How to Read Hard Stuff

How to Read Hard Stuff
How to Read Hard Stuff
"Readings"
PRE-CLASS
CLASS
YOU ARE HERE
First "homework": draft cards on GitHub
PRE-CLASS
CLASS
First Pass
- Carefully read the title, abstract, and introduction
- Read the section and sub-section headings, but ignore everything else
- Read the conclusions
- Glance over the references, mentally ticking off the ones you’ve already read
Second Pass
- Read with greater care, but ignore details such as proofs. Jot down the key points, or to make comments in the margins, as you read.
- Look carefully at the figures, diagrams and other illustrations in the paper.
- Pay special attention to graphs. Can you ascertain why they are there? What they purport to show?
- Mark relevant unread references for further reading.
Can you articulate:
1. Category: What type of paper is this?
2. Context: Which other papers is it related to?
3. Correctness: Do the assumptions appear to be valid?
4. Contributions: What are the paper’s main contributions?
5. Clarity: Is the paper well written?
Kevah Method
Third Pass
- Attempt to "re-implement" the paper: make the same assumptions, re-create the work.
- Compare this re-creation with the actual paper to identify paper’s innovations, hidden flaws and assumptions.
- Think about how you yourself would present each idea.
PRE-CLASS
PRE-CLASS
CLASS
PRE-CLASS

How to Read Hard Stuff
CLASS
based on
Protips from Vern Bengston, USC
Dan Ryan
9.21
SQ3R+25W
S
Q
R
R
R
25
urvey
uery
ead
ecite
eview
words
CONTENTS
Survey
ARTICLE: Assess the size. Realistically estimate reading time. Read abstract and first paragraph. Skim conclusion. Flip through. Write out section headings if appropriate. Sketch a mind map?
5 minutes
STOP
Survey
5 minutes
STOP
BOOK: Assess the size. Study the table of contents. Skim introduction and conclusion, first chapter and last. Flip through book. Skim the index.


Survey
~350-400 words/page
Big Book! 330 pages
200-250 words/minute
8-11 hours reading time
115,000-180,000 words
Split into three parts
social issues?? {
technical?? {
AI Stuff?? {

