Ops
TALKS
Knowledge worth sharing
#03
Florian Dambrine - Principal Engineer - @GumGum
K8s & ECS

Agenda
What DOES it DO
***
Basics
***
DEEP dive
***
CHEATSHEET
What does it do
/ K8s / ECS /
K8s / ECS


Kubernetes is a portable, extensible, open-source platform for managing containerized workloads and services
ECS is a fully managed container orchestration service
- Service discovery and load balancing
- Storage orchestration
- Automated rollouts and rollbacks
- Self-healing
- Secret and configuration management
- Integrated with AWS services
- Easy to pick up
k8s / ecs
- Entry level to container world
- Ease of use from GUI
- ecs-cli and aws-cli as a way to interact with the cluster
- API Driven - Kubernetes is first and foremost a REST API
- Restricted access to K8s control plane on AWS
- kubectl as a way to interact with the cluster
k8s / ecs - why switching over
- Local environment available in multiple flavors to build complex dev eco-system or just test locally (no local ECS dev)
- More reactive than ECS
- Can plug directly into Prometheus for scaling
- Better deployment orchestration (no downtime)
- Much more features than ECS
- Configmaps (Configuration dropped inside a volume to be used by the container)
- Init containers
- Ingress containers (Creation of ELBs from K8s)
- Volumes and EFS (mount per pod, not at the EC2 level)
Basics
MAIN CONCEPTS/ Basic Navigation
- Main concepts -
cluster
service / deployment
pods / tasks
volumes / autoscaling

