Visualization of terabyte-sized volumetric data
An example from the
Human Organ Atlas dataset
Complete scan at 19.57 um of the brain of the body donor S-20-29
Original data: JP2 stack 133 GB
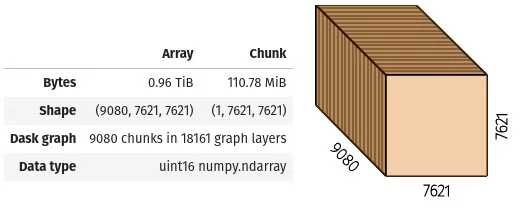
Uncompressed data: 960 GB
The OME-Zarr implementation in qim3d is needed because the official ome-zarr library does not work in 3D.
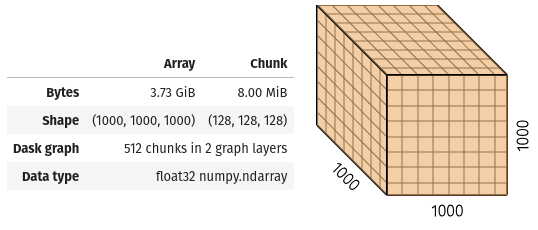

For example, with the official library, this array:
Becomes this one:
It results in a chunk with the Z dimension in the same size of the original data
Two methods are now implemented in qim3dhttps://platform.qim.dk/qim3d/io/#qim3d.io.export_ome_zarr
-
scaleZYXfor when the whole data fits in memory- very fast
- needs lots of memory
-
scaleZYXdaskfor when data does not fit in memory- process data in chunks using dask
-
currently does not work if one of the original chunk dimensions is smaller than the same dimension in the final chunk.
For example: (1,100,100) can't be exported to (10,10,10)- This means that the HOA data needs to be rechunked before being scaled.
Rechunking the brain dataset
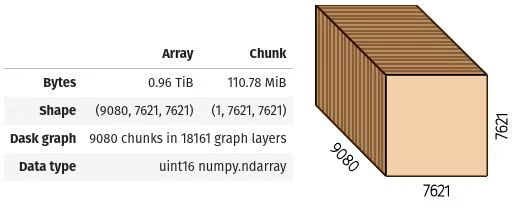

19.57um_S-20-29_brain_complete-organ (virtual stack of jp2 files)
