AWS Batch
Hands-On
Demo

Agenda
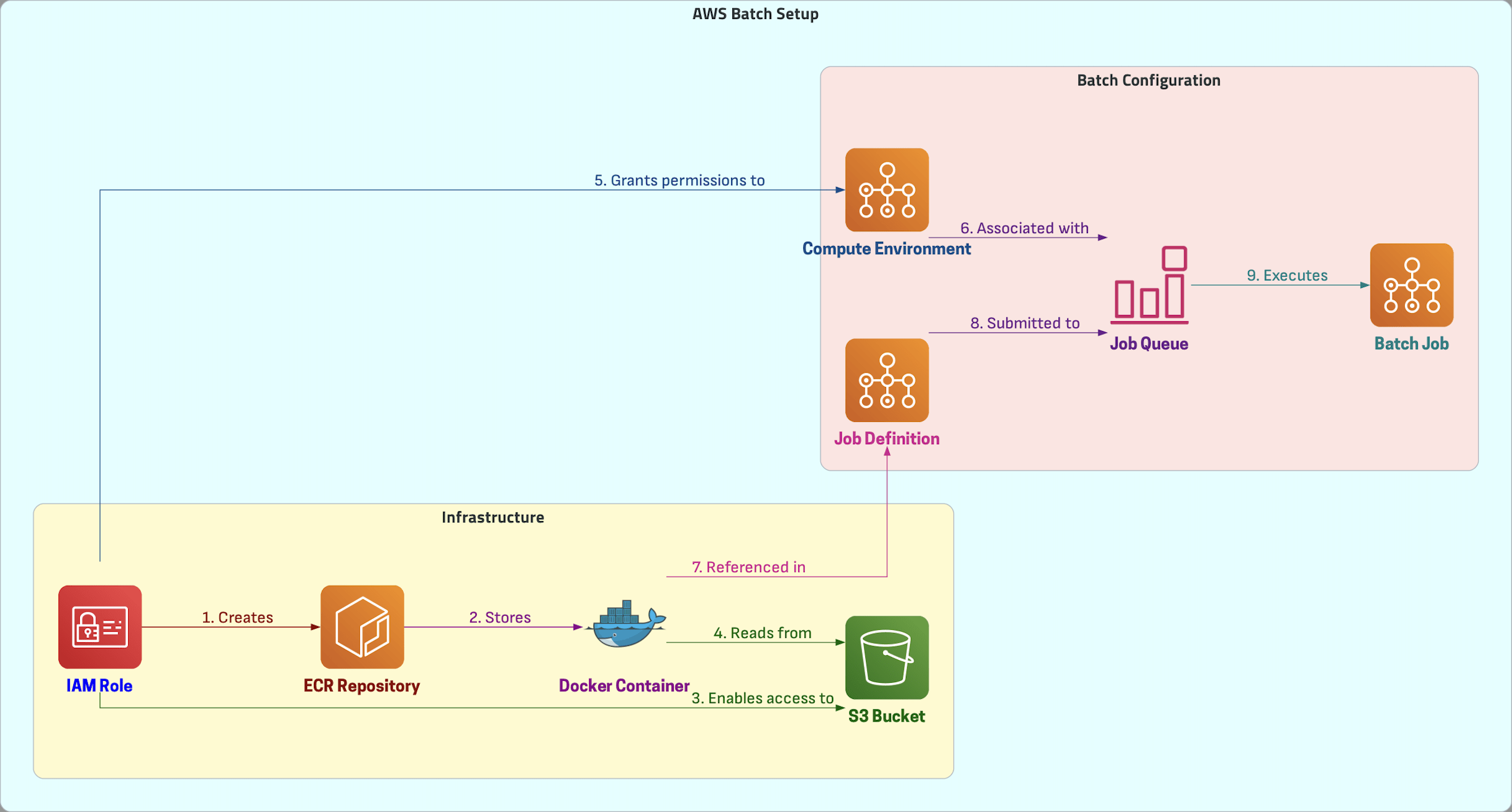
In this Demo, we will
- Create an IAM Role
- Create ECR Repository
- Create S3 Bucket and Upload Sample Data
- Create and Upload Docker Container
- Configure AWS Batch Compute Environment
- Create Job Queue
- Create Job Definition
- Submit Job
Demo Overview
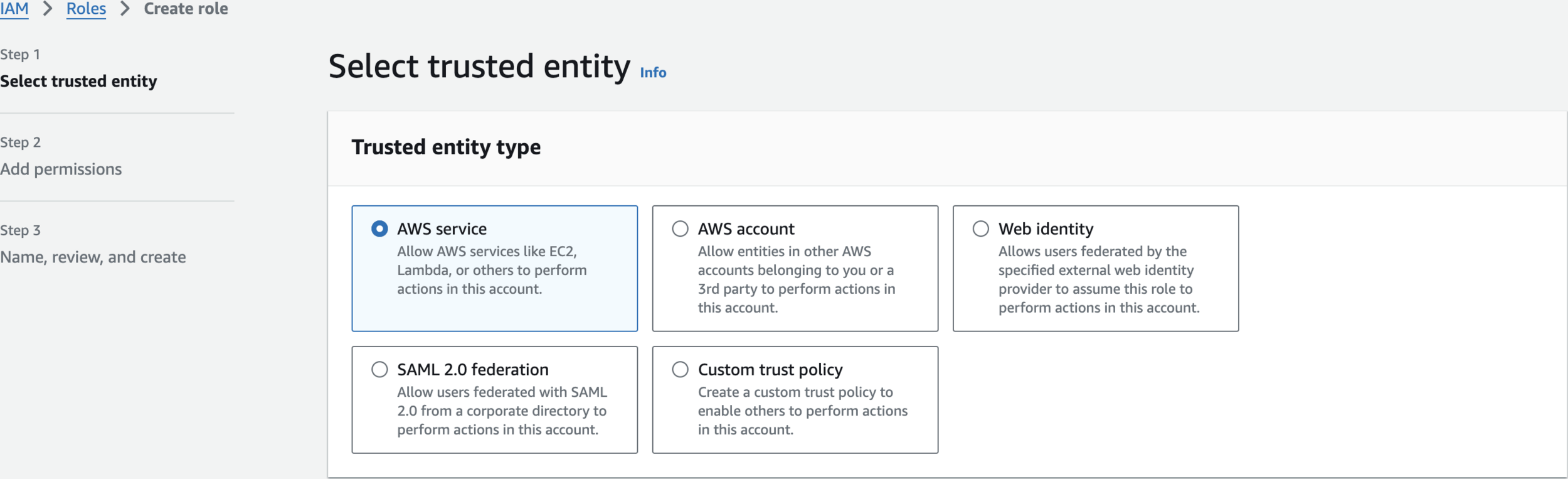
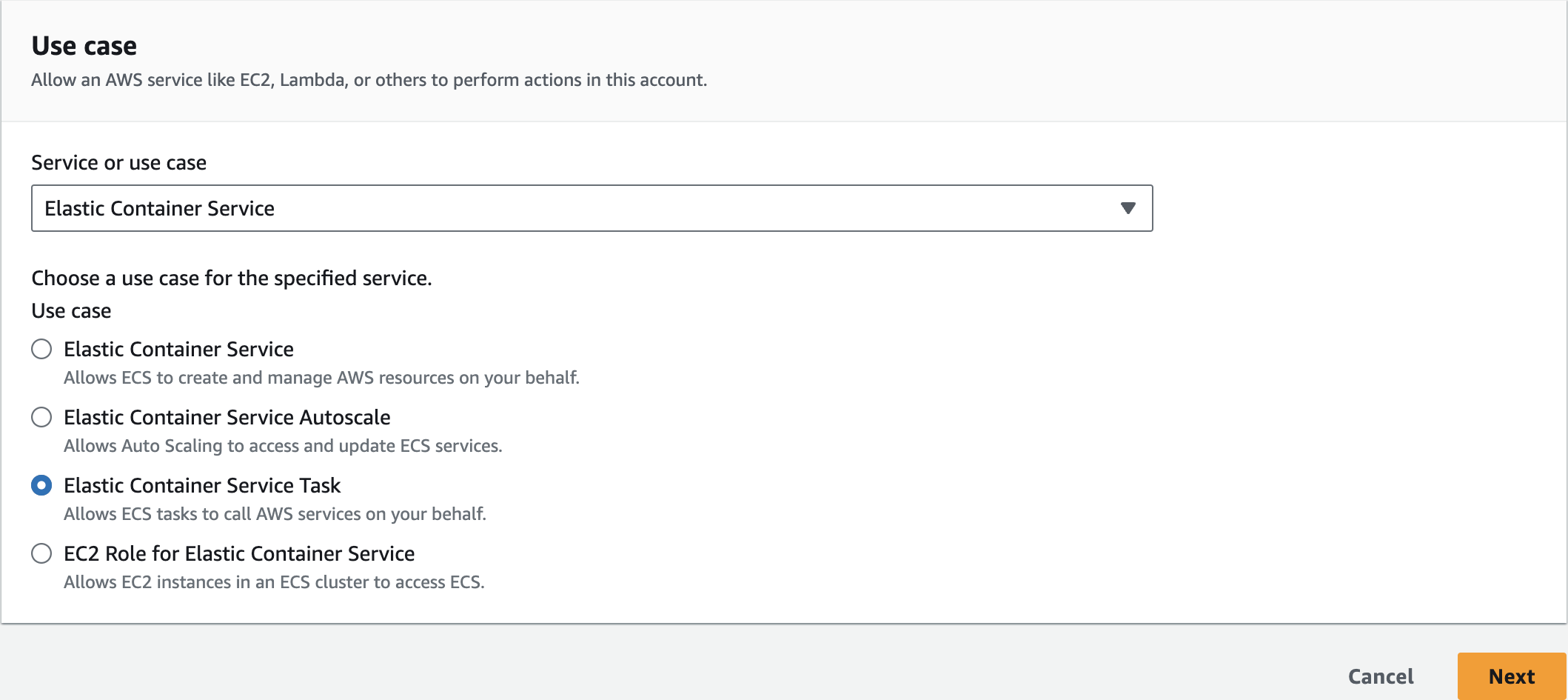
Create an IAM Role
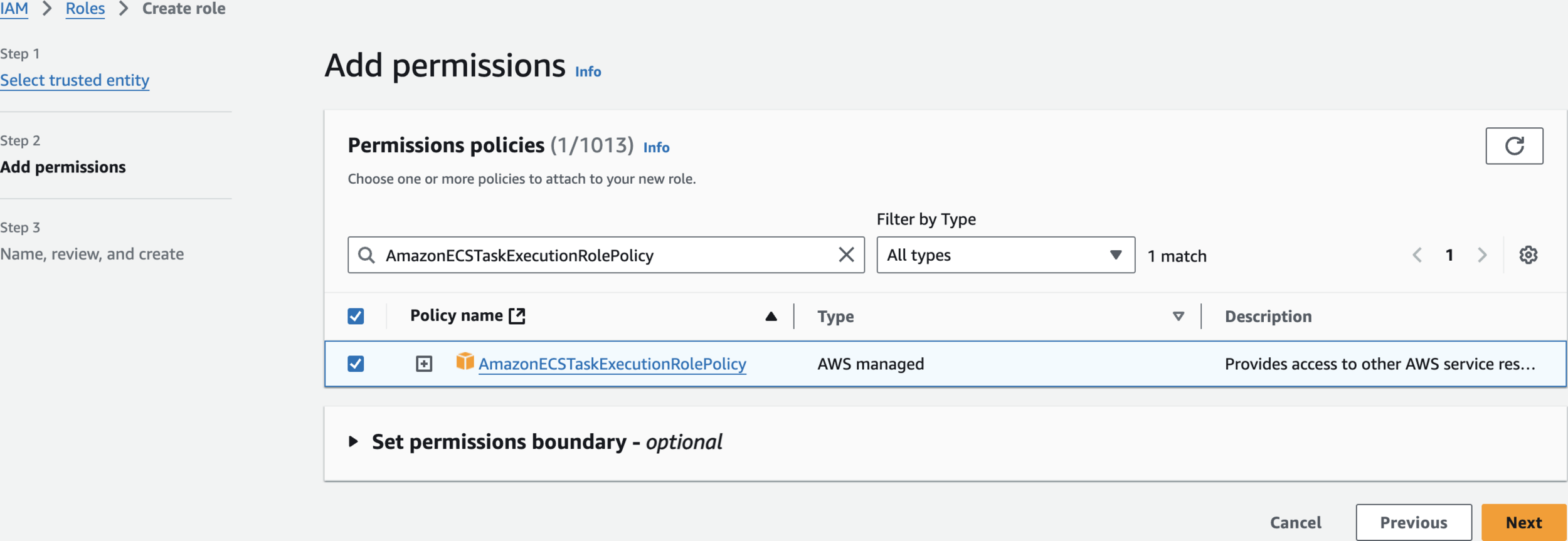
AmazonECSTaskExecutionRolePolicy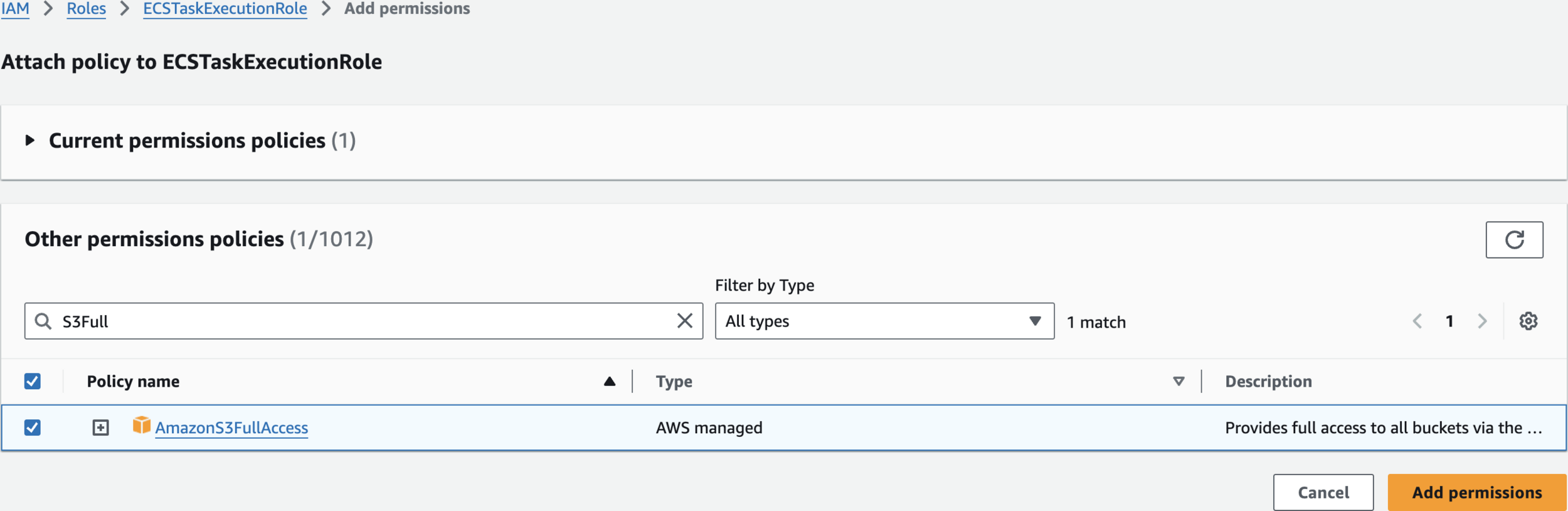
AmazonS3FullAccess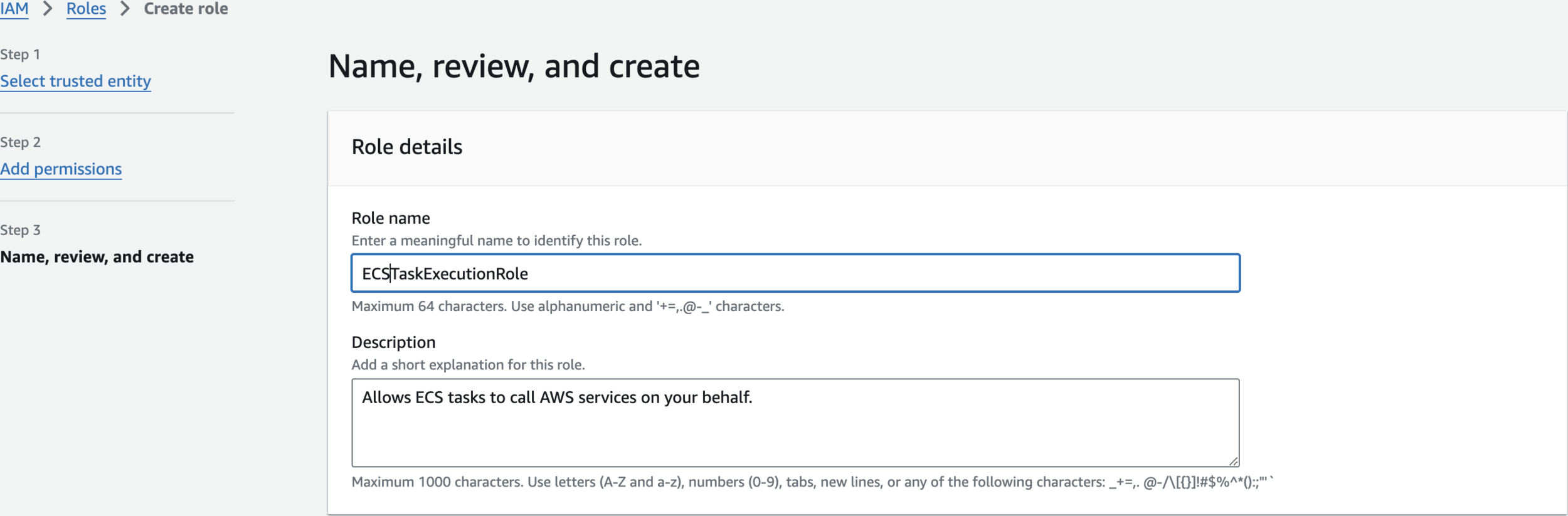
ECSTaskExecutionRole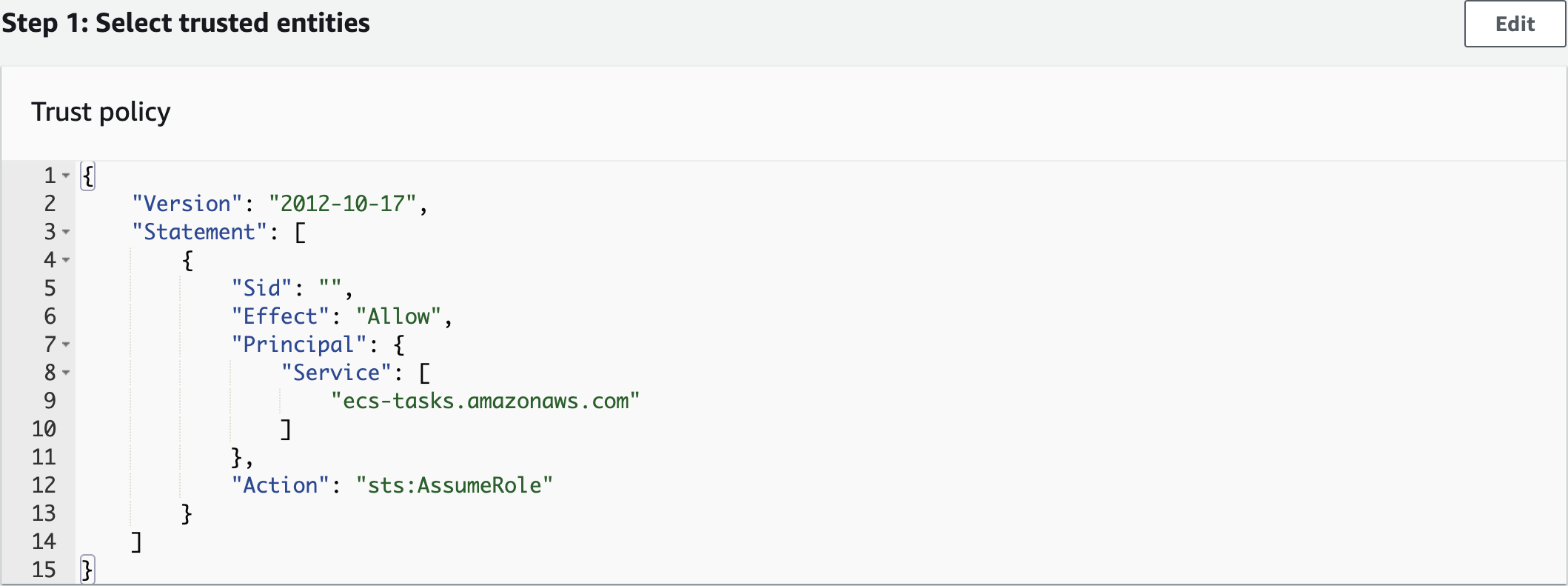

Create ECR Repository

batch-demo-app
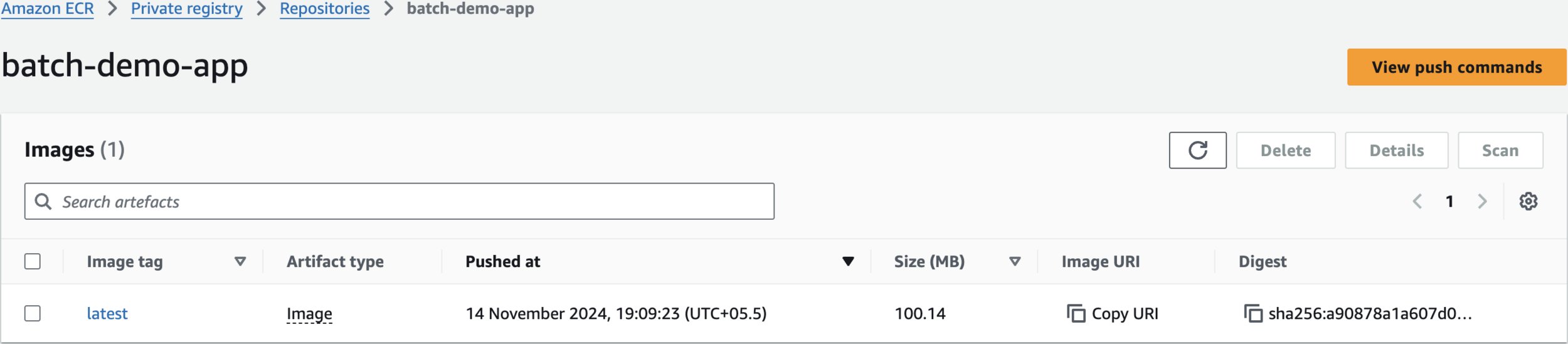
remember to check here in case you need the commands
Create S3 Bucket and Upload Sample Data
# Generate a random suffix (using timestamp)
TIMESTAMP=$(date +%Y%m%d%H%M%S)
BUCKET_NAME="batch-demo-${TIMESTAMP}"
# Create the bucket
aws s3api create-bucket \
--bucket ${BUCKET_NAME} \
--region us-east-1
echo "Created bucket: ${BUCKET_NAME}"
# Create input and output folders
# (by creating empty objects with trailing slashes)
aws s3api put-object --bucket ${BUCKET_NAME} --key input/
aws s3api put-object --bucket ${BUCKET_NAME} --key output/
Create S3 Bucket and Folder Structure
