Fondamentaux du deep learning
Contenu tiré de l'excellent cours du MIT
MIT 6.S191: Introduction to Deep Learning
© Alexander Amini and Ava Soleimany

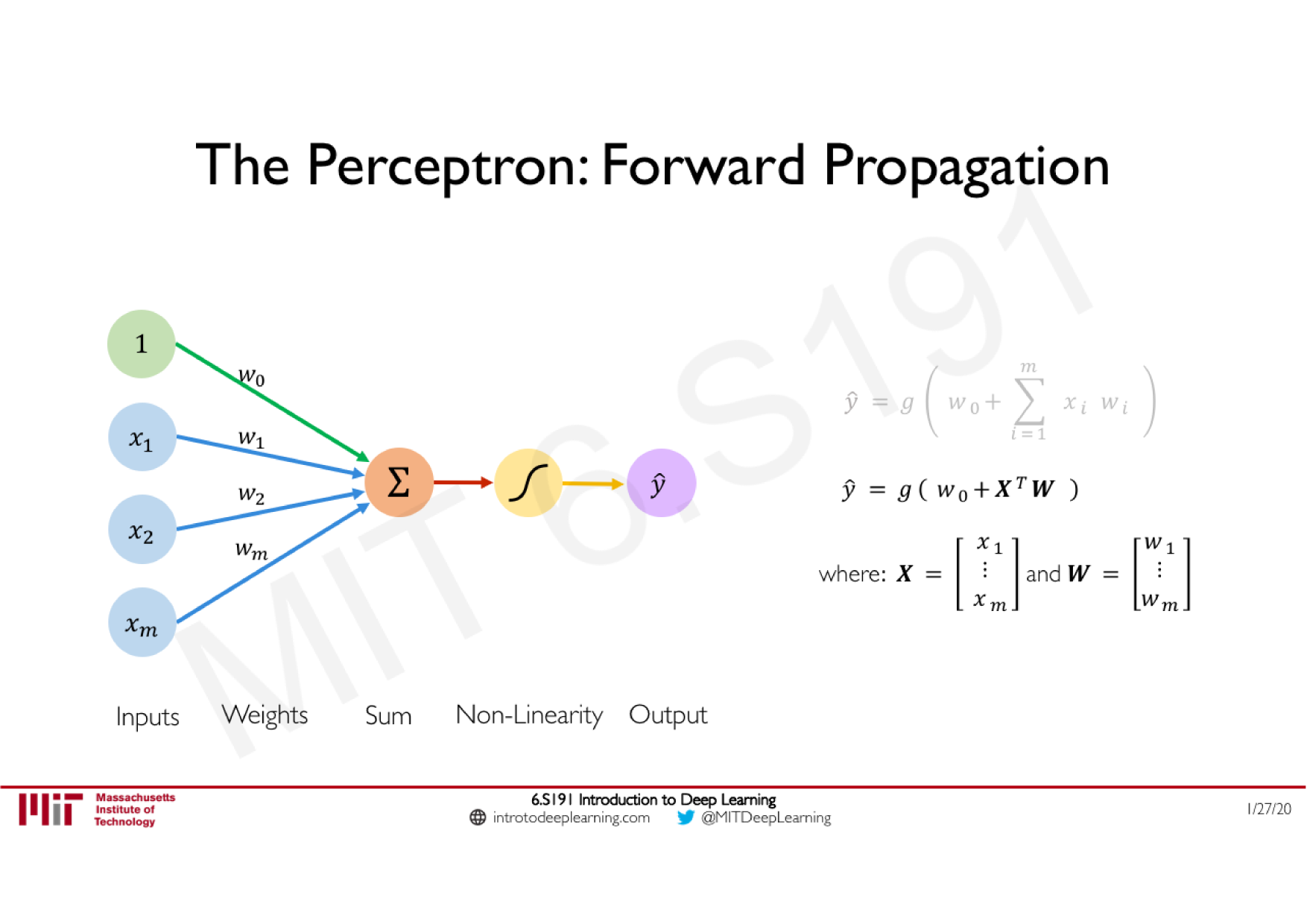
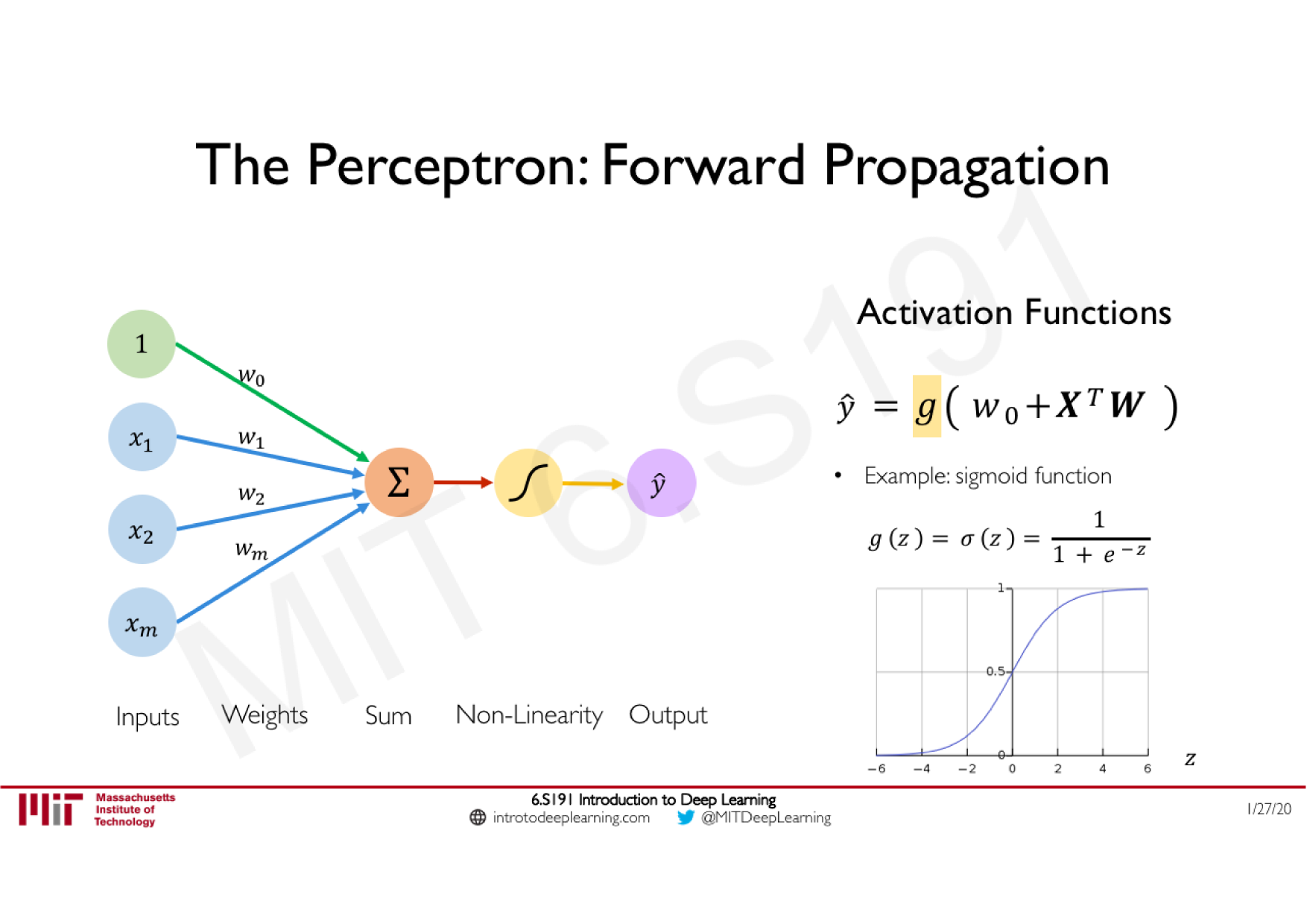
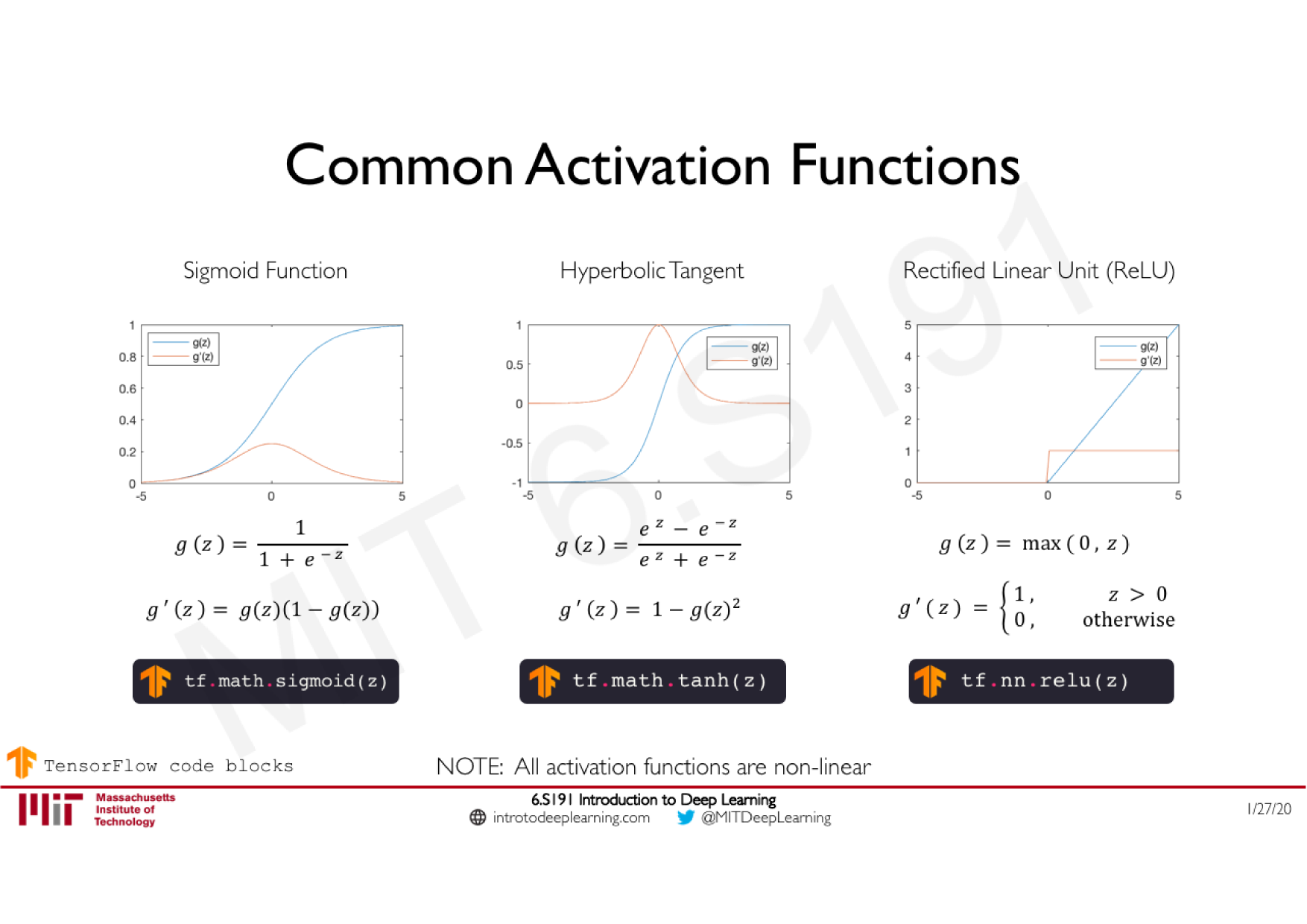


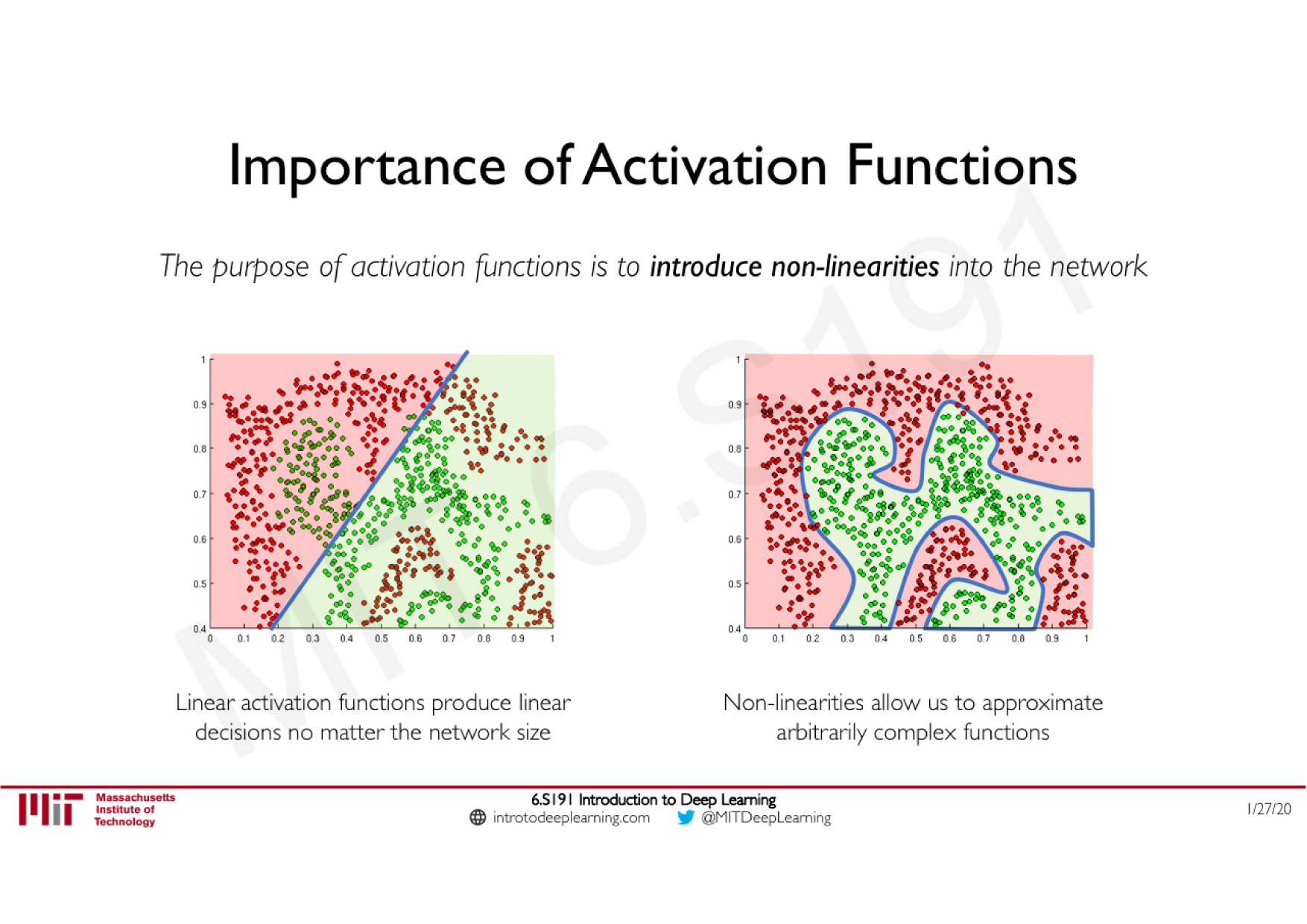

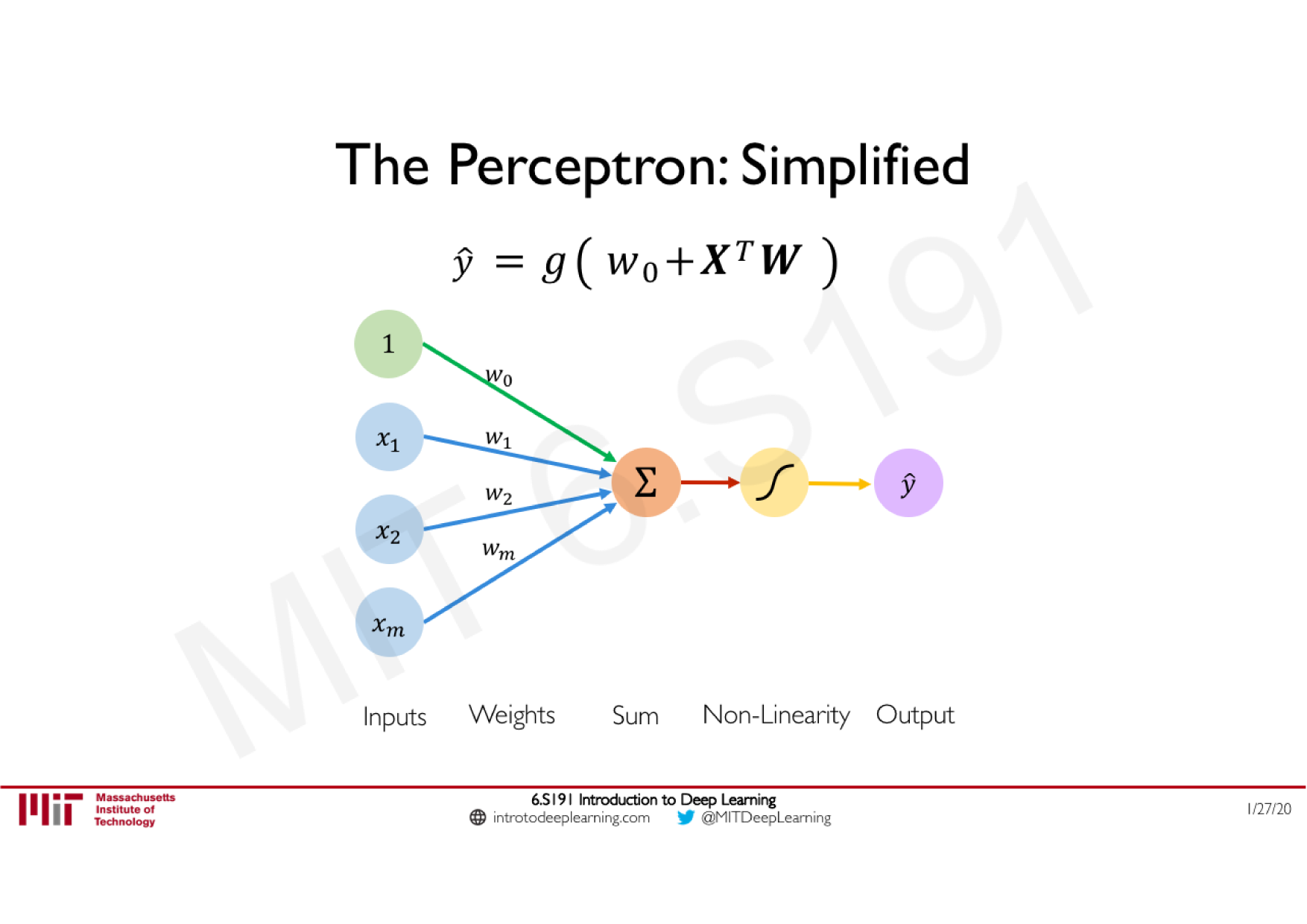
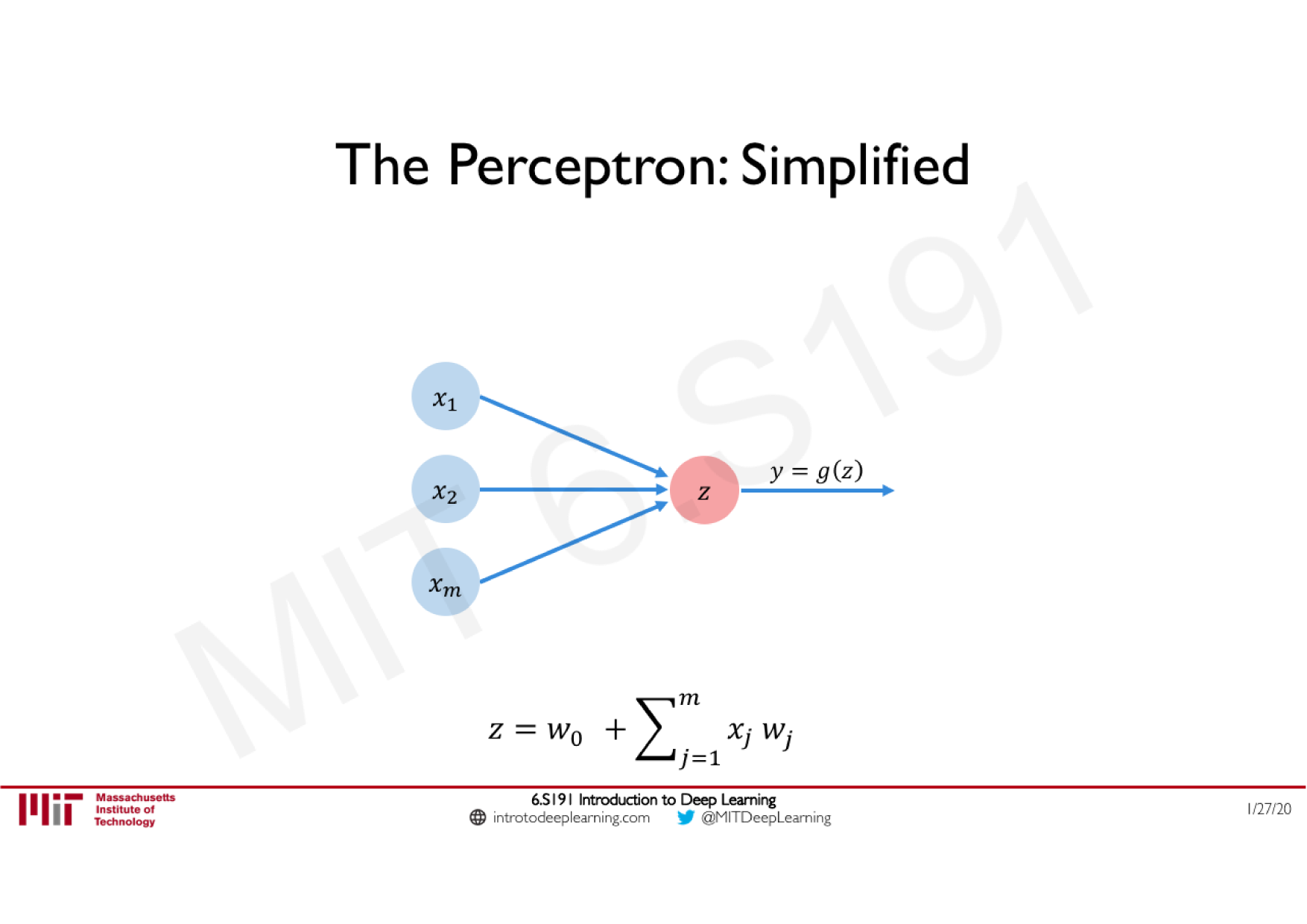
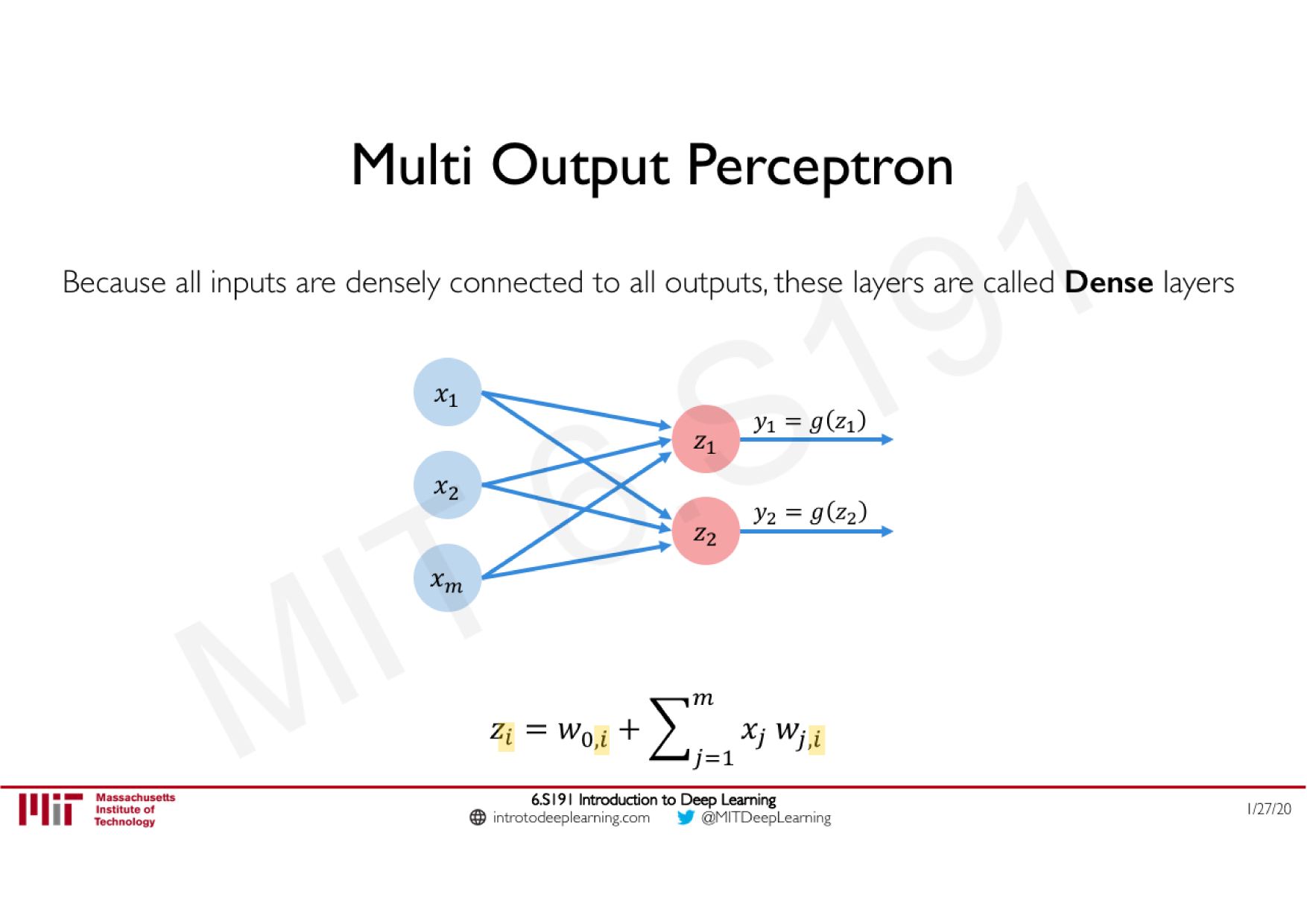

