Safe Reinforcement Learning with Adversarial Policy Evaluation
Elena Smirnova

Joint work with Elvis Dohmatob and Jeremie Mary
Introduction to RL

Environment
Agent
Action
Next state
Reward
Current state
How to learn safely?
Environment is unknown!
Learn safely under uncertainty
Prepare for the worst case
But not too conservative!

?
Overview
Safety w.r.t. finite amount of experience
Approximation for continuous action space
Safety + SOTA!
SOTA
Adversarial Bellman operator
Dynamic Programming
Introduction to RL
Markov Decision Process
$$M := (\mathcal{S}, \mathcal{A}, P, r, \gamma)$$
- state space \(\mathcal{S}\)
- action space \(\mathcal{A}\)
- transition matrix \(\left(P(s'|s,a)\right)_{s,s' \in \mathcal{S}, a \in \mathcal{A}}\): probability of moving to state \(s'\) given action \(a\) in state \(s\)
- reward \(r(s,a)\), bounded
- discount factor \(\gamma \in [0,1)\)
Policy and Value
Policy \( \pi: \mathcal{S} \rightarrow \Delta_\mathcal{A}\)
Value function \( V: \mathcal{S} \rightarrow \mathbb{R} \)
How to act in a state
How good is a state
\(\pi(a|s)\) is a probability of chosing action \(a\) in state \(s\)
Cliff walking
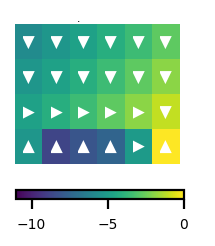
MDP
Policy and Value
RL objective
Maximize value at each state
RL algorithms
Dynamic Programming
Policy Gradient
Bellman operator
Policy and Value Iteration
SOTA: Actor-Critic algorithms
Policy Gradient Theorem
REINFORCE
SOTA: Trust Region Policy Optimization
Dynamic programming
Bellman operator \( \mathcal{T}^\pi: V \rightarrow V\)
Bellman equation
Q-value of an action * how often this action is taken
Bellman operator
Fixed point
Exists and unique
\(\gamma\)-contraction
Useful to show convergence
Greedy policy
One-step improvement
Set of greedy policies
Greedy policy choses action that maximizes Q-value
Modified Policy Iteration
Policy improvement
(Partial) Policy evaluation
\(m = \infty\) policy iteration
\(m=1\) value iteration
Basic DP algorithm!
Approximate Modified Policy Iteration
Policy improvement
Policy evaluation
Errors
RL problem
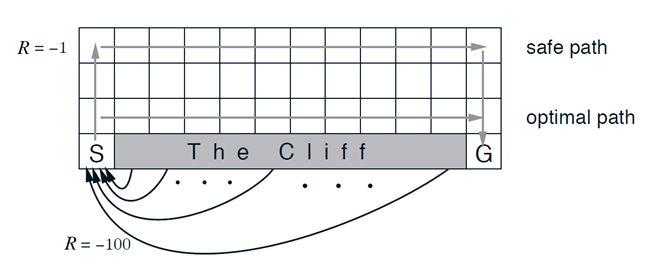
Optimization ~ mountain descent
RL ~ mountain descent in a bad weather

Safety is important
Fastest descent might be dangerous due to uncertainty over the landscape...
Safer for learner
For expert
Approximate Modified Policy Iteration
Policy improvement
Policy evaluation
Errors
AMPI errors
Estimation errors
finite sample of data
Function approximation errors
neural network value function
Difference between the exact BO and what we compute
Lower bound
The value of BO is uncertain!
Lower bound
Upper bound
Risk-averse
Exact BO
Risk-seeking
Adversarial Bellman operator
Evaluate with an adversarial policy

Convex duality
Convex conjugate of \(D_{KL}\)
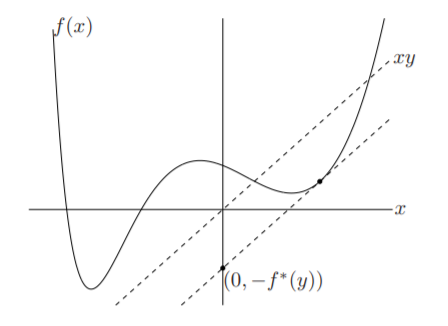
Convex duality
Convex conjugate of \(D_{KL}\) is logsumexp
Maximizing policy is Boltzmann policy
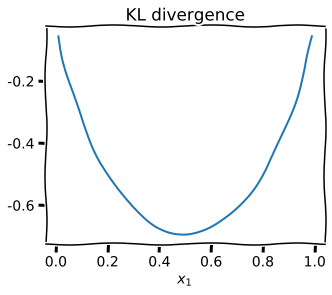
Adversarial policy
Re-weight policy action probabilities opposite to Q-values
adversarial temperature
Optimal adversarial temperature
The right level of conservatism w.r.t. current uncertainty \(\epsilon\)
1-D convex optimization (scipy.optimize.bisect)
Too conservative
Too optimistic
Safe Modified Policy Iteration
Policy improvement
(Lower bound) Policy evaluation
Slower but safer learning
Convergence
Sub-optimality bound