# First create the data.csv file
cat << 'EOF' > data.csv
month,revenue,costs,units_sold,customer_count,avg_order_value
Jan_2024,120500.50,85000.75,1250,850,96.40
Feb_2024,135750.25,92500.50,1380,920,98.35
Mar_2024,142800.75,95750.25,1450,975,98.50
Apr_2024,128900.25,88250.50,1320,890,97.65
May_2024,155200.50,98500.75,1580,1050,98.25
Jun_2024,168500.75,102750.50,1720,1150,98.00
Jul_2024,172500.50,105250.25,1750,1180,98.55
Aug_2024,180250.25,108500.50,1820,1250,99.05
Sep_2024,165750.75,101250.25,1680,1120,98.65
Oct_2024,158900.50,99750.75,1620,1080,98.10
EOFSample data.csv
# Upload data.csv to the input folder
aws s3 cp data.csv s3://${BUCKET_NAME}/input/data.csv
# Verify the setup
echo "Listing contents of bucket ${BUCKET_NAME}:"
aws s3 ls s3://${BUCKET_NAME}/ --recursive
# Save bucket name for later use
echo ${BUCKET_NAME} > bucket_name.txt
echo "Bucket name saved to bucket_name.txt"Upload data.csv to S3 Bucket
Create and Upload Docker Container
cat << 'EOF' > process_data.py
import boto3
import pandas as pd
import os
import sys
import logging
from datetime import datetime
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def process_file(input_bucket, input_key, output_bucket, output_key):
"""
Process data file from S3 and upload results back to S3.
Includes error handling and logging.
