Open Science
Hurdles, gains, and opportunities
of a modern approach to make science.

| smoia | |
| @SteMoia | |
| s.moia.research@gmail.com |
Turin, 13.09.23


(Formerly) EPFL, Lausanne, Switzerland, and UniGE, Geneva, Switzerland; physiopy (https://github.com/physiopy)
Stefano Moia, 2023
Open Science
Hurdles, gains, and opportunities
of a modern approach to make science.
Turin, 13.09.23
Disclaimers
1. I am an "open" scientist. I have a bias toward the
core tenets of Open Science as better practices.
2. My background is psychology, I am a methodologist
and neuroscientist specialised in neuroimaging.
While most examples come from my field, the
concepts are cross-disciplinary.
0. Rules & Materials
You're asking questions,
I'm doing that too!
This is a new chapter
Take home #0
This is a take home message
Terminology
Replicable, Robust, Reproducible, Generalisable

The Turing Way Community, & Scriberia, 2022 (Zenodo). Illustrations from The Turing Way (CC-BY 4.0)
Guaranteeing reproducibility is important for "reusable, transparent" research.
1
2
3
4
1. Let's begin our story...
Where does it come from?
1942-1998: first concepts of "Open Science"
2010s: current concepts of OS, responding to:
- Failed attempts to reproduce core concepts of social psychology and biomedical research
- Studies on p-hacking and questionable research practices
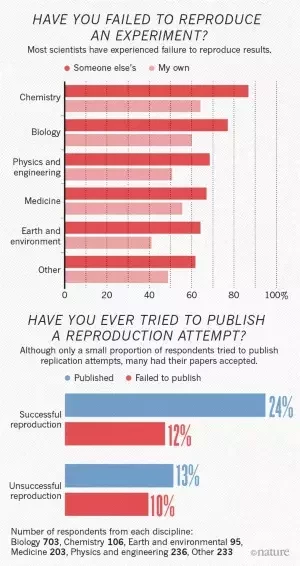
2016: Survey by Nature¹: 70% of researchers failed to reproduce other's results, 50%+ failed to reproduce their own
1. Baker 2016 (Nature)
Issues raised by the crisis
- Unavailable data / code / materials / information / procedures
- Different analysis environments (OS / libraries / versions)
- "Novelty over reproducibility" and "Publish or perish" culture of academia
- "Null results" rejection → Bias toward "positive results"
- P-hacking, data dredging, data fishing, HARKing, ...
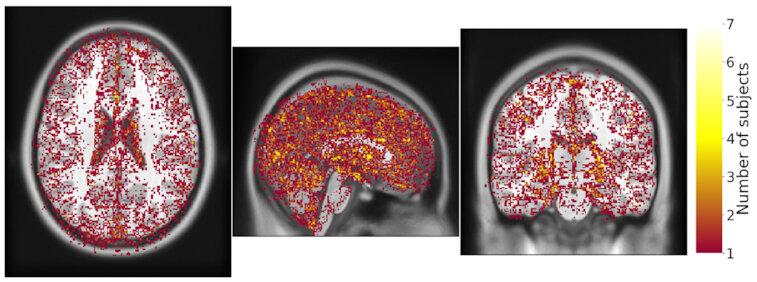
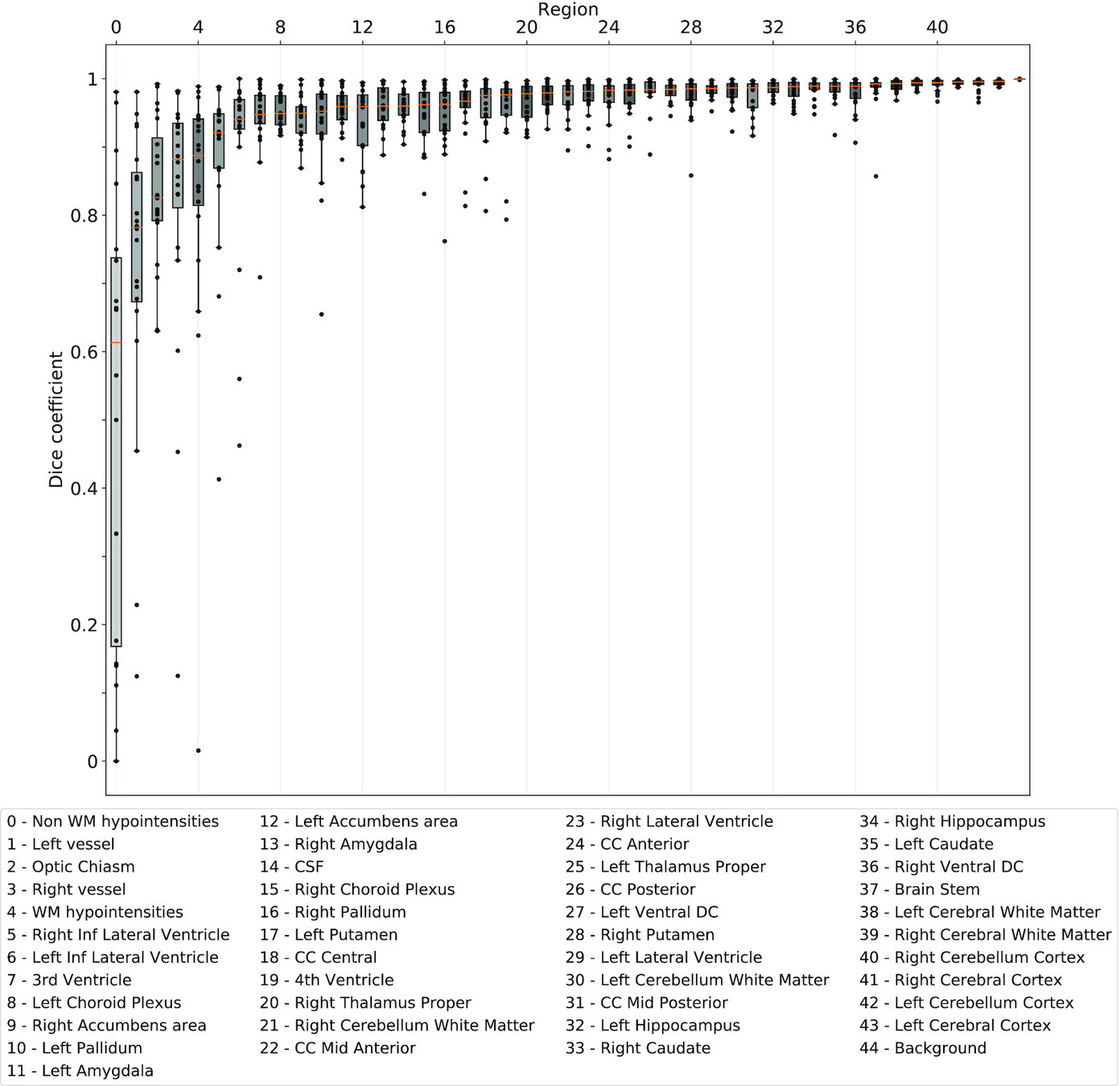
Really Replicable?
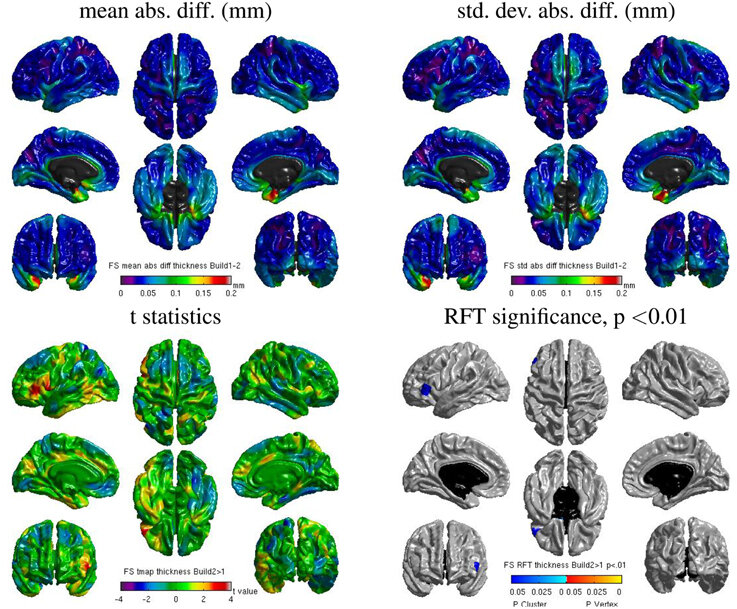
Same hardware, two Freesurfer builds (different glibc version)
Difference in estimated cortical tickness.¹
Same hardware, same FSL version, two glibc versions
Difference in estimated tissue segmentation.²
Same hardware, two Freesurfer builds (two glibc versions)
Difference in estimated parcellation.²
1. Glatard, et al., 2015 (Front. Neuroinform.) 2. Ali, et al., 2021 (Gigascience)



