Ops
TALKS
Knowledge worth sharing
#05
Florian Dambrine - Principal Engineer - @GumGum
KAFKA

Agenda
What DOES it DO
***
Basics
***
DEEP dive
***
CHEATSHEET
What does it do
Kafka Vs Traditional databases

THINGS First
EVENT First
- Indication in time that something took place
A Log is a sequence of events
Event
- Apache Kafka is a system for managing these logs
- A log in Kafka historical term is named a topic
Basics
/ Terminology /
KAfka terminology - Topic
Topic
Kafka Log
Event
KAfka terminology - Partitions
Partition 2
Event
Topic
Partition 1
Partition 3
Partition 4
| Workload | Partition Sizing |
|---|---|
| Common | 8 - 16 |
| Big topics | 120 - 200 |
| YOU'RE WRONG ! | > 200 |
-
DO NOT go above
- 4000 partitions / Broker
- 200K partitions / Cluster
Partitioning
- Rule of Thumb -
KAfka terminology - Replication
Partition 2
Event
Topic
Partition 1
Partition 3
Partition 4
REPLICAS
KAfka terminology - brokers
Kafka Broker
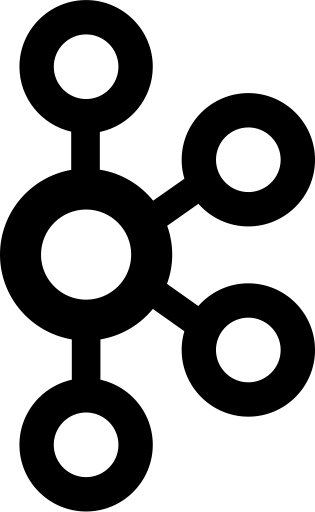
4 Nodes Kafka Cluster
Partitions are units of scalability because it allows client applications to both read and write the data from/to many brokers at the same time
KAfka terminology - Partition Leadership
L
F
L
L
F
F
L
F
L = Leader
F = Follower
Data will be ingested or served by Brokers that leads a given partition
KAfka Ecosystem - HA & ROBUST recovery
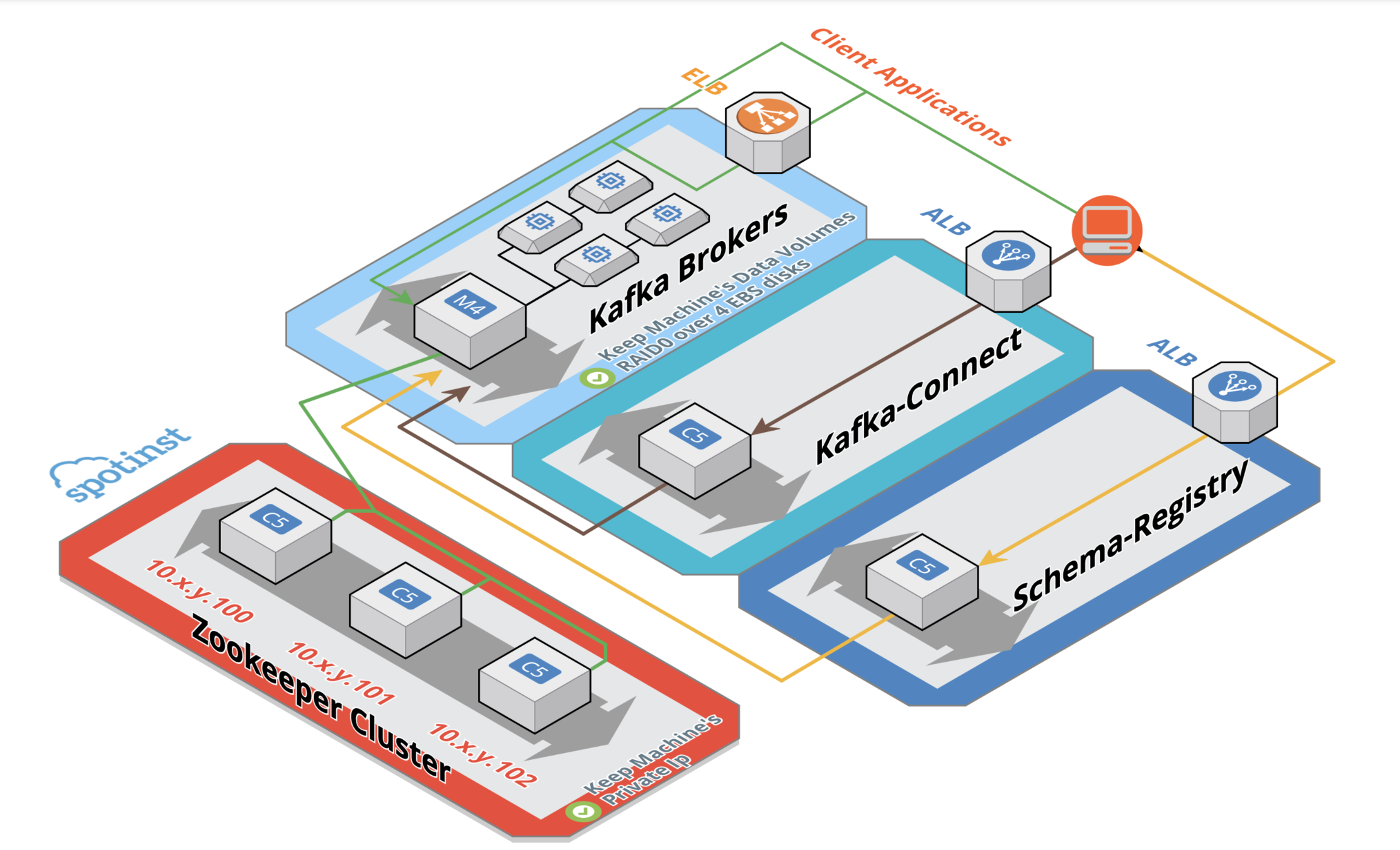
- ZK Private IP persistence
- Disk persistence on instance replacement
- ELB for single entry point
- Automatic broker.id assignment
KAfka client cluster access

once connected
1st connection
{
"bootstrap.servers": "<ELB>"
<other settings>
}["broker1", "broker2", ...]
["broker1", "broker2", ...]
Kafka Zookeeper - what's in therE ?



KAfka RCAs learnings
# Replication is key
A couple of RCAs were actually caused by topics with misconfigured replication factor leading to data loss