Define the decrease rate \( \rho = \lim \epsilon_N / \epsilon_{N-1}\).
Convergence
- Slow convergence. If \(\;\rho > \gamma\), then \[ \mathcal \|\tilde{V}_{N}-V^*\|_\infty = \mathcal O(r_N).\]
Sub-optimality bound
- (Almost) linear convergence. If \(\;\rho \le \gamma\), then \[\mathcal \|\tilde{V}_{N}-V^*\|_\infty = \begin{cases}\mathcal{O}(\gamma^N), \ \text{if} \ \rho <\gamma,\\ \mathcal{O}(N\gamma^N), \ \text{if} \ \rho = \gamma \end{cases}\]
Convergence
where \(V_t\) is the value function computed with exact evaluation step.
Safety guarantee
Adversarial BO and Policy
Safe Modified Policy Iteration
Convergence

Application to continuous control
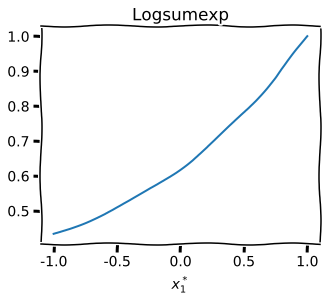
The normalization constant of the adversarial policy is an intractable integral
Continuous action space
Adversarial BO
Risk-neutral \(\lambda \rightarrow \infty\)
Risk-seeking \(\lambda > 0\)
Risk-averse \(\lambda < 0\)
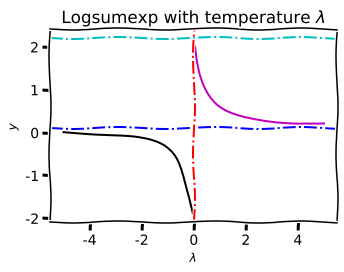
log-moment generating function
Approximate Adversarial BO
Taylor series of logsumexp up to the 2nd order at \(\lambda \rightarrow \infty\)
ABO ~ BO + variance penalization
Safe reward shaping
ABO ~ BO + variance penality = reward change
For \(\lambda > 0\) encourages to visit states with smaller variance
One-line change to implement safety!
Gaussian policies
Variance for safe reward shaping
Using Taylor expansion of Q-values around mean action
Approximate BO
Safe reward shaping
Variance of Q-values

SOTA: regularized RL
Regularized Bellman operator
Entropy regularizer
Safe Soft Actor-Critic
Soft Actor-Critic + Safe Reward Shaping
Cautious short-term and optimistic long-term!
Entropy-regularized SOTA
Simple reward modification

