foundations of data science for everyone XI
dr.federica bianco | fbb.space | fedhere | fedhere

Artificial Neural Networks
this slide deck:
Recap: Data Science
0
FDSFE
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
remote sensing
survey science
instrumental design and development
data retrieval
...
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
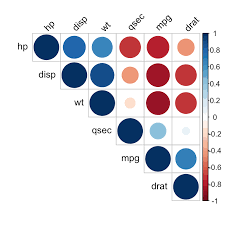

data types
identify correlation
missing variable
...
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
Scaling and
whitening
tokenizing
...
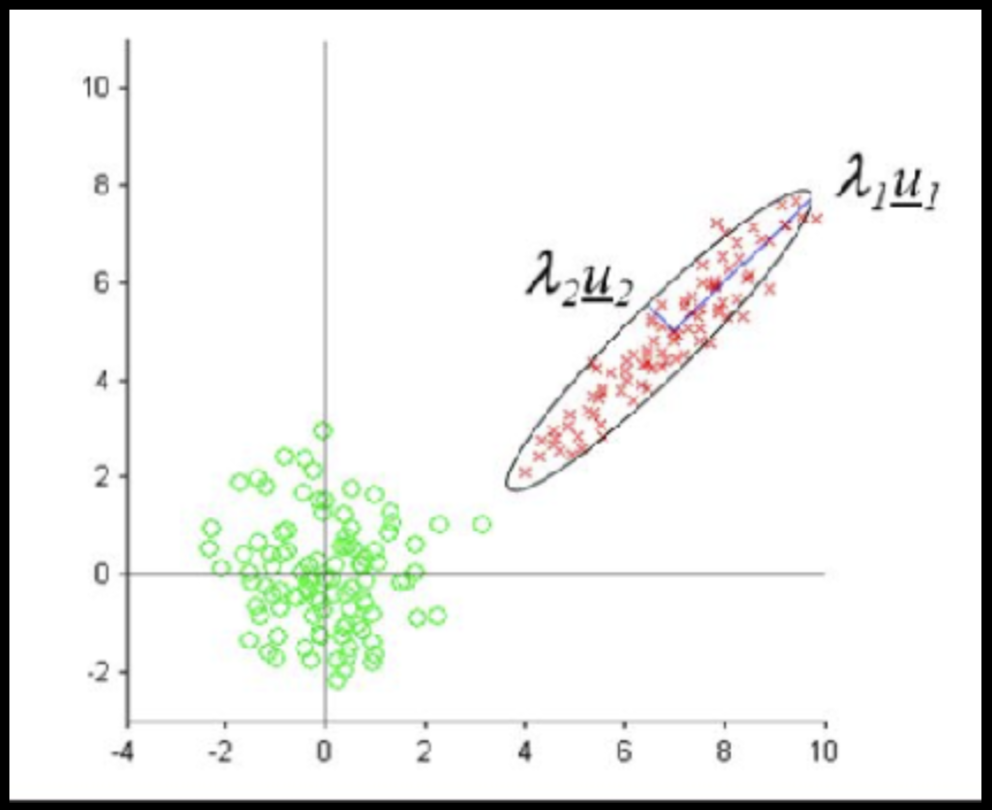
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
what is the goal:
statistical analysis
anomaly detection
prediction
structure identification
....
what is the task:
regression
classification
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.




SciPy
Data Science
The discipline that deals with extraction of information from data in a specific domain context, from data collection through inference
(Problem Identification and Planning)
- Data Collection
- Data Exploration
- Data Preparation
- Model Identification
- Model Building
- Model Evaluation
- Model Deployment.
Data driven models for exploration of structure and prediction that learn parameters from data.
Machine Learning
y
x
x
y
Reinforcement Learning
Active Learning
unupervised learning supervised learning
Data driven models for exploration of structure, prediction that learn parameters from data.
unupervised ------ supervised
set up: All features known for all observations
Goal: explore structure in the data
- data compression
- understanding structure
- anomaly detection
Algorithms: kMeans clustering, DBSCAN, Agglomerative clustering
x
y
Machine Learning
Data driven models for exploration of structure, prediction that learn parameters from data.
unupervised ------ supervised
set up: All features known for a sunbset of the data; one feature cannot be observed for the rest of the data
Goal: predicting missing feature
- classification
- regression
Algorithms: regression, (SVM), Classification and Regression Tree methods, k-nearest neighbors, neural networks, (...)
x
y
Machine Learning
unupervised ------ supervised
unupervised ------ supervised
Machine Learning
set up: All features known for a sunbset of the data; one feature cannot be observed for the rest of the data
Goal: predicting missing feature
- classification
- regression
Algorithms: regression, (SVM), Classification and Regression Tree methods, k-nearest neighbors, neural networks, (...)
set up: All features known for all observations
Goal: explore structure in the data
- data compression
- understanding structure
- anomaly detection
Algorithms: kMeans clustering, DBSCAN, Agglomerative clustering
Learning relies on the definition of a loss function
| learning type | loss / target |
|---|---|
| unsupervised | intra-cluster variance / inter cluster distance |
| supervised | distance between prediction and truth |
Machine Learning
model parameters are learned by calculating a loss function for diferent parameter sets and trying to minimize loss (or a target function and trying to maximize)
e.g. supervised
L1 = |target - prediction|
Learning relies on the definition of a loss function
Machine Learning
supervised and unsupervised
e.g. unsupervised
Inertia =
Interaction with the environment builds a reward function
Machine Learning
reinforcement
The goal of the agent is to maximize a cumulative reward signal over time
The objective is not to predict a specific output but to learn a policy or strategy that maximizes the cumulative reward over time.
Supervised Learning tasks
regression ------ classification
Target Variable: CONTINUOUS
(age, income, temperature...)
Target Variable: Categorical
(color, shape, income class...)
The definition of a loss function requires the definition of distance or similarity
Machine Learning
Minkowski distance
Jaccard similarity
Great circle distance
The definition of a loss function requires the definition of distance or similarity
Machine Learning
NN:
Neural Networks
1
NN:
Neural Networks
1.1
origins
1943


