Do not try this at home:
How we built a distributed datastore in Elixir
Product, goals, constraints
How we did it
Do this at home
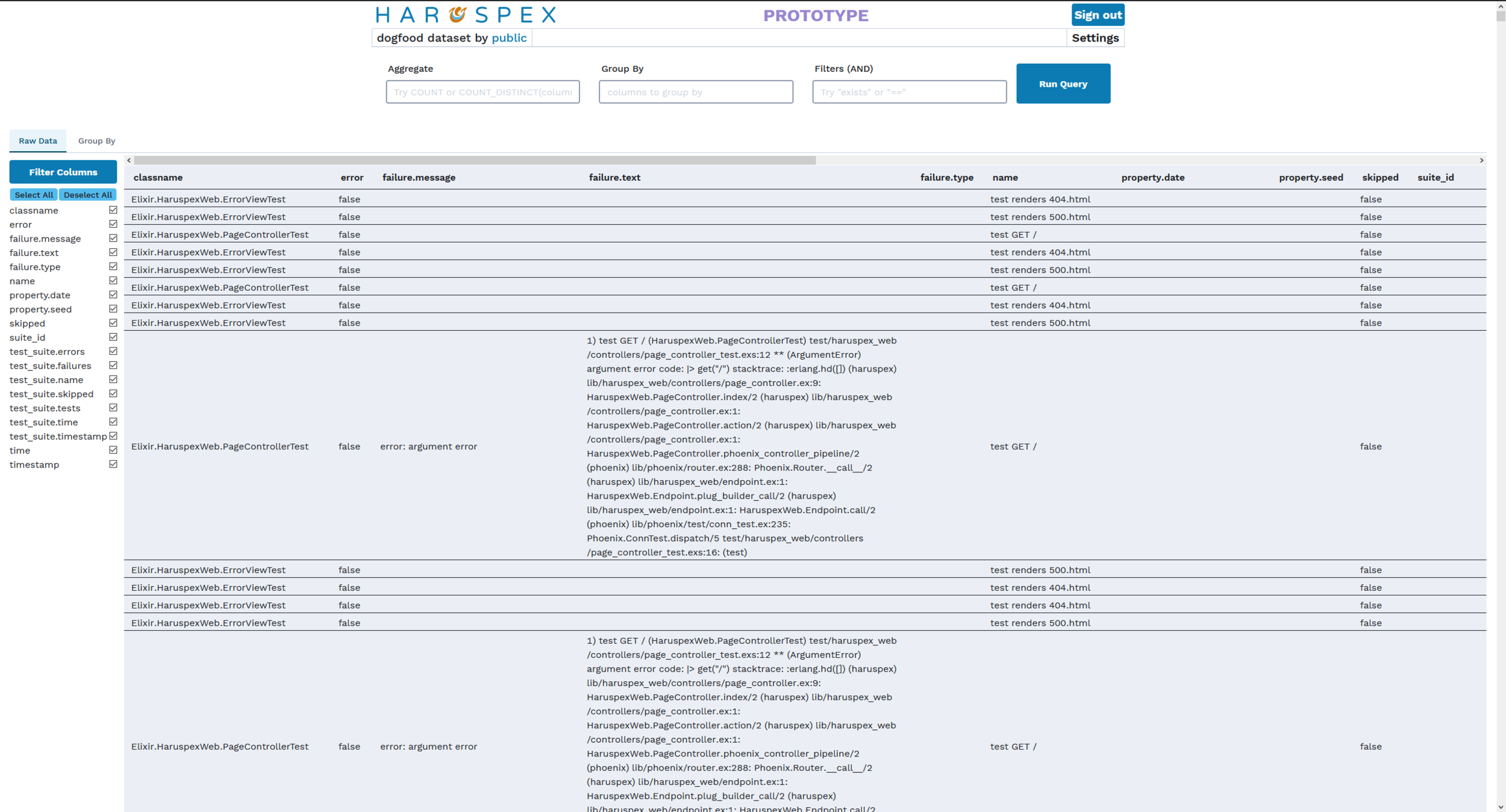
Explore tests Data
Junit files
Query it at will
Product
Goals
Query on the flight
Exploratory querying
Accept any Junit
Handle Quotas
Handle grouping functions: count distinct, percentile, ...
Handle Raw Data
Primary key on timestamp
No update of an event
No need for joins
Constraints
Limited budget
Sparse data
Under 5sec return
AP
Lot of data
Unstable schema
2 devs part time
6 months
Distributed datastore
Columnar store of flat wide KV events
Kafka
Elixir Query Engine
Elixir Quota Enforcer
Liveview query builder
Solutions
Junit to Json
Kafka
Use as a WAL
JSON events go into kafka, one topic per dataset
Storage nodes read at their pace and keep offset saved
In case of crash, we rebuild from Kafka
Use as a distribution mechanism
Kafka consumer groups
Kafka divide topics in partitions, natural distribution unit
Want two replicas per Kafka partition
Use Brod, upstreamed some advanced use
Kafka Consumer Group Protocol
Have two nodes for each partitions
Distribute the partitions over the cluster
Avoid churn
Columnar store
Columnar store
| Index | message |
|---|---|
| 1 | If |
| 2 | You |
| 15 | Look |
| 40 | There |
| .. | |
| 100 | is |
| 250 | no |
| 300 | null |
| ... | ... |
message.string
| Index | message |
|---|---|
| 1 | 124125346864 |
| 2 | 123144576764 |
| 3 | 124353426546 |
| ... | ... |
index.timestamp
Columnar store
Columnar store:
- Null take no space
- Every query goes through primary key, no need for secondary index
- Append only
- No existing format was suitable, add to build our own
- Pretty simple to handle as a file system folder
- Simple to segment by size, for quotas
- Easy support for our queries
- We support string, int, float, boolean
Ask Kafka for nodes holding partitions
Fan out the query through Task.yield_many/2
Timeout = drop the data
Time manipulation is a pain
Versionning your IR is a pain
Distributed Query Engine
Do this at home
Know your constraints

Read the research
