Stochastic Bayesian model reduction for probabilistic machine learning
Dimitrije Marković
TNB meeting 21.03.2023
I
- Bayesian deep learning
- Structured shrinkage priors
- Bayesian model reduction
- Examples
II
- Predictive and sparse coding
- Variational auto-encoders
- BMR for VAEs?
- Active VAEs?
- Bayesian deep learning
- Structured shrinkage priors
- Bayesian model reduction
- Examples
Deep learning
Optimization
Bayesian deep learning
Inference
Advantages
- More robust, accurate and calibrated predictions
- Learning from small datasets
- Continuous learning (inference)
- Distributed or federated learning (inference)
- Marginalization
Disadvantages
Solutions:
- Mean-field approximation
- Laplace approximation
- Structured posterior
Extremely large number of parameters to express the posterior
How about using Bayesian model reduction?
- Bayesian deep learning
- Structured shrinkage priors
- Bayesian model reduction
- Examples
Bayesian deep learning
Inference
Structured shrinkage priors
Nalisnick, Eric, José Miguel Hernández-Lobato, and Padhraic Smyth. "Dropout as a structured shrinkage prior." International Conference on Machine Learning. PMLR, 2019.
Ghosh, Soumya, Jiayu Yao, and Finale Doshi-Velez. "Structured variational learning of Bayesian neural networks with horseshoe priors." International Conference on Machine Learning. PMLR, 2018.
Dropout as a spike-and-slab prior
Better shrinkage priors
Regularized horseshoe prior
Piironen, Juho, and Aki Vehtari. "Sparsity information and regularization in the horseshoe and other shrinkage priors." Electronic Journal of Statistics 11.2 (2017): 5018-5051.
- Bayesian deep learning
- Structured shrinkage priors
- Bayesian model reduction
- Examples
Bayesian model reduction
Two generative processes for the data
full model
reduced model
Karl Friston, Thomas Parr, and Peter Zeidman. "Bayesian model reduction." arXiv preprint arXiv:1805.07092 (2018).
Bayesian model reduction for BDL
Two generative processes for the data
full model
reduced model
