PostgreSQL
TRAINING
(CGSO)
Abdullah Fathi


Introduction
- General purpose and object-relational database management system, the most advanced open source database system
- PostgreSQL was designed to be portable so that it could run on various platforms such as Mac OS X, Solaris, and Windows
- Free and open source software
- Requires very minimum maintained efforts because of its stability
Installation
Install PostreSQL
- Installation Directory
- Select Components (Server, pgAdmin, CLI Tools)
- Data Directory
- Enter db superuser(postgres) password
- Port: 5432
Verify the Installation
- Open "SQL Shell (psql)"
- issue command: SELECT version();
Connect to PostgreSQL Server
psql
- Launch program: "SQL Shell (psql)"
- Enter necessary information
- Interact with PostgreSQL DB by issuing an SQL statement
pgAdmin
- Launch program: "pgAdmin4"
- Right click the Servers node
- Select create -> Server...
- Enter Server Name
- Click "Connection" tab
- Enter "Host" and "password" for the postgres user
- Click Save button

Expand the server

Open Query Tool
Enter the query

Connect to PostgreSQL db from other applications


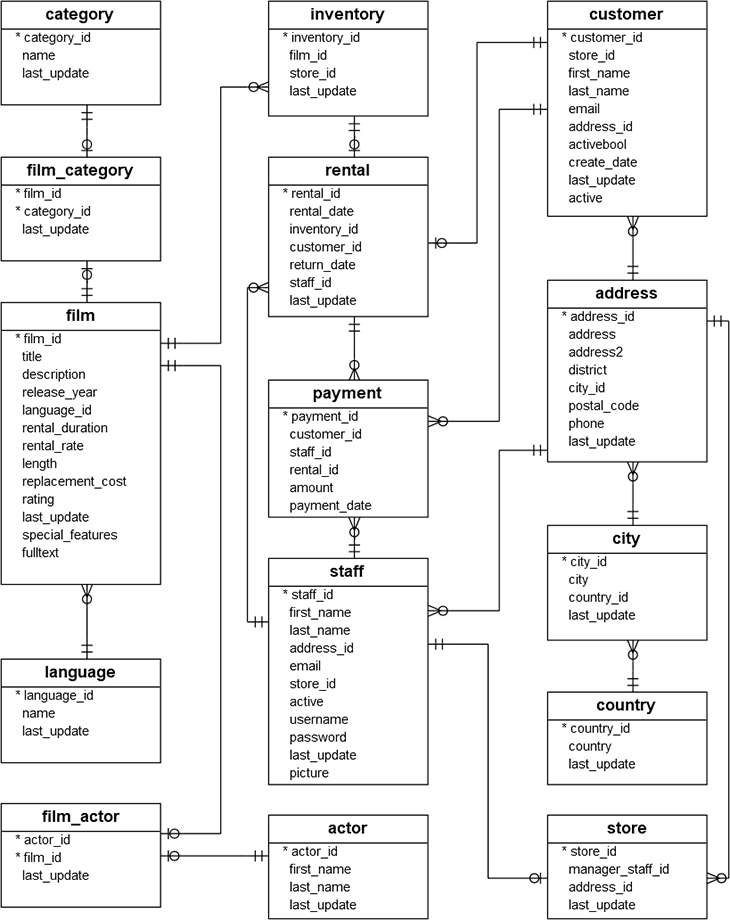
PostgreSQL Sample Database
- actor: stores actors data including first name and last name
- film: stores films data such as title, release year, length, rating, etc.
- film_actor: stores the relationships between films and actors.
- category: stores film's categories data
- film_category: stores the relationships between films and categories.
- store: contains the store data including manager staff and address.
DVD rental database (cont..)
- inventory: stores inventory data.
- rental: stores rental data.
- payment: stores cutomer's payments.
- staff: stores customer's payments.
- customer: stores customers data.
- address: stores address data for staff and customers.
- city: stores the city names.
- country: stores the country names.
Create a new Database
CREATE DATABASE dvdrental;Create Database Statement
Load the sample db using psql tool
- Download
- Launch Command Prompt (cmd)
- Navigate to bin folder of the PostgreSQL installation folder
C:\>cd C:\Program Files\PostgreSQL\11\bin- Use pg_restore to load sample db
pg_restore -U postgres -d dvdrental C:\dvdrental\dvdrental.tarLoad the sample db using pgAdmin
- Download
- Launch pgAdmin tool
- Right click on database and choose Restore... menu item
- Provide the path to sample db
C:\>cd C:\Program Files\PostgreSQL\11\bin- Click restore button
PostgreSQL Database Objects
Databases
Is a container of other objects such as tables, views, function, and indexes.
Tables
Used to store the data.
A special feature of PostgreSQL is table inheritence. A table (child table) can inherit from another table (parent table), so when you query the data from the child table, the data from the parent table is also showing up
Schemas
Is a logical container of tables and other objects inside a database. Schema is a part of the ANSI-SQL standard.
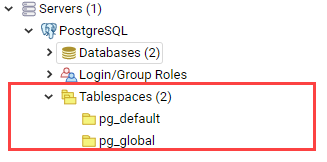
Tablespaces
Tablespace is a location on disk where PostgreSQL stores data files containing database objects e.g. indexes and tables.
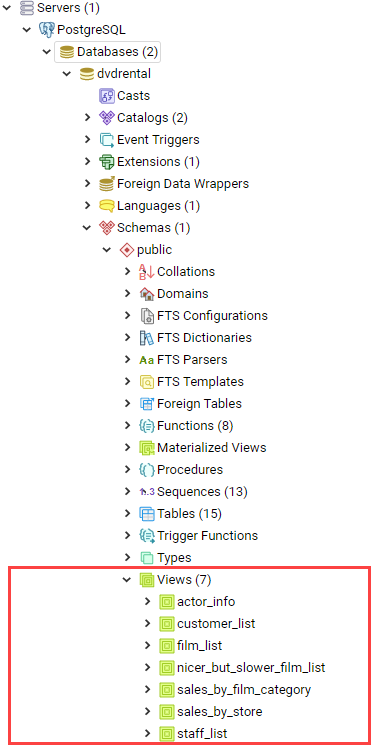
Views
Virtual table that is used to simplify complex queries and to apply security for a set of records
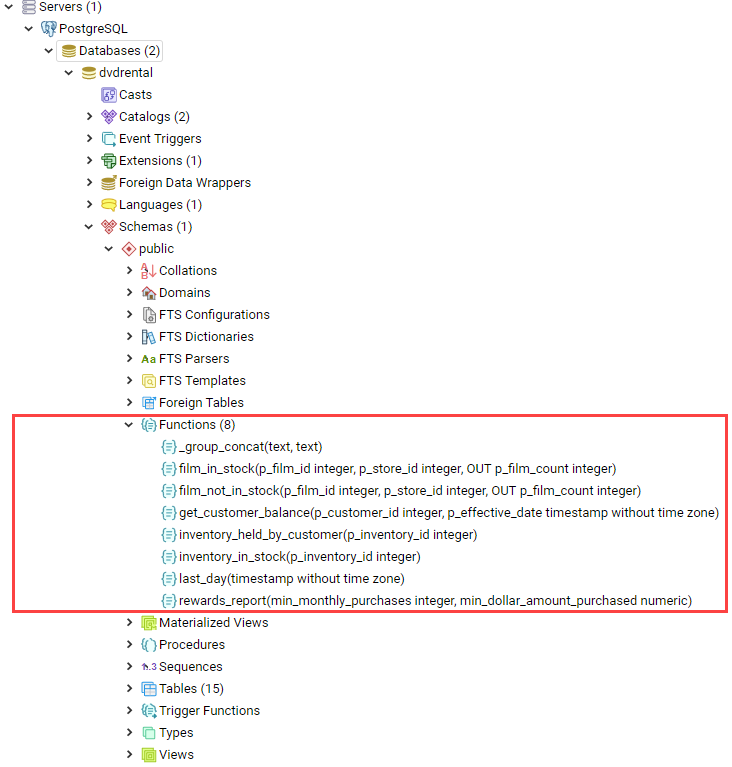
Functions
Is a block reusable SQL code that returns a scalar value of a list record.
Operators
Operators are symbolic functions. PostgreSQL allows you to define custom operators
Casts
Enable you to convert one data type into another data type
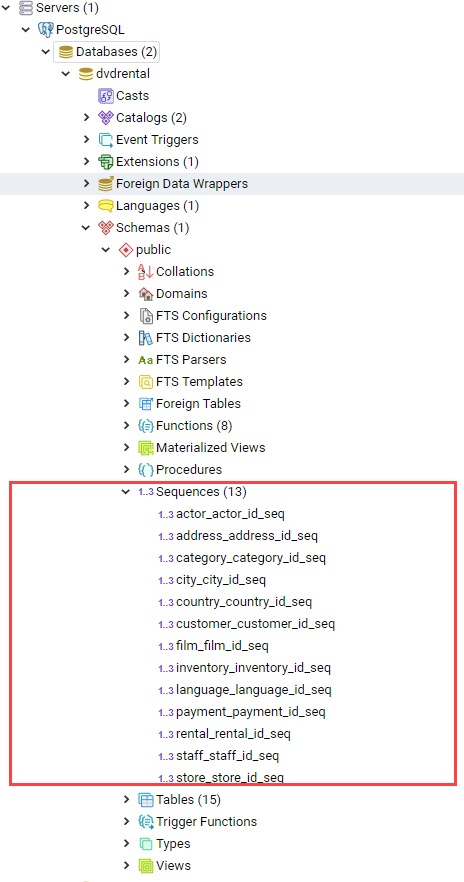
Sequence
Used to manage auto-increment columns that defined in a table as a serial column
Extension
Wrap other objects including types, casts, indexes, functions, etc. into a single unit.