Main concepts - ECS Vs K8s - Terms
| Cluster | Cluster |
| Service & Task definition | Deployment |
| Task | Pod |
| Volume | PersistentVolume |
Service
Tasks
Task definition
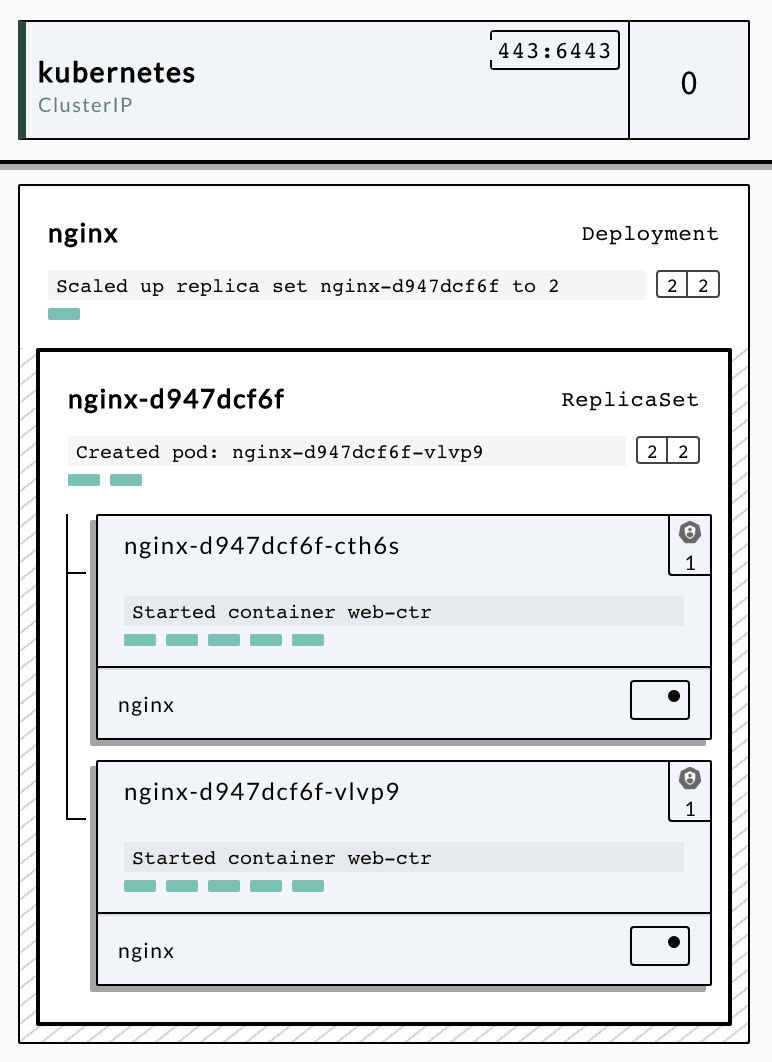
Basic navigation - AuthenticatioN
### Requirements:
### * Install aws-cli
aws ecs list-clusters
{
"clusterArns": [
"arn:aws:ecs:us-east-1:123456789910:cluster/va-mle--prod",
"arn:aws:ecs:us-east-1:123456789910:cluster/va-mle-inference--prod",
...
]
}
### Requirements:
### * Install Kubectl EKS Vendored (mac version)
### * Install aws-cli >= 1.16.156 (replacement of aws-iam-authenticator)
### Update `~/.kube/config` with EKS cluster config and alias it as `k8s-mle`
aws eks update-kubeconfig --name va-verity-prod-eks --alias verity-prod
### Set your client to connect to verity-prod in namespace monitoring
kubectl config set-context verity-prod --namespace=monitoring \
&& kubectl config
### List nodes running in the cluster
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-201-116-76.ec2.internal Ready <none> 16h v1.17.9-eks-4c6976
ip-10-201-24-166.ec2.internal Ready <none> 22m v1.17.9-eks-4c6976
ip-10-201-41-15.ec2.internal Ready <none> 13h v1.17.9-eks-4c6976BASIC NAVIGATION - Select CLUSTER
### List services running in the cluster va-mle--prod
aws ecs list-clusters
{
"clusterArns": [
"arn:aws:ecs:us-east-1:123456789910:cluster/va-mle--prod",
"arn:aws:ecs:us-east-1:123456789910:cluster/va-mle-inference--prod",
...
]
}### Set your client to connect to verity-prod in namespace default
kubectl config set-context verity-prod --namespace=default \
&& kubectl config use-context verity-prod
/// OR ///
## Switch to cluster verity-prod namespace default
kubectx verity-prod
kubens default
### List pods running in the cluster namespace
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-10-201-116-76.ec2.internal Ready <none> 16h v1.17.9-eks-4c6976
ip-10-201-24-166.ec2.internal Ready <none> 22m v1.17.9-eks-4c6976
ip-10-201-41-15.ec2.internal Ready <none> 13h v1.17.9-eks-4c6976BASIC NAVIGATION - View services / deployments
### List services running in the cluster va-mle--prod
aws ecs list-services --cluster va-mle--prod
{
"serviceArns": [
"arn:aws:ecs:us-east-1:12345678910:service/video-transcribe__prod",
...
]
}## List all running deployments in the cluster
kubectl get deployments --all-namespaces
NAME READY UP-TO-DATE AVAILABLE AGE
ai-kafka-lag-reporting--production-burrow 1/1 1 1 23d
ai-kafka-lag-reporting--production-karrot 1/1 1 1 23d
ai-kafka-lag-reporting--staging-burrow 1/1 1 1 16d
ai-kafka-lag-reporting--staging-karrot 1/1 1 1 16d
kafka-manager--production 1/1 1 1 23d
...BASIC NAVIGATION - View PODs / tasks
### List services running in the cluster va-mle--prod
aws ecs list-tasks --cluster va-mle--prod
{
"taskArns": [
"arn:aws:ecs:us-east-1:12345678910:task/va-mle--prod/08e6004b550c4adc8d760e6ef8618482",
...
]
}## List all running pods in the cluster
kubectl get pods --all-namespaces
NAME READY STATUS RESTARTS AGE
ai-kafka-lag-reporting--production-burrow-695d887765-6g2mz 1/1 Running 0 59m
ai-kafka-lag-reporting--production-karrot-769748dcd9-wl7bc 1/1 Running 0 59m
ai-kafka-lag-reporting--staging-burrow-75f69ff888-k5hcq 1/1 Running 0 59m
