Deep Probabilistic Learning
Capturing Uncertainties with Deep Neural Networks

Francois Lanusse @EiffL


Before we dive in...
Let's talk about uncertainty
A Motivating Example: Probabilistic Linear Regression
From this excellent tutorial:
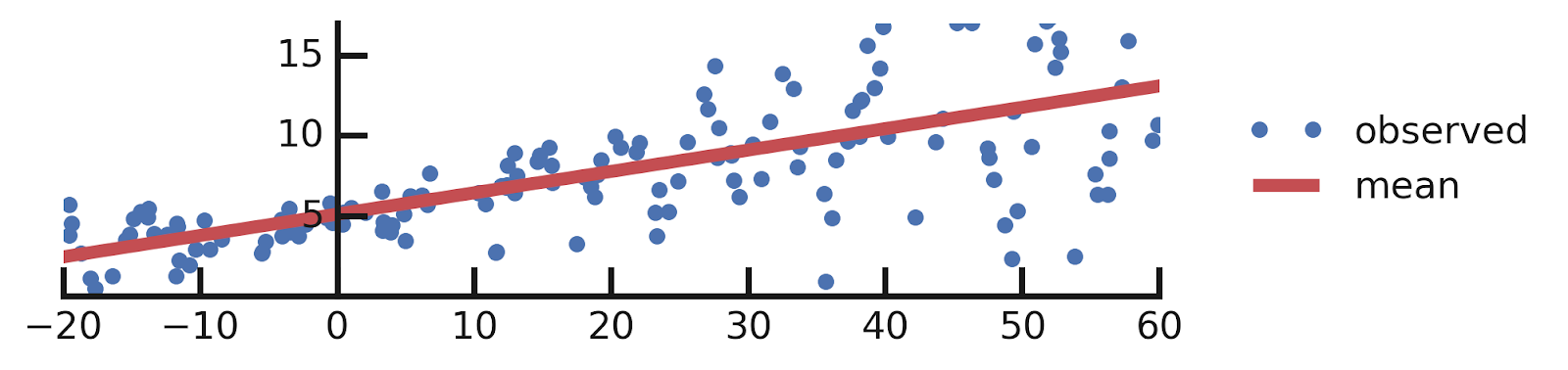
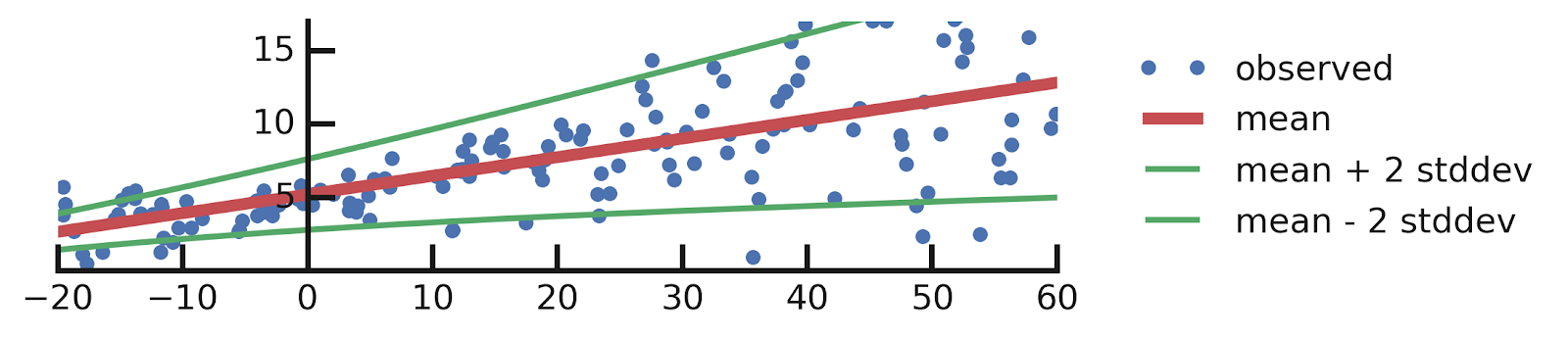
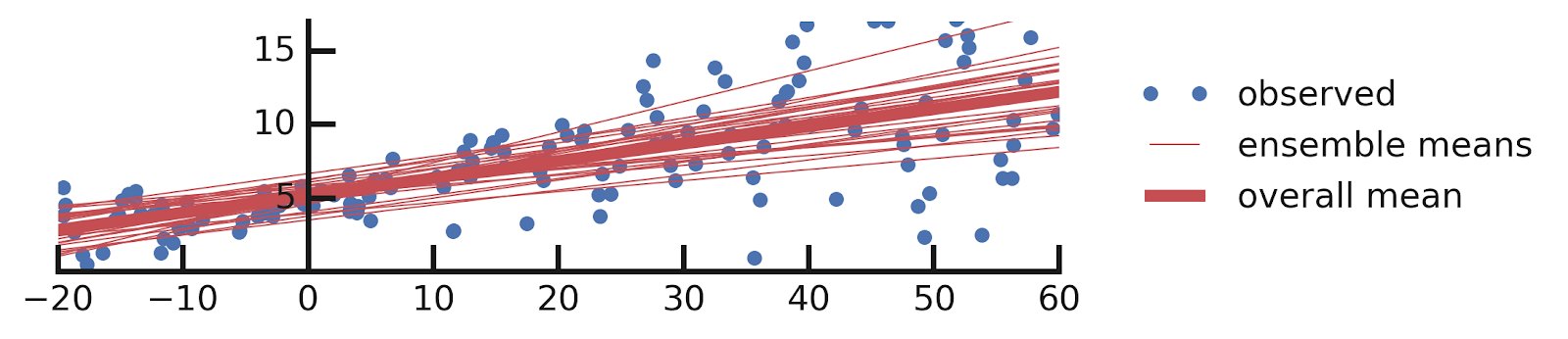

- Linear regression
- Aleatoric Uncertainties
- Epistemic Uncertainties
- Epistemic+ Aleatoric Uncertainties
Modeling Aleatoric Uncertainties
A Motivating Example: Image Deconvolution


Observed y
Unkown x
Ground-based telescope
Hubble Space Telescope

-
Step I: Assemble from data or simulations a training set of images $$\mathcal{D} = \{(x_0, y_0), (x_1, y_1), \ldots, (x_N, y_N) \}$$ => the dataset contains hardcoded assumptions about PSF P, noise n, and galaxy morphology x.
