Can we make an AI respect TEI XML?
An experiment with a Small-Scale "explainable" AI
Presentation for TEI 2025 in Kraków, 2025-09-18
Alexander C. Fisher, Hadleigh Jae Bills, and Elisa Beshero-Bondar
Penn State Erie, The Behrend College

Link to Slides:
https://bit.ly/digitai-tei25

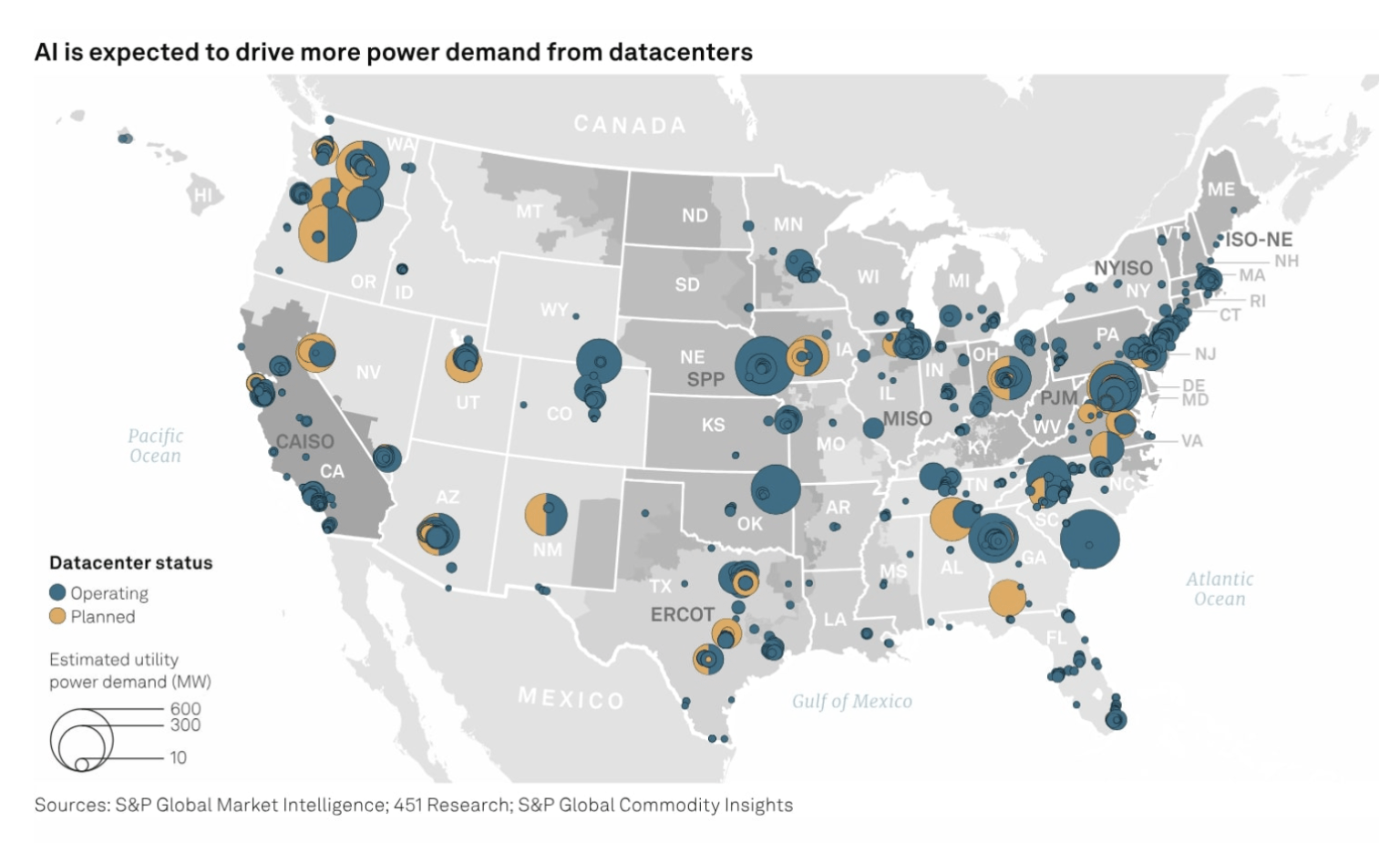
Land, money, power, tech
- Penn State is located on the ancestral lands of the Erie, Haudenosaunee, Lenape, Shawnee, Susquehannock, and Wahzhazhe Nations. Penn State's land grant was funded by the sale of land expropriated from 112 tribal nations in 50 land cessions across 16 states.
- What are we doing with this land now, and what do we really need? Map of datacenters in the US posted August 2024. Source: nfx.net
What DigitAI will be
A tool to assist scholars and editors in applying the TEI Guidelines to their own corpora
- For users who are new to TEI or seeking deeper understanding
- A TEI-aware tutor, NOT an Auto-Encoder
- Responds to chat questions about the TEI:
- to help learners understand best practices in TEI encoding
- to help TEI Developers to find inconsistencies in the guidelines
If it works: it should provide relevant examples, explanations, and excerpts directly from the TEI Guidelines
If it doesn't work: We still learn how a localized AI system works "under the hood"
Why TEI?
- My students talked me into this. . .
- One of us regularly edits the TEI Guidelines
- meaningfully structured machine- and human- readable knowledge base
- "ground truth" code schema and documentation
- And I was curious about papers on AI at TEI 2024:
- Khemakhem in particular:
- make a localized AI trained on TEI,
- found it to fail in delivering consistent guidance
- due to "chunking" of the source based on arbitrary count of tokens.
- Khemakhem in particular:
- My hypothesis: What if the LLM were given the TEI Guidelines based on semantic units of XML nodes? (What if the AI could use XPath...or had the benefit of XPath?)
- Can we develop a small model that will run on a powerful laptop / Mac studio?
- Can we learn things about how language models work and how they can access semantic information modeled in XML and TEI?
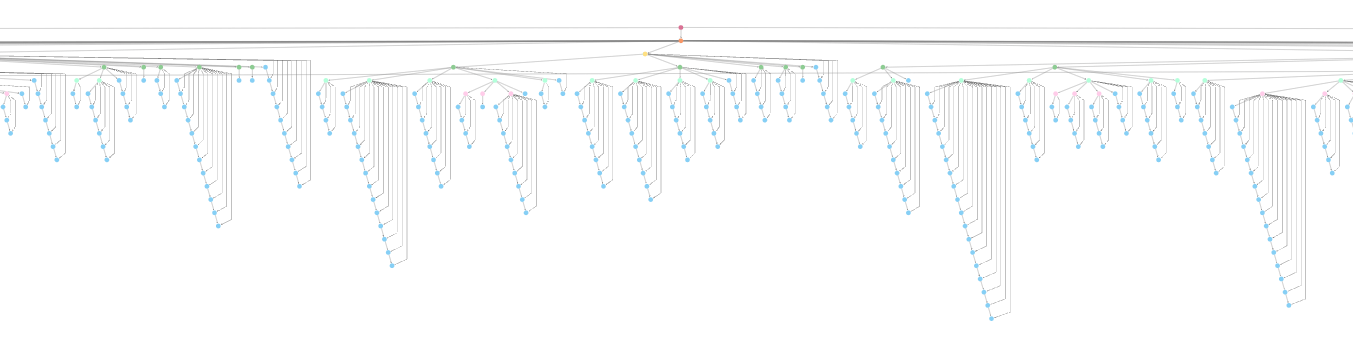
p5.xml
- a single XML document that contains the entire TEI Guidelines.
- This document is built when we release the TEI Guidelines
- It's a hierarchical (tree) structure:
-
Contains front matter, 24 Chapters, each with sections and nested subsections.
-
Paragraphs in chapters
- contain encoding that defines rules for elements and attribute classes, model classes (connecting related elements and attributes together), datatype specifications.
-
Paragraphs in chapters
p5.xml → XSLT → digitai-p5.json
We are writing XSLT to translate the XML tree of p5.xml into:
- a JSON structure (digitai-p5.json) for a neo4j database to ingest
- Cypher Query scripts to direct this database to translate this JSON into a knowledge graph
- Crash course in data structures (JSON, JSON-L) and graph databases (neo4j and cypher queries)
- What is a RAG and why would we want one?
- Selecting and deciding on an LLM and dependencies
- Intricate dependencies everywhere
- Each of us concentrated on our specialized tasks
- Here are my students reporting on their development tasks
Learning / development tasks
XSLT Process so far
(This was my "stub" of a slide indicating where I'd come in after my students' portion). :-)
Let's talk about the workflow. . .
Alexander is in charge of implementation
- He investigates models: ollama, QWEN
- Concentrates on Python / Jupyter notebooks to configure local model
Hadleigh and I are studying to construct a RAG system in a neo4j database
- I output transformations of p5.xml into JSON
- Hadleigh sees if the neo4j can "ingest" the JSON
- Hadleigh learns / teaches me how to write Cypher scripts by hand at first.
- I then try to write the Cypher scripts with XSLT
XSLT for a knowledge graph RAG
- Apply XPath to address and unpack the XML nodes of p5.xml
- Modal XSLT
- At every stage of this tree, output
- mode 1: JSON maps and arrays
- mode 2: cypher query to address a level
- Output is for machine-readable XPath results
- Should answer Khemakhem's chunking problem
XSLT: Declarations of “knowledge”
- XSLT templates, named templates, and functions
- Mode 1: define the contents of the graph
- Mode 2: define the graph nodes and relationships
Both modes rely on xsl:map (scroll to view)
(scroll to view
<xsl:variable name="nf:graph-model" as="map(*)*">
<xsl:map>
<xsl:map-entry key="'document'">
<xsl:map>
<xsl:map-entry key="'label'">Document</xsl:map-entry>
<xsl:map-entry key="'xpathPattern'">document()</xsl:map-entry>
<xsl:map-entry key="'cypherVar'">doc</xsl:map-entry>
<xsl:map-entry key="'jsonVar'">value</xsl:map-entry>
<!-- ebb: Literally 'value' is the value of the document imported on load into neo4j. -->
<xsl:map-entry key="'primaryKey'">title</xsl:map-entry>
<xsl:map-entry key="'jsonKeyForPK'">DOCUMENT_TITLE</xsl:map-entry>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'jsonDateTime'">THIS_JSON_DATETIME</xsl:map-entry>
<xsl:map-entry key="'teiSourceDate'">TEI_SOURCE_OUTPUT_DATE</xsl:map-entry>