- Leader lost
- RF=2 and 2 Brokers down
# Observability for better reactivity
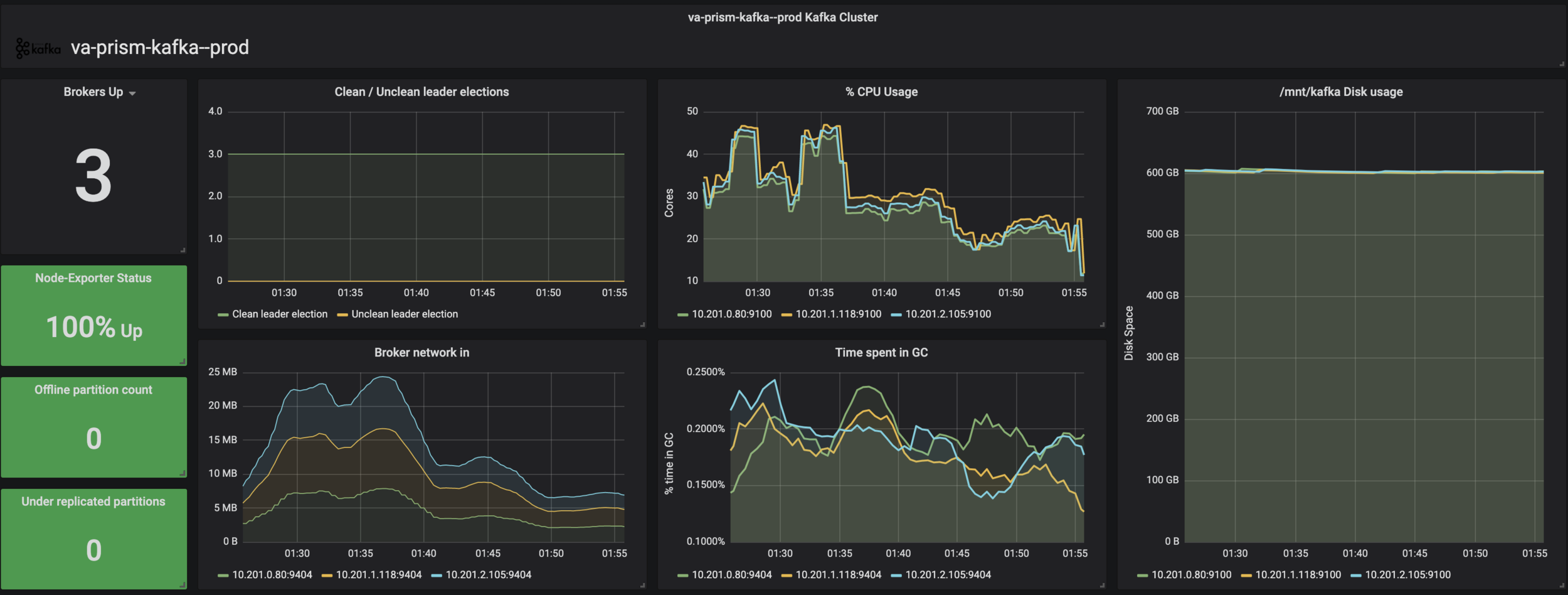
Deep-Dive
/ KAFKA Listeners /
/ Producer Anatomy / Consumer Anatomy /
/ Autocommit pitfalls /
kafka Listeners
You need to set advertised.listeners (or KAFKA_ADVERTISED_LISTENERS if you’re using Docker images) to the external address (host/IP) so that clients can correctly connect to it. Otherwise, they’ll try to connect to the internal host address—and if that’s not reachable, then problems ensue.
TL;DR
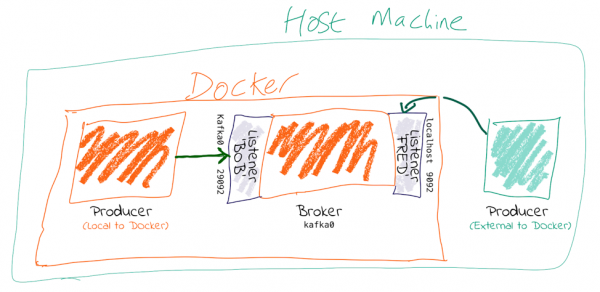
kafka Listeners
KAFKA_LISTENERS
KAFKA_ADVERTISED_LISTENERS
0.0.0.0:9092
PLAINTEXT
0.0.0.0:29092
PLAINTEXT_DOCKER
kafka:9092
host.docker.internal:29092
0.0.0.0:29093
PLAINTEXT_NGROK
4.tcp.ngrok.io:18028
PLAINTEXT
PLAINTEXT_DOCKER
PLAINTEXT_NGROK
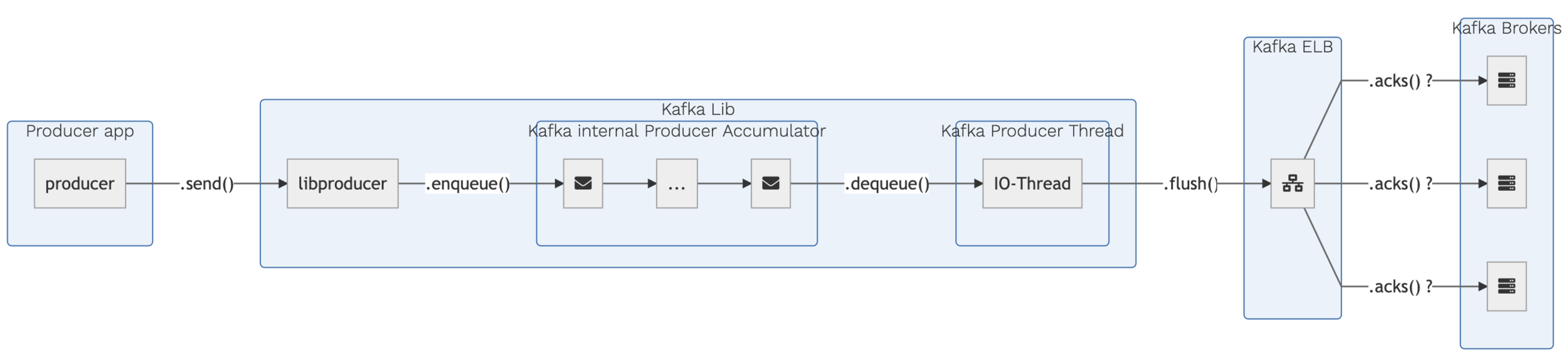
kafka Producer anatomy
produce( )
ack ?