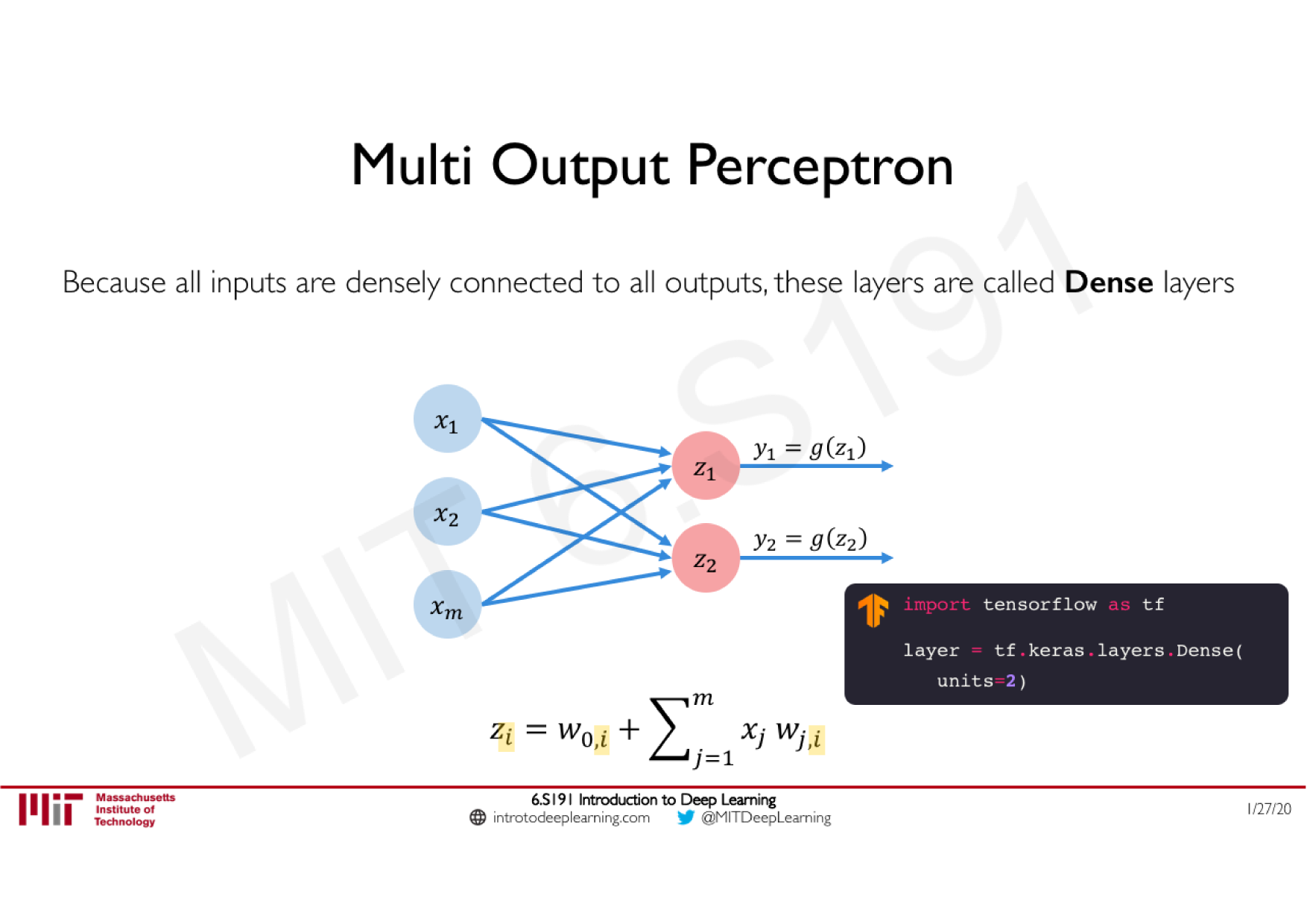
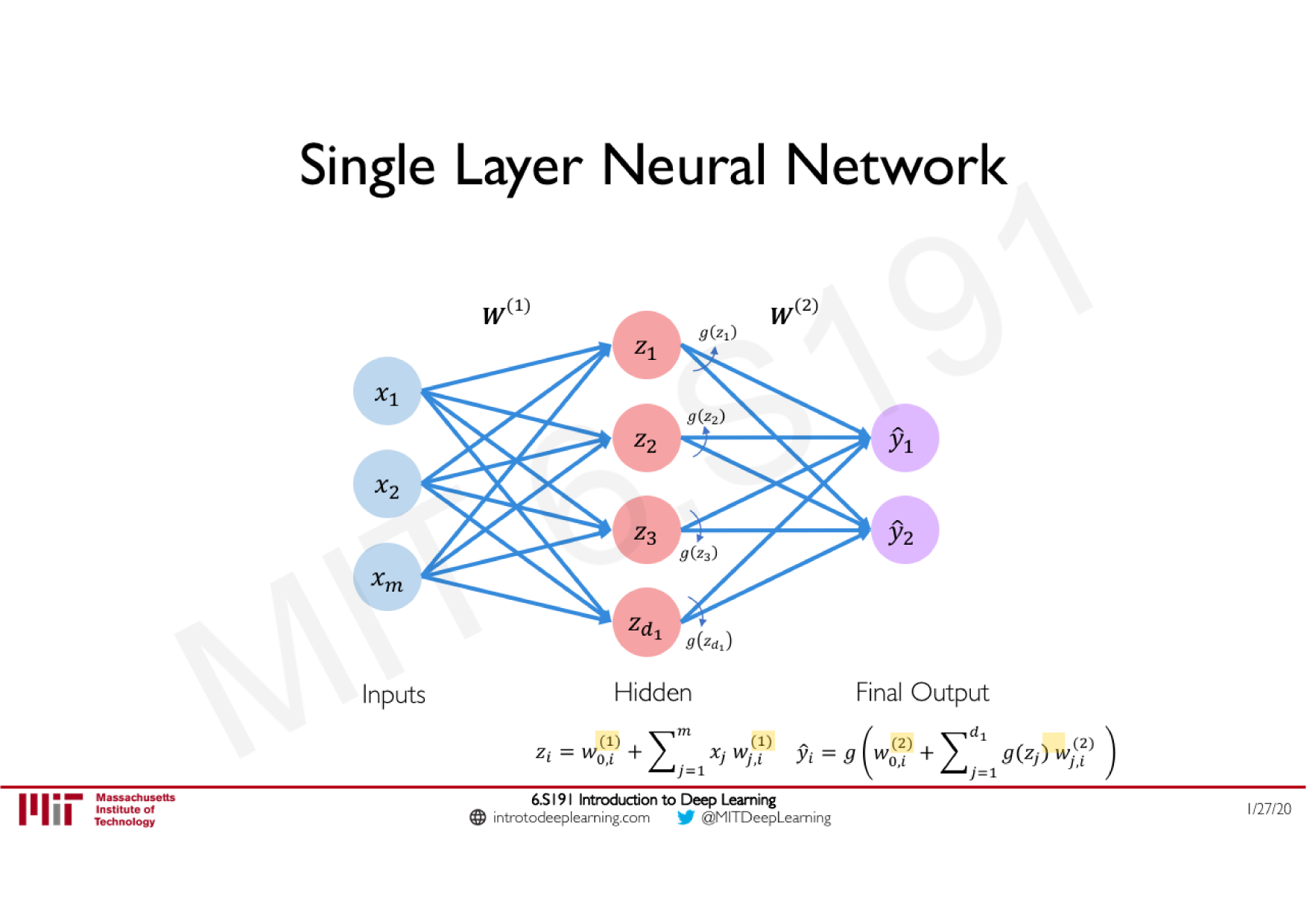
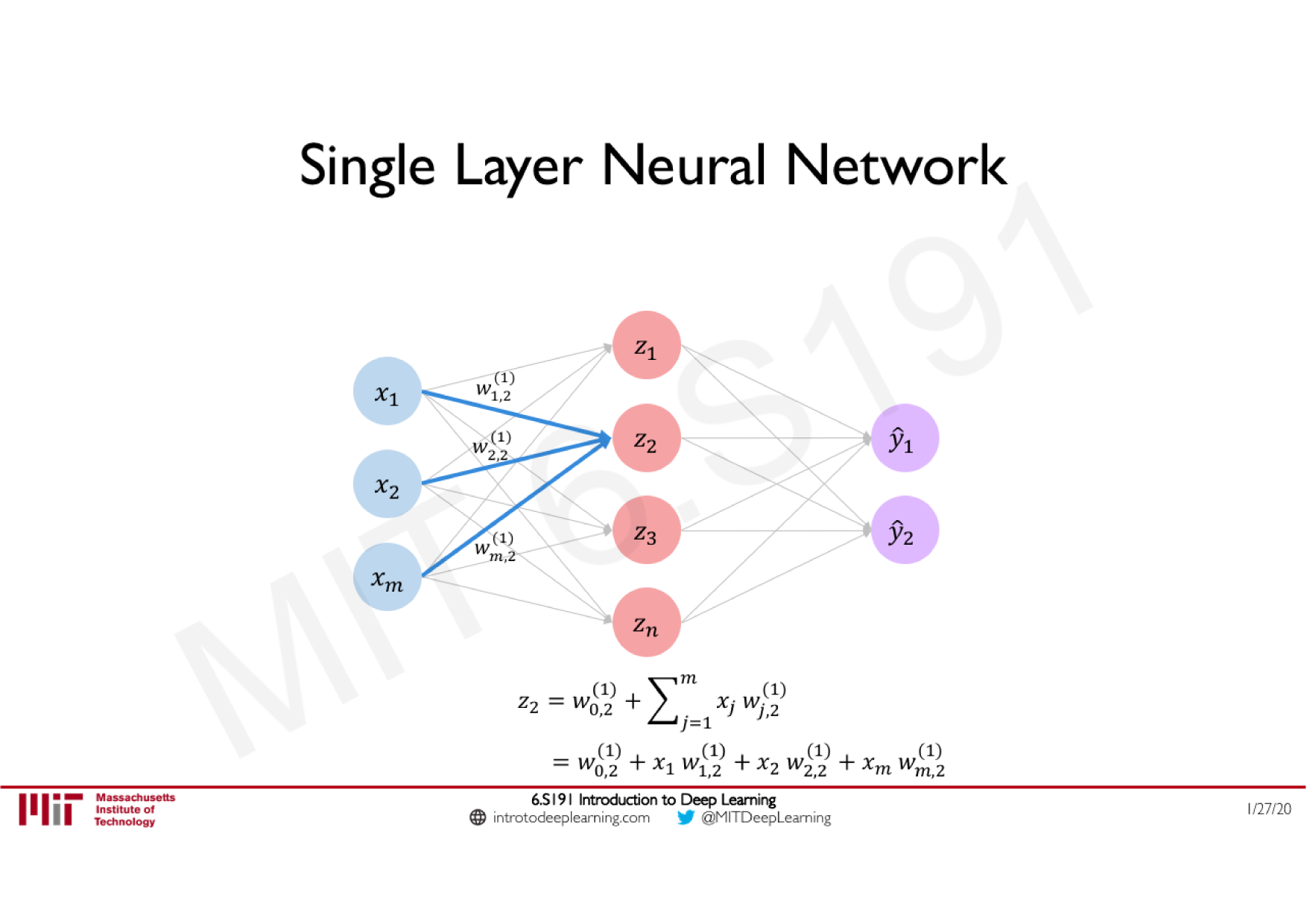
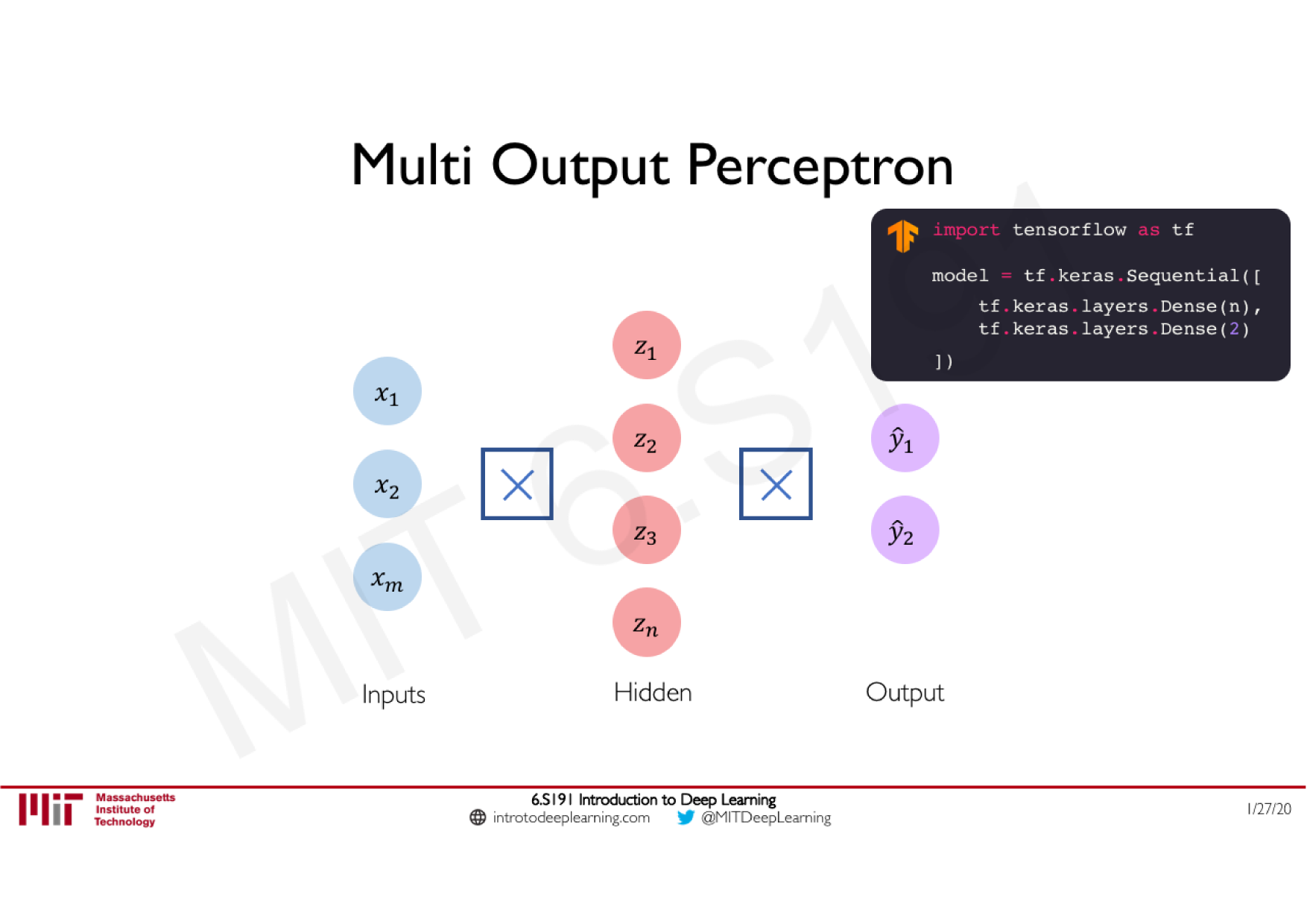
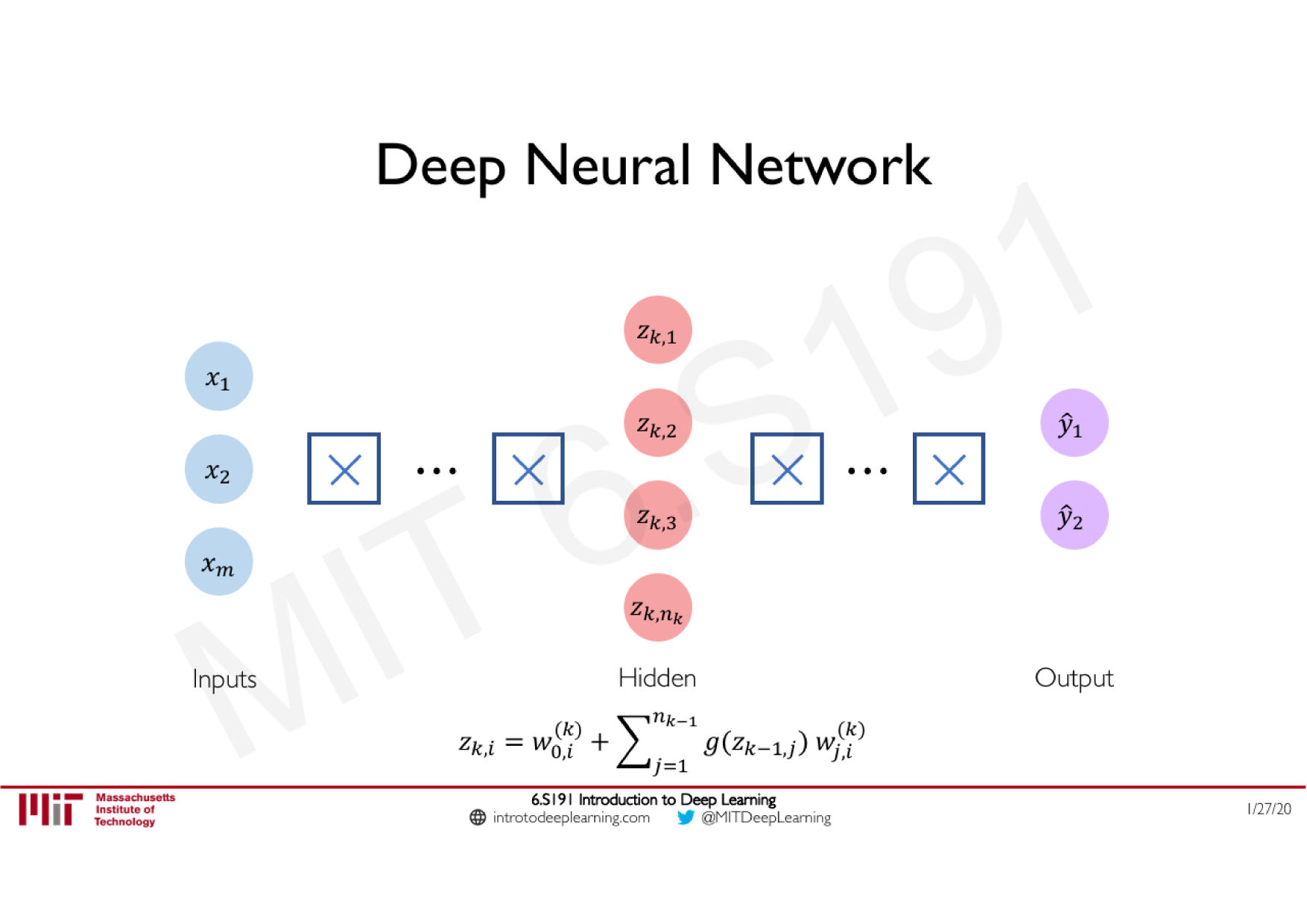
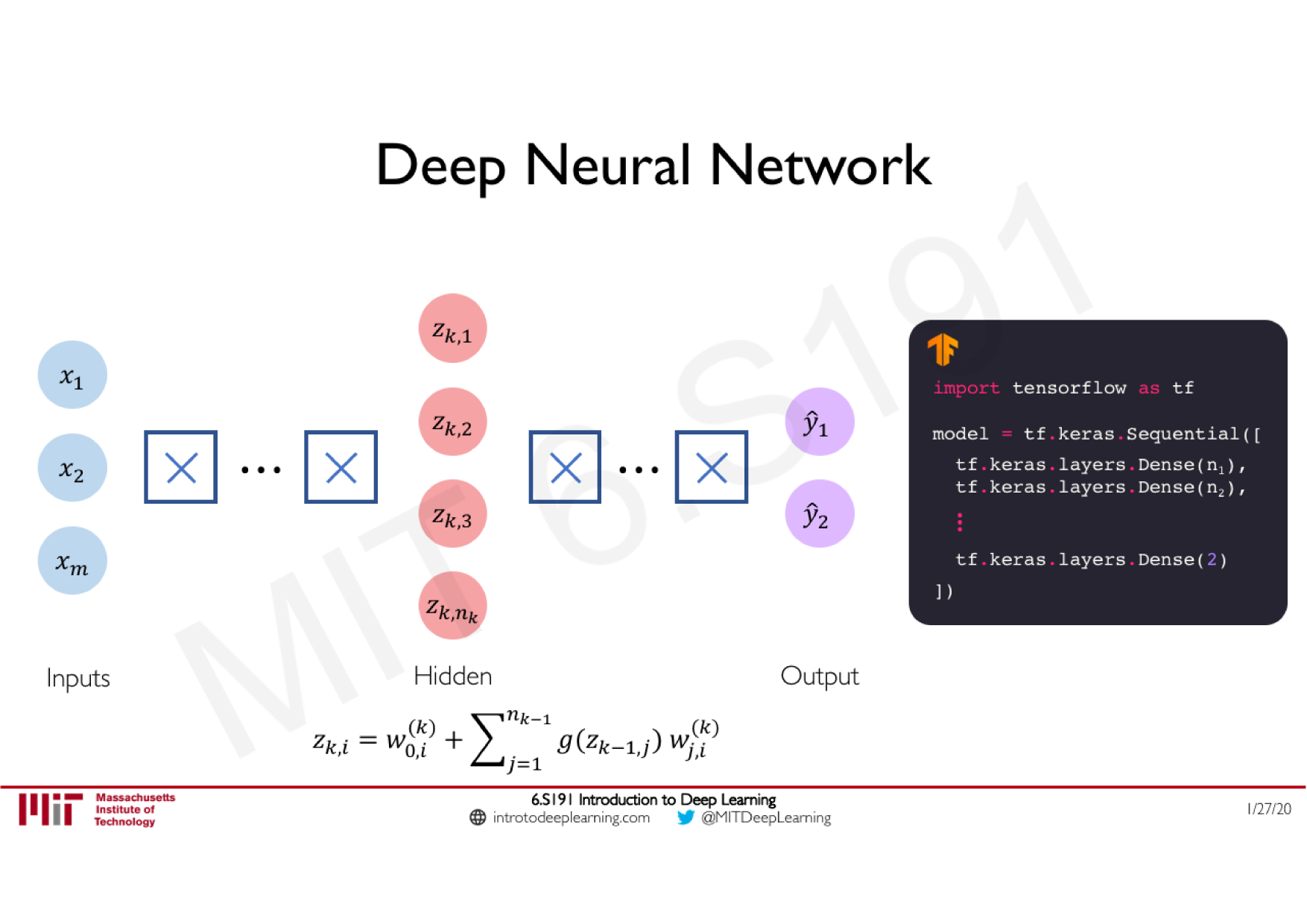


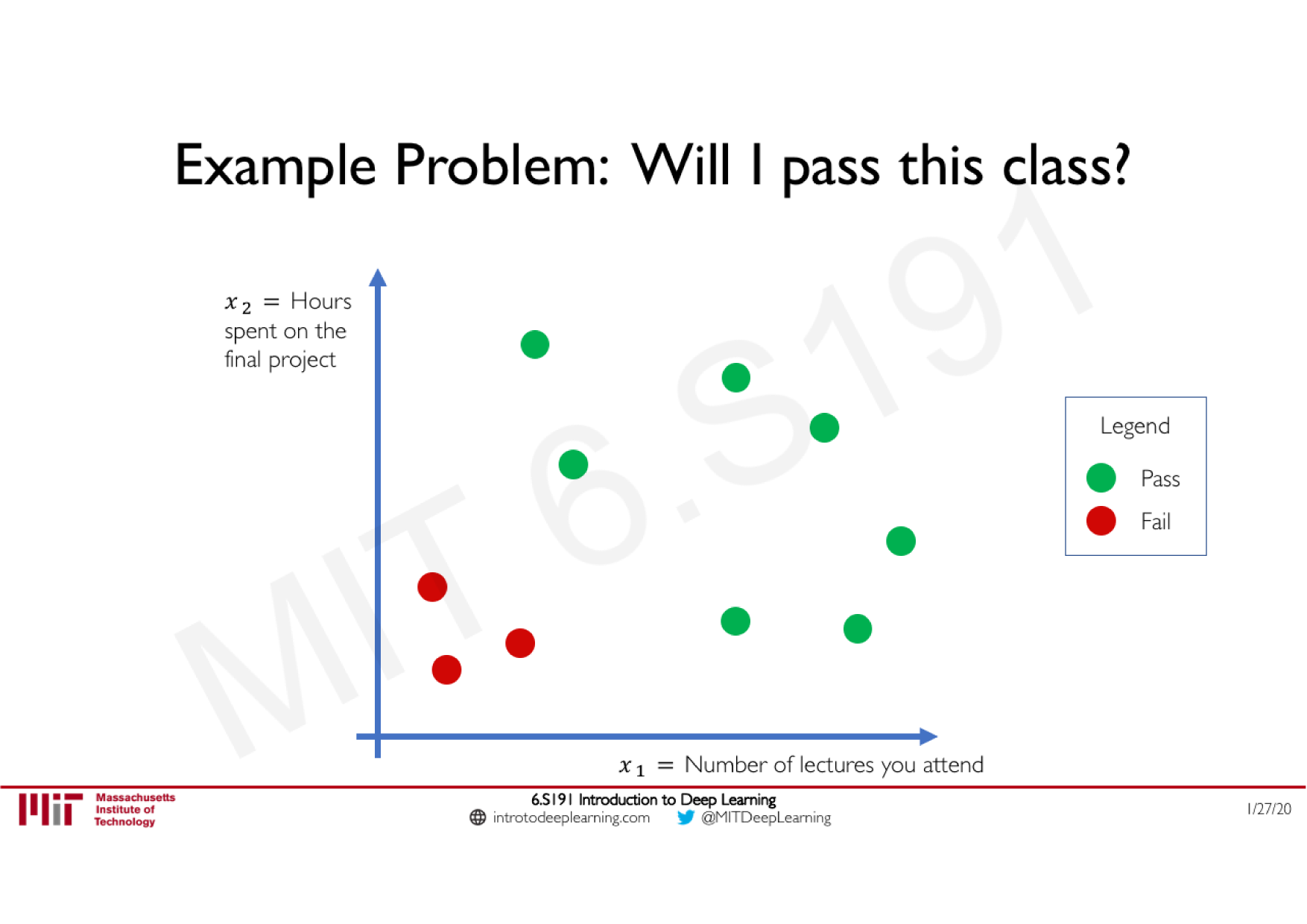
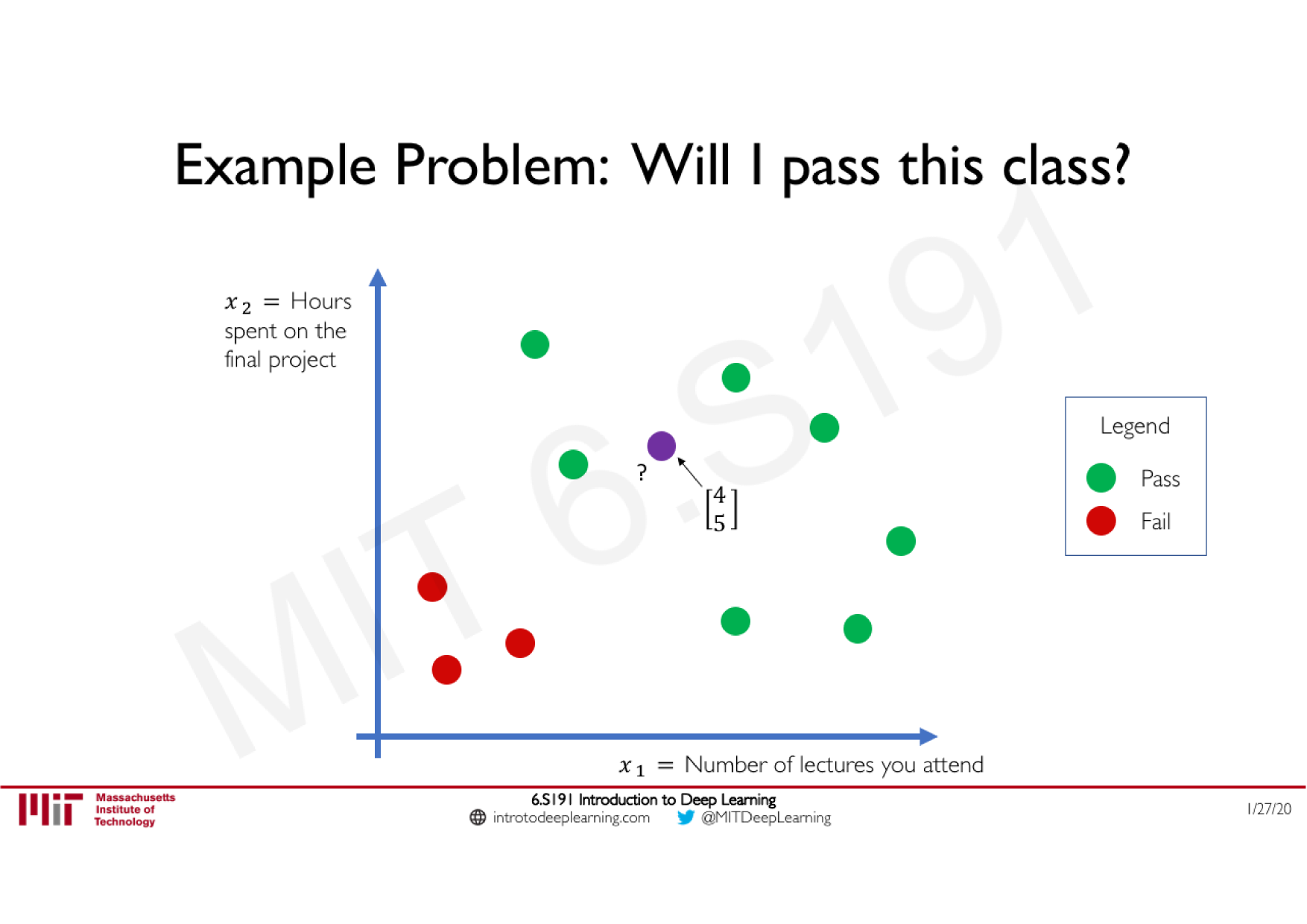
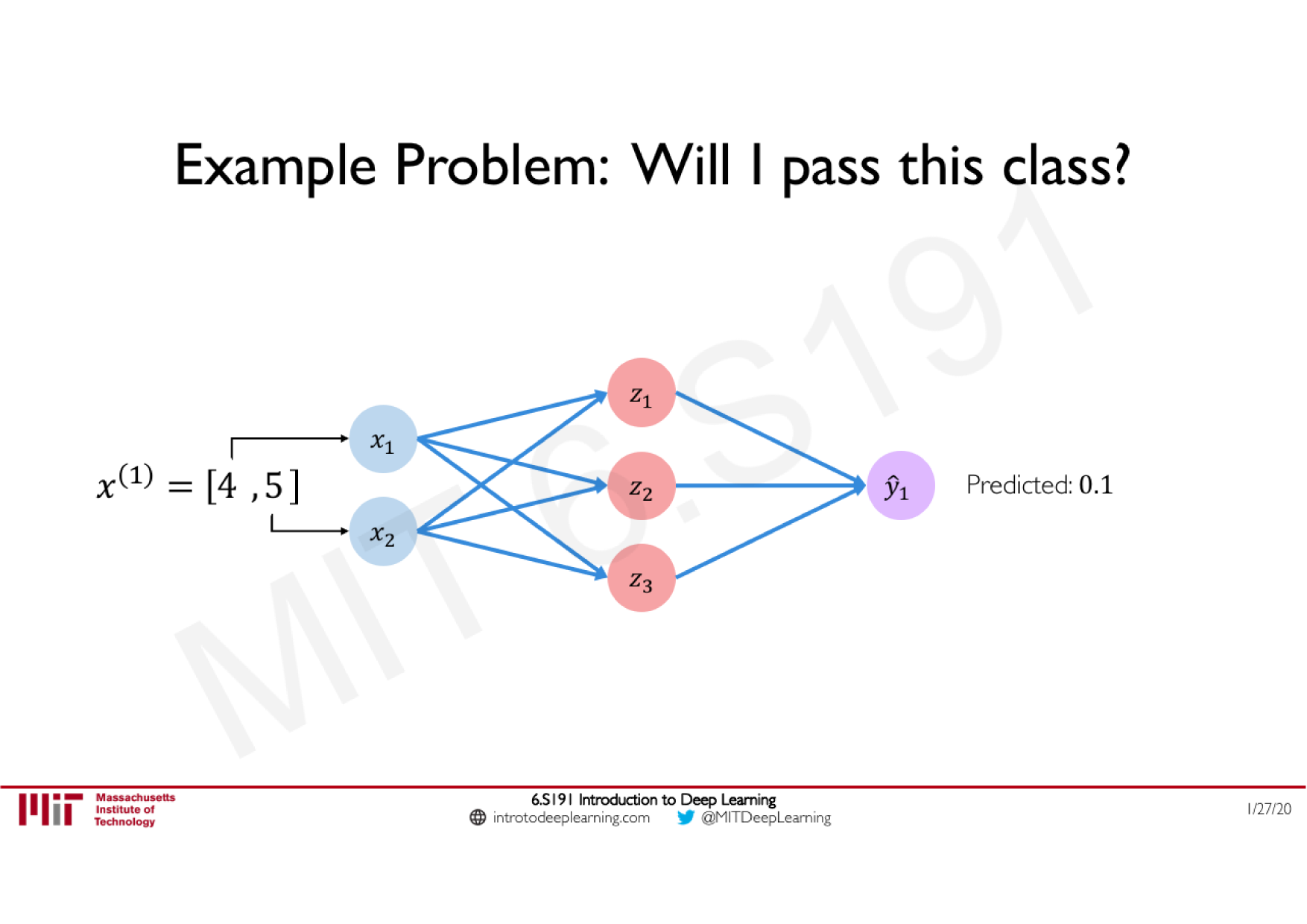
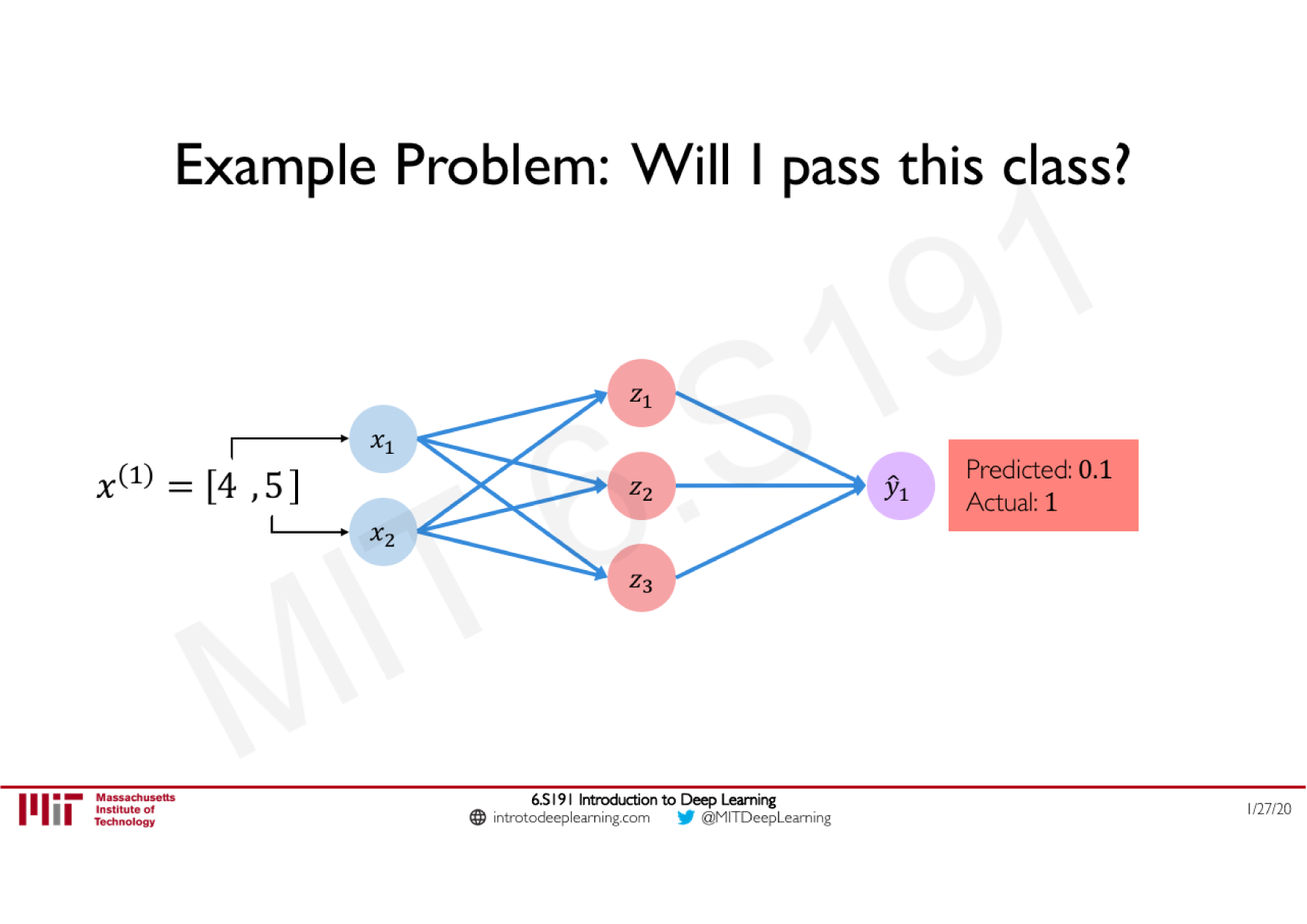
