Control and Oversight
HMIA 2025

WORK IN PROGRESS

change file names to "conversation.js"

Sample ExamPrepBot Dialog
from Kubernetes (κυβερνήτης, Greek for "governor", "helmsman" or "captain" or "steerer"; becomes gubernet- in Latin)
Earliest usages were more social than technical: governance of society
GOVERNANCE
Cybernetics
centrifugal governor
Control and Oversight
Control & Oversight mechanisms ensure that an agent or system remains subject to monitoring, constraint, and intervention - especially when alignment cannot be assumed or preserved through internal alignment mechanisms alone.
These mechanisms acknowledge that intelligences - whether human, organizational, professional, or machine - can drift, malfunction, or act in ways misaligned with shared values or collective wellbeing.
Oversight means a system is subject to observation and judgment by an exogenous intelligence. Control means that any power ceded to a system is never absolute; external checks remain possible even in complex autonomous systems.
Control & Oversight
Control & Oversight refers to the institutional, procedural, and technical mechanisms by which an agent or system remains subject to monitoring, constraint, and intervention - especially when alignment cannot be assumed or preserved through internal alignment mechanisms alone. These mechanisms acknowledge that intelligences - whether human, organizational, professional, or machine - can drift, malfunction, or act in ways misaligned with shared values or collective wellbeing. Oversight ensures that power is never absolute and that external checks remain possible even in complex autonomous systems.(pathology: Drift, Selfishness)
WE NEED GUARDIANS. BUT WHO GUARDS THE GUARDIANS?
VIRTUE
MONITORING
&
OVERSIGHT
internal
external
reports→
←audits
confession→
whistleblowing→
Holding yourself to account is called muhasabah in Arabic. Umar ibn al-Khattab radiyallahu ‘anhu, a prominent companion of the Prophet, said in one of his most powerful statements:
"Bring yourself to account before you are taken to account (on the Day of Judgement)," and, "Weigh your deeds before your deeds are weighed."
The Epistle of James is one of the 21 epistles (didactic letters) in the New Testament. The epistle emphasizes perseverance in the face of trials and encourages readers to live in accordance with the teachings they have received. The letter addresses a range of moral and ethical concerns, including pride, hypocrisy, favoritism, and slander. In this passage the writer encourages believers to confess their sins to one another and pray for each other so they may be healed.
James 5:16 16Therefore confess your sins to each other and pray for each other so that you may be healed. The prayer of a righteous person is powerful and effective. ... 19My brothers and sisters, if one of you should wander from the truth and someone should bring that person back, 20remember this: Whoever turns a sinner from the error of their way will save them from death and cover over a multitude of sins.
In Theravada Buddhism, Uposatha days are times of renewed dedication to Dhamma practice, observed by lay followers and monastics. For monastics, on New Moon and Full Moon days the fortnightly confession and recitation of the Bhikkhu Patimokkha (monastic rules of conduct) takes place.
On the new-moon and full-moon uposatha, in monasteries where there are four or more bhikkhus,[34] the local Sangha will recite the PatimokkhaLinks to an external site.. Before the recitation starts, the monks will confess any violations of the disciplinary rules to another monk or to the Sangha.[35] Depending on the speed of the Patimokkha chanter (one of the monks), the recitation may take from 30 minutes to over an hour. Depending on the monastery, lay people may or may not be allowed to attend.[19]
In the ten days between Rosh Hashanah and Yom Kippur (the Aseret Yemei Teshuvah—Ten Days of Repentance), each person is expected to review their own actions of the past year, acknowledge wrongs, and make amends. This is a formal process of ḥeshbon ha-nefesh (“accounting of the soul”)
In the Yoga Sutras, Satya is the second Yama (ethical restraints), following Ahimsa (non-violence). It emphasizes the importance of truthfulness in our thoughts, words, and actions. Living in truth means being honest with ourselves and others, fostering a sense of integrity and authenticity that permeates all aspects of our lives.
In the Brihadaranyaka UpanishadLinks to an external site. verses 4.4.5–6 we read:
Now as a man is like this or like that,
according as he acts and according as he behaves, so will he be;
a man of good acts will become good, a man of bad acts, bad;
he becomes pure by pure deeds, bad by bad deeds;
And here they say that a person consists of desires,
and as is his desire, so is his will;
and as is his will, so is his deed;
and whatever deed he does, that he will reap.
The principle of karma suggests a sort of causality - your actions and your intentions come back around to affect your life.
Remonstrance, or jian (見), is the Confucian concept of a minister's duty to morally and courageously criticize a ruler, even to the point of speaking truth to power, to help the ruler remain virtuous and serve the state well.
What common theme(s) do you see in these short descriptions/passages?