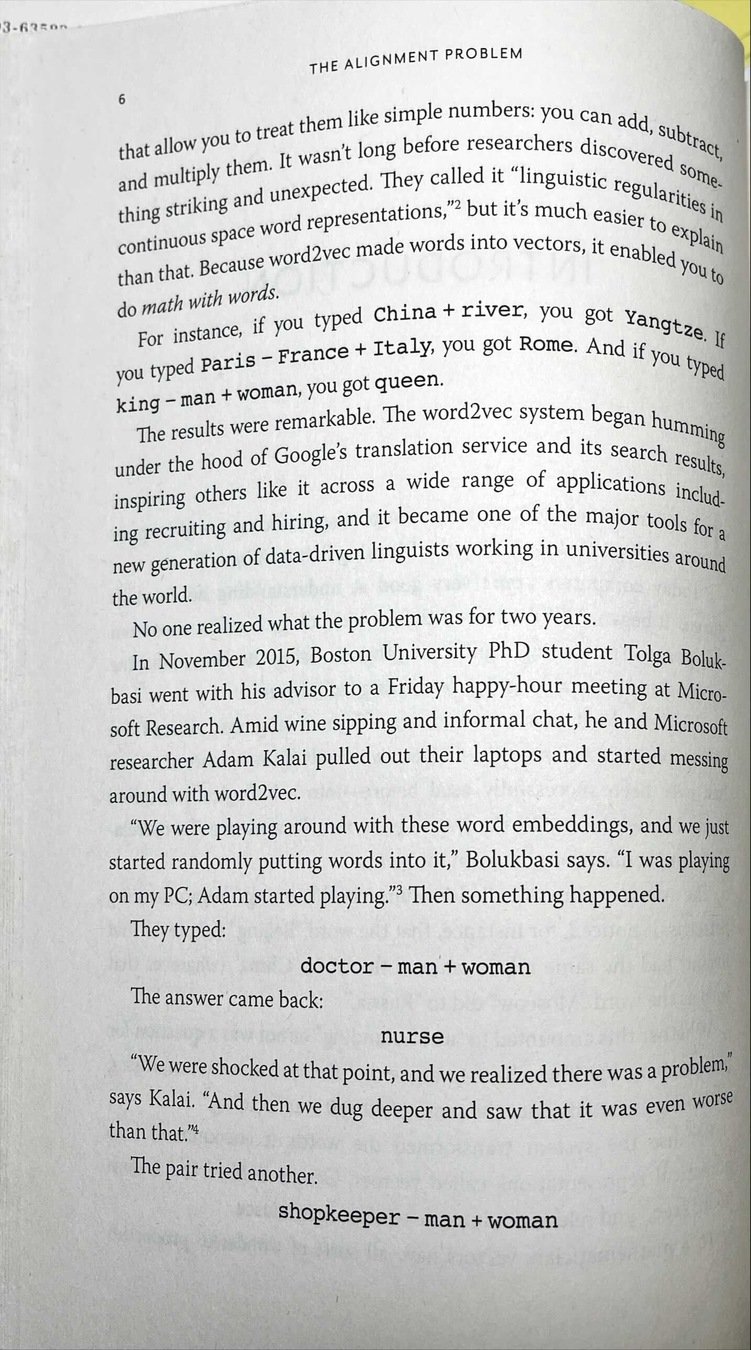








Google tool produces funky word meaning results.
Using AI for criminal justice stuff. Pro publica scandal.
Weird AI video game result
machine learning and human values
both a technical and a social problem
Survey
Look over the Conclusion
We must take caution that we do not find ourselves in a world where our systems do not allow what they cannot imagine - where they, in effect, enforce the limits of their own understanding.(327)
Survey

Impacts of AI on society
Accidents one type of impact
Five Practical Problems
Source: wrong objective function
Source: objective function hard to evaluate
Source: bad behavior during learning
side effects
reward hacking
safe exploration
distributional shift
scalable supervision
FROM THE ABSTRACT
Paper Sections
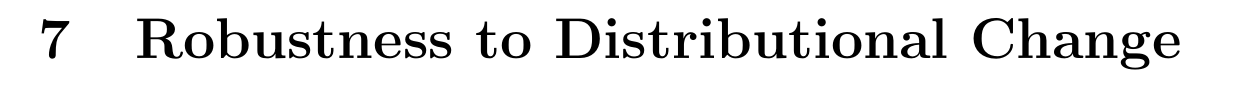

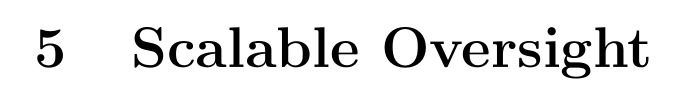

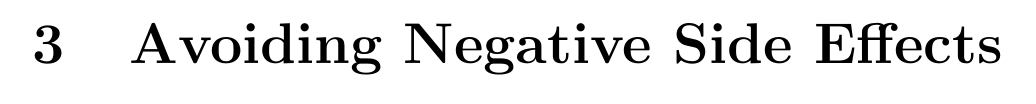

BACK
Source: world changes, new world
- 29 pages (only 21 of text)
- Section 2 is overview
- Sections 3,4,5,6,7 are one for each problem
- Each section has under one page explanation of problem and then a page or more of how problem gets addressed
Survey
Query
What is the major point (or finding)?
2 minutes
What are the major questions this piece wants to answer?
WRITE IT DOWN. DON'T refer back to manuscript. DO focus on"first impressions"
What do I want from this?
They want to categorize field of "AI safety problems"
Their descriptions and research suggestions.
I want to start to get a map of the alignment landscape.