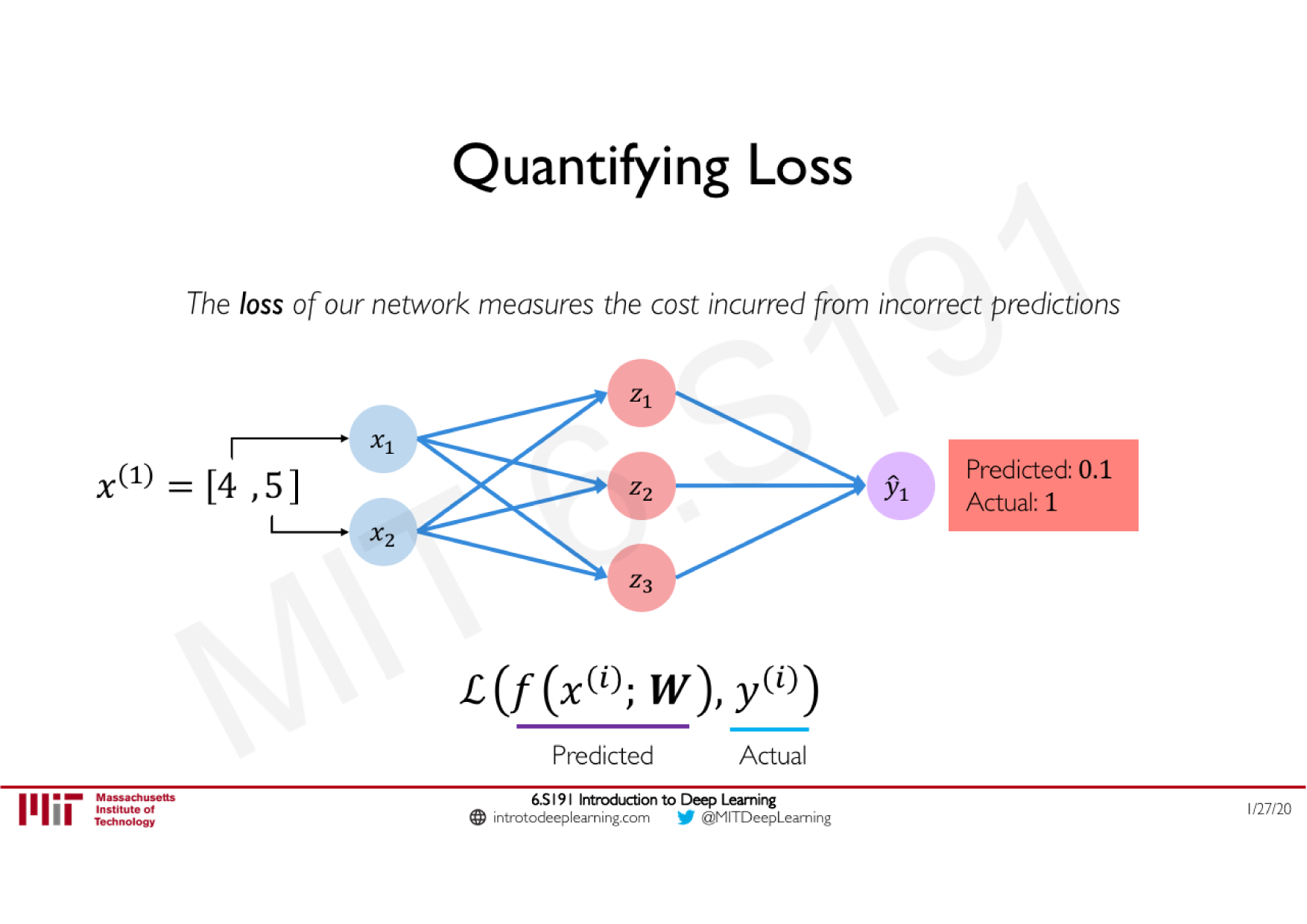
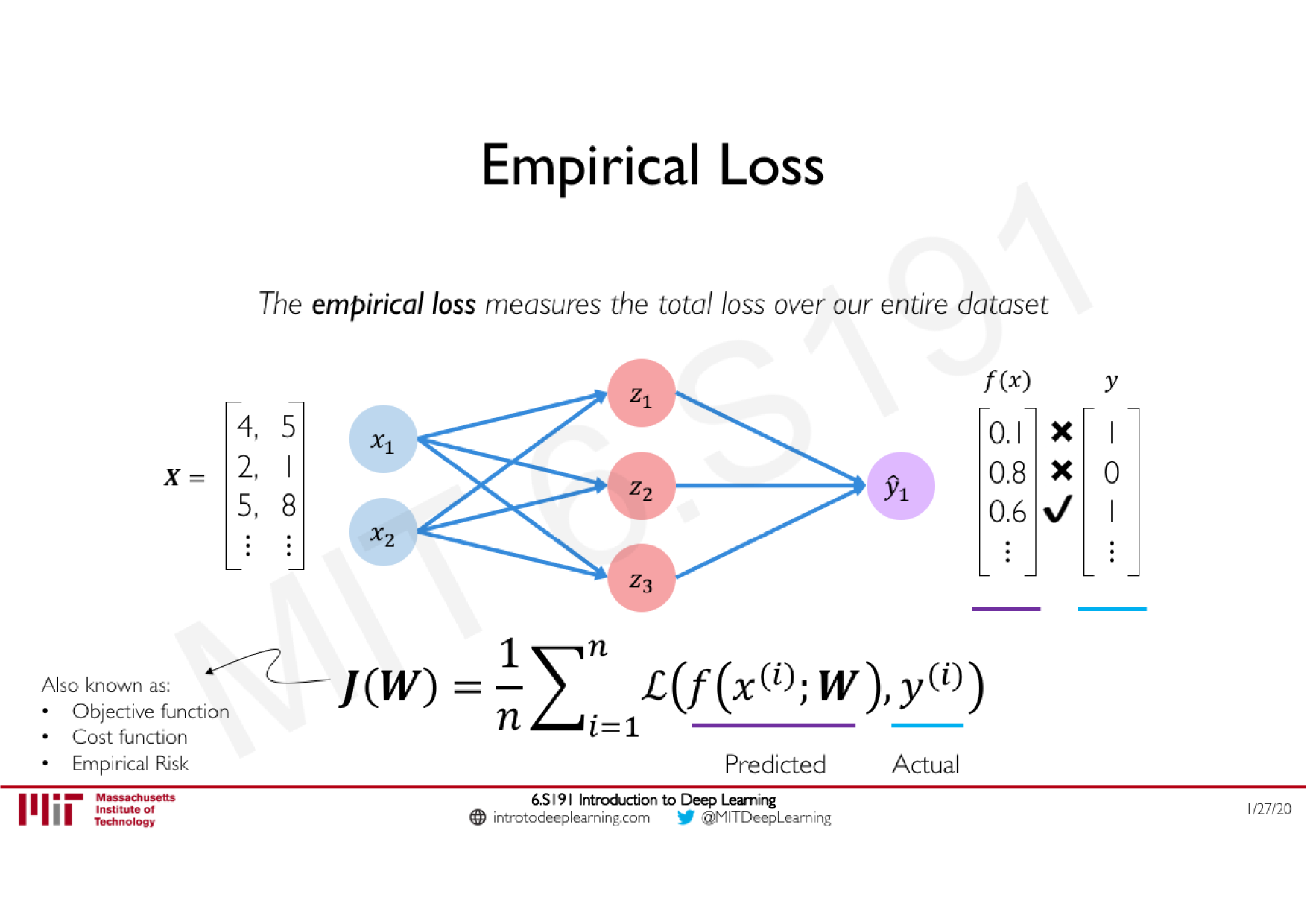
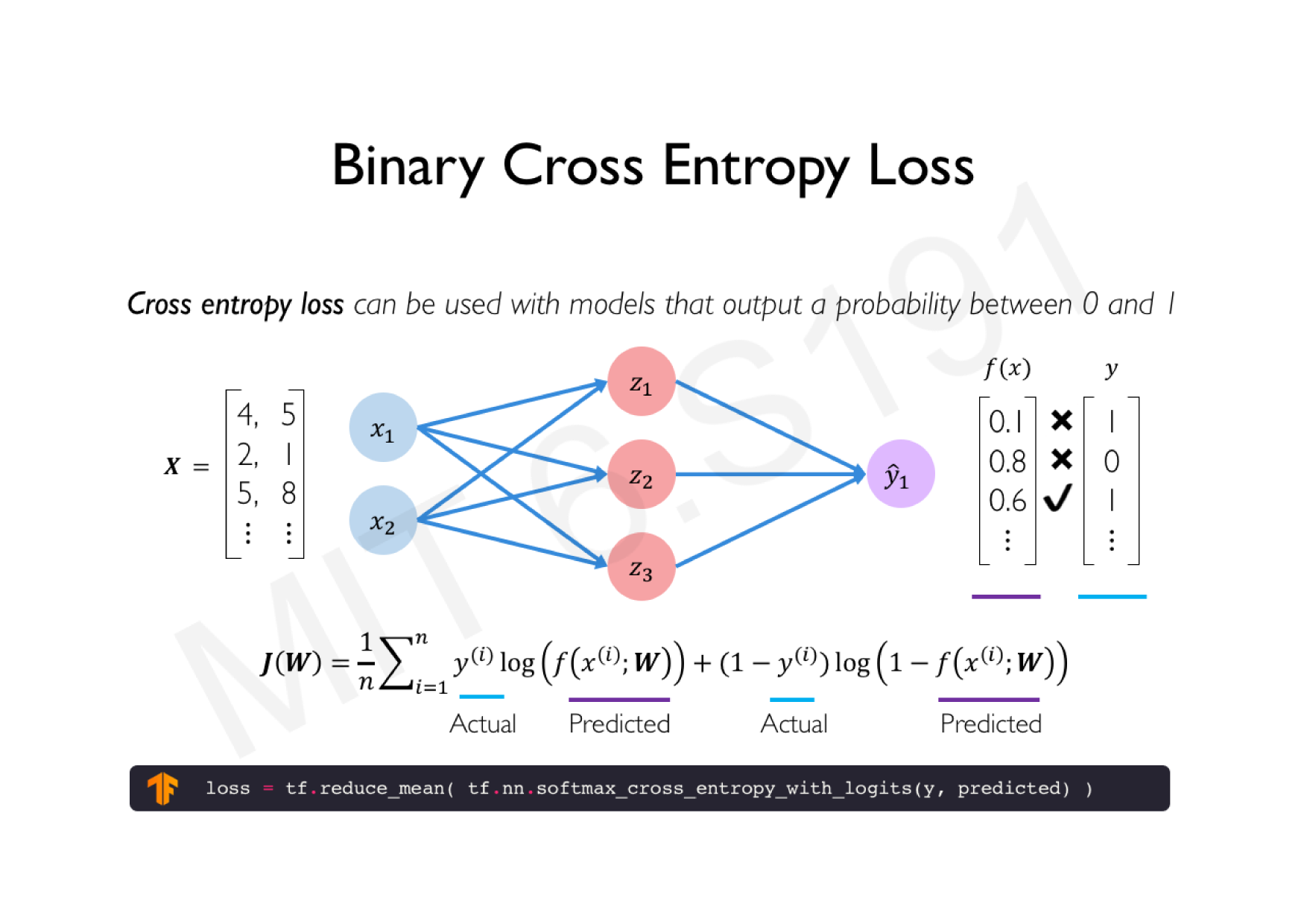




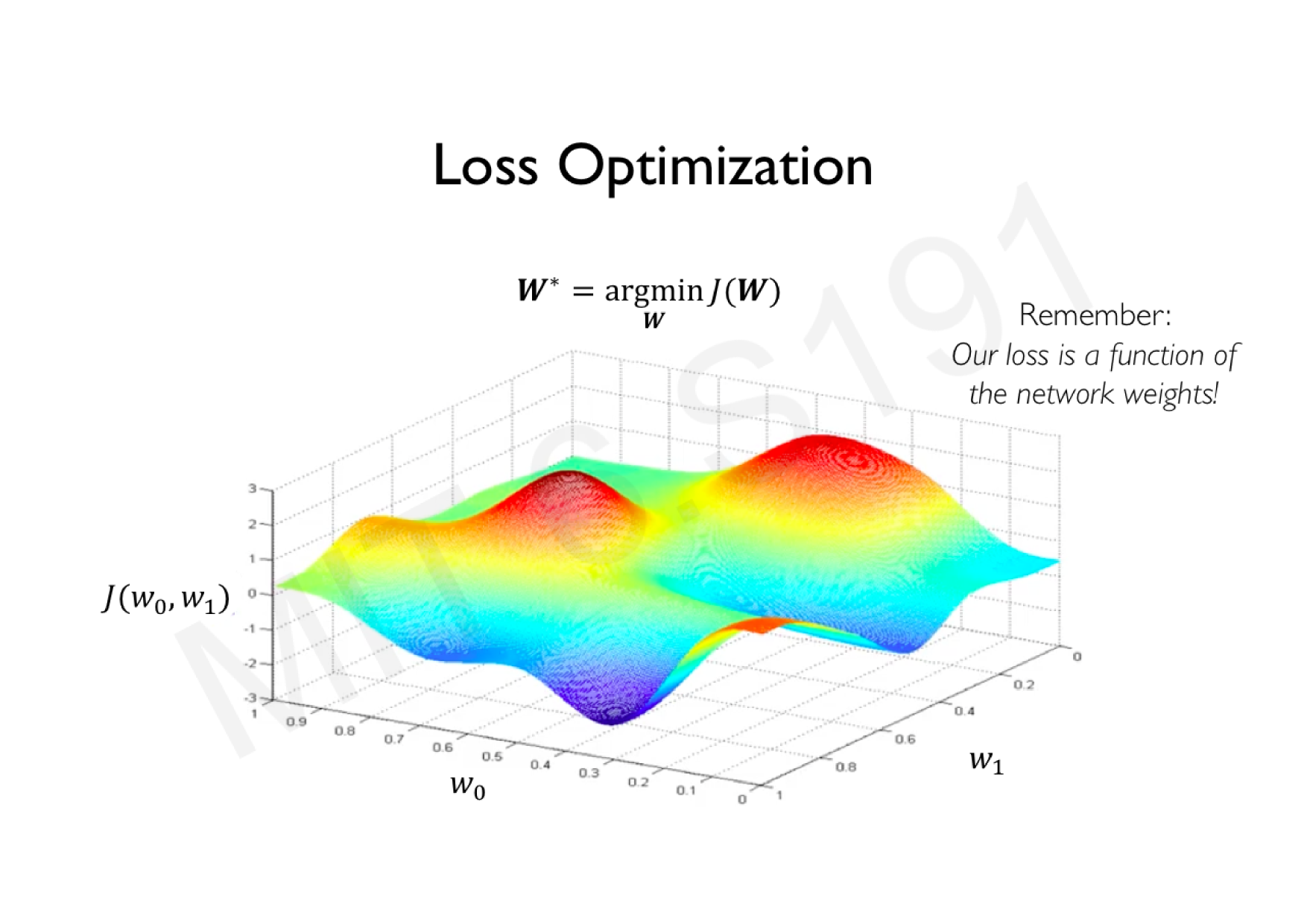
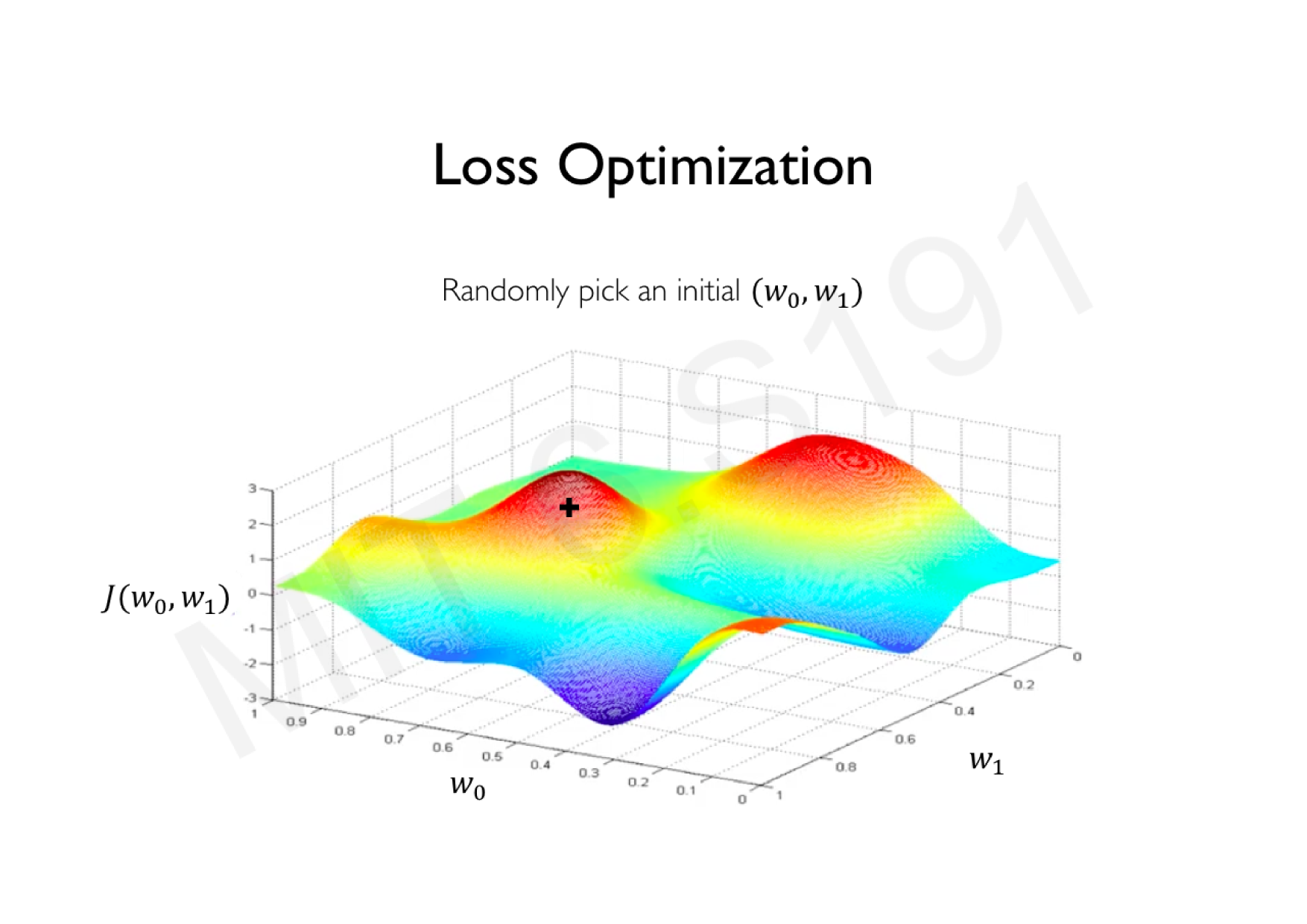
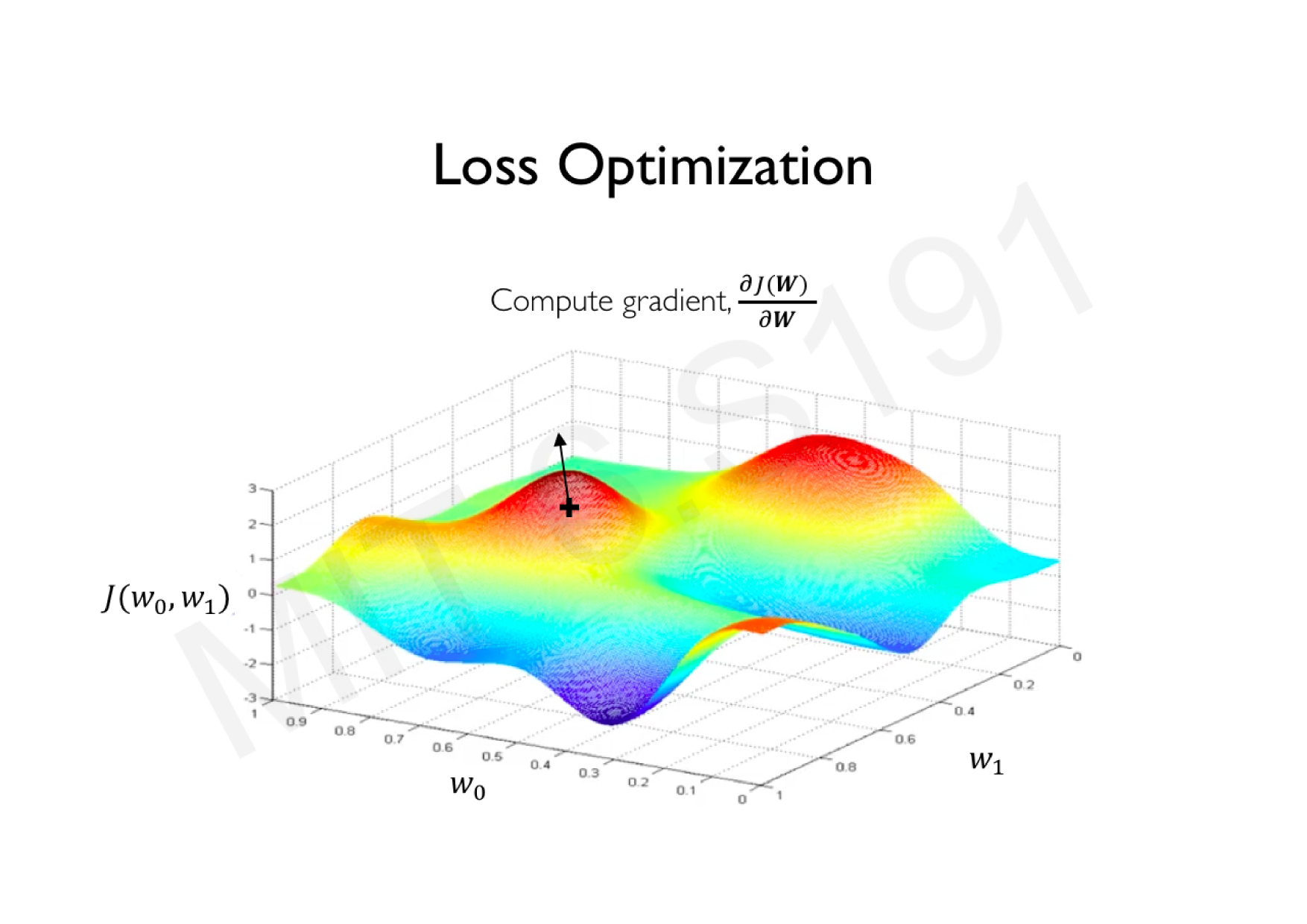
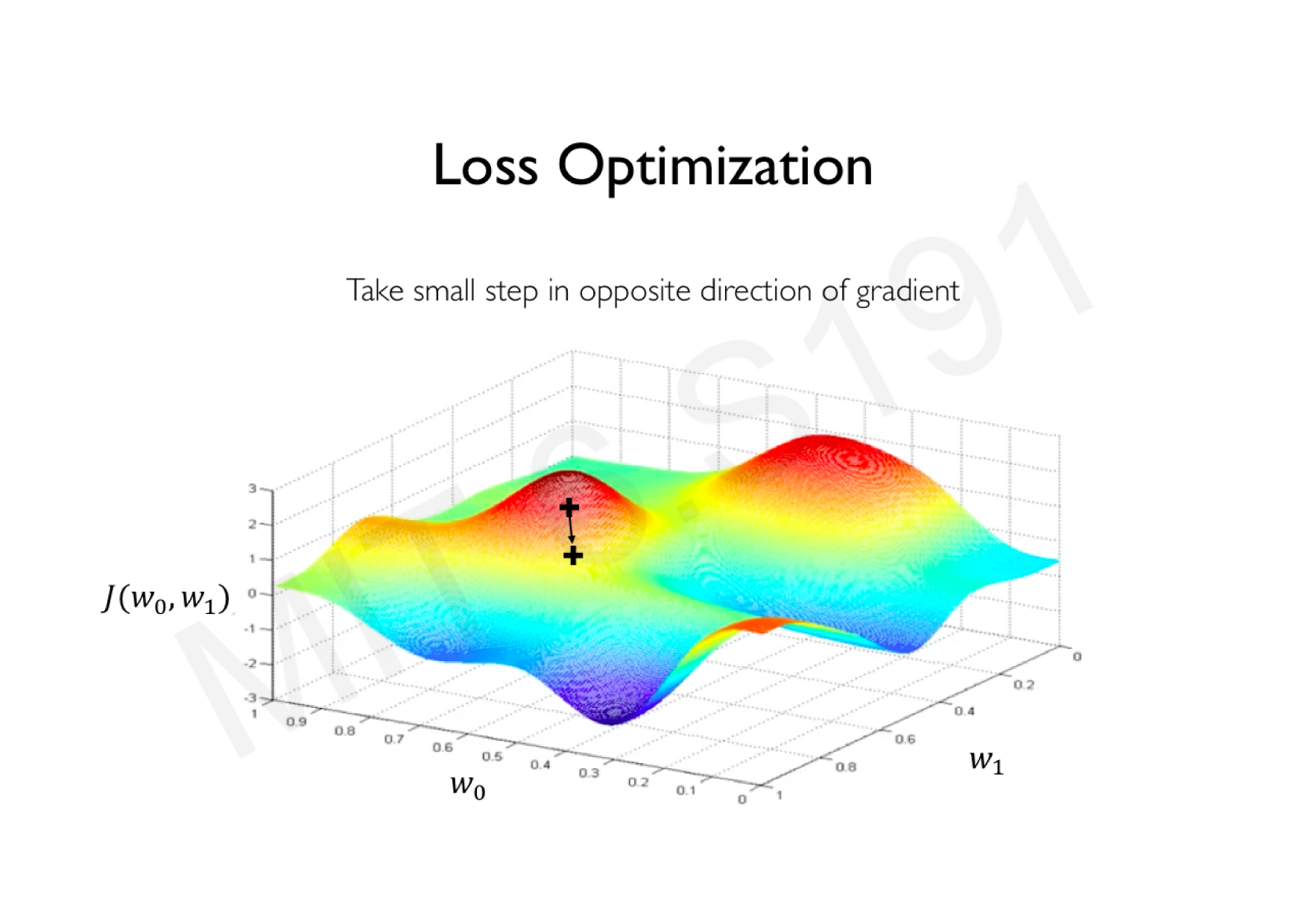
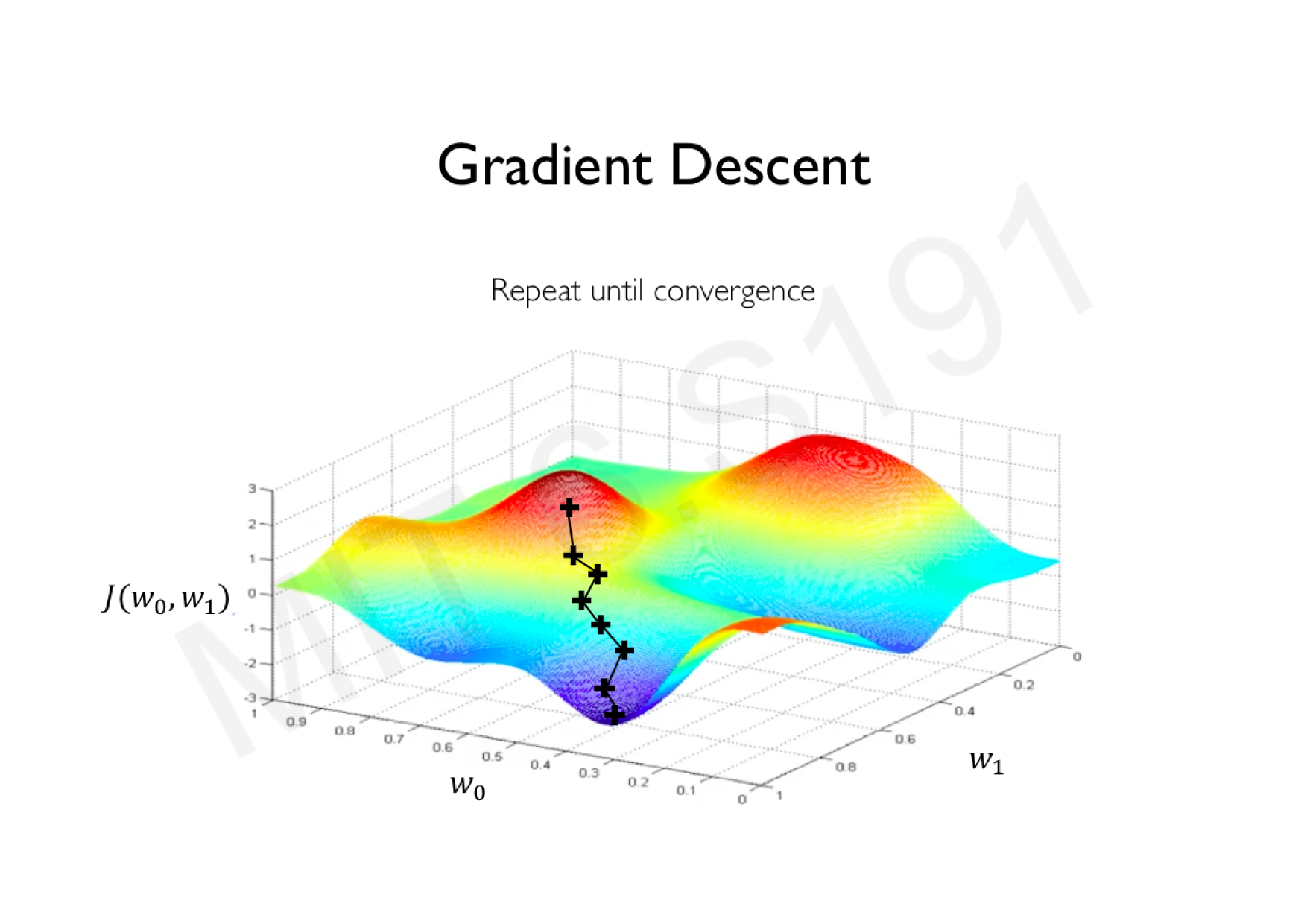



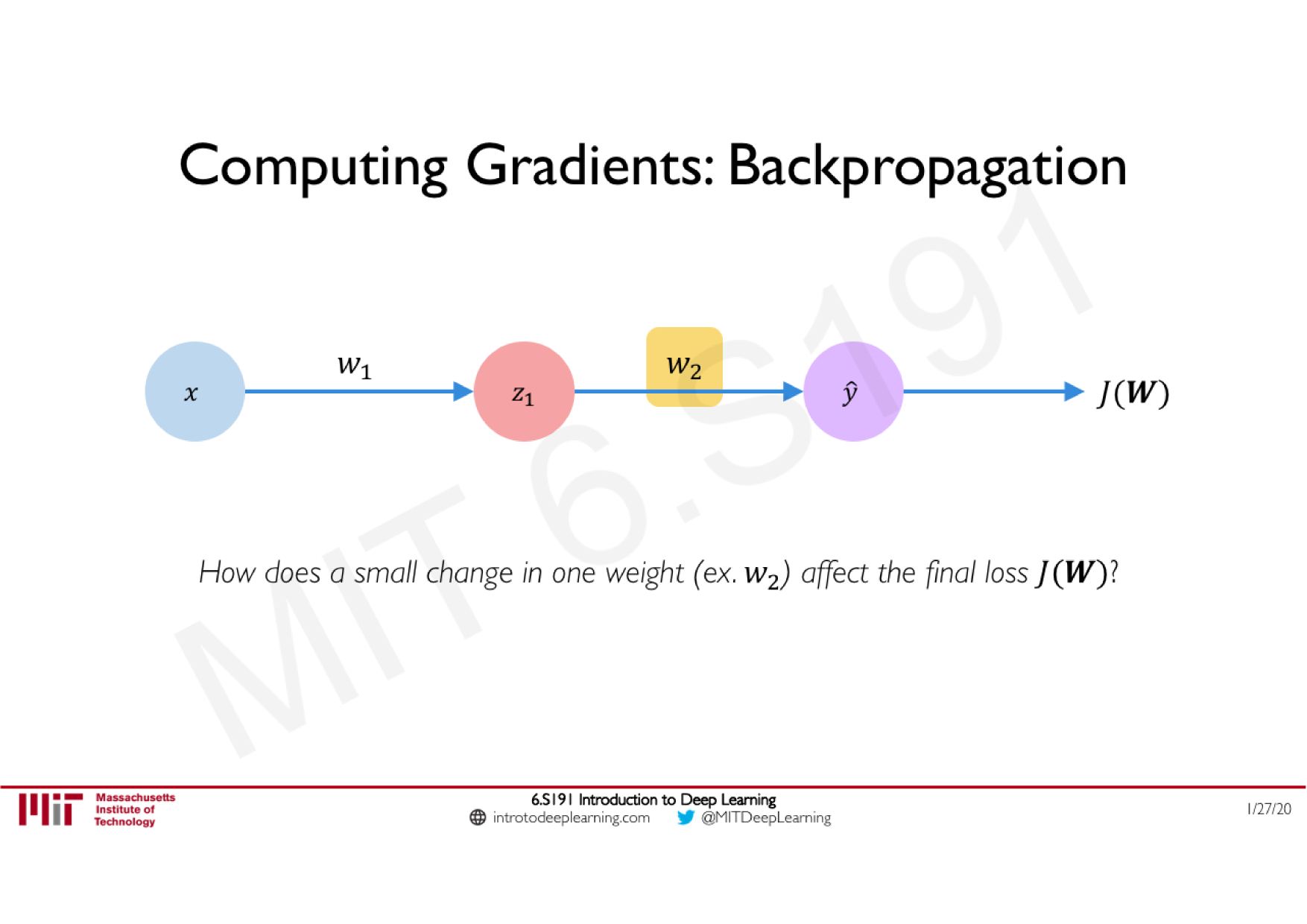
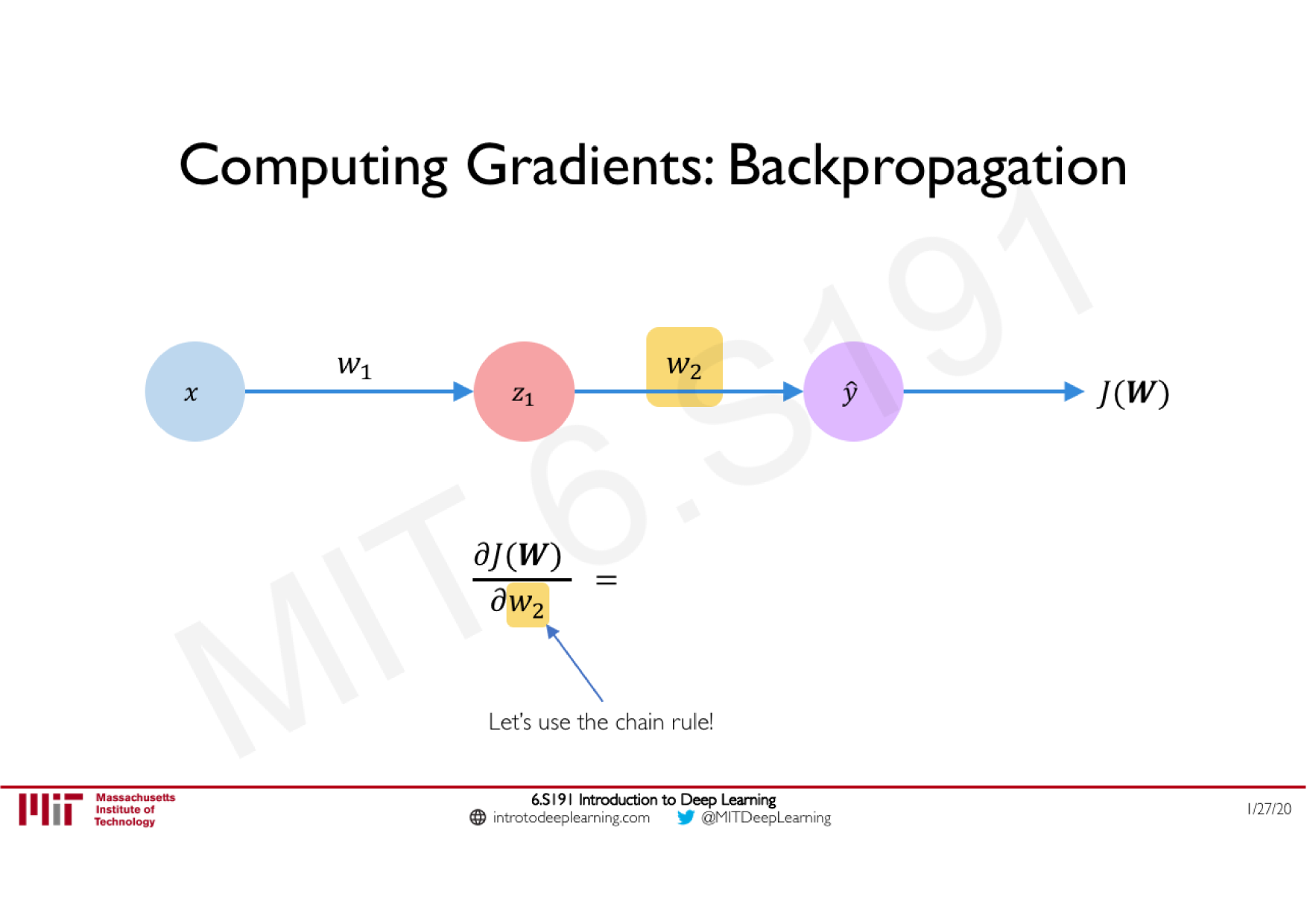
