














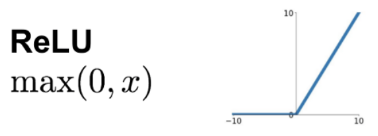











federica bianco PRO
astro | data science | data for good
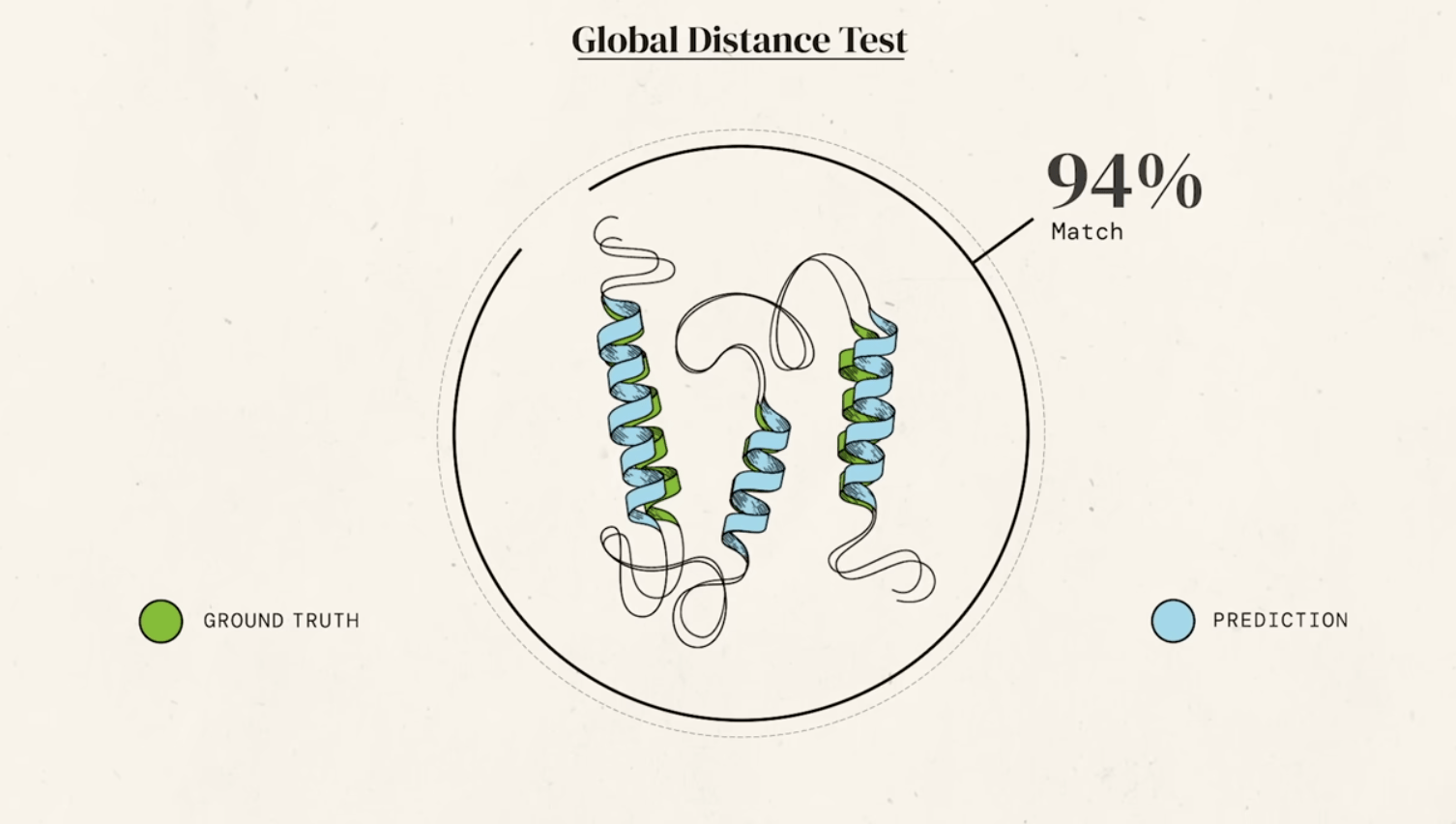
the AlphaFold revolution
Fall 2025 - UDel PHYS 664
dr. federica bianco
@fedhere
Protein folding
protein folding is the physical process by which a protein chain, freshly synthesized by a cell, folds into its native, three-dimensional structure, allowing it to perform its specific function.
The information needed for folding is encoded in the protein's amino acid sequence, which itself is encoded in DNA.
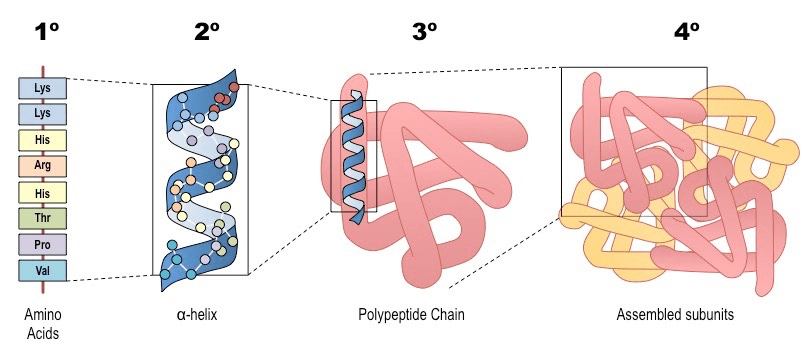
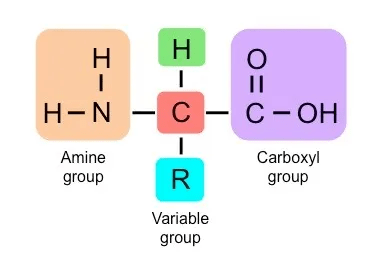
(2) Amino Acid Sequence (Primary Structure): The arrangement of amino acids in a protein. The DNA code is translated into a linear chain of amino acids. Proteins can be made from 20 different amino acids, and the structure and function of each protein are determined by the kinds of amino acids used to make it and how they are arranged.
The information needed for folding is encoded in the protein's amino acid sequence, which itself is encoded in DNA.
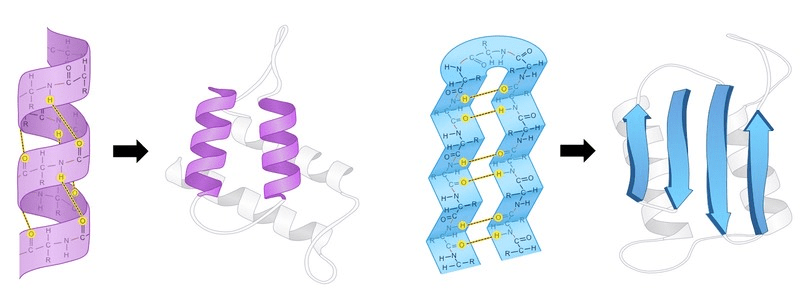
(3) Local Folding (Secondary Structure): Sections of the chain spontaneously form local, stable patterns held together by hydrogen bonds. The most common are:
α-helices: A coiled, spring-like structure.
β-sheets: Pleated strands that line up side-by-side.
It is the way a polypeptide folds in a repeating arrangement.
This folding is a result of H bonding between the amine and carboxyl groups of non-adjacent amino acids
The information needed for folding is encoded in the protein's amino acid sequence, which itself is encoded in DNA.
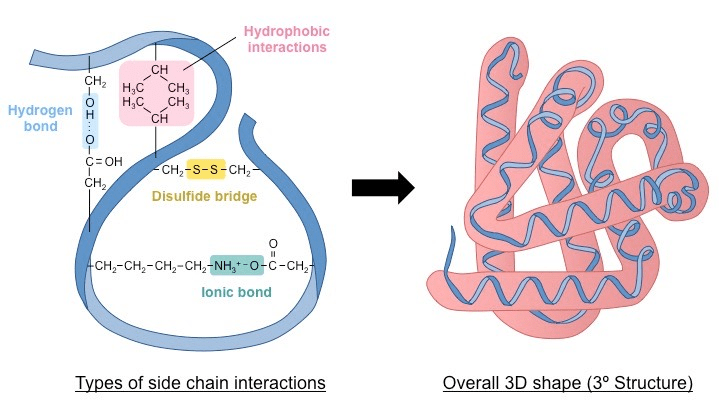
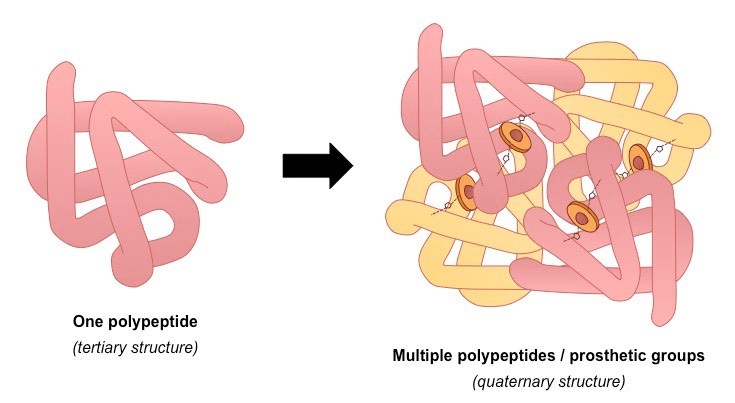
(4) Global Folding (Tertiary Structure): The entire chain folds further into a unique, compact 3D shape.