PostgreSQL SELECT Statement
- Query data from tables using the SELECT statement
- One of the most complex statements in PostgreSQL
- It has many clauses that can be used to form a flexible query
SELECT statement clauses:
- DISTINCT: Select distinct rows
- ORDER BY: Sort rows
- WHERE: Filter rows
- LIMIT or FETCH: Select a subset of rows from a table
- GROUP BY: Group rows into groups
- HAVING: Filter groups
- Join with other tables:
- INNER JOIN
- LEFT JOIN
- FULL OUTER JOIN
- CROSS JOIN
- Perform ser operations:
- UNION
- INTERSECT
- EXCEPT
SELECT statement syntax
SELECT
column_1,
column_2,
...
FROM
table_name;PostgreSQL SELECT examples
Customer table

1. Use SELECT statement to query data from one column
SELECT
first_name
FROM
customer;2. Use SELECT statement to query data from multiple column
SELECT
first_name,
last_name,
email
FROM
customer;3. Use SELECT statement to query data in all columns
SELECT
*
FROM
customer;4. Use SELECT statement with expression
SELECT
first_name || ' ' || last_name AS full_name,
email
FROM
customer;We used concatenation operator ||
5. Use SELECT statement with only expression
SELECT 5 * 3 AS result;We skip the FROM clause because the statement does not refer to any table
PostgreSQL
ORDER BY
Sort rows returned from the SELECT statement in ascending or descending order based on specified criteria
ORDER BY clause syntax
SELECT
column_1,
column_2
FROM
tbl_name
ORDER BY
column_1 ASC,
column_2 DESC;PostgreSQL
ORDER BY examples
Customer table
1. Query sorts customers by the first name in ascending order:
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC;
2. Query sorts customers by the last name in descending order:
SELECT
first_name,
last_name
FROM
customer
ORDER BY
last_name DESC;
3. Query sorts customers by the first name in ascending order and then last name in descending order:
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC,
last_name DESC;
PostgreSQL
SELECT DISTINCT
DISTINCT clause is used in the SELECT statement to remove duplicate rows from a result set
DISTINCT clause syntax
SELECT
DISTINCT column_1
FROM
table_name;If you specify multiple columns, the DISTINCT clause will evaluate the duplicate based on the combination of values of these columns
SELECT
DISTINCT column_1, column_2
FROM
table_name;DISTINCT ON (expression)
to keep the "first" row of each group of duplicates:
SELECT
DISTINCT ON (column_1) column_alias,
column_2
FROM
table_name
ORDER BY
column_1,
column_2;PostgreSQL
SELECT DISTINCT examples
1. Create new table named t1 and insert data into the table
CREATE TABLE t1 (
id serial NOT NULL PRIMARY KEY,
bcolor VARCHAR,
fcolor VARCHAR
);2. Insert some rows into the t1 table
INSERT INTO t1 (bcolor, fcolor)
VALUES
('red', 'red'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue'),
('green', 'red'),
('green', 'blue'),
('green', 'green'),
('blue', 'red'),
('blue', 'green'),
('blue', 'blue');3. Query the data from the t1 table using SELECT statement
SELECT
id,
bcolor,
fcolor
FROM
t1;
DISTINCT on one column example
SELECT
DISTINCT bcolor
FROM
t1
ORDER BY
bcolor;
DISTINCT on multiple columns example
SELECT
DISTINCT bcolor,
fcolor
FROM
t1
ORDER BY
bcolor,
fcolor;
DISTINCT ON example
SELECT
DISTINCT ON
(bcolor) bcolor,
fcolor
FROM
t1
ORDER BY
bcolor,
fcolor;

DISTINCT ON process:
PostgreSQL
WHERE clause
WHERE clause is to filter rows returned from the SELECT statement
WHERE clause syntax
SELECT select_list
FROM table_name
WHERE condition;- WHERE clause uses the condition to filter the rows returned from the SELECT statement
- The condition must evaluate to true, false, or unknown
- It can be Boolean expression or a combination of Boolean expression using AND and OR operators
- Only rows that cause the condition evaluates to true will be included in the result set
| Operator | Description |
|---|---|
| = | Equal |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal |
| <= | Less than or equal |
| <> or != | Not equal |
| AND | Logical operator AND |
| OR | Logical operator OR |
Standard comparison operators
PostgreSQL
WHERE clause examples
Customer table
1. WHERE clause with the equal (=) operator
SELECT
last_name,
first_name
FROM
customer
WHERE
first_name = 'Jamie';
2. WHERE clause with the AND operator
SELECT
last_name,
first_name
FROM
customer
WHERE
first_name = 'Jamie'
AND last_name = 'Rice';
3. WHERE clause with the OR operator
SELECT
first_name,
last_name
FROM
customer
WHERE
last_name = 'Rodriguez' OR
first_name = 'Adam';
4. WHERE clause with the IN operator
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name IN ('Ann','Anne','Annie');
5. WHERE clause with the LIKE operator
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE 'Ann%'
The % is called a wildcard that matches any string. The 'Ann%' pattern matches any string that starts with 'Ann'
6. WHERE clause with the BEtWEEN operator
SELECT
first_name,
LENGTH(first_name) name_length
FROM
customer
WHERE
first_name LIKE 'A%' AND
LENGTH(first_name) BETWEEN 3 AND 5
ORDER BY
name_length;
6. WHERE clause with the not equal operator (<>)
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE 'Bra%' AND
last_name <> 'Motley';
PostgreSQL
LIMIT clause
LIMIT clause is an optional clause of the SELECT statement that returns a subset of rows returned by query
LIMIT clause syntax
SELECT
*
FROM
table_name
LIMIT n;The statement returns n rows generated by the query. If n is zero, the query returns an empty set.
OFFSET clause syntax
SELECT
*
FROM
table
LIMIT n OFFSET m;Skip rows before returning n rows
PostgreSQL
LIMIT clause examples
Film table

1. LIMIT clause to get the first 5 films ordered by film_id
SELECT
film_id,
title,
release_year
FROM
film
ORDER BY
film_id
LIMIT 5;
2. Retrieve 4 films starting from the third one ordered by film_id
SELECT
film_id,
title,
release_year
FROM
film
ORDER BY
film_id
LIMIT 4 OFFSET 3;
2. Get the top 10 most expensive films
SELECT
film_id,
title,
rental_rate
FROM
film
ORDER BY
rental_rate DESC
LIMIT 10;
PostgreSQL
IN operator
Use IN operator in the WHERE clause to check if a value matches any value in a list of values
IN operator syntax
value IN (value1,value2,...)The expression returns true if the value matches any value in the list
value IN (SELECT value FROM tbl_name);The statement inside the parentheses is called a subquery, which is a query nested inside another query
PostgreSQL
IN operator examples
1. Get rental information of customer id 1 and 2
SELECT
customer_id,
rental_id,
return_date
FROM
rental
WHERE
customer_id IN (1, 2)
ORDER BY
return_date DESC;
2. Find all rentals with customer id is not 1 or 2
SELECT
customer_id,
rental_id,
return_date
FROM
rental
WHERE
customer_id NOT IN (1, 2);
3. Returns a list of customer id of customers that has rental's return date on 2005-05-27
SELECT
first_name,
last_name
FROM
customer
WHERE
customer_id IN (
SELECT
customer_id
FROM
rental
WHERE
CAST (return_date AS DATE) = '2005-05-27'
);
PostgreSQL
BETWEEN operator
Use BETWEEN operator to match a value against a range of values
BETWEEN operator syntax
value BETWEEN low AND high;If the value is greater than or equal to the low value and less than or equal to the high value, the expression returns true, otherwise, it returns false
value NOT BETWEEN low AND high;If you want to check if a value is out of a range, you combine the NOT operator with the BETWEEN operator
PostgreSQL
BETWEEN operator examples
Payment table

1. Select the payment whose amount is between 8 ad 9
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount BETWEEN 8
AND 9;