Beckers, Jim, et al. "Principled Pruning of Bayesian Neural Networks through Variational Free Energy Minimization." arXiv preprint arXiv:2210.09134 (2022).
BDL with shrinkage priors
Hierarchical model
Factorization
Approximate posterior
Hierarchical model
Non-centered parameterization
Approximate posterior
Hierarchical model
Variational free energy
Stochastic variational inference
Stochastic gradient
Stochastic BMR for BDL
flat model
extended model
BMR algorithm
Step 1
BMR algorithm
Step 2
New epoch
\( p(\pmb{W}) \propto \int d \pmb{\gamma} p_{W|\gamma}q_{\gamma} \)
step 1
\(\vdots\)
step 2
Pruning
- Bayesian deep learning
- Structured shrinkage priors
- Bayesian model reduction
- Examples
Regression
Linear (D=(1,100), N=100)
Logistic (D=(1,100), N=200)
Multinomial (D=(10,10), N=300)
Regression comparison
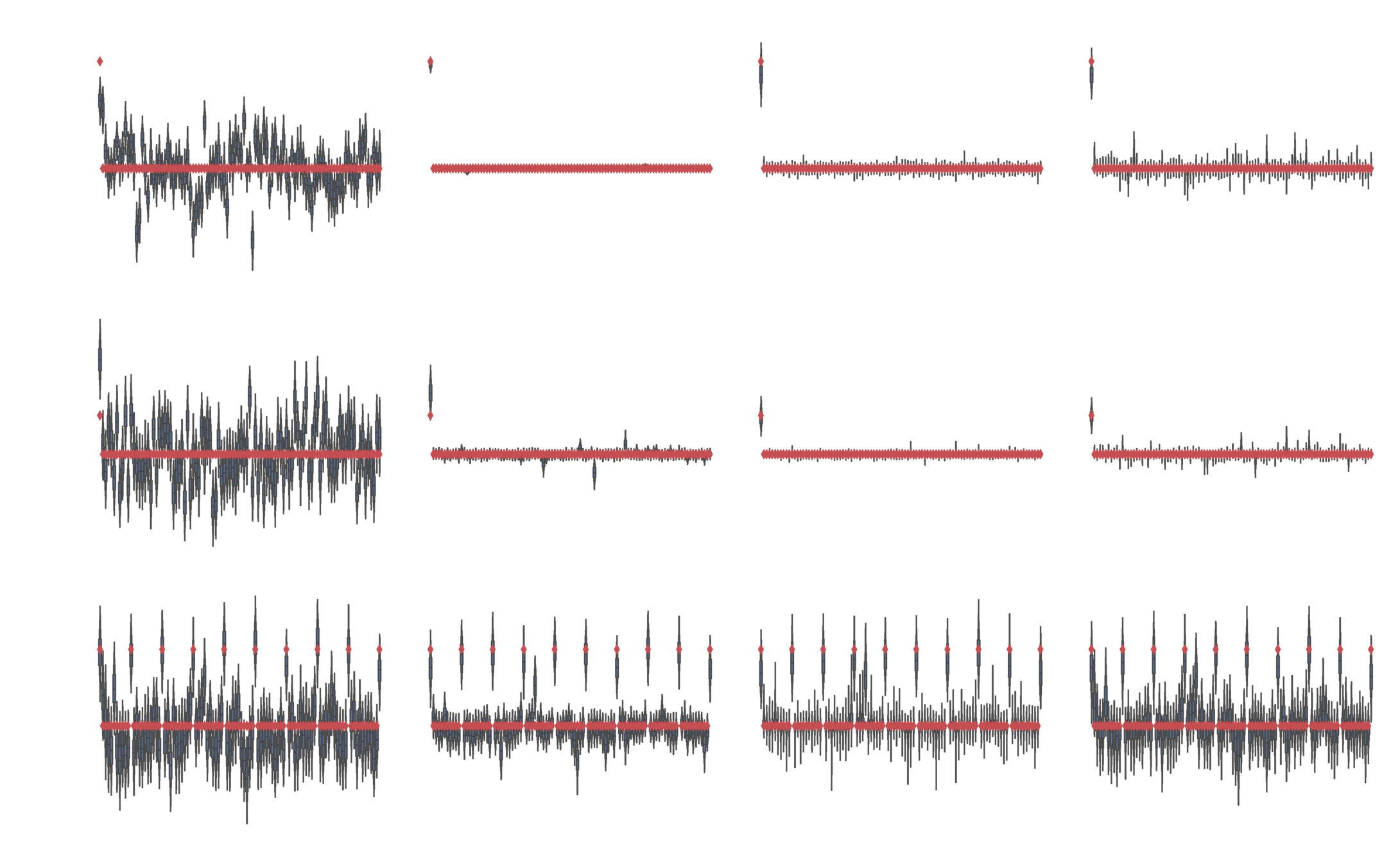
Nonlinear problem
Normal likelihood
Bernoulli likelihood
Categorical likelihood
Neural network model
Normal and Bernoulli likelihoods
Categorical likelihood
Iterative improvements
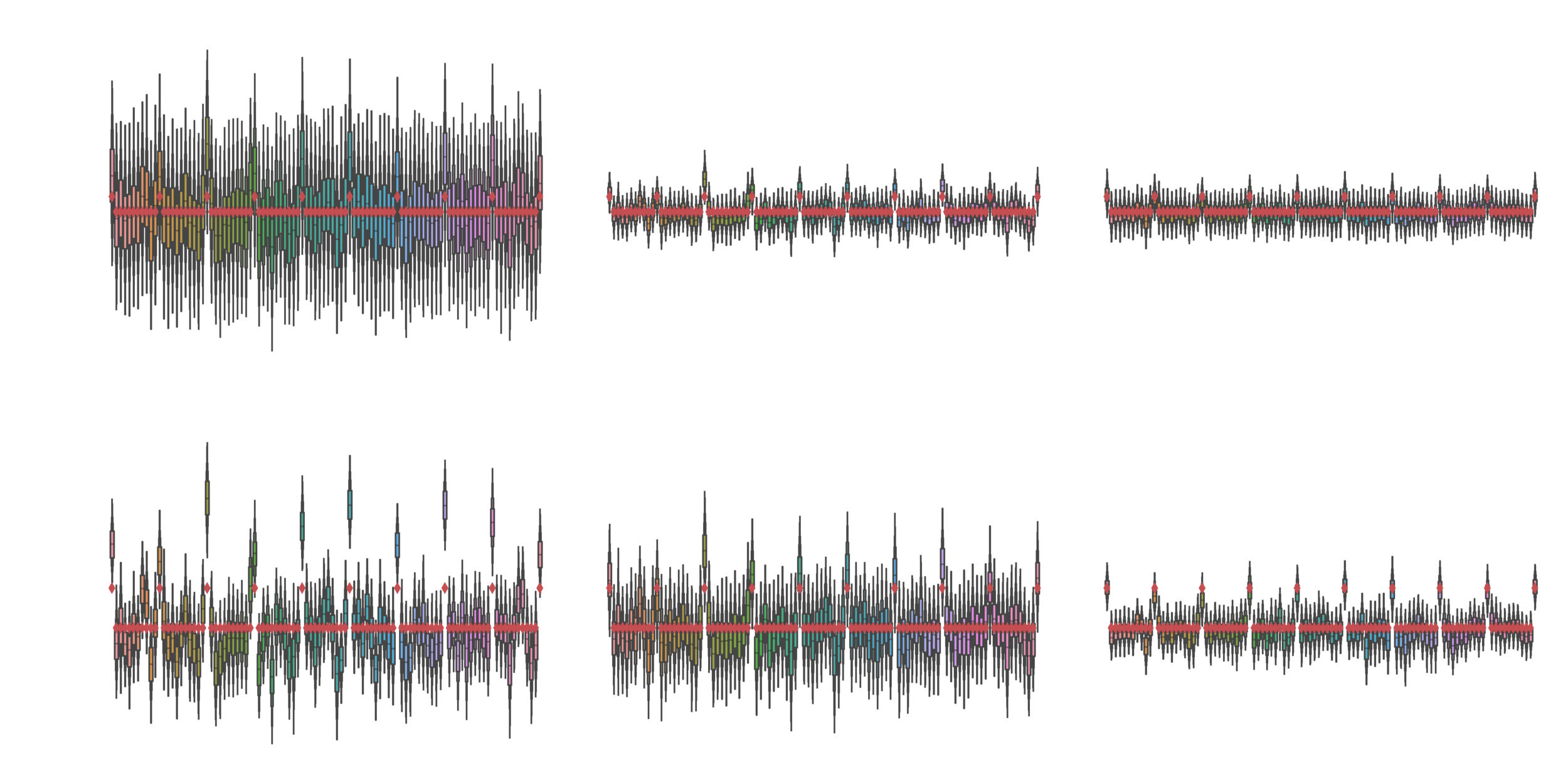