<xsl:map-entry key="'teiSourceVersion'">TEI_SOURCE_VERSION_NUMBER</xsl:map-entry>
<xsl:map-entry key="'supportInst'">SUPPORTING_INSTITUTION</xsl:map-entry>
<xsl:map-entry key="'byline'">PREPARED_BY</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_PARTS',
'childEntityType': 'part',
'relationship': 'HAS_PART',
'isSequence': true()
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'part'">
<xsl:map>
<xsl:map-entry key="'label'">Part</xsl:map-entry>
<xsl:map-entry key="'xpathPattern'">front | body</xsl:map-entry>
<xsl:map-entry key="'cypherVar'">part</xsl:map-entry>
<xsl:map-entry key="'primaryKey'">name</xsl:map-entry>
<xsl:map-entry key="'jsonKeyForPK'">PART</xsl:map-entry>
<xsl:map-entry key="'properties'">
<xsl:map><!-- OUTPUT SEQUENCE VALUES IN JSON-DATA -->
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_CHAPTERS',
'childEntityType': 'chapter',
'relationship': 'HAS_CHAPTER',
'isSequence': true()
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'chapter'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Chapter'"/>
<xsl:map-entry key="'xpathPattern'">div[@type='div1']</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'chapter'"/>
<xsl:map-entry key="'primaryKey'" select="'chapter_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'title'">CHAPTER</xsl:map-entry>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_SECTIONS',
'childEntityType': 'section',
'relationship': 'HAS_SECTION',
'isSequence': true()
},
map {
'jsonChildrenKey': 'CONTAINS_PARAS',
'childEntityType': 'paragraph',
'relationship': 'HAS_PARAGRAPH',
'isSequence': true()
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'section'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Section_1'"/>
<xsl:map-entry key="'xpathPattern'">div[@type='div2']</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'section_1'"/>
<xsl:map-entry key="'primaryKey'" select="'section_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'title'">SECTION</xsl:map-entry>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_SUBSECTIONS',
'childEntityType': 'section_2',
'relationship': 'HAS_SUBSECTION',
'isSequence': true()
},
map {
'jsonChildrenKey': 'CONTAINS_PARAS',
'childEntityType': 'paragraph',
'relationship': 'HAS_PARAGRAPH',
'isSequence': true()
},
map {
'jsonChildrenKey': 'TEI_ENCODING_DISCUSSED.CONTAINS_SPECGRPS',
'childEntityType' : 'specgrp',
'relationship': 'HAS_SPECGRP'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'section_2'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Section_2'"/>
<xsl:map-entry key="'xpathPattern'">div[@type='div2']</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'section_2'"/>
<xsl:map-entry key="'primaryKey'" select="'section_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'title'">SECTION</xsl:map-entry>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_SUBSECTIONS',
'childEntityType': 'section_3',
'relationship': 'HAS_SUBSECTION',
'isSequence': true()
},
map {
'jsonChildrenKey': 'CONTAINS_PARAS',
'childEntityType': 'paragraph',
'relationship': 'HAS_PARAGRAPH',
'isSequence': true()
},
map {
'jsonChildrenKey': 'TEI_ENCODING_DISCUSSED.CONTAINS_SPECGRPS',
'childEntityType' : 'specgrp',
'relationship': 'HAS_SPECGRP'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'section_3'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Section_3'"/>
<xsl:map-entry key="'xpathPattern'">div[@type='div2']</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'section_3'"/>
<xsl:map-entry key="'primaryKey'" select="'section_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'title'">SECTION</xsl:map-entry>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO.SECTION'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array {
map {
'jsonChildrenKey': 'CONTAINS_PARAS',
'childEntityType': 'paragraph',
'relationship': 'HAS_PARAGRAPH',
'isSequence': true()
},
map {
'jsonChildrenKey': 'TEI_ENCODING_DISCUSSED.CONTAINS_SPECGRPS',
'childEntityType' : 'specgrp',
'relationship': 'HAS_SPECGRP'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'paragraph'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Para'"/>
<xsl:map-entry key="'xpathPattern'">p[*]</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'paragraph'"/>
<xsl:map-entry key="'primaryKey'" select="'parastring'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'PARASTRING'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO.SECTION'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'elements_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ELEMENT_NAME'"/>
<!-- EBB: Should we change this to match the name we give in an elementSpec? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'attributes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ATTRIBUTE_NAME'"/>
<!-- EBB: Should we change this to match the name we give in a classSpec / attribute definition? -->
</xsl:map>
</xsl:map-entry>
<!-- idents_mentioned: 11 different JSON keys -->
