How Machines Learn
Matei Constantinescu
How machines learn, and pass the Marshmallow Test

Eat one marshmallow now - or wait for two later?

Humans can learn to wait for two marshmallows instead of eating one on the spot

Protocol says: EAT IMMEDIATELY...unless...I can learn a better rule?
Code vs Learning: Two ways to control a machine
if marshmallow == seen: eat()

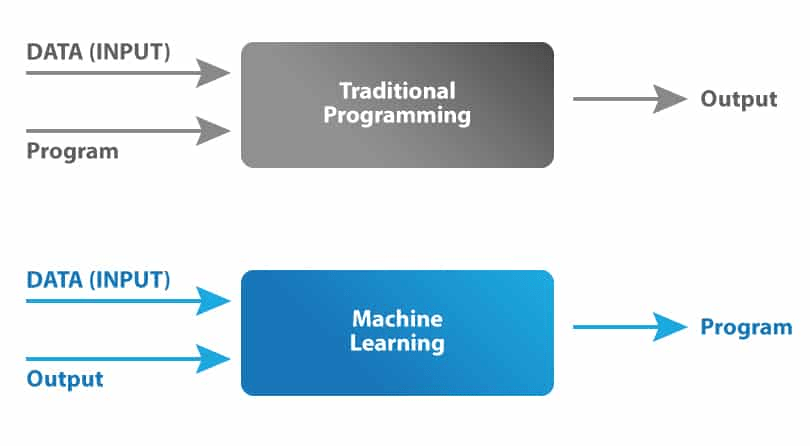
Old way: explicit rules - we hand-write the code
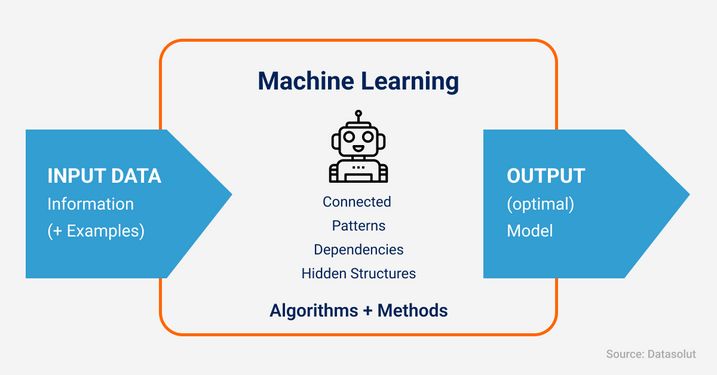
Machine Learning way: give data & let machine find rule
Supervised Learning: Learning from labeled examples
Subtitle



Data
Cat
Marshmallow
Dog
Labels

Loss
Accuracy
Model tries to map labels to data
Neural Networks: Layers of Numbers
Subtitle
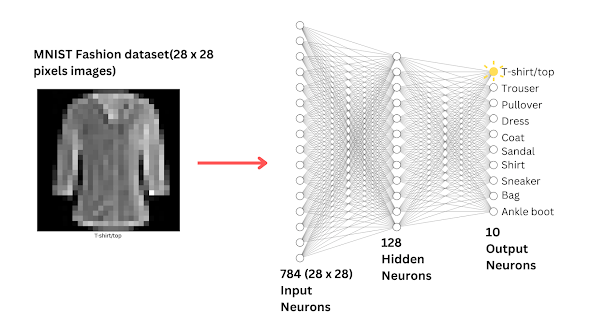
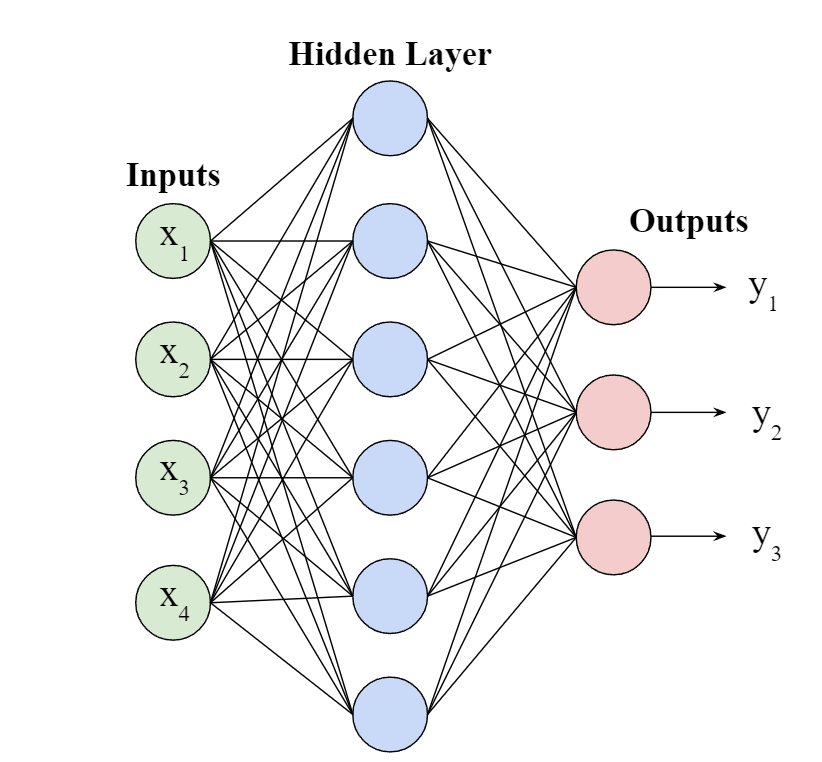
Each connection has a weight. Training is finding good weights.
Example from Fashion-MNIST: 28×28 pixels → Dense(128) → Dense(10)
Gradient Descent - Rolling down the loss mountain
Subtitle