2. get payments whose amount is not in the range of 8 and 9
SELECT
customer_id,
payment_id,
amount
FROM
payment
WHERE
amount NOT BETWEEN 8
AND 9;
3. Check a value against of date ranges by using the literal date in ISO 8601 format
SELECT
customer_id,
payment_id,
amount,
payment_date
FROM
payment
WHERE
payment_date BETWEEN '2007-02-07'
AND '2007-02-15';
PostgreSQL
LIKE operator
Use LIKE operator for pattern matching technique
- Construct a pattern by combining a string with wildcard characters and use the LIKE or NOT LIKE operator to find the matches:
- Percent (%): for matching any sequence of characters
- Underscore (_) for matching any single character
- If the pattern does not contain any wildcard character, the LIKE operator acts like the equal (=) operator
LIKE operator syntax
string LIKE patternThe expression returns true if the string matches the pattern, otherwise it returns false
string NOT LIKE patternThe expression returns true if LIKE returns true and vice versa
PostgreSQL
LIKE operator examples
SELECT
'foo' LIKE 'foo', -- true
'foo' LIKE 'f%', -- true
'foo' LIKE '_o_', -- true
'bar' LIKE 'b_'; -- false, because it find matches string begin with letter b and followed by any single character1. Find cutomers whose first name contains er string
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE '%er%'
2. Find cutomers whose first name begins with any single character, followed by the literal string her, and ends with any number of characters
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE '_her%';
PostgreSQL
NOT LIKE operator examples
1. Find cutomers whose first name does not begin with Jen
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name NOT LIKE 'Jen%';
PostgreSQL extension of LIKE operator
PostgreSQL provides the ILIKE operator that acts like the LIKE operator. ILIKE operator matches value
case-insensitively
1. The BAR% pattern matches any string that begins with BAR, Bar, BaR, etc.
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name ILIKE 'BAR%';
PostgreSQL also provides some operators that act like the LIKE, NOT LIKE, ILIKE and NOT ILIKE operator as shown below:
- ~~ is equivalent to LIKE
- ~~* is equivalent to ILIKE
- !~~ is equivalent to NOT LIKE
- !~~* is equivalent to NOT ILIKE
PostgreSQL
IS NULL operator
NULL means missing or not applicable information
1. Create contacts table that stores the first name, last name, email and phone number of contact.
CREATE TABLE contacts(
id INT GENERATED BY DEFAULT AS IDENTITY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL,
phone VARCHAR(15),
PRIMARY KEY (id)
);2. Define the phone column as nullable column and insert NULL into the phone column
INSERT INTO contacts(first_name, last_name, email, phone)
VALUES
('John','Doe','john.doe@example.com',NULL),
('Lily','Bush','lily.bush@example.com','(408-234-2764)');SELECT
id,
first_name,
last_name,
email,
phone
FROM
contacts
WHERE
phone = NULL;3. Find the contact who does not have a phone number
The statement returns no row because the expression phone = NULL always return false. Even though there is NULL in the phone column, the expression NULL = NULL returns false. This is because NULL is not equal to any value even itself
IS NULL operator syntax
value IS NULLThe expression returns true if the value is NULL or false if it is not
PostgreSQL
IS NULL operator examples
Get the contact who does not have any phone number stored in the phone column
SELECT
id,
first_name,
last_name,
email,
phone
FROM
contacts
WHERE
phone IS NULL;
PostgreSQL
IS NOT NULL operator examples
Get the contact who does have phone number stored in the phone column
SELECT
id,
first_name,
last_name,
email,
phone
FROM
contacts
WHERE
phone IS NOT NULL;
PostgreSQL
ALIAS operator
PostgreSQL alias assigns a table or a column a temporary name in a query. The aliases only exist during the execution of the query
Column ALIAS operator syntax
SELECT column_name AS alias_name
FROM table;the column_name is assigned an alias as alias_name. The AS keyword is optional so you can skip it
PostgreSQL
Column ALIAS operator examples
Find full names of all customers
SELECT
first_name || ' ' || last_name AS full_name
FROM
customer
ORDER BY
full_name;
- PostgreSQL evaluates the ORDER BY clause after the SELECT clause, you can use the column alias in the ORDER BY clause.
- For the other clauses evaluated before the SELECT clause such as WHERE, GROUP BY and HAVING, you cannot reference the column alias in these clauses
Table ALIAS operator syntax
SELECT
column_list
FROM
table_name AS alias_name;PostgreSQL
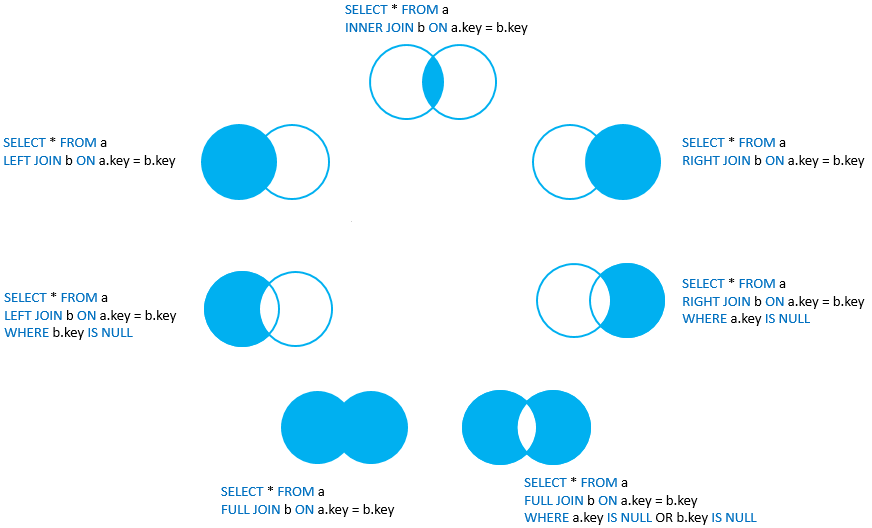
JOINS
- PostgreSQL JOIN is used to combine columns from one (self-join) or more tables based on the values of the common columns between the tables.
- The common columns are typically the primary key columns of the first table and foreign key columns of the second table
PostgreSQL supports inner join, left join, right join, full outer join, cross join, natural join and a special kind of join called self-join
PostgreSQL
INNER JOIN clause
INNER JOIN clause is to get data from two tables named A and B. The B table has the fka field that relates to the primary key of the A table

INNER JOIN clause syntax
SELECT
A.pka,
A.c1,
B.pkb,
B.c2
FROM
A
INNER JOIN B ON A .pka = B.fka;The expression returns true if the value is NULL or false if it is not
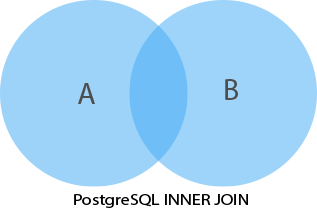
The INNER JOIN clause returns rows in A table that have the corresponding rows in the B table
PostgreSQL
INNER JOIN
clause examples
(2 tables)
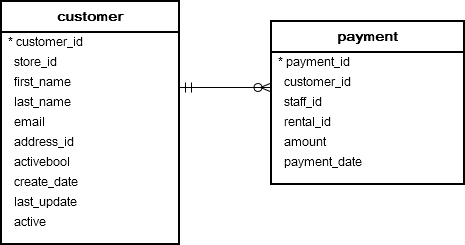
Table customer and payment
Each customer may have zero or many payments. Each payment belongs to one and only one customer. The customer_id field establishes the link between two tables
Join customer table to payment
SELECT
customer.customer_id,
first_name,
last_name,
email,
amount,
payment_date
FROM
customer
INNER JOIN payment ON payment.customer_id = customer.customer_id
#WHERE
#customer.customer_id = 2;
ORDER BY
customer.customer_id;
PostgreSQL
INNER JOIN
clause examples
(3 tables)
Table customer, staff and payment
- Each staff relates to zero or many payments. Each payment is processed by one and only one staff.
- Each customer has zero or many payments. Each payment belongs to one and only customer.
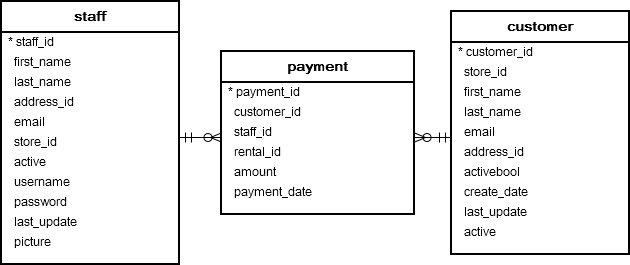
Join 3 tables
SELECT
customer.customer_id,
customer.first_name customer_first_name,
customer.last_name customer_last_name,
customer.email,
staff.first_name staff_first_name,
staff.last_name staff_last_name,
amount,
payment_date
FROM
customer
INNER JOIN payment ON payment.customer_id = customer.customer_id
INNER JOIN staff ON payment.staff_id = staff.staff_id;
PostgreSQL
LEFT JOIN clause
- LEFT JOIN clause is used to select rows from the A table which may or may not have corresponding rows in the B table
- In case, there is no matching row in the B table, the values of the columns in the B table are substituted by the NULL values

LEFT JOIN clause syntax
SELECT
A.pka,
A.c1,
B.pkb,
B.c2
FROM
A
LEFT JOIN B ON A .pka = B.fka;- The LEFT JOIN clause returns all rows in the left table ( A) that are combined with rows in the right table ( B) even though there is no corresponding rows in the right table ( B).
- The LEFT JOIN is also referred as LEFT OUTER JOIN

PostgreSQL
LEFT JOIN
clause examples
Table film and inventory
Each row in the film table may have zero or many rows in the inventory table. Each row in the inventory table has one and only one row in the film table
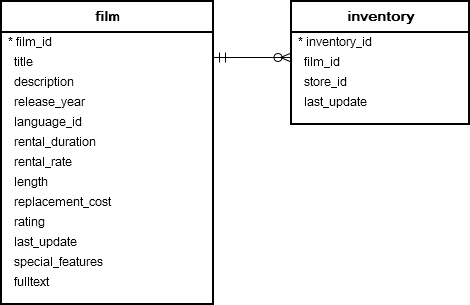
Use LEFT JOIN clause to join film table to the inventory
SELECT
film.film_id,
film.title,
inventory_id
FROM
film
LEFT JOIN inventory ON inventory.film_id = film.film_id;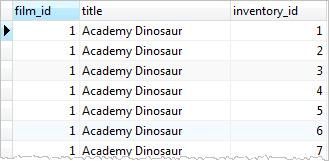
Add a WHERE clause to select only films that are not in the inventory
SELECT
film.film_id,
film.title,
inventory_id
FROM
film
LEFT JOIN inventory ON inventory.film_id = film.film_id
WHERE
inventory.film_id IS NULL;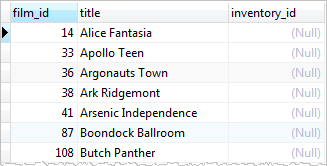
PostgreSQL
SELF JOIN clause
- A self-join is a query in which a table is joined to itself. Self-joins are useful for comparing values in a column of rows within the same table
- To form a self-join, you specify the same table twice with different aliases, set up the comparison, and eliminate cases where a value would be equal to itself
SELF JOIN clause syntax
SELECT column_list
FROM A a1
INNER JOIN A b1 ON join_predicate;table A is joined to itself using the INNER JOIN clause. you can also use the LEFT JOIN or RIGHT JOIN clause
PostgreSQL
SELF JOIN
clause examples
Table film