- Step II: Train the neural network under a regression loss of the type: $$ \mathcal{L} = \sum_{i=0}^N \parallel x_i - f_\theta(y_i)\parallel^2 $$


Let's try to understand the neural network output by looking at the loss function
$$ \mathcal{L} = \sum_{(x_i, y_i) \in \mathcal{D}} \parallel x_i - f_\theta(y_i)\parallel^2 \quad \simeq \quad \int \parallel x - f_\theta(y) \parallel^2 \ p(x,y) \ dx dy $$ $$\Longrightarrow \int \left[ \int \parallel x - f_\theta(y) \parallel^2 \ p(x|y) \ dx \right] p(y) dy $$
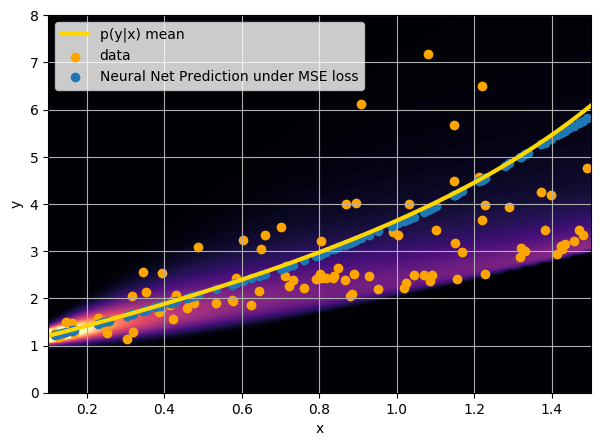
This is minimized when $$f_{\theta^\star}(y) = \int x \ p(x|y) \ dx $$
i.e. when the network is predicting the mean of p(x|y).

credit: Venkatesh Tata
Let's start with binary classification
=> This means expressing the posterior as a Bernoulli distribution with parameter predicted by a neural network
How do we adjust this parametric distribution to match the true posterior ?
Step 1: We neeed some data
cat or dog image
label 1 for cat, 0 for dog
Probability of including cats and dogs in my dataset
Implicit prior

Image search results for cats and dogs
Implicit likelihood
A distance between distributions: the Kullback-Leibler Divergence
Step 2: We need a tool to compare distributions