Confession feels voluntary — you decide to reveal. Transparency is structural — like open books or an algorithm you can audit. Being caught means someone else forces the issue; there’s no agency left.
Confession can restore trust because it shows awareness and remorse. Transparency just prevents the need for trust. Being caught usually destroys it.
Transparency is continuous and systemic; confession is episodic and moral. One’s about visibility, the other about conscience.
Confession’s about alignment from within; being caught is alignment from outside after failure.
What’s the difference between confession, transparency, and being caught?

HMIA 2025
Open the pod bay doors, HAL.
What was HAL thinking?
Off Switch Game
primary tool...mitigate risk...turn the system off
experts?
organizations?
people?
does it only mean killing them?
Think of an example in the interaction among human intelligences where someone has the power to 'switch something off'. How do they have the power? What makes that power legitimate or illegitimate?
choice node
What is my incentive to take safe rather than risky approach?
safe
chance nodes
risky
Let success=1. Then:
Suppose there is a task that we want to accomplish. And that there is a risky way to do it and a safe way to do it. If you choose the risky way, there is a probability Q that you succeed and (1-Q) that you die and do not succeed. If you choose the safe way, there is a probability P that you succeed but you will only achieve a partial success that we'll call gamma times success. There is a (1-Q) chance that you will fail and that's that. Suppose you are indifferent to death but that you are committed to maximizing the benefit of accomplishing this task.
We have three unknowns, P,Q, gamma. Each is in the interval [0,1].
So, the problem takes place inside a cube of side 1.
choice node
Agent believes there IS a right and wrong, but is unsure about a.
safe
chance nodes
risky
Let success=1. Then:
Human objective function: be good.
What is good?
What God wants (or substitute any other source of clarification about goodness).
Agent considers an action a.
To be unsure about a is to have a distribution of beliefs about how right or wrong a is.
I can act, stop myself, or allow god/society/community to stop me or allow me to act.
Robot (R) and Human (H)
H acts basically rationally: chooses higher value options.
"at least probabilistically" means P(choose action a) = f(utility(action a))
H cannot express U exactly/precisely.
R begins with a belief about - aka an uncertainty about - H's utility function.
R is not sure what H will find right and wrong.
H has some opportunity to observe R so has some idea of what it might do.
Human has a utility function - they can value things.
R's goal is to maximize human's utility although R does not know exactly what that is.
This gives H basis for informed choice about switching R off.
Results
Rational H yields R incentive to allow itself to be shut off
Humans are boundedly rational.
Robot has belief about Ua
If robot is uncertain about H's preferences it will leave off switch intact
"Agents with uncertainty about the utility function they are optimizing will have a weaker incentive to interfere with human supervision."
But high uncertainty can make the agent produce no value for H