"""
s3 = boto3.client('s3')
try:
logger.info(f"Starting processing of s3://{input_bucket}/{input_key}")
# Download input file
local_input = f'/tmp/input_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
s3.download_file(input_bucket, input_key, local_input)
# Process the data
df = pd.read_csv(local_input)
logger.info(f"Loaded data with shape: {df.shape}")
# Get numeric columns only
numeric_columns = df.select_dtypes(include=['float64', 'int64']).columns
# Calculate statistics for numeric columns only
result = pd.DataFrame({
'column': numeric_columns,
'mean': df[numeric_columns].mean(),
'median': df[numeric_columns].median(),
'std': df[numeric_columns].std()
})
# Save and upload results
local_output = f'/tmp/output_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
result.to_csv(local_output, index=False)
s3.upload_file(local_output, output_bucket, output_key)
logger.info(f"Successfully uploaded results to s3://{output_bucket}/{output_key}")
# Cleanup temporary files
os.remove(local_input)
os.remove(local_output)
except Exception as e:
logger.error(f"Error processing file: {str(e)}")
raise
def main():
if len(sys.argv) != 5:
logger.error("Required arguments: input_bucket input_key output_bucket output_key")
sys.exit(1)
process_file(sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4])
if __name__ == "__main__":
main()
EOFSample Application Code
cat << 'EOF' > Dockerfile
FROM python:3.9-slim
# Install dependencies
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy application
COPY process_data.py .
# Set permissions
RUN chmod +x process_data.py
# Set entry point
ENTRYPOINT ["python", "process_data.py"]
EOFDockerfile
cat << 'EOF' > requirements.txt
boto3==1.26.137
pandas==2.0.0
numpy==1.24.3
EOFrequirements.txt
# Export environment variables
export AWS_ACCOUNT_ID=651623850282
export AWS_REGION=us-east-1
# ECR repository URL
export ECR_REPO="${AWS_ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com"