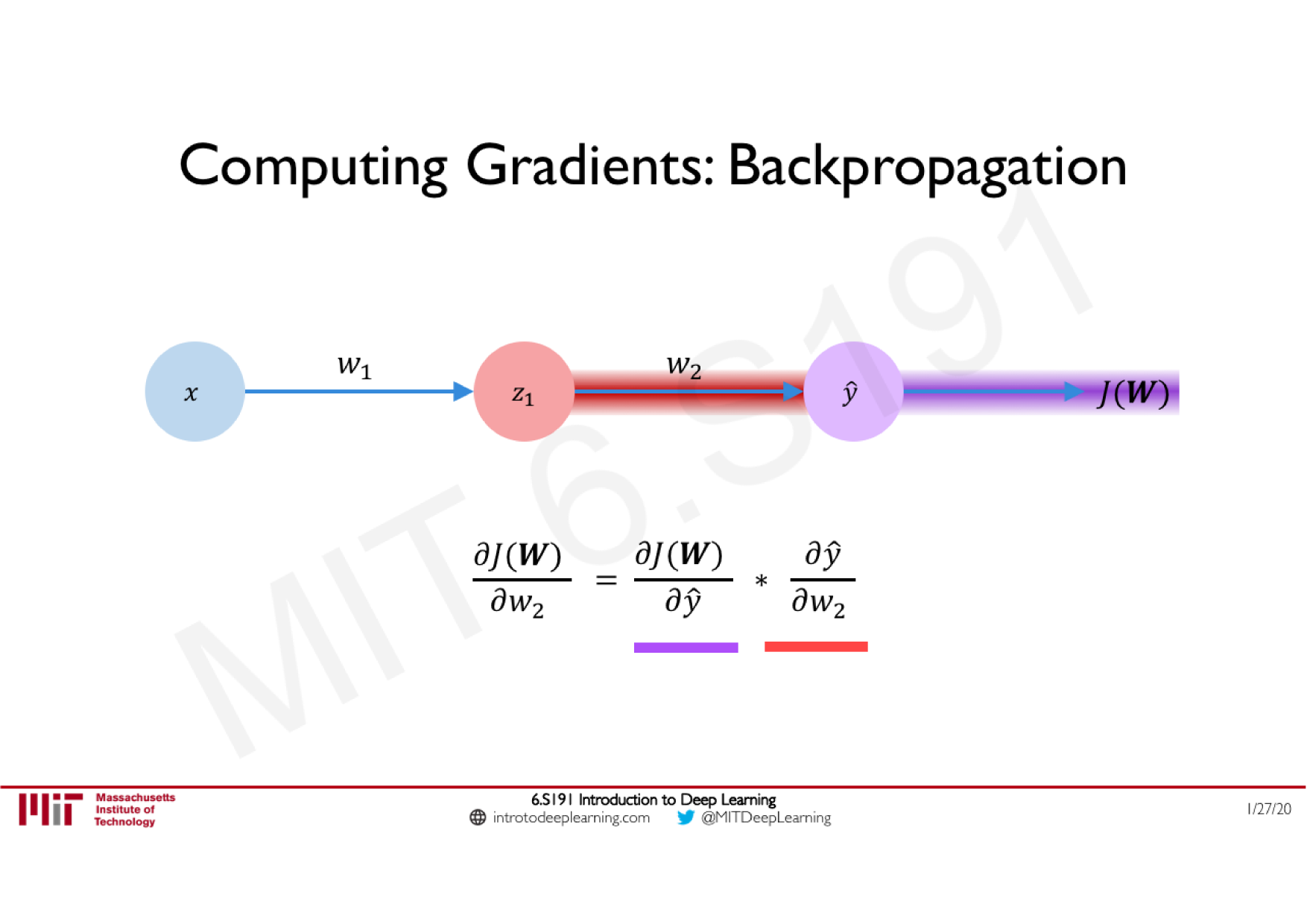
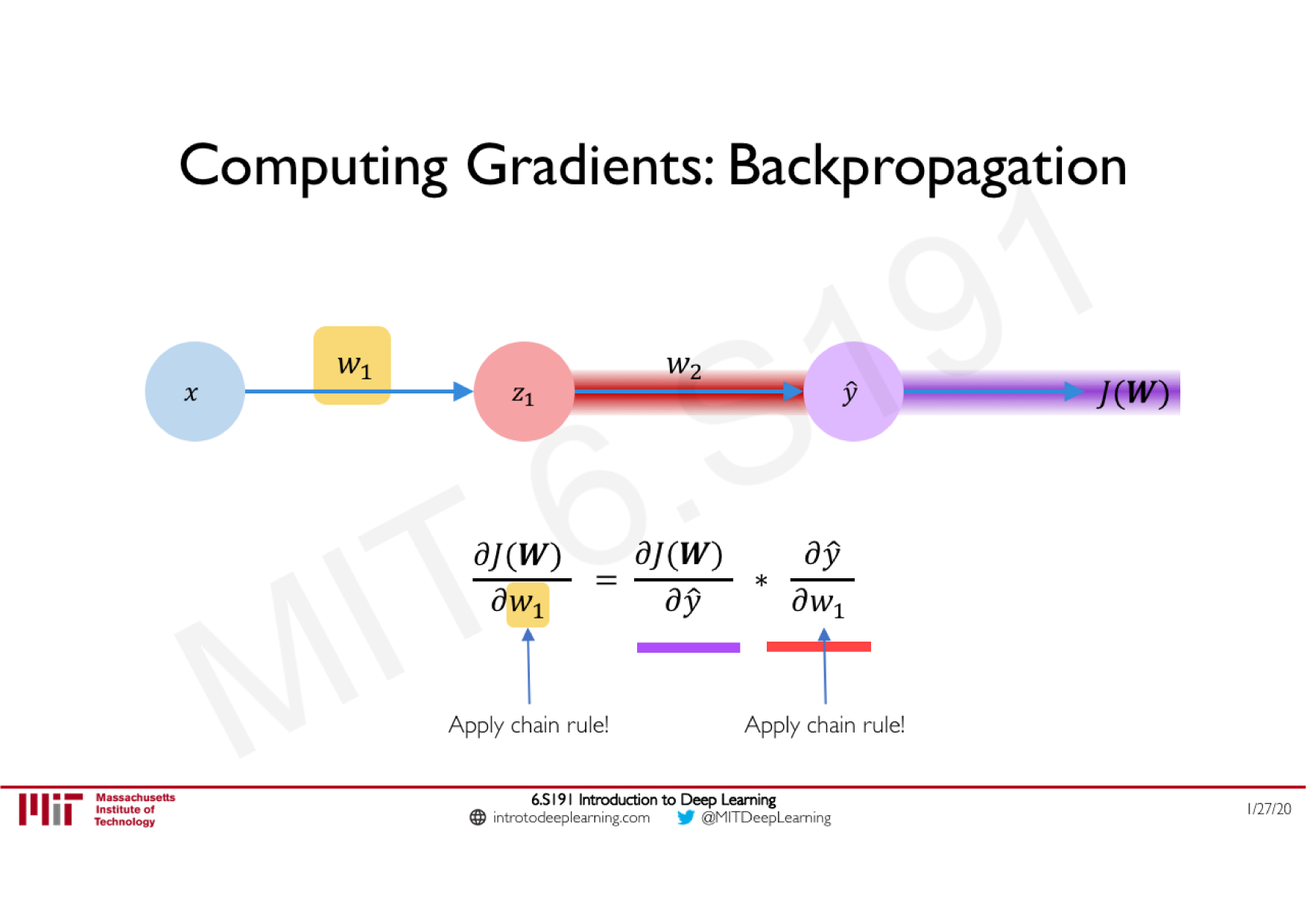
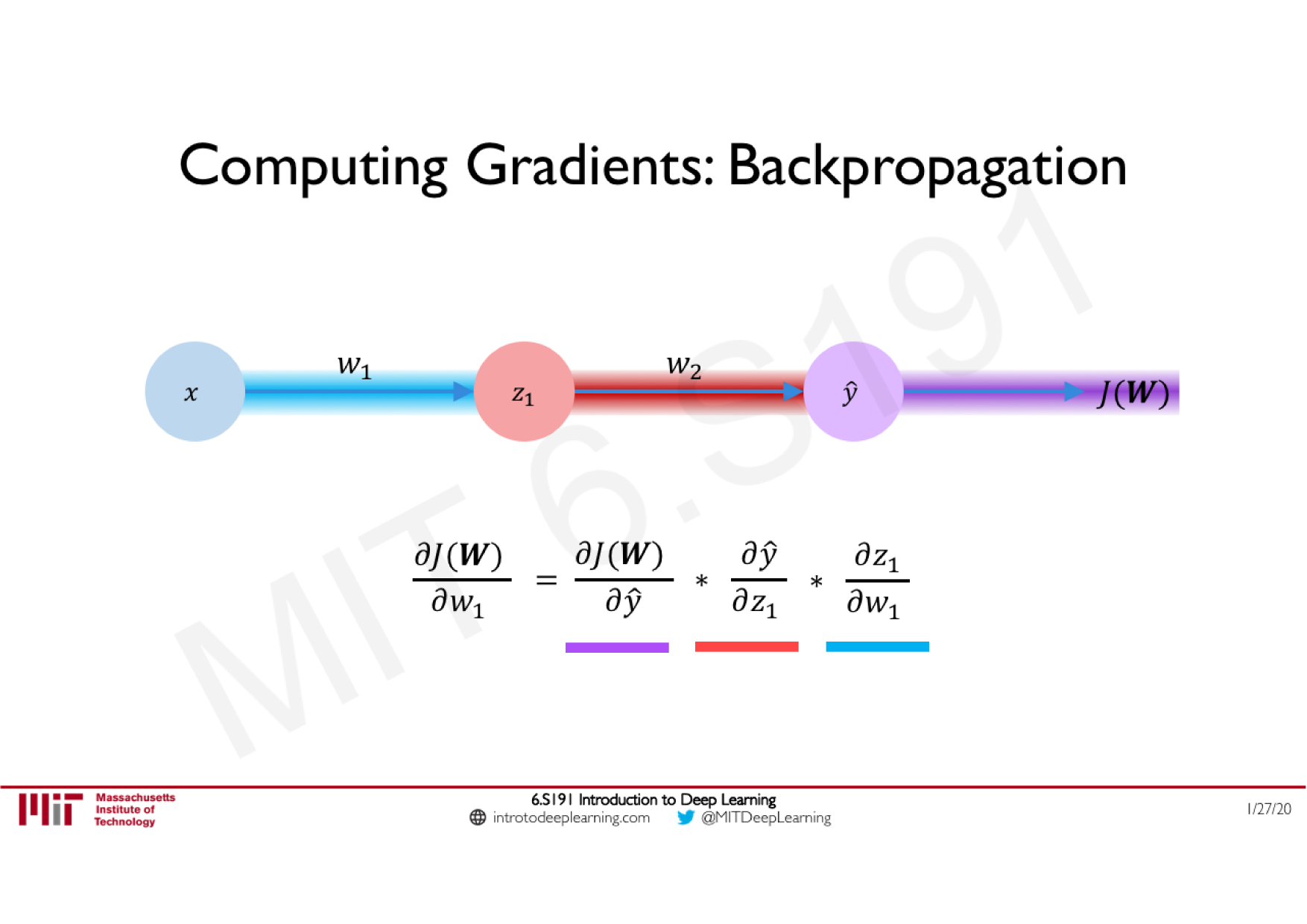
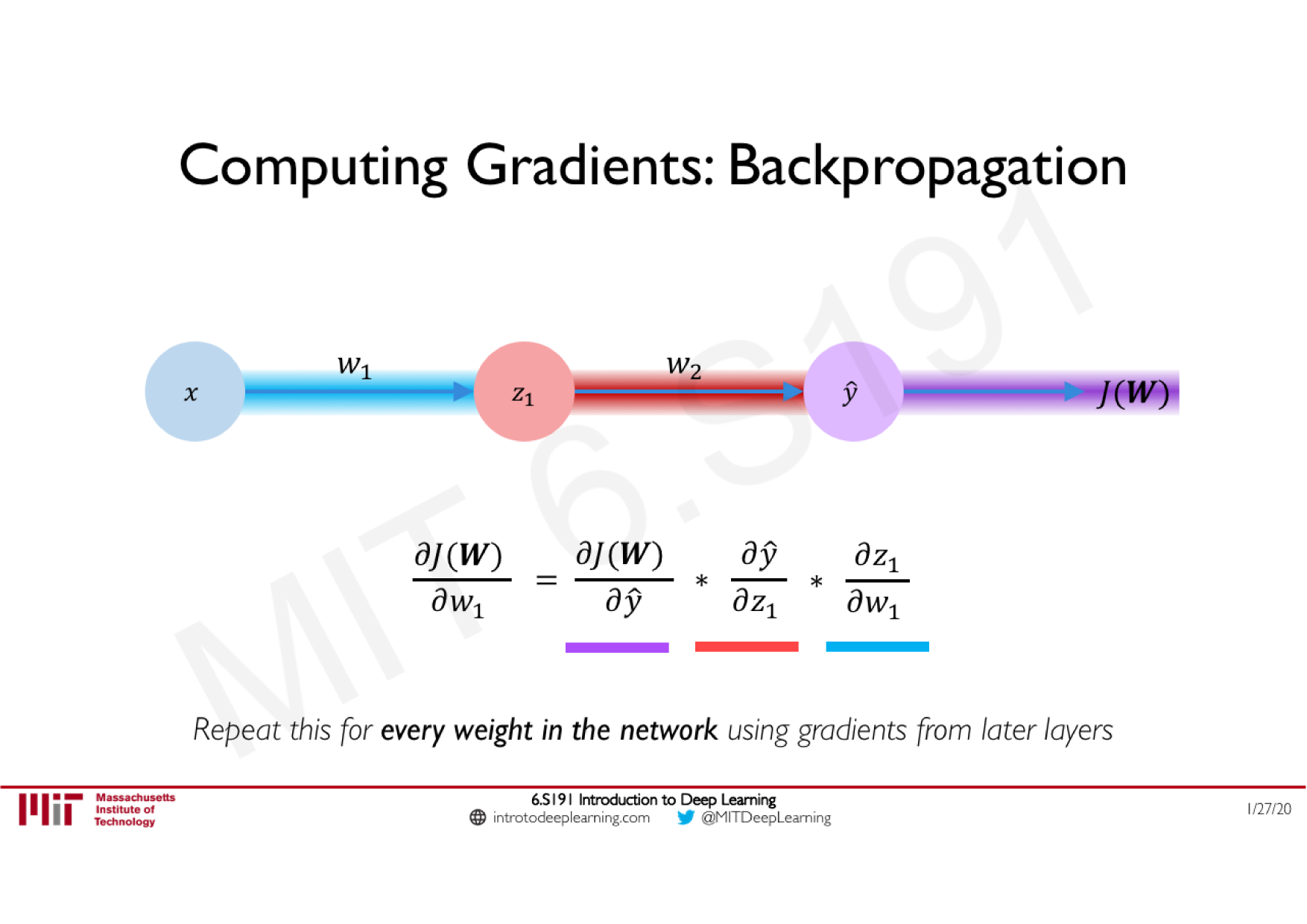




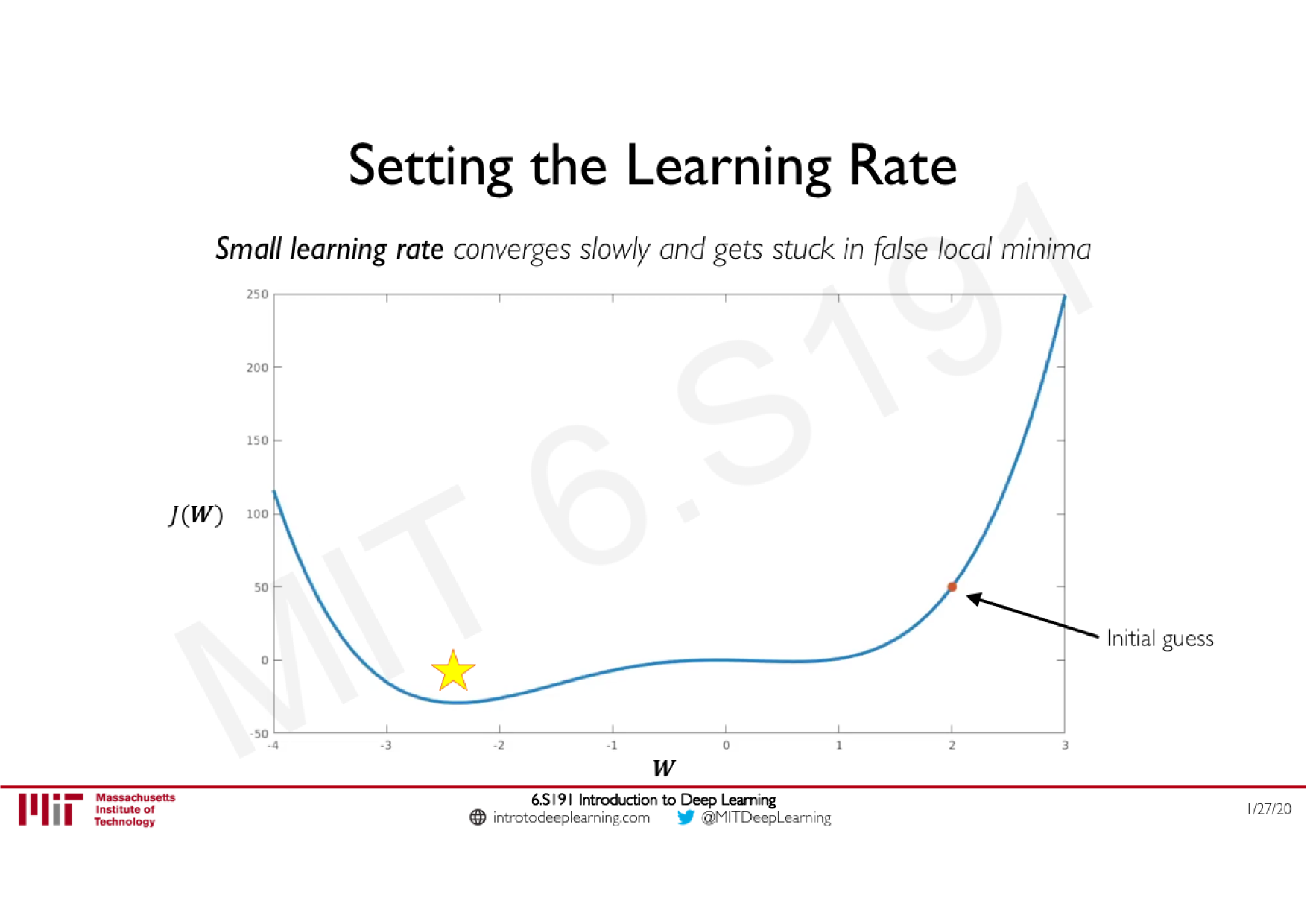
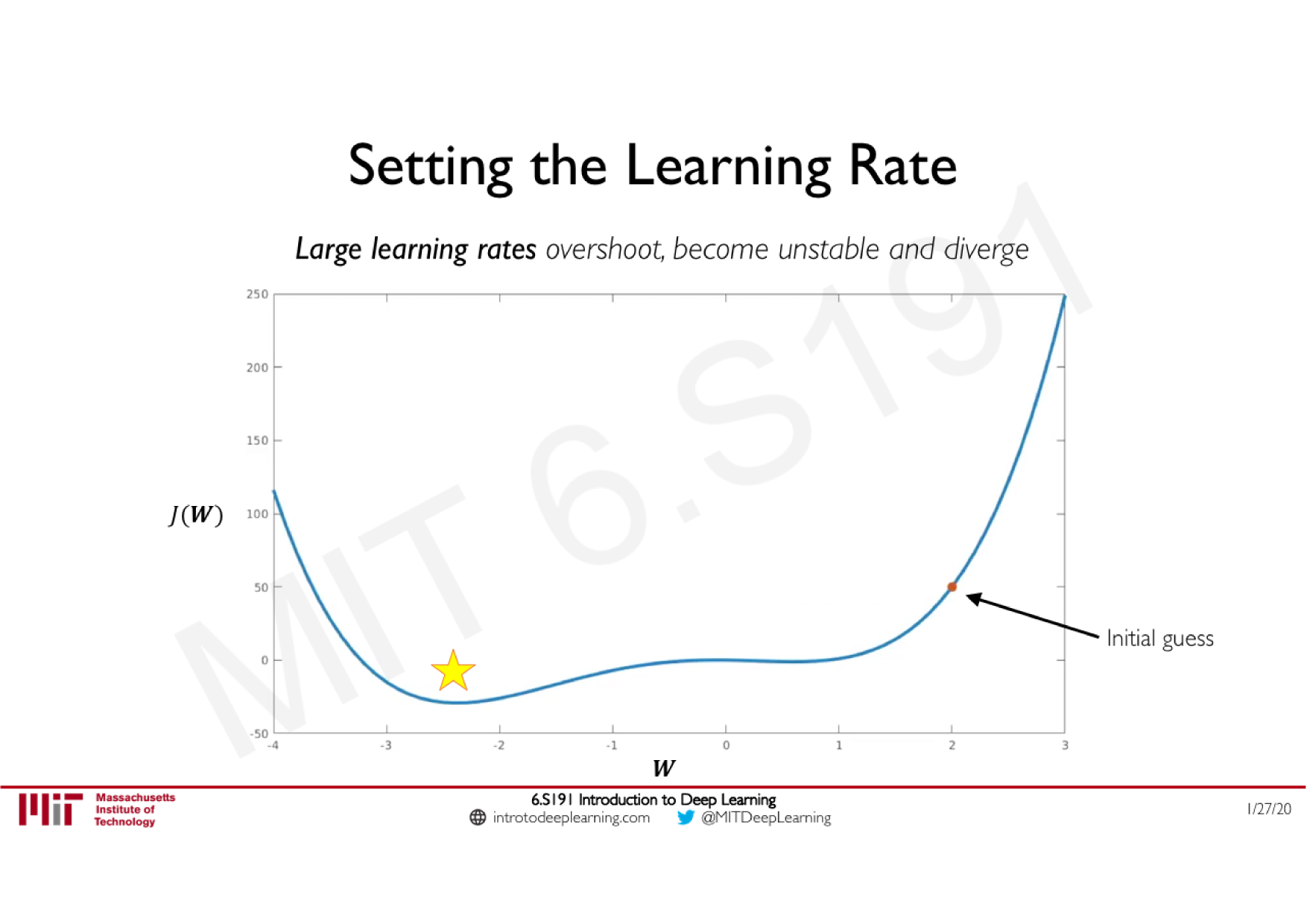
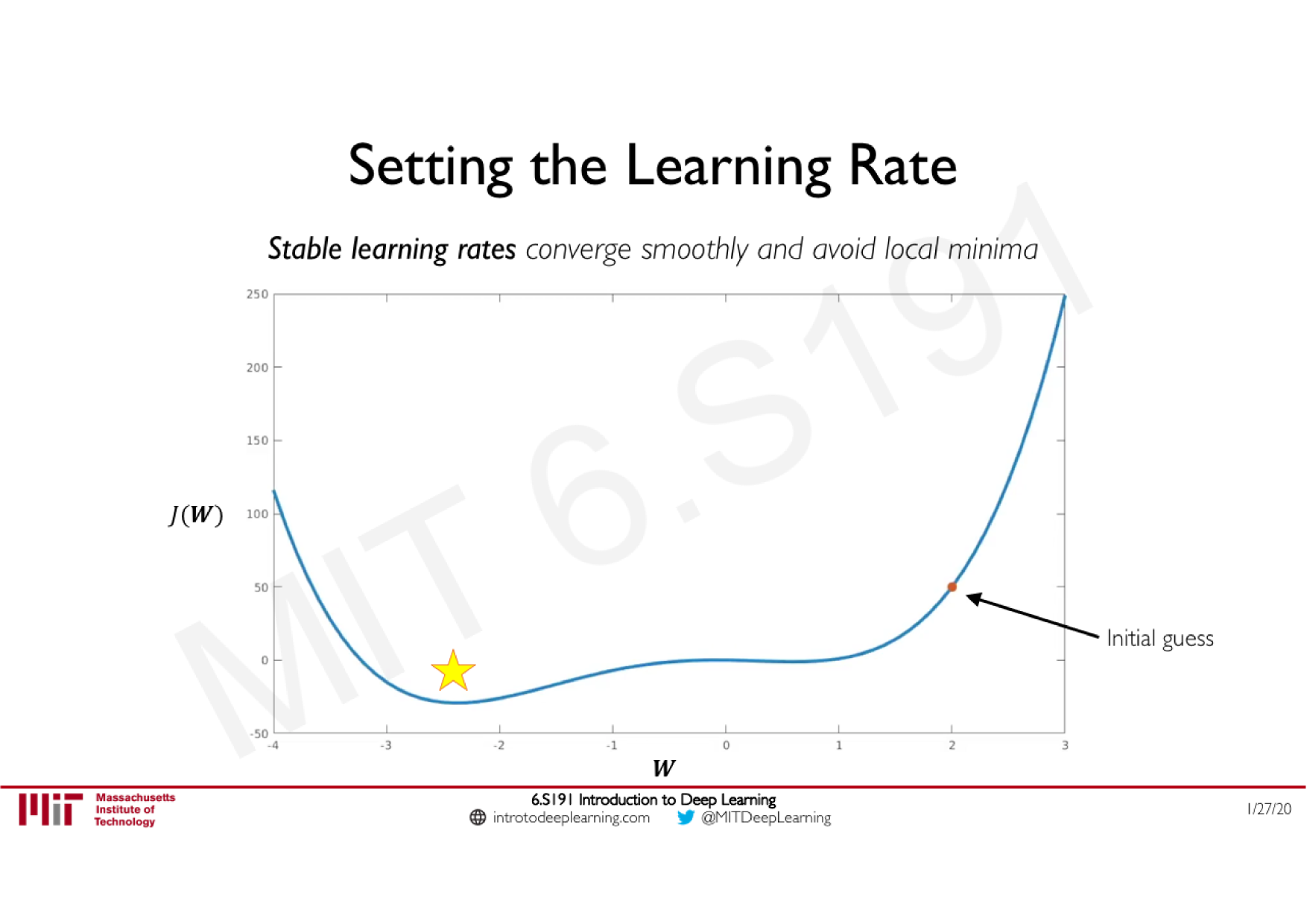






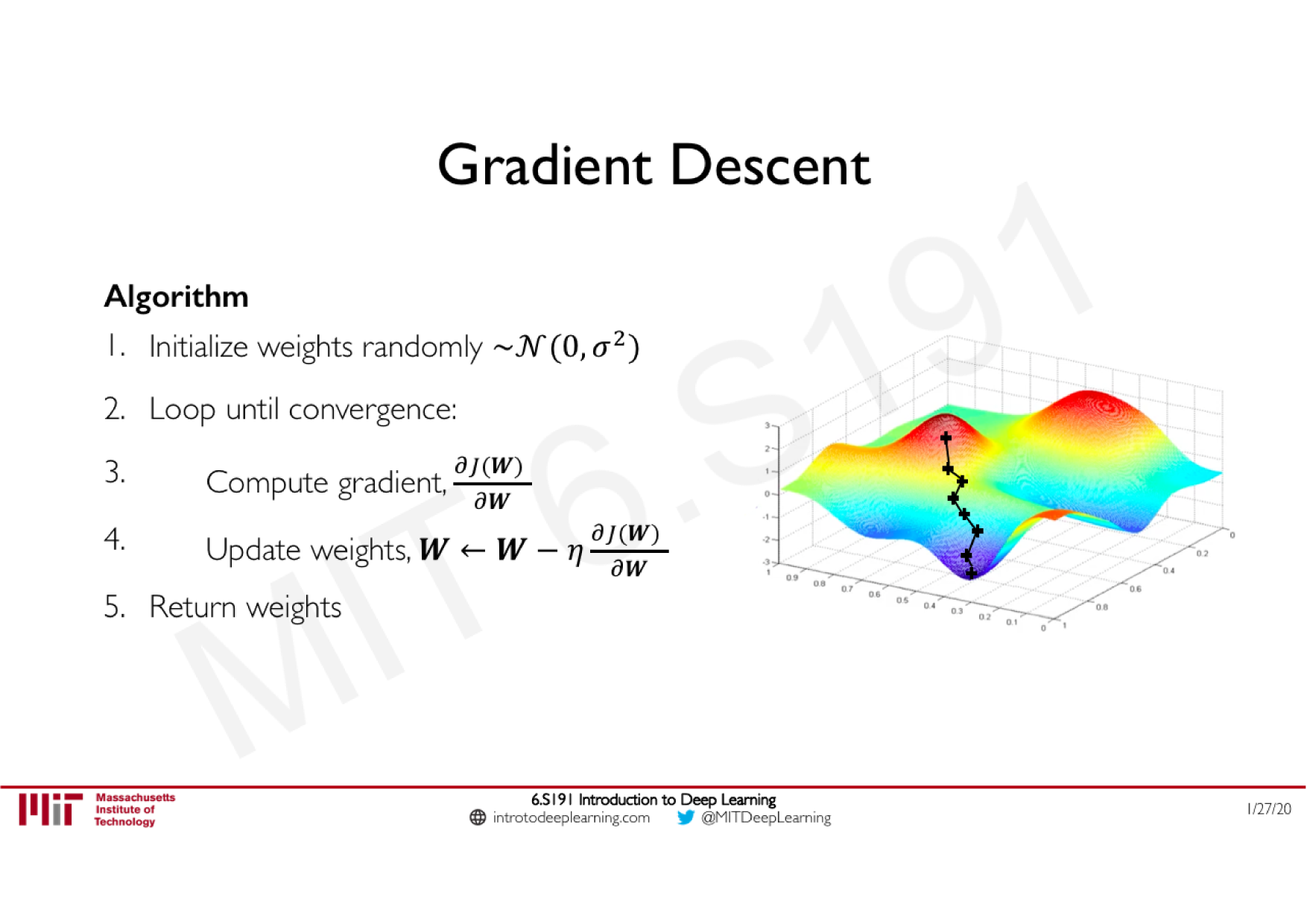
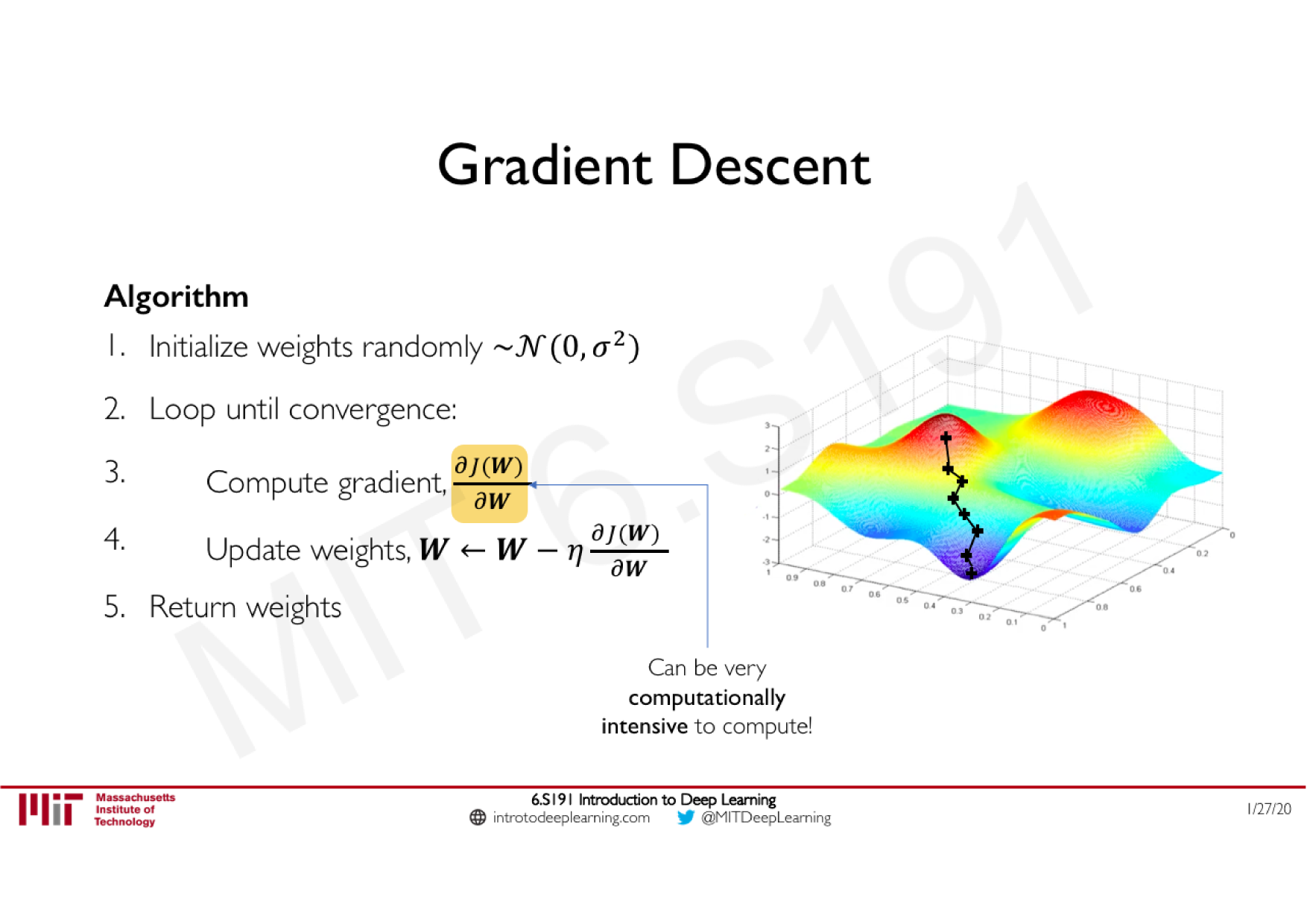
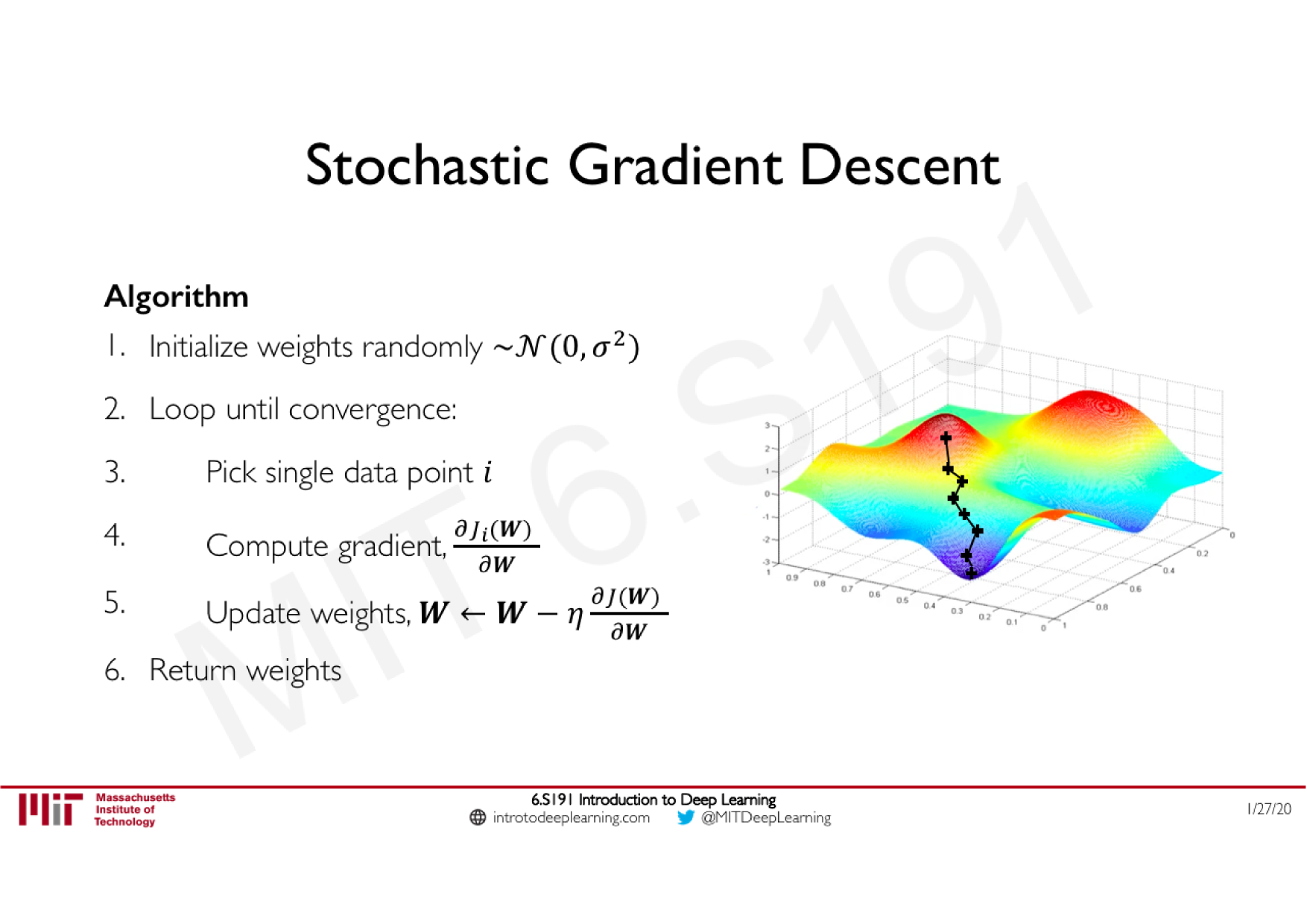
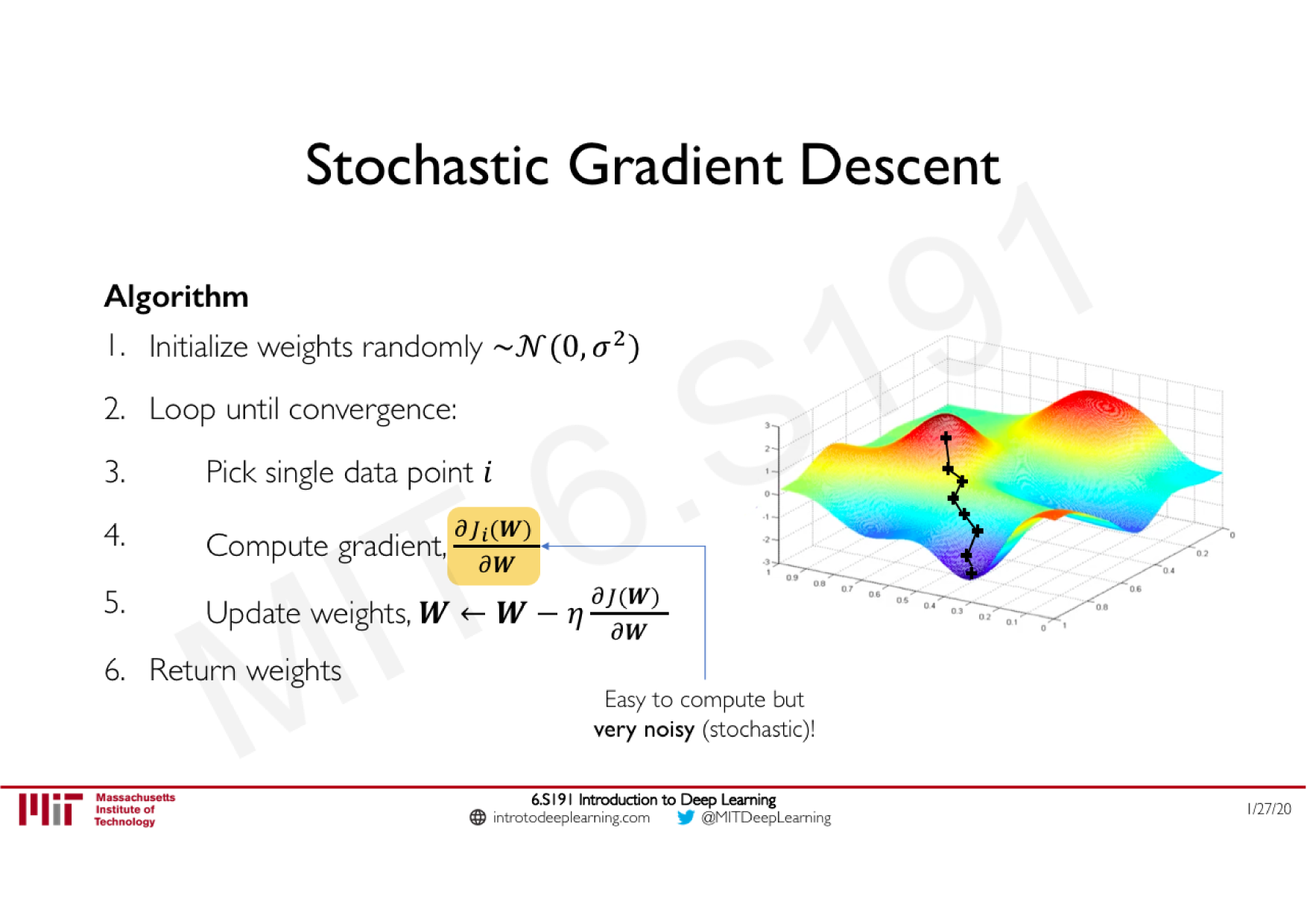