Minimizing this KL divergence is equivalent to minimizing the negative log likelihood of the model
In our case of binary classification:
We recover the binary cross entropy loss function !
The Probabilistic Deep Learning Recipe
- Express the output of the model as a distribution
- Optimize for the negative log likelihood
- Maybe adjust by a ratio of proposal to prior if the training set is not distributed according to the prior
- Profit!
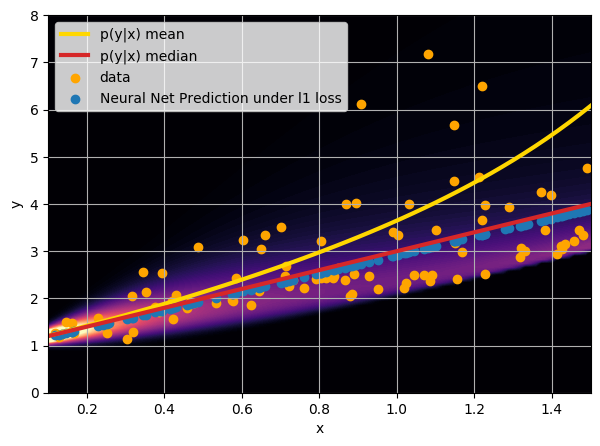
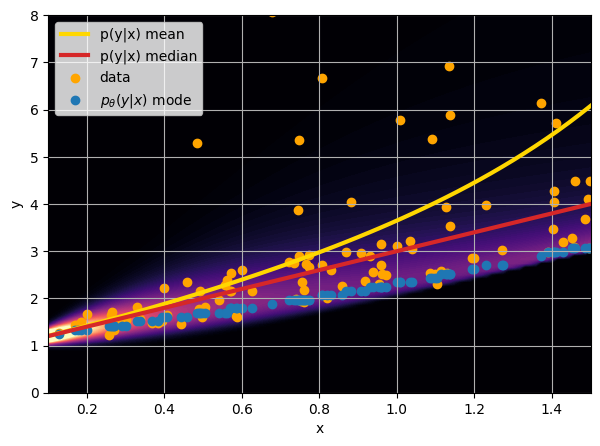
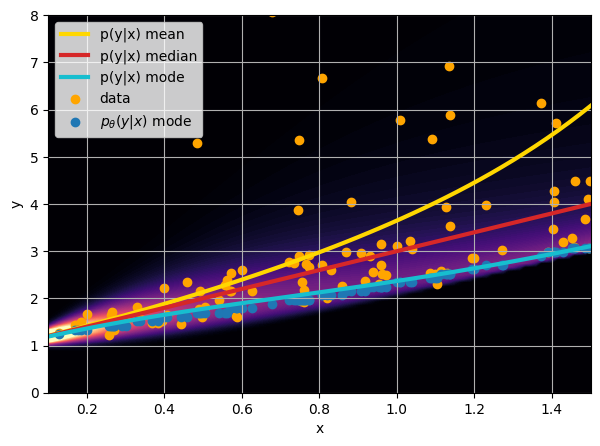
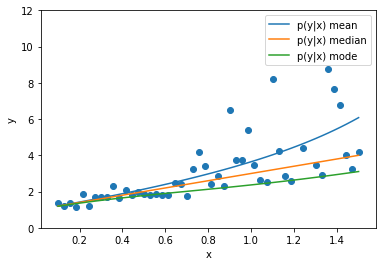
Let us consider a toy regression example
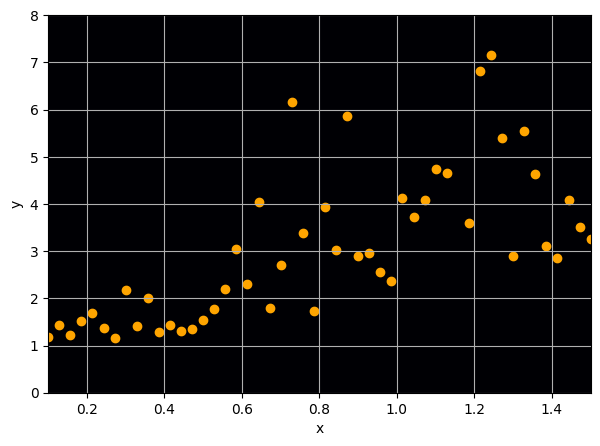
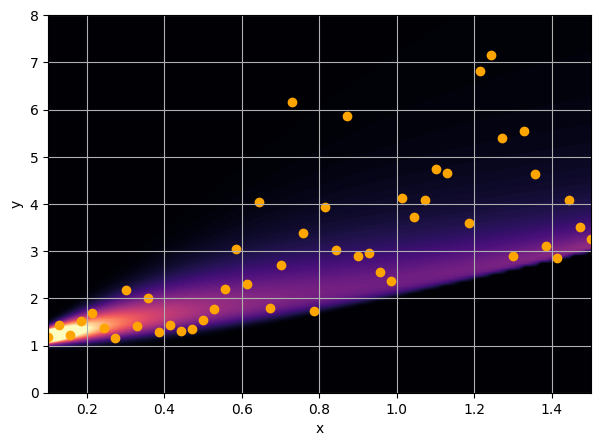
There are intrinsic uncertainties in this problem, at each x there is a full
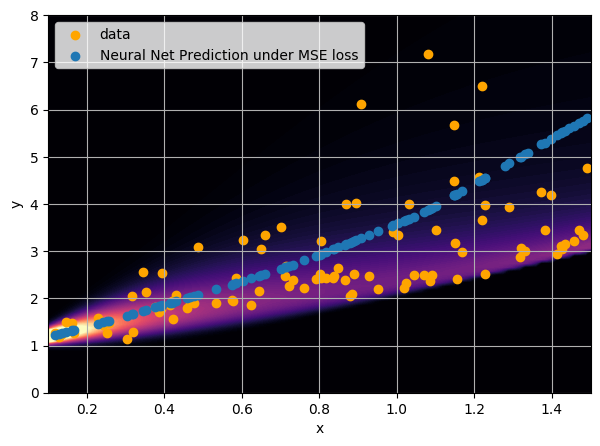
- Option 1) Train a neural network to learn a function under an MSE loss:
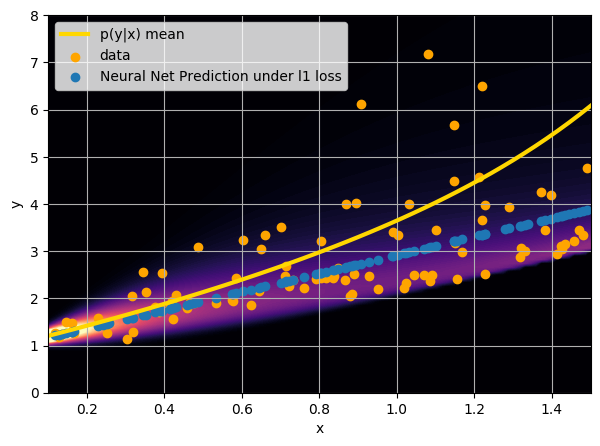
- Option 2) Train a neural network to learn a function under an l1 loss:
- Option 3) Train a neural network to learn a distribution using a Maximum Likelihood loss
I have a set of data points {x, y} where I observe x and want to predict y.
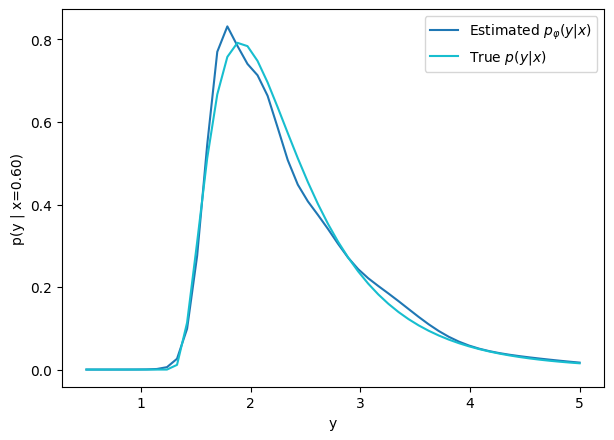
How do we model distributions?