ai-kafka-lag-reporting--staging-karrot-6b9d66d985-hhr7w 1/1 Running 0 59m
kafka-manager--production-6dcb578fc-bnfpb 1/1 Running 0 59m
prometheus-mle--production-alertmanager-6f57c4684b-dw9xs 2/2 Running 0 14h
prometheus-mle--production-kube-state-metrics-6c88687bd8-jkmfc 1/1 Running 0 59m
prometheus-mle--production-pushgateway-5b9dbd7f94-s9rb2 1/1 Running 0 59m
prometheus-mle--production-server-688cb4bf47-bdrw2 2/2 Running 0 59m
prometheus-nlp--production-alertmanager-cb88575cb-58xxf 2/2 Running 0 59m
prometheus-nlp--production-kube-state-metrics-5fb889bbc8-qnkzp 1/1 Running 0 59m
prometheus-nlp--production-pushgateway-64f76bfc48-rv2qb 1/1 Running 0 59m
prometheus-nlp--production-server-7565ffb9b9-rk6bn 2/2 Running 0 16h
prometheus-verity--production-alertmanager-6794ddd944-8chvf 2/2 Running 0 59m
BASIC NAVIGATION - INSPECT SERVICE SPECS
### Inspect task specs from cluster va-mle--prod
aws ecs describe-tasks --cluster va-mle--prod --task-arn arn:aws:ecs:us-east-1:12345678910:task/va-mle--prod/08e6004b550c4adc8d760e6ef8618482
{
"tasks": [
{
"attachments": [],
"availabilityZone": "us-east-1e",
"clusterArn": "arn:aws:ecs:us-east-1:12345678910:cluster/va-mle--prod",
"connectivity": "CONNECTED",
"connectivityAt": 1603390576.188,
"containerInstanceArn": "arn:aws:ecs:us-east-1:12345678910:container-instance/va-mle--prod/8e5d58e75ce5423a91550ff7731ad373",
"containers": [
{
"containerArn": "arn:aws:ecs:us-east-1:12345678910:container/d72d8b0d-fd0f-43ab-8cbb-394a092f9cc1",
"taskArn": "arn:aws:ecs:us-east-1:12345678910:task/va-mle--prod/08e6004b550c4adc8d760e6ef8618482",
"name": "prism-api",
"image": "12345678910.dkr.ecr.us-east-1.amazonaws.com/gumgum/machine-learning-engineering/prism-api:0.9.3",
"imageDigest": "sha256:ad8d6a83347f83c862cfcae638bafa4cf0cd6fd53ae646b5a6c0be875ec2b3dd",
"runtimeId": "88ba0668d15aac5186f3a88ba68f802f952aa4641192661589fdba8b5e972a0b",
"lastStatus": "RUNNING",
"networkBindings": [
{
"bindIP": "0.0.0.0",
"containerPort": 8080,
"hostPort": 32774,
"protocol": "tcp"
},
{
"bindIP": "0.0.0.0",
"containerPort": 9090,
"hostPort": 32773,
"protocol": "tcp"
}
],
"networkInterfaces": [],
"healthStatus": "UNKNOWN",
"cpu": "1536",
"memory": "3584"
}
],
"cpu": "1536",
"createdAt": 1603390576.188,
"desiredStatus": "RUNNING",
"group": "service:prism-api__advertising-prod",
"healthStatus": "UNKNOWN",
"lastStatus": "RUNNING",
"launchType": "EC2",
"memory": "3584",
"overrides": {
"containerOverrides": [
{
"name": "prism-api"
}
],
"inferenceAcceleratorOverrides": []
},
"pullStartedAt": 1603390576.564,
"pullStoppedAt": 1603390577.564,
"startedAt": 1603390577.564,
"startedBy": "ecs-svc/3925212241363435971",
"tags": [],
"taskArn": "arn:aws:ecs:us-east-1:12345678910:task/va-mle--prod/08e6004b550c4adc8d760e6ef8618482",
"taskDefinitionArn": "arn:aws:ecs:us-east-1:12345678910:task-definition/prism-api__advertising-prod:11",
"version": 2
}
],
"failures": []
}## Inspect pod spec
kubectl describe pod ai-kafka-lag-reporting--production-burrow-695d887765-6g2mz
Name: ai-kafka-lag-reporting--production-burrow-695d887765-6g2mz
Namespace: monitoring
Priority: 0
Node: ip-10-201-41-15.ec2.internal/10.201.41.15
Start Time: Fri, 23 Oct 2020 06:18:23 -0700