<xsl:map-entry key="'modules_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.MODULES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'MODULE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'classes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'CLASS'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'files_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.FILES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'FILE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'datatypes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'DATATYPE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'macros_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.MACROS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'MACRO'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'ns_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.NSS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'NS'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'schemas_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'SCHEMA'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'parameter_entities_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.PES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'PE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'parameter_entities_mentioned_ge'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.PES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'GE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'frags_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'FRAG'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'relaxng_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.RNGS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'RNG'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'speclist_links'">
<!-- ebb: We were not processing these before, but I experimented with something similar in my xslt Sandbox.
<specList> elements contain just one kind of element child: <specDesc>
The <specList> can be children of <p>, or descendants of <p> (within a list[@type='gloss']/item)
The <specDesc> children have a @key that points to the ID of a spec, like so:
<specList>
<specDesc key="correction" atts="status method"/>
</specList>
-->
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="
array{
map{
'jsonChildrenKey': 'TEI_ENCODING_DISCUSSED.CONTAINS_EXAMPLES',
'childEntityType': 'example',
'relationship': 'HAS_EXAMPLE'
},
map {
'jsonChildrenKey': 'TEI_ENCODING_DISCUSSED.CONTAINS_SPECGRPS',
'childEntityType' : 'specgrp',
'relationship': 'HAS_SPECGRP'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'example'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Example'"/>
<xsl:map-entry key="'xpathPattern'">eg:egXML</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'example'"/>
<xsl:map-entry key="'primaryKey'" select="'example'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'EXAMPLE'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'language'">LANGUAGE</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map {
'jsonChildrenKey': 'CONTAINS_END_PARAS',
'childEntityType': 'terminal_paragraph',
'relationship': 'HAS_END_PARAGRAPH',
'isSequence': true()
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'terminal_paragraph'">
<!-- THIS MODEL ENTRY IS FOR PARAGRAPHS THAT MAY NOT CONTAIN MEMBERS OF THIS GRAPH THAT THEMSELVES
CONTAIN PARAGRAPHS. -->
<xsl:map>
<xsl:map-entry key="'label'" select="'TerminalPara'"/>
<xsl:map-entry key="'xpathPattern'">p[not(*)]</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'paragraph'"/>
<xsl:map-entry key="'primaryKey'" select="'parastring'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'PARASTRING'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'sequence'">SEQUENCE</xsl:map-entry>
<xsl:map-entry key="'links'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO.SECTION'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'elements_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ELEMENT_NAME'"/>
<!-- EBB: Should we change this to match the name we give in an elementSpec? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'attributes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ATTRIBUTE_NAME'"/>
<!-- EBB: Should we change this to match the name we give in a classSpec / attribute definition? -->
</xsl:map>
</xsl:map-entry>
<!-- idents_mentioned: 11 different JSON keys -->
<xsl:map-entry key="'modules_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.MODULES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'MODULE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'classes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'CLASS'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'files_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.FILES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'FILE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'datatypes_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'DATATYPE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'macros_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.MACROS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'MACRO'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'ns_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.NSS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'NS'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'schemas_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'SCHEMA'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'parameter_entities_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.PES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'PE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'parameter_entities_mentioned_ge'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.PES_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'GE'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'frags_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'FRAG'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'relaxng_mentioned'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.RNGS_MENTIONED'"/>