The information needed for folding is encoded in the protein's amino acid sequence, which itself is encoded in DNA.
(5) Complex Assembly (Quaternary Structure): Some proteins are made of multiple folded polypeptide chains (subunits) that assemble together to form the final, functional protein (e.g., hemoglobin).
Drug Design (Structure-Based Drug Design): Most drugs work by binding to a specific protein to either activate or block its function: design drugs to perfectly fit into a protein active site.
Example: Predicting the structure of the SARS-CoV-2 spike protein was crucial for rapidly developing vaccines and therapeutic antibodies
Understanding Genetic Diseases
Fighting "Misfolding" Diseases: Alzheimer's and Parkinson's,
Motivation
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
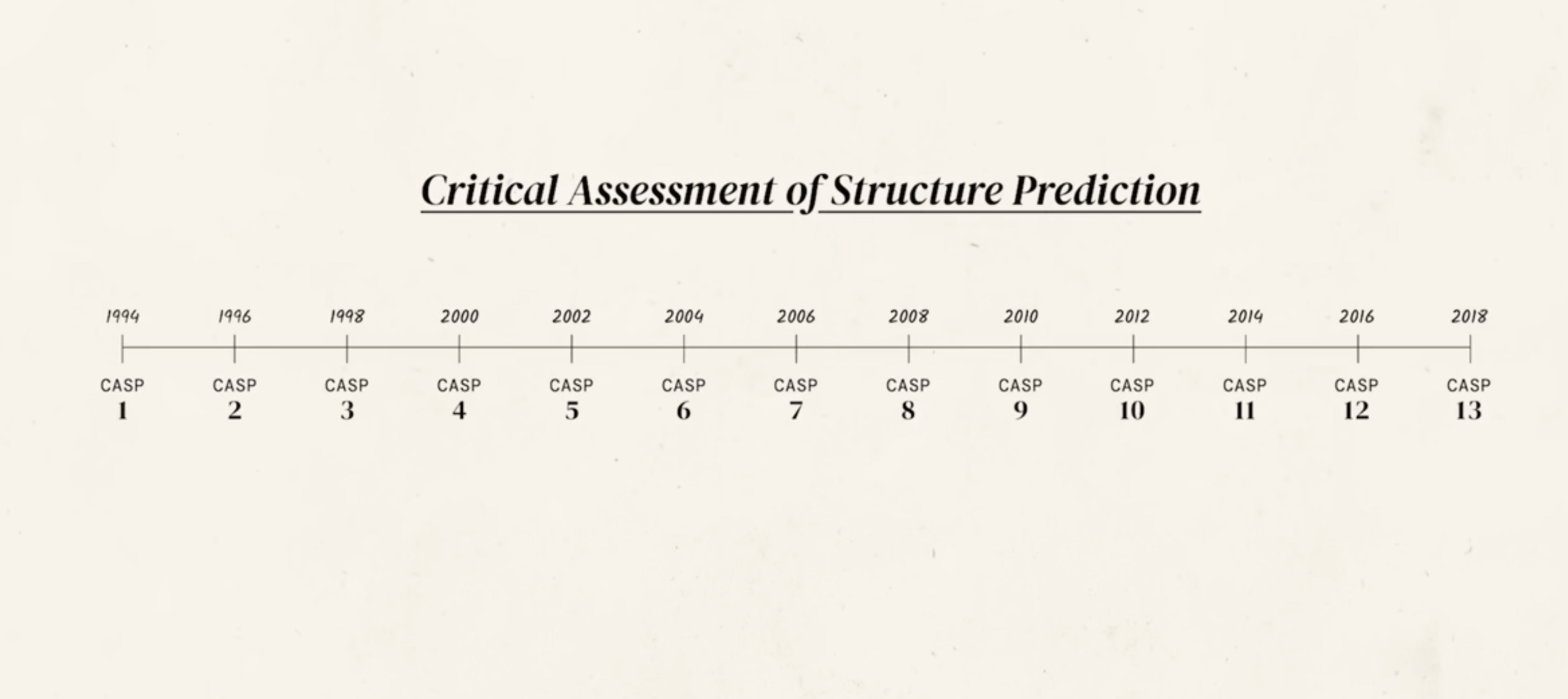
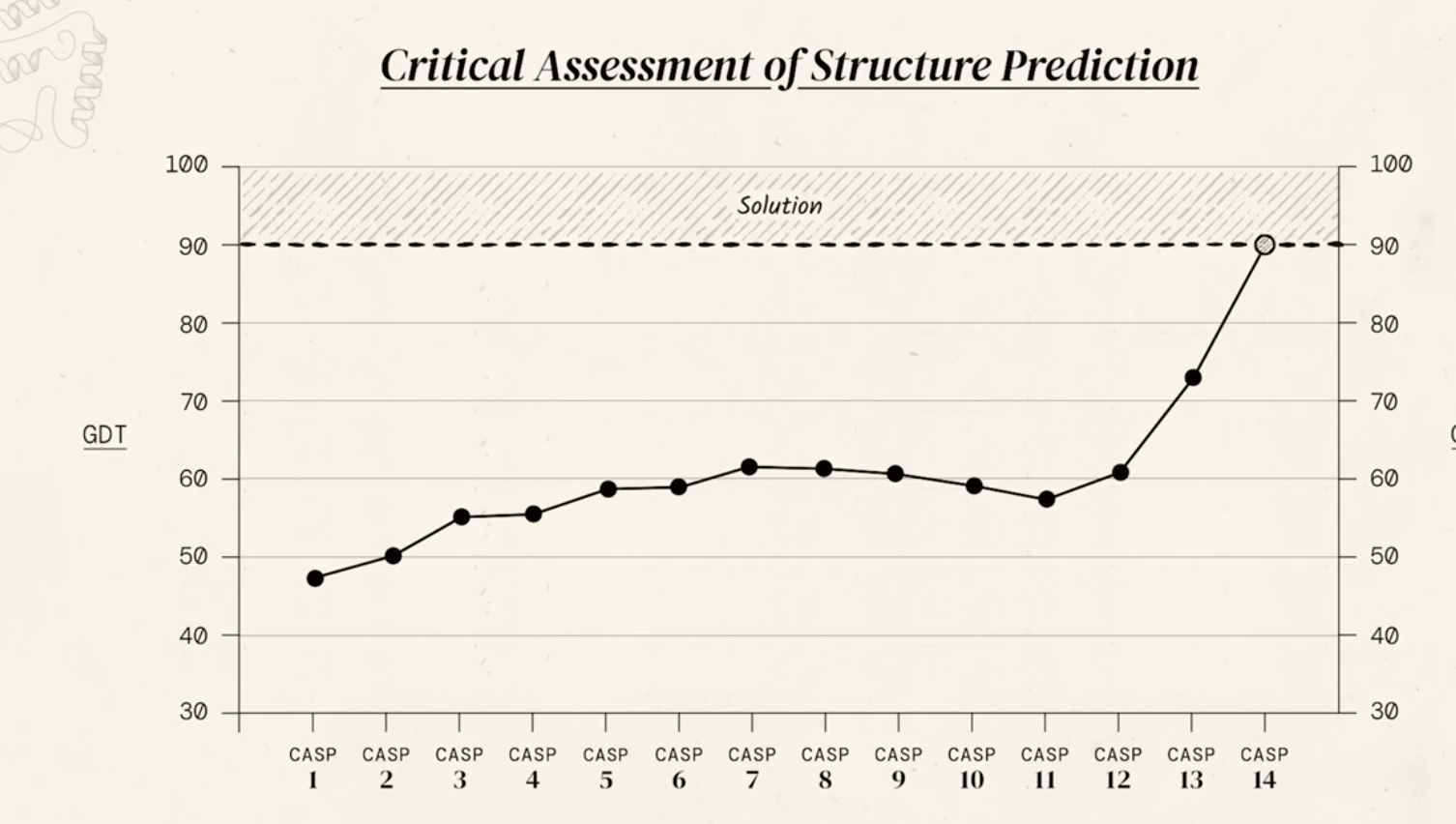
send out groups of 100 proteins and ask researchers to predict folding
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
How it works: It uses a deep learning network trained on the thousands of known protein structures in the Protein Data Bank (PDB). It looks for evolutionary patterns and physical constraints to predict the 3D coordinates of every atom.