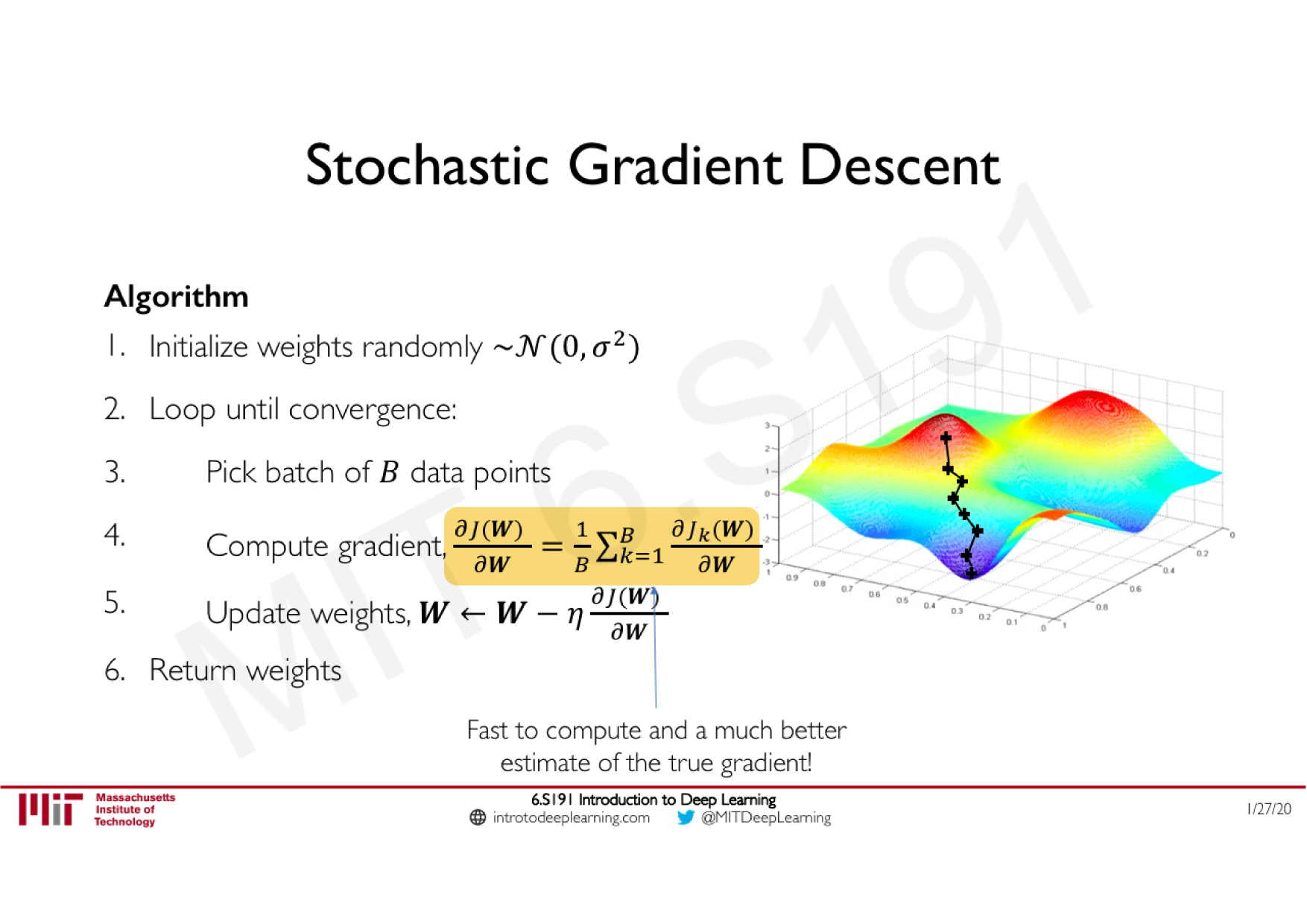
Variations de la descente de gradient stochastique
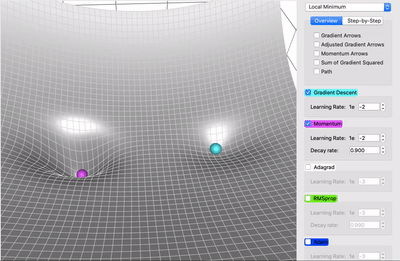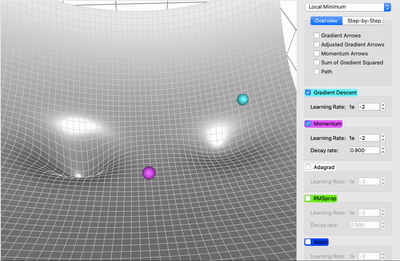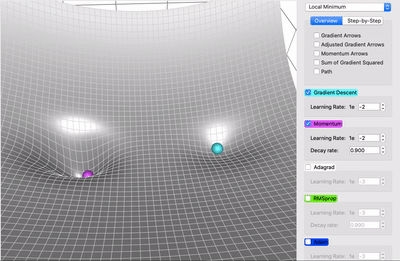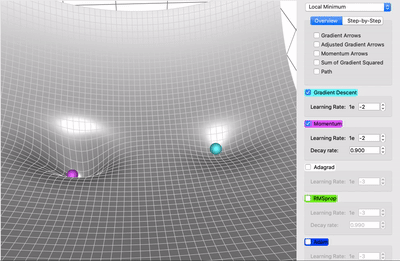
Descente de gradient classique
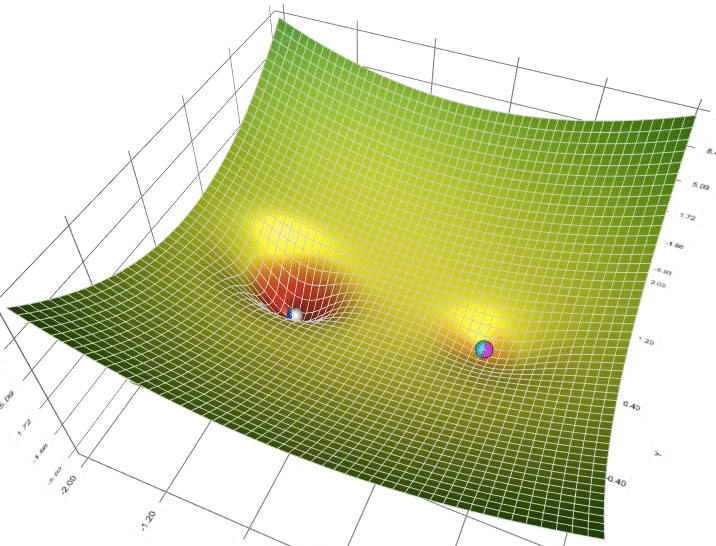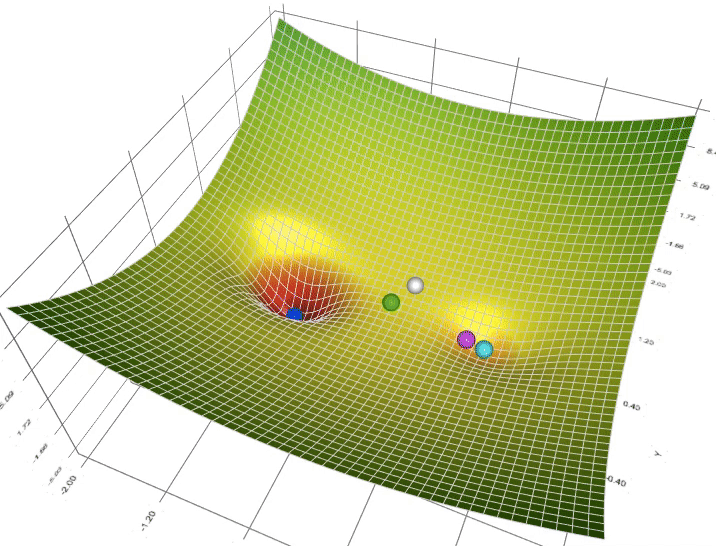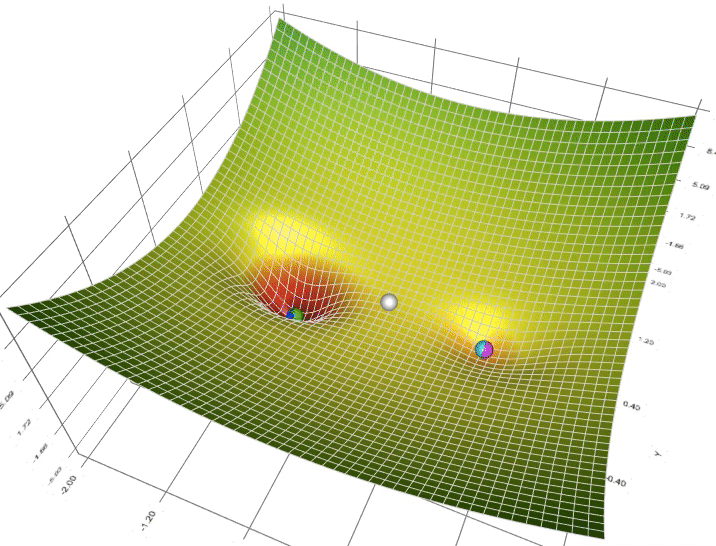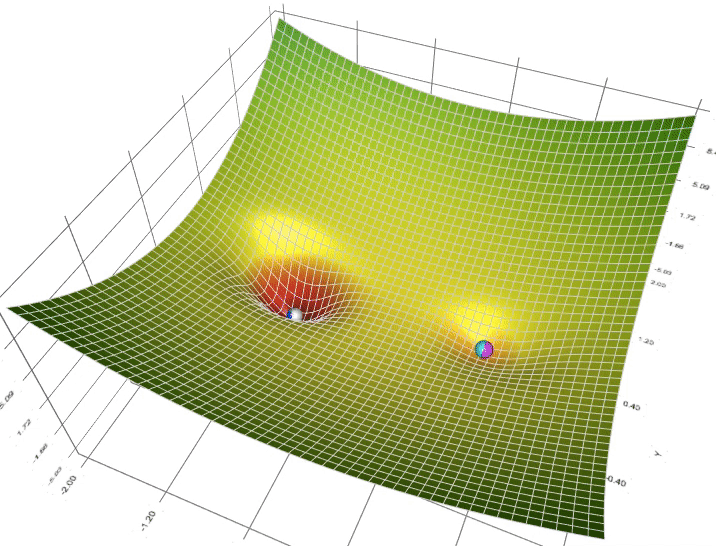