We need a parametric conditional distribution to
compute
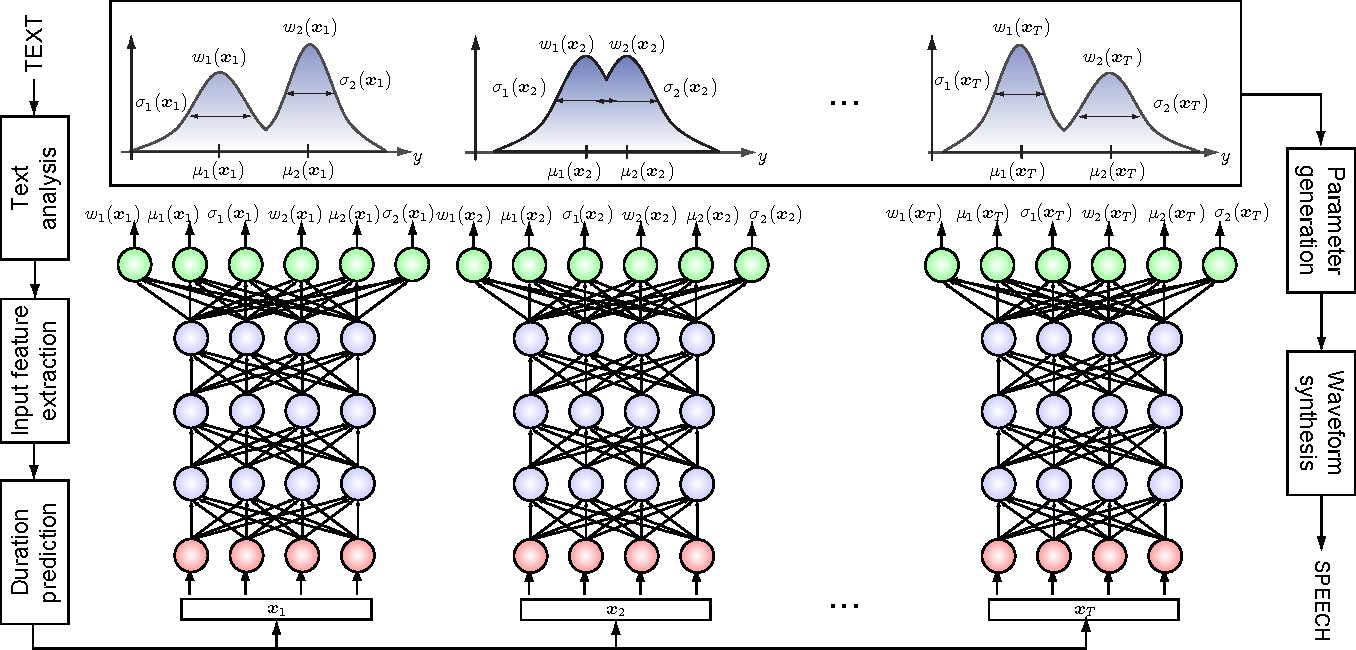
- Mixture Density Networks
Bishop 1994
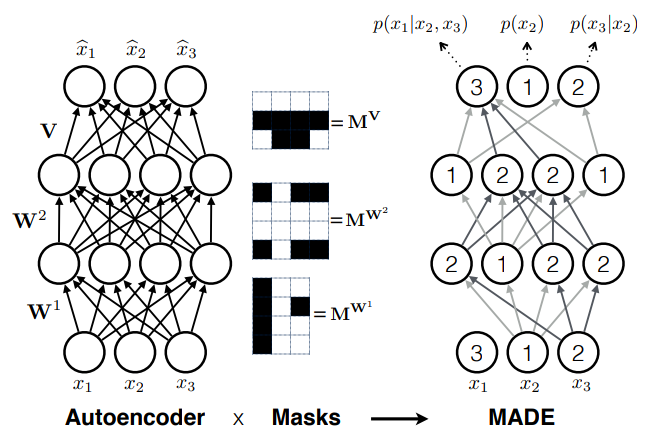
- Autoregressive models
e.g. MADE (Germain et al. 2015)
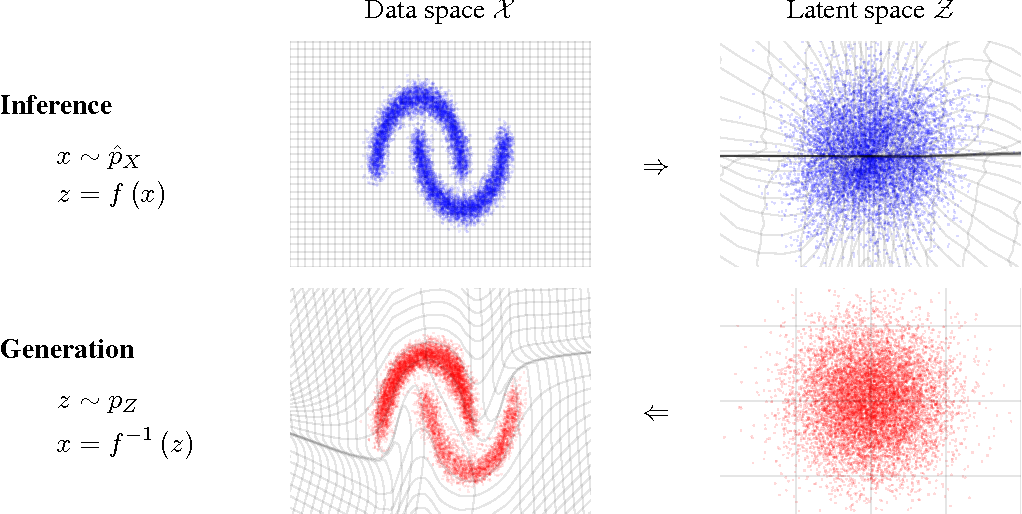
- Normalizing Flows
e.g. MAF (Papamakarios et al. 2017)
How do we do this in practice?
import tensorflow as tf
import tensorflow_probability as tfp
tfd = tfp.distributions
# Build model.
model = tf.keras.Sequential([
tf.keras.layers.Dense(1+1),
tfp.layers.IndependentNormal(1),
])
# Define the loss function:
negloglik = lambda x, q: - q.log_prob(x)
# Do inference.
model.compile(optimizer='adam', loss=negloglik)
model.fit(x, y, epochs=500)
# Make predictions.
yhat = model(x_tst)Let's try it out!