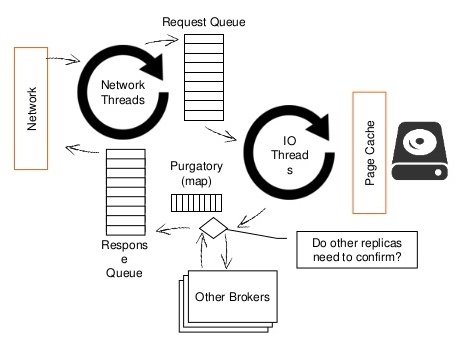
kafka consumer anatomy
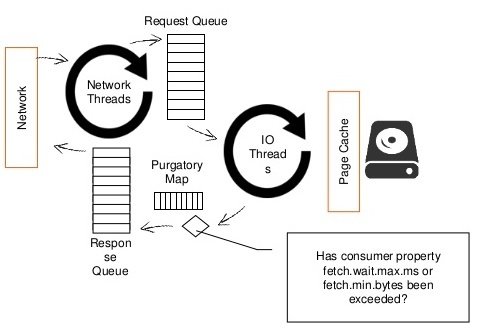
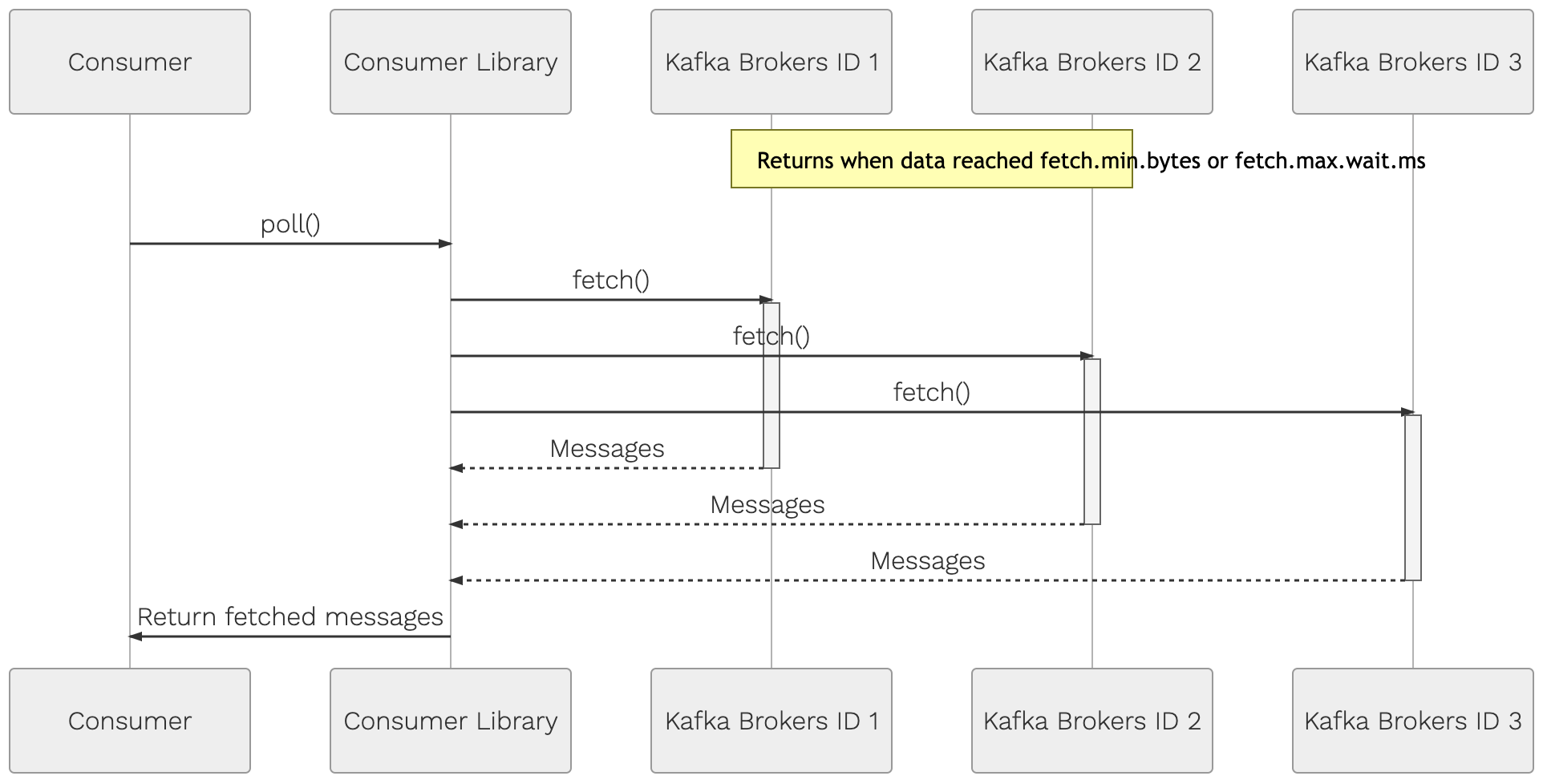
consume()
commit || auto commit - that is the question...
