How We Understand AI Models
Christian Yoon
Vending machines are like machine learning models...
-
Input goes in and output comes out, but inner workings are hidden
-
Models make accurate predictions but we can’t see the steps in between
-
This makes them hard to trust and debug

-
SAEs act like opening the vending machine panel to see how it works
-
They break model activations into interpretable components
-
Each “part” (or feature) activates for a specific concept, letting us see what the model notices
-
SAEs help turn the black box into something we can inspect, label, and understand
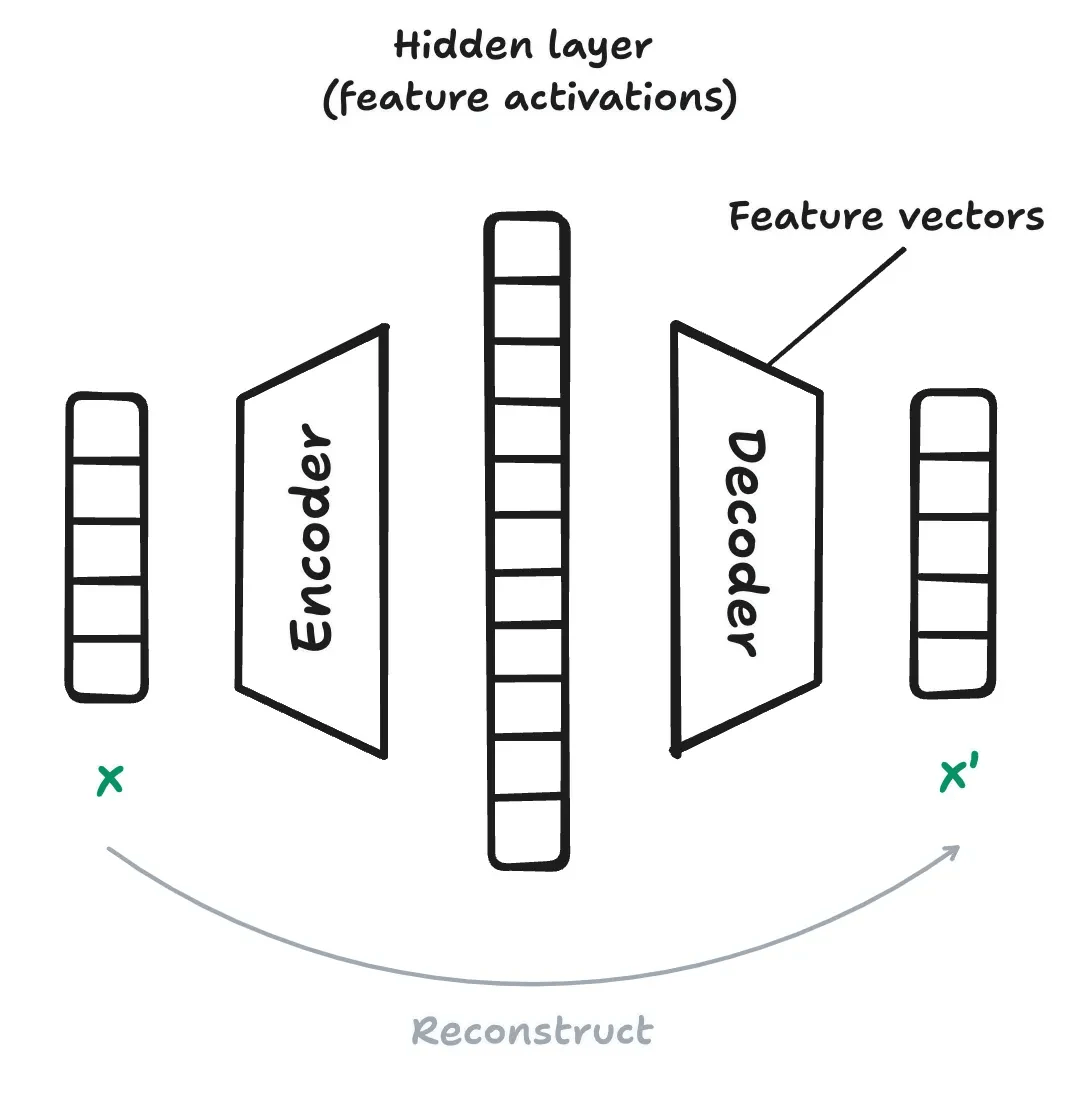
Sparse Autoencoders (SAEs)