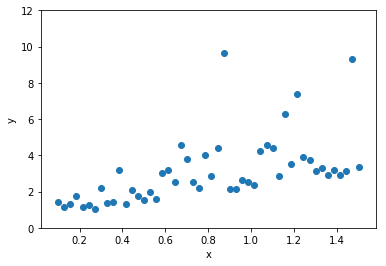
This is our data
Build a regression model for y gvien x
import tensorflow.keras as keras
import tensorflow_probability as tfp
# Number of components in the Gaussian Mixture
num_components = 16
# Shape of the distribution
event_shape = [1]
# Utility function to compute how many parameters this distribution requires
params_size = tfp.layers.MixtureNormal.params_size(num_components, event_shape)
gmm_model = keras.Sequential([
keras.layers.Dense(units=128, activation='relu', input_shape=(1,)),
keras.layers.Dense(units=128, activation='tanh'),
keras.layers.Dense(params_size),
tfp.layers.MixtureNormal(num_components, event_shape)
])
negloglik = lambda y, q: -q.log_prob(y)
gmm_model.compile(loss=negloglik, optimizer='adam')
gmm_model.fit(x_train.reshape((-1,1)), y_train.reshape((-1,1)),
batch_size=256, epochs=20)A Concrete Example: Estimating Masses of Galaxy Clusters
Try it out at this notebook


We want to make dynamical mass measurements using information from member galaxy velocity dispersion and about the radial distance distribution (see Ho et al. 2019).
First attempt with an MSE loss
regression_model = keras.Sequential([
keras.layers.Dense(units=128, activation='relu', input_shape=(14,)),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dense(units=64, activation='tanh'),
keras.layers.Dense(units=1)
])
regression_model.compile(loss='mean_squared_error', optimizer='adam')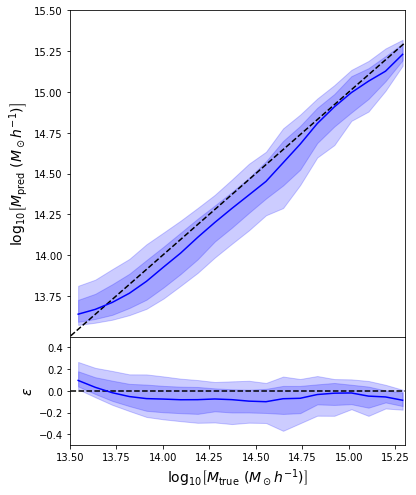
- Simple Dense network using 14 features derived from galaxy positions and velocity information
- We see that the predictions are biased compared to the true value of the mass... Not good.
Second attempt: Probabilistic Modeling
num_components = 16
event_shape = [1]
model = keras.Sequential([
keras.layers.Dense(units=128, activation='relu', input_shape=(14,)),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dense(units=64, activation='tanh'),
keras.layers.Dense(tfp.layers.MixtureNormal.params_size(num_components, event_shape)),
tfp.layers.MixtureNormal(num_components, event_shape)
])
negloglik = lambda y, p_y: -p_y.log_prob(y)
model.compile(loss=negloglik, optimizer='adam')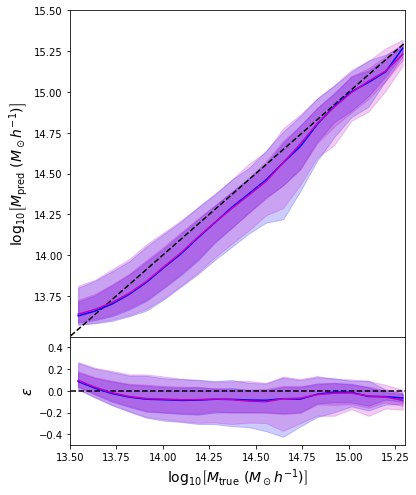
- Same Dense network but now using a Mixture Density output.
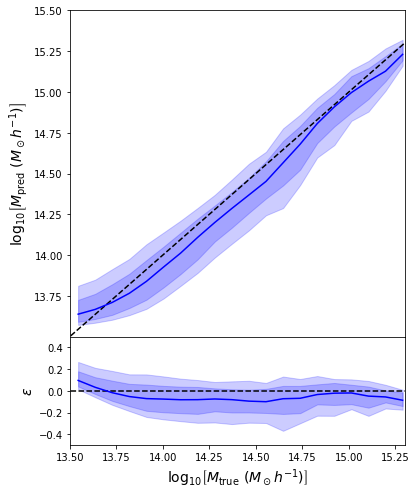
- Using the mean of the predicted distribution as our mass estimate: We see the exact same behaviour
What am I doing wrong???
