
Parallel computing
Introduction
Written by: Igor Korotach
What is parallel computing?
Parallel computing is a type of computation where many calculations or the execution of processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time.
Types of parallelism
- Bit-level
- Instruction-level
- Data
- Task
Batch processing

What is MapReduce?
MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
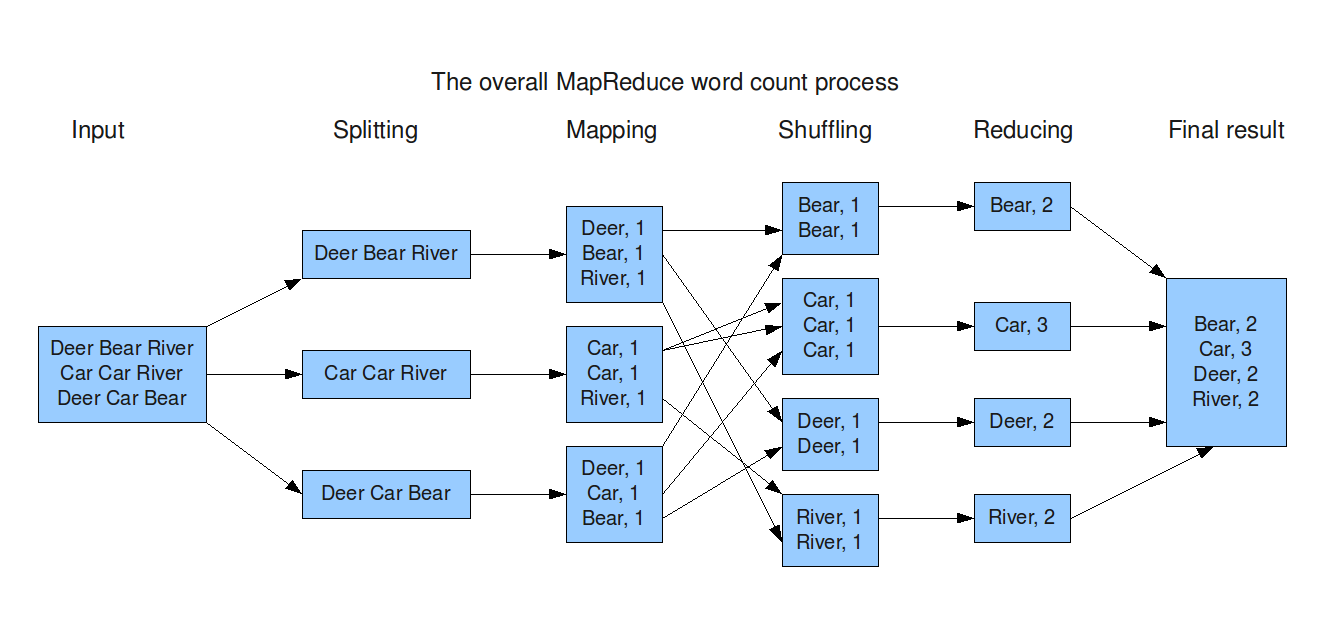
A MapReduce program is composed of a map procedure, which performs filtering and sorting (such as sorting students by first name into queues, one queue for each name), and a reduce method, which performs a summary operation (such as counting the number of students in each queue, yielding name frequencies).
A MapReduce framework (or system) is usually composed of three operations (or steps):
- Map: each worker node applies the map function to the local data, and writes the output to a temporary storage. A master node ensures that only one copy of the redundant input data is processed.
- Shuffle: worker nodes redistribute data based on the output keys (produced by the map function), such that all data belonging to one key is located on the same worker node.
- Reduce: worker nodes now process each group of output data, per key, in parallel.