Really Replicable?
Same hardware, two Freesurfer builds (different glibc version)
Difference in estimated cortical tickness.¹
Same hardware, same FSL version, two glibc versions
Difference in estimated tissue segmentation.²
Same hardware, two Freesurfer builds (two glibc versions)
Difference in estimated parcellation.²
1. Glatard, et al., 2015 (Front. Neuroinform.) 2. Ali, et al., 2021 (Gigascience)
The mass extintion level issue
Aarts et al. 2015 (Science)
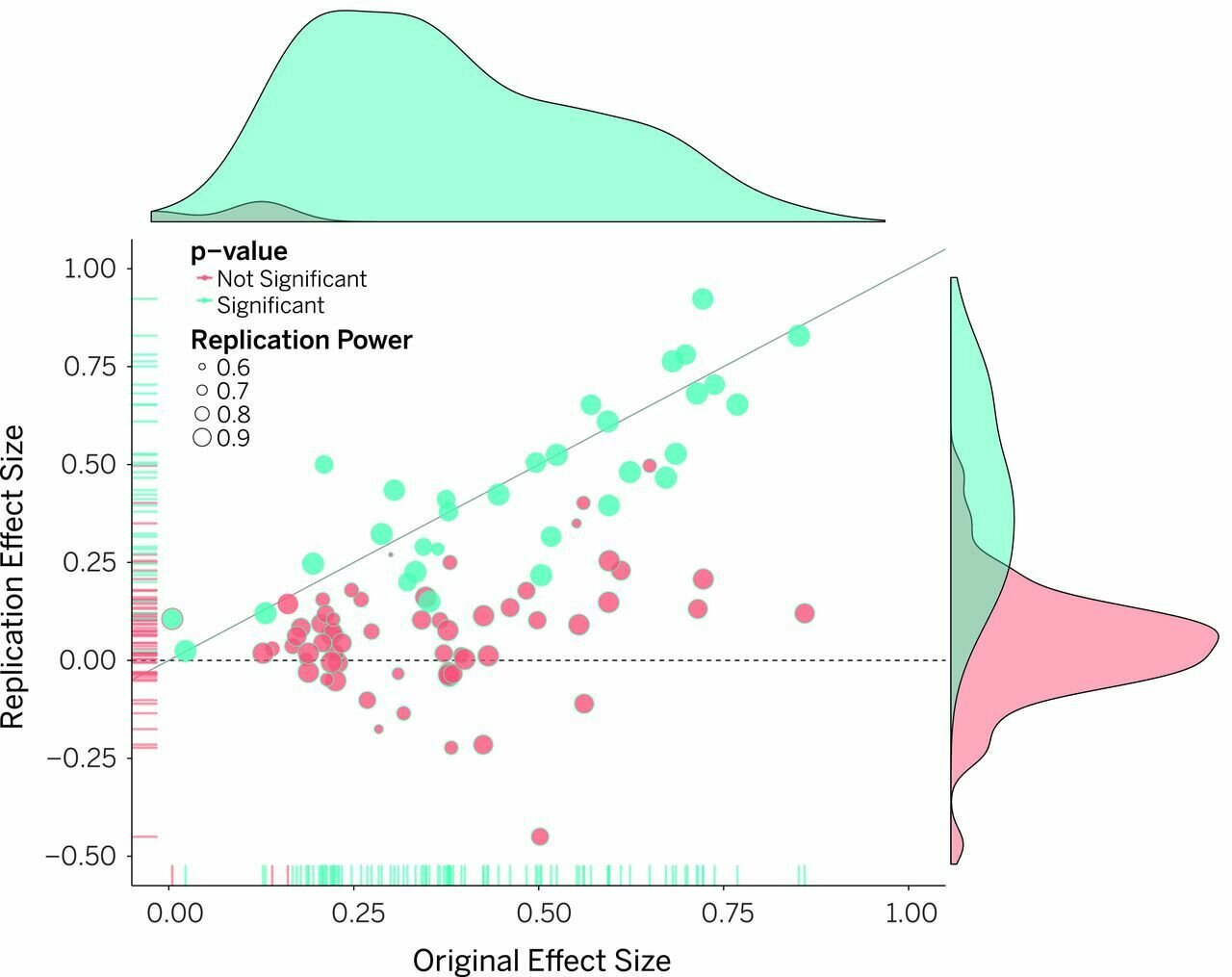



What does failure to generalise tell us about hypotheses and scientific facts?
Take home #1
Just because you found something, it might not mean
it's a generalisable finding.
Be honest about it, and take preventive measures
to improve generalisation.
2. What, Why, and How
What is Open Science?
To be Open, Science should be publicly available, reusable,
and transparent¹. It should aim at reaching:
1. The Turing Way Community, 2019 (Zenodo). https://the-turing-way.netlify.app (CC-BY 4.0)
- Open Data
- Open Source Software
- Open Hardware
- Open Access (outreach)
- Reproducible results
- Usable artefacts, independently of setting.
- Complete and clear process documentation
Newer points of view might add:
- Two-stages submissions
- Open and inclusive culture (environment, research)
- Collaborative science
- Clear scientific communication
What is Open Science/Development?
To be Open, Science should be publicly available, reusable,
and transparent¹. It should aim at reaching:
Open Source Software Development is the idea of developing a software publicly, sharing it from the beginning of the development, fostering a democratic community of contributors in support of the project, using version control and software testing to improve quality.
1. The Turing Way Community, 2019 (Zenodo). https://the-turing-way.netlify.app (CC-BY 4.0)
- Open Data
- Open Source Software
- Open Hardware
- Open Access (outreach)
- Reproducible results
- Usable artefacts, independently of setting.
- Complete and clear process documentation
Why Open Science/Development?
OS/D makes academic research available to its real funding bodies: citizens, policy-makers, industry.
Well made OS/D guarantees more certain results and reduces the impact of human error.
It also reduces publication bias¹ ².
Ethics
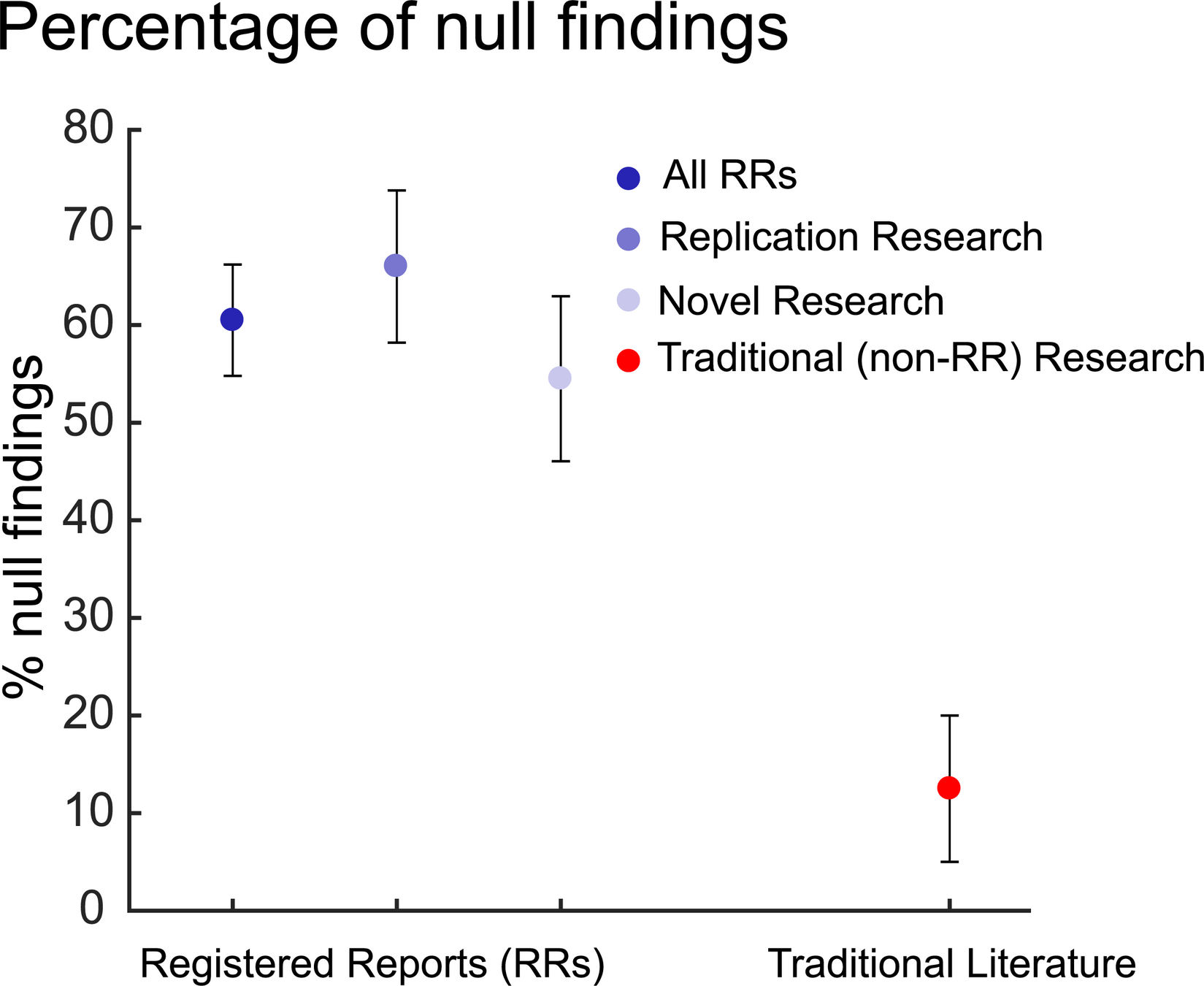
1. Allen & Mehler, 2019 (PLoS Biol) 2. Scheel, Schijen, & Lakens, 2021 (AMPPS)
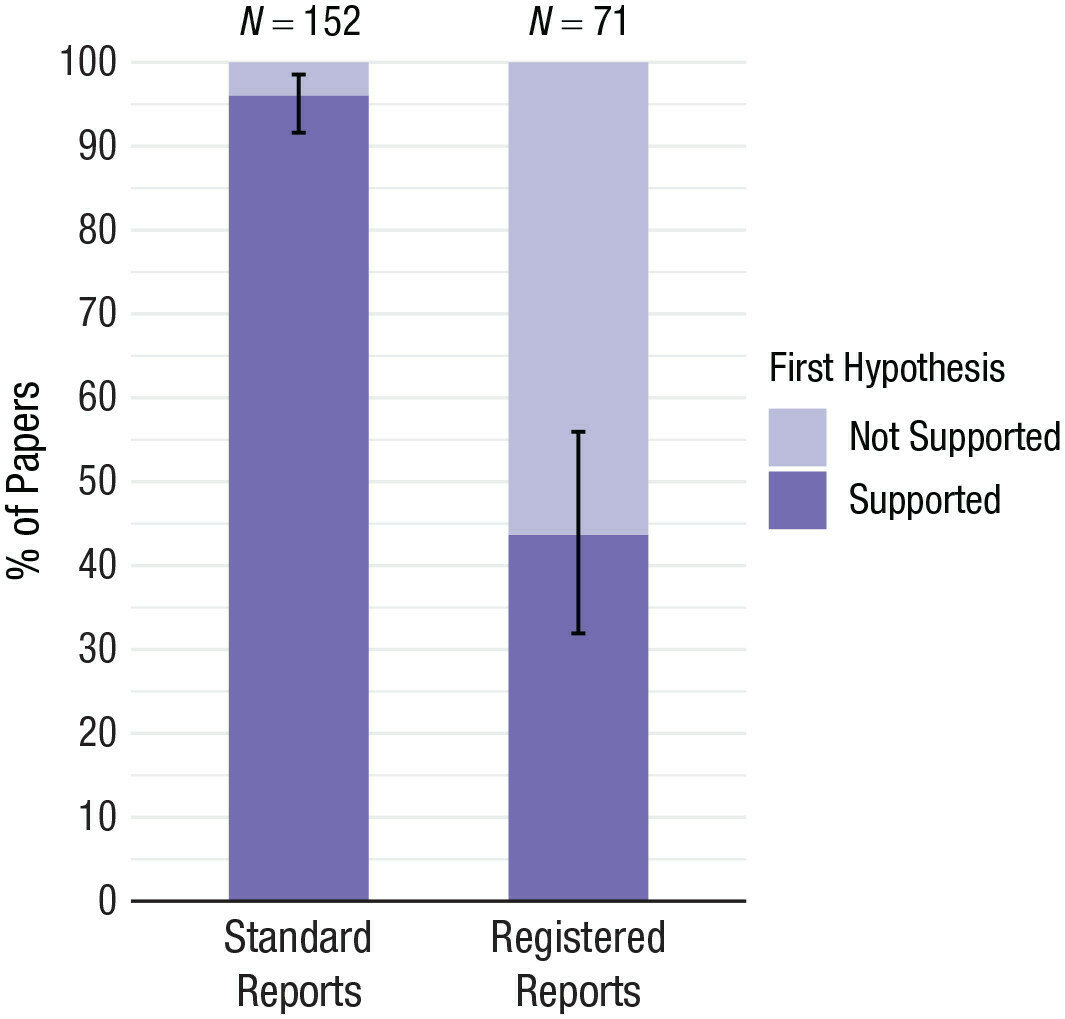
Why Open Science/Development?
OS/D increases the amount of citable output and the amount of citations¹ ².
Selfishness (career advantage)
1. McKiernan, et al., 2016 (eLife), 2. SpringerNature 2020
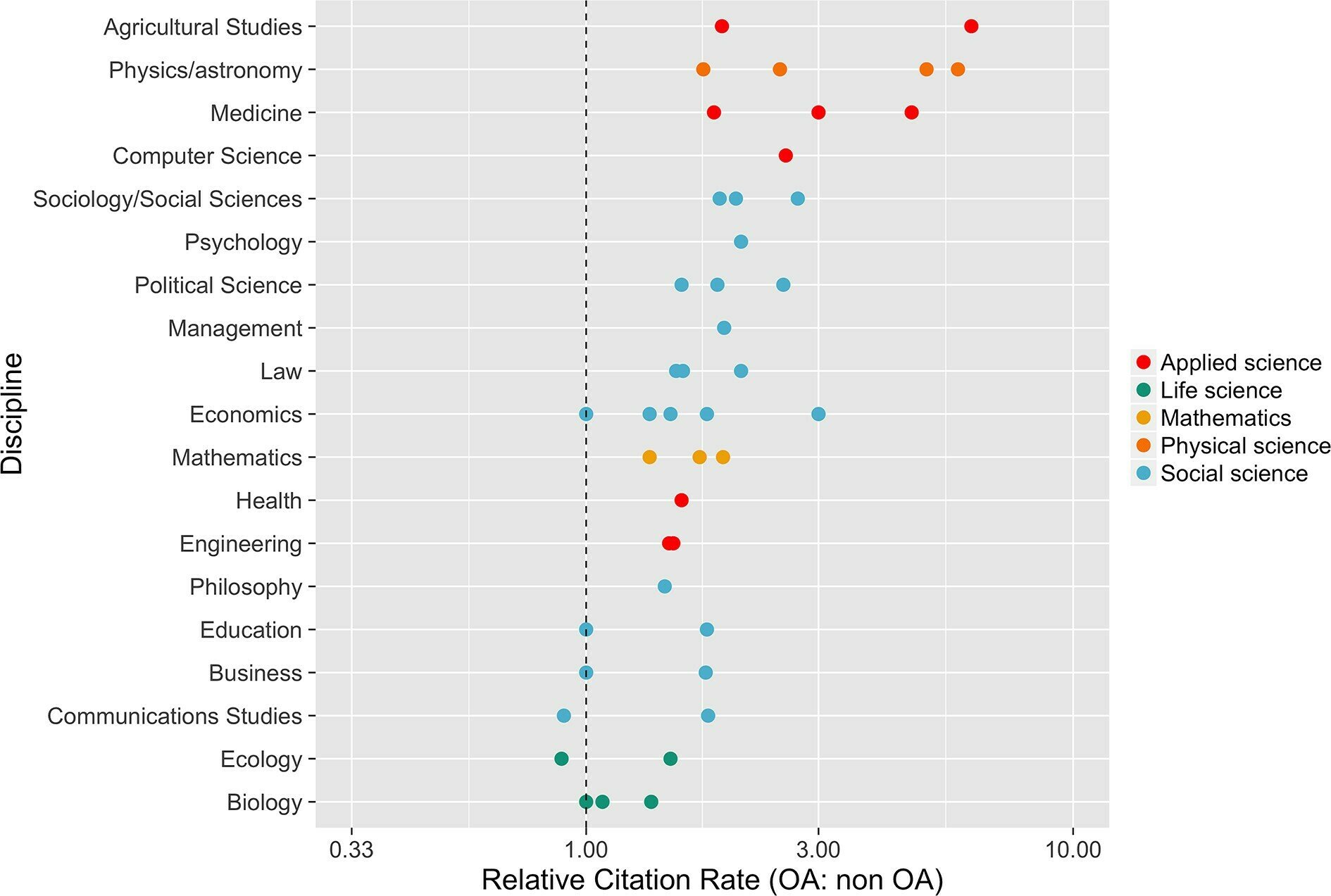
Your future self will be happier to collaborate with you!

