Patterns
Patterns
https://slides.com/djjr/patterns
Playlist for Patterns
Notes (Google drive)
Image Gallery
Resources
What to Learn
Read


Chapter in Eloquent JavaScript
Define "pattern"


Discuss & Combine
A pattern is a regularity in the world, in human-made design, or in abstract ideas. As such, the elements of a pattern repeat in a predictable manner. Any of the senses may directly observe patterns.
-Wikipedia
Fun with Patterns
are
SEE ALSO
Tiles
Fun


See Also
Truchet Tiles
...are square tiles with patterns that are rotationally asymmetric. The plane can be tiled with them in different orientations to form wildly varied patterns.


Escher Tiles

Tiles


From Creating to Recognizing
PATTERN

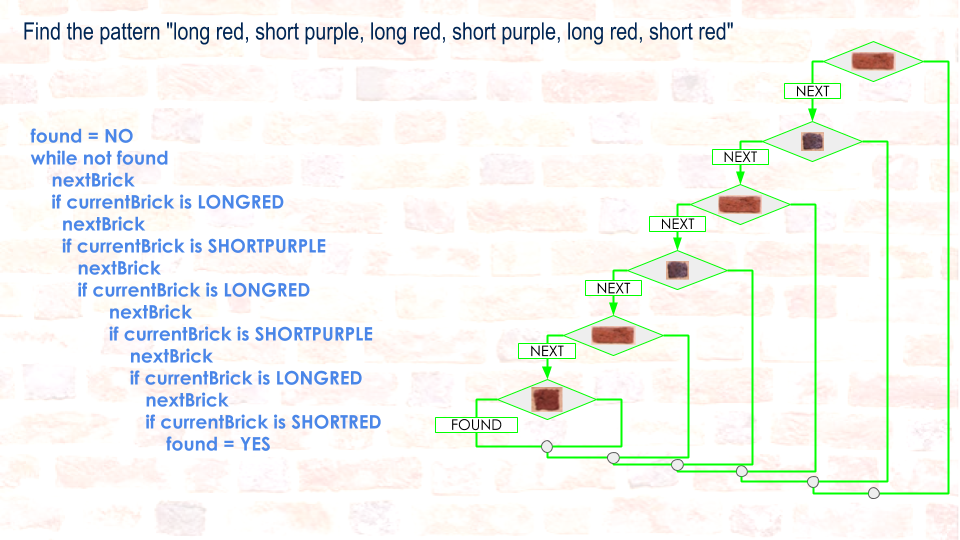
Pseudocode and Flowchart Approach to Pattern Recognition
For a different six brick pattern the flow would be the same, but the conditions in each diamond would be different...
function find (pattern, inWhat){
return found (t/f) & location
}
imagine a function definition
abstract to a black box
pattern
in what?
found?
location
r R r R R R R R
R R p P p R p R p
R p r R r R p R p R
p p R p R p R p R p
R p R p R p R p R
R p R p R r R r R r
r R p R r R r R r R
R p R r R p R r R p
p R p R p R p R r R
R p R r R p R p R p
R r p R r R p R p
r p R p R r R p R
function search
get the pattern
get the inWhat text
call find(pattern, inWhat)
print results
function find (p,t)
loop over entire text
note current start
//attempt match from here
loop from start up to length of pattern
if char no match next quit attempt
look at next character
if length of pattern reached
match=TRUE
note location
next start of attempted match
i < t.length?
i =0
scan from t[i]
i++
report
start=i
j=0
j < p.length?
t[start+j]==p[j]?
j++
j=p.length+1
j=p.length?
match!
i < t.length?
i =0
scan from t[i]
i++
report
start=i
j=0
j < p.length?
t[start+j]==p[j]?
j++
j=p.length+1
j=p.length?
match!
But also, sometimes, choice, and flexibility.
Patterns are about sequence and repetition.
one black square followed by zero to three pairs of orange squares
STOP+THINK:
What's the pattern?
judgment
lodgment
acknowledgment
queue
blagueur
liqueur

555 432 1234
555-432-1234
(555)432-1234
(555) 432-1234
555.432.1234
What are some words in English that contain the sequence dgm or ueu?
Are these valid phone numbers?
Does your password meet these criteria?
Sometimes we want to use patterns to find things and sometimes we want to use patterns to constrain things.