Back to our Dynamical Mass Predictions
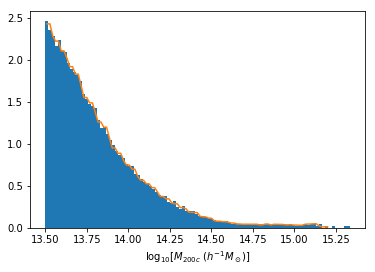
Distribution of masses in our training data
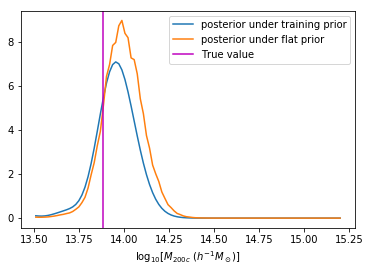
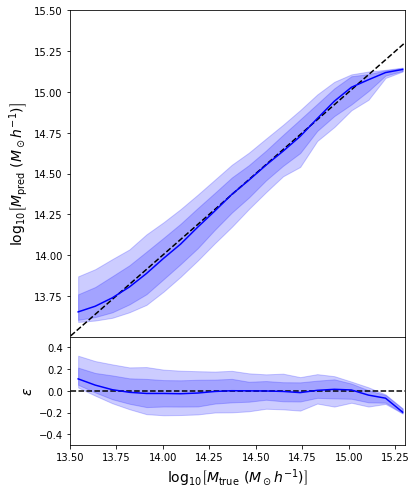
We can reweight the predictions for a desired prior
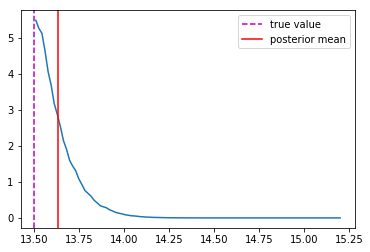
Last detail, use the mode instead of the mean posterior
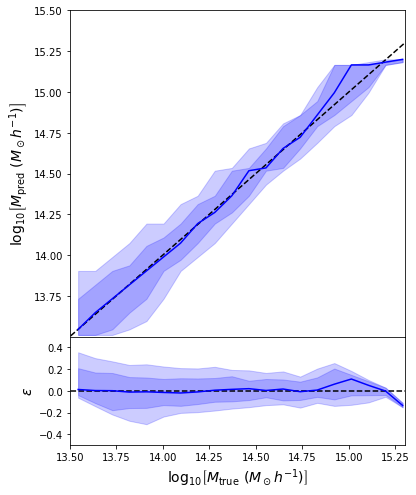
Takeaway Message
- Using a model that outputs distributions instead of scalars is always better!
- It's 2 lines of TensorFlow Probability
- Careful about interpreting these distributions as a Bayesian posterior, the training set acts as an Interim Prior, not necessarily matching your Bayesian prior.
Modeling Epistemic Uncertainties
A Quick reminder
From this excellent tutorial:
- Linear regression
- Aleatoric Uncertainties
- Epistemic Uncertainties
- Epistemic+ Aleatoric Uncertainties
The idea behind Bayesian Neural Networks