AlphaFOLD
Anfinsen’s dogma
In standard physiological environment, a protein’s structure is determined by the sequence of amino acids that make it up (1972 Nobel Prize in Chemistry).
If so we should be able to reliably predict a protein’s structure from its sequence.
Levinthal’s paradox
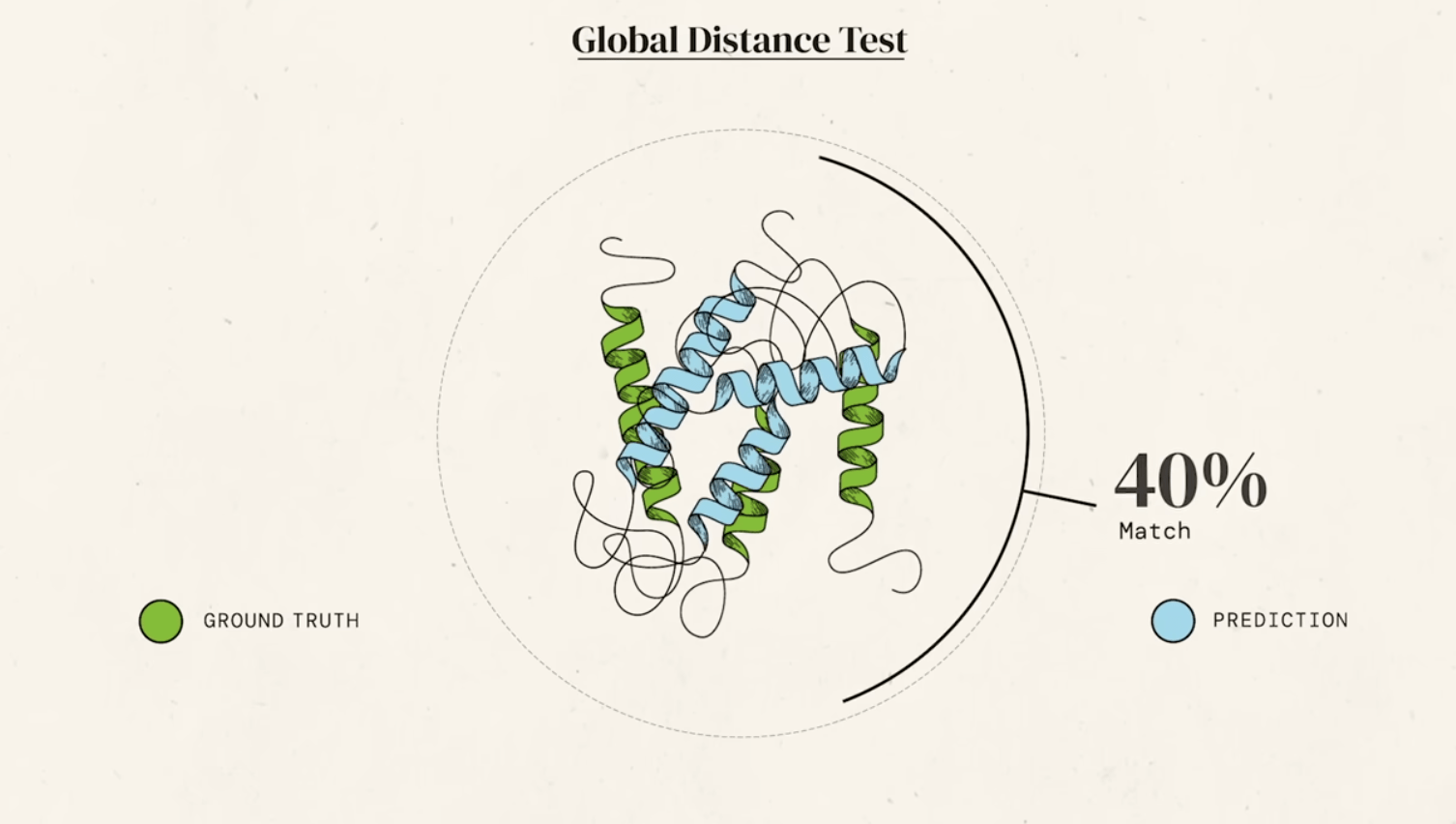
In the 1960s, Cyrus Levinthal showed that finding the native folded state of a protein by a random search among all possible configurations can take a time comparable with the lifetime of the Universe.
35 aminoacids ->1e33 ways to fold
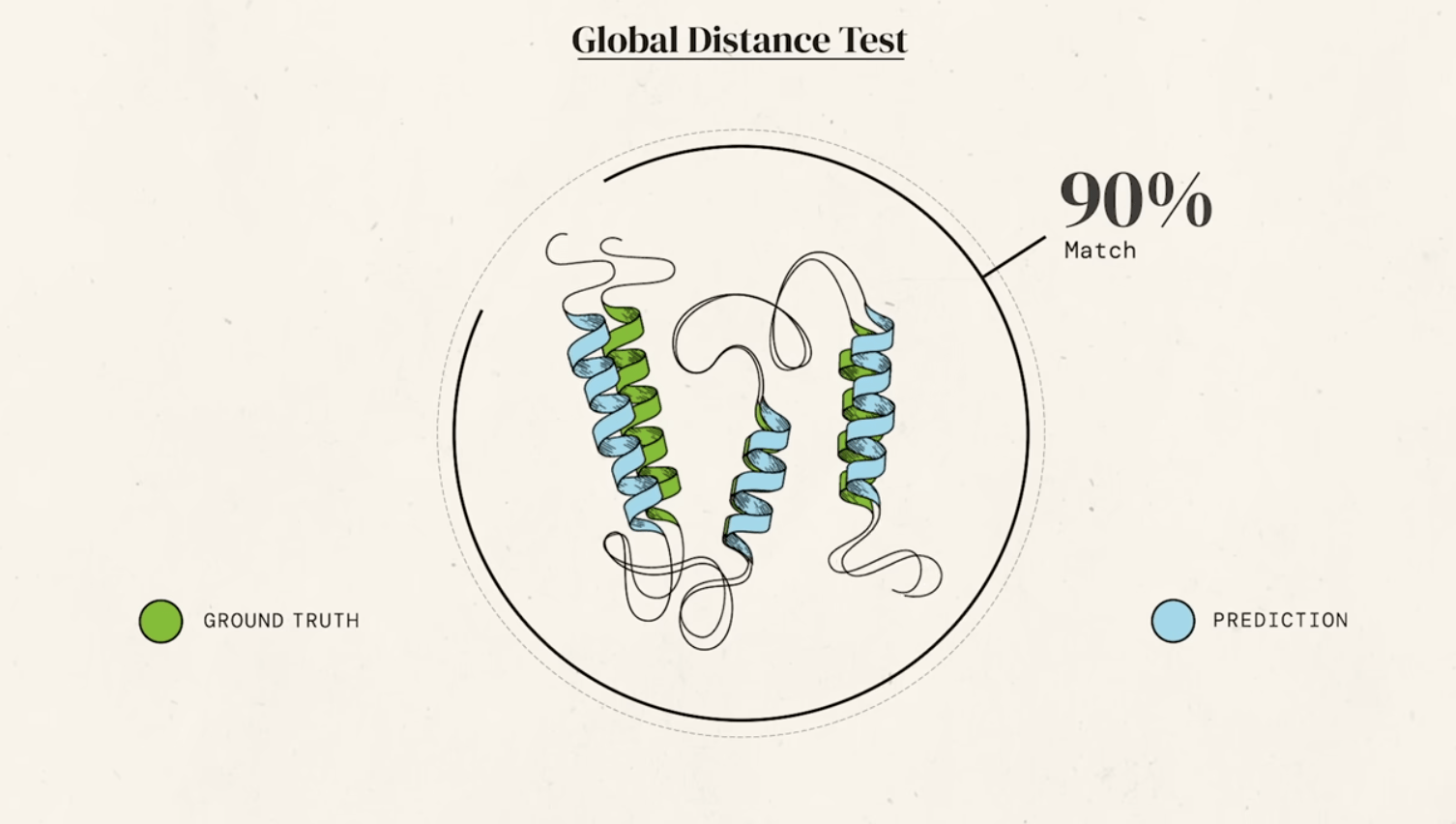
A small and physically reasonable energy bias against locally unfavorable configurations, of the order of a few kT, can reduce Levinthal's time to a biologically significant size.
