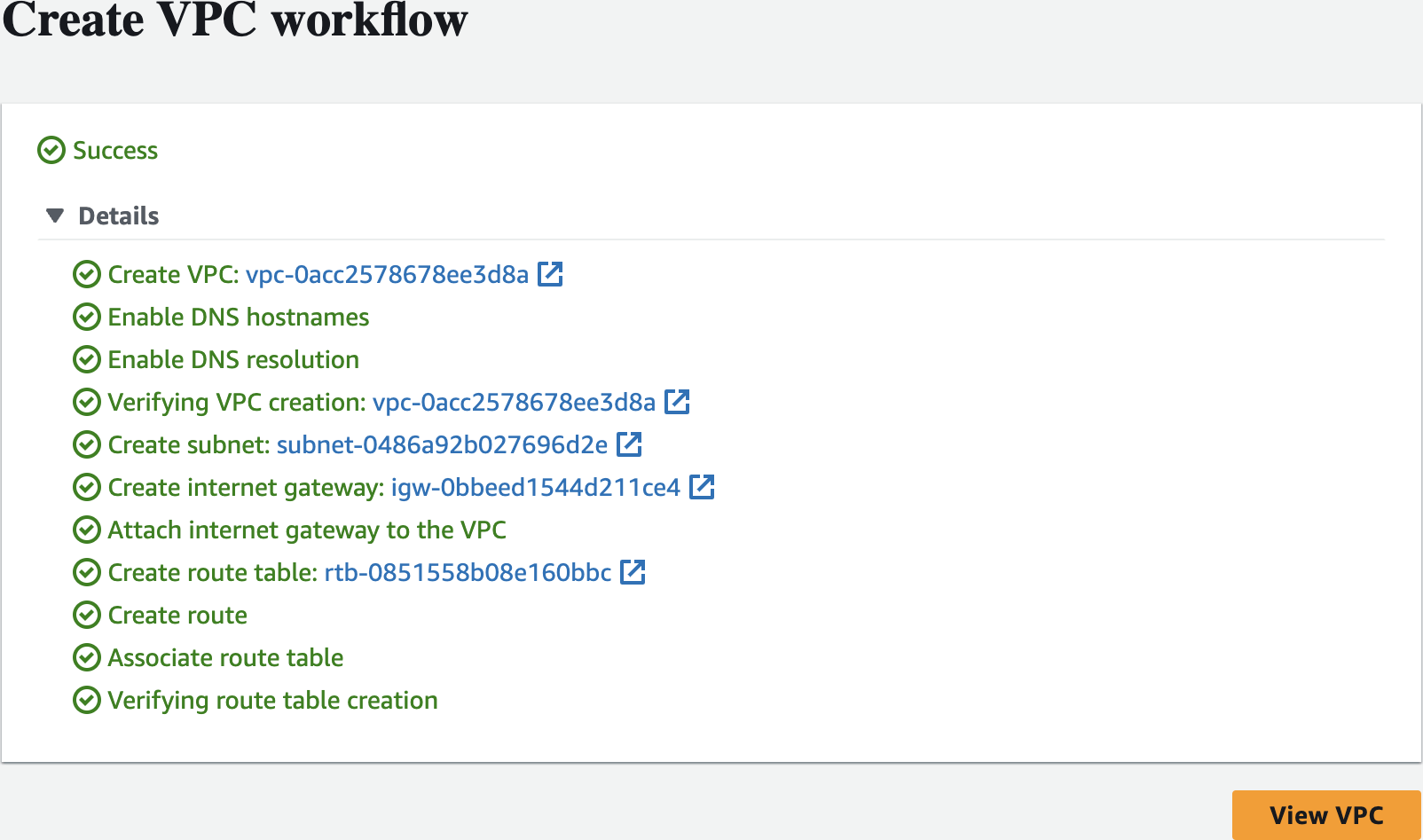
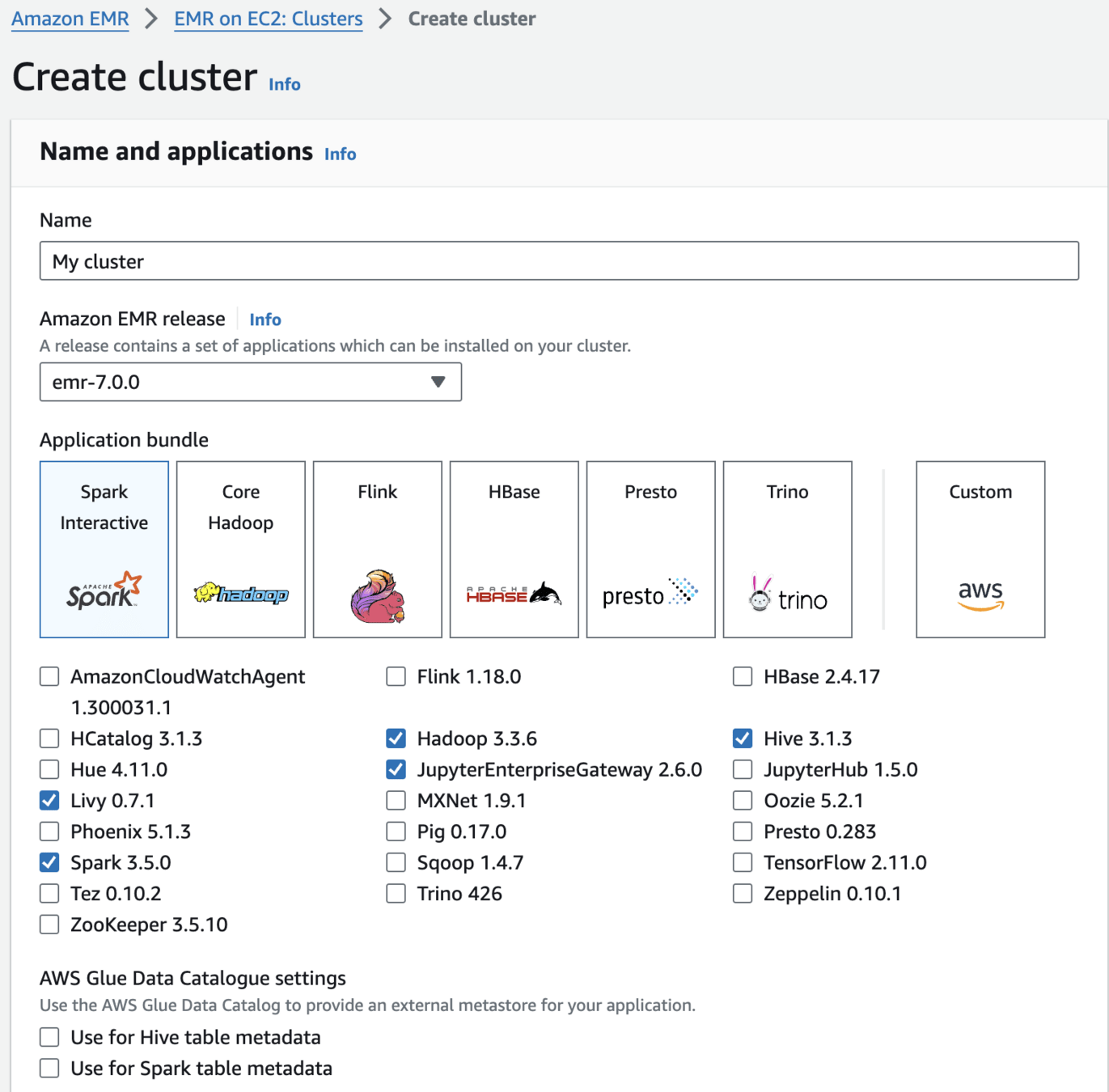
Create an Amazon EMR Cluster as follows - Name and applications
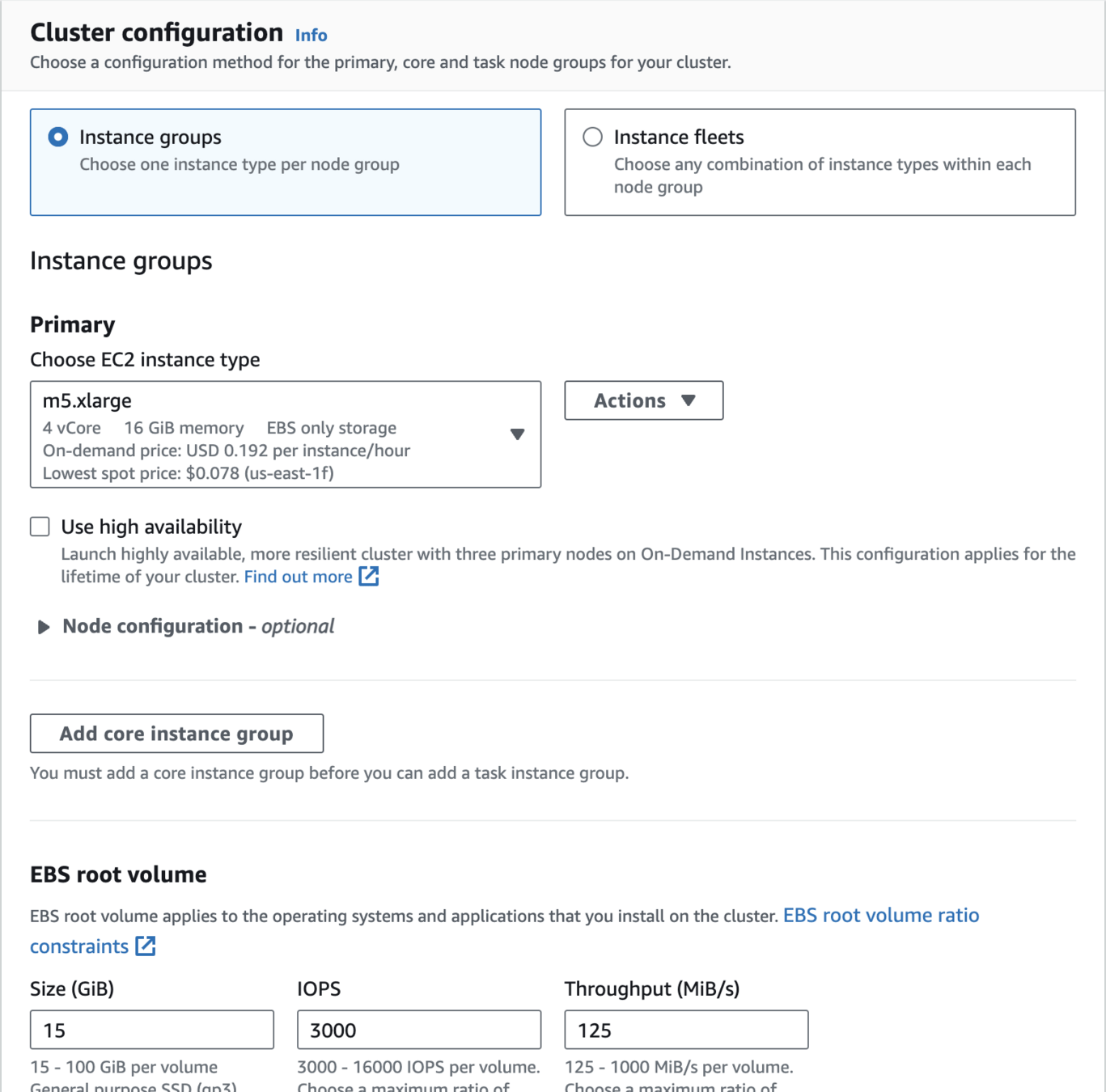
Create an Amazon EMR Cluster as follows - Cluster Configuration
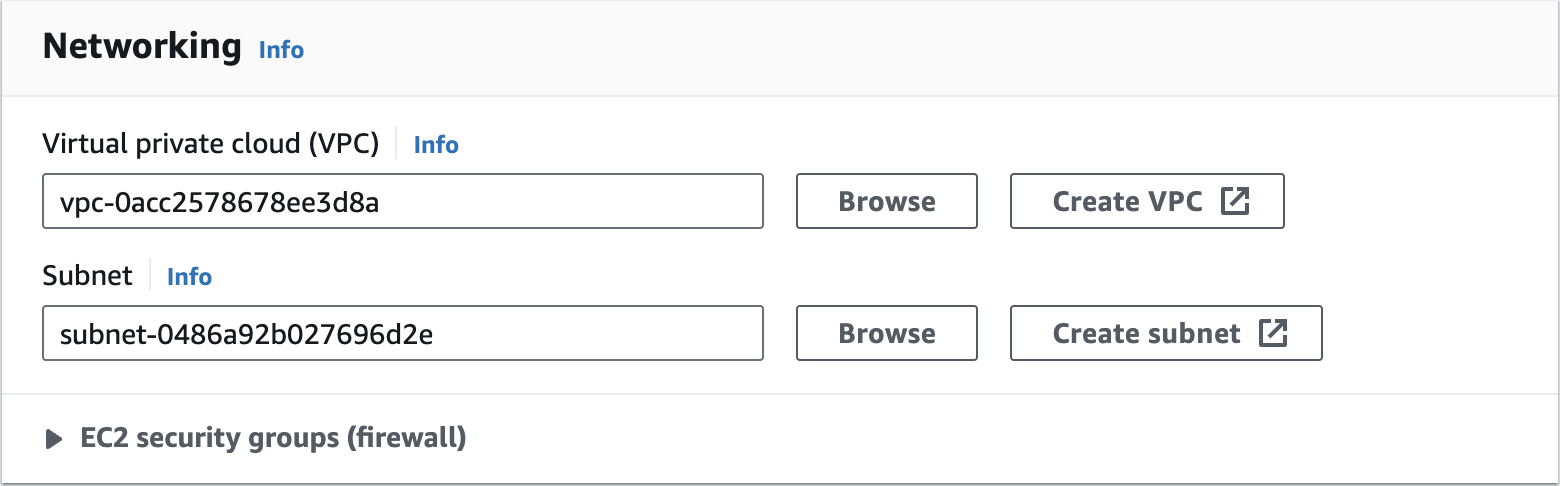