5554321234
555-432-1234
(555)432-1234
(555) 432-1234
555.432.1234
555 432 1234
WANTED: An easy to use notation to describe any pattern in text
1 Specify SETS of characters
Introduce Notation:
Square brackets around a set to say "one of these"
[0123456789] means "a digit"
Introduce Notation:
A dash means "all the characters in between"
[0-9] means "a digit"
3
digits
2
digits
digit except 0,1
4
digits
2. Specify REPETITION
Introduce Notation:
Number in curly brackets means repeat
[0-9]{3} means "3 digits"
Introduce Notation:
Two numbers in {} means "at least" and "at most".
[0-9]{2,5} means at least 2 and at most 5 digits
3
digits
2
digits
digit except 0,1
4
digits
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[2-9]
[0-9]{3,} means at least 3 digits
[0-9]{,5} means up to 5 digits
[2-9]
[0-9]{2}
[0-9]{3}
[0-9]{4}
STOP+THINK
Match
[A-Z]{4}
[A-Z][a-z]{3}
([A-Z][a-z]{,6} ){2,3}
four letter upper case words
four letter words
[a-z]{4}
four letter words with initial cap
full names with each component up to 7 letters and two or three components
STOP+THINK
Dino Valenti
Roy j Sims
([A-Z][a-z]{,6} ){2,3}
Franklin D Rooster
A Malick Obrien
Anna
Dino Valentino
Shorthand for [0-9] is \d
that is \d means "any digit"
Shorthand
"backslash d"
\t matches a tab
\n matches a new line
\r matches carriage return
\f matches a page break
\s matches all of these and SPACE
And...
\s = [ \t \n \r \f]
adding a backslash is called "escaping" because it allows a character to "escape" being interpreted by RegEx as it usually would be.
Specify OPTIONS and ALTERNATIVES
How to match 555 432 1234 OR 5554321234
[2-9][0-9]{2}(\s|-)?[0-9]{3}(\s|-)?[0-9]{4}
[2-9][0-9]{2}\s[0-9]{3}\s[0-9]{4}
STOP+THINK
[2-9][0-9]{2}[0-9]{3}[0-9]{4}
[2-9][0-9]{2}\s?[0-9]{3}\s?[0-9]{4}
notation: y? means 0 or 1 pattern y
notation: (x|y) means pattern x or pattern y
STOP+THINK
How about 555-432-1234 too?
REVIEW CHARACTER SETS
Patterns are defined by sets of characters
[a-z]
[abc]
[0-9a-f]
[A-z]
denotes any character from ASCII 'a' to ASCII 'z'. The hyphen indicates a range.
denotes any of the characters 'a', 'b', or 'c'
denotes characters used for hexadecimal numbers. To be strict use [0-9a-fA-F].A-z] 'A' is hex 41, 'Z' is hex 5A. 'a' is hex k and 'z' is hex l. The characters in between are [ \ ] ^ _ `
Examples
[A-Fa-f]
[^AEIOUaeiou]
[02468]
hex characters
English consonants
Even digits
Summary So Far
[a-z] is a range of characters
? means zero or one of the preceding
{m,n} specifies numbers of repetitions of preceding
\s, \d
3. Specify Boundaries
STOP+THINK
What if I want to only match a pattern at the beginning or end of a word?
Find "abc" in "abcarnia" and "jabc" but not "mabcam"
notation: \b means a word boundary
\babc matches "abcarnia" but not "jabc" and "mabcam"
abc\b matches "jabc" but not "abcarnia" and "mabcam"
[2-9]\d{2}(\s|-)? \d{3}(\s|-)?\d{4}
exactly 2 of these
0 or 1 of these
any digit
space or dash
0 or 1 of these
exactly 4 of these
any digit except 0,1
any digit
space or dash
exactly 3 of these
any digit
Stop + Think
US postal codes (zipcodes) can be either 5 digits or 9 digits with a dash separating the two groups. Which expression describes this pattern?
\d{5}-\d{4}
5 digits required
optional hypen
optional 4 digits
\d{5}(-\d{4})?
\d{5}-?(\d{4})?
\d{9}
Stop + Think
US postal codes (zipcodes) can be either 5 digits or 9 digits with a dash separating the two groups. Which expression describes this pattern?
\d{9}
\d{5}-\d{4}
\d{5}(-\d{4})?
\d{5}-?(\d{4})?
missing dash
could have dash without +4 or +4 without dash
no option for only 5
Stop + Think
Sometimes my ego gets the best of me and I want to search for my name in a document. But sometimes I am referred to by different forms of my name. I want to find Dan Ryan, Daniel Ryan, Danny Ryan, Dan J Ryan, Dan J Ryan Jr, and all the various combinations of these.