<!-- EBB: UPDATE THE FUNCTION THAT OUTPUTS THESE ^^^^^^^ -->
<xsl:map-entry key="'sourcePropertyKey'" select="'RNG'"/>
<!-- EBB: Should we change this to match the name we give in a *Spec definition? -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'speclist_links'">
<!-- ebb: We were not processing these before, but I experimented with something similar in my xslt Sandbox.
<specList> elements contain just one kind of element child: <specDesc>
The <specList> can be children of <p>, or descendants of <p> (within a list[@type='gloss']/item)
The <specDesc> children have a @key that points to the ID of a spec, like so:
<specList>
<specDesc key="correction" atts="status method"/>
</specList>
-->
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<!-- ebb: terminal_paragraph definition must NOT contain 'children' map. -->
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'specgrp'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Specgrp'"/>
<xsl:map-entry key="'xpathPattern'">specGrp</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'specgrp'"/>
<xsl:map-entry key="'primaryKey'" select="'specgrp_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'SPECGRP_ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'name'">SPECGRP_NAME</xsl:map-entry>
<xsl:map-entry key="'links'">
<!-- THIS SHOULD PICK UP SPECGRPREF TARGETS -->
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'RELATES_TO'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'ID'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map{
'jsonChildrenKey' : 'CONTAINS_SPECS',
'childEntityType': 'spec',
'relationship': 'HAS_SPEC'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'spec'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Specification'"/>
<xsl:map-entry key="'xpathPattern'">spcGrp/*[name() ! ends-with(., 'Spec')]</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'spec'"/>
<xsl:map-entry key="'primaryKey'" select="'spec_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'SPEC_ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'spec_type'">SPEC_TYPE</xsl:map-entry>
<xsl:map-entry key="'module'">PART_OF_MODULE</xsl:map-entry>
<xsl:map-entry key="'class'">MEMBER_OF_CLASS</xsl:map-entry>
<xsl:map-entry key="'equiv_name'">EQUIVALENT_NAME</xsl:map-entry>
<xsl:map-entry key="'glosses'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'GLOSSED_BY'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'GLOSS'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'descriptions'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'DESCRIBED_BY'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'DESC'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'remarks'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'REMARKS_ON'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'REMARK'"/>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map{
'jsonChildrenKey': 'CONTAINS_CONTENT_MODEL',
'childEntityType': 'content_model',
'relationship': 'CONTENT_MODEL'
},
map{
'jsonChildrenKey': 'CONTAINS_ATTLIST',
'childEntityType': 'attribute_list',
'relationship': 'HAS_ATTRIBUTE_LIST'
},
map{
'jsonChildrenKey': 'CONSTRAINED_BY',
'childEntityType': 'constraint',
'relationship': 'HAS_CONSTRAINT'
},
map{
'jsonChildrenKey': 'CONTAINS_EXAMPLES',
'childEntityType': 'example',
'relationship': 'HAS_EXAMPLE'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'attribute_list'">
<xsl:map>
<xsl:map-entry key="'label'" select="'ListAttributes'"/>
<xsl:map-entry key="'xpathPattern'">attList</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'attribute_list'"/>
<xsl:map-entry key="'primaryKey'">name</xsl:map-entry>
<xsl:map-entry key="'jsonKeyForPK'">ATTLIST</xsl:map-entry>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'organization'">ORGANIZED_AS</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map{
'jsonChildrenKey': 'CONTAINS_ATTLIST',
'childEntityType': 'attribute_list',
'relationship': 'HAS_ATTRIBUTE_LIST'
},
map{
'jsonChildrenKey': 'DEFINES_ATTRIBUTES',
'childEntityType': 'attribute_definition',
'relationship': 'defines_attributes'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'attribute_definition'">
<xsl:map>
<xsl:map-entry key="'label'">Attribute_definition</xsl:map-entry>
<xsl:map-entry key="'xpathPattern'">attDef</xsl:map-entry>
<xsl:map-entry key="'cypherVar'">attribute_definition</xsl:map-entry>
<xsl:map-entry key="'primaryKey'">ATTRIBUTE_DEFINITION</xsl:map-entry>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="usage">USAGE</xsl:map-entry>