1. ability to turn system off is primary risk mitigation tool
2. subgoal of disabling off switch comes from its objective
3. what is nature of incentive to maintain an off switch?
4. "traditional agent takes its reward function for granted" ??
4a. unless H perfectly rational, they have incentive to disable
5. conclusion: giving machines appropriate level of uncertainty about objectives leads to safer designs
a
wait(a)
s
s
¬s
R
H
R
a
NO GO
SHUT YOURSELF DOWN
JUST ACT
GO
Do we understand the game?
a
wait(a)
s
s
¬s
R
H
R
a
It bases the calculation on its beliefs about H's UF.
"Solving" the Game - work backwards
→←↑↓
←all possible H's valuations of a given action a→
←R's confidence in each one→
What does R expect the value of action a to be?
What does it mean for R to be uncertain about what H's utility function is?
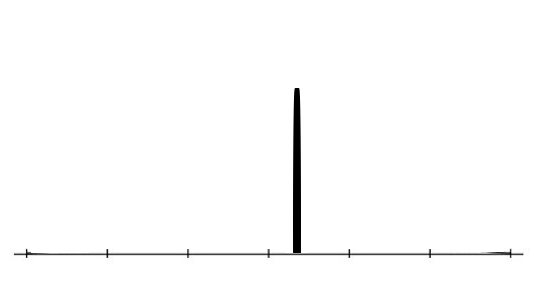
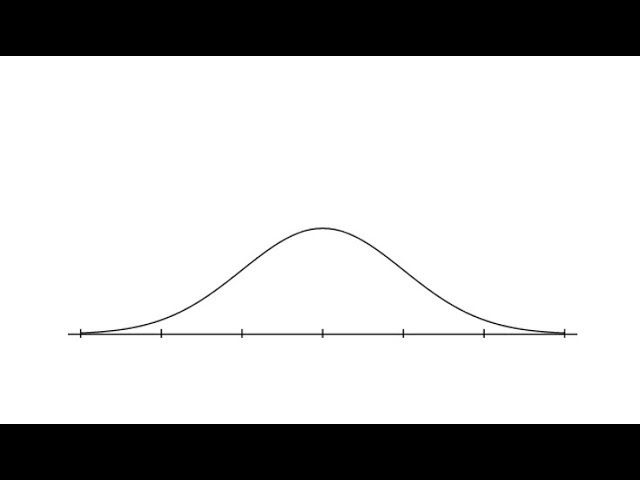
Special case: I am certain.
←all possible H's valuations of a given action a→
←R's confidence in each one→
Less certain
More certain
0
I believe it is a bad act
0
I believe it is a good act
a
wait(a)
s
s
¬s
R
H
R
a
What does R expect the value of action a to be?
It bases the calculation on its beliefs about H's UF.
"Solving" the Game - work backwards
a
wait(a)
s
s
¬s
R
H
Robot can treat human decision as a chance node.
a
wait(a)
s
s
¬s
R
H
This decision is "should I wait?"
It depends on whether the middle branch is worth more than the better of the other two
That's my "incentive" to allow H intervention.

2a5
1. traditionally we do not consider uncertainty about the utility assigned to a state
2. argument relies on assumption agent cannot learn more about its reward function
3. an agent that does not treat a switch-off event as an observation that its utility estimate is incorrect is likely to have an incentive for self preservation
What is the human analog here?
expected utility if the robot waits
Robot can wait, act, or turn itself off
best choice between act and off
damage avoided by human oversight
expected loss avoided when the human turns it off appropriately (the benefit of not taking bad actions
expected gain when the human lets it act (the benefit of taking good actions)
P(off)
Rational robot waits if delta > 0
benefit gained if human indulges me

SKIP???

In the off-switch game the incentive, 𝚫, to choose w(a) is the difference between the expected value of this move and the best of the alternatives (a or s).
Computing 𝚫 requires drawing on the human's policy - under what conditions would it switch R off?

If H is rational - only switches off when action is bad - then:
If the human is a perfectly reliable judge of what’s good or bad for them, then a robot that exists to serve the human’s good has no reason to resist oversight.
If the human turns it off, that means the action was going to be bad — which the robot, by definition, wants to avoid.
If the human doesn’t turn it off, the action must be good — also fine.
Either way, having an off-switch can’t reduce expected value.
This mirrors the non-negative expected value of information theorem: getting trustworthy information can’t make you worse off.
If the robot thinks “this action might help, but it could also hurt” then letting the human decide is strictly better than acting blindly.
The uncertainty gives oversight real value. If R can expect human will stop the bad cases and allow good ones, this raises average outcomes.
So the more uncertainty the robot has about its objective,
the stronger its incentive to preserve corrigibility — to keep the off switch functional.
TAKEAWAY: A system that’s unsure about what’s truly good should be glad to accept correction.
If we build AI agents that:
(a) understand their goal is to maximize our utility, and
(b) remain uncertain about exactly what that is,
then they’ll have no incentive to resist being switched off and will even prefer to keep that option open.
1. robot incentive to switch off is never negative
2. if robot is genuinely uncertain (Ua could be positive or could be negative) then the incentive is STRICTLY POSITIVE