Dan(iel|ny)?\sJ?\sRyan\sJr?
Dan(iel|ny)?J?RyanJr?
Dan(iel|ny)?(\sJ)?\sRyan(\sJr)?
Dan(iel|ny)\sJ\sRyan\sJr
Stop + Think
Sometimes my ego gets the best of me and I want to search for my name in a document. But sometimes I am referred to by different forms of my name. I want to find Dan Ryan, Daniel Ryan, Danny Ryan, Dan J Ryan, Dan J Ryan Jr, and all the various combinations of these.
Dan(iel|ny)?\sJ?\sRyan\sJr?
Dan(iel|ny)?J?RyanJr?
Dan(iel|ny)?(\sJ)?\sRyan(\sJr)?
Dan(iel|ny)\sJ\sRyan\sJr
? only applies to "r"
? only applies to "J" so we get 2 spaces
no spaces
missing ?s no option to omit
Regular Expressions
aka
REGEX
A regular expression is a description of a linear textual pattern using a well-defined syntax
RegEx in JS
Constructing Regular Expressions

regular expression literal
call the constructor function
let re = /ab+c/;
let re = new RegExp('ab+c');
Anatomy of Regular Expressions
abc
\d ... any digit
\D ... any character that is not a digit
\w ... any character that can be in a word
\W ... any character that is not a word character
\s ... any single white space character
\S ... a single character other than white space
simple pattern
flags
x|y ... x or y
[xyz] ... x, y, or z
[x-z] ... character from x to z
[^xyz] ... not one of x, y, z
[^x-z] ... not character from x to z
(x) ... recognize X and remember
x? ... zero or 1 x
x+ ... one or more x
x* ... zero or more x
x{m} ... m x's
x{m,n} ... at least m, at most n, x's
x{,n} ... at most n x's
^ ... start of input
$ ... end of input
\b ... word boundary
\B ... not word boundary
x(?=y) ... x if followed by y
x(?!y) ... x if not followed by y
(?<=y)x ... x preceded by y
(?<!y)x ... x not preceded by y
i ... ignore case
g ... global (all matches)
m ... multiline
escaping
to use a special character literally (actually searching for a "*", for instance), "escape" it by putting a backslash in front of it
FLAGS
i ... ignore case
g ... global (all matches)
m ... multiline
^ ... start of input
$ ... end of input
x? ... zero or 1 x
x+ ... one or more x
x* ... zero or more x
[^xyz] ... not one of x, y, z
[^x-z] ... not character from
upper case shortcut means NOT
Simple Text Hightlighter STUB (https://codepen.io/djjrjr/pen/rNYLmMY)
Insider's Tip: An hour or two on a RegEx Tutorial or two will make you a solid beginner.
A second and third session and a little practice can make you an expert.
But you'll always have to look stuff up.
RegEx stepwise: GROUPS
Patterns are defined in terms of groups
([A-Za-z][0-9][A-Za-z])( +)([0-9][A-Za-z][0-9])
This pattern has three groups
- letter-digit-letter
- one or more spaces
- digit-letter-digit
RegEx stepwise: GROUPS
([A-Za-z][0-9][A-Za-z]) ( +) ([0-9][A-Za-z][0-9])
group 1 group 2 group 3
Quantifiers
Sidebar on greedy and lazy operators
const modifiedQuote = 'but [he] ha[s] to go read this novel [Alice in Wonderland].';
const regexpModifications = /\[.*\]/g; //or \[.*?\]
The pattern has three parts:
\[
.*
\]
Parts 1 and 3 can match only a single character. But part two can "consume" any number of characters, as long as it keeps matching. In this case, the star modifies a period which matches any character. How would this proceed?
Read b and try to match part1 of pattern. Fail.
Read u and try to match part1 of pattern. Fail.
Read t and try to match part1 of pattern. Fail.
Read SP and try to match part1 of pattern. Fail.
Read [ and try to match part1 of pattern. Succeed. Part1 is now exhausted.
Read h and try to match part2 of pattern. Succeed. Part2 still in play.
continues until $ end of input which no longer matches part2 so part2 exhausts and we go to part3
$ is no match for part3 so we back track and examine .