Comparison
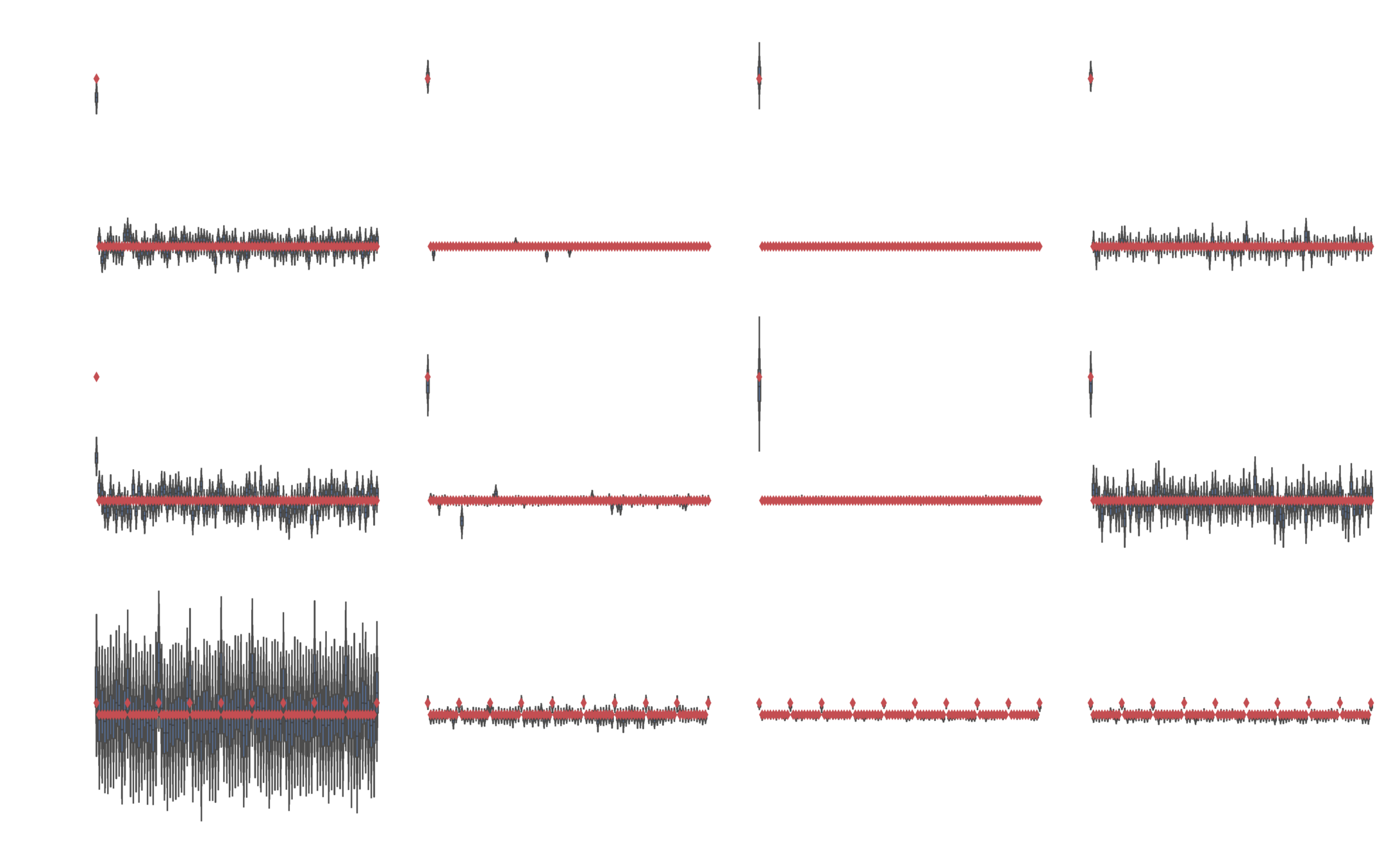
Leave one out cross validation
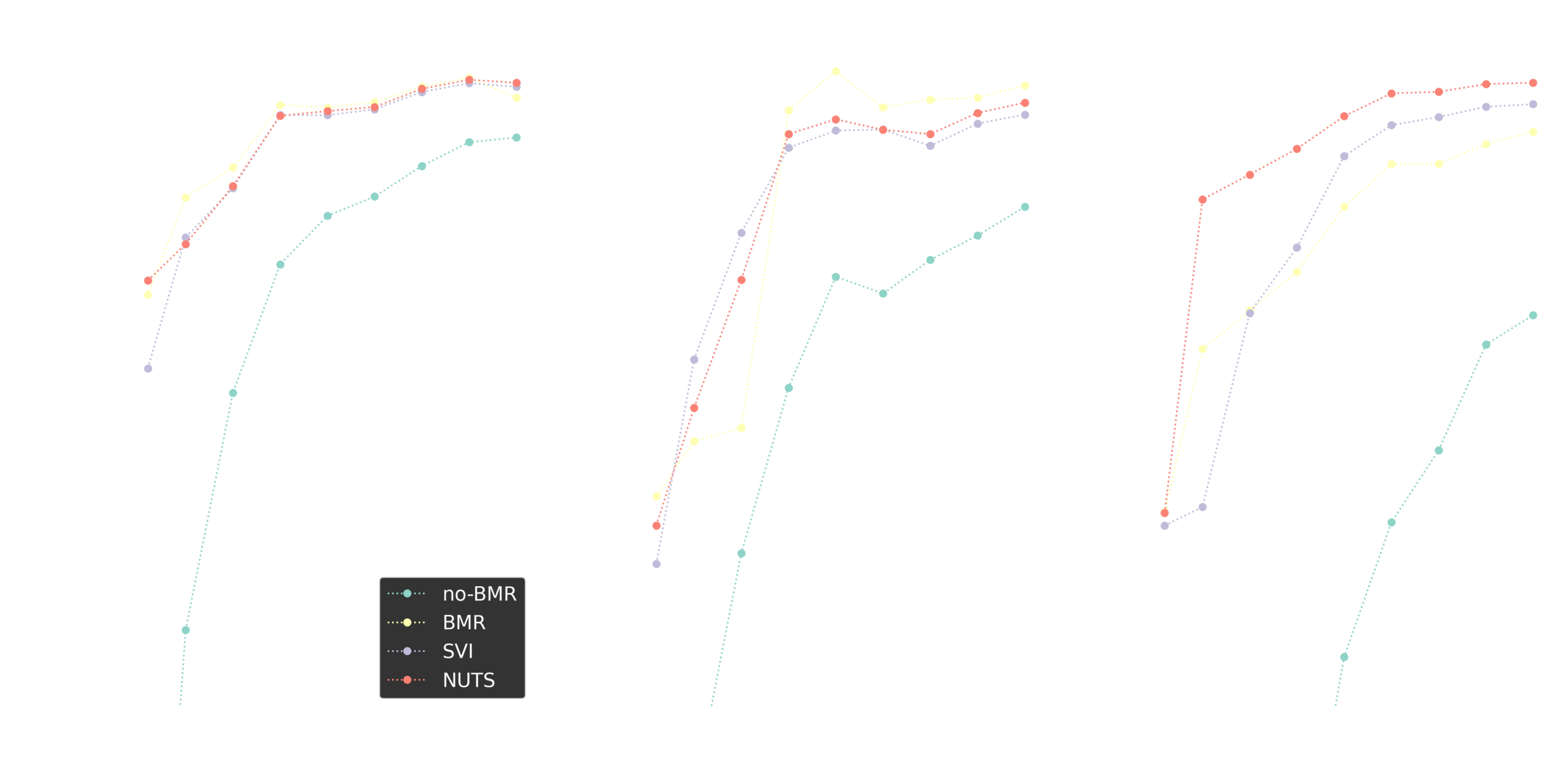
Image classification
Fashion MNIST

Image classification
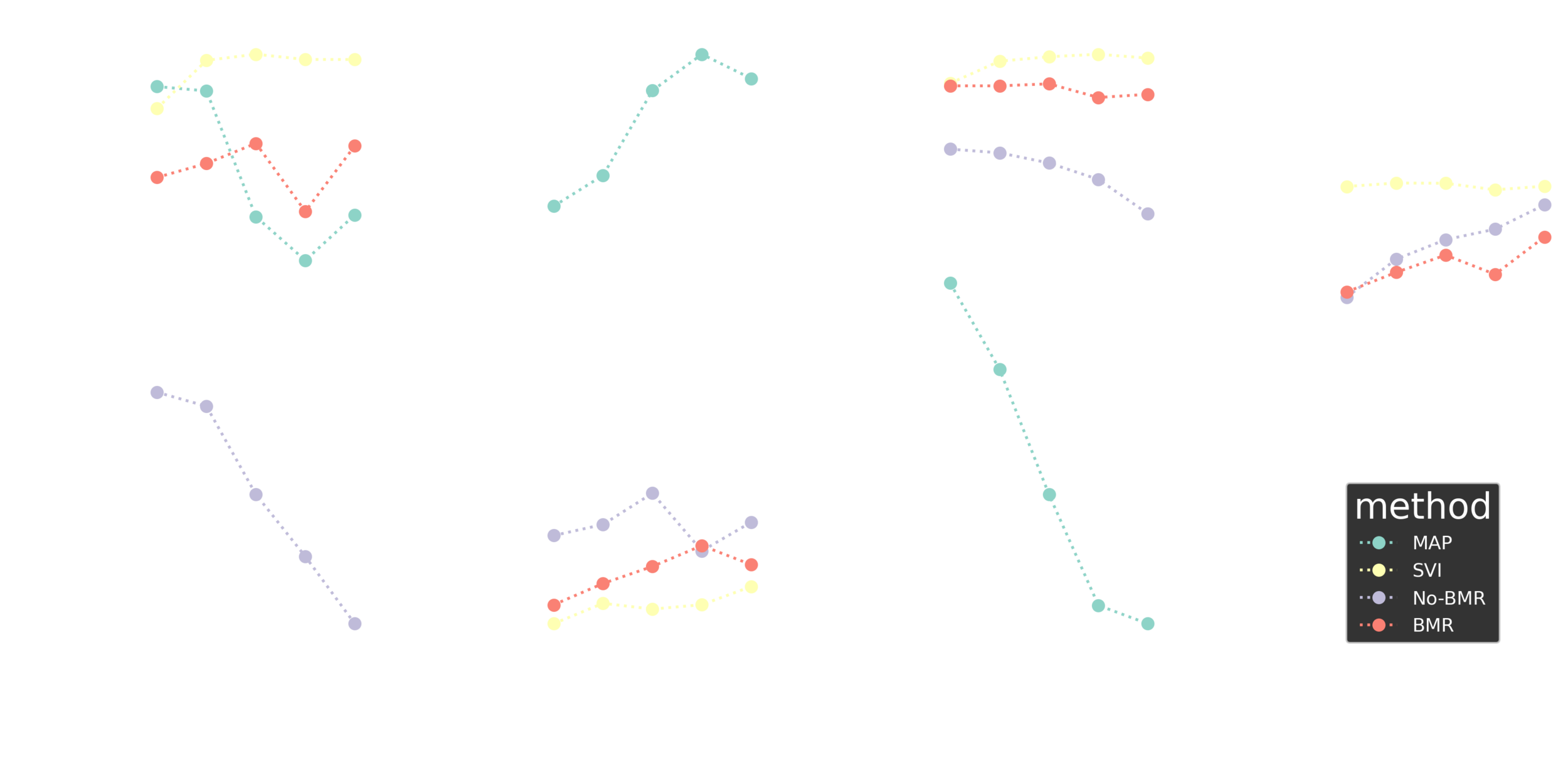
Summary I
Stochastic BMR seems to work great and shows a potential for a range of deep learning applications.
https://github.com/dimarkov/numpc
Idea: might be possible to prune large pre-trained models using Laplace approximation.
We could probably use SBMR in generative models such as Variatonal autoencoders.
Naturally complements distributed and federated inference problems.
The second part
Beyond BDL
Probabilistic ML for edge devices
Bring ML/AI algorithms to a hardware with a range of compute capabilities.
Privacy preserving distributed computing.
Computationally efficient and biologically inspired learning and inference.
Contemplations on how to combine active inference, predictive coding, sparse coding, variational auto-encoders and bayesian model reduction?