# Get ECR login token
aws ecr get-login-password --region ${AWS_REGION} \
| docker login --username AWS --password-stdin ${ECR_REPO}
# Build image
docker build -t batch-demo-app .
# Tag image
docker tag batch-demo-app:latest ${ECR_REPO}/batch-demo-app:latest
# Push to ECR
docker push ${ECR_REPO}/batch-demo-app:latestPush Docker Image to ECR
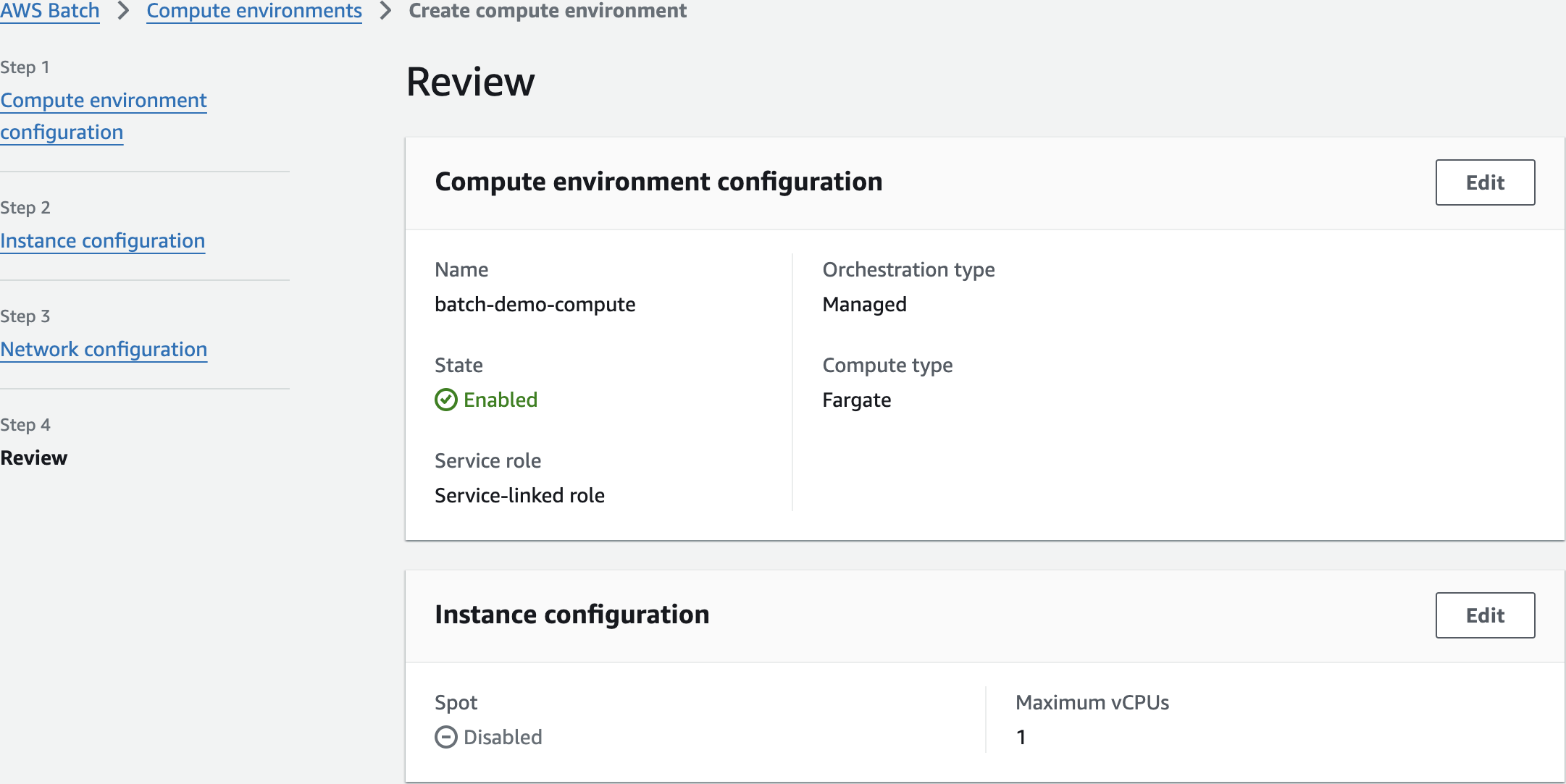
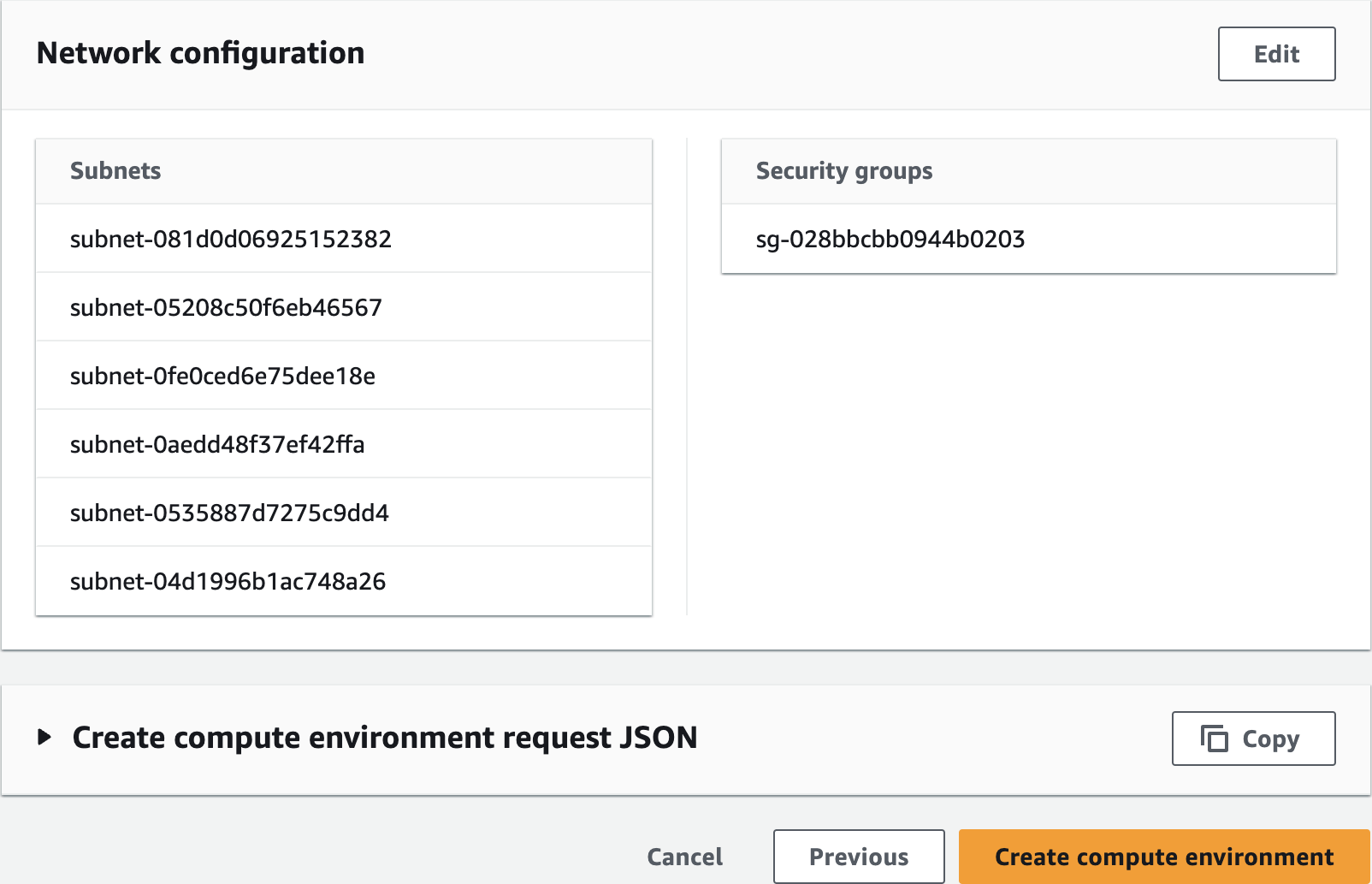
Configure AWS Batch Compute Environment
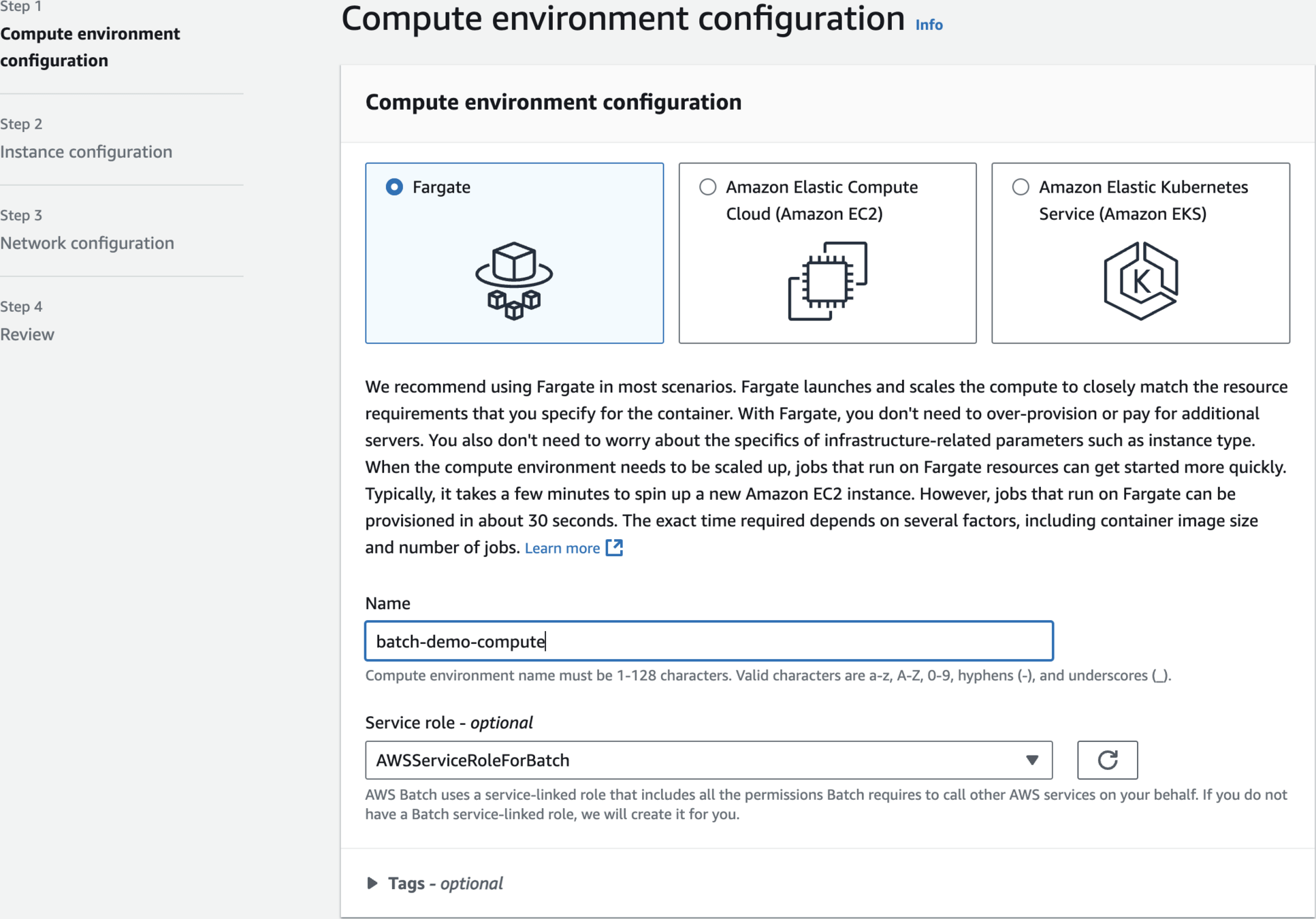
batch-demo-compute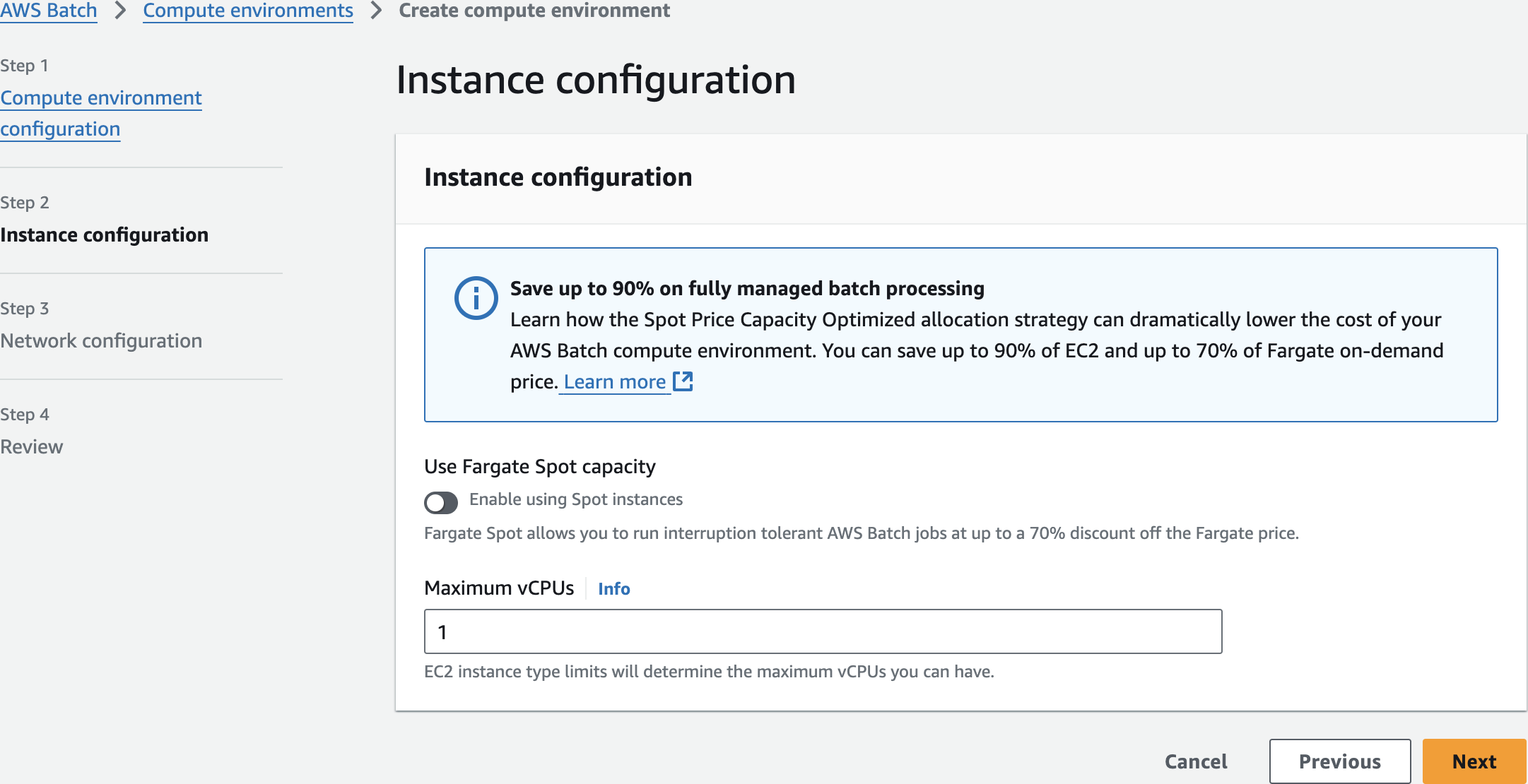

Create Job Queue