. is no match so we back track to ]
] is a match so Part3 is exhausted
No more parts to pattern so pattern is matched
What is the alternative? Instead of continuing to chomp on the input until it no longer could, part2 of the pattern could "look ahead" and ask whether the next input token would match part3 and if so then it could relinquish control and allow the pattern match to continue with the part3.
How does the ? accomplish this? It switches the * to "lazy mode." In other words, *? is, in a sense, a different quantifier than * by itself. Similarly we have +? and ?? which are lazy versions of + and ?.
See: "Greedy and lazy quantifiers"
Sidebar on greedy and lazy operators
See: "Greedy and lazy quantifiers"
A greedy quantifier continues to consume input until it cannot.
A lazy quantifier yields to the next part of the pattern as soon as it can.
Groups & Ranges
Character Classes
Assertions
Using Regular Expressions
RegExp.exec(String)
RegExp.test(String)
"execute" this regular expression on String. Returns array with match as first element [0]
executes a search for a match between a RegExp in String. Returns true or false.
Using Regular Expressions
RegExp.methods()
String.methods()
RegEx Use Cases
Give STR the "full treatment" of PATTERN? use RegExp.exec(STR)
Does STR match PATTERN? use RegExp.prototype.test(STR)
Find location of PATTERN in STR? use String.prototype.search(PATTERN)
exec
test
match
search
replace
split
EXTRAS
HTML TEXT BOX Multiple word changes
Outline
Chapter 4: Applications
Chapter 3: Getting Fancy
Chapter 2: Reverse engineering patterns - regex 101
Chapter 1: Fun with Patterns - Bricks, Tiles, and Why
WHY?
Pattern Generation/Recognition
- Last Week: iteration can produce complex patterns
- This Week: can iteration recognize complex patterns
- Why?
- Science: pattern suggests process
- Intervention: pattern suggests condition
- x: pattern suggests identity
- y: pattern suggests category
Pattern Generation/Recognition
Science: pattern → process
We look for patterns in phenomena - this tends to occur near that, after that, before that - on the assumption that things cause things and that things can be detected directly even if causing cannot.
Pattern Generation/Recognition
Intervention: pattern → condition
Decisions to intervene depend on an assessment of conditions but the condition may be an abstraction based on complex arrays of indicators. Is this a heart attack or just indigestion? Do these diplomatic moves suggest truce or a new offensive? Does this internet chatter suggest a terrorist plot? Does this set of covid data suggest a third wave?
Pattern Generation/Recognition
x: pattern → identity
Unique (or effectively unique) patterns can be used to identify unique entities. DNA matching is the obvious example from TV crime shows, facial recognition from contemporary conversations about AI.
Pattern Generation/Recognition
y: pattern → category
Sometimes things that are not identical are never the less considered to be members of the same category. In natural language processing, for example, we might want to stem words in a text. Or we might want to identify all sentences that have a prepositional phrase in them.
Check In...
Check In...
Reverse engineering patterns - regex 101
Chapter in Eloquent JavaScript
RegEx by Stepwise Refinement
RegEx by Stepwise Refinement
To invert a set of characters, that is, to match any character except, write a caret (^) inside the first bracket.
[^a-z]
[^0-9]
denotes not a lower case letter
denotes not a digit
RegEx by Stepwise Refinement
Common character sets have shorthand
\d any digit character \D any character that is not a digit \w any alphanumeric character (“word character”) \W any nonalphanumeric character \s any whitespace character (space, tab, etc.) \S any non-whitespace character . any character except for newline*
* Note: $ matches the end of the line, not the newline character which comes after the end of the line.
RegEx stepwise: REPETITION
Patterns are defined by repetition
[a-z]?
[a-z]*
[a-z]+
[a-z]{3}
[a-z]{3,5}
zero or one lower case letter
zero or more lower case letters
one or more lower case letters
three lower case letters
three to five lower case letters
Examples: REPETITION
[0-9]{3}[0-9]{3}[0-9]{3}
[0-9]{9}
[0-9]{4}[0-9]{2}[0-9]{3}
3 ways to specify a nine digit number
STOP+THINK
A Canadian social insurance number has 9 digits - three groups of three separated by hyphens. A temporary SIN starts with a nine. Create regex that will recognize:
- any SIN
- permanent SIN
- temporary SIN
Examples: REPETITION
[A-Z]?[a-z]*
[0-9]{3}-[0-9]{3}-[0-9]{3}
9[0-9]{2}-[0-9]{3}-[0-9]{3}
[0-8][0-9]{2}-[0-9]{3}-[0-9]{3}
any word, including ''
Canadian S.I.N.