M-P Neuron McCulloch & Pitts 1943
M-P Neuron
1943
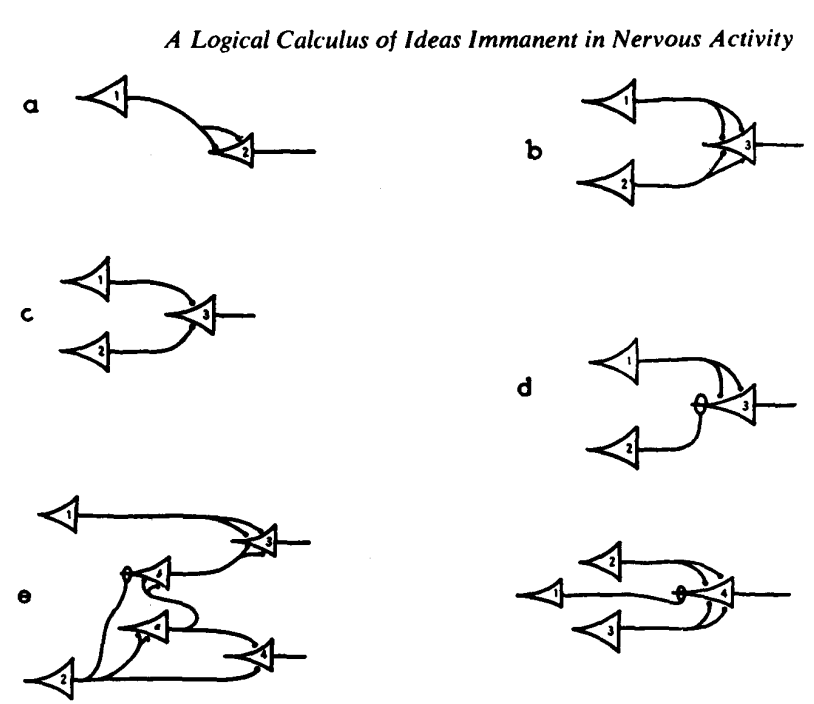
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
1943
M-P Neuron McCulloch & Pitts 1943
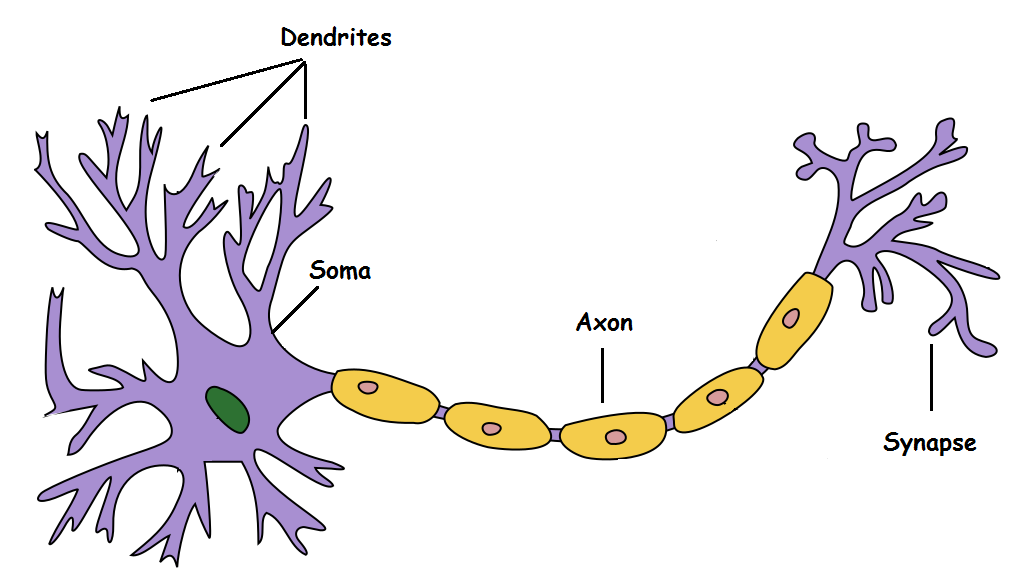
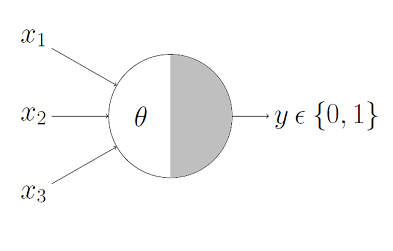
M-P Neuron
M-P Neuron
1943
M-P Neuron
its a classifier
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
M-P Neuron
1943
M-P Neuron McCulloch & Pitts 1943
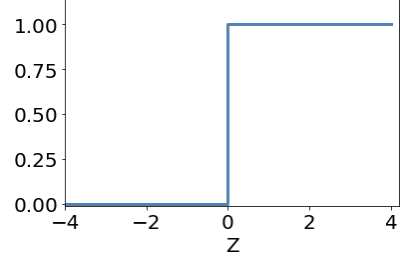
M-P Neuron
M-P Neuron
1943
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
what does have to be if
x1 = 0.1
x2 = 0.6
x3 = 0.2
and the target variable for this example is 1?
M-P Neuron
1943
if is Bool (True/False)
what value of corresponds to logical AND?
M-P Neuron McCulloch & Pitts 1943
M-P Neuron
The perceptron algorithm : 1958, Frank Rosenblatt