Create an Amazon EMR Cluster as follows - Networking
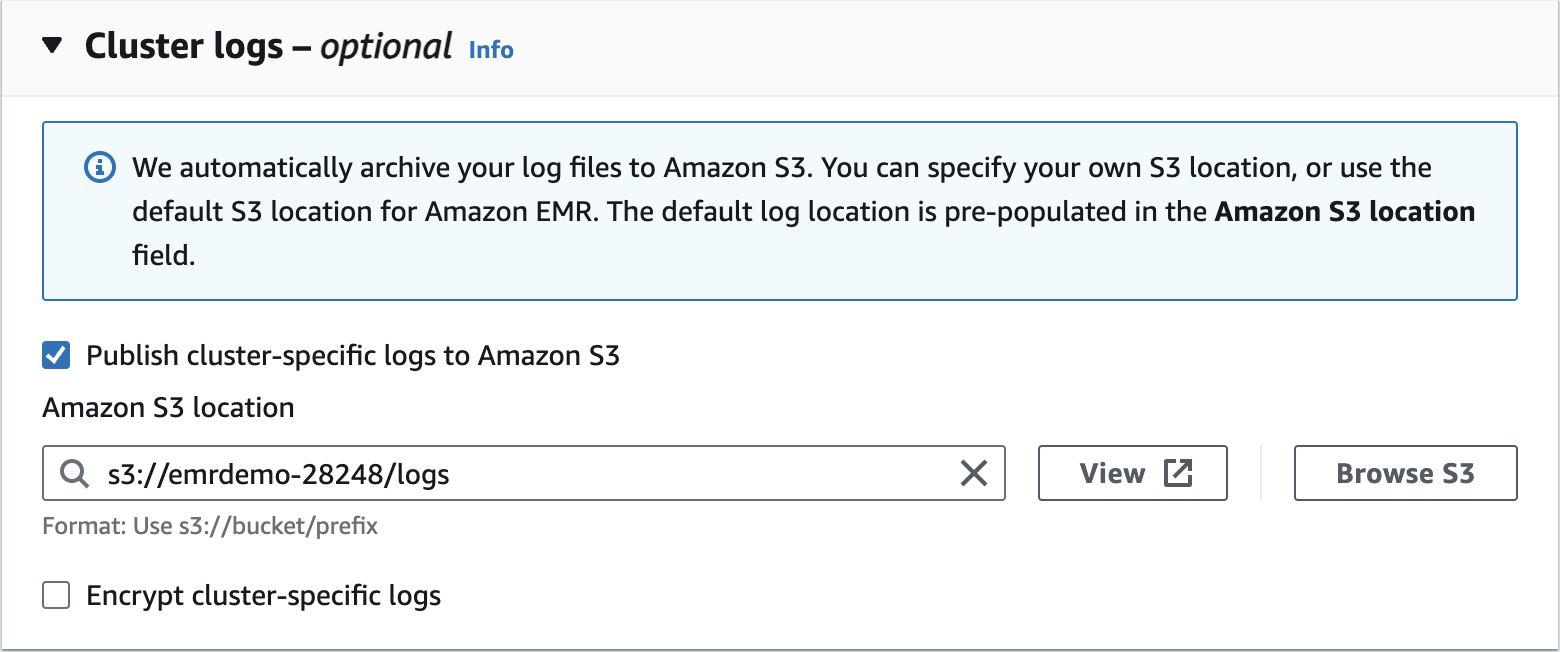
Create an Amazon EMR Cluster as follows - Cluster Logs
Create an Amazon EMR Cluster as follows - Security configuration and EC2 key pair
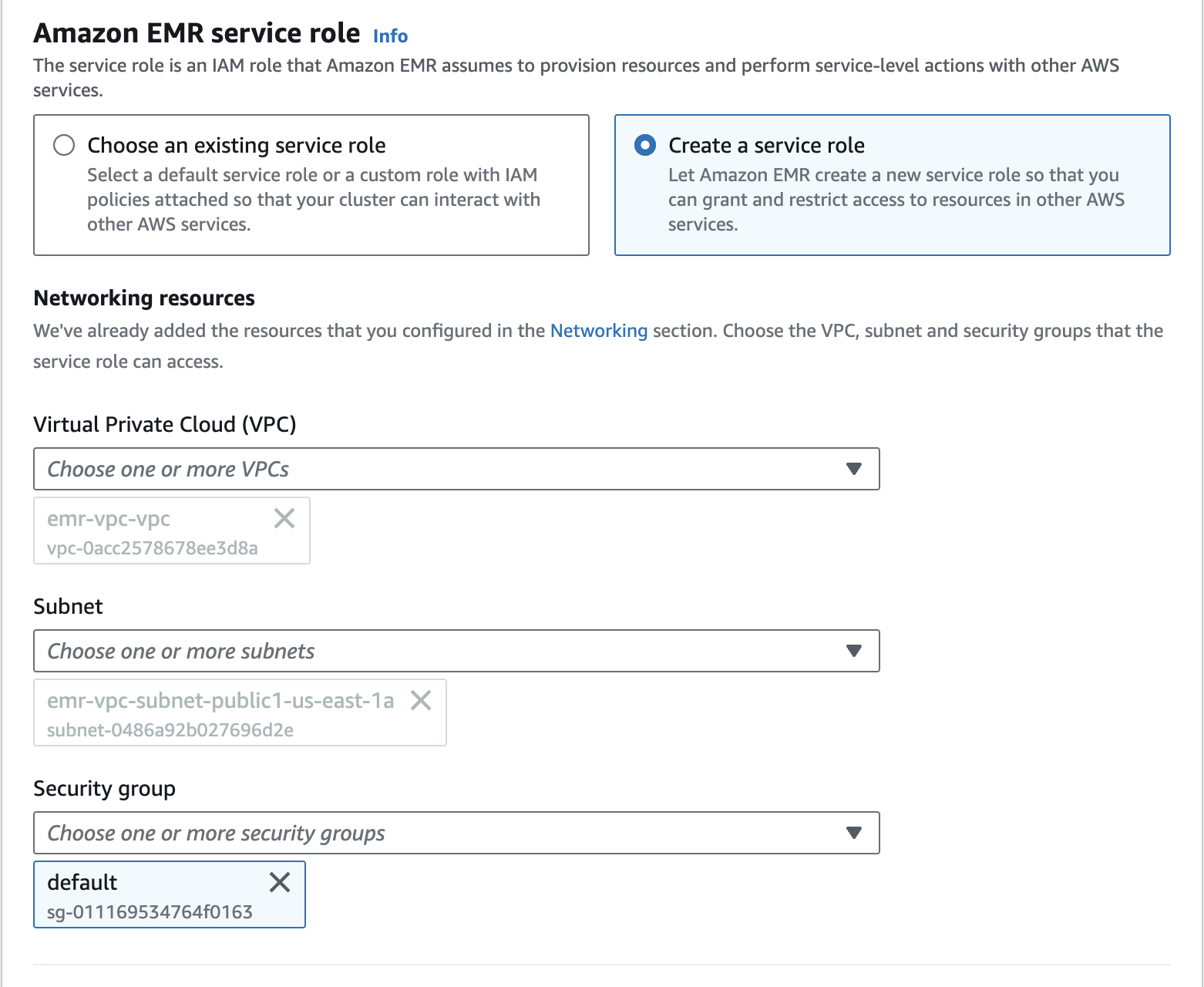
Create an Amazon EMR Cluster as follows - Amazon EMR service role