For decades, predicting a protein's 3D structure from its amino acid sequence alone (the "protein folding problem") was one of the grand challenges in biology. This was revolutionized in 2020 by DeepMind's AlphaFold, an artificial intelligence system.
he central dogma of molecular biology is: Structure Determines Function.
Enzymes: The precise 3D shape creates an "active site" where specific chemical reactions are catalyzed. The wrong shape means no reaction.
Antibodies: Their Y-shaped structure allows them to recognize and bind to foreign invaders like viruses and bacteria.
Structural Proteins (e.g., Collagen, Keratin): Their folded shapes provide strength and support to tissues like skin, hair, and bones.
Transport Proteins (e.g., Hemoglobin): Their shape allows them to pick up and release oxygen in the blood.
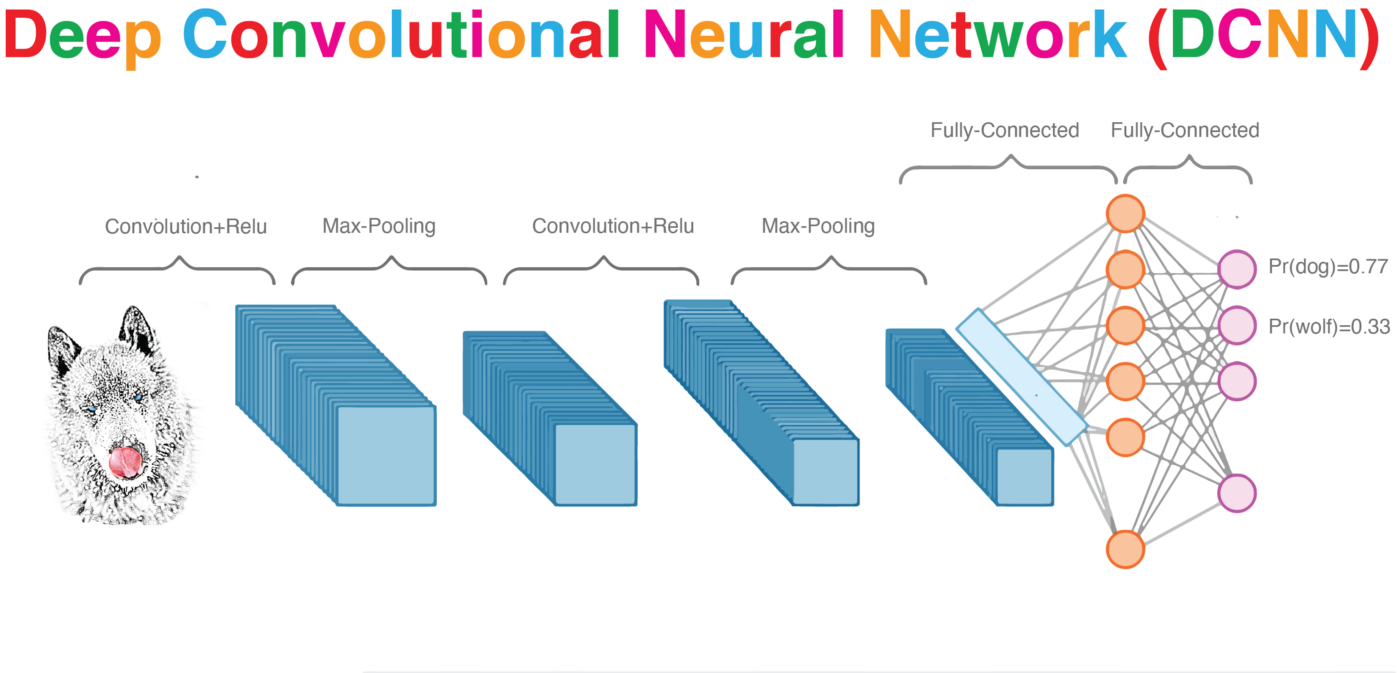
Convolutional Neural Nets
0
NN are a vast topics and we only have 2 weeks!
Some FREE references!
michael nielsen
better pedagogical approach, more basic, more clear
ian goodfellow
mathematical approach, more advanced, unfinished
michael nielsen
better pedagogical approach, more basic, more clear
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
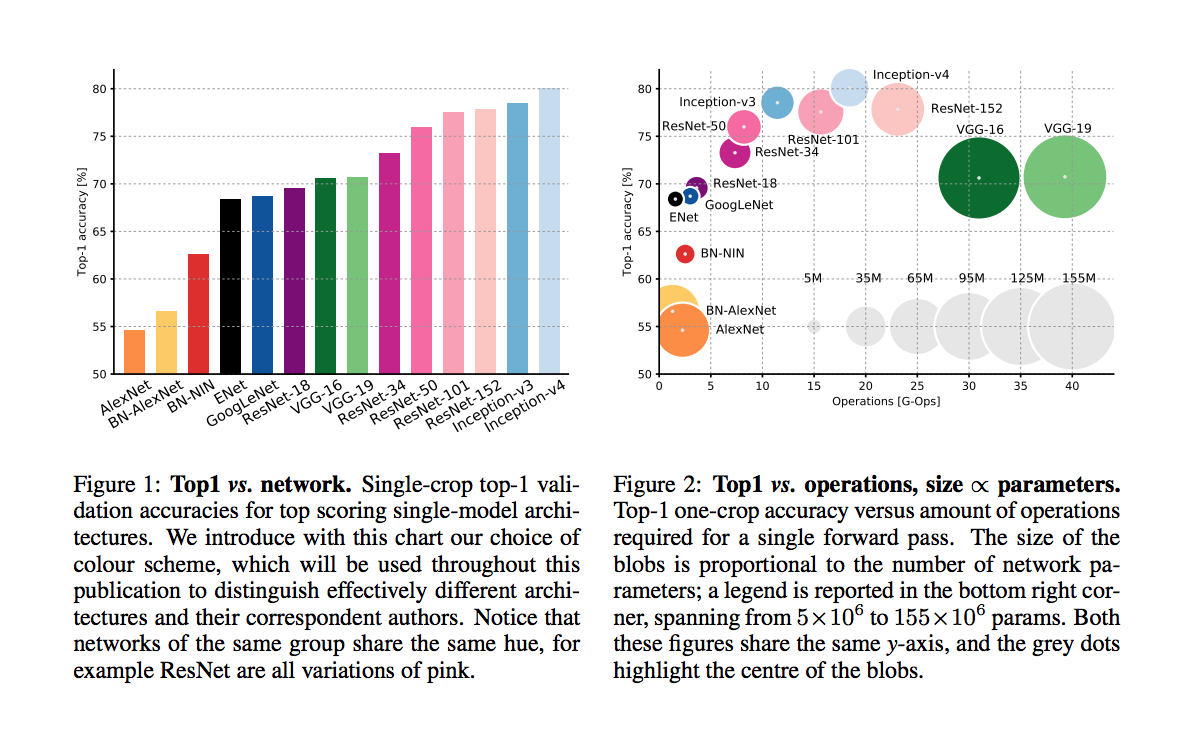