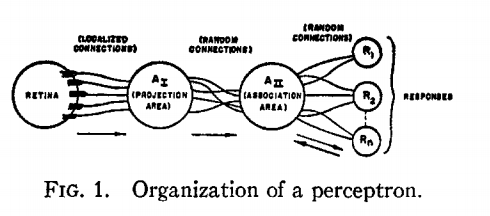
1958
Perceptron
Perceptron

1958
w1
w1
w2
w2
M-P Neuron
Perceptron
1943
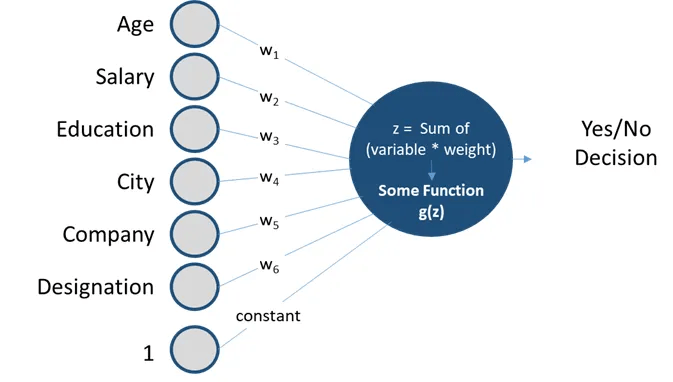
w1
w1
w2
w2
The perceptron algorithm : 1958, Frank Rosenblatt
1958
Perceptron
The perceptron algorithm : 1958, Frank Rosenblatt
.
.
.
output
weights
bias
linear regression:
1958
Perceptron
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
The perceptron algorithm : 1958, Frank Rosenblatt
x
y
1958
Perceptron
.
.
.
output
activation function
weights
bias
The perceptron algorithm : 1958, Frank Rosenblatt
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
Perceptron
The perceptron algorithm : 1958, Frank Rosenblatt
output
activation function
weights
bias
sigmoid
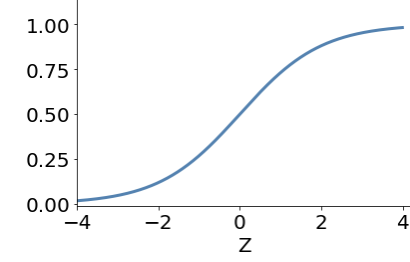
.
.
.
Perceptrons are linear classifiers: makes its predictions based on a linear predictor function
combining a set of weights (=parameters) with the feature vector.
Perceptron
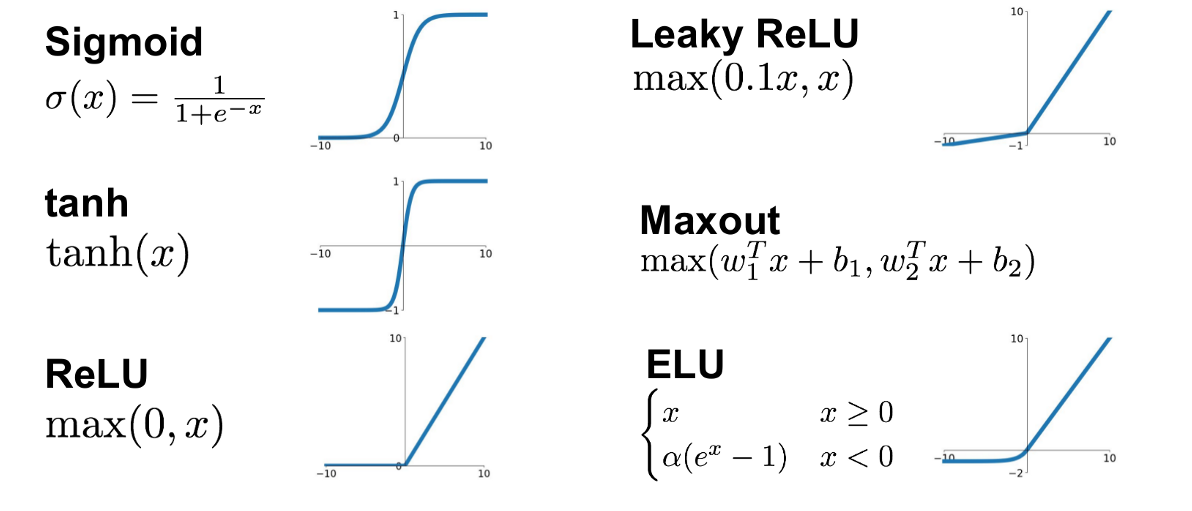
ANN examples of activation function
The perceptron algorithm : 1958, Frank Rosenblatt
Perceptron

The Navy revealed the embryo of an electronic computer today that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence.
The embryo - the Weather Buerau's $2,000,000 "704" computer - learned to differentiate between left and right after 50 attempts in the Navy demonstration
NEW NAVY DEVICE LEARNS BY DOING; Psychologist Shows Embryo of Computer Designed to Read and Grow Wiser
July 8, 1958

Deep Learning
2
DNN:
2
Problem:
Single-layer perceptrons are only capable of learning linearly separable patterns.