-
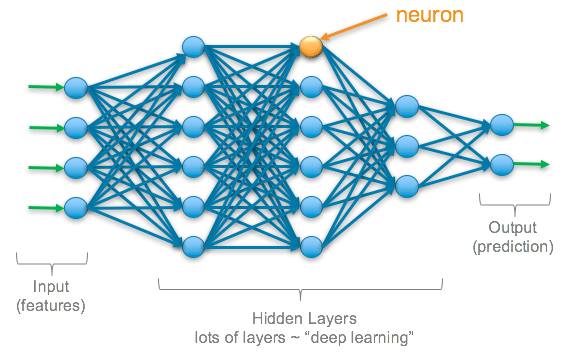
In complex/deep models, neuron activations are dense
-
Almost all neurons activate for many inputs
-
-
Hard to tell what any single neuron actually represents
-
SAEs help us separate these signals
Problems with Complex ML Models
-
SAEs have 2 parts:
-
Encoder: compresses input activations into a new feature space.
-
Decoder: reconstructs the original input from that space.
-
Main Parts of Sparse Autoencoders
-
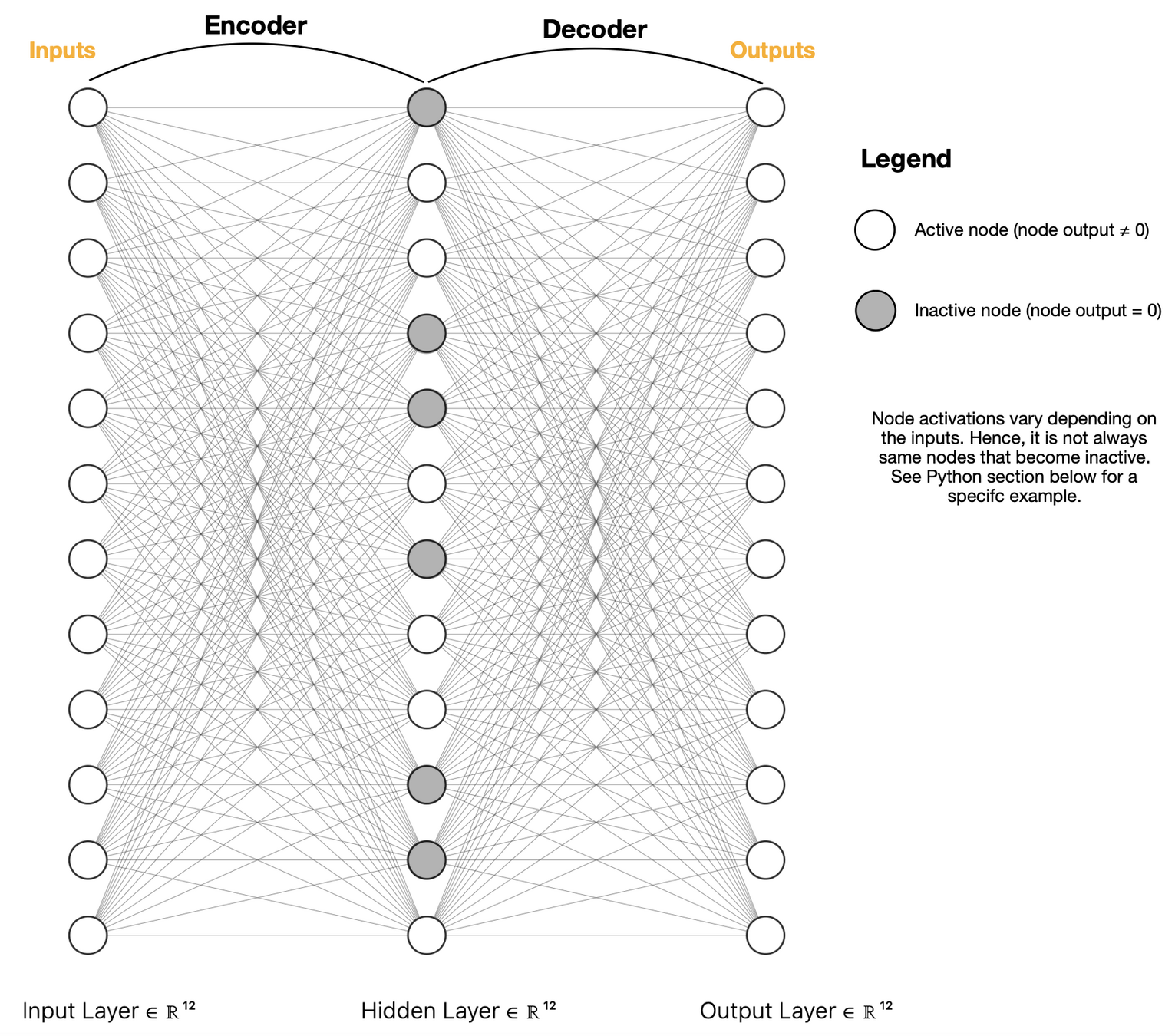
A sparse autoencoder learns a new representation where most components are zero (sparse).
-
Each nonzero component ideally corresponds to a specific concept.
-
The encoder maps activations to this sparse, high-dimensional space, and the decoder reconstructs the original activations.
-
The model is trained to rebuild accurately while keeping the representation as sparse as possible.
Core Idea of Sparse Autoencoders