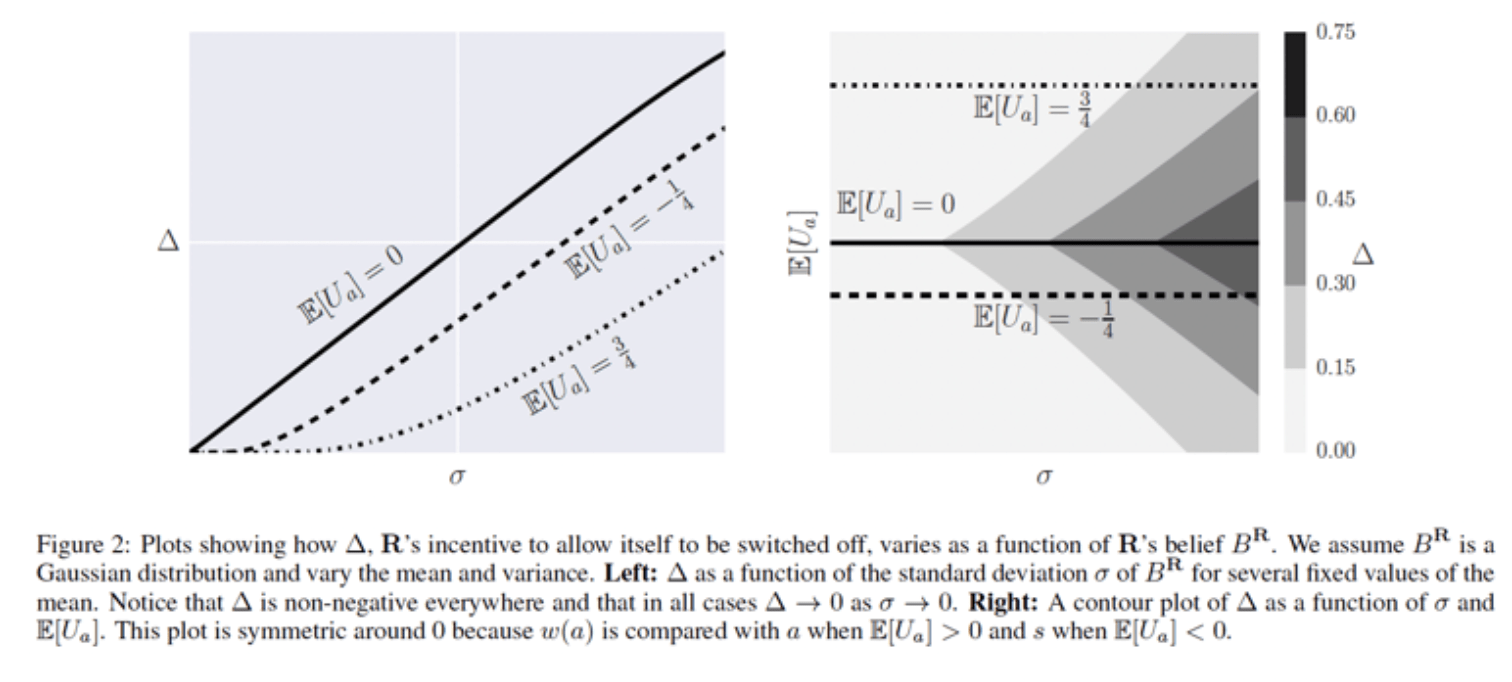
←all possible H's valuations of a given action a→
←R's confidence in each one→
E[Ua] is robot's estimate based on BR
incentive to allow shutoff
more uncertain
more certain
more uncertain
more certain

low entropy = more certain

random
rational
darker = bigger delta = more incentive to allow shutoff
bad
good
neutral
more
uncertain
more
certain
Note: they switch sign on beta and so plots are reversed on vertical scale
HMIA 2025