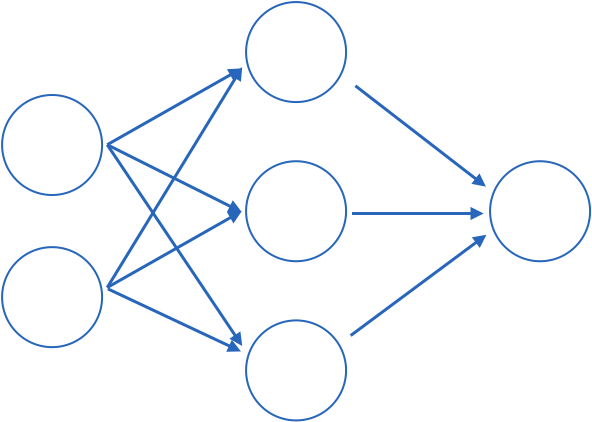
multilayer perceptron
output
layer of perceptrons
multilayer perceptron
output
input layer
hidden layer
output layer
1970: multilayer perceptron architecture
Fully connected: all nodes go to all nodes of the next layer.
Perceptrons by Marvin Minsky and Seymour Papert 1969
multilayer perceptron
output
layer of perceptrons
multilayer perceptron
output
layer of perceptrons
multilayer perceptron
layer of perceptrons
output
layer of perceptrons
multilayer perceptron
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
multilayer perceptron
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
learned parameters
multilayer perceptron
output
Fully connected: all nodes go to all nodes of the next layer.
layer of perceptrons
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
f: activation function:
turns neurons on-off
DNN:
hyperparameters of DNN
3
EXERCISE
output
how many parameters?
input layer
hidden layer
output layer
hidden layer
EXERCISE
output
how many parameters?
input layer
hidden layer
output layer
hidden layer
output
input layer
hidden layer
output layer
hidden layer
35
(3x4)+4
(4x3)+3
how many parameters?
EXERCISE
(3)+1
output
input layer
hidden layer
output layer
hidden layer
- number of layers- 1
- number of neurons/layer-
- activation function/layer-
- layer connectivity-
- optimization metric - 1
- optimization method - 1
- parameters in optimization- M
how many hyperparameters?
EXERCISE
GREEN: architecture hyperparameters
RED: training hyperparameters
EXERCISE
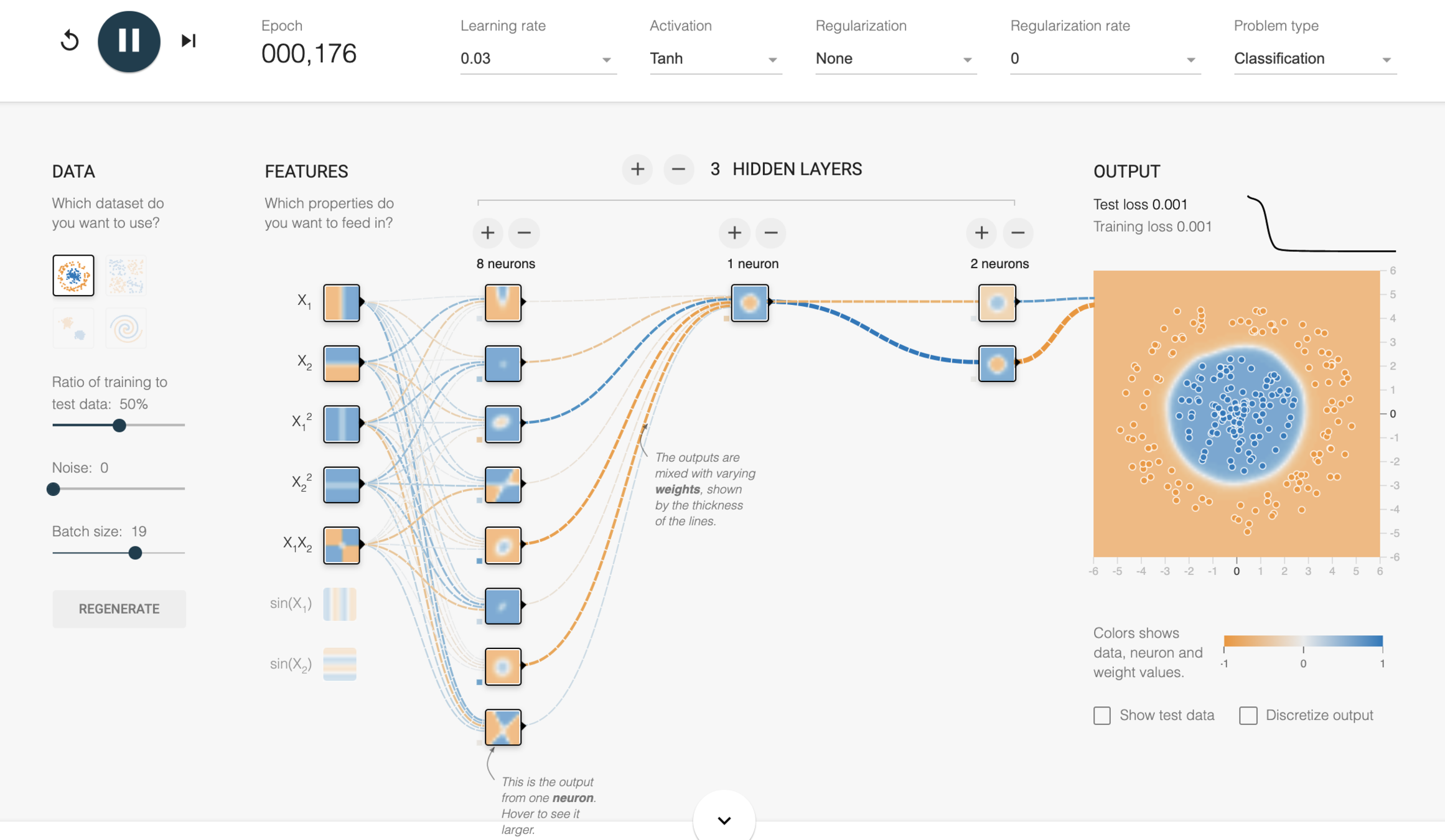
DNN:
training DNN
4
deep neural net
Fully connected: all nodes go to all nodes of the next layer.
1986: Deep Neural Nets
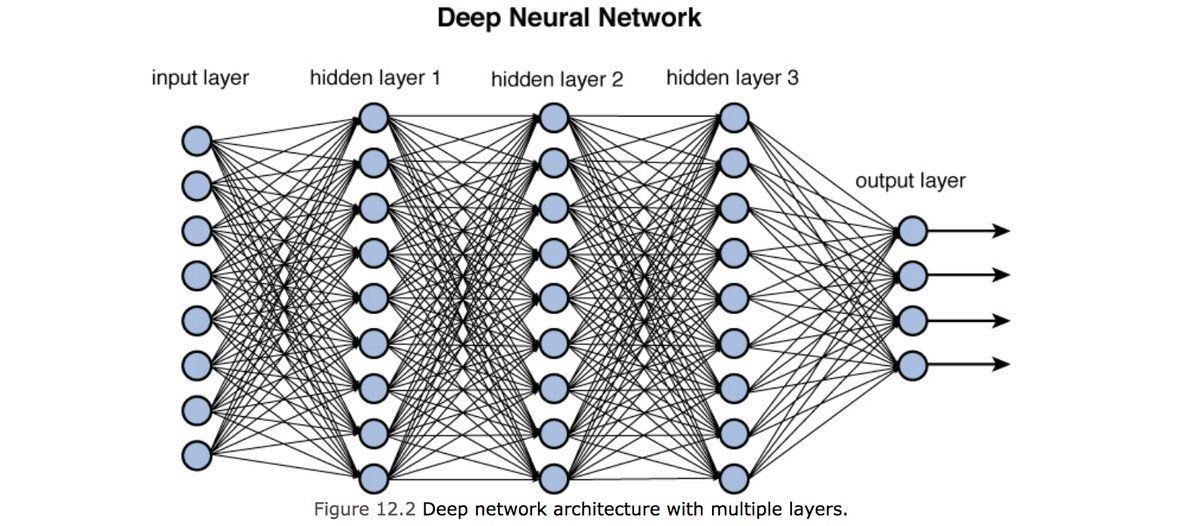
f: activation function:
turns neurons on-off
w: weight
sets the sensitivity of a neuron
b: bias:
up-down weights a neuron
In a CNN these layers would not be fully connected except the last one