19.57um_S-20-29_brain_complete-organ.zarr
This process took 38 hours to complete
- 20 CPUs
- Peak of 80GB of RAM
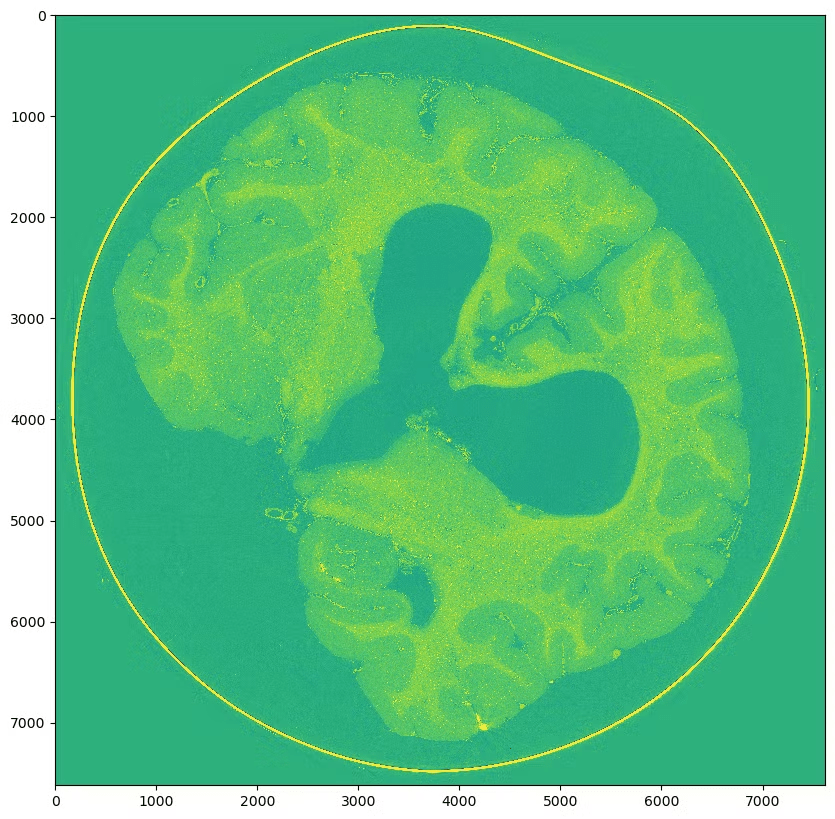
Middle slice from original
Middle slice from Zarr
From Zarr to OME-Zarr
Exporting data to OME-Zarr format at 19.57um_S-20-29_brain_complete-organ_OME.zarr
Number of scales: 8
Creating a multi-scale pyramid
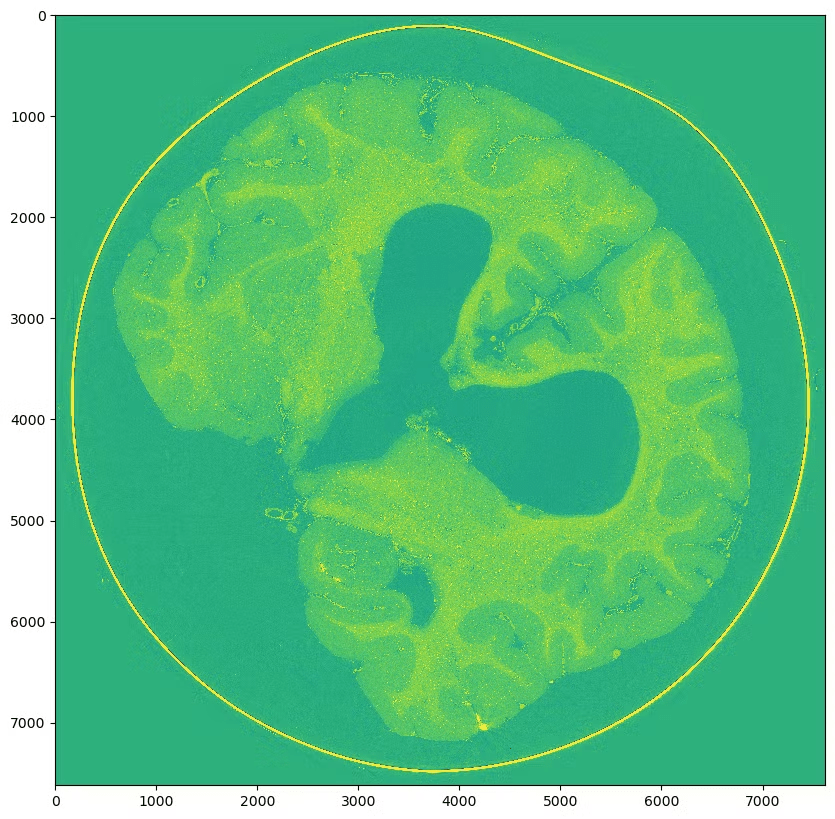
- Scale 0: (9080, 7621, 7621)
- Scale 1: (4540, 3810, 3810)
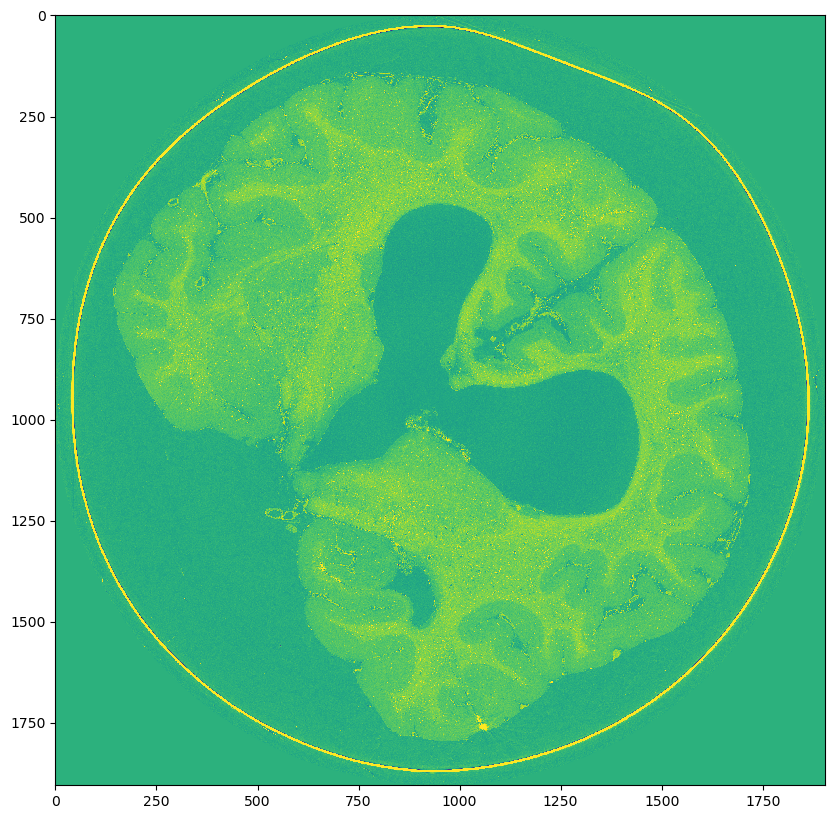
- Scale 2: (2270, 1905, 1905)
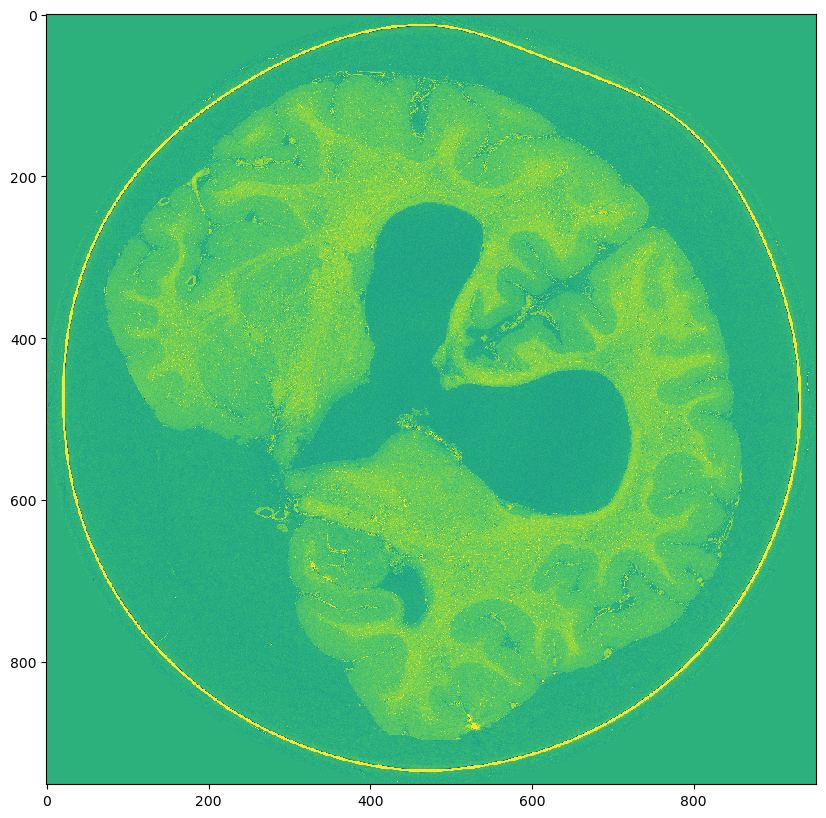