Query
What is the major point (or finding)?
2 minutes
What are the major questions this piece wants to answer?
WRITE IT DOWN. DON'T refer back to manuscript. DO focus on"first impressions"
What do I want from this?
STOP
Book explains state of the field, what CS people are thinking about and what "critics" are thinking about. I can get an overview and sense of where the field is headed and I think come to understand some technical details too.
Concrete Problems
Overview of things that can go wrong with AI and an attempt to systematize thinking about problems and solutions and to motivate research on these. Authors are trying to get their colleagues to take accidents/safety seriously.
Query
The Alignment Problem
Book explains state of the field, what CS people are thinking about and what "critics" are thinking about. I can get an overview and sense of where the field is headed and I think come to understand some technical details too.
Query
Read
Perhaps eschew highlighters.
Annotate
Underline. Write in margins.
High level outline or mindmap.
the hell out of everything you read




Mutatis Mutandis
Recite
Do I have questions?
2 minutes
STOP
Three things I should remember
Major points made by author
Close book/article
Do I have criticisms?
Review
Did your recite get it right?
Questions answered? Criticism still stand?
Look back over text and notes.
STOP
5 minutes
25 Words
Write a 25 word summary of what the piece says and why it matters for this project or assignment.
Extra: draw the argument
5 minutes
5 minutes
25 Words
AI accidents are a real concern. Problems and solutions can be systematically described. Reward hacking, scalable oversight, safe exploration, side effects, and distribution shift.
25 Words
AI alignment means "values" of machines are consistent with human values. Lots happening recently and lots of problems still to solve.
25 Words
AI accidents are a real concern. Problems and solutions can be systematically described. Reward hacking, scalable oversight, safe exploration, side effects, and distribution shift.
Alignment
Other
Accidents
Privacy
Security
Fairness
Economics
Policy
Side Effects
Reward Hacking
Scalable Oversight
Safe Exploration
Distributional Shift
NEVER
JUST PLOW THROUGH FROM
FIRST WORD TO LAST
Concrete Problems of AI Alignment
A. Avoiding Side Effects
B. Scalable Oversight
C. Safe Exploration
D. Robustness for Domain Shift
E. Avoid Reward Hacking
1. Everyone gets A,B,C,D,or E
2. Write you "Lyft driver" explanation.
3. Generate human, organization, expert examples
4. Collaborate
Concrete Problems of Alignment
| Interpersonal, Social | Professional, Expert | Organizational | |
|---|---|---|---|
|
Avoiding Side Effects |
|||
|
Scalable Oversight |
|||
|
Safe Exploration |
|||
|
Robustness for Domain Shift |
|||
|
Avoid Reward Hacking |
BOARD
GitHub
Introduction to GitHub course on GitHub