Moment (ajoute de l'inertie)
Adagrad (learning rate adaptatif)
RMSprop (ajoute un decay)
Adam (tout combiné)


Batch vs Epoch
Batch : nombre d'échantillon servant à mettre à jour
chaque calcul du gradient
Epoch : nombre de fois ou l'algorithme de la descente de gradient est passé sur toutes les données
Batch gradient descent
Stochastic gradient descent
Mini-Batch gradient descent
batch size = training size
batch size = 1
1< batch size < training size
Batch
Epoch

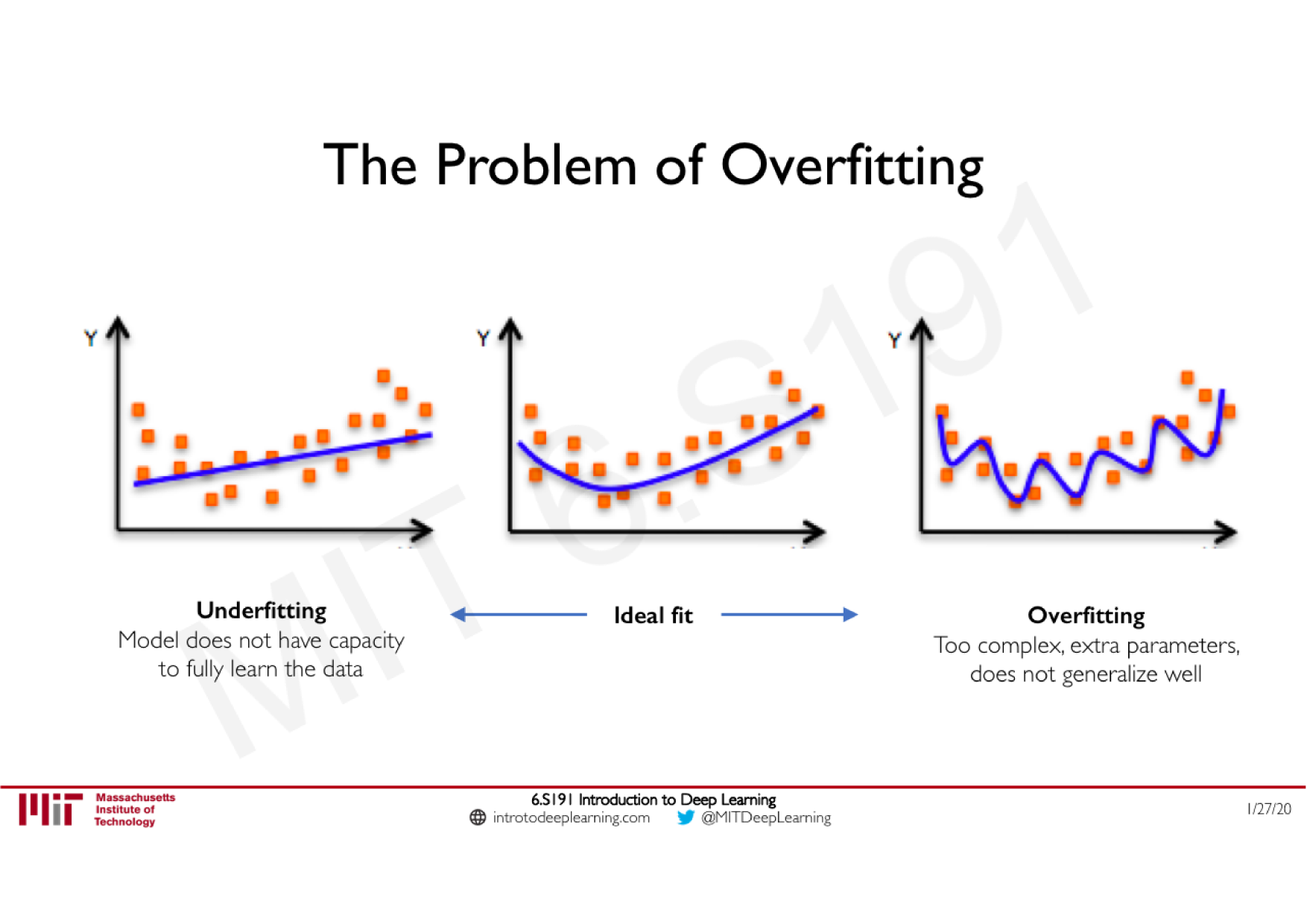


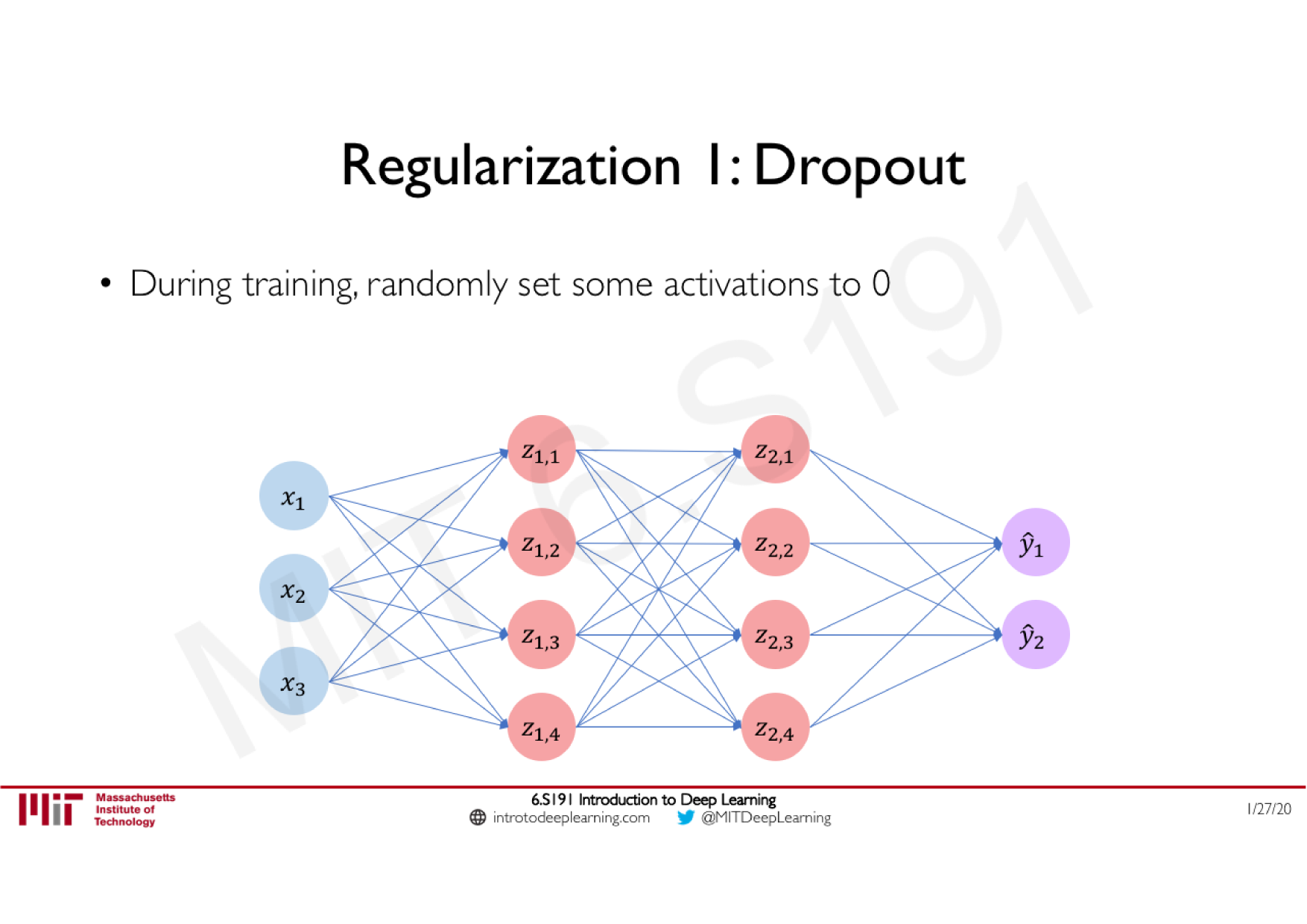
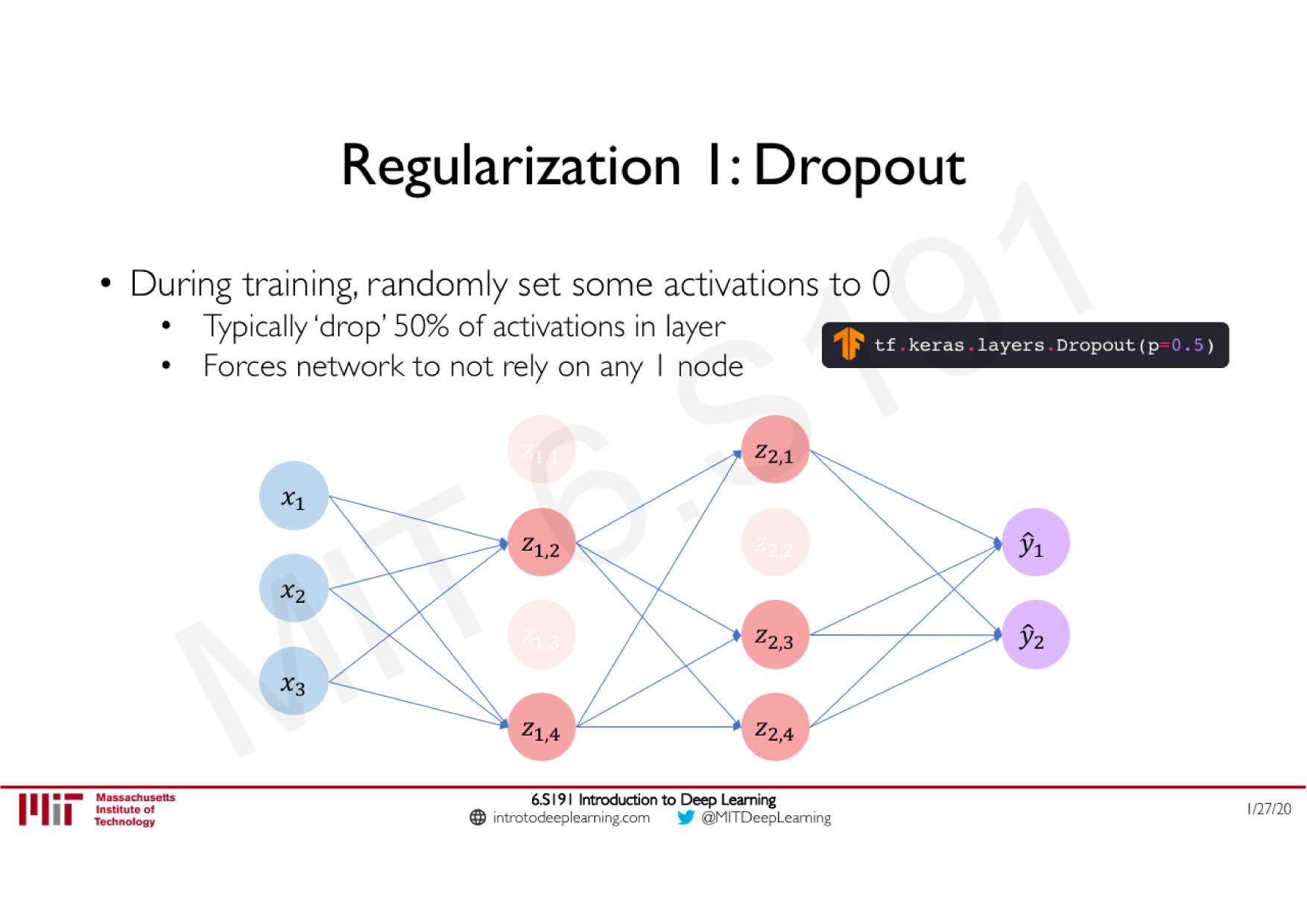
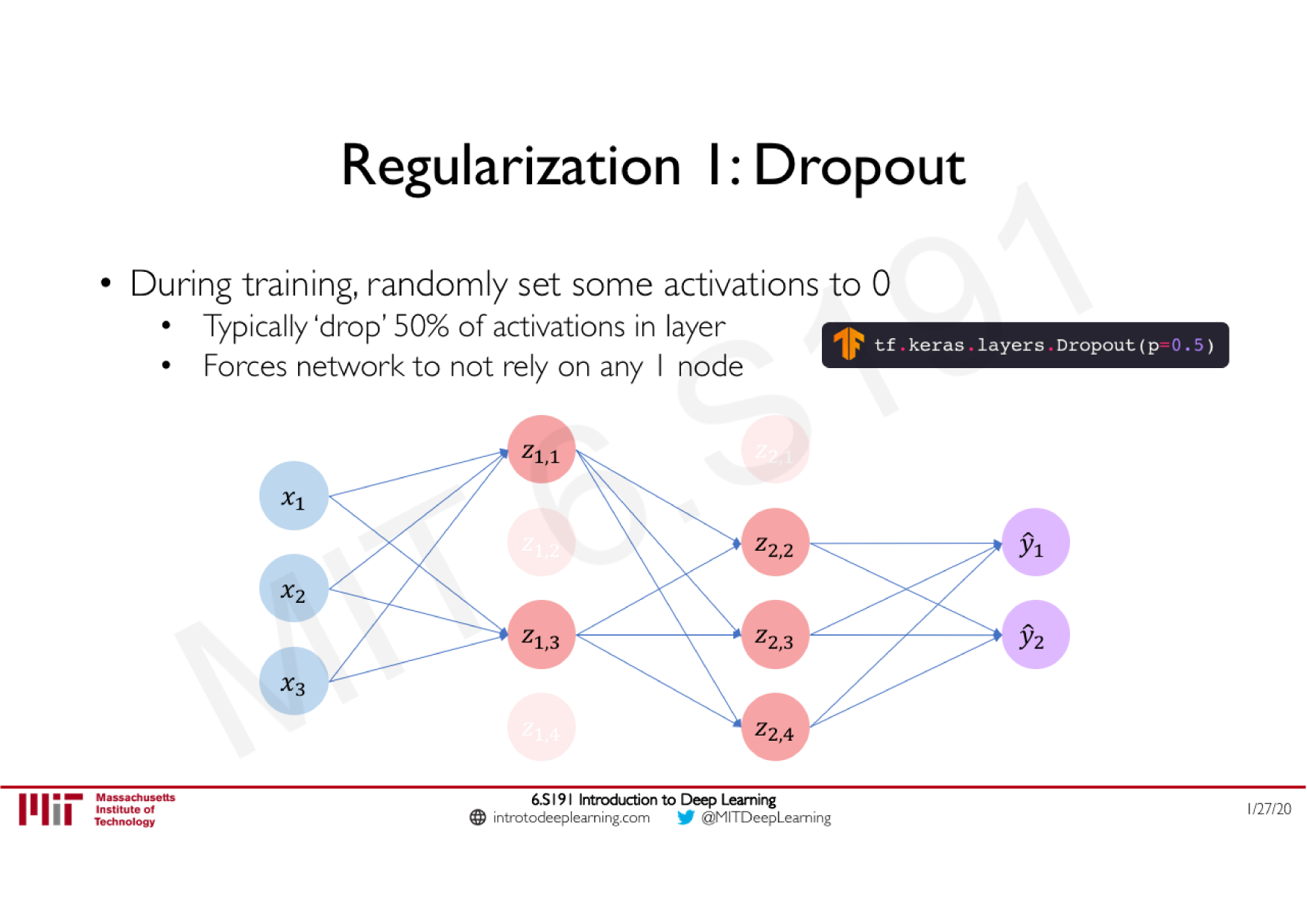
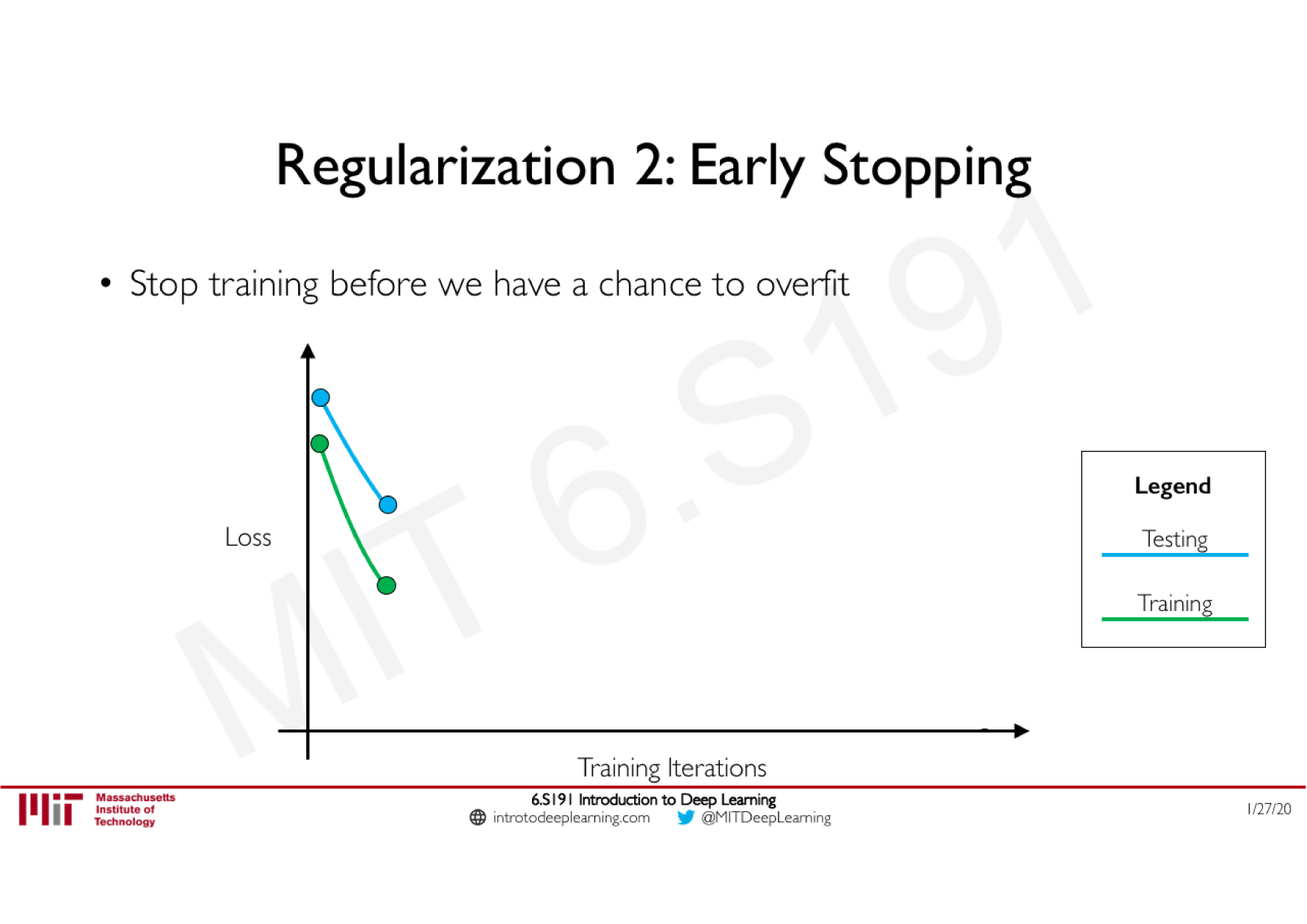
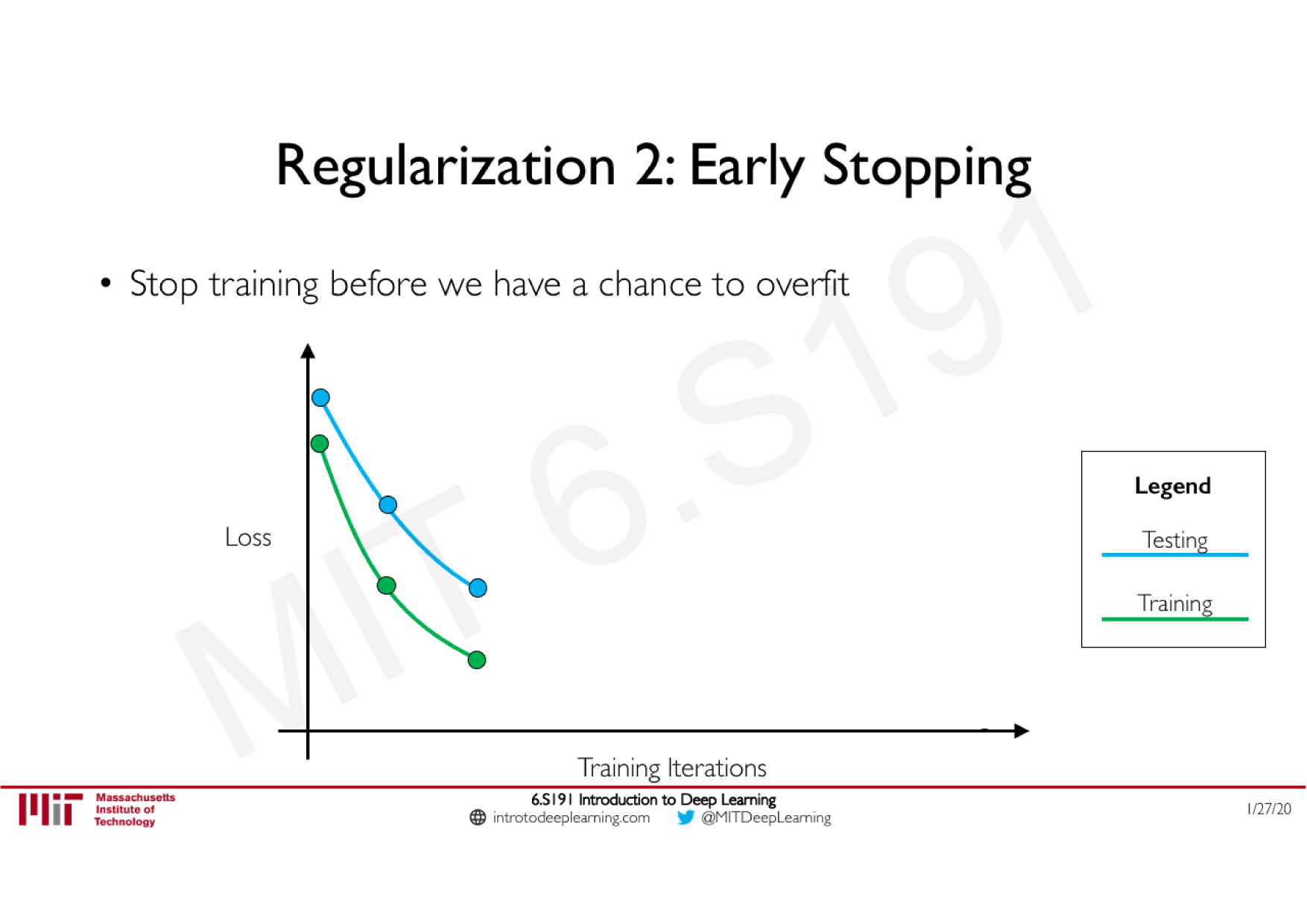
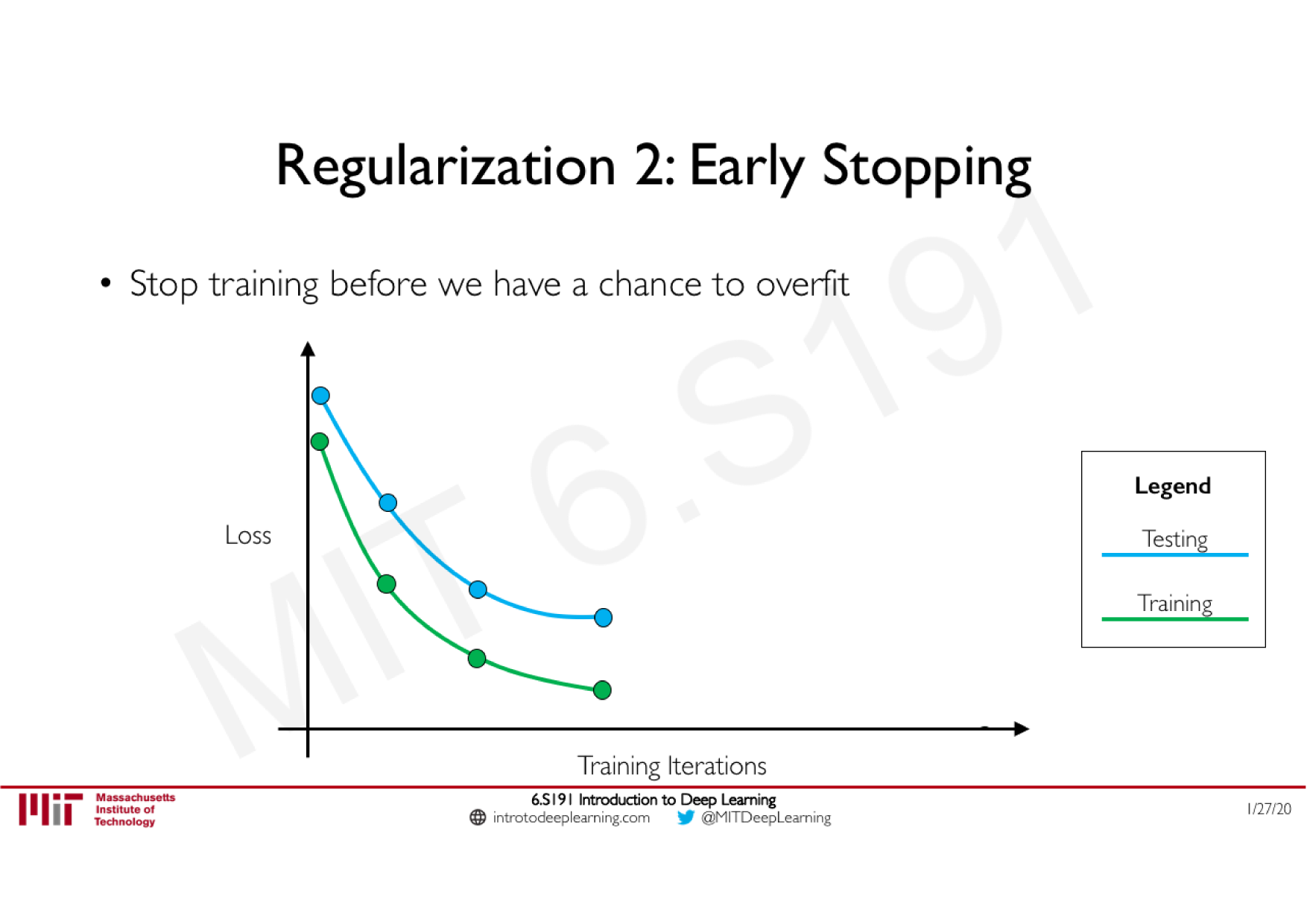
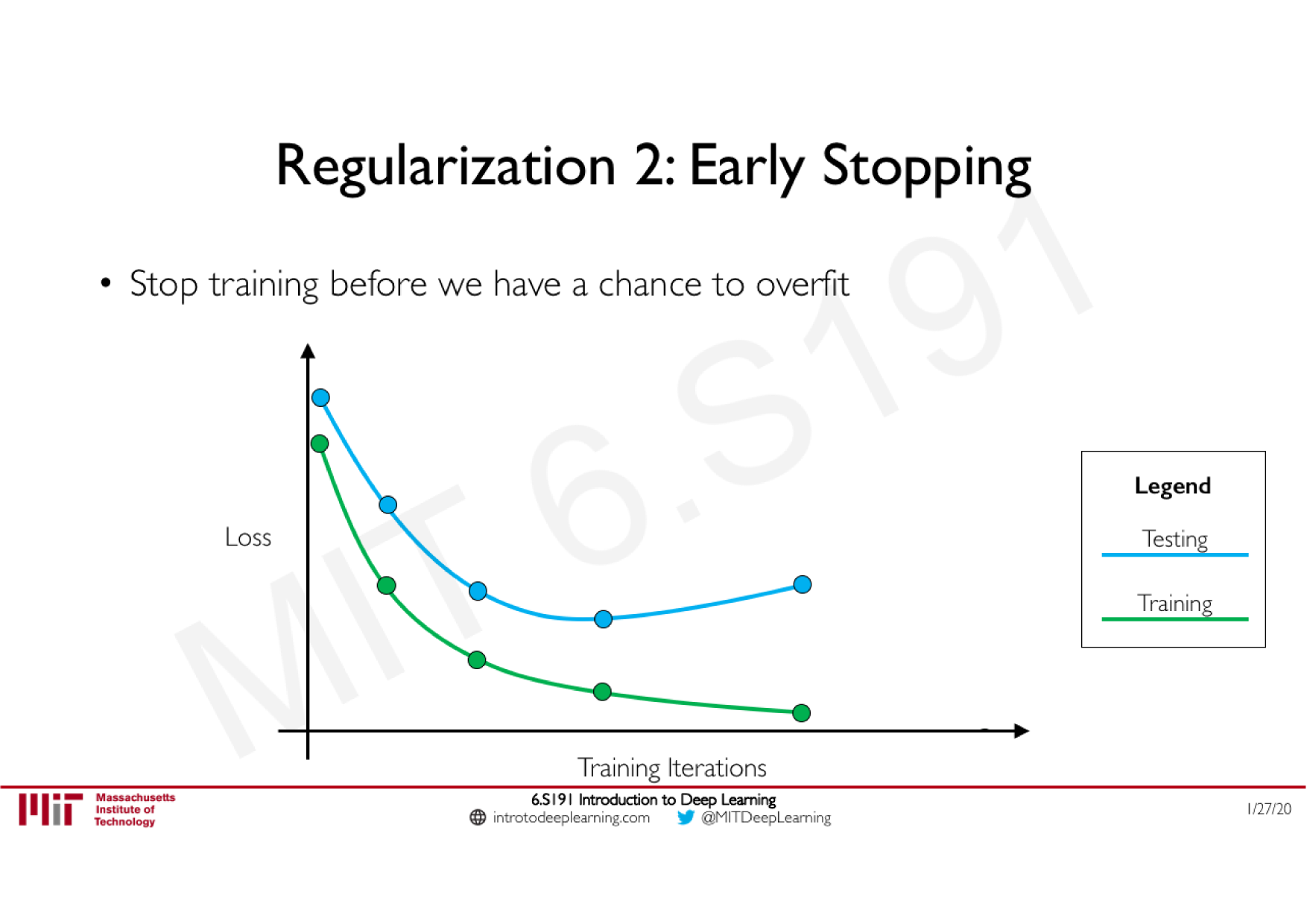
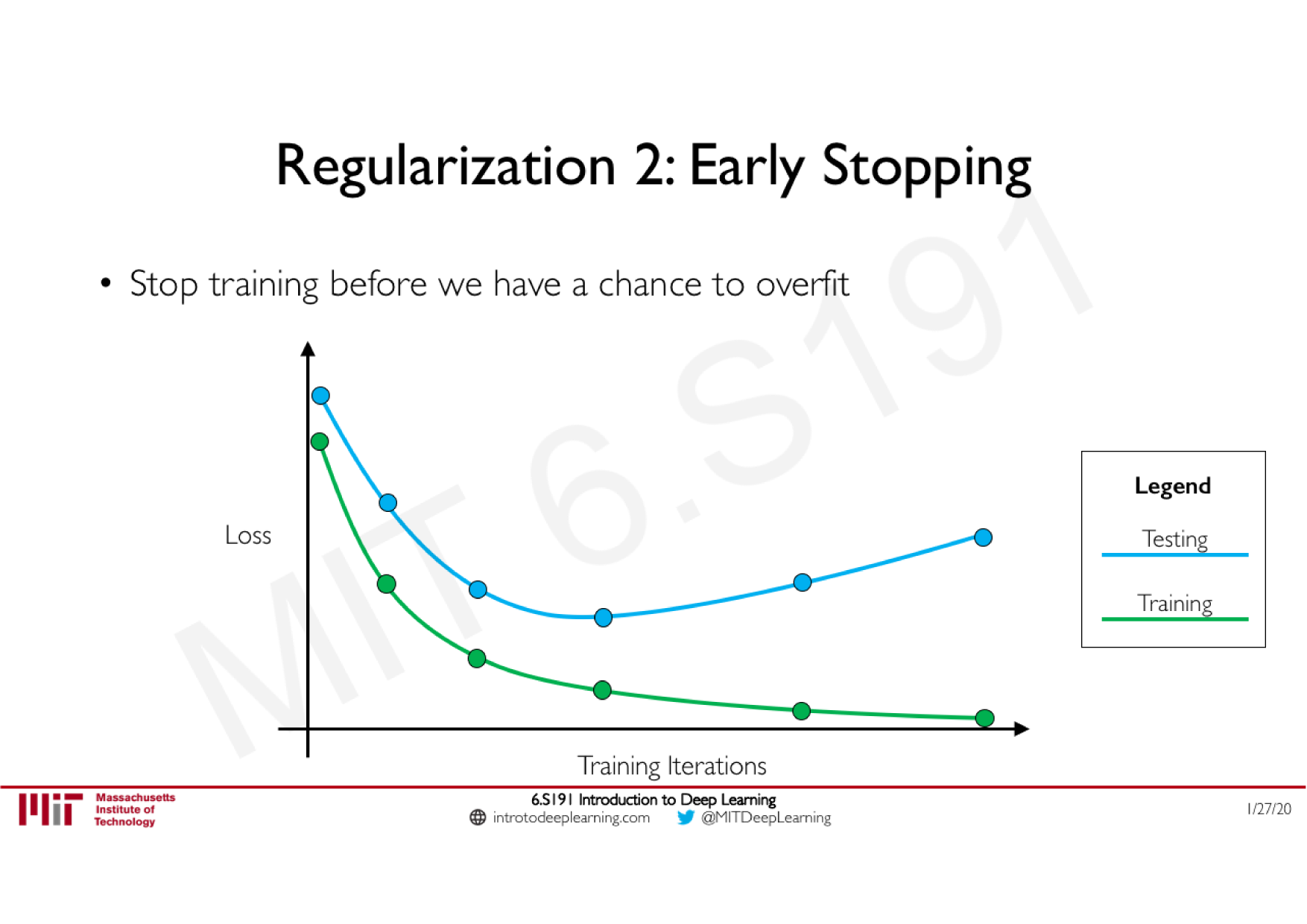