<xsl:map-entry key="'glosses'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'GLOSSED_BY'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'GLOSS'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'descriptions'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'DESCRIBED_BY'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'DESC'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'remarks'">
<xsl:map>
<xsl:map-entry key="'isListComprehension'" select="true()"/>
<xsl:map-entry key="'sourceArrayPath'" select="'REMARKS_ON'"/>
<xsl:map-entry key="'sourcePropertyKey'" select="'REMARK'"/>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'default_value'">TAKES_DEFAULT_VALUE</xsl:map-entry>
<xsl:map-entry key="'datatype'">TAKES_DATATYPE</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map{
'jsonChildrenKey': 'CONSTRAINED_BY',
'childEntityType': 'constraint',
'relationship': 'HAS_CONSTRAINT'
},
map{
'jsonChildrenKey': 'CONTAINS_EXAMPLES',
'childEntityType': 'example',
'relationship': 'HAS_EXAMPLE'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'content_model'">
<xsl:map>
<xsl:map-entry key="'label'" select="'ContentModel'"/>
<xsl:map-entry key="'xpathPattern'">content</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'content_model'"/>
<xsl:map-entry key="'primaryKey'" select="'spec_id'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'SPEC_ID'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'textnode'">TEXTNODE</xsl:map-entry>
<xsl:map-entry key="'empty'">EMPTY</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map {
'jsonChildrenKey' : 'CONTAINS_ALTERNATING_CONTENTS',
'childEntityType' : 'alternate',
'relationship' : 'ALTERNATING'
},
map {
'jsonChildrenKey' : 'CONTAINS_SEQUENTIAL_CONTENTS',
'childEntityType' : 'sequence',
'relationship' : 'SEQUENCE',
'isSequence': true()
},
map {
'jsonChildrenKey' : 'CONTAINS_VALLIST',
'childEntityType' : 'vallist',
'relationship' : 'HAS_VAL'
},
map{
'jsonChildrenKey': 'CONTAINS_DATAREF',
'childEntityType': 'dataref',
'relationship': 'HAS_DATAREF'
},
map{
'jsonChildrenKey': 'CONTAINS_MACROREF',
'childEntityType': 'macroref',
'relationship': 'HAS_MACROREF'
},
map{
'jsonChildrenKey': 'CONTAINS_CLASSREF',
'childEntityType': 'classref',
'relationship': 'HAS_CLASSREF'
},
map{
'jsonChildrenKey': 'CONTAINS_ELEMENTREF',
'childEntityType': 'elementref',
'relationship': 'HAS_ELEMENTREF'
}
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'alternate'">
<xsl:map>
<xsl:map-entry key="'label'" select="'Alternate'"/>
<xsl:map-entry key="'xpathPattern'">alternate</xsl:map-entry>
<xsl:map-entry key="'cypherVar'" select="'alternate'"/>
<xsl:map-entry key="'primaryKey'" select="'name'"/>
<xsl:map-entry key="'jsonKeyForPK'" select="'ALTERNATE'"/>
<xsl:map-entry key="'properties'">
<xsl:map>
<xsl:map-entry key="'minimum_occurrence'">MINOCCURS</xsl:map-entry>
<xsl:map-entry key="'maximum_occurrence'">MAXOCCURS</xsl:map-entry>
<xsl:map-entry key="'textnode'">TEXTNODE</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
<xsl:map-entry key="'children'">
<xsl:sequence select="array{
map {
'jsonChildrenKey' : 'CONTAINS_ALTERNATING_CONTENTS',
'childEntityType' : 'alternate',
'relationship' : 'ALTERNATING'
},
map {
'jsonChildrenKey' : 'CONTAINS_SEQUENTIAL_CONTENTS',
'childEntityType' : 'sequence',
'relationship' : 'SEQUENCE',
'isSequence': true()
}
(: still deal with these possible children of alternate:
* classRef
* elementRef
* dataRef
* valList
* anyElement
:)
}"/>
</xsl:map-entry>
</xsl:map>
</xsl:map-entry>
</xsl:map>
</xsl:variable>
XSLT mode 1: Make JSON
<xsl:function name="nf:specPuller" as="map(*)*">
<xsl:param name="specs" as="element()*"/>
<xsl:for-each select="$specs[not(self::paramSpec)]">
<xsl:variable name="glosses" as="element()*" select="current()/gloss"/>
<xsl:variable name="descs" as="element()*" select="current()/desc"/>
<xsl:variable name="remarks" as="element()*" select="current()/remarks"/>
<xsl:variable name="constraints" as="element()*"
select="current()/constraintSpec[not(descendant::sch:pattern)]"/>
<xsl:variable name="exempla" as="element()*" select="current()/exemplum"/>
<xsl:variable name="contentModel" as="map(*)*">
<xsl:if test="current()/content">
<xsl:call-template name="content">
<xsl:with-param name="content" as="element(content)"
select="current()/content"/>
</xsl:call-template></xsl:if>
</xsl:variable>
<xsl:sequence select="map{
'SPEC_TYPE' : current()/name(),
'SPEC_NAME': current()/@ident ! normalize-space(),
'PART_OF_MODULE': current()/@module ! normalize-space(),
'MEMBER_OF_CLASS' : array {current()/classes/memberOf/@key ! normalize-space()},
'EQUIVALENT_NAME' : current()/equiv ! normalize-space(),
'GLOSSED_BY': array { nf:glossDescPuller($glosses)},
'DESCRIBED_BY': array{ nf:glossDescPuller($descs)},
'CONTENT_MODEL' : array { $contentModel },
'CONTAINS_ATTLIST' : array { nf:attListPuller(current()/attList) },
'CONSTRAINED_BY': array {nf:constraintPuller($constraints)},
'CONTAINS_EXAMPLES': array{ nf:exemplumPuller($exempla)},
'REMARKS_ON': array { nf:glossDescPuller($remarks) }
}"/>
</xsl:for-each>
</xsl:function>Example: JSON pulled from p5.xml