Why Open Science/Development?
The demand from policy makers is increasing¹.
You have to.
1. McKiernan, et al., 2016 (eLife)
How do we do Open Science?
- Read literature, formulate hypotheses, identify your biases, formulate SOPs, decide methods.
- Find open development projects, contribute if needed, check licences.
- Decide a (permissive) licence for the artefacts, start open developing code (share it!), use VCS, test and document code, create releases.
- Submit a Registered Report (~ Introduction, hypotheses, methods, procedures, biases), get through first peer review round.
- Create containers.
- Collect data, curate them using community schemas (e.g. BIDS), upload them on public databases with embargo ("private time").
- Run analyses in containers, interpret results, write the second part of your Registered Report (~ Results, a posteriori analyses, discussion, conclusions)
- Publish open access.
- Remove embargoes.
- Rinse and repeat.
- Read literature, formulate hypotheses, identify your biases, formulate SOPs, decide methods.
- Find open development projects, contribute if needed, check licences.
- Decide a (permissive) licence for the artefacts, start open developing code (share it!), use VCS, test and document code, create releases.
- Submit a Registered Report (~ Introduction, hypotheses, methods, procedures, biases), get through first peer review round.
- Create containers.
- Collect data, curate them using community schemas (e.g. BIDS), upload them on public databases with embargo ("private time").
- Run analyses in containers, interpret results, write the second part of your Registered Report (~ Results, a posteriori analyses, discussion, conclusions)
- Publish open access.
- Remove embargoes.
- Rinse and repeat.
Take home #2
Make your Science Open.
It will cost time, but it will, eventually, give you a return.
3. Doing "Open" Science
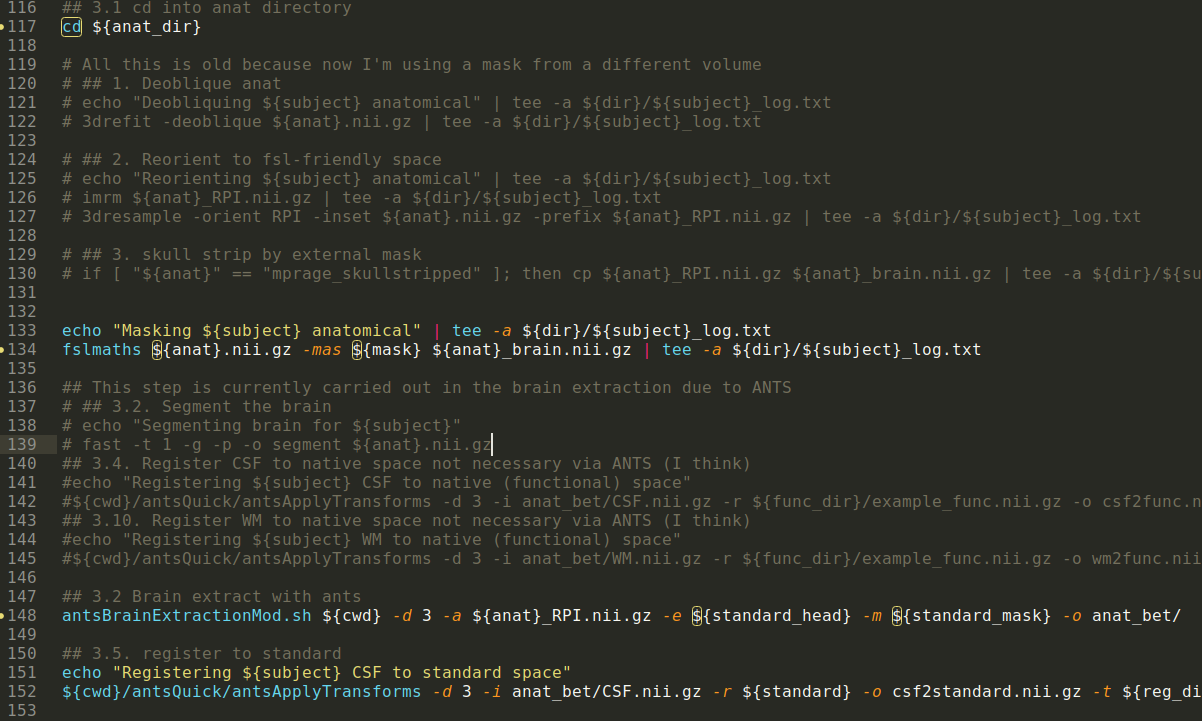
Standard Operating Procedures
https://github.com/TheAxonLab/hcph-sops
Contributions and communities
- The development can be very driven and focused on key points.
- Decision making is quick.
- Users might not be engaged enough to value your project.
- One developer = more time needed for new features, less reviewing.
- Less stability in the group = more time training.
- Smaller user base = code is less tested and consensus is not guaranteed
- The development can become more based on the help of the volunteers.
- Decision making is slower
- Sense of involvement and responsibility might increase recognition!
- Many developers = less time needed for new features and better quality!
- More stable people = more mentors.
- Bigger user base = better tested code and widespread consensus
Not all contributions are the same...
Independently from its kind, projects can have different types of contributions.
Different communities can have different requirements or follow different workflows.
Enters the contributors' guidelines
(and a code of conduct).