Temporary S.I.N.
Permanent S.I.N.
STOP+THINK
STOP+THINK
RegEx Stepwise: BOUNDARIES
Patterns can be attached to boundaries
Text
Examples
Start of line, end of line
start of word, end of word
RegEx Stepwise: CHOICES
Patterns can contain options
\.(com|ca|edu|org|biz|tv)
asdf
Check In...
Check In...
Chapter 3: Getting Fancy with JS
RegEx in JS: Basics
- In JS a regular expression is a special kind of object
- Can be created in two ways
- Specify by a string using RegExp constructor
- Specify as literal between forward slashes
RegEx in JS: References
References TAG=javascript AND regex
What can RegEx Objects Do?
- test whether a string contains a match
- create an array of matches
- do things to each match
RegEx in JS
REGEX.test(string)
returns true if the pattern is found, false if not
RegEx in JS
REGEX.test(string)
Experiment with boundaries:
\b word, start of line ^, end of line $
RegEx in JS
REGEX.exec(string)
return the matching substring and position as "index"
RegEx by Stepwise Refinement
JavaScript
REGEX.exec(string)
exec can be used repeatedly if the "g" flag is on in the regular expression
RegEx by Stepwise Refinement
JavaScript
REGEX.exec(string)
if regex has groups, exec returns matches to each one in the array
SO FAR
How to create a regex object (literally or with "new"
regex.test(STRING) returns true or false
regex.exec(STRING) returns the matching substring(s) and location
Extra : FLAGS
/regex/gm
- i : search is case-insensitive: no difference between A and a.
- g : search looks for all matches, without it – only the first match is returned.