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
Predictive coding
PC postulates that the brain is constantly adapting a generative model of the environment:
- top - down -> predictions of sensory signals
- bottom - up -> prediction errors
Millidge, Beren, Anil Seth, and Christopher L. Buckley. "Predictive coding: a theoretical and experimental review." arXiv preprint arXiv:2107.12979 (2021).
Paradigms:
- Unsupervised predictive coding
- Supervised predictive coding:
- Generative or discriminative
Supervised PC
Song, Yuhang, et al. "Can the brain do backpropagation?---exact implementation of backpropagation in predictive coding networks." Advances in neural information processing systems 33 (2020): 22566-22579.
Generative
Discriminative
\(y\)
\(z\)
\(X\)
\(X\)
\(z\)
\(y\)
Supervised PC
Song, Yuhang, et al. "Can the brain do backpropagation?---exact implementation of backpropagation in predictive coding networks." Advances in neural information processing systems 33 (2020): 22566-22579.
Equivalence between backpropagation based training of ANNs and inference and learning based training of SPCNs
Distributed inference, and layer specific Hebbian like learning of weights.
MAP estimates of latent states, and MLE estimate of weights.
Unsupervised PC
\(y\)
\(z\)
\(X\)
A proper generative model of various sensory modalities.
Both generative and discriminative.
Link to variational auto-encoders.
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
Variational auto-encoders
\(z\)
\( \pmb{\mathcal{D}} \)
\( \pmb{\mathcal{D}} \)
Encoder
Decoder
\( p(\pmb{\mathcal{D}}| \pmb{z}) \)
\( q( \pmb{z}|\pmb{\mathcal{D}}) \)
Unlike PC, VAE use amortized variational inference - for its efficiency and scalability
Biological connection
Marino, Joseph. "Predictive coding, variational autoencoders, and biological connections." Neural Computation 34.1 (2022): 1-44.
Bayesian inference and learning for PCNs
Biological connection
Marino, Joseph. "Predictive coding, variational autoencoders, and biological connections." Neural Computation 34.1 (2022): 1-44.