Finds all pair of films that have the same length
SELECT
f1.title,
f2.title,
f1. length
FROM
film f1
INNER JOIN film f2 ON f1.film_id <> f2.film_id
AND f1. length = f2. length;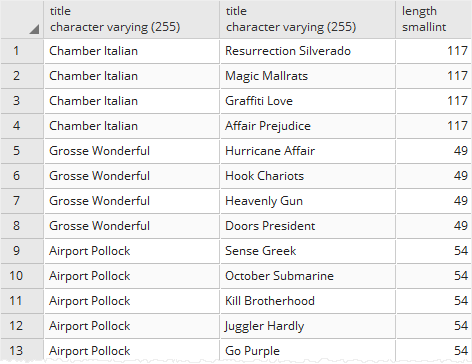
PostgreSQL
FULL OUTER JOIN clause
- The full outer join combines the results of both left join and right join.
- If the rows in the joined table do not match, the full outer join sets NULL values for every column of the table that lacks a matching row.
- For the matching rows , a single row is included in the result set that contains columns populated from both joined tables.
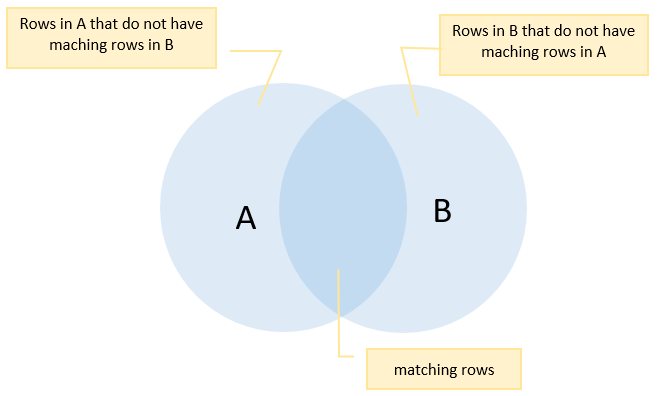
FULL OUTER JOIN clause syntax
SELECT * FROM A
FULL [OUTER] JOIN B on A.id = B.id;The OUTER keyword is optional
PostgreSQL
SELF JOIN
clause examples
1. Create 2 new tables
CREATE TABLE
IF NOT EXISTS departments (
department_id serial PRIMARY KEY,
department_name VARCHAR (255) NOT NULL
);
CREATE TABLE
IF NOT EXISTS employees (
employee_id serial PRIMARY KEY,
employee_name VARCHAR (255),
department_id INTEGER
);Each department has zero or many employees and each employee belongs to zero or one department
2. Add some sample data into the departments and employees tables
INSERT INTO departments (department_name)
VALUES
('Sales'),
('Marketing'),
('HR'),
('IT'),
('Production');
INSERT INTO employees (
employee_name,
department_id
)
VALUES
('Bette Nicholson', 1),
('Christian Gable', 1),
('Joe Swank', 2),
('Fred Costner', 3),
('Sandra Kilmer', 4),
('Julia Mcqueen', NULL);3. Query data from the departments and employees tables
# SELECT * FROM departments;
department_id | department_name
---------------+-----------------
1 | Sales
2 | Marketing
3 | HR
4 | IT
5 | Production
(5 rows)# SELECT * FROM employees;
employee_id | employee_name | department_id
-------------+-----------------+---------------
1 | Bette Nicholson | 1
2 | Christian Gable | 1
3 | Joe Swank | 2
4 | Fred Costner | 3
5 | Sandra Kilmer | 4
6 | Julia Mcqueen |
(6 rows)4. Use the FULL OUTER JOIN to query data from both employees and departments tables
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d ON d.department_id = e.department_id;5. result set includes every employee who belongs to a department and every department which have an employee. In addition, it includes every employee who does not belong to a department and every department that doesn’t have an employee
employee_name | department_name
-----------------+-----------------
Bette Nicholson | Sales
Christian Gable | Sales
Joe Swank | Marketing
Fred Costner | HR
Sandra Kilmer | IT
Julia Mcqueen | NULL
NULL | Production
(7 rows)6. Find the department that does have any employee
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d ON d.department_id = e.department_id
WHERE
employee_name IS NULL;employee_name | department_name
---------------+-----------------
NULL | Production
(1 row)6. Find the employee who does not belong to any department
SELECT
employee_name,
department_name
FROM
employees e
FULL OUTER JOIN departments d ON d.department_id = e.department_id
WHERE
department_name IS NULL;employee_name | department_name
---------------+-----------------
Julia Mcqueen | NULL
(1 row)PostgreSQL
CROSS JOIN clause
-
CROSS JOIN clause allows you to produce the Cartesian Product of rows in two or more tables
-
Different from the other JOIN operators such as LEFT JOIN or INNER JOIN, the CROSS JOIN does not have any matching condition in the join clause
CROSS JOIN clause syntax
SELECT *
FROM T1
CROSS JOIN T2;is also equivalent to:
SELECT *
FROM T1, T2;Text
SELECT *
FROM T1
INNER JOIN T2 ON TRUE;Use the INNER JOIN clause with the condition evaluates to true to perform the cross join
PostgreSQL
CROSS JOIN
clause examples
We will perform the CROSS JOIN of two tables T1 and T2. For every row from T1 and T2 i.e., a cartesian product, the result set will contain a row that consists of all columns in the T1 table followed by all columns in the T2 table. If T1 has N rows, T2 has M rows, the result set will have N x M rows
1. Create T1 and T2 tables and insert some sample data
CREATE TABLE T1 (label CHAR(1) PRIMARY KEY);
CREATE TABLE T2 (score INT PRIMARY KEY);
INSERT INTO T1 (label)
VALUES
('A'),
('B');
INSERT INTO T2 (score)
VALUES
(1),
(2),
(3);2. use the CROSS JOIN operator to join the T1 table with the T2 table
SELECT
*
FROM
T1
CROSS JOIN T2;label | score
-------+-------
A | 1
B | 1
A | 2
B | 2
A | 3
B | 3
(6 rows)3. Illustration Result of the CROSS JOIN operator when we join the T1 table with the T2
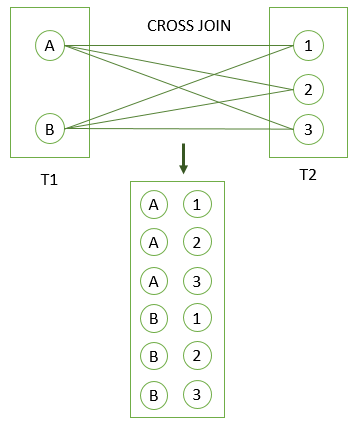
PostgreSQL
GROUP BY
clause
-
GROUP BY clause divides the rows returned from the SELECT statement into groups.
-
For each group, you can apply an aggregate function e.g., SUM() to calculate the sum of items or COUNT() to get the number of items in the groups
GROUP BY clause syntax
SELECT column_1, aggregate_function(column_2)
FROM tbl_name
GROUP BY column_1;- The GROUP BY clause must appear right after the FROM or WHERE clause.
- Followed by the GROUP BY clause is one column or a list of comma-separated columns.
- Beside the table column, you can also use an expression with the GROUP BY clause
PostgreSQL
GROUP BY clause examples