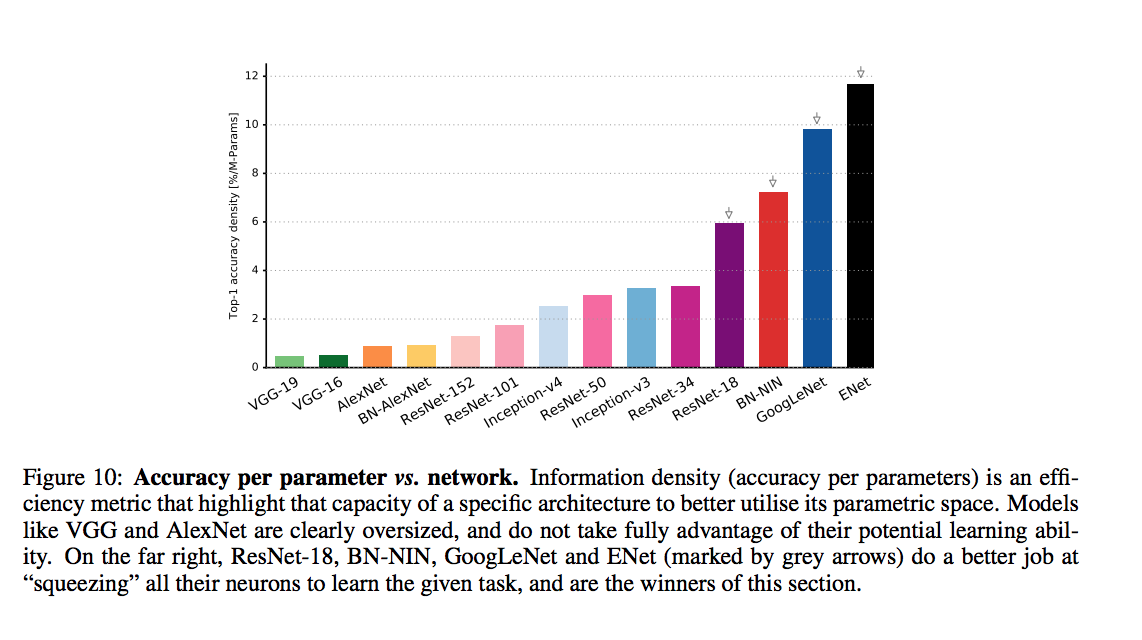
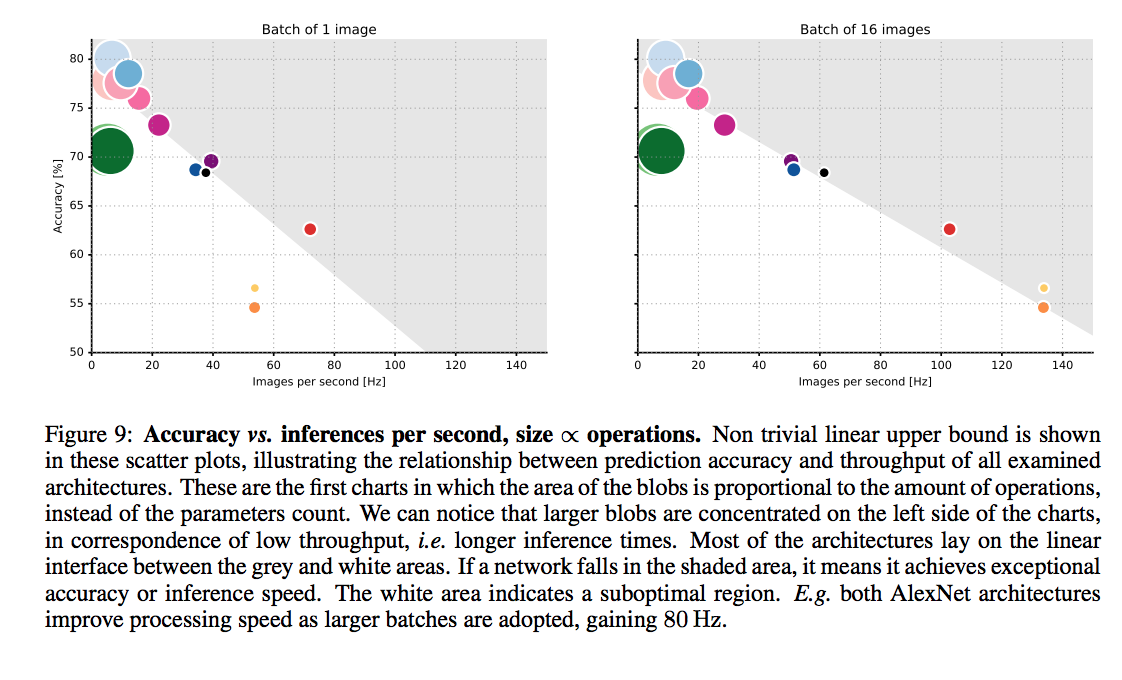
An article that compars various DNNs
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
accuracy comparison
An article that compars various DNNs
batch size
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Lots of parameters and lots of hyperparameters! What to choose?
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
Lots of parameters and lots of hyperparameters! What to choose?
Lots of parameters and lots of hyperparameters! What to choose?
cheatsheet
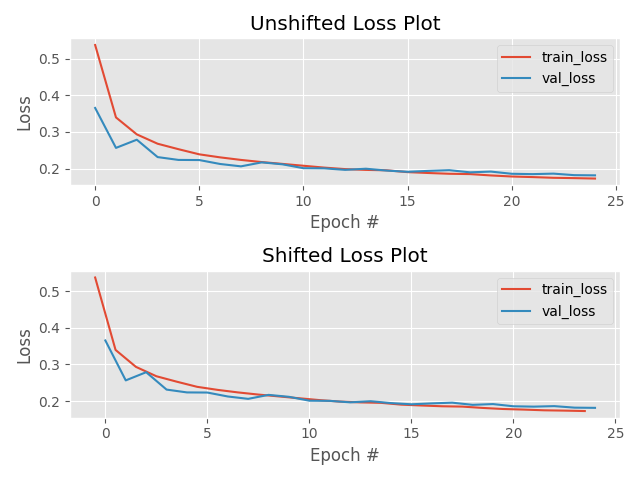
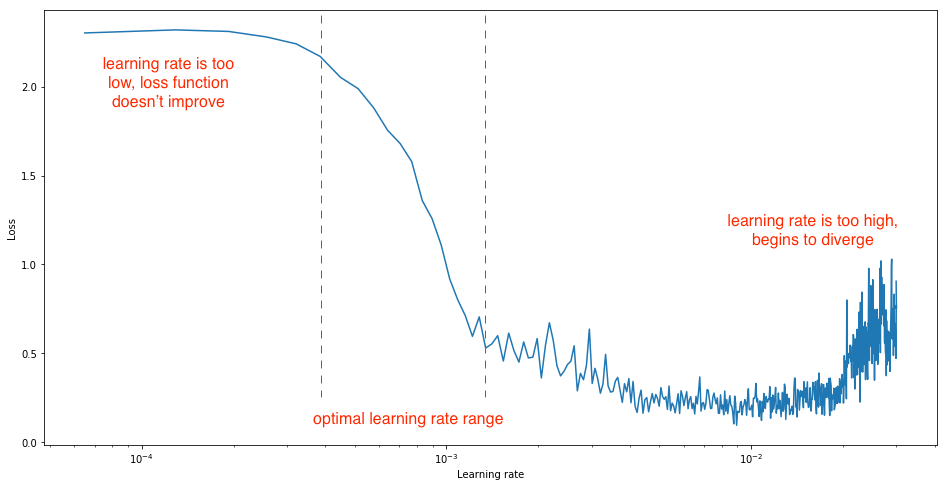
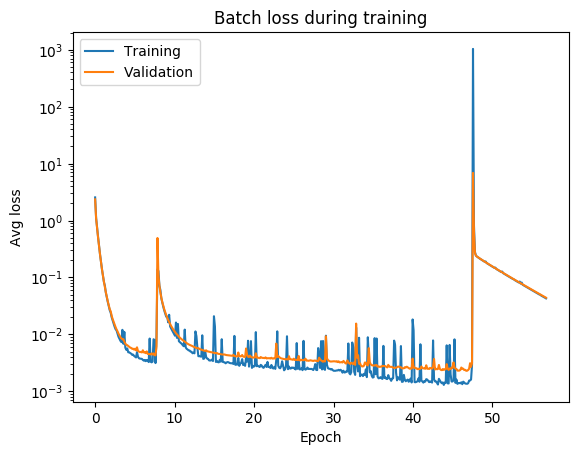
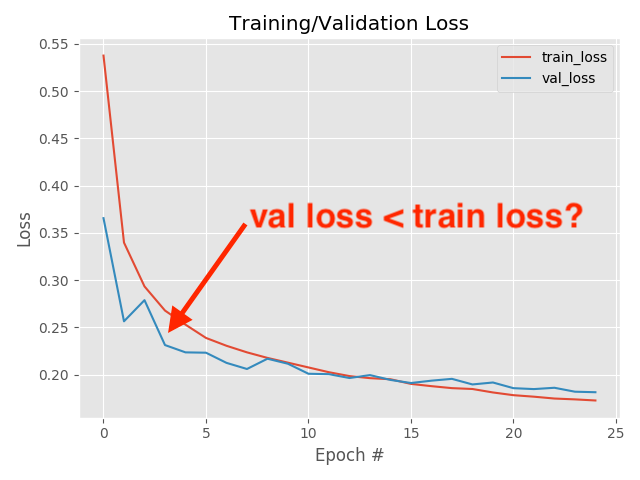
always check your loss function! it should go down smoothly and flatten out at the end of the training.
not flat? you are still learning!
too flat? you are overfitting...
loss (gallery of horrors)
jumps are not unlikely (and not necessarily a problem) if your activations are discontinuous (e.g. relu)
when you use validation you are introducing regularizations (e.g. dropout) so the loss can be smaller than for the training set
loss and learning rate (not that the appropriate learning rate depends on the chosen optimization scheme!)