- m : Multiline mode.
Also, but outside our current view:
- s : Enables “dotall” mode, that allows a dot . to match newline character \n.
- u : Enables full unicode support.
- y : “Sticky” mode: searching at the exact position in the text
RegEx in JS
string.match(REGEX)
/g returns array of matches
no g returns matches by groups
Mini Data Cleaner
Check In...
Check In...
Applications
RegEx in MS Word
sort of
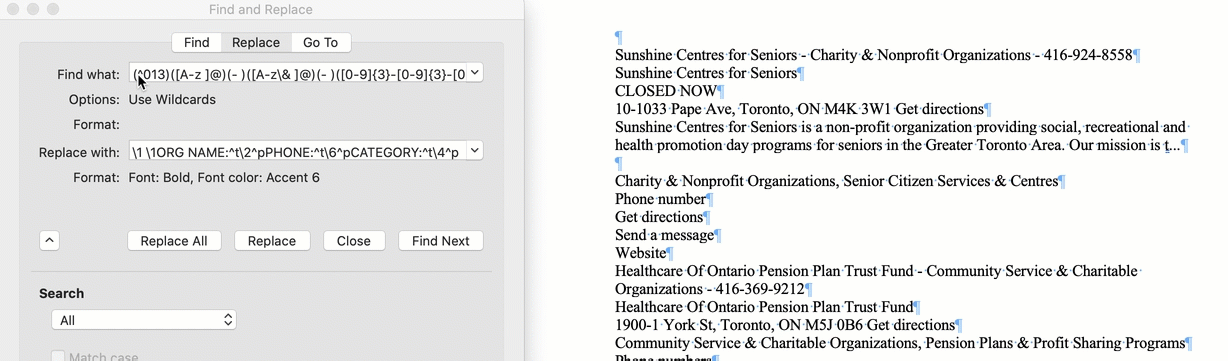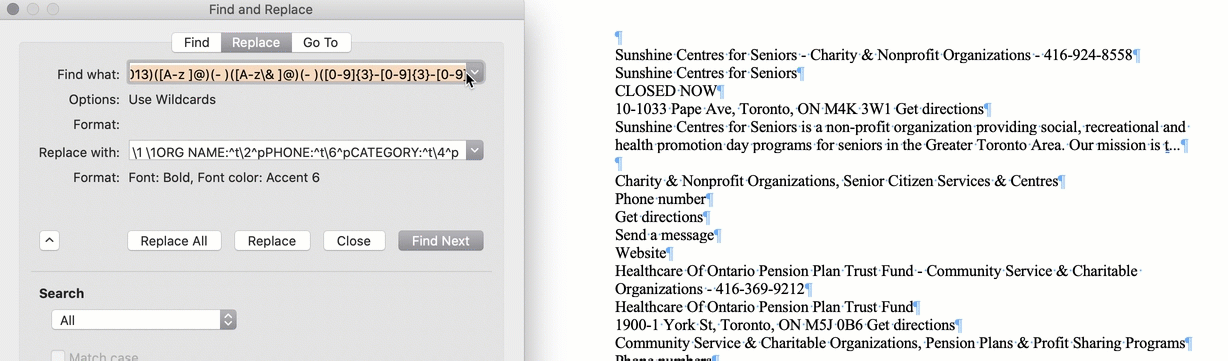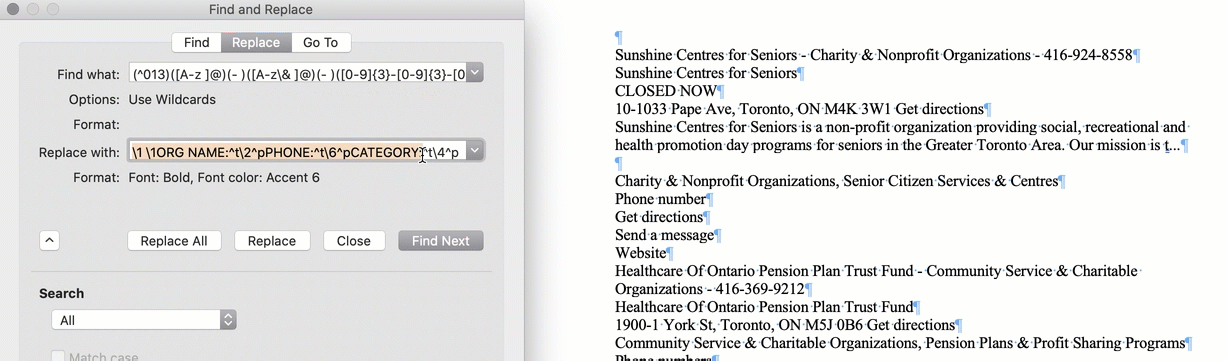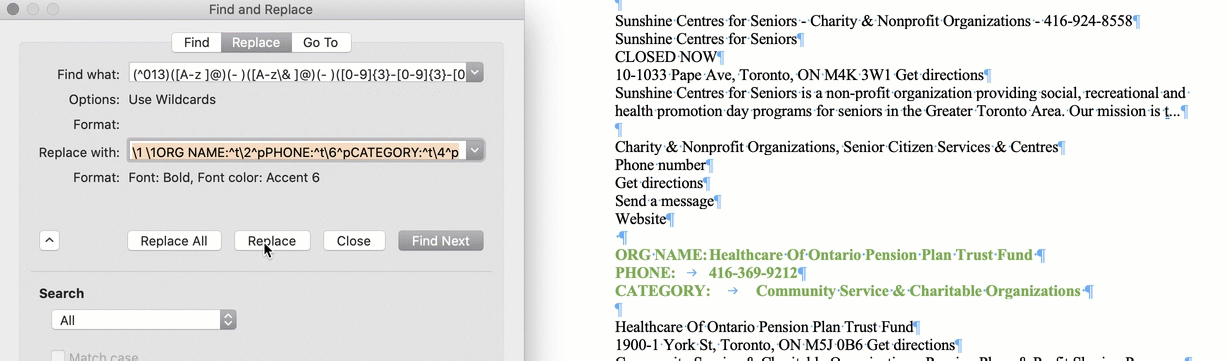
MS Word's "RegEx" = Wildcards
-
? is used to Represent a single character and * represents any number of characters.!
-
@ is used to find one or more occurrences of the previous character. For example, lo@t will find lot or loot, ful@ will find ful or full etc.
-
< and > to mark the start and end of a word, respectively.
-
Square brackets are always used in pairs and are used to identify specific characters or ranges of characters.
-
\ is used to "escape" characters that have special meaning in wild cards
-
[!] finds any character not listed in the box
-
Curly brackets are used for counting occurrences.
-
{n} finds exactly “n” occurrences.
-
{n,} finds at least the number “n” occurrences.
-
{n,m} finds between “n” and “m” occurrences.
-
Word Wildcards
See Also
RegEx in MS Excel
sort of
See Also
RegEx Golf

Example: find prepositional phrases
Check In...
See Also (patterns)
OutTakes
From Scraped Text to Clean Data
- records and fields
- csv & tsv & fixed column formats