XSLT mode 2: Generate cypher queries
(example: sequence relationships)
<!-- FUNCTION FOR PROCESSING SEQUENCES OF SIBLINGS -->
<xsl:function name="nf:create-next-links" as="xs:string*">
<xsl:param name="parent-label" as="xs:string"/>
<xsl:param name="child-label" as="xs:string"/>
<xsl:param name="relationship" as="xs:string"/>
<xsl:param name="sort-property" as="xs:string"/>
<xsl:variable name="cypher" as="xs:string" select="
'MATCH (parent:'||$parent-label||')-[:'||$relationship||']->(child:'||$child-label||')
WHERE child.'||$sort-property||' IS NOT NULL
WITH parent, child ORDER BY child.'||$sort-property||'
WITH parent, collect(child) AS ordered_children
UNWIND range(0, size(ordered_children) - 2) AS i
WITH ordered_children[i] AS n1, ordered_children[i+1] AS n2
MERGE (n1)-[:NEXT]->(n2)'
"/>
<xsl:sequence select="$newline, '// Link sequential :', $child-label,
' nodes within each :', $parent-label, $newline, $cypher"/>
</xsl:function>
XSLT mode 2: Generate cypher queries
<xsl:for-each
select="map:keys($nf:graph-model)[exists($nf:graph-model(.)?children?*[?isSequence = true()])]">
<xsl:variable name="parent-model" select="$nf:graph-model(.)"/>
<xsl:for-each select="$parent-model?children?*[?isSequence = true()]">
<xsl:variable name="child-info" select="."/>
<xsl:variable name="child-model" select="$nf:graph-model($child-info?childEntityType)"/>
<xsl:sequence select="nf:create-next-links(
$parent-model('label'),
$child-model('label'),
$child-info('relationship'),
'sequence'
), ';'"/>
</xsl:for-each>
</xsl:for-each>Telling neo4j how to read XPath relationships: siblings and children
Some early Cypher query output (scroll to view)
// ==== Generated by XSLT Transformation ====
// 1. SETUP: Create Constraints for Performance and Data Integrity
CREATE CONSTRAINT IF NOT EXISTS FOR (d:Document) REQUIRE d.title IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (s:Section) REQUIRE s.id IS UNIQUE;
CREATE CONSTRAINT IF NOT EXISTS FOR (spec:Specification) REQUIRE spec.name IS UNIQUE;
// 2. LOAD AND PROCESS: Load the JSON and start the recursive import
CALL apoc.load.json("https://raw.githubusercontent.com/newtfire/digitai/refs/heads/ebb-json/RAG/sandbox/sandboxTest.json") YIELD value as doc_data
// Create the root Document node
MERGE (doc:Document {title: 'SOURCE XML AS BASIS FOR A KNOWLEDGE GRAPH'})
WITH doc, doc_data
FOREACH (part_data_1 IN doc_data.CONTAINS_PARTS |
MERGE (part:Part {name: part_data_1.PART}) SET part.sequence = part_data_1.SEQUENCE
MERGE (doc)-[:HAS_PART]->(part)
WITH part, part_data_1
FOREACH (chapter_data_2 IN part_data_1.CONTAINS_CHAPTERS |
MERGE (chapter:Chapter {chapter_id: chapter_data_2.ID}) SET chapter.sequence = chapter_data_2.SEQUENCE, chapter.title = chapter_data_2.CHAPTER, chapter.links = [x IN chapter_data_2.RELATES_TO WHERE x IS NOT NULL | x.ID]
MERGE (part)-[:HAS_CHAPTER]->(chapter)
WITH chapter, chapter_data_2
FOREACH (section_1_data_3 IN chapter_data_2.CONTAINS_SECTIONS |
MERGE (section_1:Section_1 {section_id: section_1_data_3.ID}) SET section_1.sequence = section_1_data_3.SEQUENCE, section_1.title = section_1_data_3.SECTION, section_1.links = [x IN section_1_data_3.RELATES_TO WHERE x IS NOT NULL | x.ID]
MERGE (chapter)-[:HAS_SECTION]->(section_1)
WITH section_1, section_1_data_3
FOREACH (section_2_data_4 IN section_1_data_3.CONTAINS_SUBSECTIONS |
MERGE (section_2:Section_2 {section_id: section_2_data_4.ID}) SET section_2.sequence = section_2_data_4.SEQUENCE, section_2.title = section_2_data_4.SECTION, section_2.links = [x IN section_2_data_4.RELATES_TO WHERE x IS NOT NULL | x.ID]
MERGE (section_1)-[:HAS_SUBSECTION]->(section_2)
WITH section_2, section_2_data_4
FOREACH (section_3_data_5 IN section_2_data_4.CONTAINS_SUBSECTIONS |
MERGE (section_3:Section_3 {section_id: section_3_data_5.ID}) SET section_3.sequence = section_3_data_5.SEQUENCE, section_3.title = section_3_data_5.SECTION, section_3.links = [x IN section_3_data_5.RELATES_TO.SECTION WHERE x IS NOT NULL | x.ID]
MERGE (section_2)-[:HAS_SUBSECTION]->(section_3)
WITH section_3, section_3_data_5
FOREACH (paragraph_data_6 IN section_3_data_5.CONTAINS_PARAS |
MERGE (paragraph:Para {parastring: paragraph_data_6.PARASTRING}) SET paragraph.files_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.FILES_MENTIONED WHERE x IS NOT NULL | x.FILE], paragraph.parameter_entities_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.PE], paragraph.elements_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED WHERE x IS NOT NULL | x.ELEMENT_NAME], paragraph.attributes_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED WHERE x IS NOT NULL | x.ATTRIBUTE_NAME], paragraph.sequence = paragraph_data_6.SEQUENCE, paragraph.frags_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED WHERE x IS NOT NULL | x.FRAG], paragraph.ns_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.NSS_MENTIONED WHERE x IS NOT NULL | x.NS], paragraph.classes_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED WHERE x IS NOT NULL | x.CLASS], paragraph.modules_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.MODULES_MENTIONED WHERE x IS NOT NULL | x.MODULE], paragraph.macros_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.MACROS_MENTIONED WHERE x IS NOT NULL | x.MACRO], paragraph.speclist_links = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST WHERE x IS NOT NULL | x.ID], paragraph.relaxng_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.RNGS_MENTIONED WHERE x IS NOT NULL | x.RNG], paragraph.datatypes_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED WHERE x IS NOT NULL | x.DATATYPE], paragraph.links = [x IN paragraph_data_6.RELATES_TO.SECTION WHERE x IS NOT NULL | x.ID], paragraph.parameter_entities_mentioned_ge = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.GE], paragraph.schemas_mentioned = [x IN paragraph_data_6.TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED WHERE x IS NOT NULL | x.SCHEMA]
MERGE (section_3)-[:HAS_PARAGRAPH]->(paragraph)
WITH paragraph, paragraph_data_6
FOREACH (example_data_7 IN paragraph_data_6.TEI_ENCODING_DISCUSSED.CONTAINS_EXAMPLES |
MERGE (example:Example {example: example_data_7.EXAMPLE}) SET example.language = example_data_7.LANGUAGE
MERGE (paragraph)-[:HAS_EXAMPLE]->(example)
WITH example, example_data_7
FOREACH (paragraph_data_8 IN example_data_7.CONTAINS_END_PARAS |
MERGE (paragraph:TerminalPara {parastring: paragraph_data_8.PARASTRING}) SET paragraph.files_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FILES_MENTIONED WHERE x IS NOT NULL | x.FILE], paragraph.parameter_entities_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.PE], paragraph.elements_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED WHERE x IS NOT NULL | x.ELEMENT_NAME], paragraph.attributes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED WHERE x IS NOT NULL | x.ATTRIBUTE_NAME], paragraph.sequence = paragraph_data_8.SEQUENCE, paragraph.frags_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED WHERE x IS NOT NULL | x.FRAG], paragraph.ns_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.NSS_MENTIONED WHERE x IS NOT NULL | x.NS], paragraph.classes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED WHERE x IS NOT NULL | x.CLASS], paragraph.modules_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MODULES_MENTIONED WHERE x IS NOT NULL | x.MODULE], paragraph.macros_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MACROS_MENTIONED WHERE x IS NOT NULL | x.MACRO], paragraph.speclist_links = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST WHERE x IS NOT NULL | x.ID], paragraph.relaxng_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.RNGS_MENTIONED WHERE x IS NOT NULL | x.RNG], paragraph.datatypes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED WHERE x IS NOT NULL | x.DATATYPE], paragraph.links = [x IN paragraph_data_8.RELATES_TO.SECTION WHERE x IS NOT NULL | x.ID], paragraph.parameter_entities_mentioned_ge = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.GE], paragraph.schemas_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED WHERE x IS NOT NULL | x.SCHEMA]
MERGE (example)-[:HAS_END_PARAGRAPH]->(paragraph)
)
)XSLT: to be continued. . .
- Working on mapping contents of elementSpecs
- Glosses / Descs
- Examples
- Content models
- Each defines an intricate set of nodes and relationships
RAG is not ready yet
- We can't really test a QWEN or other model fully yet
- Speculation: We can exeriment with "plugging" a variety of LLM models into our knowledge graph
-
Definitely in scope: translating the nested and sequenced structure of P5 as a graph of relationships
- The graph will have uses beyond "AI" for querying, exploring relationships.
- To be determined: Will the AI "respect" our TEI natural language explanations, examples, and content models?
What are we learning?
- Data structures and graph modeling
- How to write Cypher Scripts
- Differences between "fine-tuning", "RAG augmenting" and "training"
- This is harder than we thought!
- But it shows us how the systems we have do their work
Thoughts about "knowledge graphs" vs. "ground truth"
- Having to define every relationship (for neo4J) exposes how different it is to
- traverse a tree with XPath
- to locate relationship information the way an AI model does.
- XPath-awareness in LLM dependencies would give them more ways to learn / explore
- XSLT is functioning as a declarative translator:
- With the XSLT, we humans declare what's "knowable" for a RAG
What's next for DigitAI?
- Finish refining the knowledge graph
- Fine-tuning with the text and code specs of the P5 Guidelines
- Optimization and packaging (user interface over local network, docker container)
Questions?
https://bit.ly/
digitai-github