Hopper
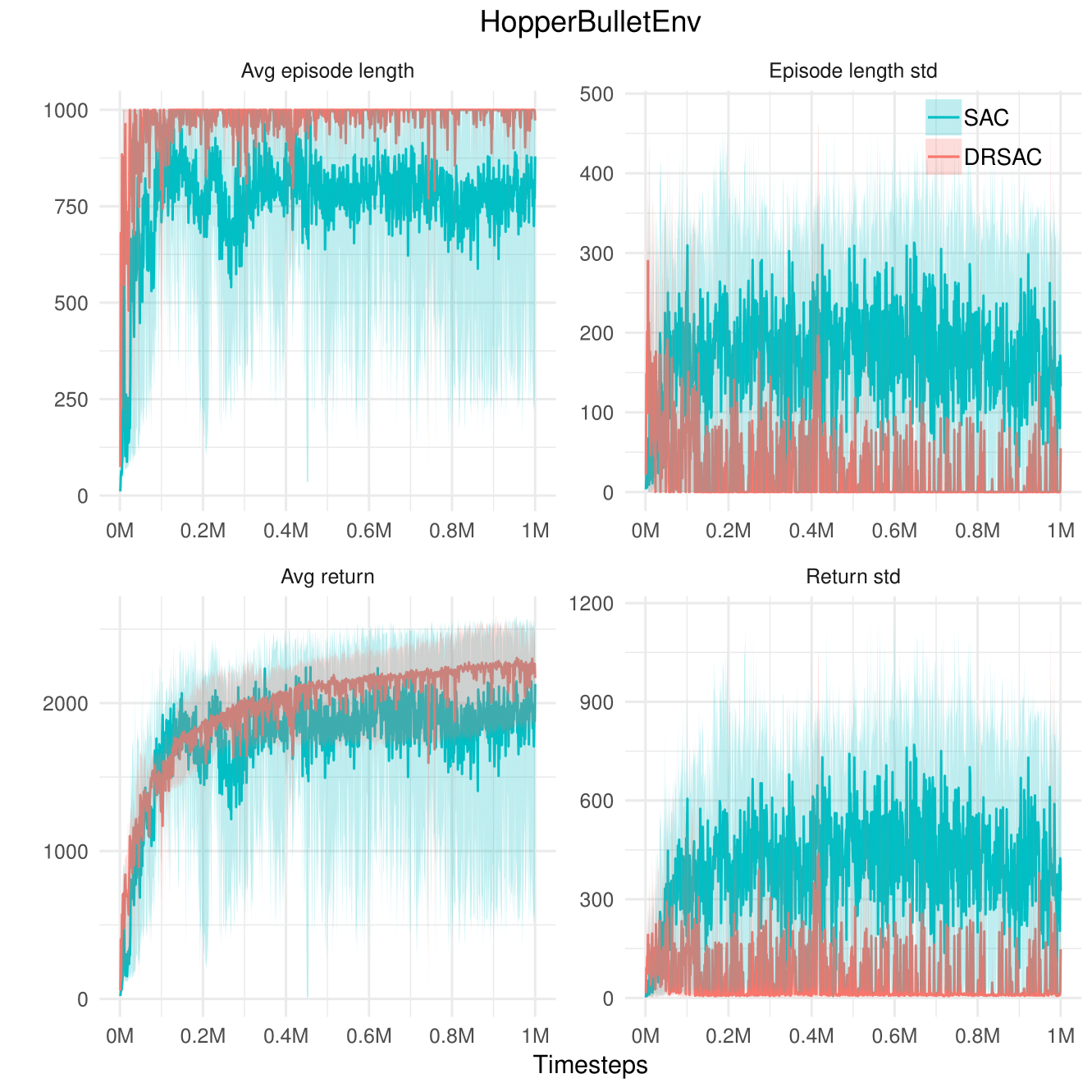

Longer episodes
Stable learning score
SAC (Baseline) vs. Safe SAC (Proposed)
Walker2D
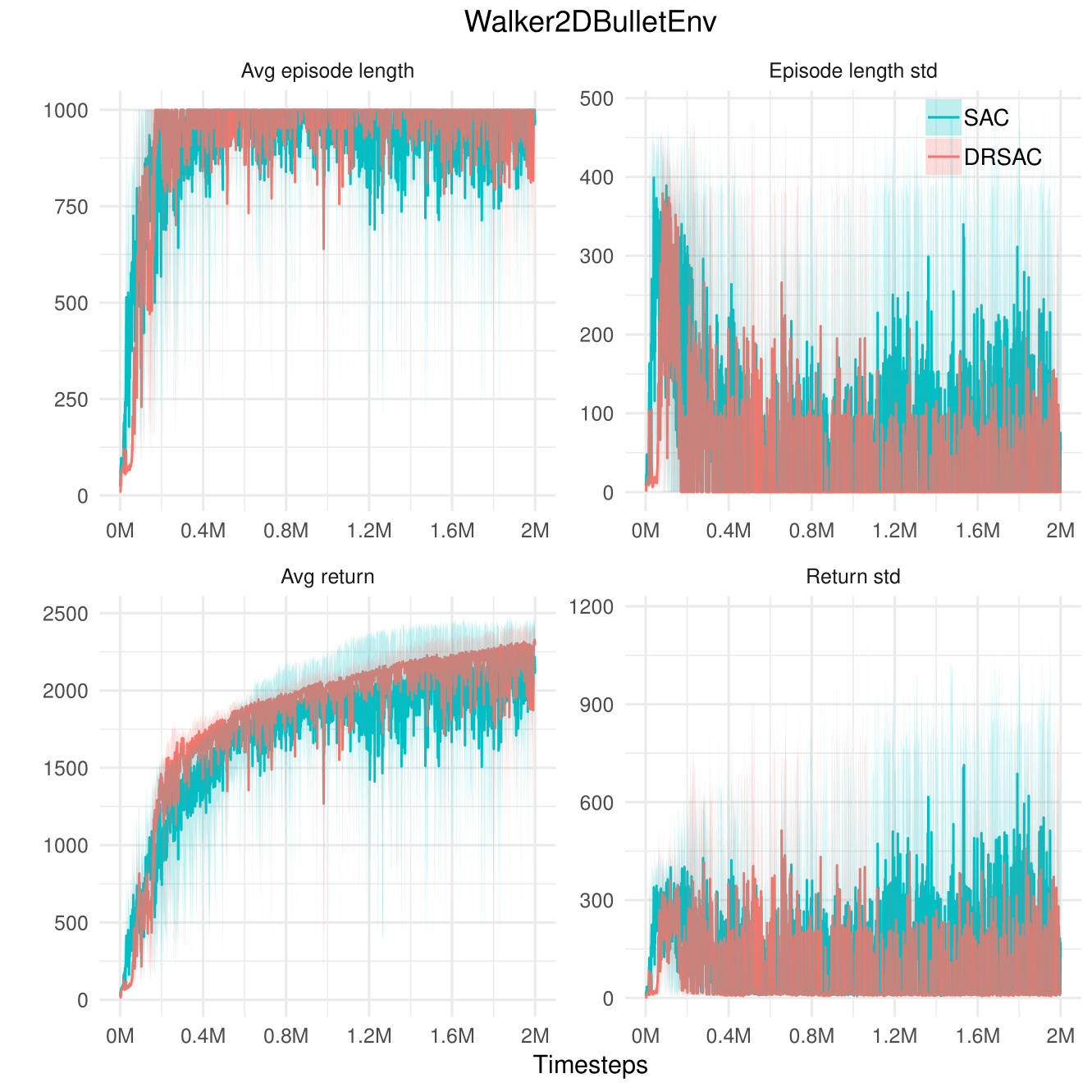

Quite stable already
Stable learning score
SAC (Baseline) vs. Safe SAC (Proposed)
Test performance of Safe SAC
| Hopper | Walker2D | |
|---|---|---|
| Return Avg | Similar | Similar |
| Return Std | -76% +/- 21 | -78% +/- 48 |
| Episode Len Avg | Similar | Similar |
| Episode Len Std | -76% +/- 13 | -77% +/- 42 |
Percent change w.r.t. SAC
Hopper
Walker2D
Code available!
def _get_adv_reward_cor(self, q1_mu, q1_mu_targ, mu, mu_targ, std, std_targ):
# state visit counter
n_s = self._n_s_ph if self._use_n_s else self._total_timestep_ph
# size of uncertainty set
adv_eps = tf.divide(self._adv_c, tf.pow(tf.cast(n_s, tf.float32), self._adv_eta))
# approximate standard deviation of Q-values at current and next states
g0 = tf.gradients(q1_mu, mu)[0]
g0_targ = tf.gradients(q1_mu_targ, mu_targ)[0]
approx_q_std = self._approx_q_std_2_order(g0, q1_mu, mu, std, self._observations_ph)
approx_q_std_targ = self._approx_q_std_2_order(g0_targ, q1_mu_targ, mu_targ, std_targ,
self._next_observations_ph)
# approximate adversarial parameter
adv_lambda = tf.divide(approx_q_std, tf.sqrt(2*adv_eps))
# safe reward correction (simplified by substituting lambda approximation)
adv_reward_cor = 1. / (2*adv_lambda) *
(self._discount*approx_q_std_targ - approx_q_std)
return adv_reward_corSummary
lower bound w.r.t. estimation errors
using convex duality
to the optimal policy
approximation for continuous control
exploration strategy
Safety
Scalability
Convergence
Safe reward shaping
Short-term risk-averse and long-term risk-seeking
References
- T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290, 2018.
- B. Scherrer, M. Ghavamzadeh, V. Gabillon, B. Lesner, and M. Geist. Approximate modified policy iteration and its application to the game of tetris. Journal of Machine Learning Research, 16:1629–1676, 2015
- E. Smirnova, E. Dohmatob, J. Mary. Distributionally robust reinforcement learning. RL4RealLife workshop, ICML 2019. arXiv preprint arXiv:1902.08708, 2019