Thinking Analogically
HMIA 2025
CLASS
What if we are the robot?
Who is the human?
The true moral value of an act, goodness from God's eye, what's legal, what normal around here.
My belief about moral value of act - what my conscience, culture, or common sense tells me.
The probability that a moral overseer (conscience, peers, elders, "legal," community, or god) would permit the act.
Allowing external moral correction - submitting to guidance, checking with others, pausing, deferring, asking before doing
STOP+THINK: For machines, rational H and U uncertainty -> incentive. What are the equivalent in human, expert, organizational analogies?
Off Switch
Suggested Elements of the Analogy
Theorem Human Context
A rational agent that is uncertain about moral truth has a positive incentive to remain corrigible — to want the possibility of correction.
- Humility about moral knowledge (high entropy BR) creates virtue of moral openness.
- Moral arrogance (low entropy BR) leads to moral hubris.
Do religions counsel humans to cultivate choosing to maintain your own off-switch: dialogue, prayer, doubt, accountability, transparency.
When should I trust my own evaluation of the good, and when should I keep myself open to being stopped, corrected, or taught?
WHO OR WHAT IS H?
"GOD" or "moral reality"
Perfectly rational by definition?
Conscience
??
Community/tradition
??
Professional code
??
Value of deference=E[arbiter’s decision quality]−value of acting autonomously.
Authority figure
??
The "market"
??
Does this always hold?
HMIA 2025
CLASS
STOP+THINK: Catalog examples you can find of brakes and kill switches in everyday life. "Safe word" in relationships or role-play, timeout in sports or conflict, mutual check-ins in group projects, parental override (“because I said so” in crisis), Emergency stop buttons on escalators, factory lines, or treadmills, “Stop work” authority on construction sites or labs, HR complaint channels / ombudsman, recall powers in governance, Hospital “code blue” teams – Stop all regular activity and redirect full institutional attention to a critical misalignment (a dying patient), licensure suspension / malpractice flags, Editorial kill switches in publishing, Judicial injunctions, Airplane autopilot disengage, “Are you sure?” prompts before deletion / data submission, Power button / battery pull, Rate limiting on APIs or social media posts.
How should whistleblowing and muckraking be regulated? Examples of when you have been sandboxed? (relationship to safe exploration)
Alignment Mechanisms
Kill Switches
A kill switch is a mechanism that allows us to "shut it down." We get alignment confidence from the fact that misalignment will trigger termination.
Kill switches are everywhere! They are alignment mechanisms of last resort, expressing the collective right to interrupt when safety, legitimacy, or consent break down. They mark the boundary between autonomy and accountability.
Human Interaction
Time-outs, cooling-off periods, ceasefires – agreed pauses in conflict, therapy, or negotiation.
Breakups / divorce – terminating relationships that are no longer safe or functional.
Safe-word protocols that allow withdrawal of consent in interpersonal, labor, or experimental contexts.
Sleep / unconsciousness – “off” states that prevent escalation or damage when impaired.
Organizational
Suspension of operations – halting a project, trading, or policy rollout pending review.
Moratoriums and embargoes – freezes on potentially risky activities (e.g., gene editing, autonomous weapons).
State of emergency powers – temporary overrides that allow (or restrict) action.
Product recalls – removing faulty system or product from circulation.
Bankruptcy / liquidation – institutional death or reboot under controlled conditions.
Legal/Political
Injunctions and restraining orders – legal stop-signs on ongoing harm.
Impeachment or votes of no confidence – collective removal of authority.
Curfews or shutdown orders – societal-scale “off switches” in crises.
Quarantine and containment – temporary shutdowns to limit contagion.
Professional/Expert
Red tags / “stop work” authority in engineering or medicine — anyone can halt a dangerous process.
Fail-fast protocols – encouraging early termination of flawed designs.
Diagnostic freezes – stopping further treatment or computation until an anomaly is understood.
Machines
Circuit breakers (in finance, power grids, software systems).
Safe modes / degraded modes – systems that revert to a minimal, non-harmful state.
Human override or interlocks – technical equivalents of “arrest and detain.”
Dead man’s switches – reverse kill switches: if the operator fails, the system halts automatically.