... but all should be recognised
Depending on the community and the governance scheme, contributions might be recognised differently. Check if it is explained clearly, if not ask about it.
One way of recognising contributors is the all-contributors specification.
Open Development
Open (Source Scientific Software) Development: the idea of developing a scientific tool:
- in an open and public way
- sharing it from the beginning of the development
- fostering a democratic community of contributors in support of the project
- acknowledging all contributions
- using version control and (automatic) testing
Two main elements: the tool itself and the community around it.
The tool or project is not necessarily code based!
Take home #3
Don't reinvent the wheel:
look for what you need, it might be out already in some other form!
Contribute to development or join a community: it might seem harder at first, but it will provide better artefacts (and improve your network!)
Disclaimer:
I am not a legal expert.
If you ever have any doubts, contact the Technology Transfer Office
of your University.
License your work
A work that is not licensed is not public (paradox!)
There are n+1 (open source) licences to pick up from.
www.choosealicense.org
The licence should be the first commit you make in a project.
Personal picks for science:
Apache 2.0 and CC-BY-ND-4.0
(consider L-GPLv3.0, and CC-BY-4.0 too)
Understand licensing and ownership
- Check the licence of code, data, and libraries you are "borrowing".
- Pay attention to single vs double licensing (e.g. academic vs commercial).
- Check licence compatibility.
- Remember that institutions might have rights to what their employees do:
- However, they can also help you with licensing and license enforcement.
EPFL is the owner of its employees’ inventions and software. Inventors or authors in case of software have the right to one-third of net revenue resulting from the commercialization of their inventions with some exceptions according to directives.
Licence compatibility
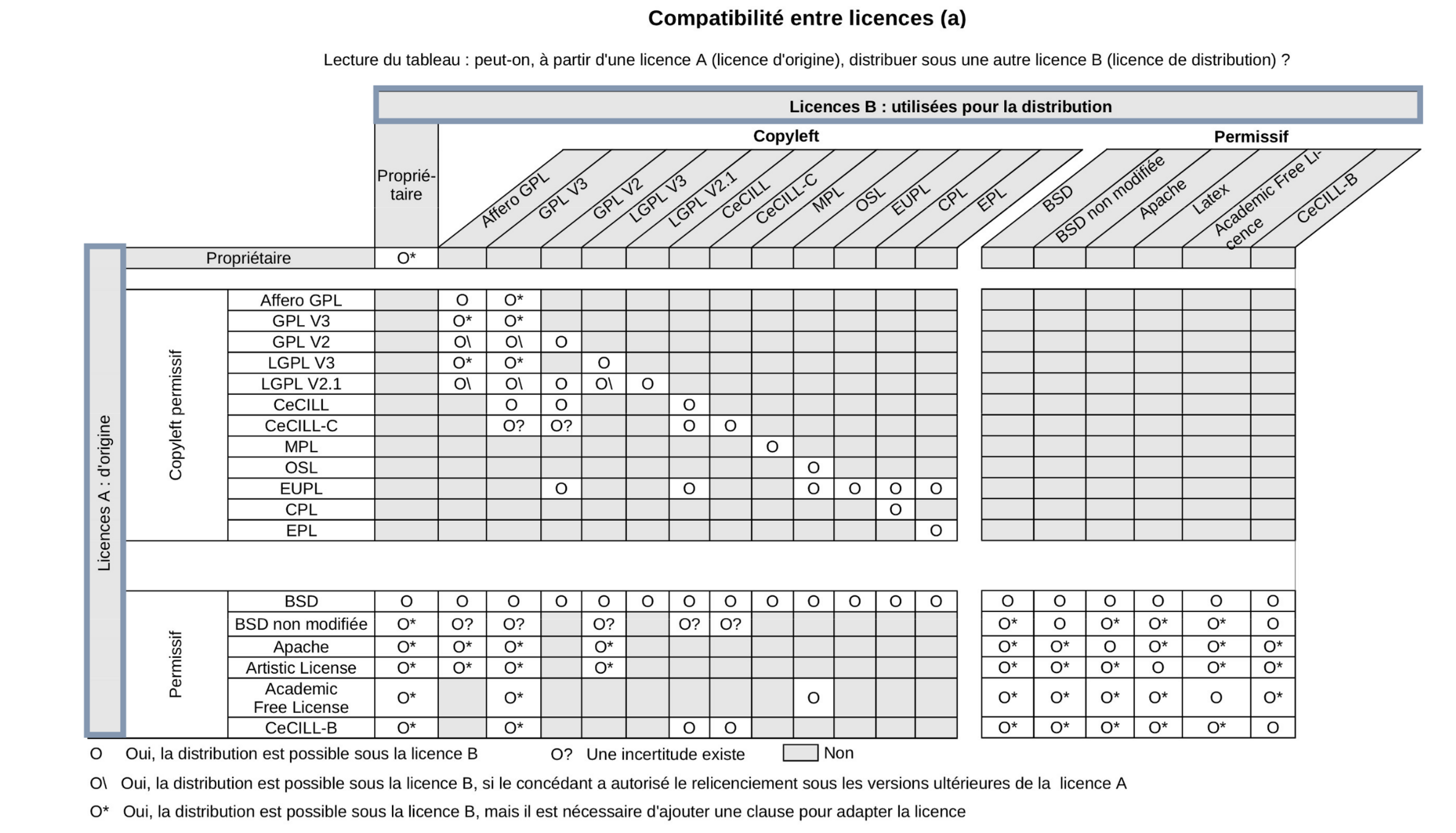
© Sebastien Adams, I WANT TO DISTRIBUTE MY SOFTWARE DEVELOPMENTS. HOW TO DEFINE AN OPEN LICENSING STRATEGY?
© Benjamin Jean (2011), Option libre. Du bon usage des licences libres.
License your work in the right way
- Put a copy of the licence or a link to it as close as possible to "borrowed" material, if not in it.
- If any license requires its adoption for derivatives (e.g. GPL), you must licence your work with the same licence.
- You can ask the original authors to change their licence (e.g. GPL to L-GPL) or give you special permissions.
- Remember to add licences disclaimers in all of your files.
[...]
if __name__ == "__main__":
_main(sys.argv[1:])
"""
Copyright 2022, Stefano Moia & EPFL.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""

License your work in the right way

[...]
License your work in the right way
MATLAB users:
- If you include external functions/scripts/libraries, your work is considered a derivative. Report licence, authors, and origin of the code inside them and respect their licence.
- Alternatively, don't include anything but state requirements / create install scripts.
- If you are releasing a build, the build is considered a derivative.
Python users:
- If you copy-paste code, your work is a derivative.
- Imports are trickier:
- Technically, GPL or © licences triggers on import.
- Practically, it's a really grey area. Make those imports optional, and specify their licences as clearly as possible.
Take home #4
Licensing is as complicated as it is important.
Double check licenses of borrowed material, report them in your own work
for licence tracking.
Remember that institutions have rights on your work, but can should help you with licensing.
Does any of these situations look familiar?
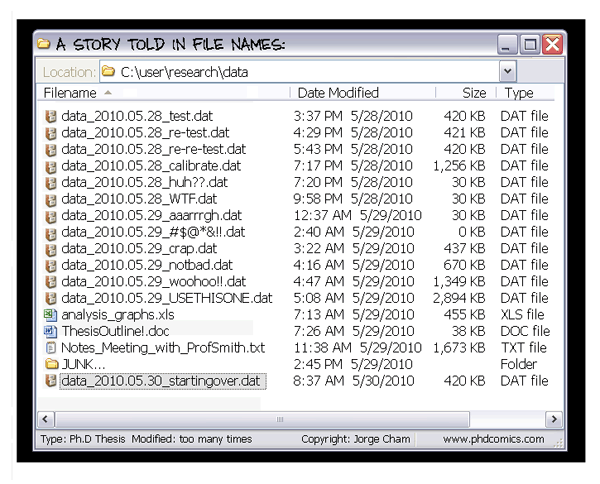
I can't work on that project now because my colleague/friend/dog is working on [a different part than what I'd modify of] it at the moment...