Labels: app.kubernetes.io/instance=ai-kafka-lag-reporting--production
app.kubernetes.io/name=burrow
pod-template-hash=695d887765
Annotations: checksum/config: 76685e6b14d969203808ad9b123ce98882855ce11558a90291622c008cbb65f1
checksum/templates: 2f6e14d9dc3289a56da3ee67666dff22aa865cbac57762a4efde12fd200a4437
kubernetes.io/psp: eks.privileged
Status: Running
IP: 10.201.38.236
IPs:
IP: 10.201.38.236
Controlled By: ReplicaSet/ai-kafka-lag-reporting--production-burrow-695d887765
Containers:
burrow:
Container ID: docker://e4107e28b35f093f3f48ab2f80f0895971d325507cd499c0dba7dc636a3ba1f4
Image: ifoodhub/burrow:1.3.3
Image ID: docker-pullable://ifoodhub/burrow@sha256:ed9b8629983eddf496fc953fbe053db78370db594bd3cf1541c38c03c8b7b5b1
Port: 8000/TCP
Host Port: 0/TCP
State: Running
Started: Fri, 23 Oct 2020 06:18:27 -0700
Ready: True
Restart Count: 0
Liveness: http-get http://:http/burrow/admin delay=0s timeout=1s period=10s #success=1 #failure=3
Readiness: http-get http://:http/burrow/admin delay=0s timeout=1s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/etc/burrow from config (rw)
/etc/burrow/templates from templates (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-btxjt (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: ai-kafka-lag-reporting--production-burrow
Optional: false
templates:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: ai-kafka-lag-reporting--production-burrow-templates
Optional: false
default-token-btxjt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-btxjt
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events: <none>BASIC NAVIGATION - Check logs
### Inspect logs of a container from cluster va-mle--prod
# ¯\_(ツ)_/¯
ssh ubuntu@<instance>
docker ps
docker logs -f <container-id>
{"level":"warn","ts":1603459219.4788227,"msg":"unknown consumer","type":"module","coordinator":"storage","class":"inmemory","name":"default","worker":2,"cluster":"va-verity-kafka","consumer":"KMOffsetCache-kafka-manager--production-6dcb578fc-bnfpb","topic":"","partition":0,"topic_partition_count":0,"offset":0,"timestamp":0,"owner":"","client_id":"","request":"StorageFetchConsumer"}
{"level":"info","ts":1603459219.478872,"msg":"cluster or consumer not found","type":"module","coordinator":"evaluator","class":"caching","name":"default","cluster":"va-verity-kafka","consumer":"KMOffsetCache-kafka-manager--production-6dcb578fc-bnfpb","showall":false}## Check pod logs
# ❤
kubectl logs -f ai-kafka-lag-reporting--production-burrow-695d887765-6g2mz
{"level":"warn","ts":1603459219.4788227,"msg":"unknown consumer","type":"module","coordinator":"storage","class":"inmemory","name":"default","worker":2,"cluster":"va-verity-kafka","consumer":"KMOffsetCache-kafka-manager--production-6dcb578fc-bnfpb","topic":"","partition":0,"topic_partition_count":0,"offset":0,"timestamp":0,"owner":"","client_id":"","request":"StorageFetchConsumer"}
{"level":"info","ts":1603459219.478872,"msg":"cluster or consumer not found","type":"module","coordinator":"evaluator","class":"caching","name":"default","cluster":"va-verity-kafka","consumer":"KMOffsetCache-kafka-manager--production-6dcb578fc-bnfpb","showall":false}Deep-Dive
Tooling / helm / helmfile / Gitops
Deep dive - General tooling