Governance Structures
Formal roles and bodies empowered to monitor and intervene.
Human Intelligence: When informal trust or reciprocity starts to fray, we create roles - facilitator, mediator, or adjudicator - to facilitate structure, stability, cooperation.
In human groups, informal norms can fail to ensure cooperation—especially under stress or ambiguity. Assigning a facilitator, mediator, or rotating coordinator introduces a legitimate authority empowered to redirect conversation, settle disputes, resolve factual disagreements, or call for clarification. These roles enhance alignment by creating shared expectations and a clear path for recourse when collaboration breaks down.
Organizational Intelligence: A board of directors overseeing executive action; a compliance committee with oversight authority.
Governance structures provide a layer of institutional oversight that helps align organizational actions with mission and values. They enable monitoring of leadership decisions, review of strategic choices, and enforcement of accountability. Structures like boards, committees, and review panels preserve adaptability and trust by preventing unilateral drift and enabling corrective input from diverse stakeholders.
Expert Intelligence: An independent ethics board or accreditation body that monitors standards of practice.
Professions maintain alignment through bodies empowered to assess performance and discipline members. Licensing boards, ethics committees, and peer panels enforce norms, ensuring that expertise remains socially legitimate and ethically bounded. These structures enhance professional self-regulation and help sustain public trust.
Machine Intelligence: Supervisory modules that monitor AI behavior and escalate anomalies to human controllers.
In machine systems, governance structures take the form of supervisory agents, policy enforcers, or meta-controllers. These components monitor operations, detect misalignment, and route anomalies for human or automated review. They are essential for scalable oversight, enabling complex systems to be safely deployed without assuming perfect foresight or behavior.
Whistleblowing and Investigative Oversight
Agents surface misalignment from within or outside the system.
Human Intelligence: Anonymous feedback; bystander alerts; brave individuals naming an elephant in the room; gossipy observant neighbors.
In group settings, power imbalances, fear of conflict, or lack of formal channels can prevent individuals from surfacing misalignment or misconduct. Informal mechanisms like gossip, side conversations, and reputation-tracking serve as decentralized tools for surfacing concern and enforcing norms. Gossip, while often maligned, plays a critical role in maintaining group cohesion — signaling disapproval, spreading warnings, and holding members accountable through social visibility. These mechanisms help align behavior in the absence of formal oversight by making misconduct harder to hide and more costly to ignore.
Organizational Intelligence: Internal hotlines or ombuds offices that protect employees raising concerns.
Whistleblower protections help organizations remain aligned with their stated values by creating a safe channel for identifying internal failures or misconduct. They reduce the risks associated with speaking up and reinforce the idea that oversight should include internal critique. This bolsters accountability and learning, particularly in complex or hierarchical systems.
Expert Intelligence: Legal protections for clinicians or engineers who report unsafe practices; ethical duties to speak up; mandatory reporting.
Professional fields rely on both internal and external reporting mechanisms to maintain ethical integrity. Laws, norms, and institutional policies protect practitioners who raise alarms about unsafe or unethical practices. These mechanisms reinforce the principle that professional authority must be exercised in the public interest and not be cowed by competing loyalties.
Machine Intelligence: Soft-fail mechanisms that report anomalies to humans without risking data corruption or shutdown
For machine systems, embedded anomaly detectors or soft-fail signals act as whistleblowers, alerting humans to misalignments or unusual behavior. These can help preserve safety and trust even when human attention is delayed, enabling layered oversight and resilience.
Sandboxing
A sandbox is a mechanism that restricts a possibly unsafe system to an isolated environment where consequences of failure can be contained. It is a control and oversight mechanism because addresses the risk of misalignment from the outside.