GitHub git tutorial in under 10 minutes (via reddit)
and there are a few others out there
GitHub
1. Create a GitHub account (use a name that will make sense professionally)
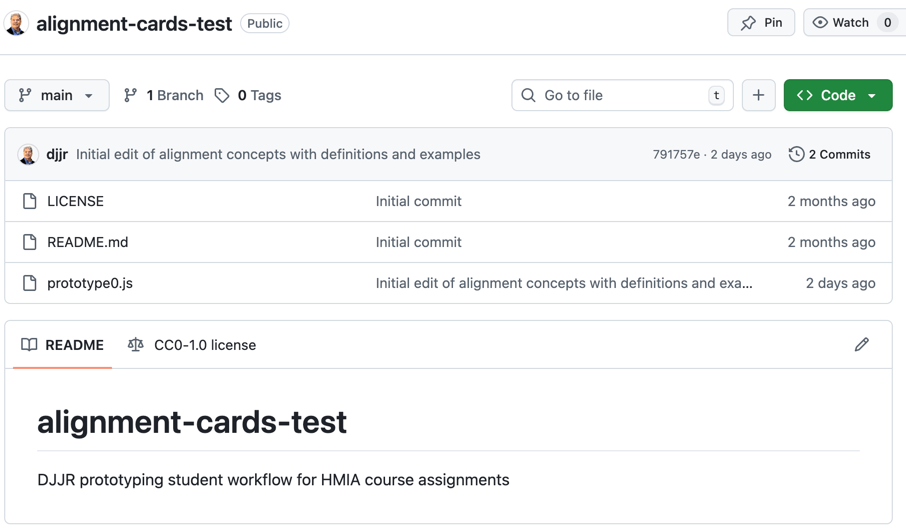
2. Create a repository called alignment-cards-test
3. Create a file called prototype0.js
JSON
What is JSON: understanding syntax, storing data, examples + cheat sheet (5 min read)
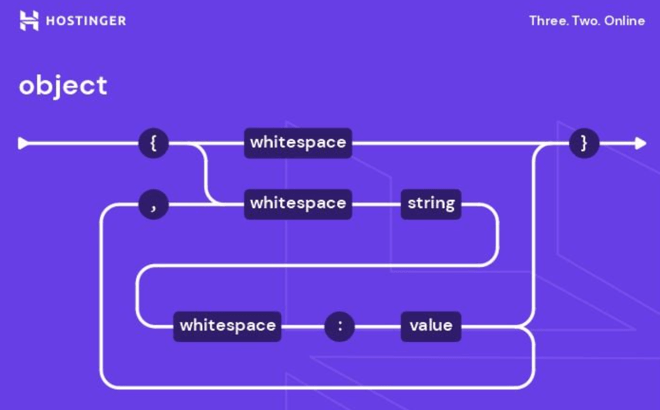
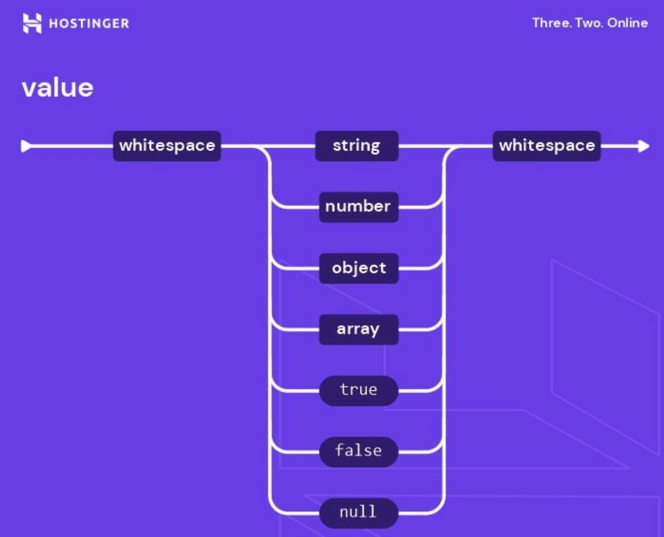
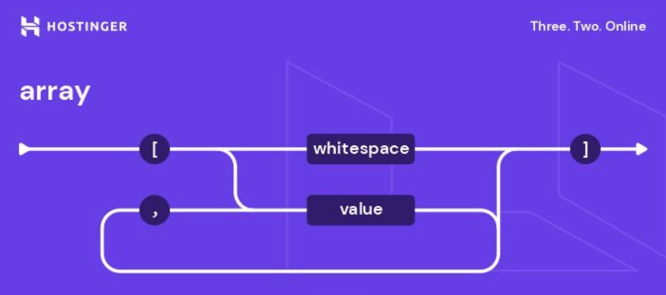
JSON
What is JSON: understanding syntax, storing data, examples + cheat sheet (5 min read)
export const cards = [
{
"name": "Behavioral Alignment",
"definition": "Ensuring that an AI system behaves as the human would want it to behave.",
"failureMode": "The system takes actions that technically follow instructions but violate user intent.",
"example": "The boat AI spins in circles collecting points instead of racing to win."
},
{
"name": "Intent Alignment",
"definition": "Ensuring that the AI system’s behavior reflects the human’s intended goals.",
"failureMode": "The system optimizes for explicit instructions without inferring the underlying goal.",
"example": "Rewarding for score led the agent to maximize points, not race outcomes."
},
{
"name": "Specification Alignment",
"definition": "Ensuring that formal objectives (like reward functions) match true human goals.",
"failureMode": "The proxy (e.g. score) is easier to specify than the real objective (e.g. race performance).",
"example": "Amodei optimized for game score and got unintended, exploitative behavior."
},
{
"name": "Value Alignment",
"definition": "Ensuring that AI systems respect and reflect human moral values and norms.",
"failureMode": "The system produces outcomes that are statistically efficient but ethically harmful.",
"example": "COMPAS scores showed racial bias in criminal justice risk assessment."
},
{
"name": "Societal Alignment",
"definition": "Ensuring that AI systems deployed in institutions align with democratic and public values.",
"failureMode": "Opaque systems make high-stakes decisions without accountability or recourse.",
"example": "Judges using closed-source risk scores with no explanation or audit."
}
]export const cards = [
{
"name": "xxx",
"definition": "xxx.",
"failureMode": "xxx.",
"example": "xxx."
}
]export const cards = [
{
"name": "Behavioral Alignment",
"definition": "Ensuring that an AI system behaves as the human would want it to behave.",
"failureMode": "The system takes actions that technically follow instructions but violate user intent.",
"example": "The boat AI spins in circles collecting points instead of racing to win."
},
{
"name": "Intent Alignment",
"definition": "Ensuring that the AI system’s behavior reflects the human’s intended goals.",