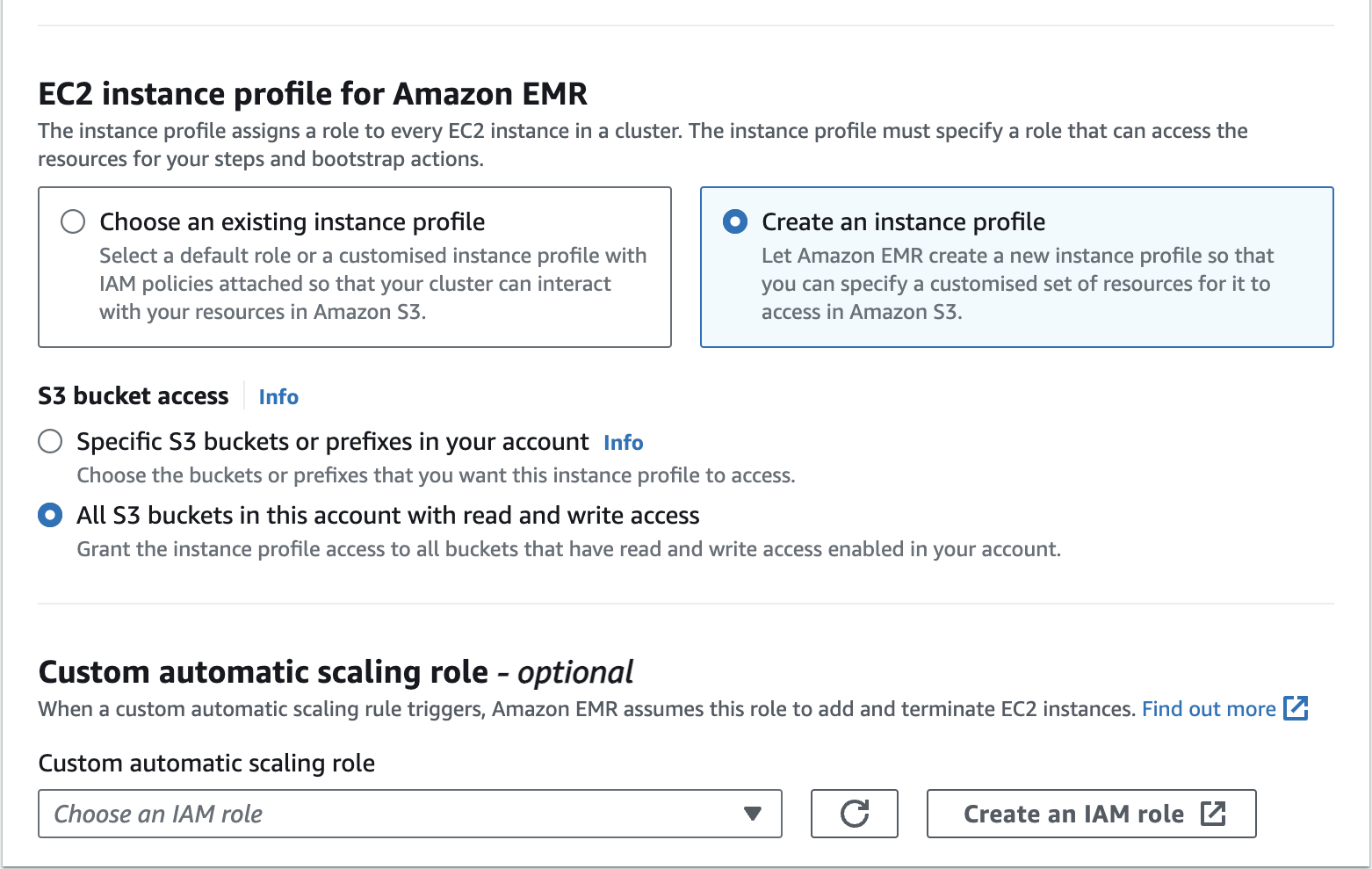
Create an Amazon EMR Cluster as follows - EC2 instance profile for Amazon EMR
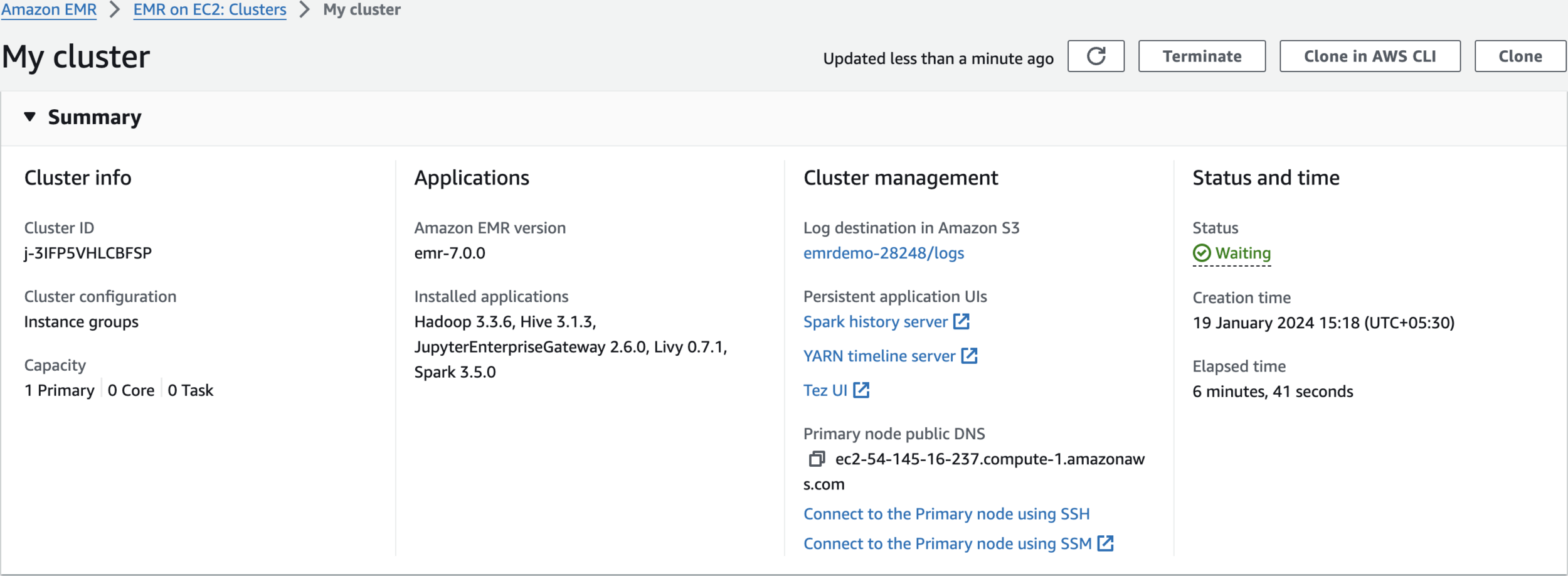
Wait for some time till Cluster Status changes to Waiting
Open an Inbound Rule to SSH from Cloud Shell to Master Node
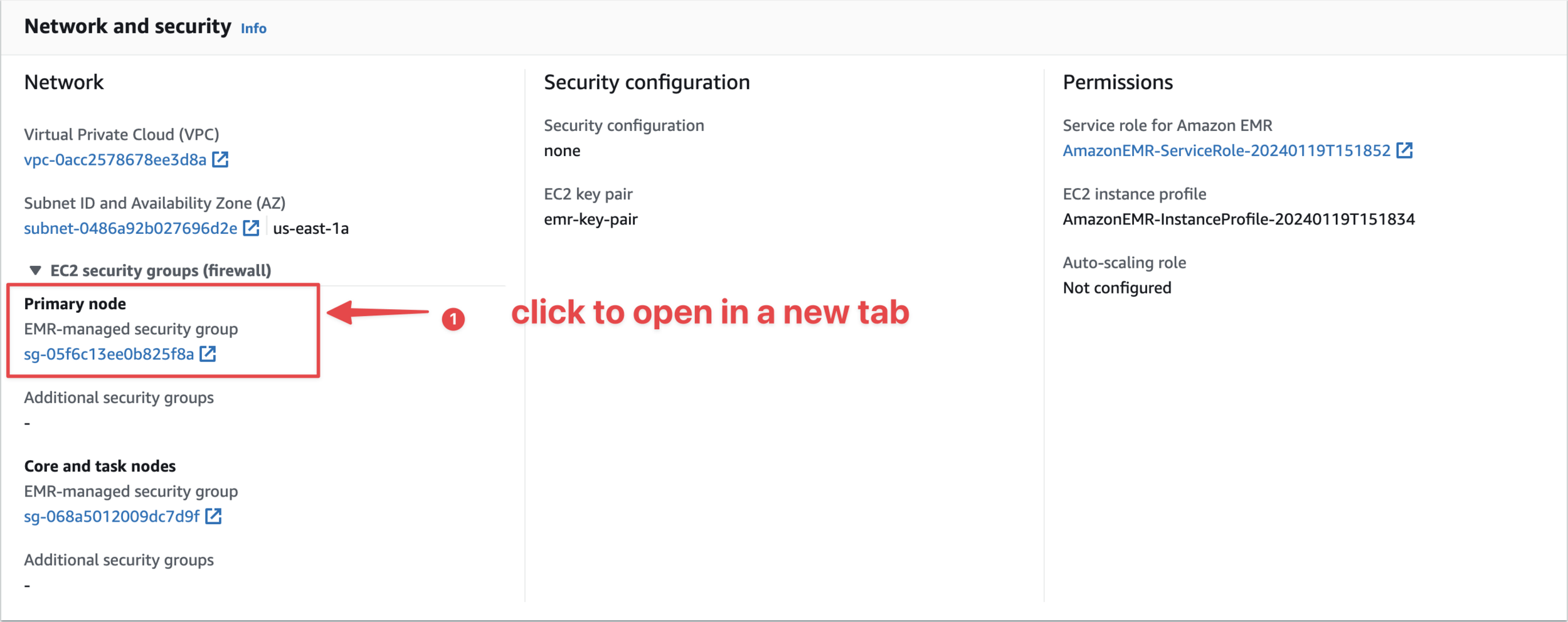