Table payment
Gets data from the payment table and groups the result by customer id without applying an aggregate function
SELECT
customer_id
FROM
payment
GROUP BY
customer_id;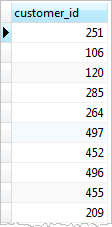
In this case, the GROUP BY acts like the DISTINCT clause that removes the duplicate rows from the result set
- Get how much a customer has been paid, by using the GROUP BY clause to divide the payments table into groups.
- For each group, you calculate the total amounts of money by using the SUM() function
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id;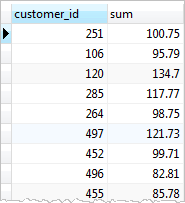
Use the ORDER BY clause with GROUP BY clause to sort the groups
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id
ORDER BY
SUM (amount) DESC;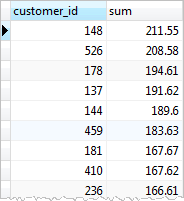
Count the number of transactions each staff has been processing and group the payments table based on staff id and use the COUNT() function to get the number of transactions
SELECT
staff_id,
COUNT (payment_id)
FROM
payment
GROUP BY
staff_id;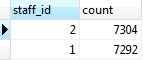
PostgreSQL
HAVING clause
-
HAVING clause often use in conjunction with the GROUP BY clause to filter group rows that do not satisfy a specified condition.
-
HAVING clause sets the condition for group rows created by the GROUP BY clause after the GROUP BY clause applies while the WHERE clause sets the condition for individual rows before GROUP BY clause applies.
-
This is the main difference between the HAVING and WHERE clauses
HAVING clause syntax
SELECT
column_1,
aggregate_function (column_2)
FROM
tbl_name
GROUP BY
column_1
HAVING
condition;PostgreSQL
HAVING clause with SUM function examples
Table payment
Gets the total amount of each customer by using the GROUP BY clause and selects the only customer who has been spending more than 200
SELECT
customer_id,
SUM (amount)
FROM
payment
GROUP BY
customer_id
HAVING
SUM (amount) > 200;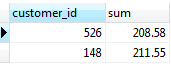
PostgreSQL
HAVING clause with COUNT examples
Table customer
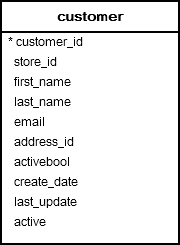
Get number of customers per store
SELECT
store_id,
COUNT (customer_id)
FROM
customer
GROUP BY
store_id
Use the HAVING clause to select store that has more than 300 customers
SELECT
store_id,
COUNT (customer_id)
FROM
customer
GROUP BY
store_id
HAVING
COUNT (customer_id) > 300;
PostgreSQL
UNION operator
The UNION operator combines result sets of two or more SELECT statements into a single result set
UNION operator syntax
SELECT
column_1,
column_2
FROM
tbl_name_1
UNION
SELECT
column_1,
column_2
FROM
tbl_name_2;The following are rules applied to the queries:
- Both queries must return the same number of columns.
- The corresponding columns in the queries must have compatible data types.
- The UNION operator removes all duplicate rows unless the UNION ALL is used
- UNION operator often use to combine data from similar tables that are not perfectly normalized. Those tables are often found in the reporting or data warehouse system.
PostgreSQL
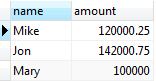
UNION operator examples
Let’s take a look at the following tables:
- sales2007q1: stores sales data in Q1 2007.
- sales2007q2: stores sales data in Q2 2007.
sales2007q1 data:
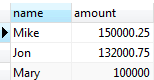
sales2007q2 data:
Use the UNION operator to combine data from both tables
SELECT *
FROM
sales2007q1
UNION
SELECT *
FROM
sales2007q2;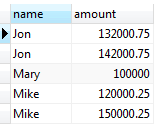
There are five rows in the combined result set because the UNION operator removes one duplicate row
Use ORDER BY to sort the combined result returned by the UNION operator
SELECT *
FROM
sales2007q1
UNION ALL
SELECT *
FROM
sales2007q2
ORDER BY
name ASC,
amount DESC;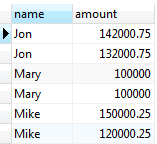
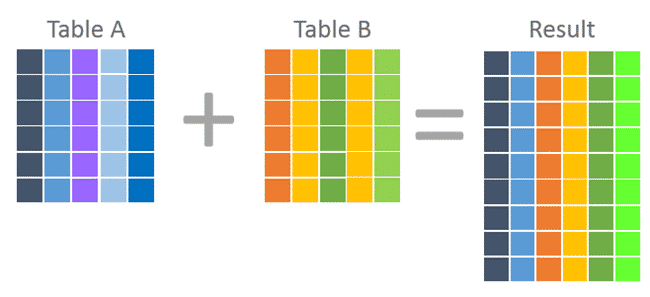
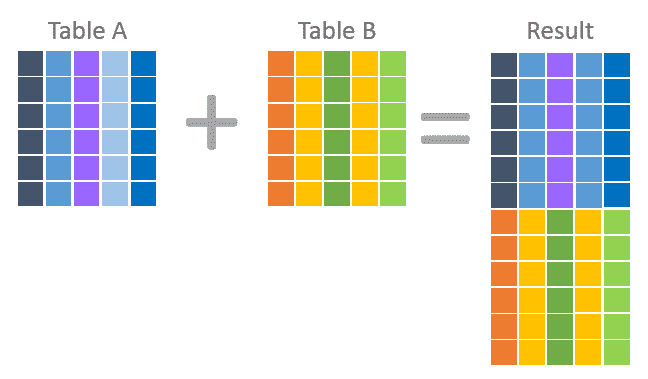
JOIN combine columns
UNION combine rows
PostgreSQL
GROUPING SETS
A grouping set is a set of columns by which you group. Typically, a single aggregate query defines a single grouping set
PostgreSQL
GROUPING SETS examples
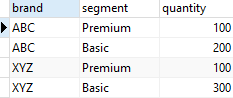
1. Create a new sales table
CREATE TABLE sales (
brand VARCHAR NOT NULL,
segment VARCHAR NOT NULL,
quantity INT NOT NULL,
PRIMARY KEY (brand, segment)
);
INSERT INTO sales (brand, segment, quantity)
VALUES
('ABC', 'Premium', 100),
('ABC', 'Basic', 200),
('XYZ', 'Premium', 100),
('XYZ', 'Basic', 300);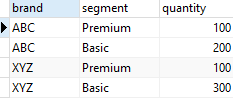
The sales table stores the number of products sold by brand and segment
2. Get number of products sold by brand and segment
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
brand,
segment;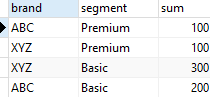
3. Finds the number of product sold by brand with a grouping set of the brand
SELECT
brand,
SUM (quantity)
FROM
sales
GROUP BY
brand;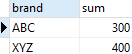
4. Finds the number of products sold by segment with a grouping set of the segment
SELECT
segment,
SUM (quantity)
FROM
sales
GROUP BY
segment;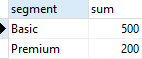
5. Finds the number of products sold for all brands and segments with an empty grouping set
SELECT
SUM (quantity)
FROM
sales;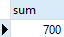
Suppose that instead of four result sets, you wanted to see a unified result set with the aggregated data for all grouping sets. To achieve this, you use the UNION ALL to unify all the queries above
6. UNION ALL requires all result sets to have the same number of columns with compatible data types, you need to adjust the queries by adding NULL to the selection list of each
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
brand,
segment
UNION ALL
SELECT
brand,
NULL,
SUM (quantity)
FROM
sales
GROUP BY
brand
UNION ALL
SELECT
NULL,
segment,
SUM (quantity)
FROM
sales
GROUP BY
segment
UNION ALL
SELECT
NULL,
NULL,
SUM (quantity)
FROM
sales;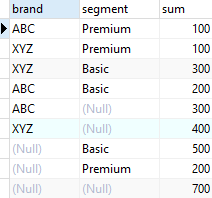
- Previous query generated a single result set with the aggregates for all grouping sets
-
It has two main problems:
- It is quite lengthy
- It has a performance issue because PostgreSQL has to scan the sales table separately for each query
- To make it more efficient, PostgreSQL provides the GROUPING SETS which is the subclause of the GROUP BY clause
GROUPING SETS operator syntax
SELECT
c1,
c2,
aggregate_function(c3)
FROM
table_name
GROUP BY
GROUPING SETS (
(c1, c2),
(c1),
(c2),
()
);- GROUPING SETS allows you to define multiple grouping sets in the same query
- In this syntax, you have four grouping sets (c1,c2), (c1), (c2), and ()
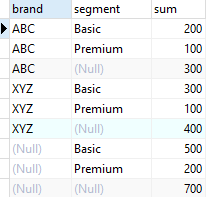
7. Use GROUPING SETS instead of UNION ALL to the example above
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand, segment),
(brand),
(segment),
()
);
Grouping function
GROUPING function accepts a name of a column and returns bit 0 if the column is the member of the current grouping set and 1 otherwise
Example:
SELECT
GROUPING(brand) grouping_brand,
GROUPING(segment) grouping_segement,
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
GROUPING SETS (
(brand, segment),
(brand),
(segment),
()
)
ORDER BY
brand,
segment;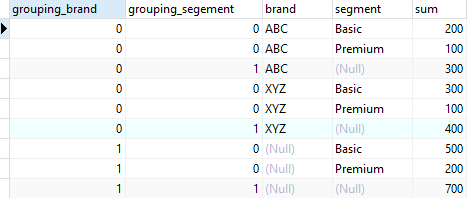
PostgreSQL
CUBE
CUBE is a subclause of the GROUP BY clause. The CUBE allows you to generate multiple grouping sets.
CUBE subclause syntax
SELECT
c1,
c2,
c3,
aggregate (c4)
FROM
table_name
GROUP BY
CUBE (c1, c2, c3);Specify the columns (dimensions or dimension columns) which you want to analyze and aggregation function expressions
- The query generates all possible grouping sets based on the dimension columns specified in CUBE.
- The CUBE subclause is a short way to define multiple grouping sets so the following are equivalent:
CUBE(c1,c2,c3)
GROUPING SETS (
(c1,c2,c3),
(c1,c2),
(c1,c3),
(c2,c3),
(c1),
(c2),
(c3),
()
) In general, if the number of columns specified in the CUBE is n, then you will have 2^n combinations
PostgreSQL allows you to perform a partial cube to reduce the number of aggregates calculated. The following shows the syntax:
SELECT
c1,
c2,
c3,
aggregate (c4)
FROM
table_name
GROUP BY
c1,
CUBE (c1, c2);PostgreSQL
CUBE examples
1. Use the sales table created in the GROUPING SETS (previously)
2. Use CUBE subclause to generate multiple grouping sets
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
CUBE (brand, segment)
ORDER BY
brand,
segment;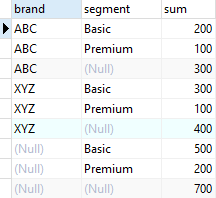
Query to performs a partial cube
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
brand,
CUBE (segment)
ORDER BY
brand,
segment;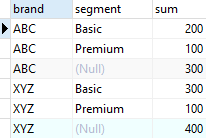
PostgreSQL
ROLLUP
-
ROLLUP is a subclause of the GROUP BY clause that offers a shorthand for defining multiple grouping sets. A grouping set is a set of columns to which you want to group
-
Different from the CUBE subclause, ROLLUP does not generate all possible grouping sets based on the specified columns. It just makes a subset of those.
-
The ROLLUP assumes a hierarchy among the input columns and generates all grouping sets that make sense considering the hierarchy. This is the reason why ROLLUP is often used to generate the subtotals and the grand total for reports
For example, the CUBE (c1,c2,c3) makes all eight possible grouping sets:
(c1, c2, c3)
(c1, c2)
(c2, c3)
(c1,c3)
(c1)
(c2)
(c3)
()However, the ROLLUP(c1,c2,c3) generates only four grouping sets, assuming the hierarchy c1 > c2 > c3 as follows:
(c1, c2, c3)
(c1, c2)
(c1)
()
A common use of ROLLUP is to calculate the aggregations of data by year, month, and date, considering the hierarchy
year > month > date
ROLLUP syntax
SELECT
c1,
c2,
c3,
aggregate(c4)
FROM
table_name
GROUP BY
ROLLUP (c1, c2, c3);Specify the columns (dimensions or dimension columns) which you want to analyze and aggregation function expressions
It is also possible to do a partial roll up to reduce the number of subtotals generated
SELECT
c1,
c2,
c3,
aggregate(c4)
FROM
table_name
GROUP BY
c1,
ROLLUP (c2, c3);PostgreSQL
ROLLUP examples
1. Use the ROLLUP subclause to find the number of products sold by brand (subtotal) and by all brands and segments (total)
SELECT
brand,
segment,
SUM (quantity)
FROM
sales
GROUP BY
ROLLUP (brand, segment)
ORDER BY
brand,
segment;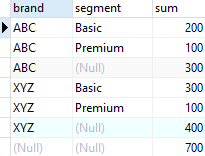
- As you can see from the output, the third row shows the number of products sold for the ABC brand, the sixth row displays the number of products show for the XYZ brand.
- The last row shows the grand total which displays the total products sold for all brands and segments. In this example, the hierarchy is
brand > segment.
Perform a partial rollup
SELECT
segment,
brand,
SUM (quantity)
FROM
sales
GROUP BY
segment,
ROLLUP (brand)
ORDER BY
segment,
brand;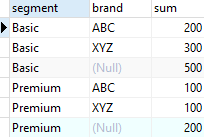
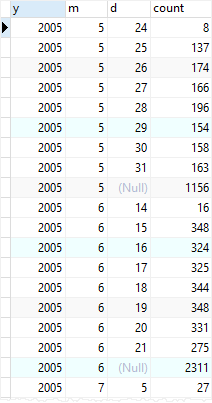
Other Example
Table rental