Building a DNN
with keras and tensorflow
autoencoder for image recontstruction
What should I choose for the loss function and how does that relate to the activation functiom and optimization?
| loss | good for | activation last layer | size last layer |
|---|---|---|---|
| mean_squared_error | regression | linear | one node |
| mean_absolute_error | regression | linear | one node |
| mean_squared_logarithmit_error | regression | linear | one node |
| binary_crossentropy | binary classification | sigmoid | one node |
| categorical_crossentropy | multiclass classification | sigmoid | N nodes |
| Kullback_Divergence | multiclass classification, probabilistic inerpretation | sigmoid | N nodes |
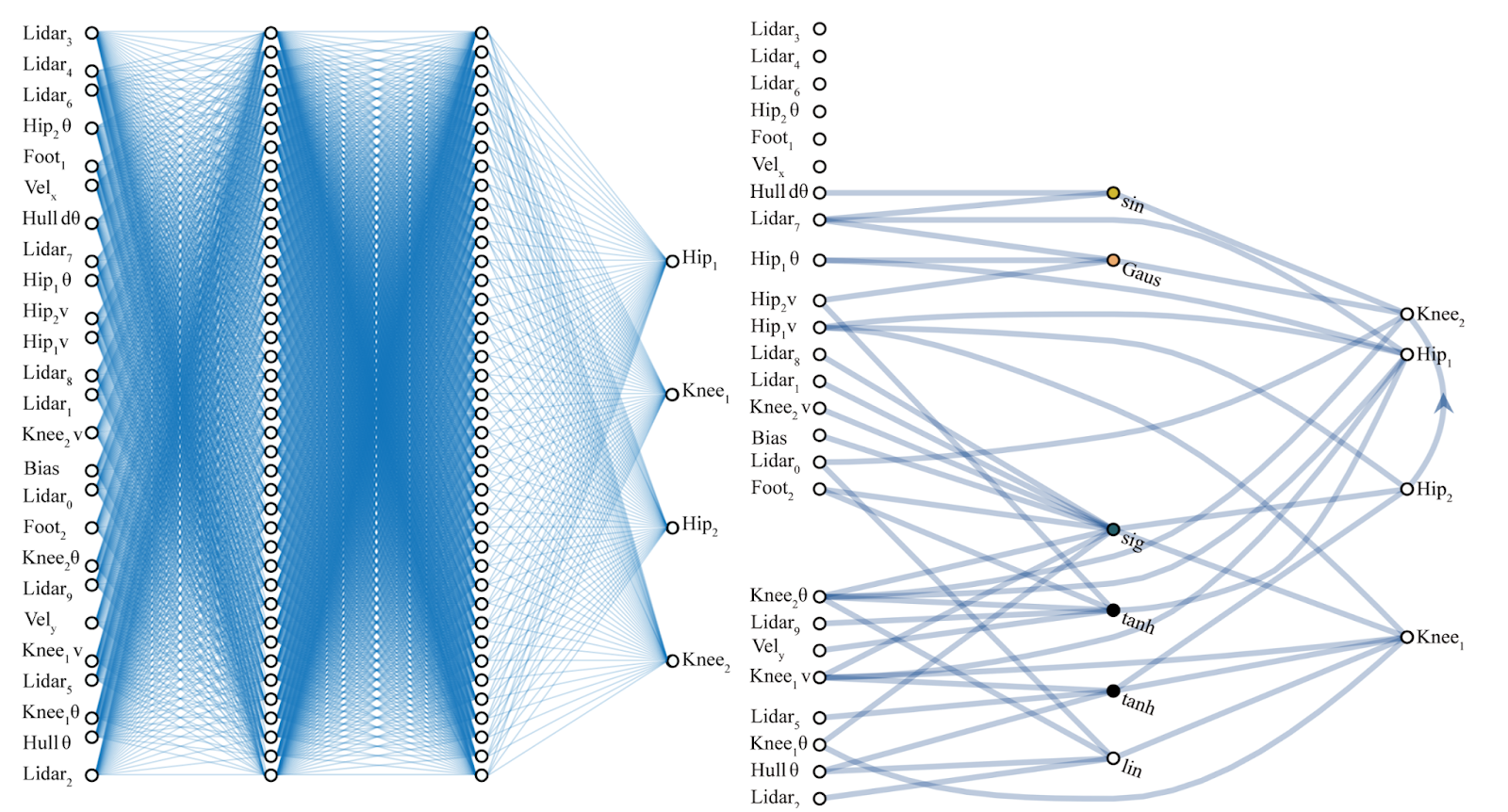
On the interpretability of DNNs
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
@akumadog
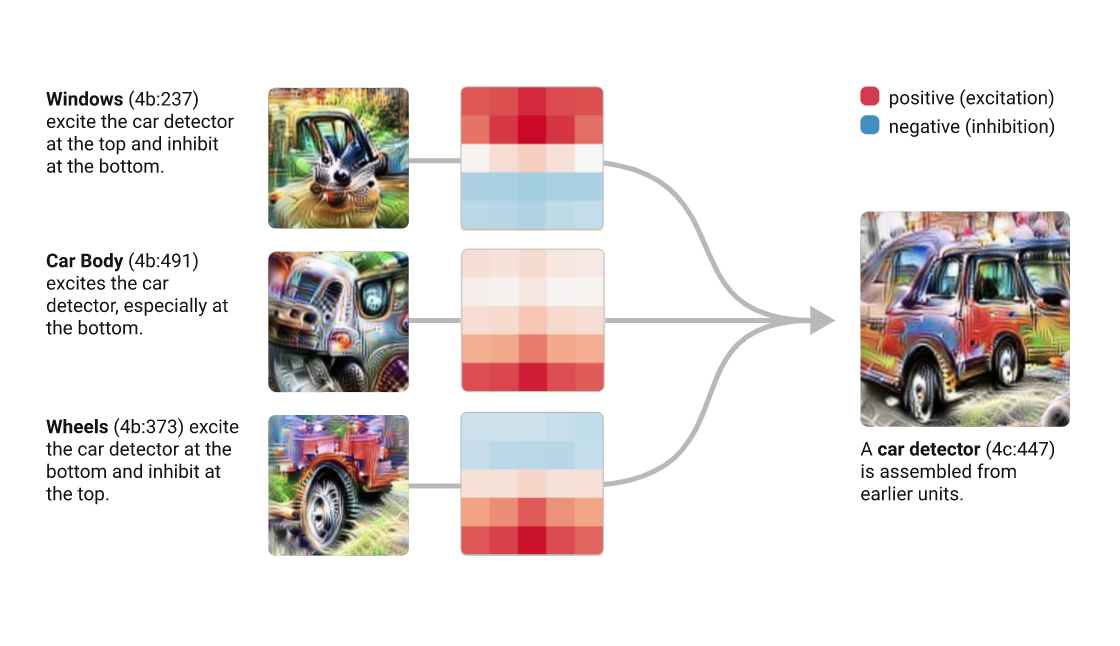
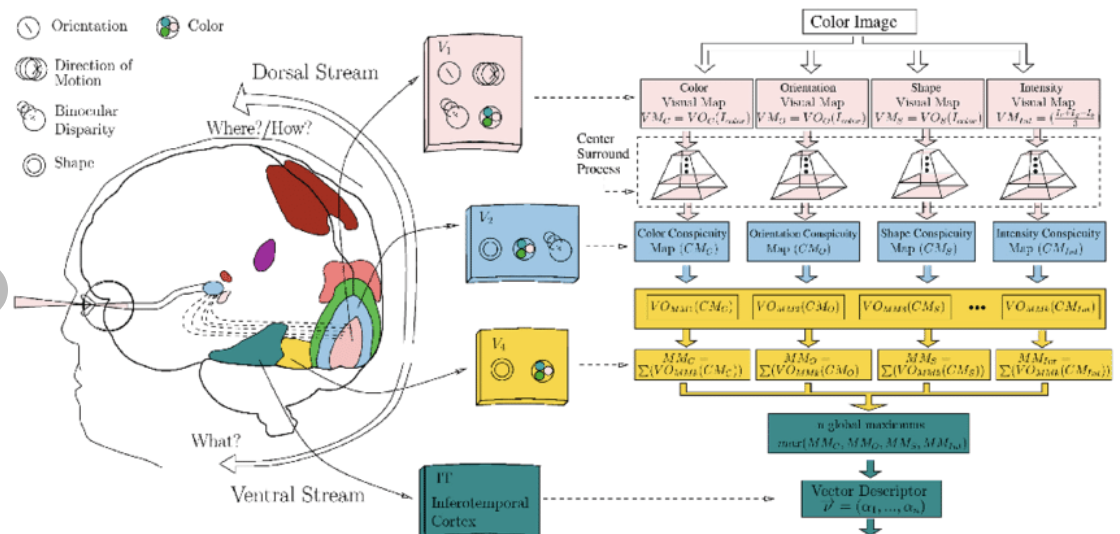
The visual cortex learns hierarchically: first detects simple features, then more complex features and ensembles of features
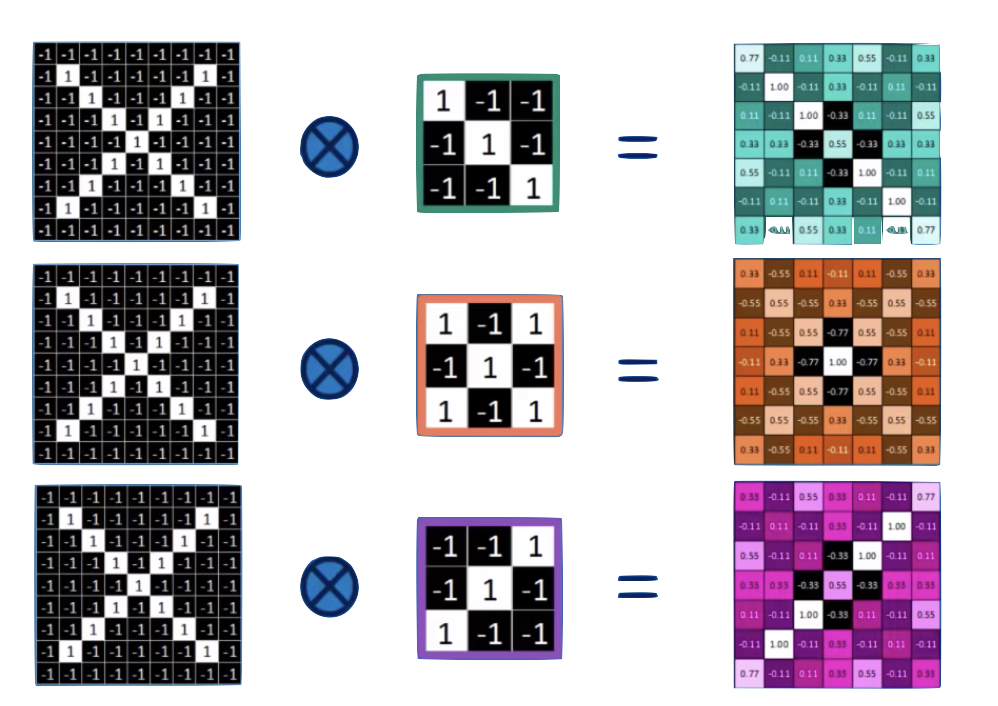
Convolution
convolution is a mathematical operator on two functions
f and g
that produces a third function
f x g
expressing how the shape of one is modified by the other.
