principles of Urban Science 13
dr.federica bianco | fbb.space | fedhere | fedhere

fine tuning
this slide deck:
Transfer Learning
can you use it for another task?
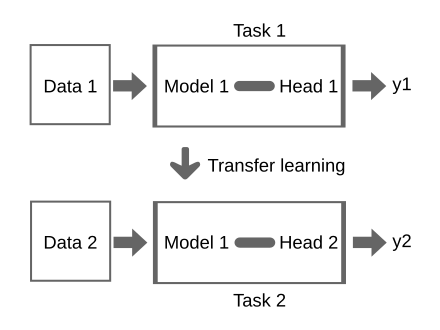
you have a model which was trained on some data
DOMAIN ADAPTATION: learning a model from a source data distribution and applying that model on a target data with a different distribution: the features are the same but have different distributions
e.g. Learn an energy model in one city (using building size, usage, occupancy) then apply it to a different city
?
Transfer Learning
does the model generalize to answer question on the new dataset with accuracy?
YES
NO
No need for additional learning: the model is transferable!
Fine Tune your model on the new data
you have a model which was trained on some data
Transfer Learning
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
Transfer Learning
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
Industry models like Chat-GPT or SAM are trained on huge amount of data we scientists could not afford to get!
Transfer Learning
What problems does it solve?
Small labelled dataset for supervised learning: use a model trained on a larger related dataset (and possibly fine tune with small amount of labels)
Limited computational resources because more are not available or to limit environmental impact of AI, as low level learning can be reused
knowledge learned from a task is re-used in order to boost performance on a related task.
you have a model which was trained on some data
And large companies like Open-AI, Facebook, Google have unmatched computational resources
Fine-tuning by retraining everything for few epochs (few 10)
Start with the saved trained model:
weights and biases are set in the pre-trained model by training on Data 1
restart training from those weights and biases and adjust weights by running only a few epochs
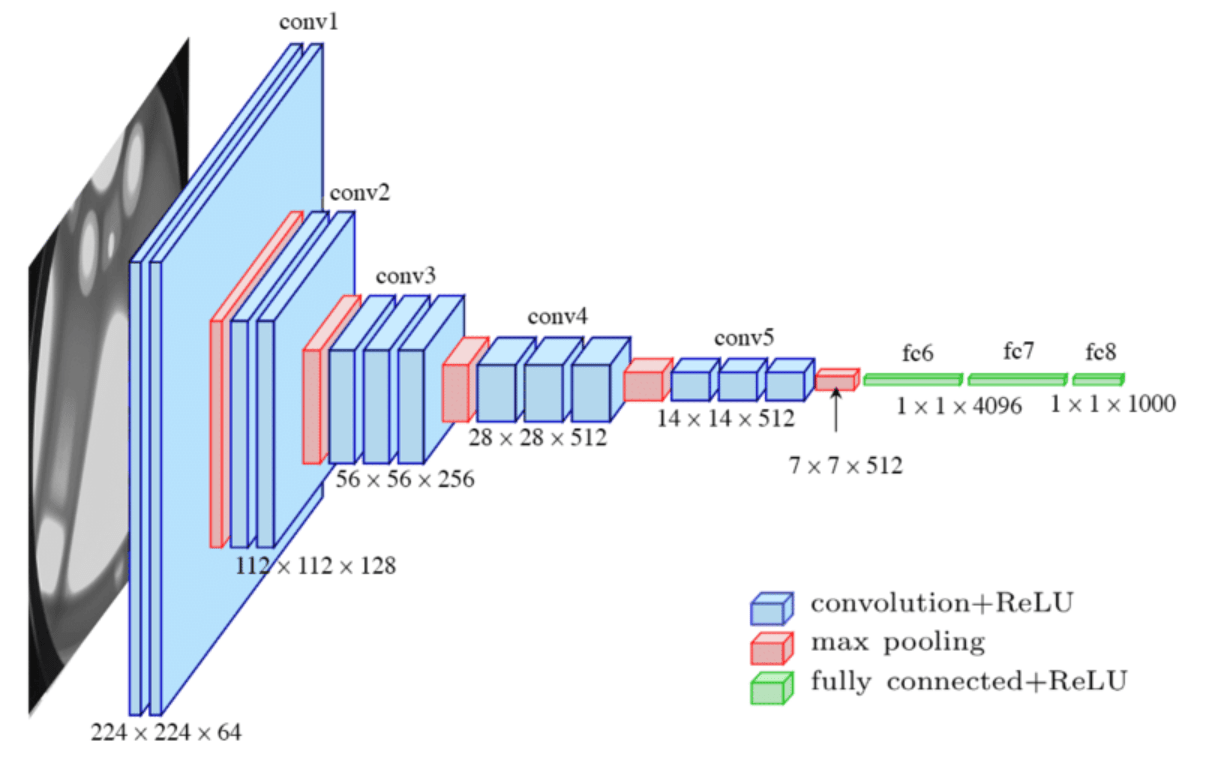
"Chop the head" fine tuning
prediction "head"
original data
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment
prediction "head"

early layers learn simple generalized features (like lines for CNN)
original data
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment

early layers learn simple generalized features (like lines for CNN)
prediction "head"
original data

late layers learn complex aggregate specialized features
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment
early layers learn simple generalized features (like lines for CNN)
prediction "head"
original data
late layers learn complex aggregate specialized features
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment