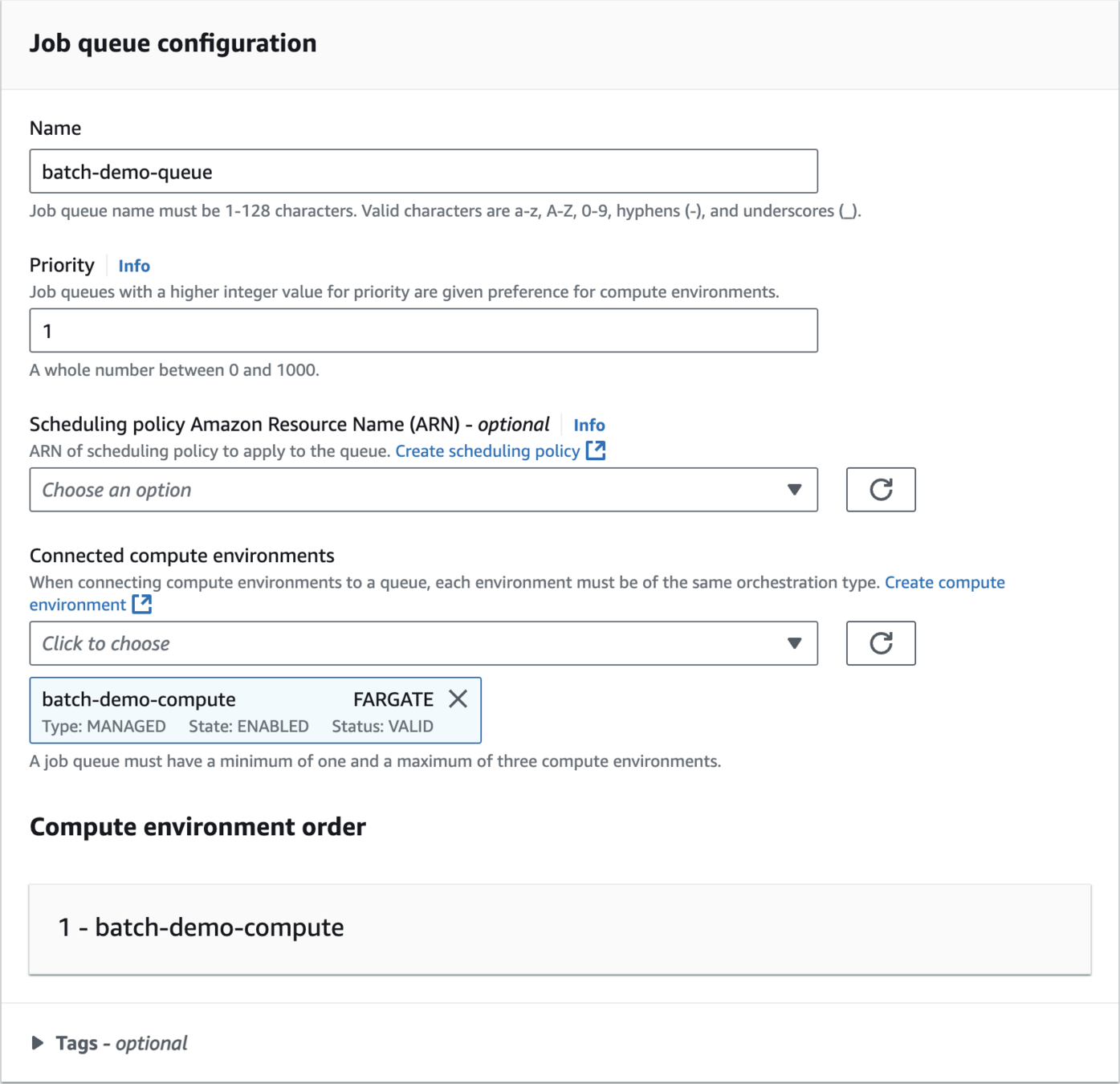
batch-demo-queue
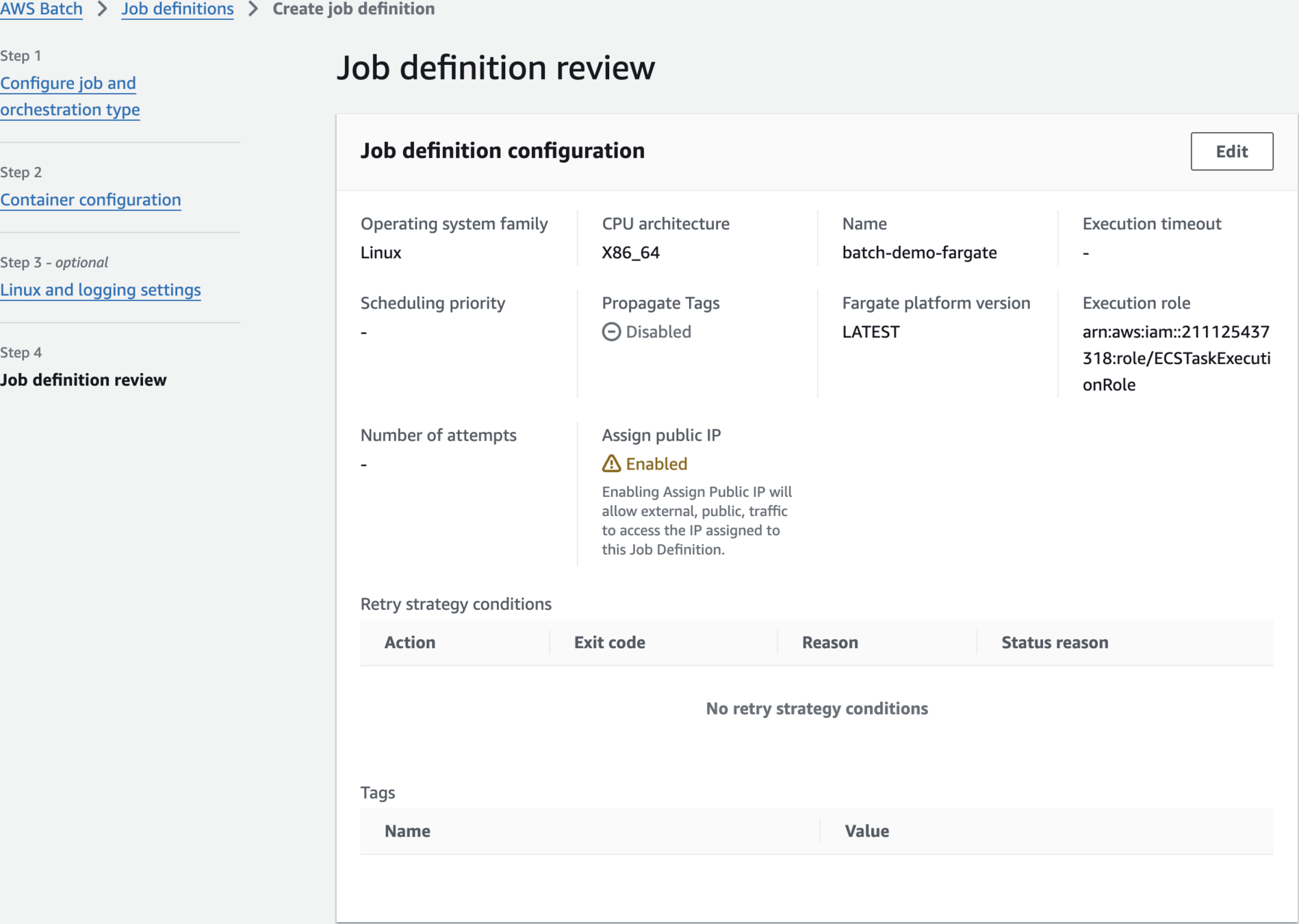
Create Job Definition
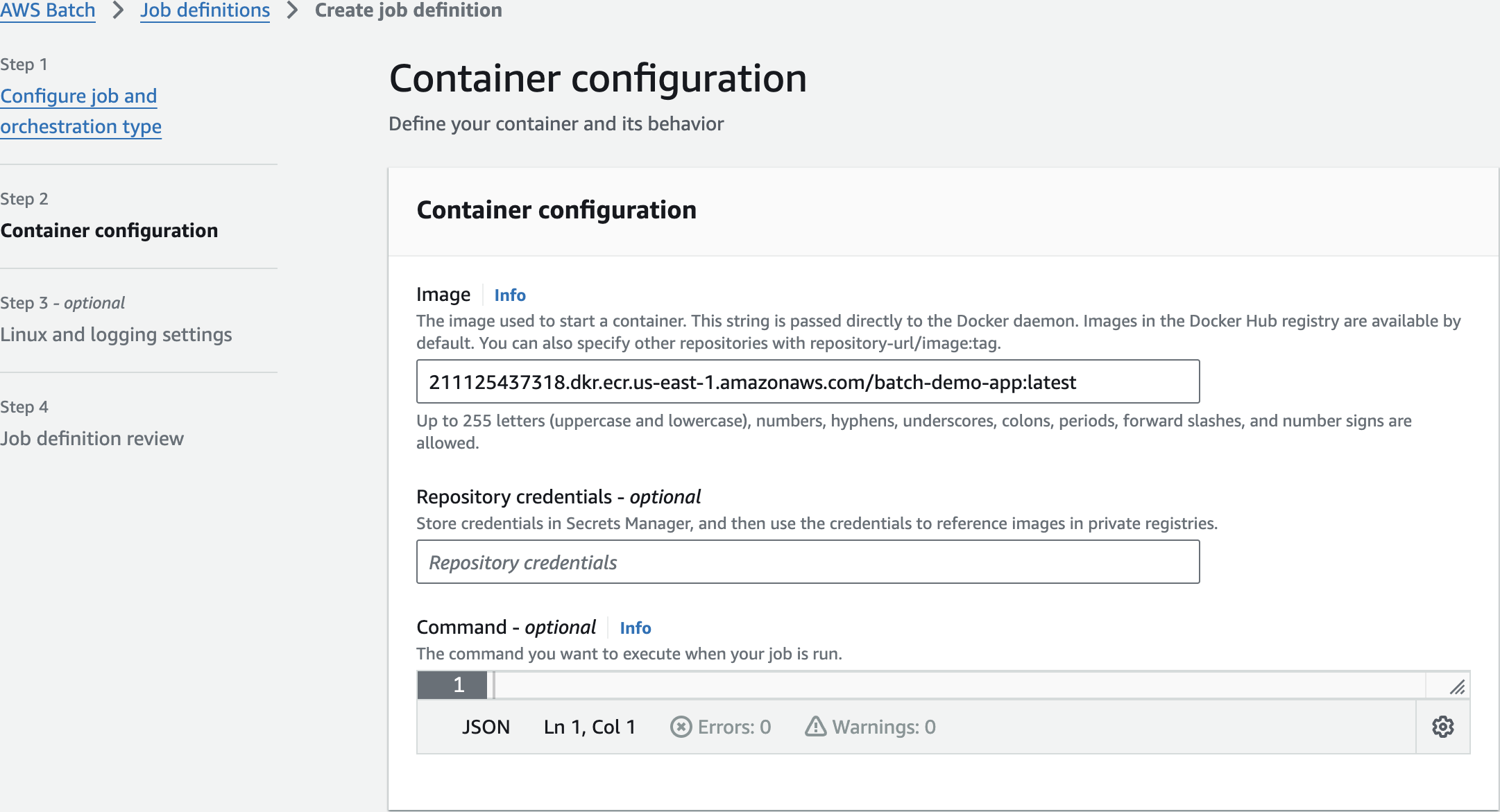
651623850282.dkr.ecr.us-east-1.amazonaws.com/batch-demo-app:latest
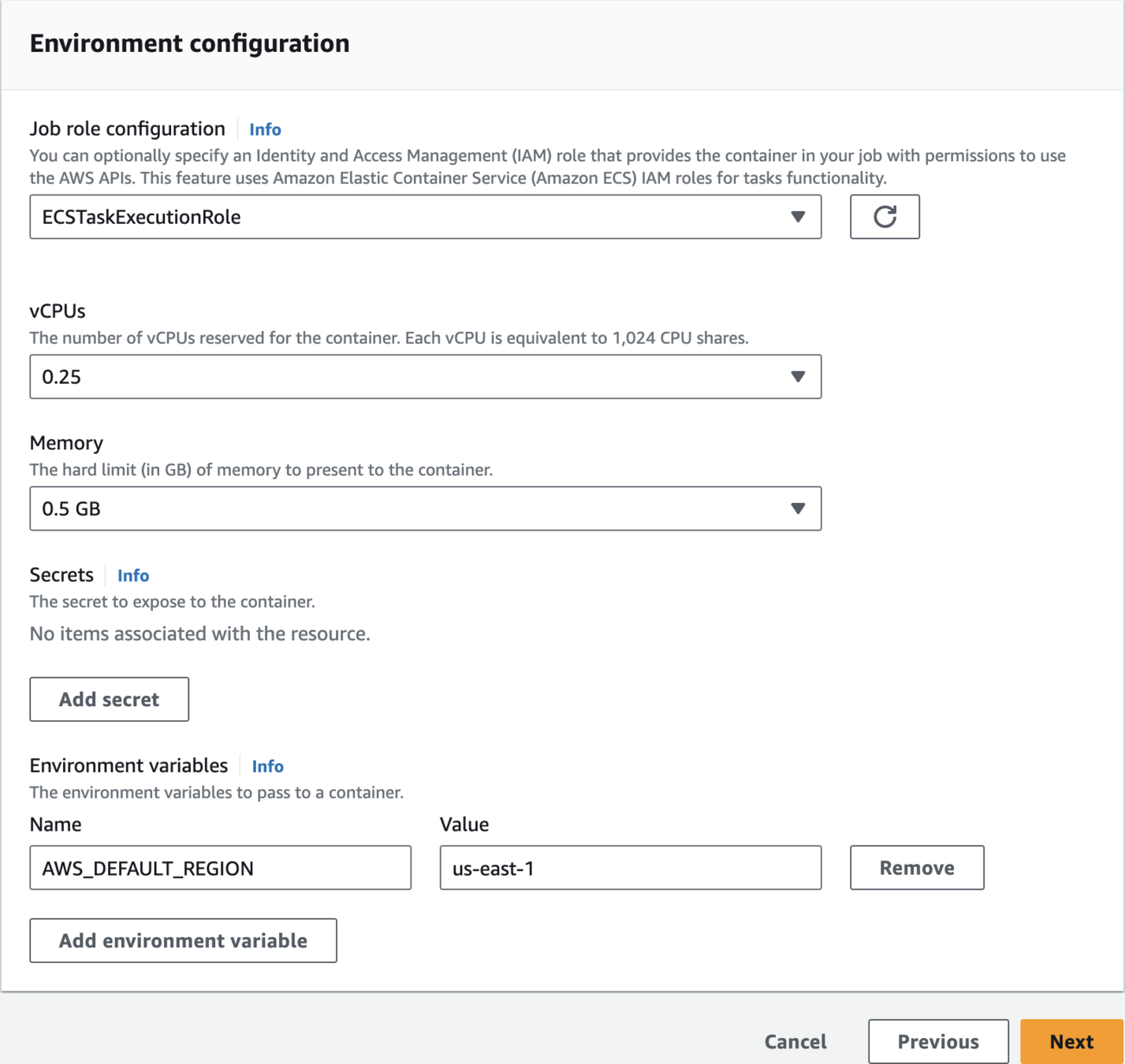



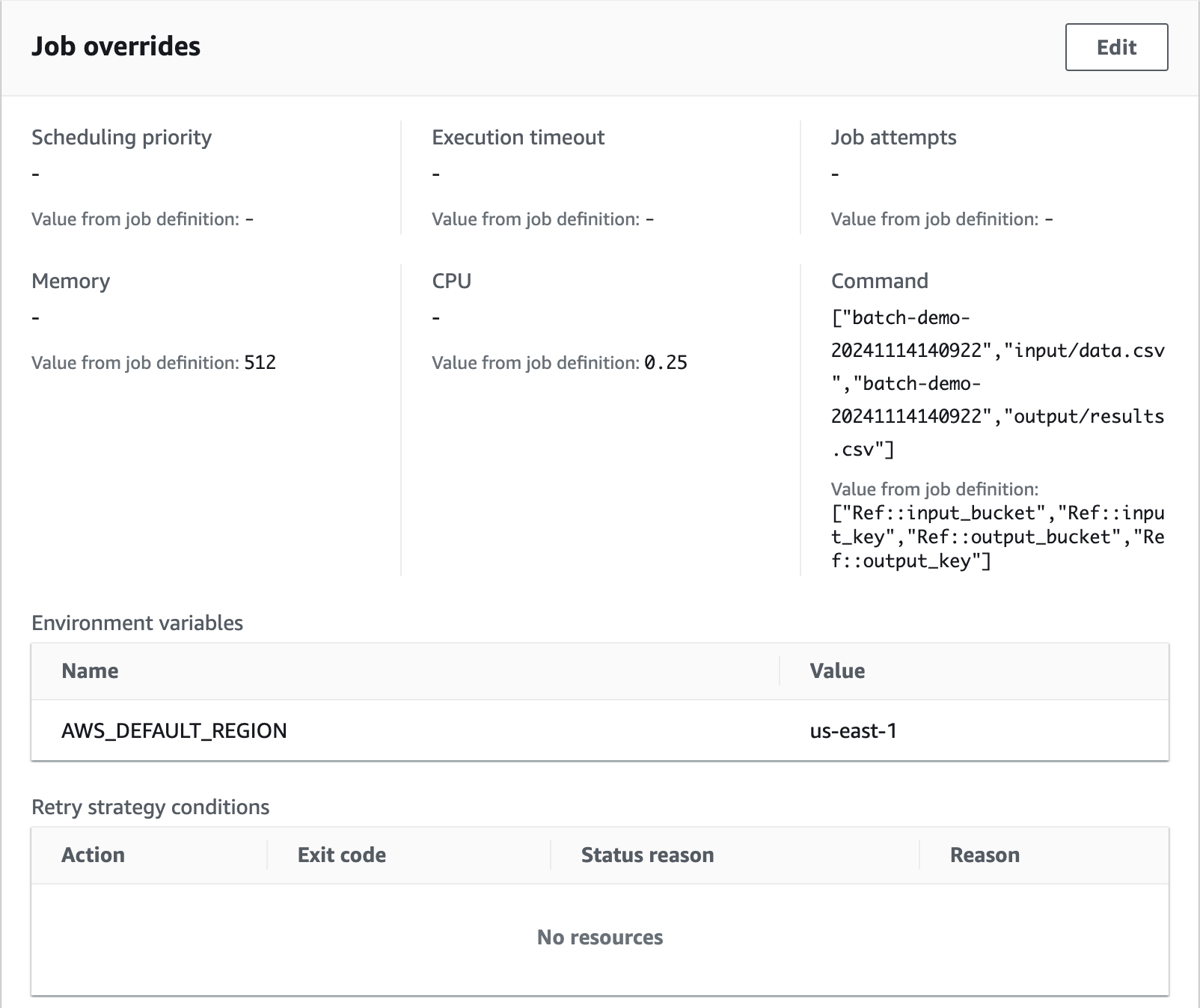
us-east-1AWS_DEFAULT_REGION
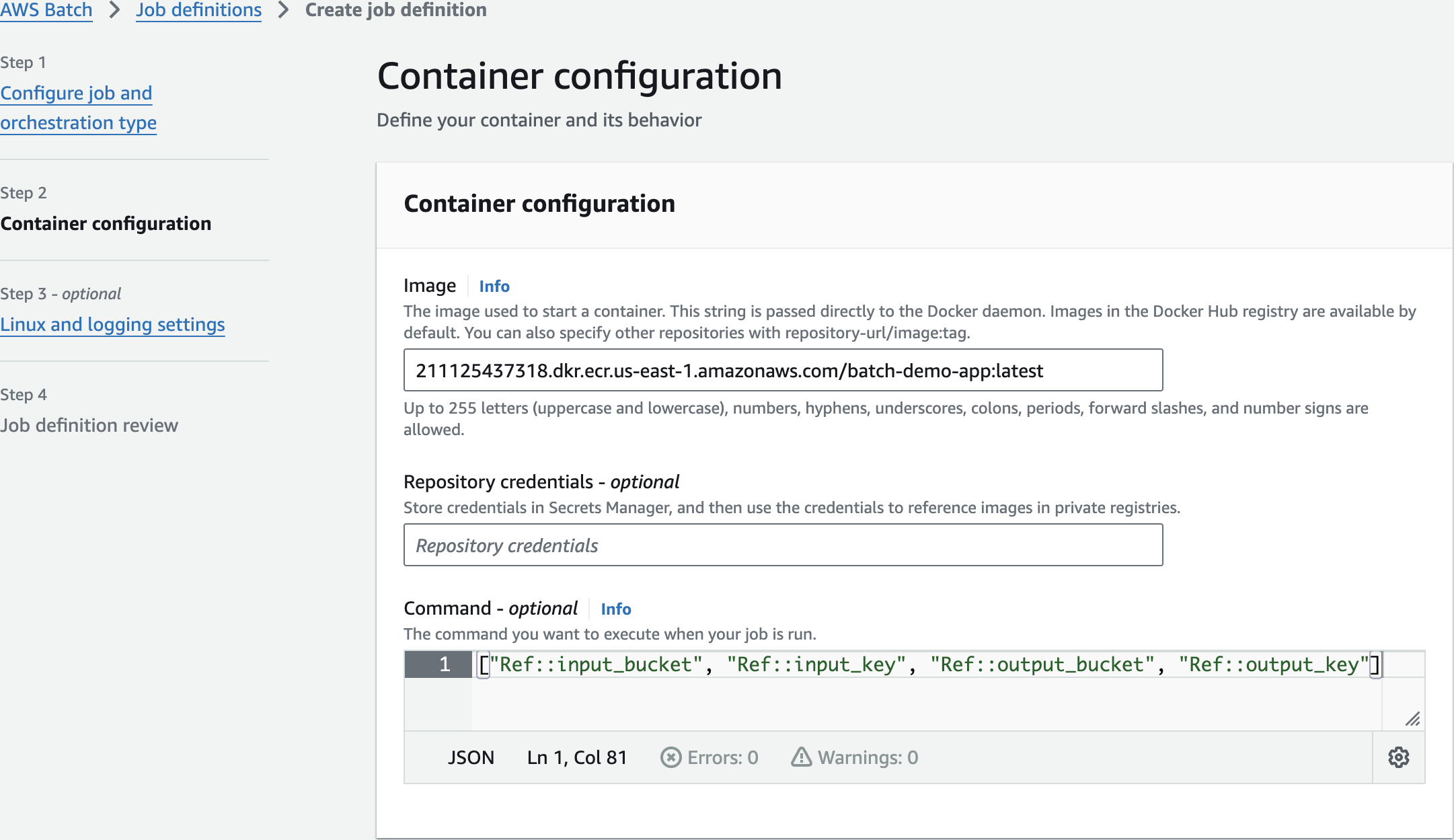
["Ref::input_bucket", "Ref::input_key", "Ref::output_bucket", "Ref::output_key"]

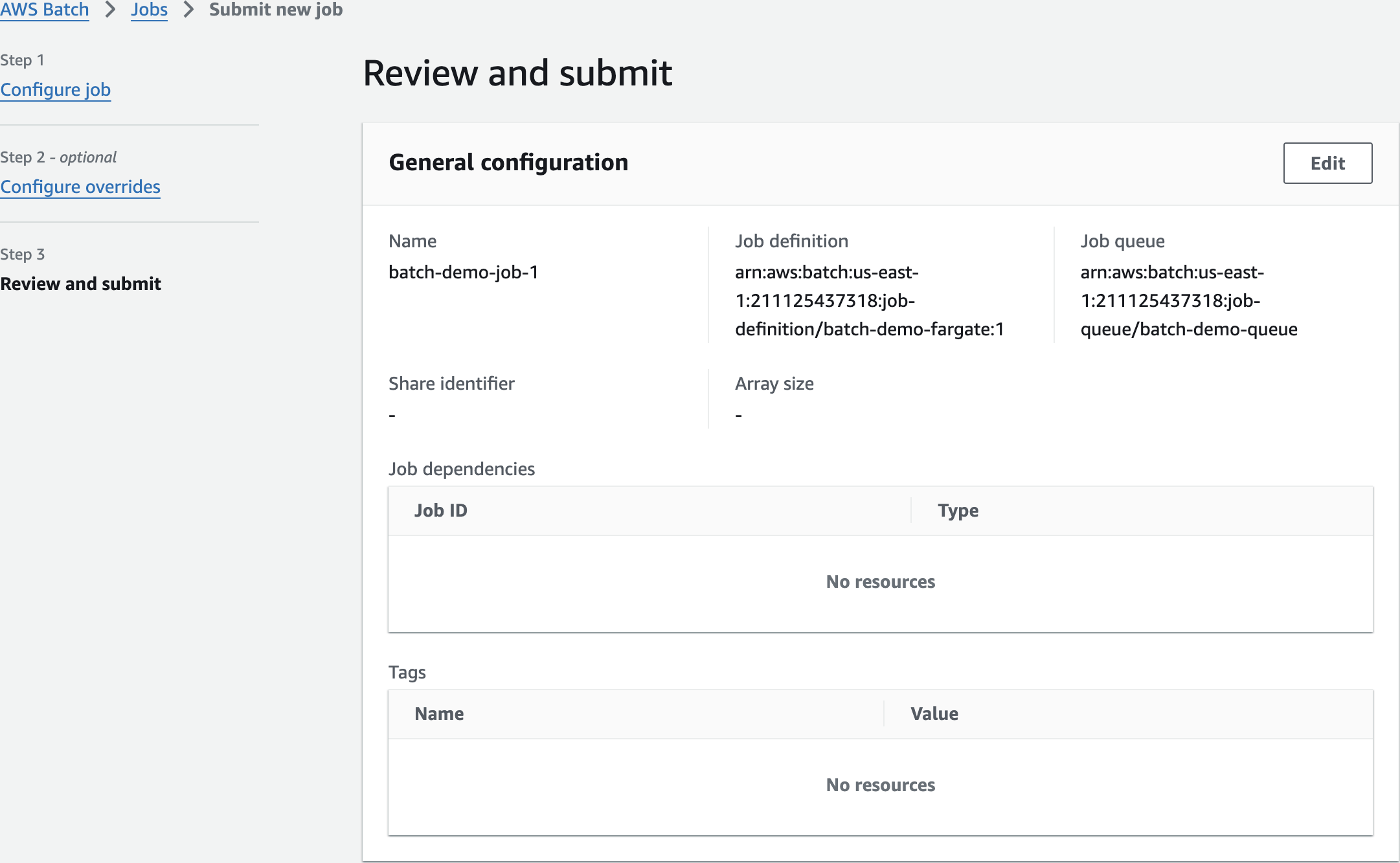
Submit Job
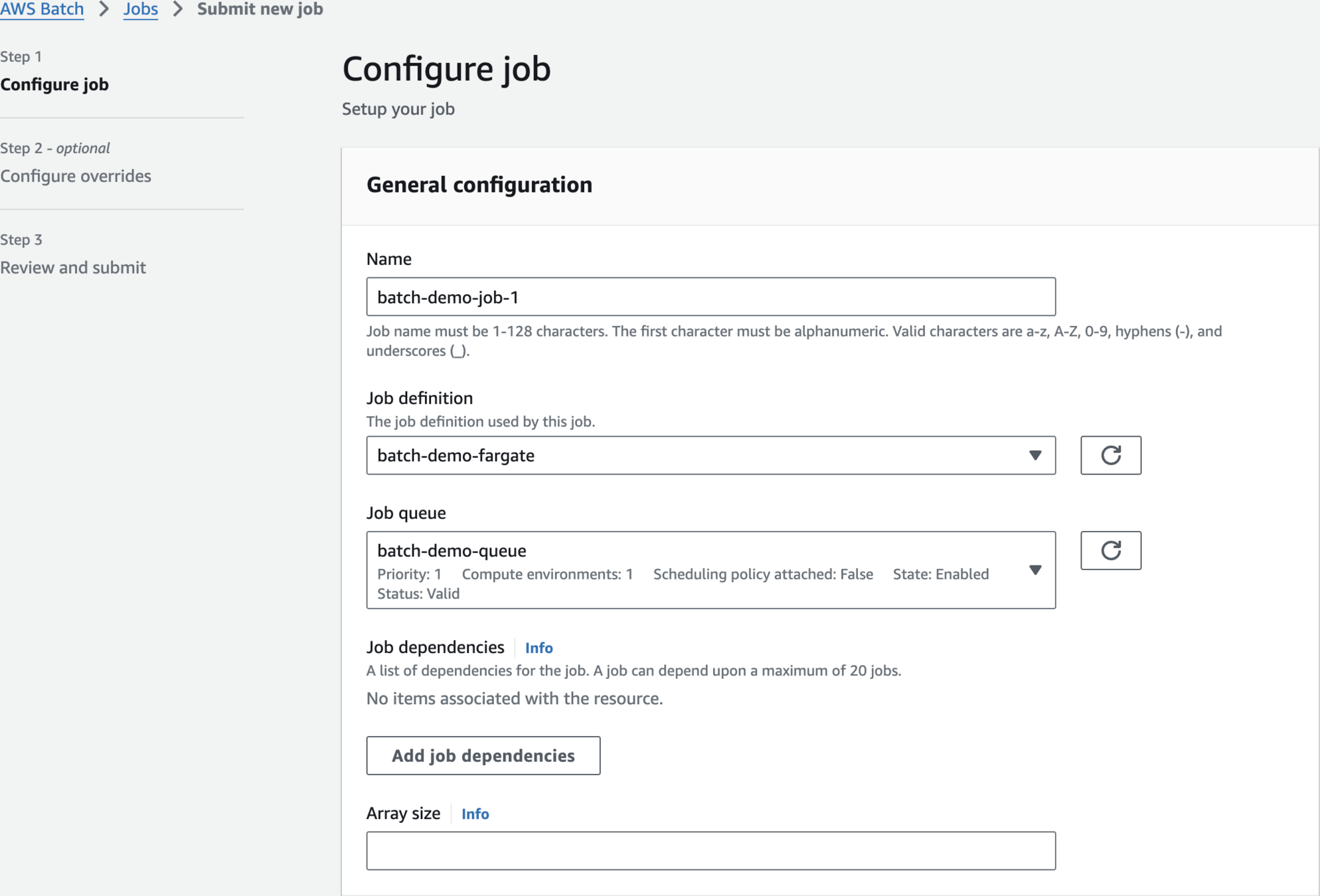
batch-demo-job-1


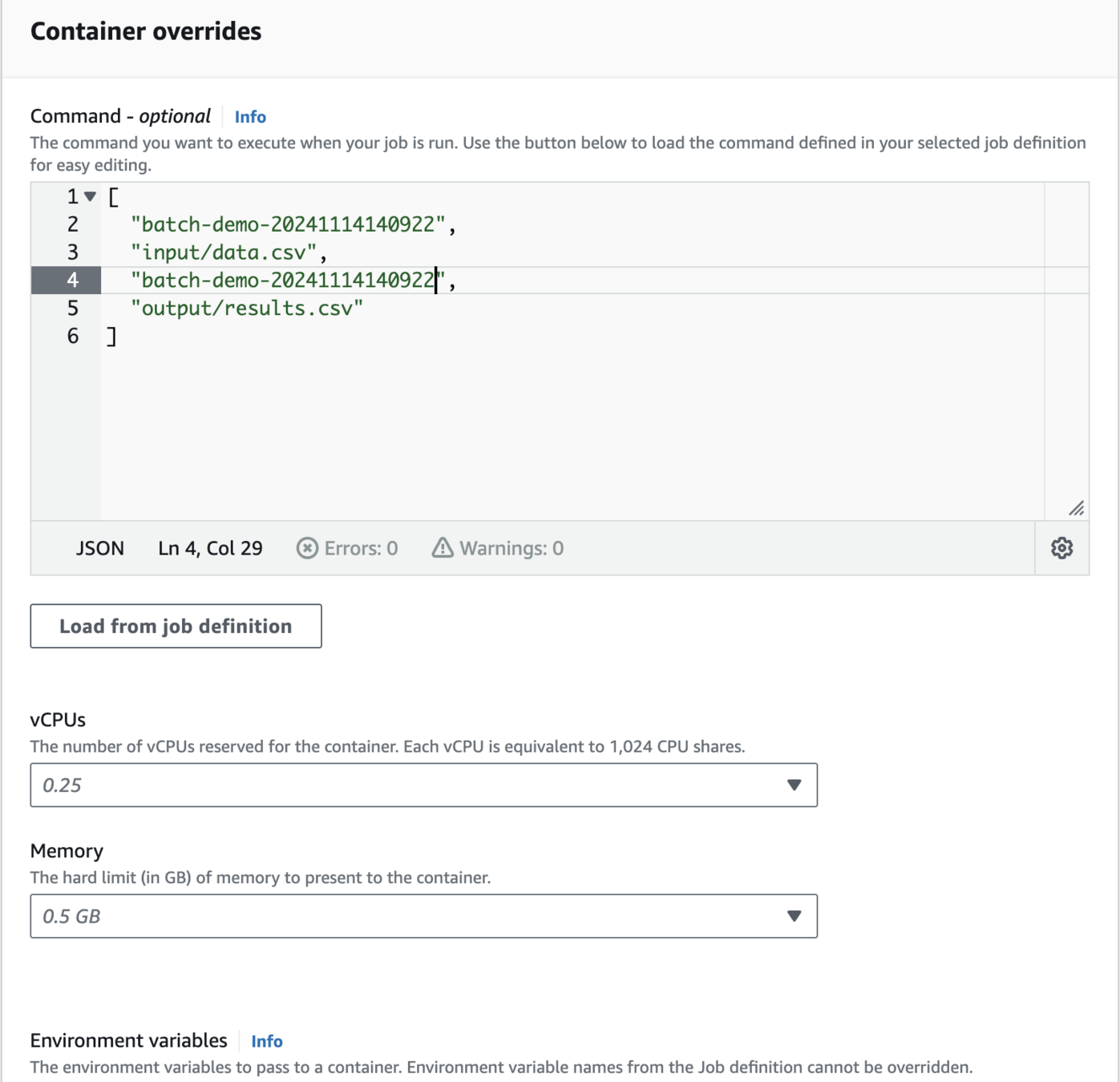
[
"batch-demo-20241114140922",