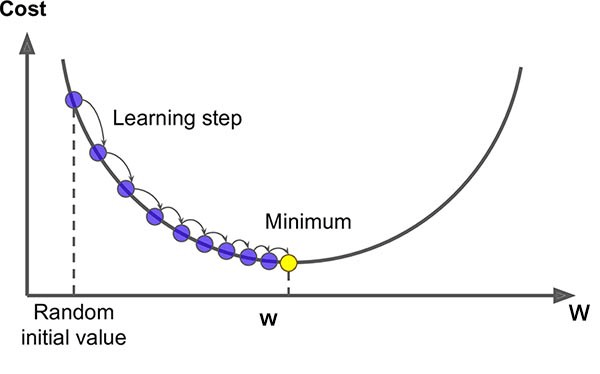
We compute the gradient of the loss and move the weights a tiny step downhill.
Optimizer: e.g., ‘adam’ or SGD. Learning rate controls step size.
Not Just Supervised: Unsupervised & Reinforcement Learning
Subtitle
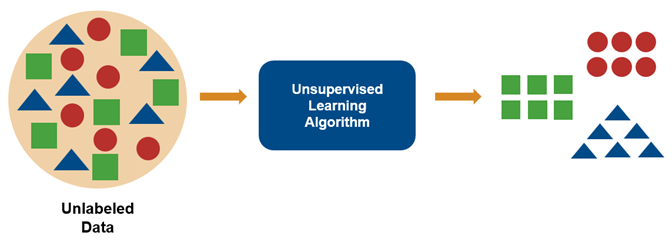
Unsupervised: find patterns in unlabeled data.
Reinforcement: learn by trial and error with rewards.
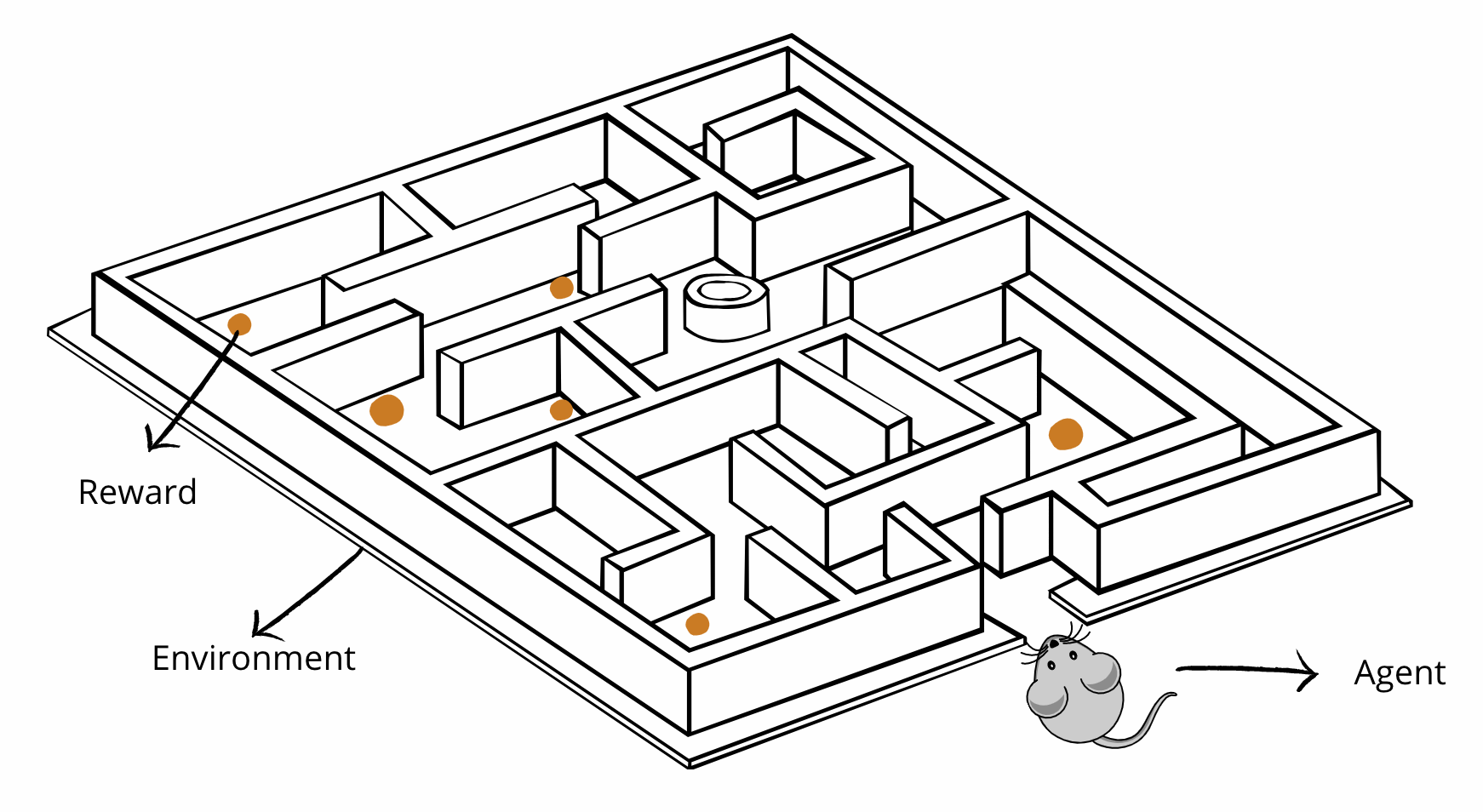
Gridworld: Decisions, Rewards, and Policies
Subtitle
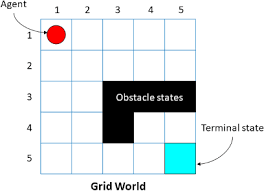
A state = a square. An action moves you to a new state. Each action has a probability.
Policy(s) = probabilities of each action in that state.