- Scale 3: (1135, 952, 952)
- Scale 4: (567, 476, 476)
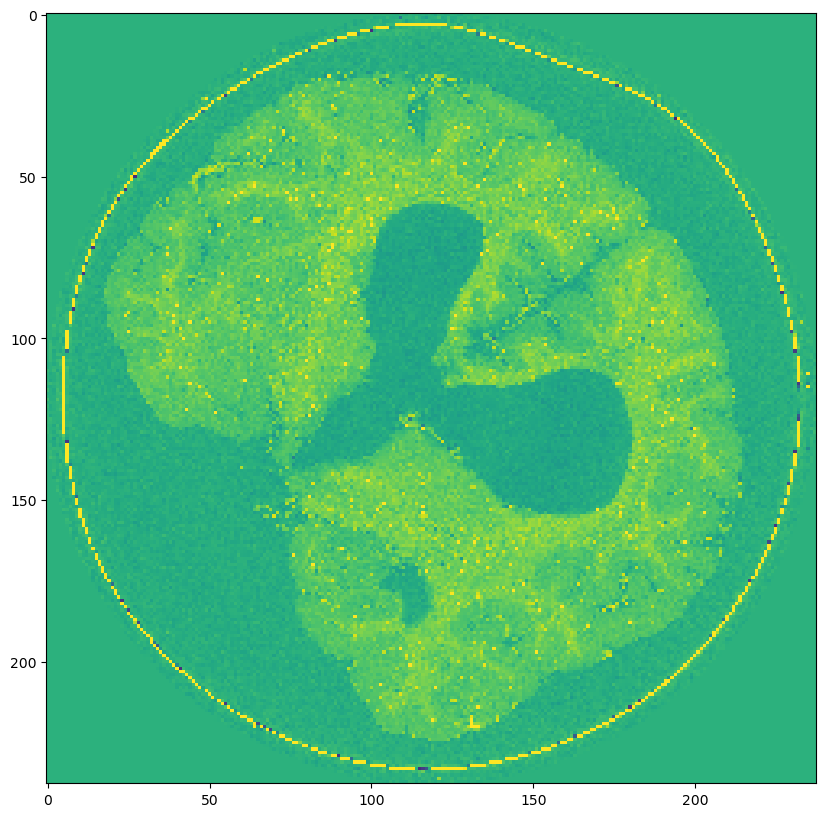
- Scale 5: (283, 238, 238)
- Scale 6: (141, 119, 119)
- Scale 7: (70, 59, 59)
Writing data to diskpath = "19.57um_S-20-29_brain_complete-organ_OME.zarr"
qim3d.io.export_ome_zarr(path, vol, downsample_rate=2, method="scaleZYXdask")Our implementation creates scales until the smallest can fit in a single chunk
The job was killed for reaching the memory limit of 120GB when Scale 6 was being processed.
It ran for 26 hours.
Middle slice from original
Scale 5: (283, 238, 238)
