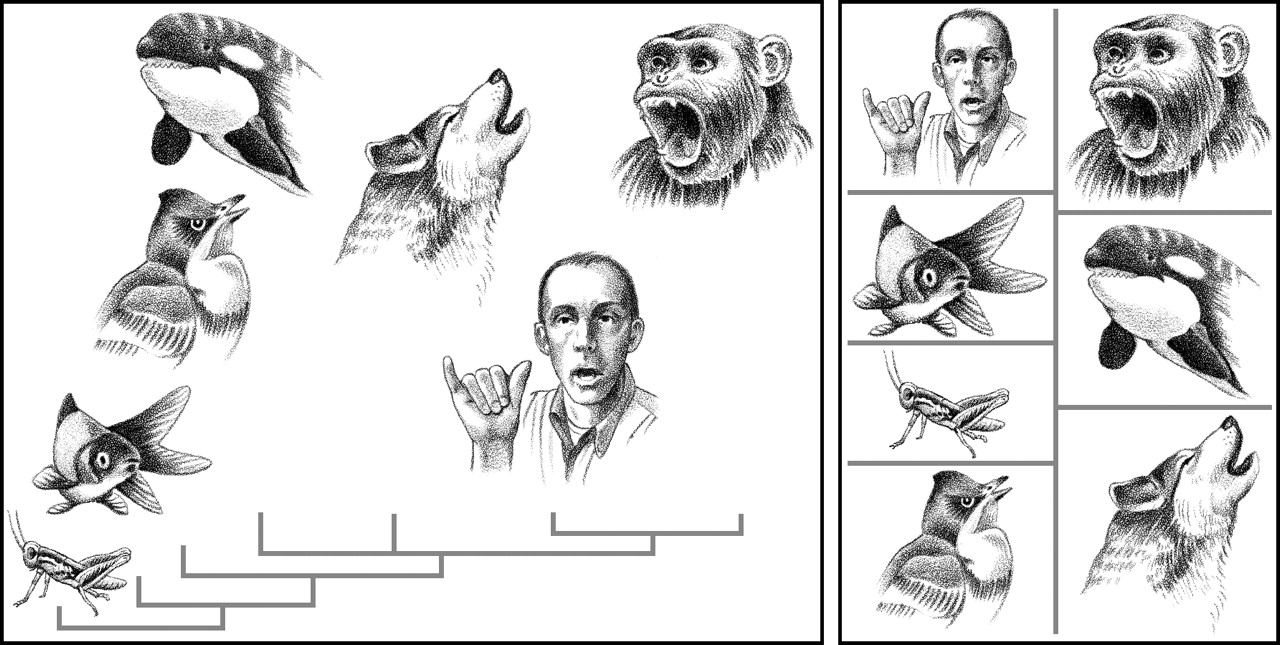
"If a martian graced our planet, it would be struck by one remarkable similarity among Earth's living creatures and a key difference."

Marc D. Hauser et al.,The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?. Science 298,1569-1579(2002).DOI:10.1126/science.298.5598.1569
kien
Concerning similarity, it would note that all living things ... [share a] ... universal language encoded in DNA base pairs.

Marc D. Hauser et al.,The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?. Science 298,1569-1579(2002).DOI:10.1126/science.298.5598.1569
In contrast, it would notice the absence of a universal code of communication
Marc D. Hauser et al.,The Faculty of Language: What Is It, Who Has It, and How Did It Evolve?. Science 298,1569-1579(2002).DOI:10.1126/science.298.5598.1569

Text embeddings are the technology we’ve built to fill that void, transforming our messy, fragmented words into a universal numerical landscape that machines can intuitively navigate.
Tokens & Embeddings: Text's Secret Code

Contents
- I ❤ strawberries
- Glitches & Quirks
- Vector Playground
- Next-Gen Magic
- Exit Ticket
01
I ❤ strawberries
How Does Your Text Become Math?
Let's use some "magic" to reveal the first step of how AI understands language.
Original Text
I ❤ strawberries
Tokenization ↓
[40, 1037, 21020, 219, 23633, 1012]
Every word, symbol, and even typo must be converted to numbers before the model can start "thinking."