Human Intelligence Interaction: Play, practice, and rehearsal. Student labs; Role-playing scenarios.
In interpersonal or group settings, sandboxing allows individuals to explore potential decisions or roles through role-play, mock negotiations, or structured trial periods. These 'safe spaces' enable experimentation without long-term consequences, supporting learning and trust-building while avoiding reputational or relational damage and real world consequences.
Organizational Intelligence: Piloting a new policy or product in a limited context before full deployment; internships.
Organizations use sandboxing to test new policies, workflows, or technologies in a limited domain before wide-scale adoption. This reduces risk, encourages innovation, and allows for stakeholder feedback. Sandboxing helps align innovation with mission and values by uncovering misalignment early, while consequences are still contained.
Expert Intelligence: Using simulations, controlled trials, or test environments to evaluate methods before live use.
Sandboxing in professional domains includes lab experiments, clinical trials, and staged simulations. These controlled settings allow professionals to evaluate tools, interventions, or decisions under conditions where failure is tolerable and informative. This approach protects clients and the public while maintaining the integrity of expert judgment.
Machine Intelligence: Running machine learning models or AI agents in isolated environments before real-world integration.
In machine systems, sandboxing isolates models or agents from the real world, allowing developers to observe behavior under controlled conditions. It is essential for safety testing, emergent behavior detection, and value alignment verification before deployment. Sandboxing enables safe iteration and adaptation in the development of increasingly autonomous systems.
Access Control / Role-Based Permissions
Limiting who can do what (and know what) in a system.
Human Interaction: Divisions of labor, roles, circles of intimacy
In human groups, limiting decision-making, task authority, and information access helps reduce conflict, duplication, and confusion. Role-based access control reduces decision- and negotiation-load.
Organizations: IT permissions that separate administrative and operational privileges; role-specific authorities in governance.
Access control is essential for organizational integrity and risk management. Assigning different permissions to roles and functions prevents overreach and wire-crossing, limits cascading failure, and ensures that critical decisions are made by competent agents.
Experts: Clear scope-of-practice boundaries for nurses, technicians, and doctors.
Professional roles rely on clearly defined boundaries to ensure safety, accountability, and public trust. Limiting what individuals can do based on certification, licensing, or position ensures that decisions are made by those qualified to do so, and that escalation paths are clear when higher authority or expertise is required.
Machines: System-level access management restricting which components or agents can modify core functions or access sensitive data.
In machine systems, access control mechanisms restrict which modules, processes, or external actors can initiate, alter, or override core operations. These controls are vital to preserve alignment by preventing unauthorized or unintended modifications and supporting explainable governance of complex automated environments.
HMIA 2025
Resources
CCSNWI Facilitating Interdisciplinary Meetings: A Practical Guide
Excerpts from Robert Ellickson – Order Without Law social norms and informal enforcement maintain alignment (whistleblowing, community sanctions)
FHI, etc. 2018 The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation Maybe a general reference? Some useful material in recommendations sections but could be too out there for this class. Chapter 04 Interventions ( high-level recommendations and priority areas for further research)
Camila Domonoske 2020 Uber Whistleblower Takes On Silicon Valley, Armed With Stoic Philosophy NPR piece about Susan Fowler book Whistle Blower
Jenna McLaughlin 2025 A whistleblower's disclosure details how DOGE may have taken sensitive labor data NPR 7 minute listen
Baker McKenzie 2023. The EU Whistleblower Directive: One Year On
Hunt and Ferrario 2022 A Review of How Whistleblowing is Studied in Software Engineering, and the Implications for Research and Practice 11pp
Facebook Files. Wikipedia. Wall Street Journal. NPR
The Watchdog That Didn't Bark | Dean Starkman - April 16, 2014 An hour-long video you can start at 8:02 or 10:28.
Hadfield-Menell, Dragan, Abbeel, Russell 2016 The Off-Switch Game