Finds the number of rental per day, month, and year by using the ROLLUP
SELECT
EXTRACT (YEAR FROM rental_date) y,
EXTRACT (MONTH FROM rental_date) M,
EXTRACT (DAY FROM rental_date) d,
COUNT (rental_id)
FROM
rental
GROUP BY
ROLLUP (
EXTRACT (YEAR FROM rental_date),
EXTRACT (MONTH FROM rental_date),
EXTRACT (DAY FROM rental_date)
);
PostgreSQL
SUBQUERY
SUBQUERY allows us to construct complex query
Suppose we want to find the films whose rental rate is higher than the average rental rate. We can do it in two steps:
- Find the average rental rate by using the SELECT statement and average function ( AVG).
- Use the result of the first query in the second SELECT statement to find the films that we want.
SIMPLE EXAMPLE
1. Gets the average rental rate
SELECT
AVG (rental_rate)
FROM
film;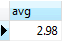
The average rental rate is 2.98
2. Get films whose rental rate is higher than the average rental rate
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > 2.98;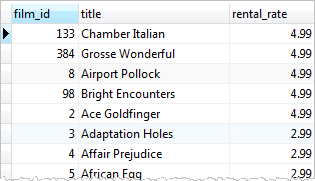
- The code is not so elegant, which requires two steps. We want a way to pass the result of the first query to the second query in one query. The solution is to use a subquery.
- A subquery is a query nested inside another query such as SELECT, INSERT, DELETE and UPDATE. In this training, we are focusing on the SELECT statement only.
SUBQUERY EXAMPLE
To construct a subquery, we put the second query in brackets and use it in the WHERE clause as an expression
SELECT
film_id,
title,
rental_rate
FROM
film
WHERE
rental_rate > (
SELECT
AVG (rental_rate)
FROM
film
);The query inside the brackets is called a subquery or an inner query. The query that contains the subquery is known as an outer query
PostgreSQL executes the query that contains a subquery in the following sequence:
- First, executes the subquery.
- Second, gets the result and passes it to the outer query.
- Third, executes the outer query.
PostgreSQL SUBQUERY with IN operator
- A subquery can return zero or more rows. To use this subquery, use the IN operator in the WHERE clause
- Get films that have the returned date between 2005-05-29 and 2005-05-30
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory ON inventory.inventory_id = rental.inventory_id
WHERE
return_date BETWEEN '2005-05-29'
AND '2005-05-30';
It returns multiple rows so we can use this query as a subquery in the WHERE clause of a query
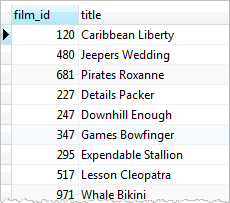
SELECT
film_id,
title
FROM
film
WHERE
film_id IN (
SELECT
inventory.film_id
FROM
rental
INNER JOIN inventory ON inventory.inventory_id = rental.inventory_id
WHERE
return_date BETWEEN '2005-05-29'
AND '2005-05-30'
);
PostgreSQL SUBQUERY with EXIST operator
-
A subquery can be an input of the EXISTS operator. If the subquery returns any row, the EXISTS operator returns true. If the subquery returns no row, the result of EXISTS operator is false
-
The EXISTS operator only cares about the number of rows returned from the subquery, not the content of the rows, therefore, the common coding convention of EXISTS operator is as follows:
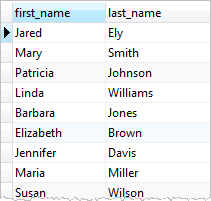
EXISTS (SELECT 1 FROM tbl WHERE condition);SELECT
first_name,
last_name
FROM
customer
WHERE
EXISTS (
SELECT
1
FROM
payment
WHERE
payment.customer_id = customer.customer_id
);
The query works like an inner join on the customer_id column. However, it returns at most one row for each row in the customer table even though there are some corresponding rows in the payment table
PostgreSQL
ANY Operator
ANY operator compares a value to a set of values returned by a subquery
ANY operator syntax
expresion operator ANY(subquery)- The subquery must return exactly one column.
- The ANY operator must be preceded by one of the following comparison operator =, <=, >, <, > and <>
- The ANY operator returns true if any value of the subquery meets the condition, otherwise, it returns false.
PostgreSQL
ANY Operator examples
Table film and film_category
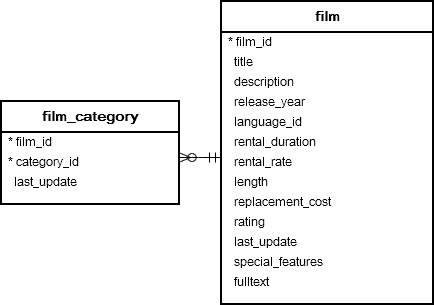
1. Get the maximum length of film grouped by film category
SELECT
MAX( length )
FROM
film
INNER JOIN film_category
USING(film_id)
GROUP BY
category_id;2. Use the previous query as a subquery in the following statement that finds the films whose lengths are greater than or equal to the maximum length of any film category
SELECT title
FROM film
WHERE length >= ANY(
SELECT MAX( length )
FROM film
INNER JOIN film_category USING(film_id)
GROUP BY category_id );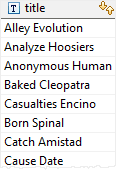
ANY vs IN
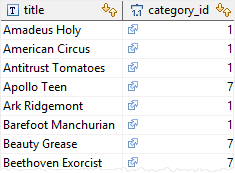
The = ANY is equivalent to IN operator
Gets the film whose category is either Action or Drama
SELECT
title,
category_id
FROM
film
INNER JOIN film_category
USING(film_id)
WHERE
category_id = ANY(
SELECT
category_id
FROM
category
WHERE
NAME = 'Action'
OR NAME = 'Drama'
);
The following statement uses the IN operator which produces the same result:
SELECT
title,
category_id
FROM
film
INNER JOIN film_category
USING(film_id)
WHERE
category_id IN(
SELECT
category_id
FROM
category
WHERE
NAME = 'Action'
OR NAME = 'Drama'
);-
Note that the <> ANY operator is different from NOT IN.
-
The following expression:
x <> ANY (a,b,c) is equivalent to
x <> a OR <> b OR x <> cPostgreSQL
ALL Operator
PostgreSQL ALL operator allows you to query data by comparing a value with a list of values returned by a subquery
ALL operator syntax
comparison_operator ALL (subquery)- The ALL operator must be preceded by a comparison operator such as equal (=), not equal (!=), greater than (>), greater than or equal to (>=), less than (<), and less than or equal to (<=).
- The ALL operator must be followed by a subquery which also must be surrounded by the parentheses
With the assumption that the subquery returns some rows, the ALL operator works as follows:
- column_name > ALL (subquery) the expression evaluates to true if a value is greater than the biggest value returned by the subquery.
- column_name >= ALL (subquery) the expression evaluates to true if a value is greater than or equal to the biggest value returned by the subquery.
- column_name < ALL (subquery) the expression evaluates to true if a value is less than the smallest value returned by the subquery.
- column_name <= ALL (subquery) the expression evaluates to true if a value is less than or equal to the smallest value returned by the subquery.
- column_name = ALL (subquery) the expression evaluates to true if a value is equal to any value returned by the subquery.
- column_name != ALL (subquery) the expression evaluates to true if a value is not equal to any value returned by the subquery.
PostgreSQL
ALL operator examples
Table film