Bayesian inference and learning for VAEs
Amortized inference
Iterative amortized inference
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
Sparse coding
SC postulates that sensory stimuli is encoded by the strong activation of a relatively small set of neurons.
Efficient representation: e.g. sparse coding of natural images leads to wavelet-like (gabor) filters filters that resemble the receptive fields of simple cells in the visual cortex
SC postulates that sensory stimuli is encoded by the strong activation of a relatively small set of neurons.
Principle assumption in spiking neuronal networks.
Numerous applications in ML and an inspiration for sparse variational autoencoders.
Illing, Bernd, Wulfram Gerstner, and Johanni Brea. "Biologically plausible deep learning—but how far can we go with shallow networks?." Neural Networks 118 (2019): 90-101.
Sparse coding math
Boutin, Victor, et al. "Sparse deep predictive coding captures contour integration capabilities of the early visual system." PLoS computational biology 17.1 (2021): e1008629.
Sparse coding math
Boutin, Victor, et al. "Sparse deep predictive coding captures contour integration capabilities of the early visual system." PLoS computational biology 17.1 (2021): e1008629.
Sparse variational autoencoders
Asperti, Andrea. "Sparsity in variational autoencoders." arXiv preprint arXiv:1812.07238 (2018).
Barello, Gabriel, Adam S. Charles, and Jonathan W. Pillow. "Sparse-coding variational auto-encoders." BioRxiv (2018): 399246.
Kandemir, Melih. "Variational closed-form deep neural net inference." Pattern Recognition Letters 112 (2018): 145-151.
Incorporate sparse coding assumptions into variational auto-encoders for a proper probabilistic treatment.
Does structural sparsity result in activation sparsity?
Dynamical sparse coding
Generalised coordinates?
Dynamical sparsity?
Contextual dynamics
\(y_{t-1}\)
\(z\)
\(z_t\)
\(z\)
\(z_{t-1}\)
\(z\)
\(s_{t-1}\)
\(y_t\)
\(z\)
\(z_t\)
\(z\)
\(z_t\)
\(z\)
\(s_t\)
\(y_{t+1}\)
\(z\)
\(z_t\)
\(z\)
\(z_{t+1}\)
\(z\)
\(s_{t+1}\)
Switching linear dynamics?
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
BMR
Sparsification of variational auto-encoders
Structure learning (e.g. latent state graph topology)
II
- Predictive coding
- Variational auto-encoders
- Sparse coding
- BMR for VAEs?
- Active VAEs?
Active inference
Active variational auto-encoders:
- actively selecting salient parts of stimuli (data)
- selecting most informative subset for training
Parr, Thomas, and Karl J. Friston. "Active inference and the anatomy of oculomotion." Neuropsychologia 111 (2018): 334-343.
Parr, Thomas, and Karl J. Friston. "The active construction of the visual world." Neuropsychologia 104 (2017): 92-101.
Parr, Thomas, and Karl J. Friston. "Working memory, attention, and salience in active inference." Scientific reports 7.1 (2017): 14678.
Active inference
- Multi-agent systems:
- emergent global generative models from interaction of simple agents implementing sparse active variational autoencoders.
- Active federated (distributed) inference and learning
Heins, Conor, et al. "Spin glass systems as collective active inference." arXiv preprint arXiv:2207.06970 (2022).
Friston, Karl J., et al. "Designing Ecosystems of Intelligence from First Principles." arXiv preprint arXiv:2212.01354 (2022).
Ahmed, Lulwa, et al. "Active learning based federated learning for waste and natural disaster image classification." IEEE Access 8 (2020): 208518-208531.
Summary II
Predictive and sparse coding <=> Variational auto-encoders
Challenges:
- Defining Bayesian sparse predictive coding for time series data.
- Using stochastic BMR for sparse structure learning.
- Incorporating dynamic sparse VAEs into active inference agents.
Few references
Murphy, Kevin P. Probabilistic machine learning: an introduction. MIT press, 2022.
Wilson, Andrew Gordon. "The case for Bayesian deep learning." arXiv preprint arXiv:2001.10995 (2020).
Bui, Thang D., et al. "Partitioned variational inference: A unified framework encompassing federated and continual learning." arXiv preprint arXiv:1811.11206 (2018).
Murphy, Kevin P. Probabilistic machine learning: Advanced Topics. MIT Press 2023