Version Control
Version Control
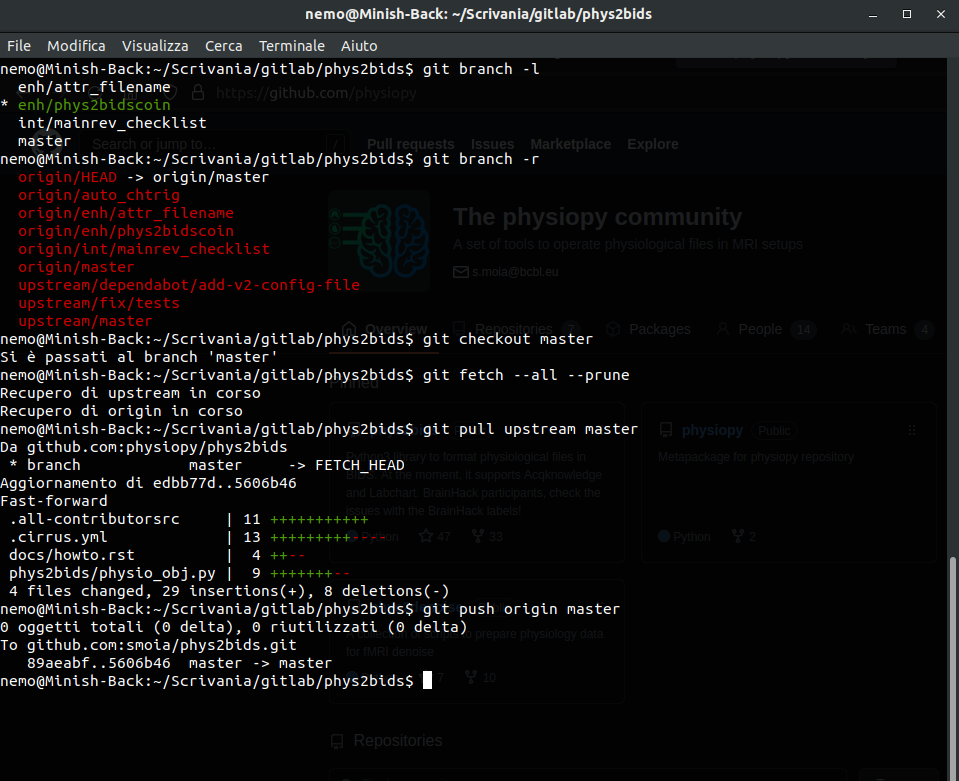
Version Control
Version control systems are a way to manage and track changes to files.




Content
Aggregation/delivery
A classic git(Hub) flow

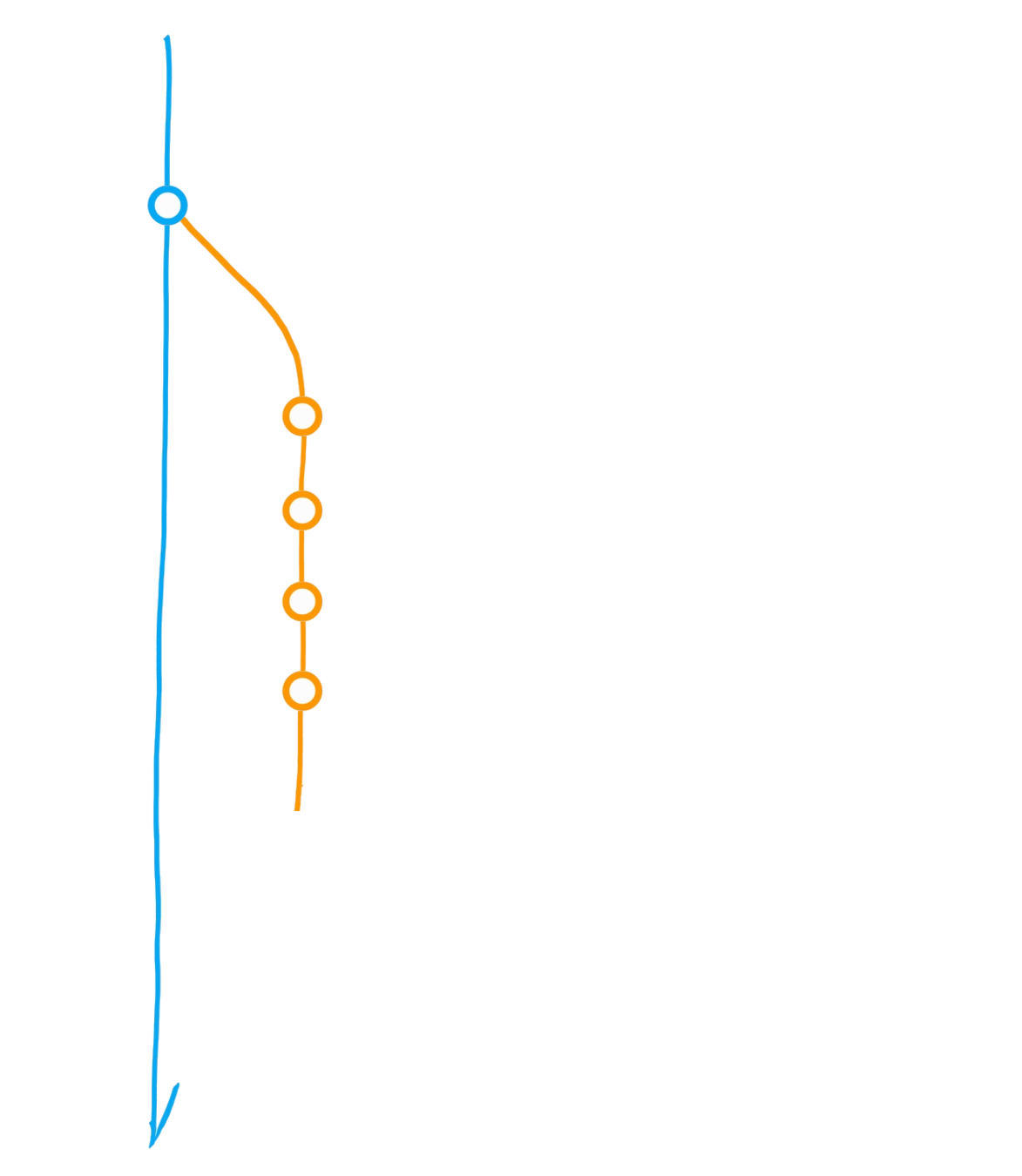
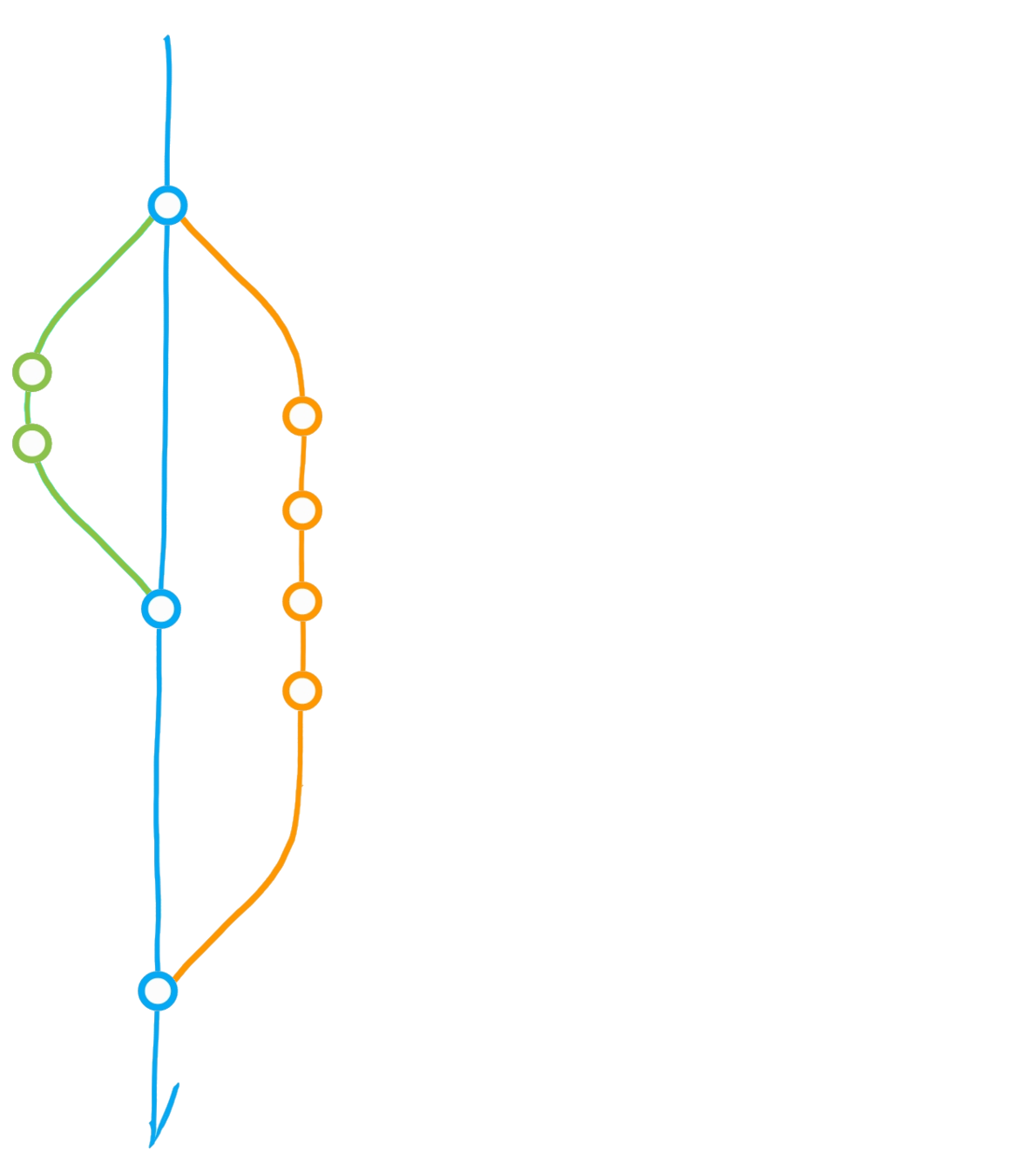
Create branch "dev"
Commit
Merge dev into main