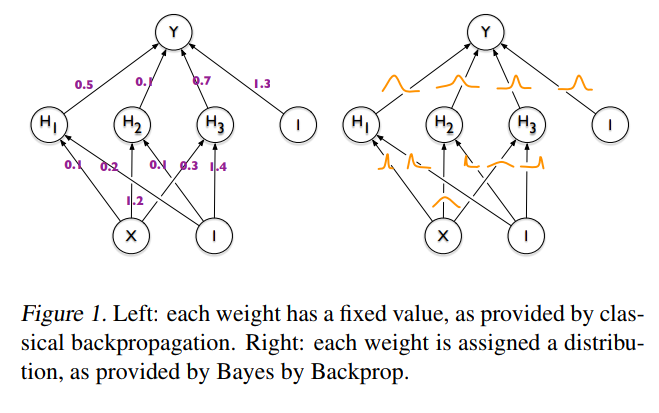
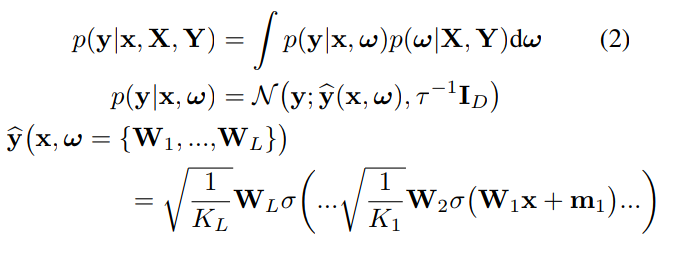
Given a training set D = {X,Y}, the predictions from a Neural Network can be expressed as:
Weight Estimation by Maximum Likelihood
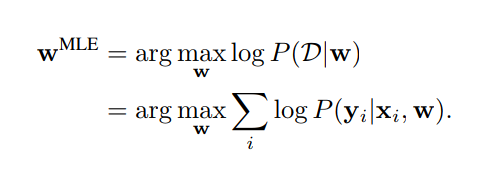
Weight Estimation by Variational Inference
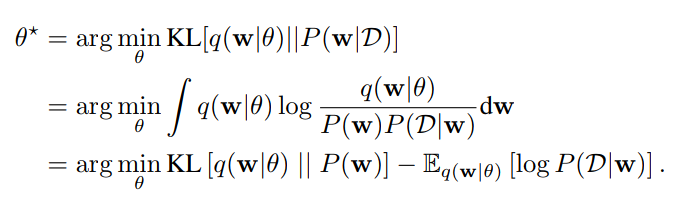
A first approach to BNNs:
Bayes by Backprop (Blundel et al. 2015)
-
Step 1: Assume a variational distribution for the weights of the Neural Network
-
Step 2: Assume a prior distribution for these weights
- Step 3: Learn the parameters of the variational distribution by minimizing the ELBO
What happens in practice
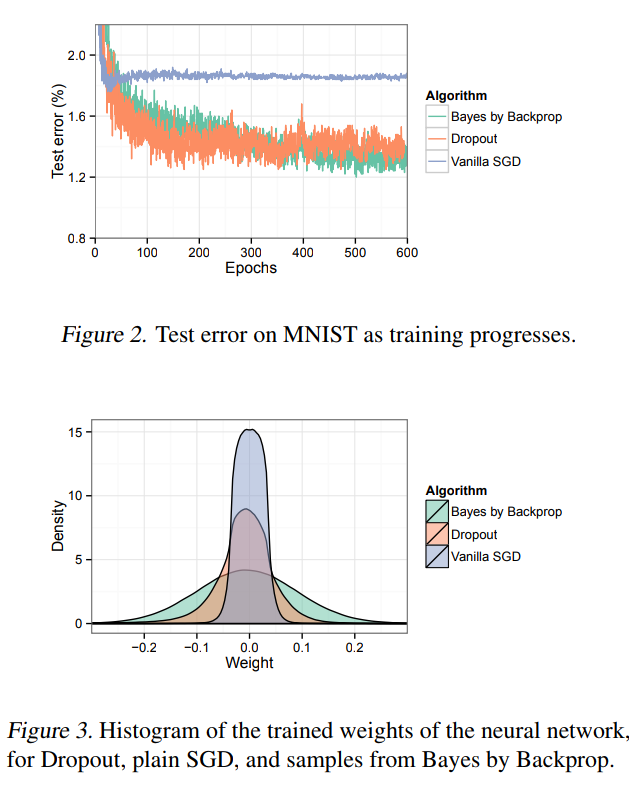
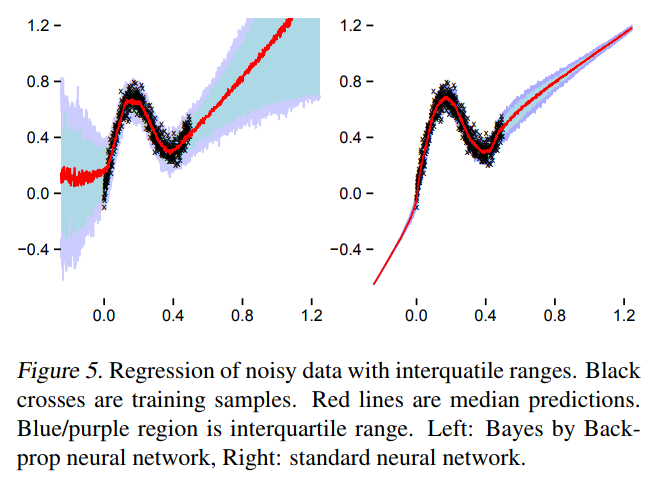
TensorFlow Probability implementation
A different approach:
Dropout as a Bayesian Approximation (Gal & Ghahramani, 2015)
Quick reminder on dropout
Hinton 2012, Srivastava 2014