"input/data.csv"
"batch-demo-20241114140922",
"output/results.csv"
]
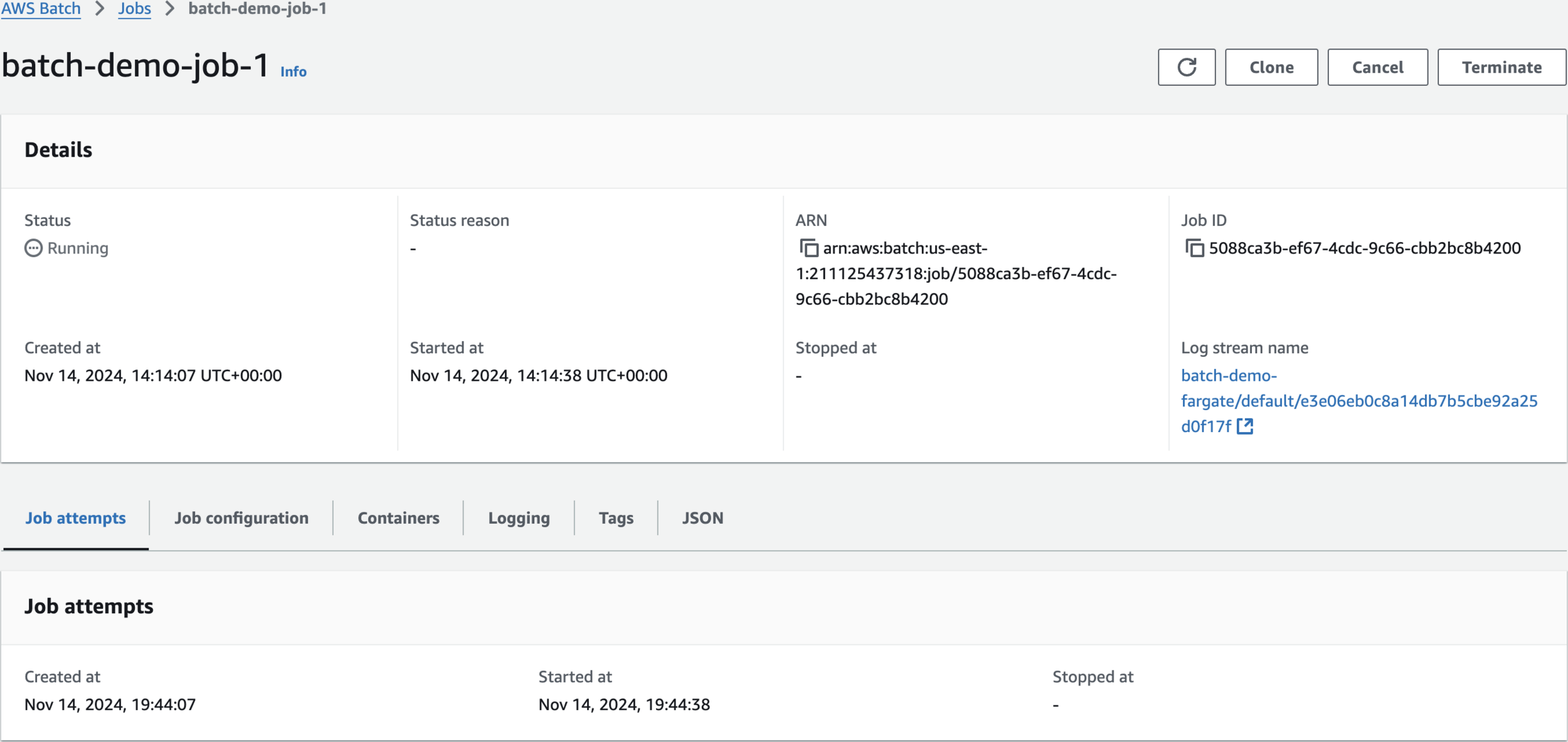
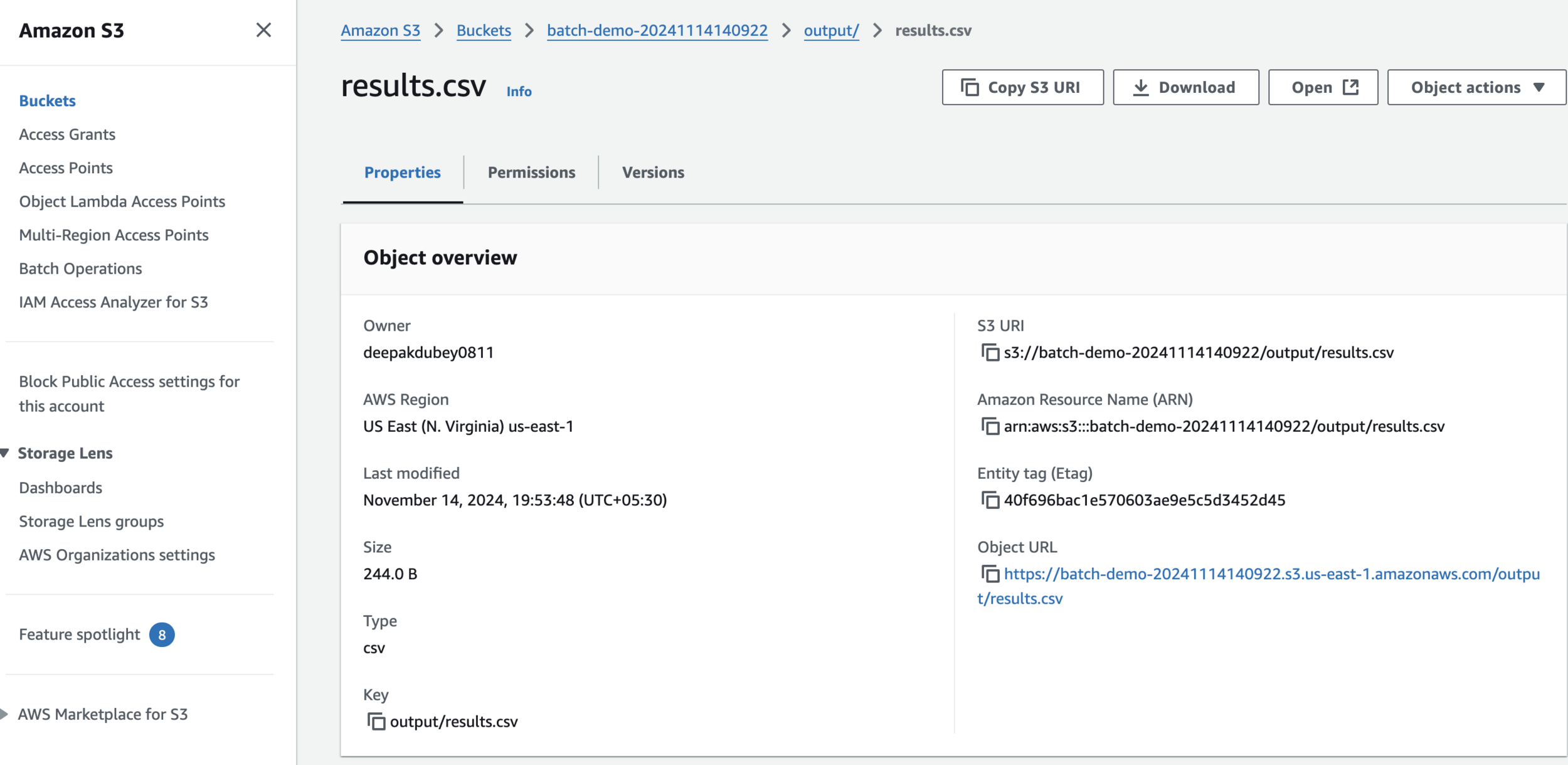
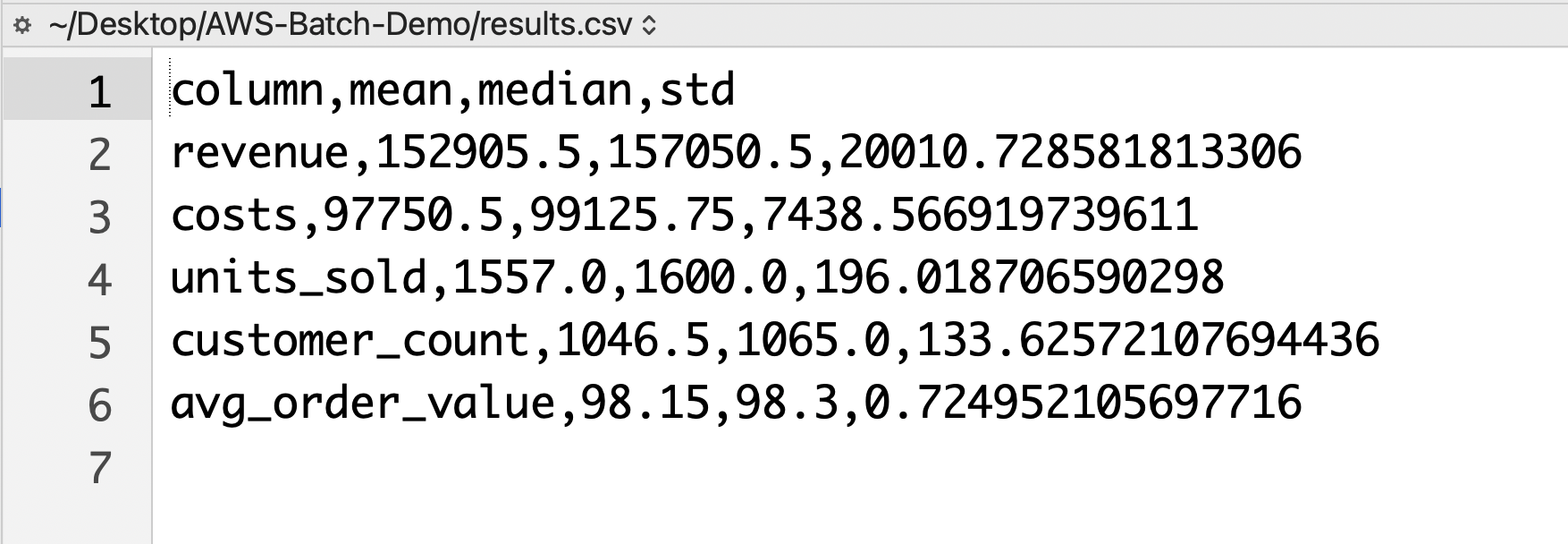
Clean Up
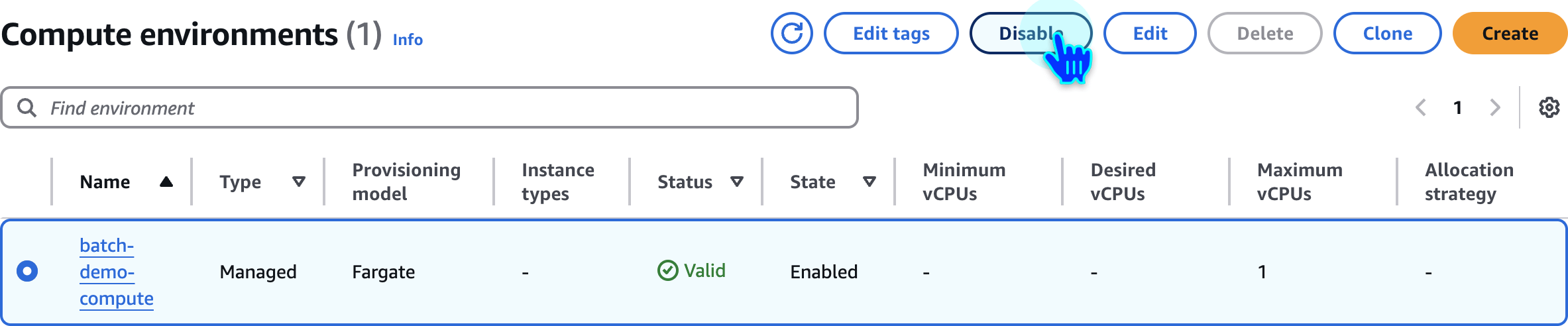
Disable Compute Environment
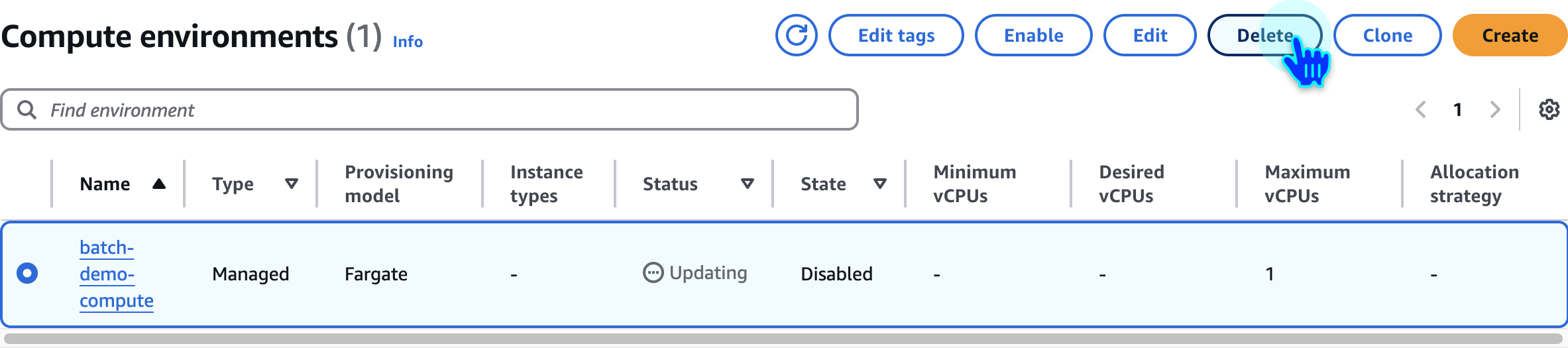
Delete Compute Environment

Disable Job Queue

Delete Job Queue
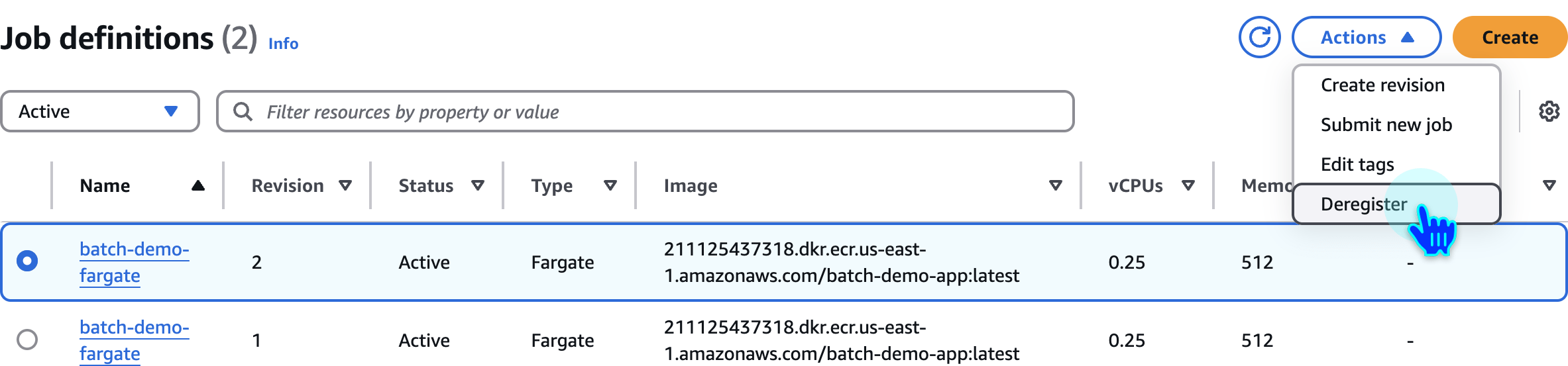
Deregister Job Definition
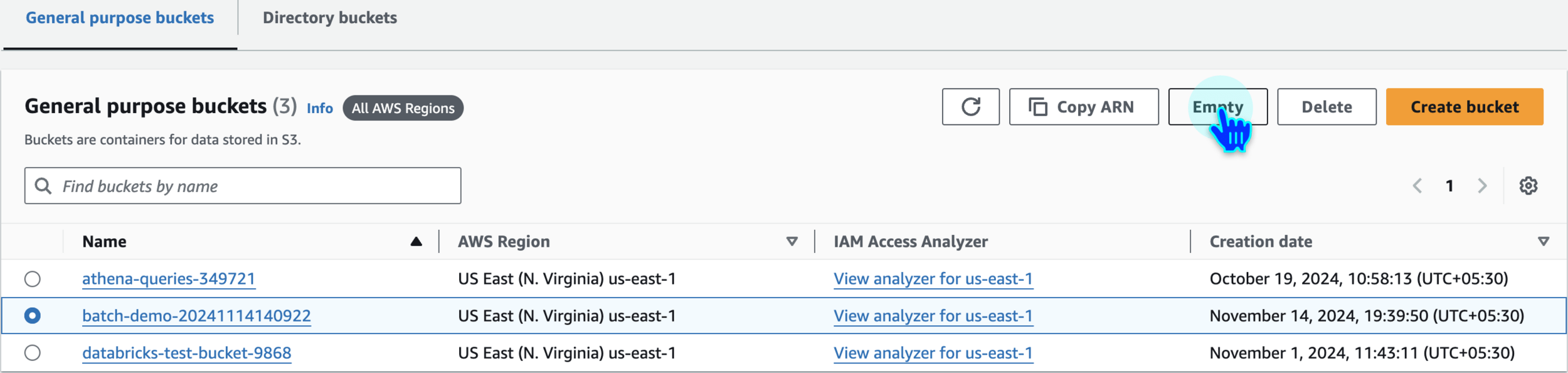
Empty S3 Bucket
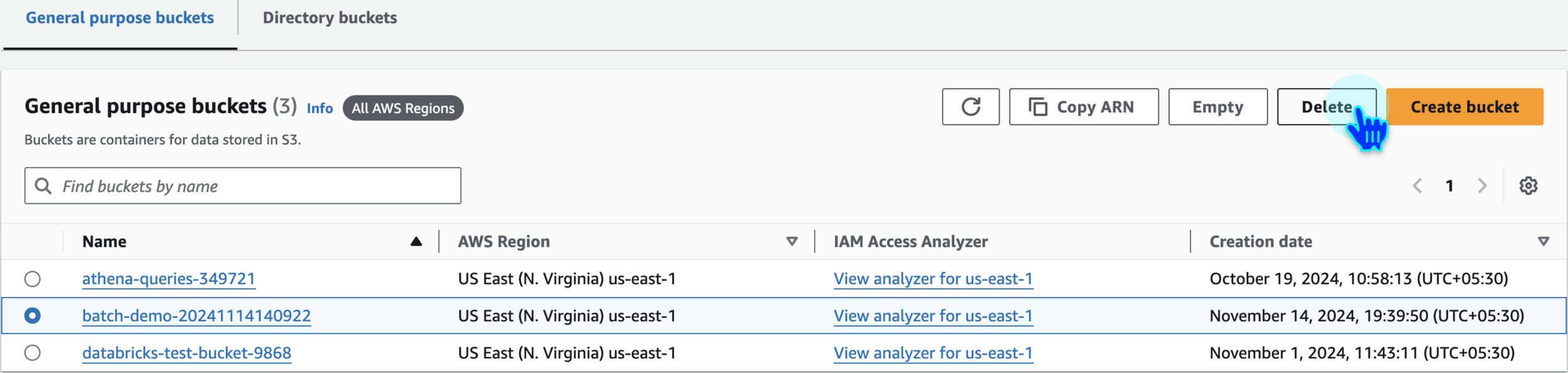
Delete S3 Bucket
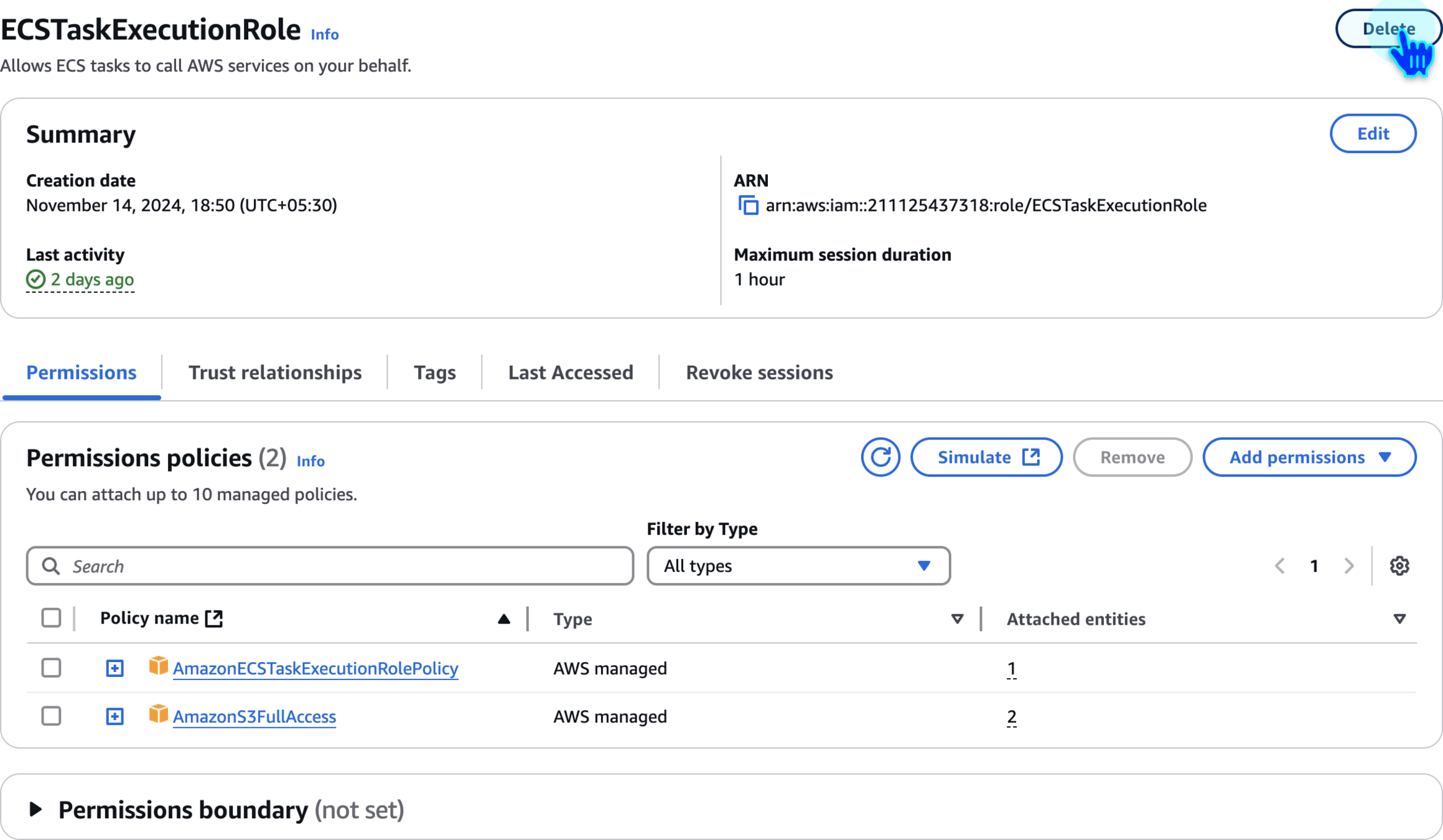
Delete IAM Role
Delete Repository Images