Seminal paper
Y. LeCun 1998
.
.
.
Any linear model:
y : prediction
ytrue : target
Error: e.g.
intercept
slope
L2
x
Find the best parameters by finding the minimum of the L2 hyperplane
at every step look around and choose the best direction
back-propagation
back-propagation

how does linear descent look when you have a whole network structure with hundreds of weights and biases to optimize??
.
.
.
output

Training models with this many parameters requires a lot of care:
. defining the metric
. optimization schemes
. training/validation/testing sets
But just like our simple linear regression case, the fact that small changes in the parameters leads to small changes in the output for the right activation functions.
define a cost function, e.g.
Training models with this many parameters requires a lot of care:
. defining the metric
. optimization schemes
. training/validation/testing sets
But just like our simple linear regression case, the fact that small changes in the parameters leads to small changes in the output for the right activation functions.
define a cost function, e.g.
Training a DNN
feed data forward through network and calculate cost metric
for each layer, calculate effect of small changes on next layer
back-propagation
how does linear descent look when you have a whole network structure with hundreds of weights and biases to optimize??
think of applying just gradient to a function of a function of a function... use:
1) partial derivatives, 2) chain rule


define a cost function, e.g.
Training a DNN

Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
-
architecture - wide networks tend to overfit, deep networks are hard to train
- number of epochs - the sweet spot is when learning slows down, but before you start overfitting... it may take DAYS! jumps may indicate bad initial choices (like in all gradient descent)
- loss function - needs to be appropriate to the task, e.g. classification vs regression
-
activation functions - needs to be consistent with the loss function
- optimization scheme - needs to be appropriate to the task and data
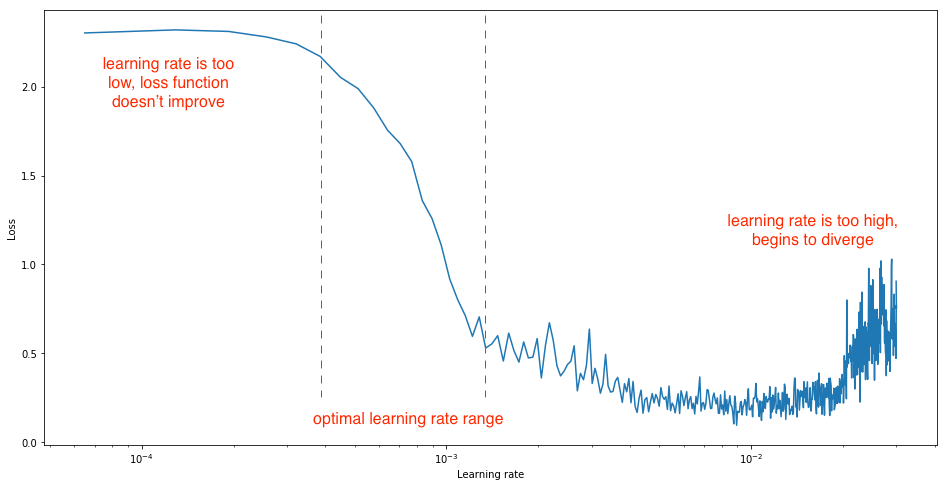
- learning rate in optimization - balance speed and accuracy
- batch size - smaller batch size is faster but leads to overtraining
An article that compars various DNNs