Diverging main: conflict?
Merge main into dev
Initialise repository
"Main" branch
Main
Dev
Bug
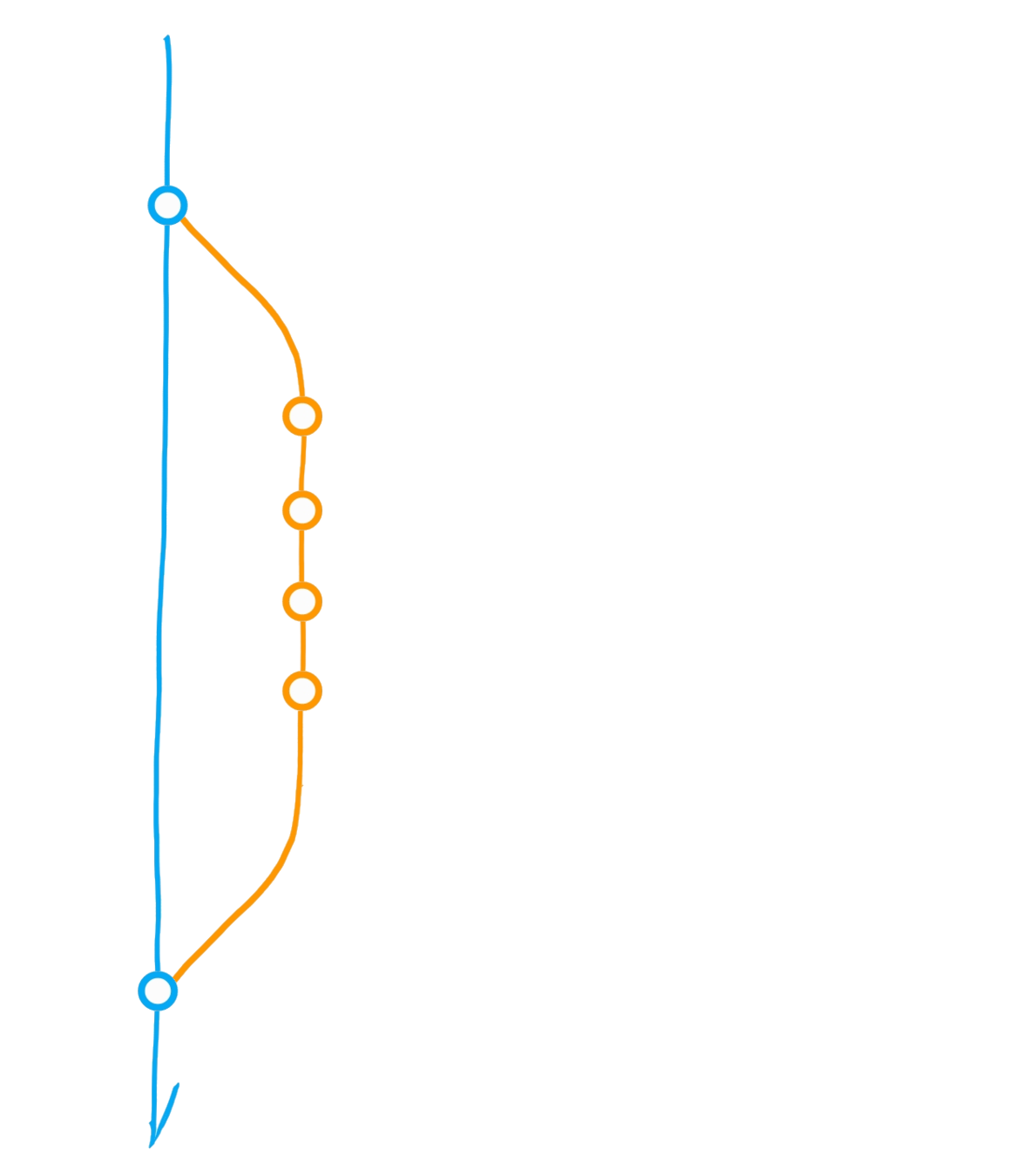
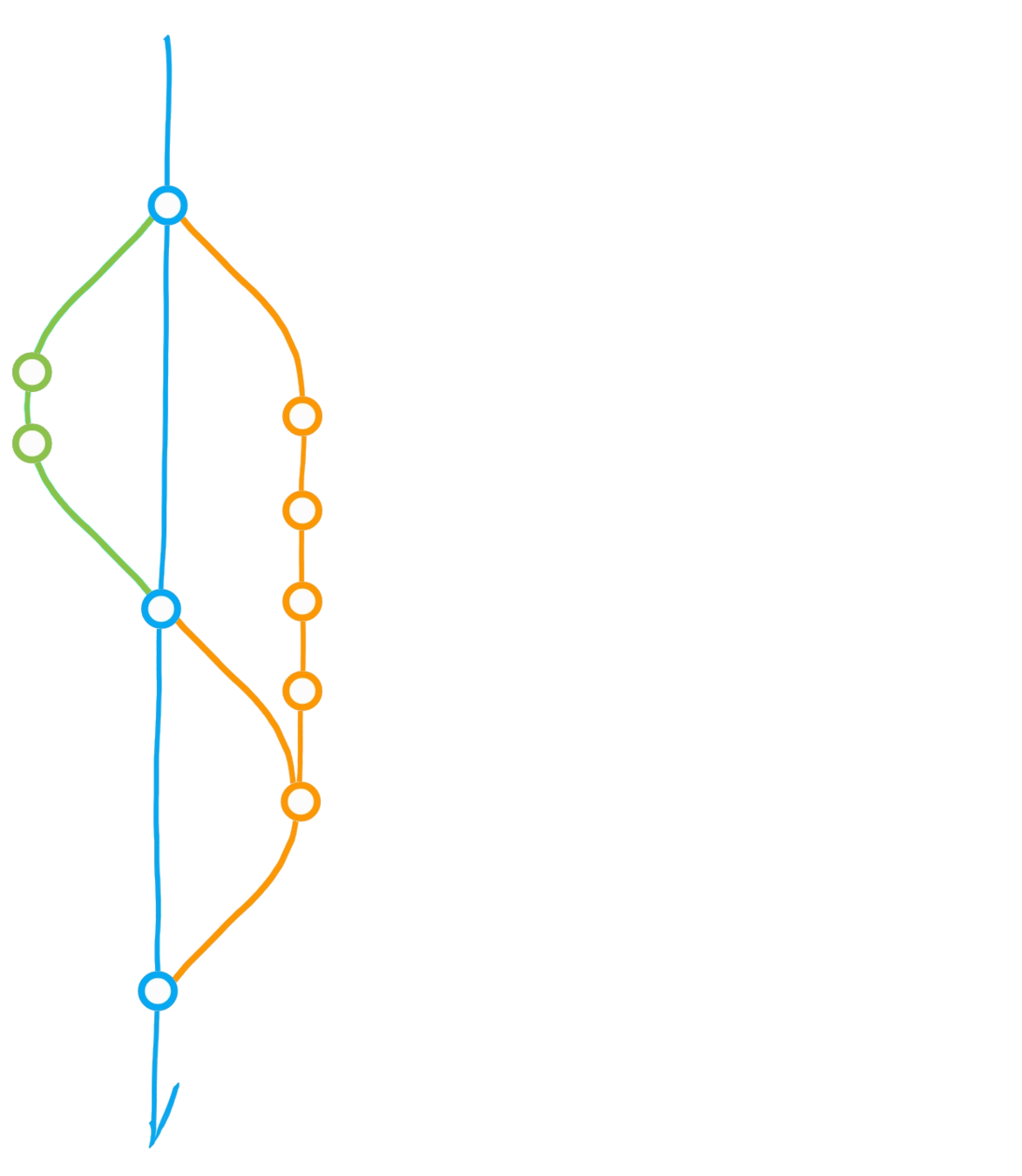
A classic git(Hub) flow
Create branch "dev"
Commit
Merge dev into main
Diverging main: conflict?
Merge main into dev
Initialise repository
"Main" branch