Variational Distribution of Weights under Dropout
-
Step 1: Assume a Variational Distribution for the weights
-
Step 2: Assume a Gaussian prior for the weights, with "length scale" l
- Step 3: Fit the parameters of the variational distribution by optimizing the ELBO

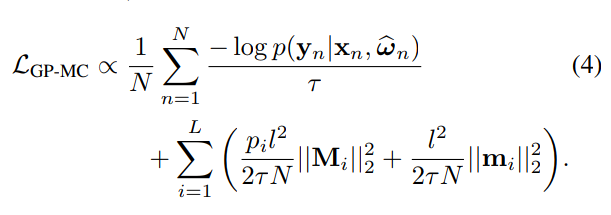
Example
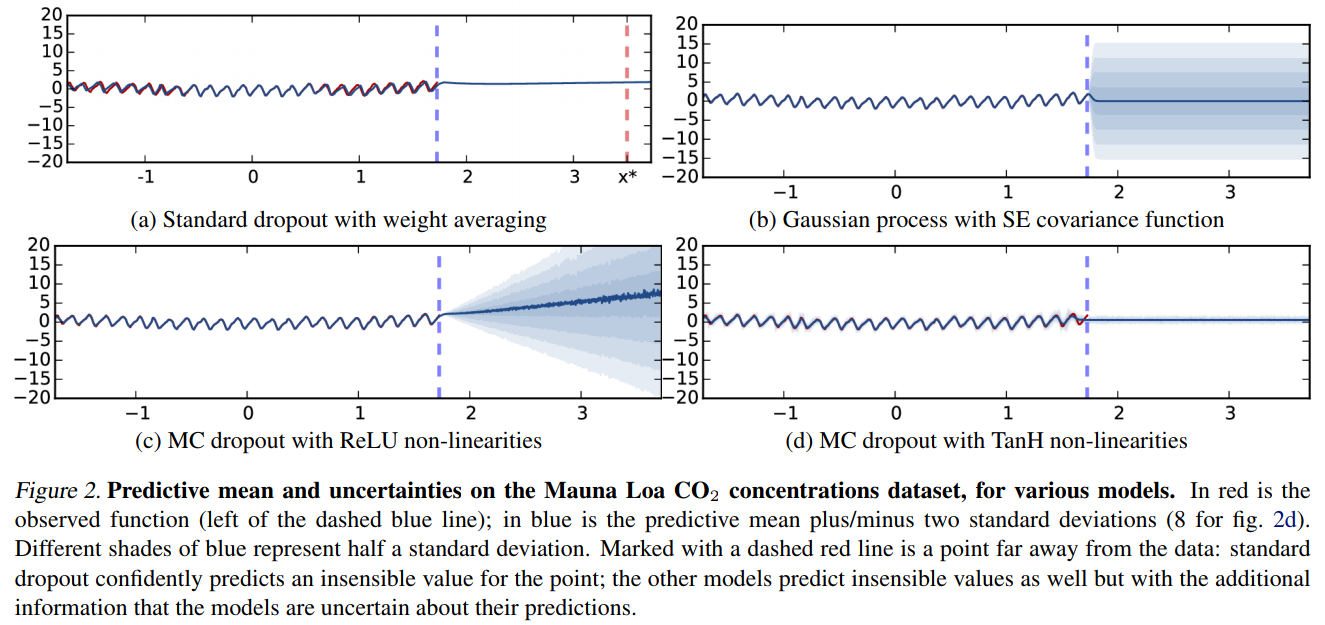
These are not the only methods
- Noise contrastive priors: https://arxiv.org/abs/1807.09289
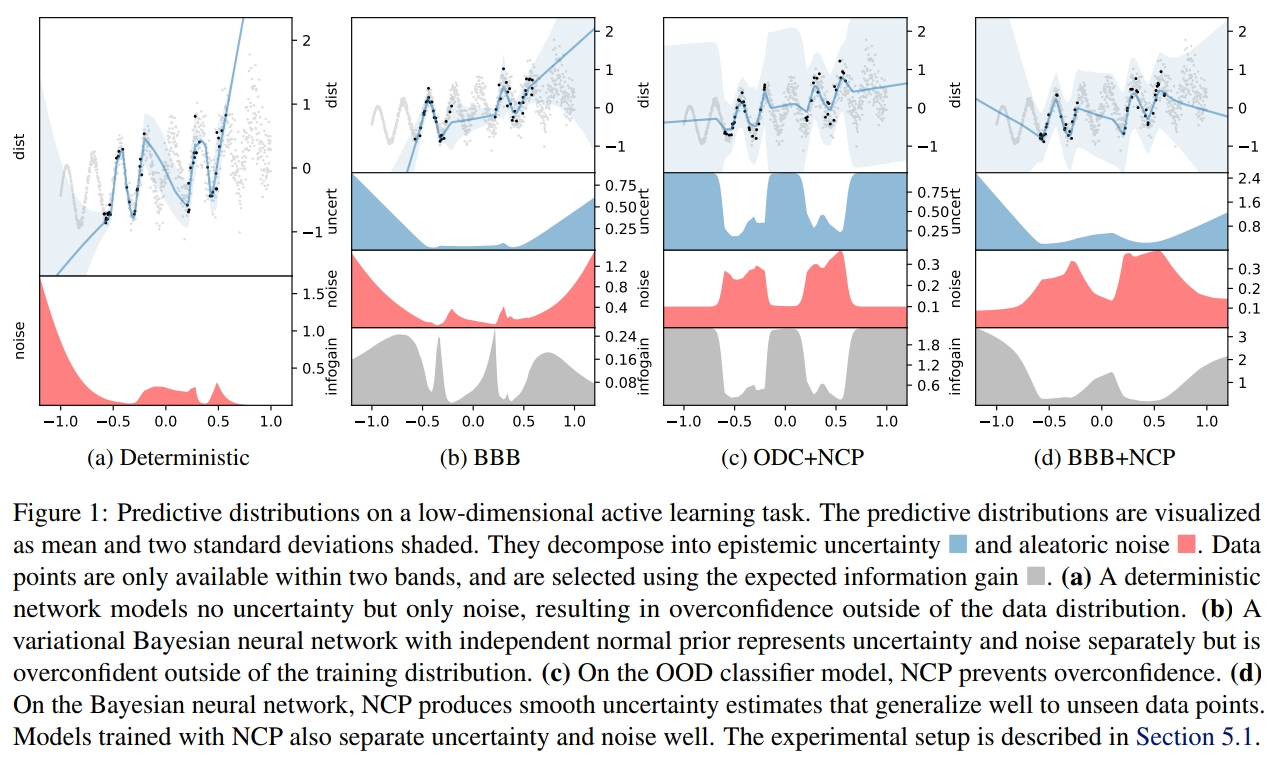
Takeaway message on Bayesian Neural Networks
- They give a practical way to model epistemic uncertainties, aka unknowns unknows, aka errors on errors
- Be very careful when interpreting their output distributions, they are Bayesian posterior, yes, but under what priors?
- Having access to model uncertainties can be used for active sampling
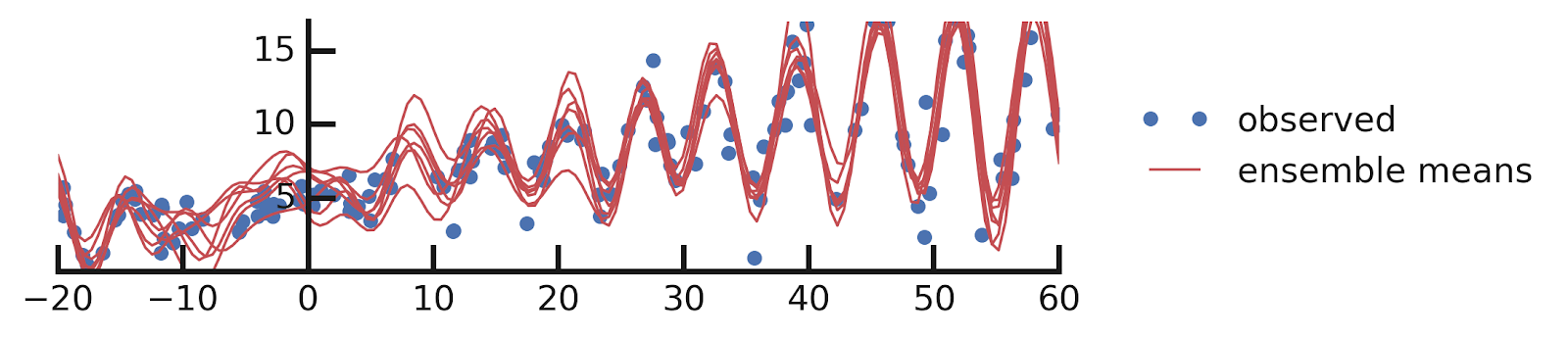
Putting it all together