Middle slice from original
Scale 4: (567, 476, 476)

Middle slice from original
Scale 3: (1135, 952, 952)
Middle slice from original
Scale 2: (2270, 1905, 1905)
Middle slice from original
Scale 1: (4540, 3810, 3810)
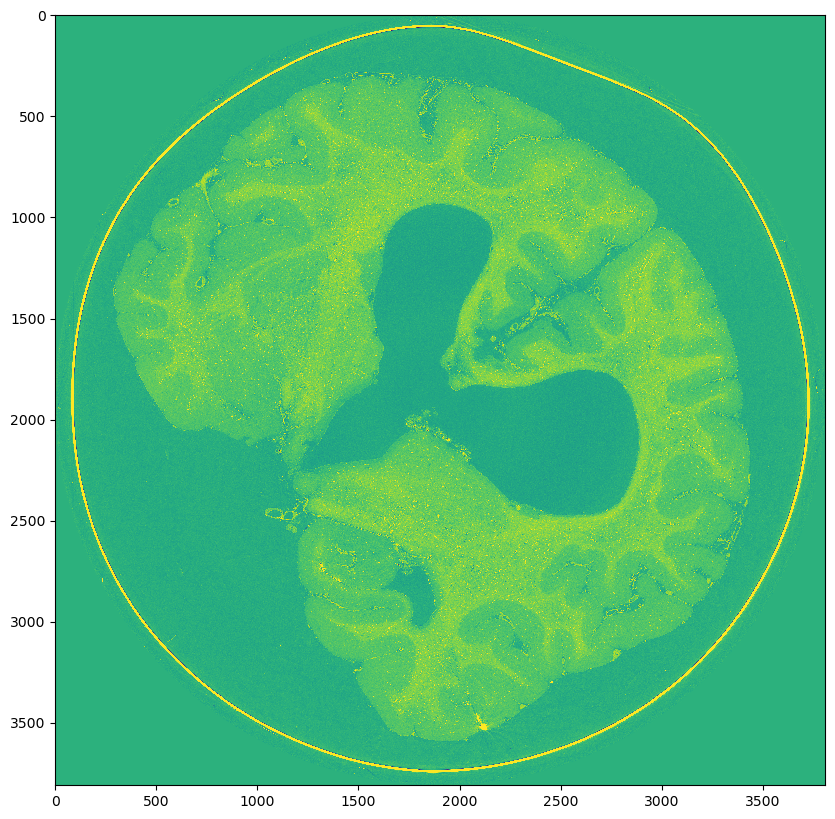
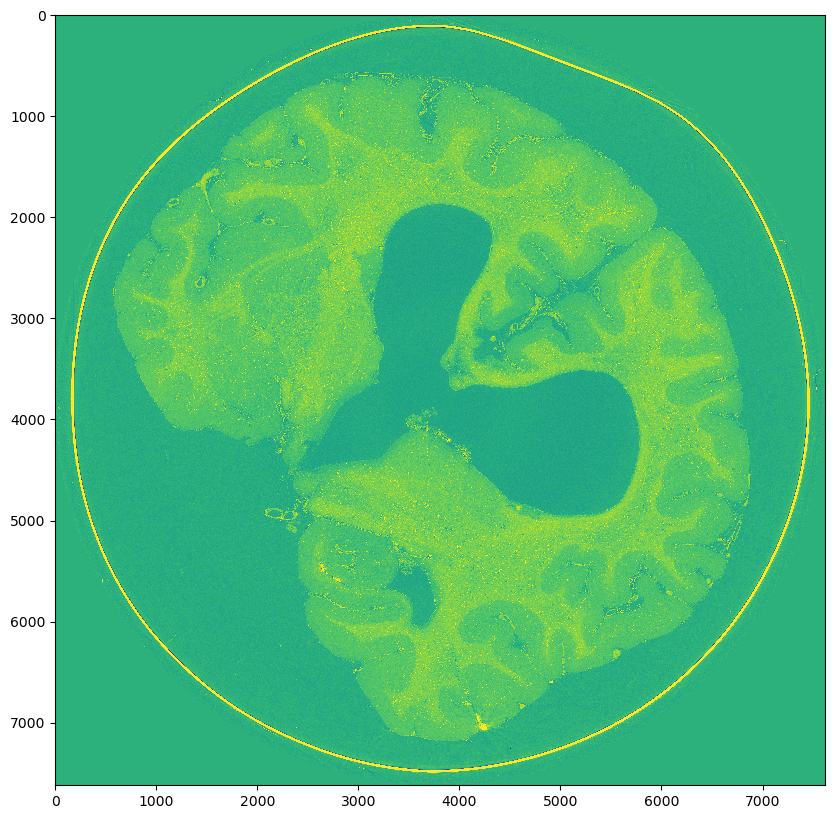
Middle slice from original
Scale 0: (9080, 7621, 7621)
Data usage
Scale 0: 935.00 GB
Scale 1: 125.00 GB
Scale 2: 17.00 GB
Scale 3: 2.10 GB
Scale 4: 0.28 GB
Scale 5: 0.04 GB
141 GB
1076 GB
All scales together are only 15% larger than the original scale
Visualization works fine with the itk-vtk-viewer