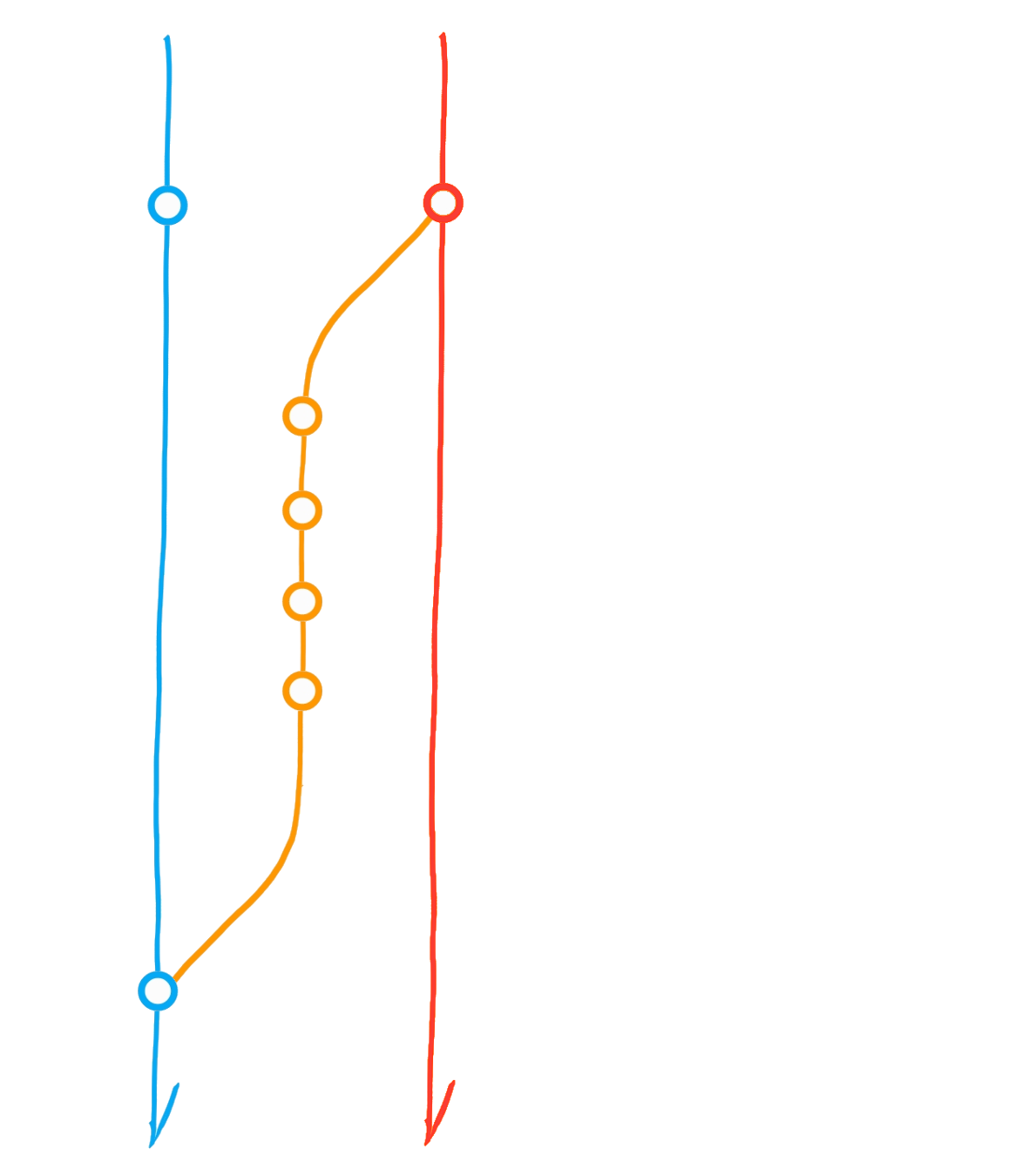

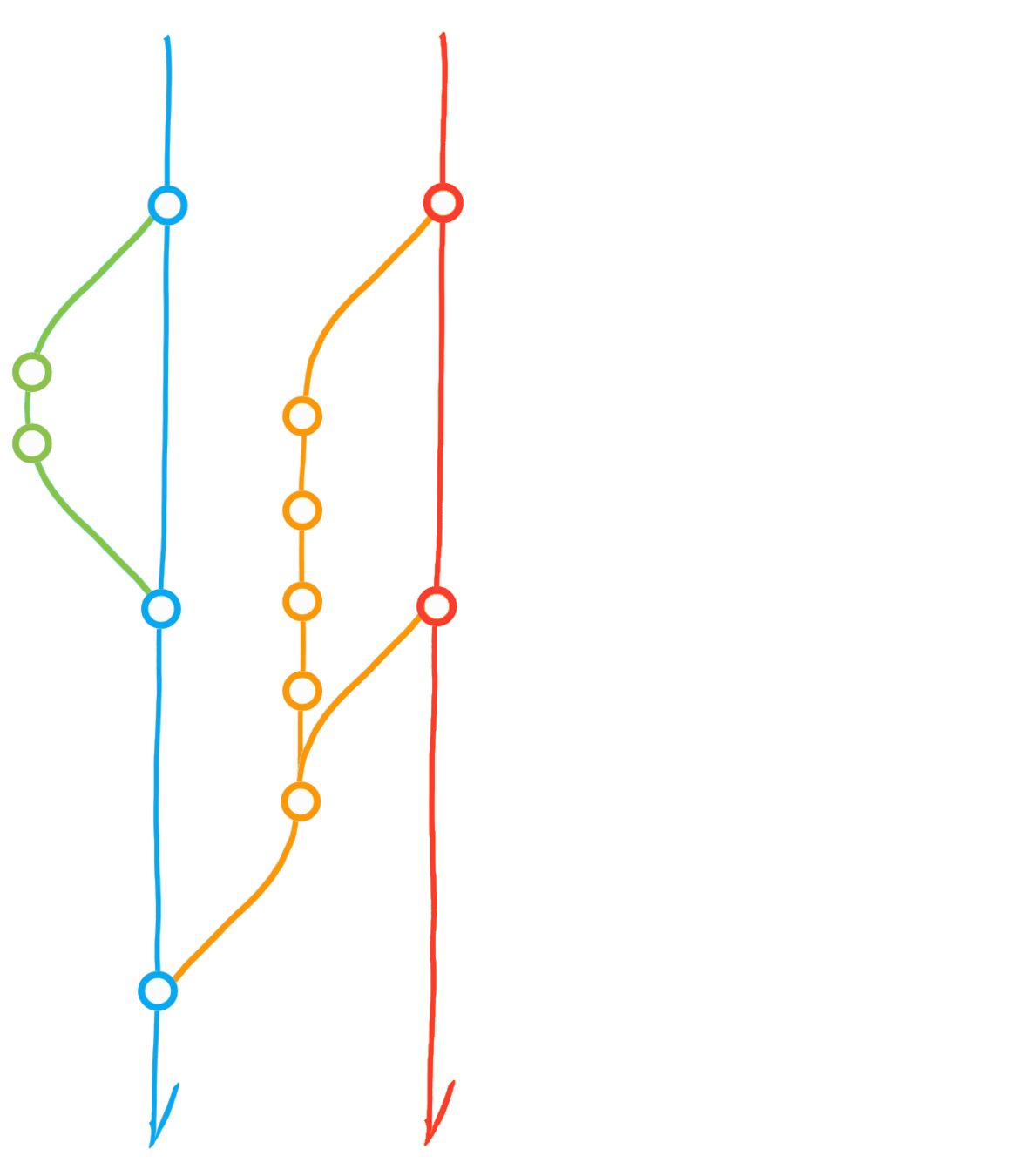

Fork ("upstream" vs "origin")
Pull from upstream
Merge origin/main into dev
Clone (local repository)
Pull Request
Pull from *
Push to *
Main
Dev
Upstream
Main
Origin
Dev
Main
(local)

VCS for data
File history
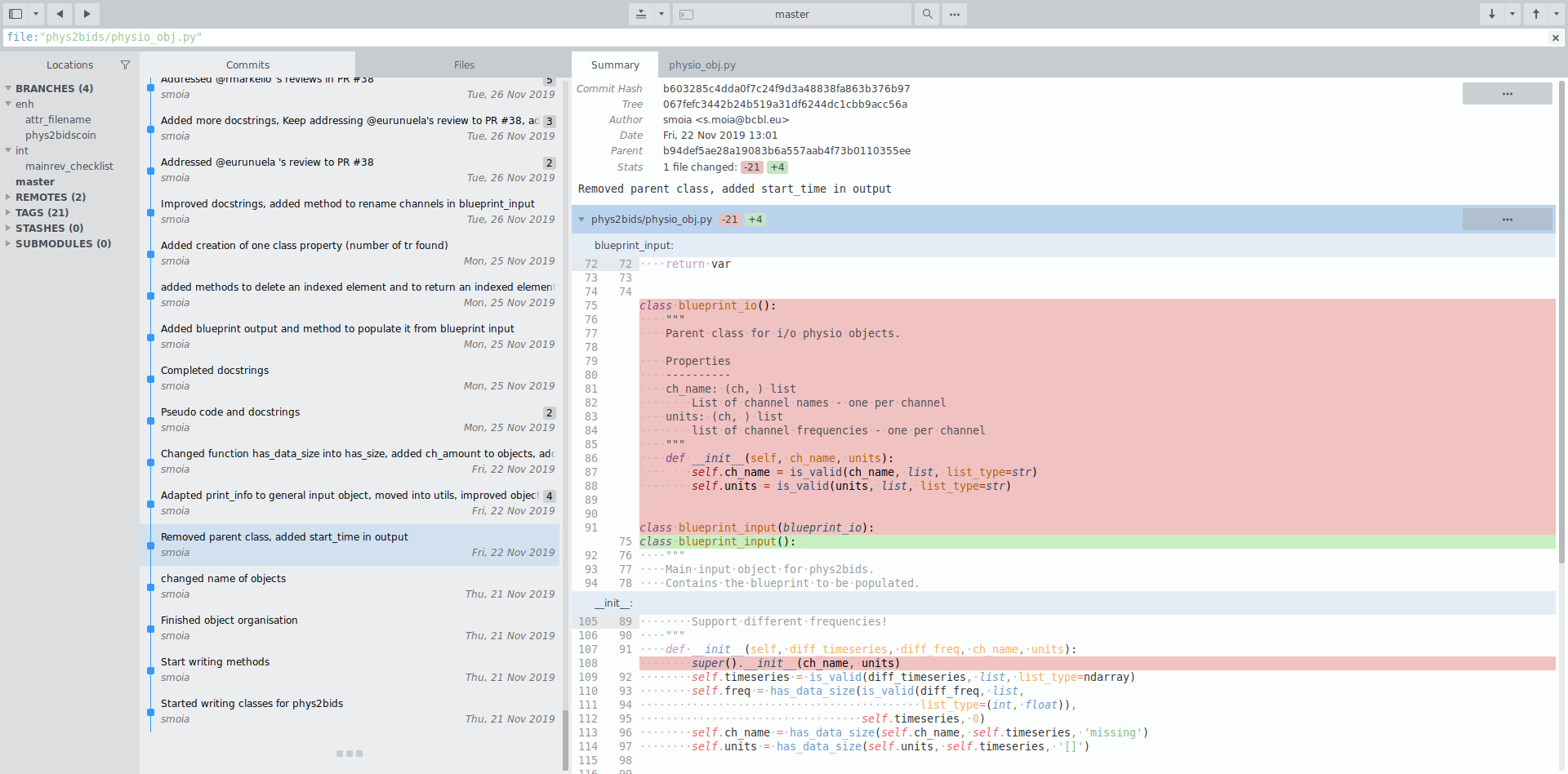
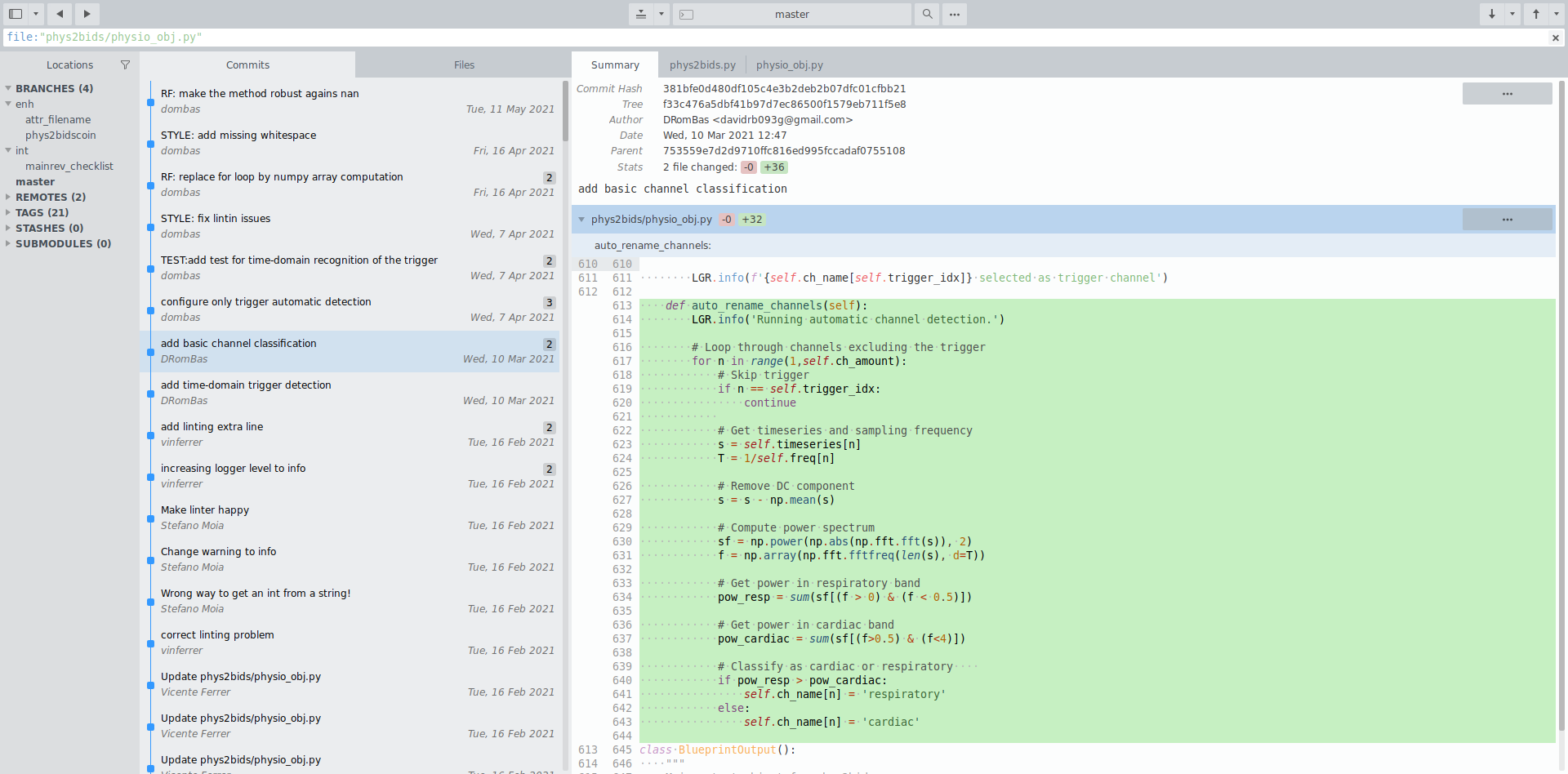
Automation at work
- Continuous Integration: frequently integrating new changes into the main branch of a tool. Normally, workflows run automatic steps at each integration, e.g. automatic testing.
- Continous Deployment: frequently deploying (releasing) new versions of a tool using automated workflows (e.g. right after integration).
Automation at work
- Pre-commit [local, remote]: Automate code checks and styling on git commit
- Pytest, pytest-cov [local, remote]: (automated) testing and coverage
- Codecov [remote]: automated code coverage change check
- Auto [remote]: automated version update, tag, release, and changelog
- Zenodo, PyPI [remote]: automated DOI and package publishing
- Readthedocs [remote]: (automated) documentation publishing