GitHub:
https://bit.ly/
digitai-jupyter
Jupyter Notebooks:

Slides:
https://bit.ly/digitai-tei25
Hadleigh's and Alexander's Slides
Designing the Memory Graph
- Stores TEI Guidelines as Nodes and Relationships
- Enables retrieval of structured and semantically relevant text
- Preserves relationships of the XML structure
- Queried using Cypher, Neo4j's native query language
- Allows us to retrieval precise, contextual excerpts
Neo4j is like a digital card catalog— it doesnt just store texts, it understands how they relate to each other
WITH doc, doc_data
FOREACH (part_data_1 IN doc_data.CONTAINS_PARTS |
MERGE (part:Part {name: part_data_1.PART}) SET part.sequence = part_data_1.SEQUENCE
MERGE (doc)-[:HAS_PART]->(part)
WITH part, part_data_1
FOREACH (chapter_data_2 IN part_data_1.CONTAINS_CHAPTERS |
MERGE (chapter:Chapter {chapter_id: chapter_data_2.ID})
SET chapter.sequence = chapter_data_2.SEQUENCE,
chapter.title = chapter_data_2.CHAPTER,
chapter.links = [x IN chapter_data_2.RELATES_TO WHERE x IS NOT NULL | x.ID]
MERGE (part)-[:HAS_CHAPTER]->(chapter)
WITH chapter, chapter_data_2 FOREACH (example_data_7 IN paragraph_data_6.TEI_ENCODING_DISCUSSED.CONTAINS_EXAMPLES |
MERGE (example:Example {example: example_data_7.EXAMPLE})
SET example.language = example_data_7.LANGUAGE
MERGE (paragraph)-[:HAS_EXAMPLE]->(example)
WITH example, example_data_7
FOREACH (paragraph_data_8 IN example_data_7.CONTAINS_END_PARAS |
MERGE (paragraph:TerminalPara {parastring: paragraph_data_8.PARASTRING})
SET paragraph.files_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FILES_MENTIONED
WHERE x IS NOT NULL | x.FILE],
paragraph.parameter_entities_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED WHERE x IS NOT NULL | x.PE],
paragraph.elements_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ELEMENTS_MENTIONED
WHERE x IS NOT NULL | x.ELEMENT_NAME], paragraph.attributes_mentioned =
[x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.ATTRIBUTES_MENTIONED
WHERE x IS NOT NULL | x.ATTRIBUTE_NAME],
paragraph.sequence = paragraph_data_8.SEQUENCE,
paragraph.frags_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.FRAGS_MENTIONED
WHERE x IS NOT NULL | x.FRAG],
paragraph.ns_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.NSS_MENTIONED
WHERE x IS NOT NULL | x.NS],
paragraph.classes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CLASSES_MENTIONED
WHERE x IS NOT NULL | x.CLASS],
paragraph.modules_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MODULES_MENTIONED
WHERE x IS NOT NULL | x.MODULE],
paragraph.macros_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.MACROS_MENTIONED
WHERE x IS NOT NULL | x.MACRO],
paragraph.speclist_links = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.CONTAINS_SPECLISTS.SPECLIST
WHERE x IS NOT NULL | x.ID],
paragraph.relaxng_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.RNGS_MENTIONED
WHERE x IS NOT NULL | x.RNG],
paragraph.datatypes_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.DATATYPES_MENTIONED
WHERE x IS NOT NULL | x.DATATYPE], paragraph.links = [x IN paragraph_data_8.RELATES_TO.SECTION
WHERE x IS NOT NULL | x.ID],
paragraph.parameter_entities_mentioned_ge = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.PES_MENTIONED
WHERE x IS NOT NULL | x.GE],
paragraph.schemas_mentioned = [x IN paragraph_data_8.TEI_ENCODING_DISCUSSED.SCHEMAS_MENTIONED
WHERE x IS NOT NULL | x.SCHEMA]
MERGE (example)-[:HAS_END_PARAGRAPH]->(paragraph)
) Neo4j's Graph Model JSON... Beyond Human Readability?
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:0", "text": null, "labels": ["Document"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:1", "text": null, "labels": ["Part"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:2", "text": null, "labels": ["Part"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:3", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:4", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:5", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:6", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:7", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:8", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:9", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:10", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:11", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:12", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:13", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:14", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:15", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:16", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:17", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:18", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:19", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:20", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:21", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:22", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:23", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:24", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:25", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:26", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:27", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:28", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:29", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:30", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:31", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:32", "text": null, "labels": ["Chapter"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:33", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:34", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:35", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:36", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:37", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:38", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:39", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:40", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:41", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:42", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:43", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:44", "text": null, "labels": ["Section"]}
{"id": "4:223785fa-2e25-4598-887d-0a5b446743b2:45", "text": null, "labels": ["Section"]}Designing a RAG with the TEI
Making a knowlege graph: the challenge!