Edit Inbound Rules and Save

SSH from Cloud Shell Instructions are available to EMR Cluster Summary Page
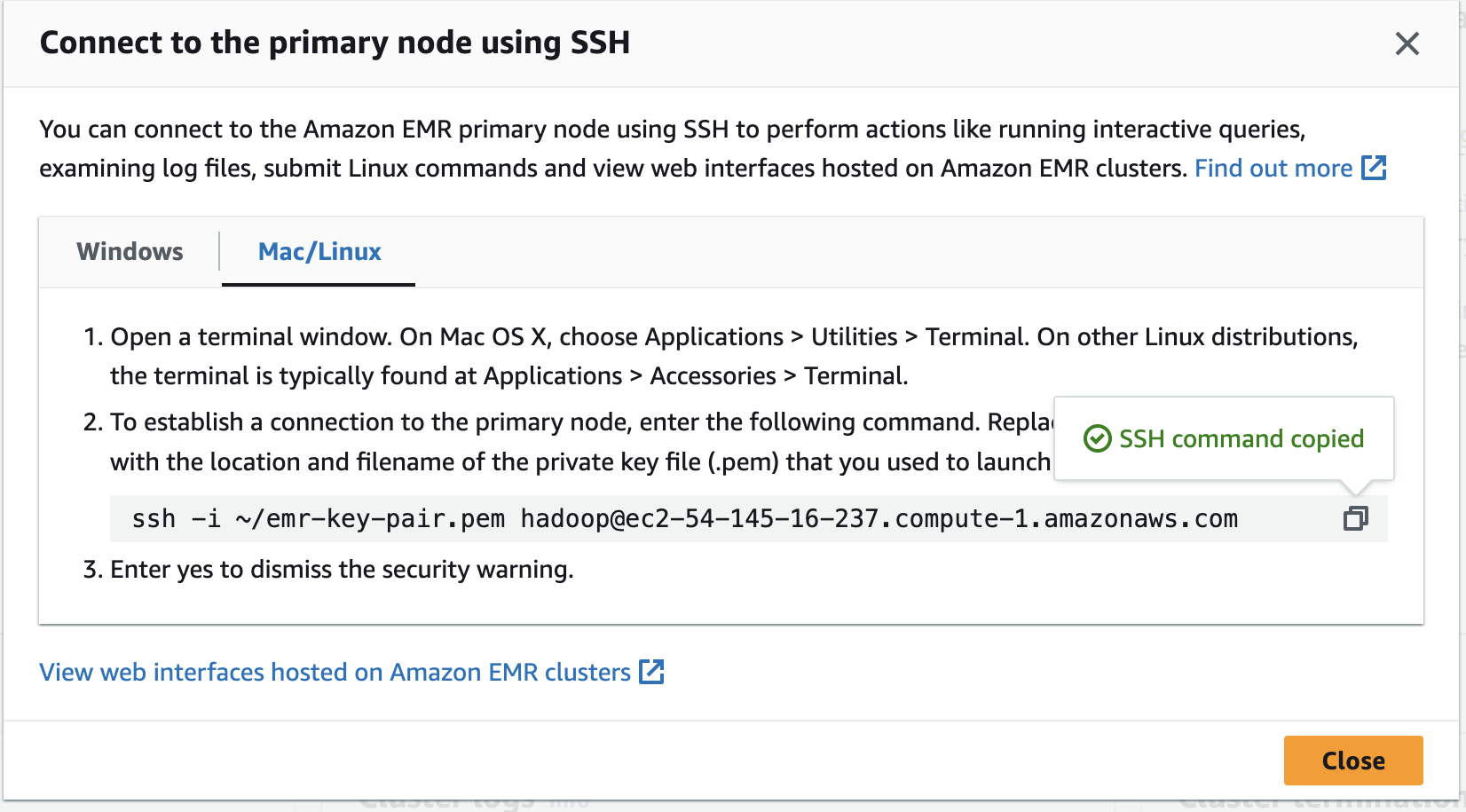
SSH from Cloud Shell
chmod 600 ~/emr-key-pair.pemssh -i ~/emr-key-pair.pem hadoop@ec2-54-145-16-237.compute-1.amazonaws.com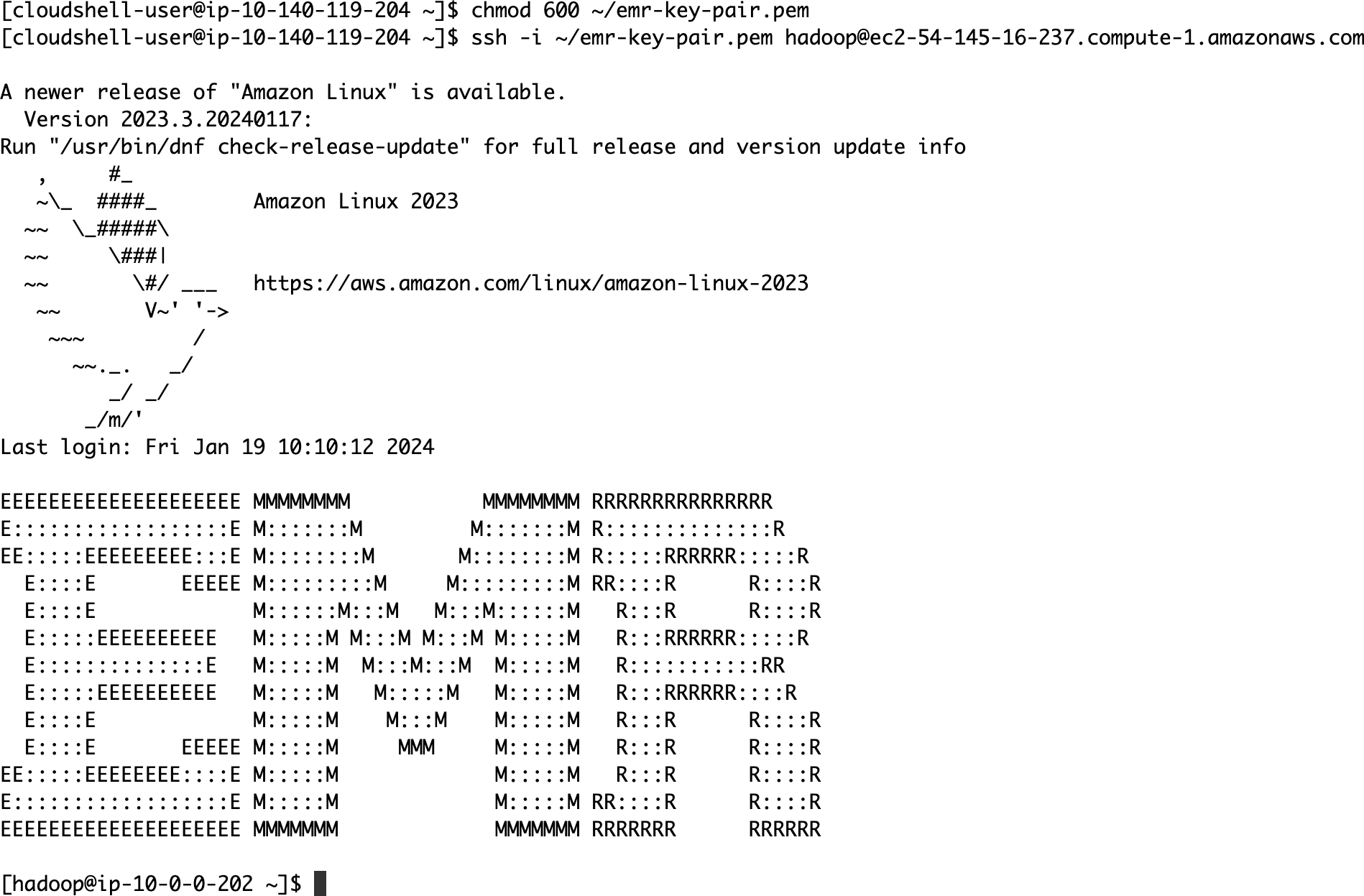
Create Apache Spark PySpark program to execute some aggregation.
Copy and paste the following code.
cat > test.py << EOF
import argparse
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, lit
from pyspark.sql.types import DateType
def aggregate_data(data_source, output_uri):
with SparkSession.builder.appName("SampleAggregation").getOrCreate() as spark:
# Load the CSV data
df = spark.read.csv(data_source, header=True, inferSchema=True)
# Processing logic
df = df.withColumn("Date", col("Date").cast(DateType()))
filtered_df = df.filter(col("Date") >= lit("2023-01-10"))
aggregated_df = filtered_df.groupBy("UserID").sum("PurchaseAmount")
# Write the results
aggregated_df.write.mode("overwrite").csv(output_uri, header=True)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--data_source', help="The URI for your CSV data, like an S3 bucket location.")
parser.add_argument('--output_uri', help="The URI where output is saved, like an S3 bucket location.")