pip install pre-commit # Install via pip, or
# Comes installed with development extras
pip install -e /path/to/phys2cvr[dev]
cd /path/to/phys2cvr
pre-commit init
pre-commit run
Take home #5
Working with VCS allows you to:
-
track changes in time
-
access to automations
-
work in parallel on new features without disrupting the "main" version of your project
Bonus: it can force a team to double check projects!
Pre-registrations & Registered reports
Pre-registration
- Upload of hypotheses (and methods/protocols) on a public server (e.g. Open Science Framework)
- Embargoed until paper publication
- No peer review
- No certainty of publication
- Weaker version of open publishing
- Submission in two stages of a manuscript in a journal
- Public once accepted
- Two-stage peer review
- Higher certainty of publication (depending on journal)
- Stronger version of open publishing
Registered report
Registered reports
Data standards & metadata
Data standards & metadata
1. Gorgolewski, et al., 2016 (Scientific Data) 2. Zwiers, Moia, Oostenweld, 2022, (Front. Neuroinf.)
Take home #6
Adopt community data standards
and add metadata
to improve reusability!
Containerisation
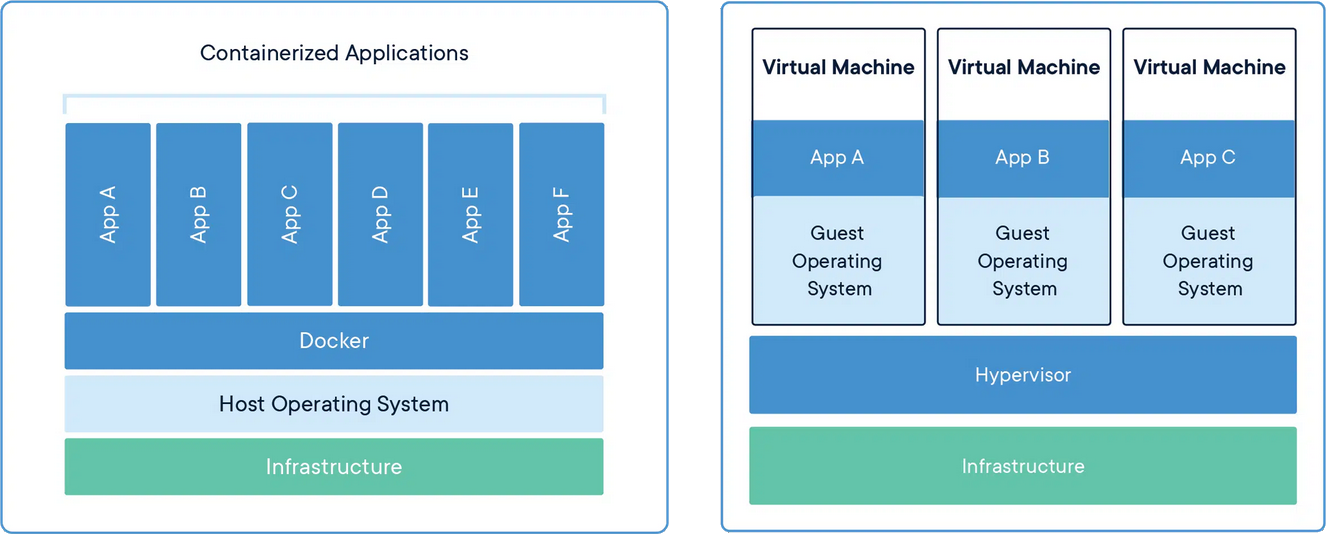

Docker vs Apptainer
Bootstrap: docker
From: python:3.8.13-slim-buster
%environment
export DEBIAN_FRONTEND=noninteractive
export TZ=Europe/Brussels
%post
# Set install variables, create tmp folder
export DEBIAN_FRONTEND=noninteractive
export TZ=Europe/Brussels
# Prepare repos and install dependencies
pip3 install nigsp[all]
# Final removal of lists and cleanup
rm -rf /var/lib/apt/lists/*
FROM python:3.8.13-slim-buster AS nigspdock
WORKDIR /app
# Prepare environment
COPY .. .
RUN pip3 install .[all]
ENV LANG="en_US.UTF-8" \
LC_ALL="en_US.UTF-8"
CMD nigsp
ARG BUILD_DATE
ARG VCS_REF
ARG VERSION
LABEL org.label-schema.build-date=$BUILD_DATE \
org.label-schema.name="NiGSP" \
org.label-schema.description="NiGSP: python library for Graph Signal Processing on Neuroimaging data" \
org.label-schema.url="https://github.com/miplabch/nigsp" \
org.label-schema.vcs-ref=$VCS_REF \
org.label-schema.vcs-url="https://github.com/miplabch/nigsp" \
org.label-schema.version=$VERSION \
org.label-schema.schema-version="1.0"
Docker
Apptainer
Docker vs Apptainer
Docker:
- Targeting Laptops: better OS support
- Offers public hub to share built containers
- Docker containers can be built in Singularity
Apptainer:
- Built for HPCs (Unix only), maintained by the Linux Foundation
- Easier syntax
- Supports Docker containers
Easily build a neuroimaging container
Easily build a neuroimaging container
BIDSapps: containers for BIDS pipelines
1. Gorgolewski, et al., 2017 (PLoS Comp. Biol.)
Take home #7
Don't think that because your study "works", it's reproducible.
Create (or adopt) containers and share them with your code to maximise the reproducibility of your analyses.
Last take home message:
What you do in your scientific work has an impact on society.
It's not about you.
Open science can help you with it.
Thanks to...
...the MIP:Lab @ EPFL
...you for the (sustained) attention!
That's all folks!
...the Focus lab, for having me here
(and allowing me to dip my feet into research)
...the Physiopy contributors


| smoia | |
| @SteMoia | |
| s.moia.research@gmail.com |
Stefano Moia, 2023
1. Be honest about generalisation of results, take preventive measures to improve it.
2. Make your science open, it's a time investment, with a good return over time.
3. Don't reinvent the wheel, contribute to existing projects!
4. Pay attention to Licencing!
5. Working with VCS allows you to track changes in time and implement automation.
6. Adopt data standards and add metadata to improve reusability.
7. Use containers to maximise results reproducibility.
Take home messages
Any question [/opinions/objections/...]?
Oh, and don't forget!

Oh, and don't forget!

Open Science (Turin 2023)
By Stefano Moia
Open Science (Turin 2023)
CC-BY 4.0 Stefano Moia, 2023. Images are property of the original authors and should be shared following their respective licences. This presentation is otherwise licensed under CC BY 4.0. To view a copy of this license, visit https://creativecommons.org/licenses/by/4.0/