1. Get the average lengths of all films grouped by film rating
SELECT
ROUND(AVG(length), 2) avg_length
FROM
film
GROUP BY
rating
ORDER BY
avg_length DESC;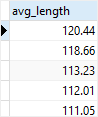
2. Find all films whose lengths are greater than the list of the average lengths above by using the ALL and greater than operator (>)
SELECT
film_id,
title,
length
FROM
film
WHERE
length > ALL (
SELECT
ROUND(AVG (length),2)
FROM
film
GROUP BY
rating
)
ORDER BY
length;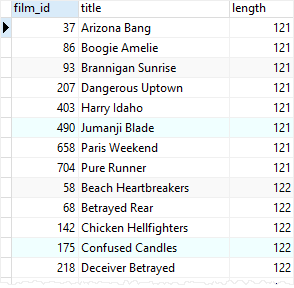
PostgreSQL
EXIST Operator
The EXISTS operator is used to test for existence of rows in a subquery
EXIST operator syntax
EXISTS (subquery)-
The EXISTS accepts an argument which is a subquery.
-
If the subquery returns at least one row, the result of EXISTS is true. In case the subquery returns no row, the result is of EXISTS is false.
-
EXISTS is often used with the correlated subquery.
-
The result of EXISTS depends on whether any row returned by the subquery, and not on the content of the rows. Therefore, the columns that appear on the SELECT clause of the subquery are not important.
The common coding convention is to write EXISTS in the following form:
SELECT
column_1
FROM
table_1
WHERE
EXISTS( SELECT
1
FROM
table_2
WHERE
column_2 = table_1.column_1);Note that if the subquery returns NULL, the result of EXISTS is true.
PostgreSQL
EXIST operator examples
Table customer and payment
1. Find customers who have at least one payment whose amount is greater than 11
SELECT first_name,
last_name
FROM customer c
WHERE EXISTS
(SELECT 1
FROM payment p
WHERE p.customer_id = c.customer_id
AND amount > 11 )
ORDER BY first_name,
last_name;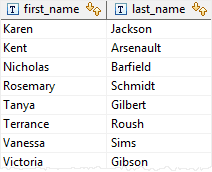
In this example, for each customer in the customer table, the subquery checks the payment table to find if that customer made at least one payment (p.customer_id = c.customer_id) and the amount is greater than 11 ( amount > 11)
2. NOT EXISTS example
SELECT first_name,
last_name
FROM customer c
WHERE NOT EXISTS
(SELECT 1
FROM payment p
WHERE p.customer_id = c.customer_id
AND amount > 11 )
ORDER BY first_name,
last_name;NOT EXISTS is opposite to EXISTS, meaning that if the subquery returns no row, NOT EXISTS returns true. If the subquery returns any rows, NOT EXISTS returns false
Find customers who have not made any payment that greater than 11
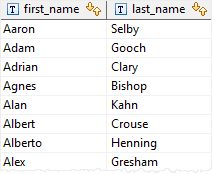
3. EXIST and NULL
SELECT
first_name,
last_name
FROM
customer
WHERE
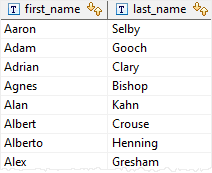
EXISTS( SELECT NULL )
ORDER BY
first_name,
last_name;The subquery returned NULL, therefore, the query returned all rows from the customer table
If the subquery returns NULL, EXISTS returns true
PostgreSQL
INSERT statement
INSERT statement that allows you to insert one or more rows into a table at a time
INSERT statement syntax
INSERT INTO table(column1, column2, …)
VALUES
(value1, value2, …);To add multiple rows into a table at a time, use the following syntax:
INSERT INTO table (column1, column2, …)
VALUES
(value1, value2, …),
(value1, value2, …) ,...;INSERT statement syntax (Cont.)
To insert data that comes from another table, use the INSERT INTO SELECT statement as follows:
INSERT INTO table(column1,column2,...)
SELECT column1,column2,...
FROM another_table
WHERE condition;PostgreSQL
INSERT statement examples
Create new table
CREATE TABLE link (
ID serial PRIMARY KEY,
url VARCHAR (255) NOT NULL,
name VARCHAR (255) NOT NULL,
description VARCHAR (255),
rel VARCHAR (50)
);Insert 1 row
INSERT INTO link (url, name)
VALUES
('https://slides.com/fathi-ch3k','PostgreSQL Training');-
To insert character data, you must enclose it in single quotes (‘) for example 'PostgreSQL Training'. For the numeric data type, you don’t need to do so, just use plain numbers such as 1, 2, 3.
-
If you omit any column that accepts the NULL value in the INSERT statement, the column will take its default value. In case the default value is not set for the column, the column will take the NULL value.
-
PostgreSQL provides a value for the serial column automatically so you do not and should not insert a value into the serial column.
If you want to insert a string that contains a single quote character such as O'Reilly Media, you have to use a single quote (‘) escape character as shown in the following query:
INSERT INTO link (url, name)
VALUES
('http://www.oreilly.com','O''Reilly Media');Insert multiple rows
INSERT INTO link (url, name)
VALUES
('http://www.google.com','Google'),
('http://www.yahoo.com','Yahoo'),
('http://www.bing.com','Bing');Insert date
ALTER TABLE link ADD COLUMN last_update DATE;
ALTER TABLE link ALTER COLUMN last_update
SET DEFAULT CURRENT_DATE;add a new column named last_update into the link table and set its default value to CURRENT_DATE
inserts a new row with specified date into the link table. The date format is YYYY-MM-DD
INSERT INTO link (url, name, last_update)
VALUES
('http://www.facebook.com','Facebook','2013-06-01');Insert date (cont..)
INSERT INTO link (url, name, last_update)
VALUES
('https://www.fotia.com.my','Fotia',DEFAULT);You can also use the DEFAULT keyword to set the default value for the date column or any column that has a default value.
Insert data from another table
CREATE TABLE link_tmp (LIKE link);1. Create new table
2. Insert rows from the link table whose values of the date column are not NULL
INSERT INTO link_tmp
SELECT
*
FROM
link
WHERE
last_update IS NOT NULL;Get the last insert id
INSERT INTO link (url, NAME, last_update)
VALUES('https://www.mampu.gov.my','MAMPU',DEFAULT)
RETURNING id;Get the last insert id from the table after inserting a new row, use the RETURNING clause in the INSERT statement
PostgreSQL
UPDATE statement
UPDATE statement to update existing data in a table
UPDATE statement syntax
UPDATE table
SET column1 = value1,
column2 = value2 ,...
WHERE
condition;Determine which rows you want to update in the condition of the WHERE clause. If you omit the WHERE clause, all the rows in the table are updated
PostgreSQL
UPDATE statement examples
-
Use the link table created in the INSERT chapter
-
Update table partially example
UPDATE link
SET last_update = DEFAULT
WHERE
last_update IS NULL;PostgreSQL update table partially example
PostgreSQL update all rows in a table
UPDATE link
SET rel = 'nofollow';UPDATE link
SET description = name;PostgreSQL update join example
UPDATE link_tmp
SET rel = link.rel,
description = link.description,
last_update = link.last_update
FROM
link
WHERE
link_tmp.id = link.id;updates values that come from the link table for the columns in the link_tmp table
This kind of UPDATE statement sometimes referred to as UPDATE JOIN or UPDATE INNER JOIN because two or more tables are involved in the UPDATE statement. The join condition is specified in the WHERE clause
PostgreSQL update update with returning clause
UPDATE link
SET description = 'Learn PostgreSQL fast and easy',
rel = 'follow'
WHERE
ID = 1
RETURNING id,
description,
rel;Updates the row with id 1 in the link table and returns the updated entries
PostgreSQL
UPDATE JOIN statement
UPDATE JOIN statement allows you to update data of a table based on values in another table
UPDATE JOIN statement syntax
UPDATE A
SET A.c1 = expresion
FROM B
WHERE A.c2 = B.c2;-
To join to another table in the UPDATE statement, you specify the joined table in the FROM clause and provide the join condition in the WHERE clause. The FROM clause must appear immediately after the SET clause.
-
This form of the UPDATE statement updates column value c1 in the table A if each row in the table A and B have a matching value in the column c2
PostgreSQL
UPDATE JOIN statement examples
Create 2 new table
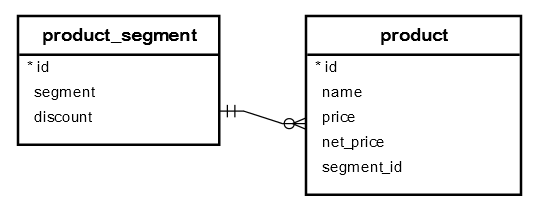
- Create a new table called product_segment that stores the product segments such as grand luxury, luxury and mass.
- The product_segment table has the discount column that stores the discount percentage based on a specific segment.
CREATE TABLE product_segment (
ID SERIAL PRIMARY KEY,
segment VARCHAR NOT NULL,
discount NUMERIC (4, 2)
);
INSERT INTO product_segment (segment, discount)
VALUES
('Grand Luxury', 0.05),
('Luxury', 0.06),
('Mass', 0.1);- Create another table named product that stores the product data
- The product table has the foreign key column segment_id that links to the id of the segment table
CREATE TABLE product(
id serial primary key,
name varchar not null,
price numeric(10,2),
net_price numeric(10,2),
segment_id int not null,
foreign key(segment_id) references product_segment(id)
);
INSERT INTO product (name, price, segment_id)
VALUES ('diam', 804.89, 1),
('vestibulum aliquet', 228.55, 3),
('lacinia erat', 366.45, 2),
('scelerisque quam turpis', 145.33, 3),
('justo lacinia', 551.77, 2),
('ultrices mattis odio', 261.58, 3),
('hendrerit', 519.62, 2),
('in hac habitasse', 843.31, 1),
('orci eget orci', 254.18, 3),
('pellentesque', 427.78, 2),
('sit amet nunc', 936.29, 1),
('sed vestibulum', 910.34, 1),
('turpis eget', 208.33, 3),
('cursus vestibulum', 985.45, 1),
('orci nullam', 841.26, 1),
('est quam pharetra', 896.38, 1),
('posuere', 575.74, 2),
('ligula', 530.64, 2),
('convallis', 892.43, 1),
('nulla elit ac', 161.71, 3);Calculate the net price of every product based on the discount of the product segment
UPDATE product
SET net_price = price - price * discount
FROM
product_segment
WHERE
product.segment_id = product_segment.id;- This statement joins the product table to the product_segment table.
- If there is a match in both tables, it gets the discount from the product_segment table, calculates the net price based on the following formula, and updates the net_price column
Check the data of the product table
SELECT
*
FROM
product;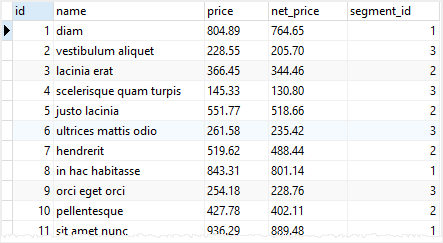
PostgreSQL CONDITIONAL TABLE EXPRESSION (CTE)
-
A common table expression is a temporary result set which you can reference within another SQL statement including SELECT, INSERT, UPDATE or DELETE
-
Common Table Expressions are temporary in the sense that they only exist during the execution of the query
Syntax of creating a CTE
WITH cte_name (column_list) AS (
CTE_query_definition
)
statement;- First, specify the name of the CTE following by an optional column list.
- Second, inside the body of the WITH clause, specify a query that returns a result set. If you do not explicitly specify the column list after the CTE name, the select list of the CTE_query_definition will become the column list of the CTE.
- Third, use the CTE like a table or view in the statement which can be a SELECT, INSERT, UPDATE, or DELETE.
CTE Example
WITH cte_film AS (
SELECT
film_id,
title,
(CASE
WHEN length < 30 THEN 'Short'
WHEN length >= 30 AND length < 90 THEN 'Medium'
WHEN length > 90 THEN 'Long'
END) length
FROM
film
)
SELECT
film_id,
title,
length
FROM
cte_film
WHERE
length = 'Long'
ORDER BY
title; 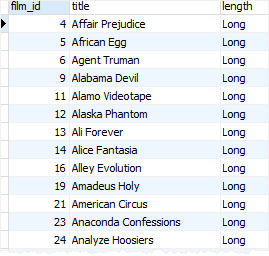
PostgreSQL CASE Conditional
CASE expression is the same as IF/ELSE statement in other programming languages
General form of the CASE statement
CASE
WHEN condition_1 THEN result_1
WHEN condition_2 THEN result_2
[WHEN ...]
[ELSE result_n]
END- Each condition is an expression that returns a boolean value, either true or false
- All result expressions must have data types that can be convertible to a single data type e.g., string, numeric, and temporal
PostgreSQL CASE Example
Film table