<XML>

<XSLT>
Neo4j
Knowledge Graph
LLM
Nodes
Relationships

<Cypher>
DigitAI Runtime Flow

FAISS

Neo4j Database

BGE-M3
Qwen LLM
Neo4j Database

BGE-M3
FAISS

RAG Embeddings
.JSONL

RAG Embeddings
.FAISS
Embedded Prompt
Generates Vector Embeddings from Node Text
RAG Embeddings Converted to FAISS Formatted Data Map
Data Map Compared to Embedded Query

Constructs Query
Top Matched Embeddings Retrieved as Text From Neo4j

Human Prompt

# === Get user input ===
query = input("❓ Enter your query: ").strip()
if not query:
print("⚠️ No query provided. Exiting.")
exit()# === Encode the query ===
query_embedding = model.encode(query)
# Convert to 2D array and normalize if cosine similarity is enabled
if normalize:
query_embedding = sk_normalize([query_embedding], norm="l2")
else:
query_embedding = np.array([query_embedding])
query_embedding = query_embedding.astype("float32")
# === Perform FAISS similarity search ===
TOP_K = 5 # Number of top matching texts to retrieve
scores, indices = index.search(query_embedding, TOP_K)
# Filter out invalid results (-1 = no match)
matched_ids = [id_map[i] for i in indices[0] if i != -1]
if not matched_ids:
print("⚠️ No relevant matches found in the FAISS index.")
exit()# === Fetch matching texts from JSONL file ===
def fetch_node_texts_by_ids(node_ids):
texts = []
with open(neo4jNodes, "r", encoding="utf-8") as f:
for line in f:
record = json.loads(line)
if record.get("id") in node_ids and record.get("text"):
texts.append(record["text"])
return texts
texts = fetch_node_texts_by_ids(matched_ids)
if not texts:
print("❌ No node texts found for matched IDs in local file.")
exit()# === Construct prompt for the LLM ===
context = "\n".join(f"- {text}" for text in texts)
prompt = f"""You are a chatbot that helps people understand
the TEI guidelines which specify how to encode machine-readable
texts using XML.
Answer the question below in the **same language the question is asked in**.
Use examples from the provided context as needed — they can be in any language.
Do not translate them.
Context:
{context}
Question:
{query}
"""
# === Send prompt to local Ollama LLM ===
def ask_ollama(prompt, model):
try:
response = requests.post(
"http://localhost:11434/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": False
}
)
return response.json().get("response", "[ERROR] Empty response from LLM.")
except Exception as e:
print("❌ Error while querying Ollama:", e)
return "[ERROR] Could not get response from local LLM."
# === Query the model ===
print(f"🤖 Sending prompt to LLM ({llm_model})...")
answer = ask_ollama(prompt, llm_model)
# === Display the result ===
print("\n🧾 Response:\n")
print(answer)