Value(s) = expected discounted reward if we start in s and follow the policy
Eat now = small reward now. Wait = bigger reward later
How to Train a Robot (for Real)
Subtitle
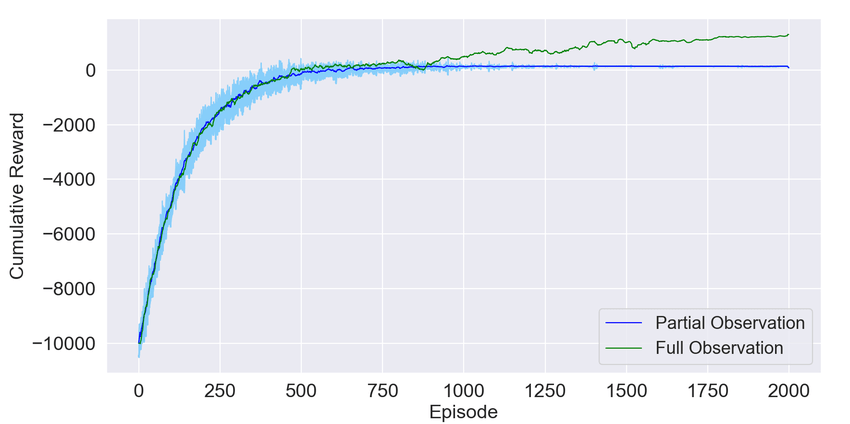
Let the agent explore and collect experience.
Use rewards to update its policy or value function.
Repeat until behavior is (mostly) good enough.
What Machines Don’t Do
Subtitle


?
Machines optimize what we tell them to optimize.
Bad or biased data ⇒ bad or biased behavior
Neural nets can be powerful but also black boxes.
Takeaway
Machines learn by optimizing: adjusting weights to fit data or maximize reward.
What we choose as data, loss, and rewards determines what they become good at.