-
We want to assign a price segment to a film with the following logic:
-
Mass if the rental rate is 0.99
-
Economic if the rental rate is 1.99
-
Luxury if the rental rate is 4.99
-
-
Count the number of films that belong to the Mass, Economic, and Luxury price segments
SELECT
SUM (
CASE
WHEN rental_rate = 0.99 THEN
1
ELSE
0
END
) AS "Mass",
SUM (
CASE
WHEN rental_rate = 2.99 THEN
1
ELSE
0
END
) AS "Economic",
SUM (
CASE
WHEN rental_rate = 4.99 THEN
1
ELSE
0
END
) AS "Luxury"
FROM
film;
PostgreSQL
NULLIF
NULLIF function is one of the most common conditional expressions provided by PostgreSQL
PostgreSQL NULLIF function syntax
NULLIF(argument_1,argument_2);NULLIF function returns a null value if argument_1 equals to argument_2, otherwise it returns argument_1
Example:
SELECT
NULLIF (1, 1); -- return NULL
SELECT
NULLIF (1, 0); -- return 1
SELECT
NULLIF ('A', 'B'); -- return APostgreSQL NULLIF function example
1. Create a new table named members
CREATE TABLE members (
ID serial PRIMARY KEY,
first_name VARCHAR (50) NOT NULL,
last_name VARCHAR (50) NOT NULL,
gender SMALLINT NOT NULL -- 1: male, 2 female
);2. Insert some rows
INSERT INTO members (
first_name,
last_name,
gender
)
VALUES
('John', 'Doe', 1),
('David', 'Dave', 1),
('Bush', 'Lily', 2);3. Calculate the ratio between male and female members
SELECT
(SUM (
CASE
WHEN gender = 1 THEN
1
ELSE
0
END
) / SUM (
CASE
WHEN gender = 2 THEN
1
ELSE
0
END
) ) * 100 AS "Male/Female ratio"
FROM
members;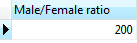
4. Remove the female member
DELETE
FROM
members
WHERE
gender = 2;Execute the query to calculate the male/female ratio again, we got the following error message:
[Err] ERROR: division by zeroSELECT
(
SUM (
CASE
WHEN gender = 1 THEN
1
ELSE
0
END
) / NULLIF (
SUM (
CASE
WHEN gender = 2 THEN
1
ELSE
0
END
),
0
)
) * 100 AS "Male/Female ratio"
FROM
members;This is because, the number of female is zero. To prevent this division by zero error, we use the NULLIF function
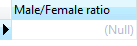
PostgreSQL CAST Operator
Convert a value of one data type into another
PostgreSQL CAST operator syntax
CAST ( expression AS target_type );- First, specify an expression that can be a constant, a table column, an expression that evaluates to a value.
- Then, specify the target data type to which you want to convert the result of the expression.
Alternative of CAST operator syntax
expression::typeSELECT
'100'::INTEGER,
'01-OCT-2015'::DATE;Example:
PostgreSQL CAST
examples
1. Cast a string to an integer example
SELECT
CAST ('100' AS INTEGER);
If the expression cannot be converted to the target type, PostgreSQL will raise an error
SELECT
CAST ('10C' AS INTEGER);[Err] ERROR: invalid input syntax for integer: "10C"
LINE 2: CAST ('10C' AS INTEGER);2. Cast a string to a date example
SELECT
CAST ('2015-01-01' AS DATE),
CAST ('01-OCT-2015' AS DATE);If the expression cannot be converted to the target type, PostgreSQL will raise an error
SELECT
CAST ('10C' AS INTEGER);[Err] ERROR: invalid input syntax for integer: "10C"
LINE 2: CAST ('10C' AS INTEGER);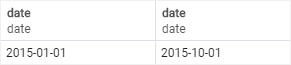
3. Cast a string to a double example
SELECT
CAST ('10.2' AS DOUBLE);You need to use DOUBLE PRECISION instead of DOUBLE
SELECT
CAST ('10.2' AS DOUBLE PRECISION);[Err] ERROR: type "double" does not exist
LINE 2: CAST ('10.2' AS DOUBLE)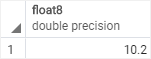
4. Cast a string to a boolean example
SELECT
CAST('true' AS BOOLEAN),
CAST('false' as BOOLEAN),
CAST('T' as BOOLEAN),
CAST('F' as BOOLEAN);
5. Convert a string to a timestamp example
SELECT '2019-06-15 14:30:20'::timestamp;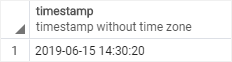
6. Using CAST with table data example
CREATE TABLE ratings (
ID serial PRIMARY KEY,
rating VARCHAR (1) NOT NULL
);Create a ratings table
Insert some sample data into the ratings table
INSERT INTO ratings (rating)
VALUES
('A'),
('B'),
('C');6. Using CAST with table data example (cont..)
INSERT INTO ratings (rating)
VALUES
(1),
(2),
(3);Because the requirements change, we use the same ratings table to store ratings as number e.g., 1, 2, 3 instead of A, B, and C
6. Using CAST with table data example (cont..)
SELECT
*
FROM
ratings;So the ratings table stores mixed values including numeric and string

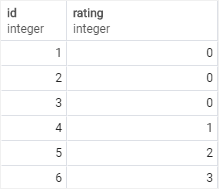
6. Using CAST with table data example (cont..)
SELECT
id,
CASE
WHEN rating~E'^\\d+$' THEN
CAST (rating AS INTEGER)
ELSE
0
END as rating
FROM
ratings;Convert all values in the rating column into integers, all other A, B, C ratings will be displayed as zero
There are no secrets to success. It is the result of preparation, hard work, and learning from failure. - Colin Powell