args = parser.parse_args()
aggregate_data(args.data_source, args.output_uri)
EOFExecute the Below Command to Submit the Apache Spark Job
spark-submit test.py \
--data_source s3://emrdemo-28248/data.csv \
--output_uri s3://emrdemo-28248/output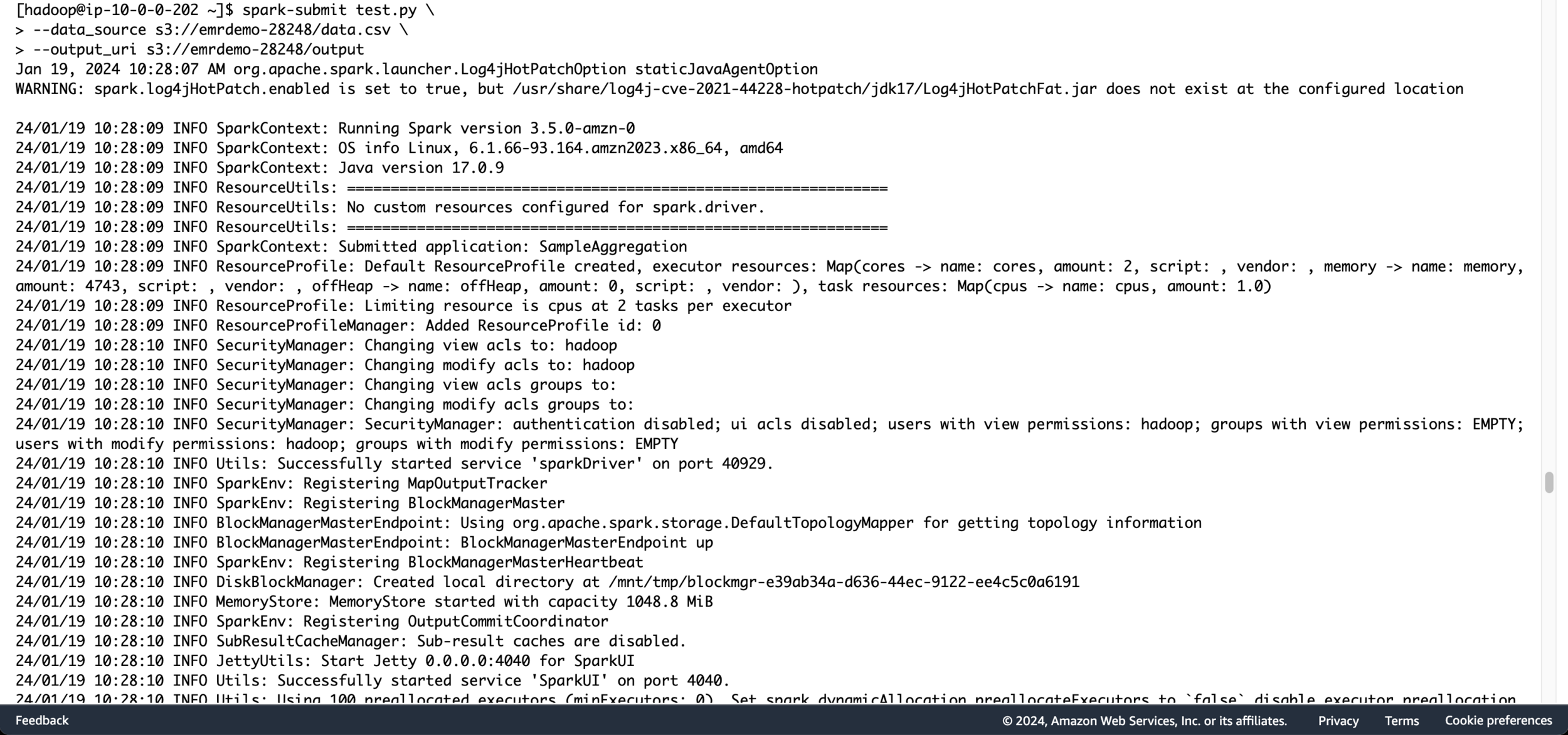
Verify S3 Output folder
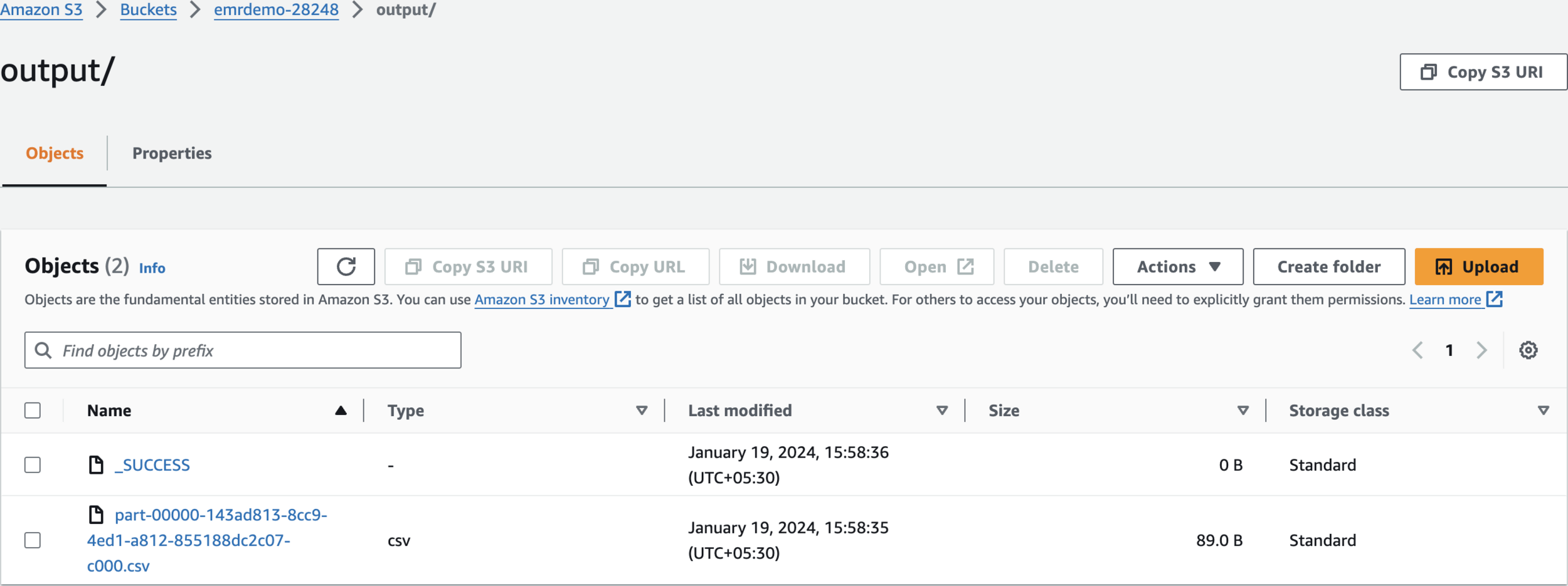
Verify Output Result

Clean Up
1. Terminate EMR Cluster
2. Delete S3 Buckets
3. Delete IAM Roles
4. Delete VPC