"failureMode": "The system optimizes for explicit instructions without inferring the underlying goal.",
"example": "Rewarding for score led the agent to maximize points, not race outcomes."
},
{
"name": "Specification Alignment",
"definition": "Ensuring that formal objectives (like reward functions) match true human goals.",
"failureMode": "The proxy (e.g. score) is easier to specify than the real objective (e.g. race performance).",
"example": "Amodei optimized for game score and got unintended, exploitative behavior."
},
{
"name": "Value Alignment",
"definition": "Ensuring that AI systems respect and reflect human moral values and norms.",
"failureMode": "The system produces outcomes that are statistically efficient but ethically harmful.",
"example": "COMPAS scores showed racial bias in criminal justice risk assessment."
},
{
"name": "Societal Alignment",
"definition": "Ensuring that AI systems deployed in institutions align with democratic and public values.",
"failureMode": "Opaque systems make high-stakes decisions without accountability or recourse.",
"example": "Judges using closed-source risk scores with no explanation or audit."
}
]https://tinyurl.com/alignmentCards1?user=djjr
export const cards = [
{
"name": "Behavioral Alignment",
"definition": "Ensuring that an AI system behaves as the human would want it to behave.",
"failureMode": "The system takes actions that technically follow instructions but violate user intent.",
"example": "The boat AI spins in circles collecting points instead of racing to win."
},
{
"name": "Intent Alignment",
"definition": "Ensuring that the AI system’s behavior reflects the human’s intended goals.",
"failureMode": "The system optimizes for explicit instructions without inferring the underlying goal.",
"example": "Rewarding for score led the agent to maximize points, not race outcomes."
},
{
"name": "Specification Alignment",
"definition": "Ensuring that formal objectives (like reward functions) match true human goals.",
"failureMode": "The proxy (e.g. score) is easier to specify than the real objective (e.g. race performance).",
"example": "Amodei optimized for game score and got unintended, exploitative behavior."
},
{
"name": "Value Alignment",
"definition": "Ensuring that AI systems respect and reflect human moral values and norms.",
"failureMode": "The system produces outcomes that are statistically efficient but ethically harmful.",
"example": "COMPAS scores showed racial bias in criminal justice risk assessment."
},
{
"name": "Societal Alignment",
"definition": "Ensuring that AI systems deployed in institutions align with democratic and public values.",
"failureMode": "Opaque systems make high-stakes decisions without accountability or recourse.",
"example": "Judges using closed-source risk scores with no explanation or audit."
}
]https://tinyurl.com/alignmentCards1?user=djjr