~ Training / Development ~
HelmFILE is a wrapper on top of helm
Helmfile is what Terragrunt is to Terraform
Helm is a package manager for Kubernetes
Helm is your new ecs-cli
Kubernetes UIs - Blog Post 04/05/2020 by

Deep dive - Helm - Introduction
Helm is a package manager for Kubernetes
Helm is your new ecs-cli...
- A chart is a collection of files that describe a related set of Kubernetes resources.
- A chart is made of Go templates
- A single chart might be used to deploy something simple, like a memcached pod, or something complex, like a full web app stack with HTTP servers, databases, caches, and so on.
### Requirements:
### * Install helm > v3.0
helm create ops-talks
Creating ops-talks
# Tree of the created chart
ops-talks
├── Chart.yaml
├── charts
├── templates
│ ├── NOTES.txt
│ ├── _helpers.tpl
│ ├── deployment.yaml
│ ├── hpa.yaml
│ ├── ingress.yaml
│ ├── service.yaml
│ ├── serviceaccount.yaml
│ └── tests
│ └── test-connection.yaml
└── values.yaml
3 directories, 10 filesWhat is a CHART ?

Deep dive - Helm - Open source Charts



$ helm install confluentinc/cp-helm-charts
$ helm install jenkins/jenkins

-
https://github.com/jenkinsci/helm-charts
-
https://github.com/confluentinc/cp-helm
-
https://github.com/helm/charts/
-
https://github.com/Lowess/helm-charts
$ helm install stable/atlantis
$ helm install stable/atlantis
Deep dive - Helm - TemplAte Hydrating
stable/atlantis
$ helm install stable/atlantis
- configmap-config.yaml
- configmap-repo-config.yaml
- extra-manifests.yaml
- ingress.yaml
- secret-aws.yaml
- secret-gitconfig.yaml
- secret-service-account.yaml
- secret-webhook.yaml
- service.yaml
- serviceaccount.yaml
- statefulset.yaml
values.yaml

Deep dive - Helm - Values Overrides
stable/atlantis
$ helm install stable/atlantis
values.yaml (default)
# Replace this with your own repo whitelist:
orgWhitelist: bitbucket.org/gumgum/*
logLevel: "debug"
myvalues.yaml (overrides)
myvalues.yaml
merge
Deep dive - HELMfile
HELMFILE IS A WRAPPER ON TOP OF HELM
Helmfile is what Terragrunt is to Terraform...
Why ?
-
Helm is a great tool for templating and sharing K8s manifests... However it can become quite cumbersome to install larger multi-tier applications or groups of applications across multiple Kubernetes clusters.
-
Give each Helm chart its own helmfile.yaml and include them recursively in a centralized helmfile.yaml.
-
Separate out environment specific values from general values. Often you’ll find while a Helm chart can take 50 different values, only a few actually differ between your environments.
-
As well as providing a set of values, either Environment specific or otherwise, you can also read Environment Variables, Execute scripts and read their output (Fetch a secret from AWS SSM)
-
Store remote state in git/s3/fileshare/etc in much the same way as Terraform does.
Deep dive - HELMfile - Layout
bases:
- ../../environments.yaml
---
repositories:
# Use Lowess (Florian Dambrine) OSS helm chart repo
- name: lowess-helm
url: https://lowess.github.io/helm-charts
templates:
default: &default
chart: "lowess-helm/karrot"
missingFileHandler: Error
namespace: "monitoring"
labels: {}
version: "0.1.3"
wait: true
installed: {{ and (env "KAFKA_LAG_REPORTING_INSTALLED" | default "true") }}
releases:
- name: "ai-kafka-lag-reporting--{{ .Environment.Name }}"
<<: *default
values:
- "./values/{{`{{ .Release.Name }}`}}.yaml"
helmfile.yaml
environments.yaml
releases
├── kafka-lag-reporting
│ ├── README.md
│ ├── helmfile.yaml
│ └── values
│ ├── ai-kafka-lag-reporting--production.yaml
│ ├── ai-kafka-lag-reporting--staging.yaml
│ └── kafka-lag-reporting--production.yaml
├── kafka-manager
│ ├── helmfile.yaml
│ └── values
│ └── kafka-manager--production.yaml
├── prometheus
│ ├── helmfile.yaml
│ └── values
│ ├── prometheus-mle--production.yaml
│ ├── prometheus-nlp--production.yaml
│ └── prometheus-verity--production.yaml
└── zoonavigator
├── helmfile.yaml
└── values
└── verity-zoonavigator--production.yaml
Deep dive - Gitops
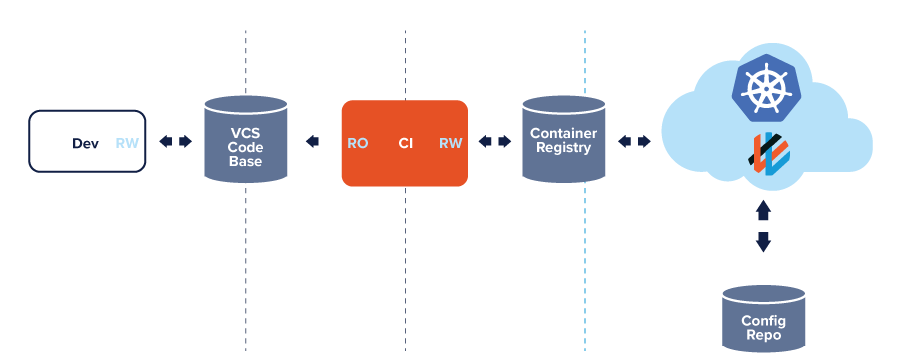
Principles of GitOpS
-
#1 The entire system described declaratively
-
#2 The canonical desired system state versioned in Git
-
#3 Approved changes that can be automatically applied to the system
-
#4 Software agents to ensure correctness and alert on divergence.
CHEATSHEET
Ops
TALKS
Knowledge worth sharing
By Florian