Don't worry if not much of this makes sense right now, I'll show visuals later!
-
These 2 concepts are super important:
-
Reconstruction loss → how close the decoded output is to the original activations.
-
Sparsity penalty → encourages most feature activations to be zero.
-
-
In Laymen's terms, SAE's try to find the simplest way to represent neurons in a model!
Core Idea of Sparse Autoencoders
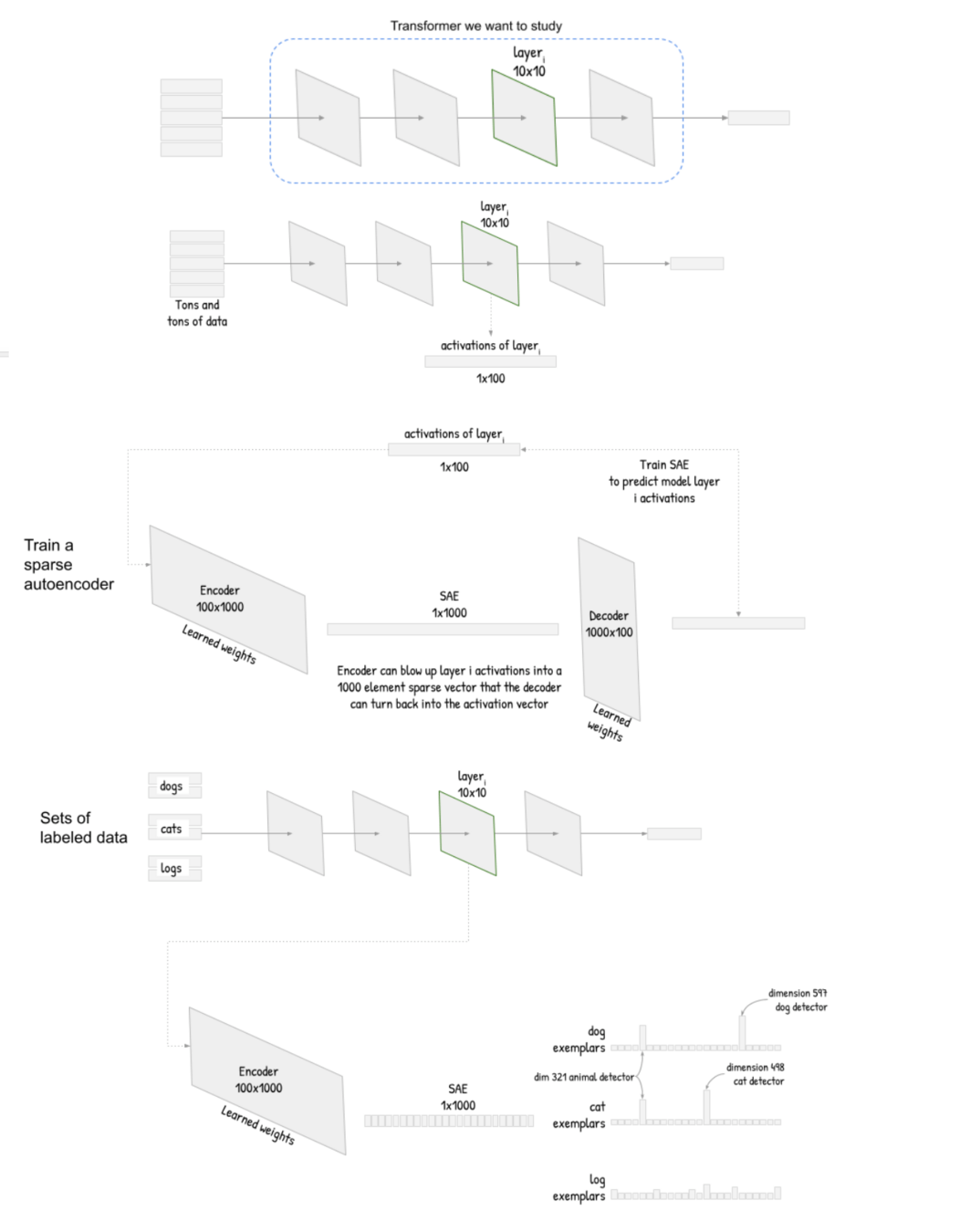
Dog
Example Use-Case


Cat
Features most correlated to dog
Features most correlated to cat
Latent vector
Latent vector
Future of SAEs
-
Scaling to frontier models
- Training SAEs on 400B+ parameter models
-
Causal steering
- Prove causation over just correlation to better control model output
-
Automated interpretation
- LLMs that self-explain their own features without human labeling

Storyboard Your Narrative

the hook
scene 1
scene 2
scene 3
scene 4
the takeaway