An article that compars various DNNs
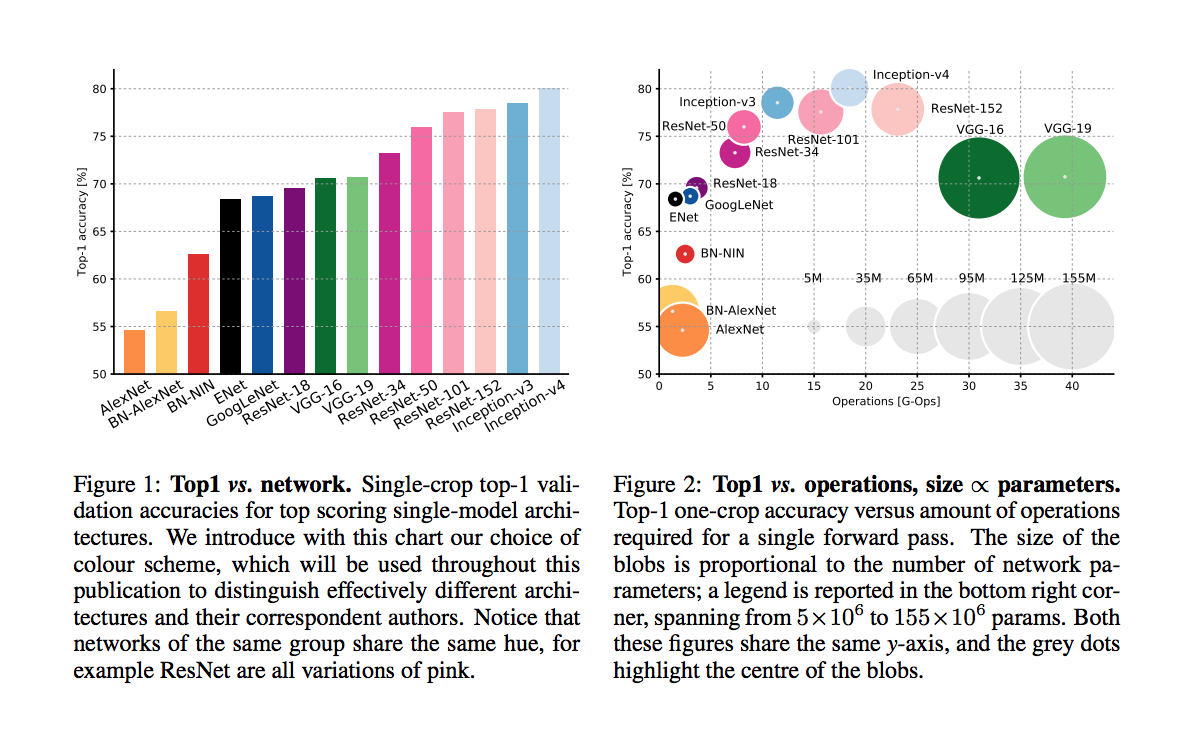
accuracy comparison
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
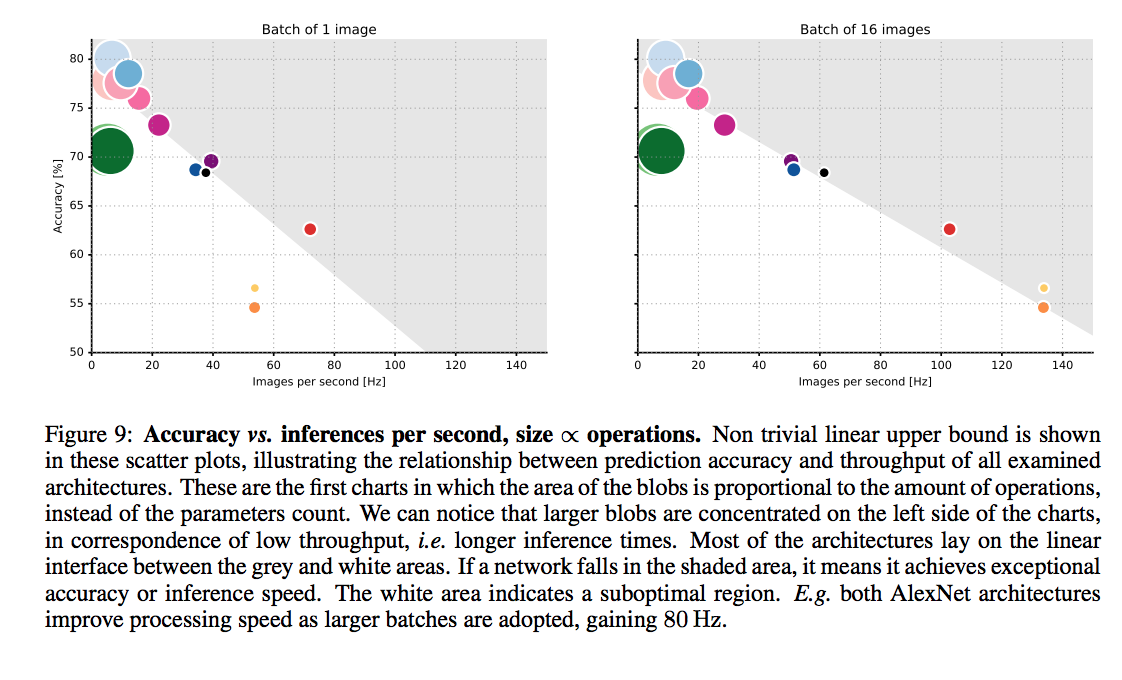
batch size
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
- architecture - wide networks tend to overfit, deep networks are hard to train
-
number of epochs - the sweet spot is when learning slows down, but before you start overfitting... it may take DAYS! jumps may indicate bad initial choices
-
loss function - needs to be appropriate to the task, e.g. classification vs regression
-
activation functions - needs to be consistent with the loss function
- optimization scheme - needs to be appropriate to the task and data
- learning rate in optimization - balance speed and accuracy
- batch size - smaller batch size is faster but leads to overtraining