Tokenization: Whole Words vs. Characters
Word-based Tokenization
Splits by spaces and punctuation—simple and intuitive.
Drawback: Huge vocabulary, can't handle new words or typos.

=> 1 million distinct words
Character-based Tokenization
Breaks text into individual characters, extremely small vocabulary.
Drawback: Sequences too long, loses semantics, low efficiency.
"unbelievable" is split into 12 characters, making it hard for the model to understand the overall meaning.
26 letters


min total number of unique tokens
min number of tokens per unit of meaning
Subword Tokenization: The key to intelligence
Balances efficiency and meaning by breaking words into meaningful "building blocks."
un + believ + able = unbelievable
common prefix + root + common suffix = complete word
This way, the vocabulary is small, fewer unknown words, and it can understand that "unbelievable" is composed of "un + believable."
02
Glitches & Quirks
The Strawberry Mystery: Why Can't AI Count?
Ask AI: "How many 'r's are in 'strawberry'?"
s-t-r-a-w-b-e-r-r-y, at a glance, 3.
['str', 'aw', 'berry'], original letter information is lost, can only guess.

03
Vector Playground
From Words to Coordinates: Entering Vector Space
Embedding encodes word meaning as an "address" in high-dimensional space—a vector.
King → [0.2, -0.5, 0.8, ..., 0.1]
(go up by 0.2, go right by -0.5,...)
In this space, words with similar meanings are closer together, and models understand relationships by calculating "distance."

LET'S TRAVEL INTO THE SPACE OF MEANINGS!!
The Magic of Embeddings: Word Vector Arithmetic
King - Man + Woman = Queen
Embeddings not only encode word meaning but also relationships.
Through vector addition and subtraction, we can explore analogies and logic in language.
LET'S TRAVEL INTO THE SPACE OF MEANINGS!!
04
Next-Gen Magic
“You shall know a word by the company it keeps”
(J. R. Firth 1957: 11)


This is of the most successful ideas of modern NLP!
Upgraded Embeddings: Context-Aware
Early embeddings were static—one word, one vector.
Modern models (like BERT) can dynamically adjust word meaning based on context.
"I need to open an account at the bank."
→ Vector points to "financial institution"
"We're having a picnic by the bank."
→ Vector points to "riverbank"


Upgraded Embeddings: Context-Aware
Early embeddings were static—one word, one vector.
Modern models (like BERT) can dynamically adjust word meaning based on context.
The same word "bank" gets different vector representations in different contexts, allowing the model to truly understand its meaning.

Embeddings Beyond Text: Going Cross-Domain
Embedding technology has expanded beyond text—any data can be encoded as vectors.
🖼️ Images
Through models like CLIP, images and text can be mapped to the same vector space, enabling "search images with text."
🎵 Audio
Spotify uses it for music recommendations.
🛒 Products
Amazon uses it for product recommendations.


05
Takeaways
Interactive Time: Create Your Own Word Vector Equation
Challenge: Try to find your own word vector relationship!
$$\text{Sushi} - \text{Japan} + \text{Italy} = \text{Pizza}$$
$$\text{Harvard} - \text{Grade inflation} + \text{Lacrosse} = \text{JHU}$$
$$\text{Washington D.C.} - \text{Suits} + \text{Sweatpants} = \text{Baltimore}$$
Summary: Tokenize, Embed, Understand
This is the secret trilogy of how AI understands language:
-
Tokenize
Break text into small chunks the model can process. -
Embed
Convert tokens into vectors in high-dimensional space. -
Understand
Understand semantics through vector operations and model reasoning.
Next time you see "strawberries," you'll know it's just a string of mysterious code in the AI world.