MapReduce example
Stream processing
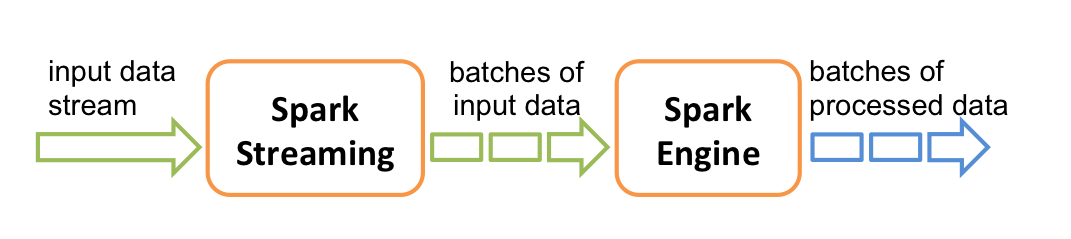
Spark Streaming

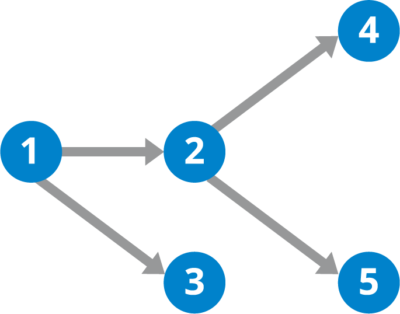
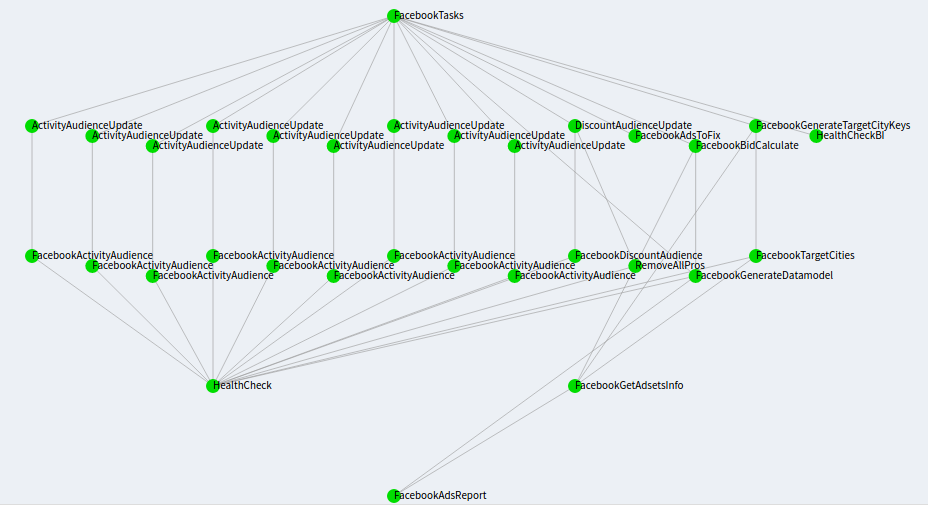
Directed Acyclic Graph (DAG)
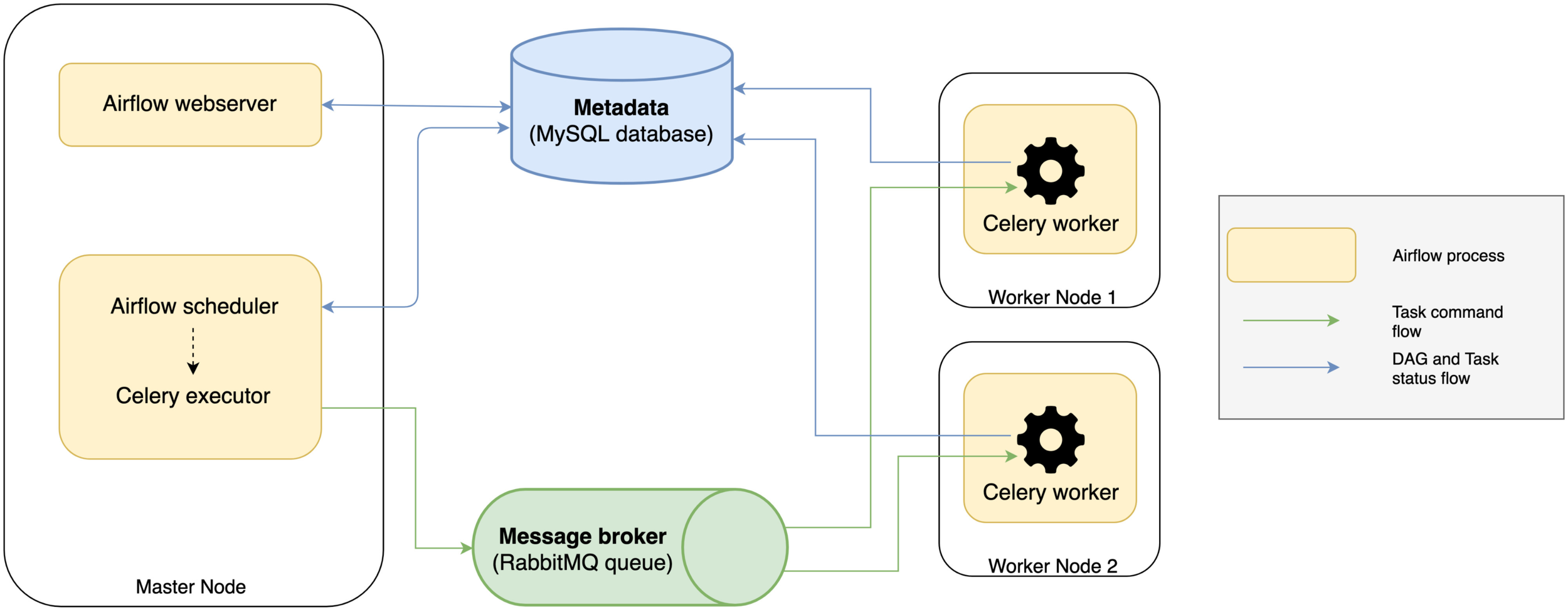
Apache Airflow
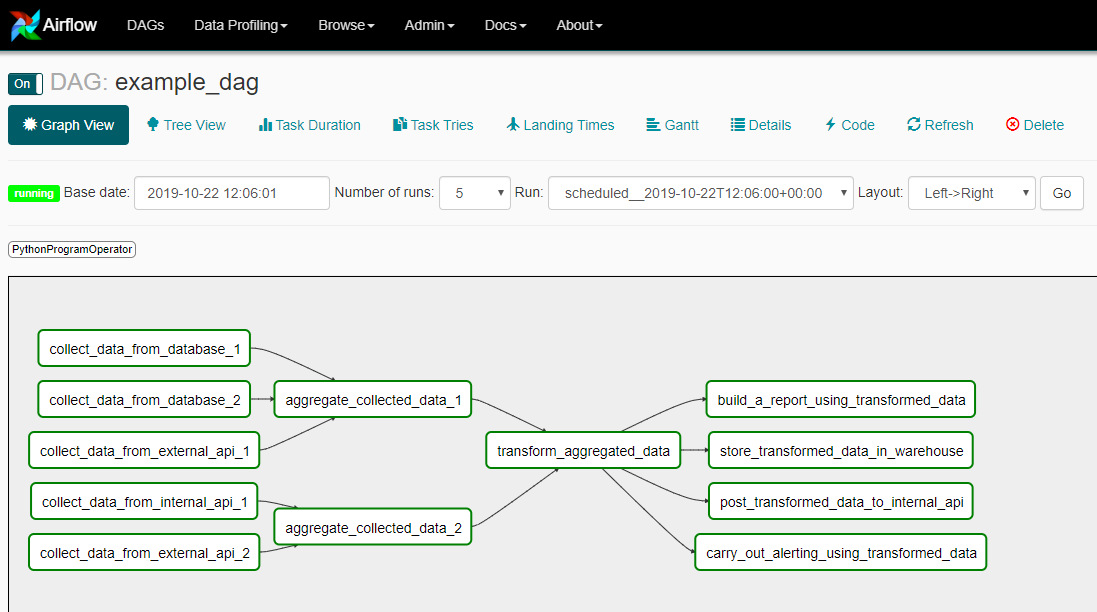
Airflow architecture
Luigi
Differences between Airflow and Spark
Spark
Excellent tool for parallelizing
Good for high performance engineering
Good for working with real-time stream data
Good for sharding data
Airflow
Excellent tool for planning
Good for scheduling ETL jobs
Good for working with different data sources
Good for montoring
Thanks for your attention. You've been awesome!
Questions?
Presentation link: https://slides.com/emulebest/parallel-computing
Mail: igorkorotach@gmail.com
Telegram: @emulebest