Replace input
early layers learn simple generalized features (like lines for CNN)
prediction "head"
late layers learn complex aggregate specialized features
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment
"Freeze" early layers
Replace input
prediction "head"
late layers learn complex aggregate specialized features
"Chop the head" fine tuning
Remember the "Deep Dream" demo and assignment
"Freeze" early layers
Retrain (late layers and) head
Replace input
prediction "head"
Fine-tuning how to:
layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))
layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
layer.trainable = False # Freeze the layer
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))
Fine-tuning how to:
layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))layer = keras.layers.Dense(3)
layer.build((None, 4)) # Create the weights
layer.trainable = False # Freeze the layer
print("weights:", len(layer.weights))
print("trainable_weights:", len(layer.trainable_weights))
print("non_trainable_weights:", len(layer.non_trainable_weights))
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = Falseparameter.requires_grad = False(some models are really only available in pytorch ATM)
layer.trainable = False


Fine-tuning SAM example:
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.transforms import Resize
from PIL import Image
import torch
import torch.nn.functional as F
import os
import cv2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h_4b8939.pth")
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
.....
from prettytable import PrettyTable
def count_parameters(model):
table = PrettyTable(['Modules', 'Parameters'])
total_params = 0
for name, parameter in model.named_parameters():
if not parameter.requires_grad: continue
params = parameter.numel()
table.add_row([name, params])
total_params+=params
print(table)
print(f'Total Trainable Params: {total_params}')
return total_paramsloading a saved model
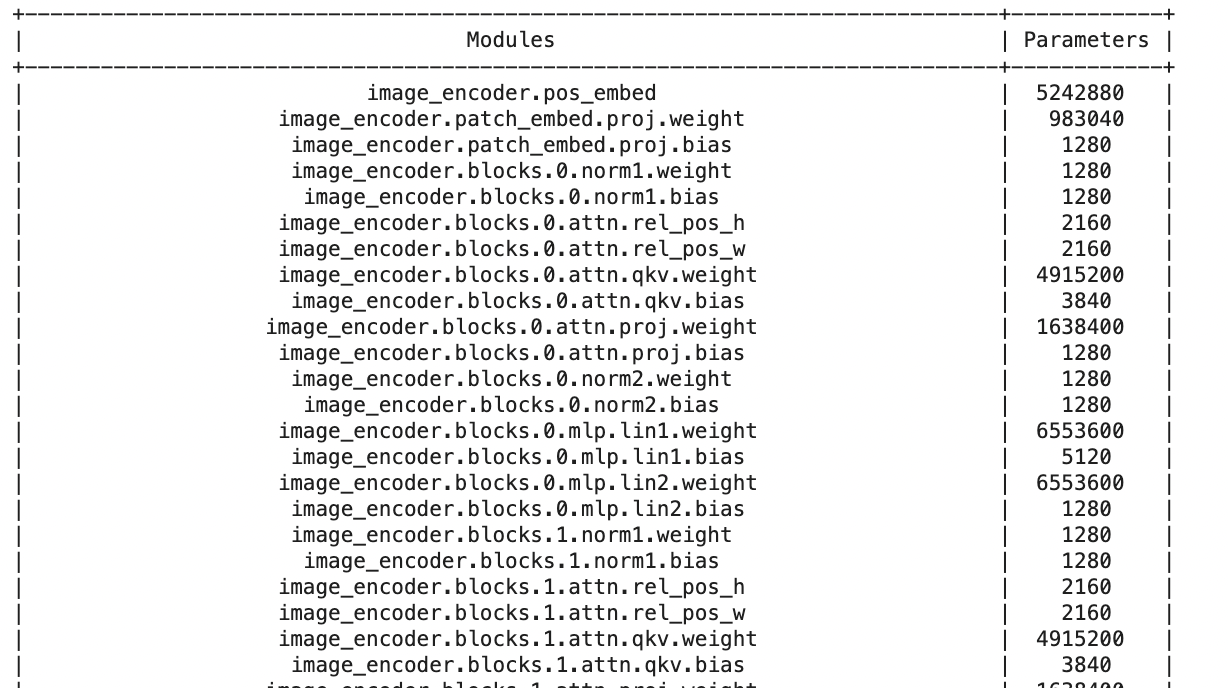
prints the number of parameters for every layer
Fine-tuning SAM example:
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
checks if "gradient=true" i.e. if weights are trainable
Fine-tuning SAM example:
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
def freeze_layer(model, layernameroot):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = False
table.add_row([name, parameter.requires_grad])
if parameter.requires_grad:
trainable +=1
print(table)
return trainable
ntrainable = freeze_layer(sam, 'mask_decoder.iou_prediction_head')
torch.save(model.state_dict(), f"samLE_funfrozen{ntrainable}.pth")checks if "gradient=true" i.e. if weights are trainable
sets gradient to false i.e. freezes the layer
Fine-tuning SAM example:
Fine-tuning SAM example:
from prettytable import PrettyTable
def count_trainablelayers(model):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
table.add_row([name, parameter.requires_grad])
trainable +=1
print(table)
return trainable
count_trainablelayers(sam) # this gives 596!!
def freeze_layer(model, layernameroot):
trainable = 0
table = PrettyTable(['Modules', 'Gradient'])
for name, parameter in model.named_parameters():
if not name.startswith(layernameroot):
#print("here", name)
parameter.requires_grad = False
table.add_row([name, parameter.requires_grad])
if parameter.requires_grad:
trainable +=1
print(table)
return trainable
ntrainable = freeze_layer(sam, 'mask_decoder.iou_prediction_head')
torch.save(model.state_dict(), f"samLE_funfrozen{ntrainable}.pth")sets gradient to false i.e. freezes the layer


... only the "head" is left to be trainable