o
two images.
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
1
1
1
1
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| -1 | -1 | 1 |
| -1 | 1 | -1 |
| 1 | -1 | -1 |
feature maps
1
1
1
1
1
convolution
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | ||
|---|---|---|
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | |
|---|---|---|
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ||
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ? | |
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -1 | 3 |
|---|---|---|
| ? | ? | |
=
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
=
input layer
feature map
convolution layer
the feature map is "richer": we went from binary to R
1
1
1
1
1
| -1 | -1 | -1 | -1 | -1 |
|---|---|---|---|---|
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | |
| -1 | -1 | -1 | ||
| -1 | -1 | -1 | -1 | -1 |
| 1 | -1 | -1 |
| -1 | 1 | -1 |
| -1 | -1 | 1 |
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
=
input layer
feature map
convolution layer
the feature map is "richer": we went from binary to R
and it is reminiscent of the original layer
7
5
7
Convolve with different feature: each neuron is 1 feature
| 7 | -3 | 3 |
| -3 | 5 | -3 |
| 3 | -1 | 7 |
7
5
7
ReLu: normalization that replaces negative values with 0's
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
Max-Pool
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 0 | 0 | 7 |
7
5
7
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
| 5 |
MaxPooling: reduce image size, generalizes result
| 7 | 0 | 3 |
| 0 | 5 | 0 |
| 3 | 0 | 7 |
7
5
7
2x2 Max Poll
| 7 | 5 |
| 5 | 7 |
MaxPooling: reduce image size & generalizes result
By reducing the size and picking the maximum of a sub-region we make the network less sensitive to specific details
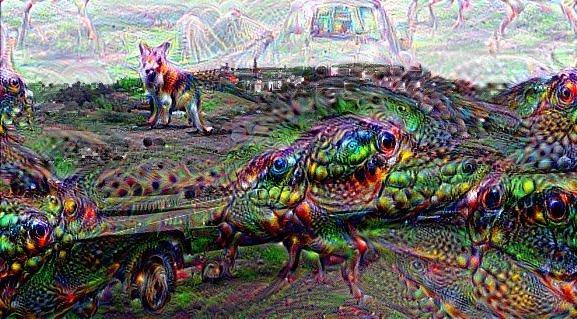
Deep Dream (DD) is a google software, a pre-trained NN (originally created on the Cafe architecture, now imported on many other platforms including tensorflow).
The high level idea relies on training a convolutional NN to recognize common objects, e.g. dogs, cats, cars, in images. As the network learns to recognize those objects is developes its layers to pick out "features" of the NN, like lines at a cetrain orientations, circles, etc.
The DD software runs this NN on an image you give it, and it loops on some layers, thus "manifesting" the things it knows how to recognize in the image.
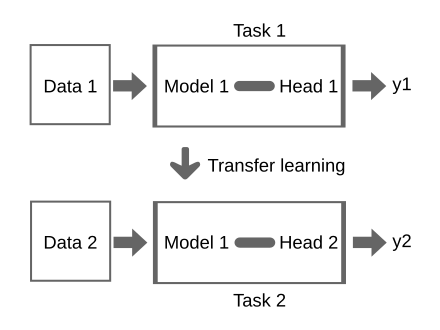
can you use it for another task?
you have a model which was trained on some data
DOMAIN ADAPTATION: learning a model from a source data distribution and applying that model on a target data with a different distribution: the features are the same but have different distributions
e.g. Learn an energy model in one city (using building size, usage, occupancy) then apply it to a different city
?
does the model generalize to answer question on the new dataset with accuracy?
YES
NO
No need for additional learning: the model is transferable!
Fine Tune your model on the new data
you have a model which was trained on some data
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
Industry models like Chat-GPT or SAM are trained on huge amount of data we scientists could not afford to get!
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
And large companies like Open-AI, Facebook, Google have unmatched computational resources
Start with the saved trained model:
weights and biases are set in the pre-trained model by training on Data 1
restart training from those weights and biases and adjust weights by running only a few epochs
prediction "head"
original data
Remember the "Deep Dream" demo and assignment
prediction "head"
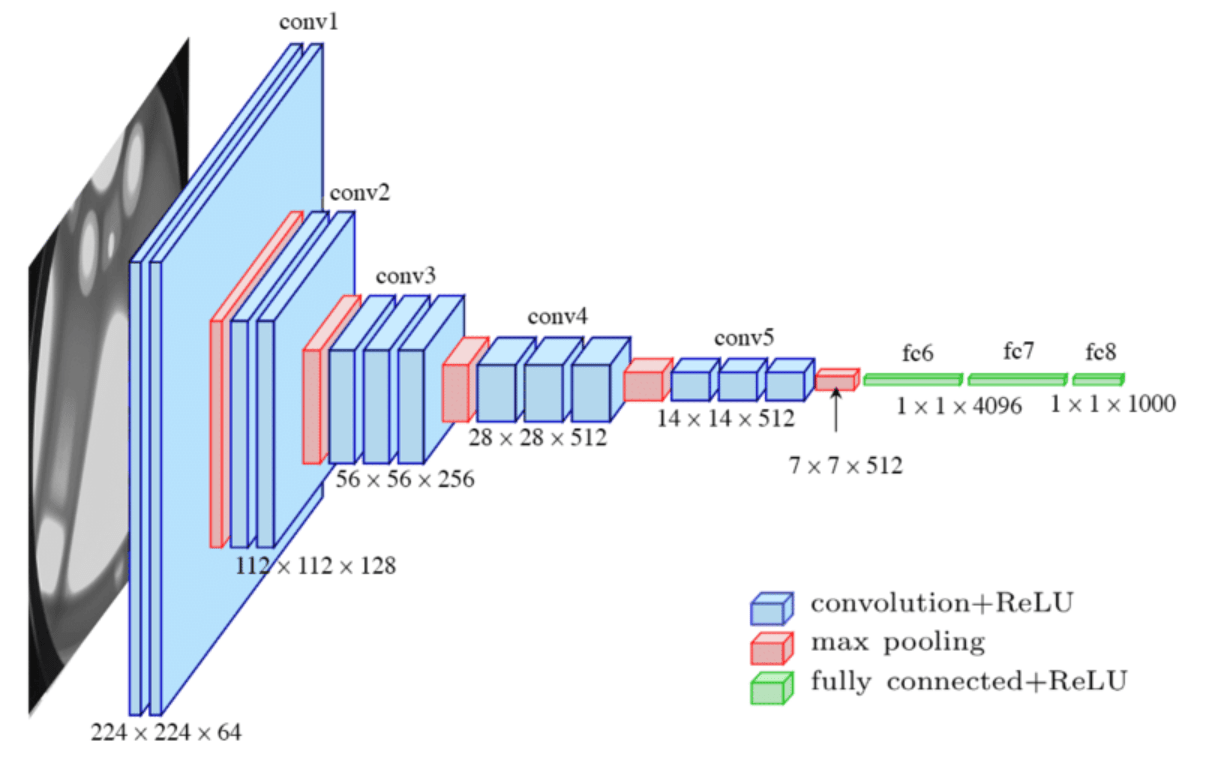
early layers learn simple generalized features (like lines for CNN)
original data
Remember the "Deep Dream" demo and assignment
early layers learn simple generalized features (like lines for CNN)
prediction "head"
original data
late layers learn complex aggregate specialized features
Remember the "Deep Dream" demo and assignment
early layers learn simple generalized features (like lines for CNN)
prediction "head"
original data
late layers learn complex aggregate specialized features
Remember the "Deep Dream" demo and assignment
Retrain (late layers and) head
Replace input
prediction "head"
- Start with the weights as trained on the original dataset
- Train for a few epochs (sometimes as few as 10!)