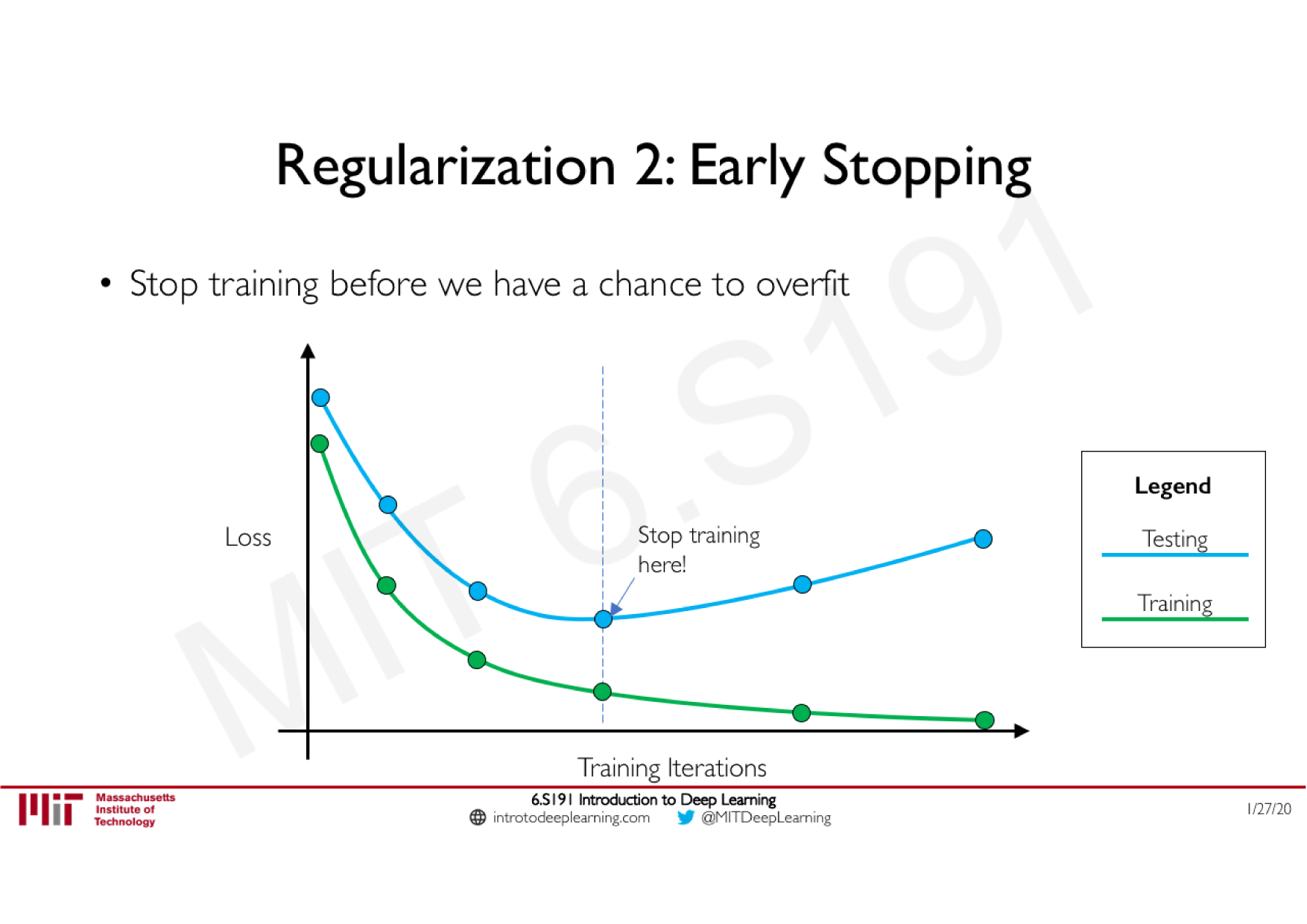
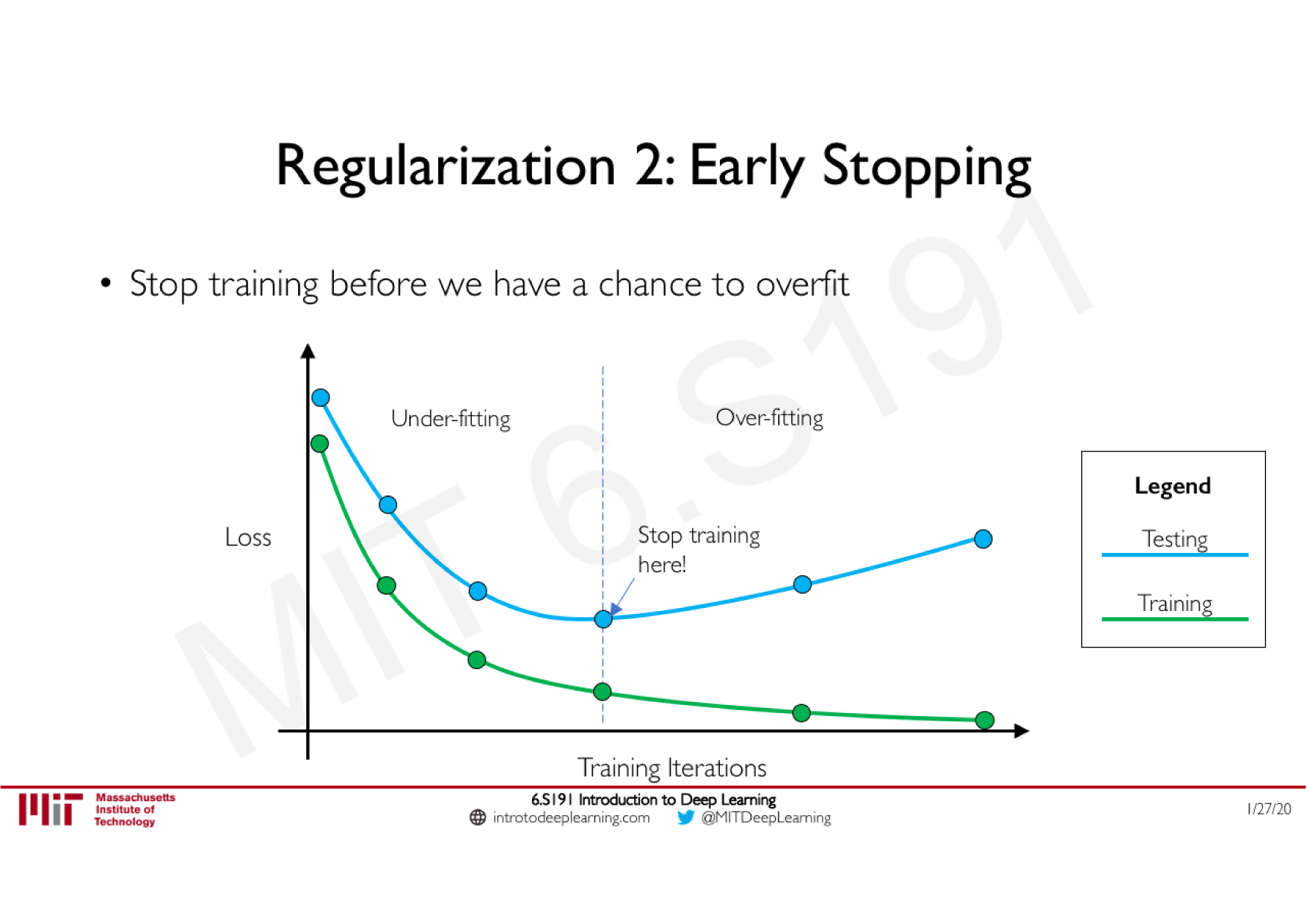
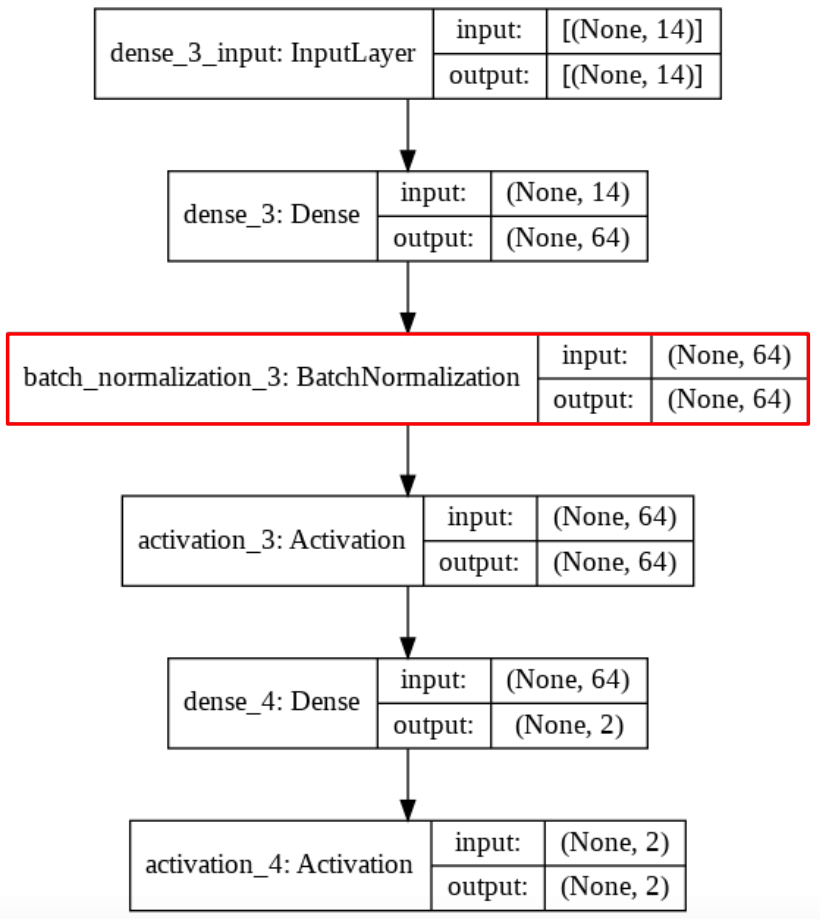
Batch Normalization
Technique courante consistant à appliquer une normalisation à la sortie d'une couche, calculée sur les données de chaque batch
Stabilise le réseau : limite les effets d'explosion ou de disparition du gradient
Principe
Effets
Accèlere les calculs
Effet similaire à une régularisation