What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Lots of parameters and lots of hyperparameters! What to choose?
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
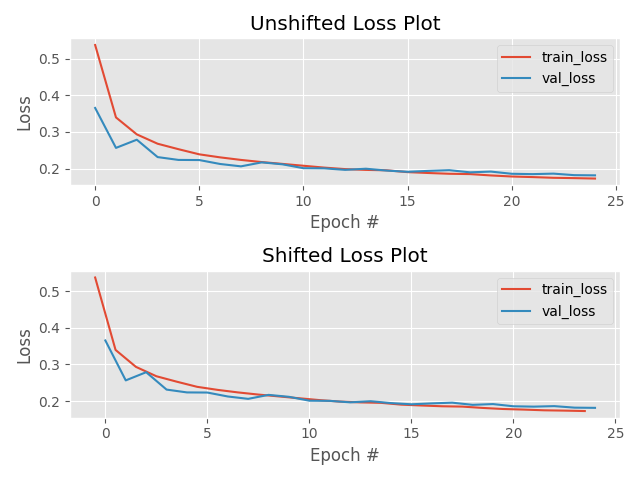
always check your loss function! it should go down smoothly and flatten out at the end of the training.
not flat? you are still learning!
too flat? you are overfitting...
loss (gallery of horrors)
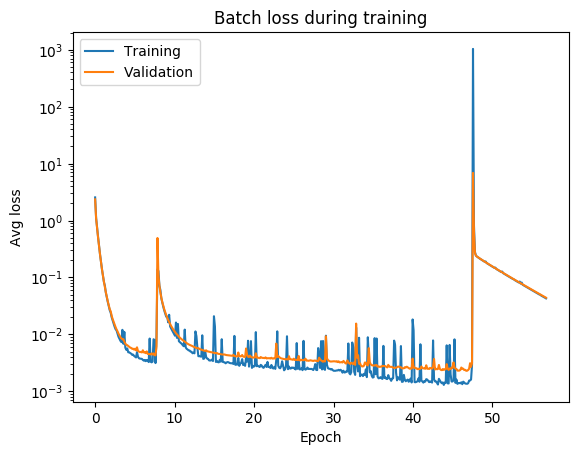
jumps are not unlikely (and not necessarily a problem) if your activations are discontinuous (e.g. relu)
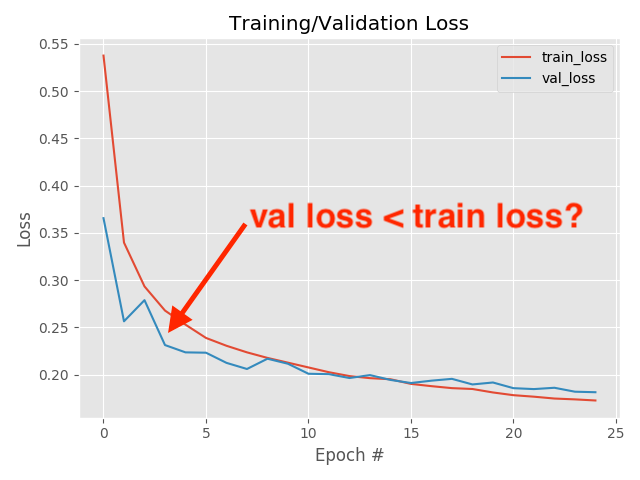
when you use validation you are introducing regularizations (e.g. dropout) so the loss can be smaller than for the training set
loss and learning rate (not that the appropriate learning rate depends on the chosen optimization scheme!)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
| loss | good for | activation last layer | size last layer |
|---|---|---|---|
| mean_squared_error | regression | linear | one node |
| mean_absolute_error | regression | linear | one node |
| mean_squared_logarithmit_error | regression | linear | one node |
| binary_crossentropy | binary classification | sigmoid | one node |
| categorical_crossentropy | multiclass classification | sigmoid | N nodes |
| Kullback_Divergence | multiclass classification, probabilistic inerpretation | sigmoid | N nodes |
On the interpretability of DNNs
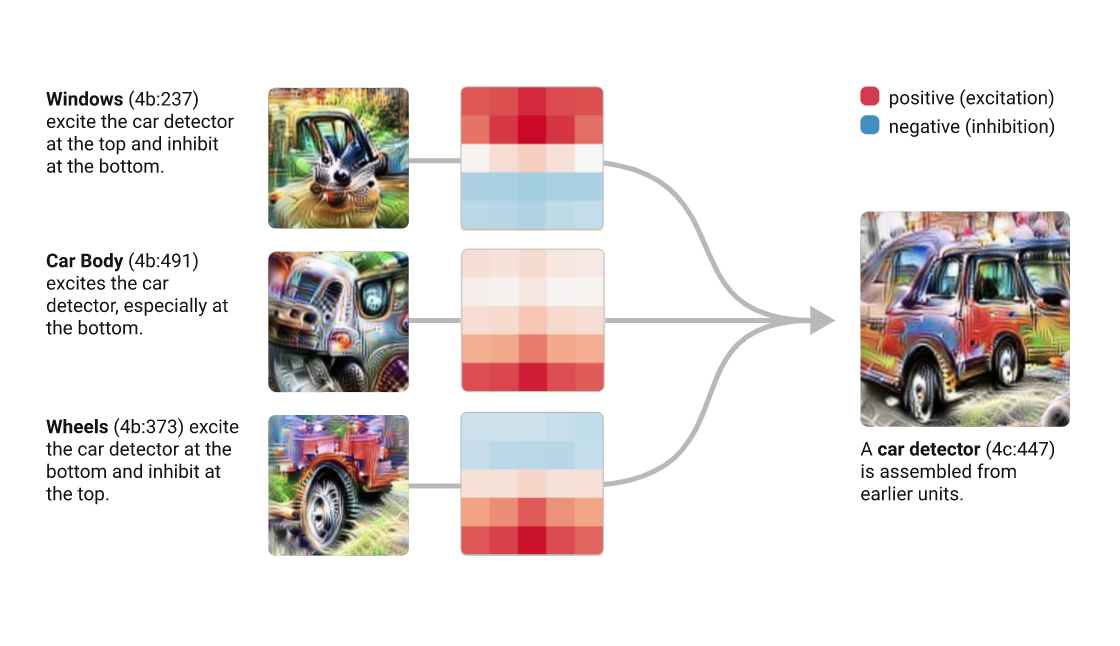