The issue of vanishing gradient persists, but in this case it's helpful as it means we are mostly training the specialized layers at the end of the NN structure
- Makes large models accessible even if each training epoch is expensive by limiting the number of training epochs needed
- All rules of training need to be respected, including checking loss, adjusting learning rate, batch size (appropriately to the new dataset) etc
late layers learn complex aggregate specialized features
Remember the "Deep Dream" demo and assignment
Replace input
early layers learn simple generalized features (like lines for CNN)
prediction "head"
late layers learn complex aggregate specialized features
Remember the "Deep Dream" demo and assignment
"Freeze" early layers
Replace input
prediction "head"
late layers learn complex aggregate specialized features
Remember the "Deep Dream" demo and assignment
"Freeze" early layers
Retrain (late layers and) head
Replace input
prediction "head"
Can also modify the prediction head to change the scope of the NN (e.g. from classification to regression)
layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
layer.trainable = False # Freeze the layer
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))
layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
layer.trainable = False # Freeze the layer
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = Falseparameter.requires_grad = False(some models are really only available in pytorch ATM)
layer.trainable = False
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.transforms import Resize
from PIL import Image
import torch
import torch.nn.functional as F
import os
import cv2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
.....
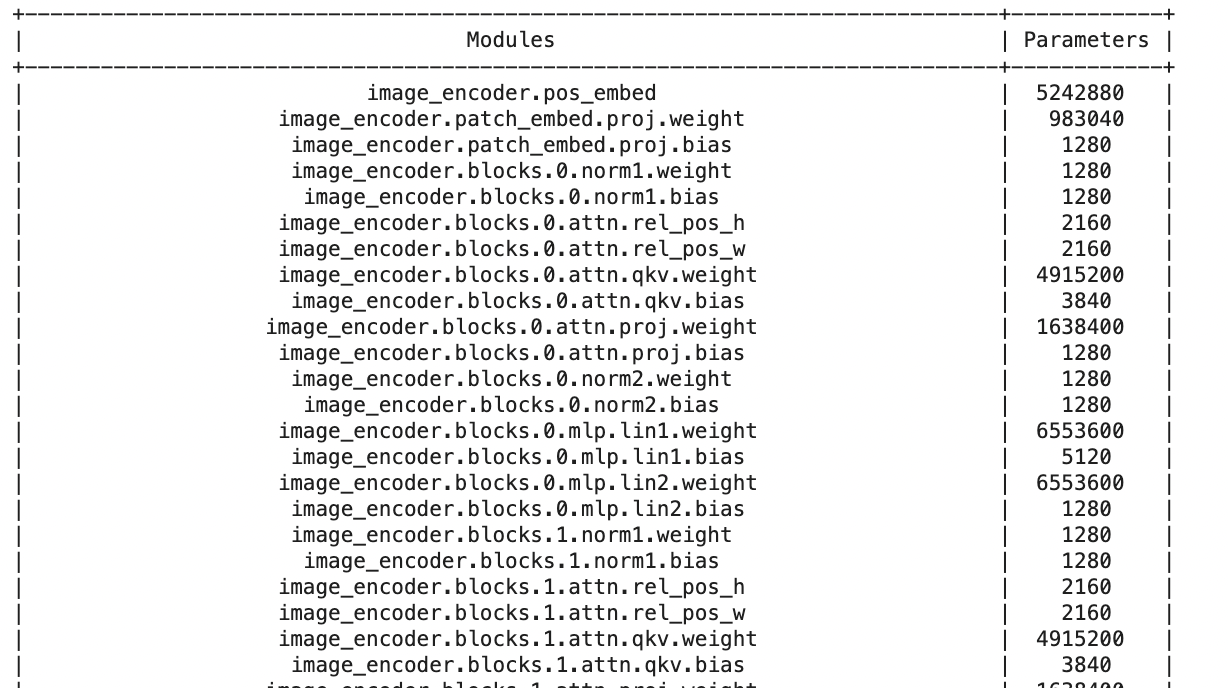
from prettytable import PrettyTable
def count_parameters(model):
table = PrettyTable(['Modules', 'Parameters'])
total_params = 0
for name, parameter in model.named_parameters():
if not parameter.requires_grad: continue
params = parameter.numel()
table.add_row([name, params])
total_params+=params
print(table)
print(f'Total Trainable Params: {total_params}')
return total_paramsloading a saved model
prints the number of parameters for every layer
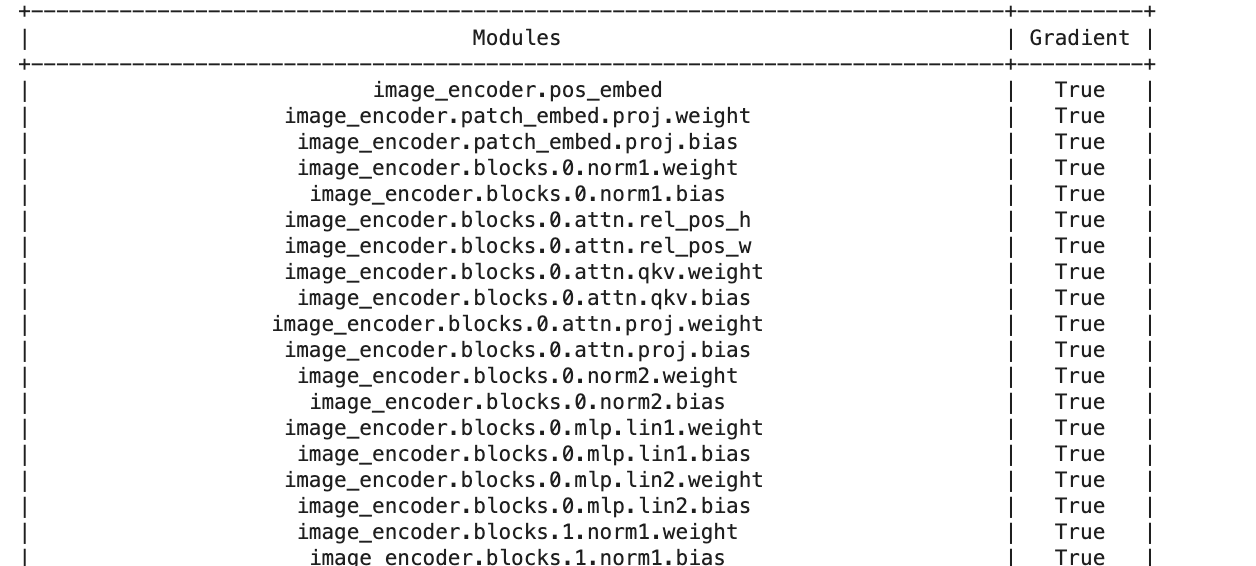
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
checks if "gradient=true" i.e. if weights are trainable
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
def freeze_layer(model, layernameroot):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = False
table.add_row([name, parameter.requires_grad])
if parameter.requires_grad:
trainable +=1
print(table)
return trainable
ntrainable = freeze_layer(sam, 'mask_decoder.iou_prediction_head')
torch.save(model.state_dict(), f"samLE_funfrozen{ntrainable}.pth")checks if "gradient=true" i.e. if weights are trainable
sets gradient to false i.e. freezes the layer
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
def freeze_layer(model, layernameroot):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = False
table.add_row([name, parameter.requires_grad])
if parameter.requires_grad:
trainable +=1
print(table)
return trainable
ntrainable = freeze_layer(sam, 'mask_decoder.iou_prediction_head')
torch.save(model.state_dict(), f"samLE_funfrozen{ntrainable}.pth")sets gradient to false i.e. freezes the layer
... only the "head" is left to be trainable
By federica bianco
fine tuning