Punch Line
Deep Neural Net are not some fancy-pants methods, they are just linear models with a bunch of parameters
Black Box?
Because they have many parameters they are difficult to "interpret" (no easy feature extraction)
tha is ok becayse they are prediction machines
deep dreams
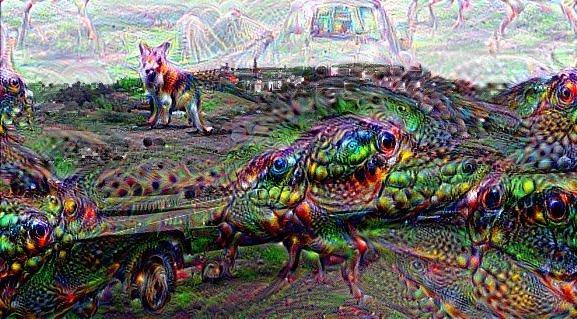
deep dreams

what is happening in DeepDream?
Deep Dream (DD) is a google software, a pre-trained NN (originally created on the Cafe architecture, now imported on many other platforms including tensorflow).
The high level idea relies on training a convolutional NN to recognize common objects, e.g. dogs, cats, cars, in images. As the network learns to recognize those objects is developes its layers to pick out "features" of the NN, like lines at a cetrain orientations, circles, etc.
The DD software runs this NN on an image you give it, and it loops on some layers, thus "manifesting" the things it knows how to recognize in the image.

@akumadog
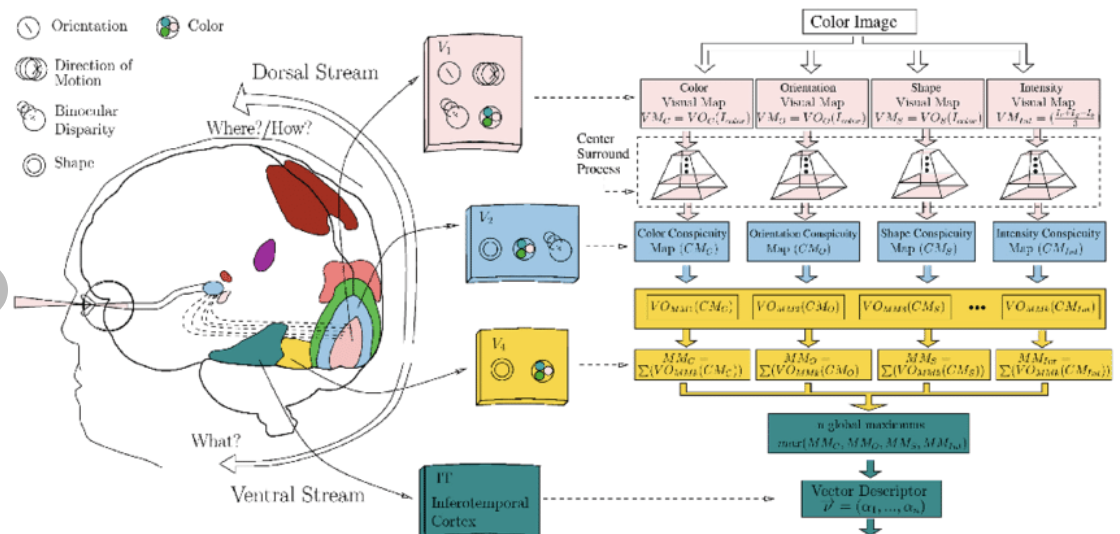
Brain Programming and the Random Search in Object Categorization
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
resources
Neural Network and Deep Learning
an excellent and free book on NN and DL
http://neuralnetworksanddeeplearning.com/index.html
History of NN
https://cs.stanford.edu/people/eroberts/courses/soco/projects/neural-networks/History/history2.html
homework