P1
P2
P3
Consumer group
Consumer 1
Consumer 2
0
1
2
3
4
5
6
7
8
Last Committed
Offset
Current
Position
High
Watermark
Log
End Offset
autocommit enabled
P1
P2
P3
Consumer group
Consumer 2
Consumer 1
from confluent_kafka import Consumer
consumer = Consumer({
"enable.auto.commit": True
})
while True:
messages = consumer.poll()
try:
process(messages) # heavy
except Exception as e:
logger.exception("Failed processing messages")autocommit disabled
P1
P2
P3
Consumer group
Consumer 2
Consumer 1
from confluent_kafka import Consumer
consumer = Consumer({
"enable.auto.commit": False
})
while True:
messages = consumer.poll()
try:
process(messages) # TODO Need to handle message
# committing once processed
except Exception as e:
logger.exception("Failed processing messages")Consumer group lifecycle
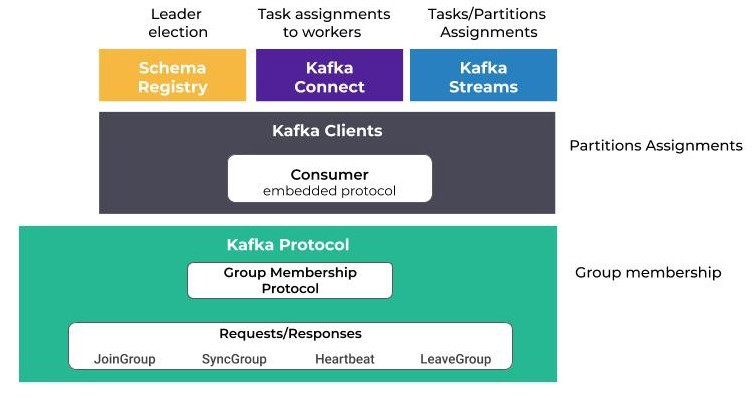
Rebalance/Rebalancing: the procedure that is followed by a number of distributed processes that use Kafka clients and/or the Kafka coordinator to form a common group and distribute a set of resources among the members of the group.
Examples:
- Confluent Schema Registry relies on rebalancing to elect a leader node.
- Kafka Connect uses it to distribute tasks and connectors among the workers.
- Kafka Streams uses it to assign tasks and partitions to the application streams instances.
MUST READ !
CHEATSHEET
kafka cli tips & tricks


alias kaf="docker run --entrypoint="" -v ~/.kaf:/root/.kaf -it lowess/kaf bash"kafka cli tips & tricks
# Consume the content <TOPIC> and copy it to a file
kaf consume <TOPIC> --offset latest 2>/dev/null | tee /tmp/kafka-stream.log# Consume the content <TOPIC> and generate reformat payload to keep url and uuid only
kaf consume <TOPIC> 2>/dev/null | jq '. | {"url": .url, "uuid": .uuid}'# Send each line from <FILE> as individual records to <TOPIC>
cat <FILE> | while read line; do echo $line | kaf produce <TOPIC>; donekafka cli tips & tricks

alias kafka-cli="docker run --rm --entrypoint="" -it confluentinc/cp-kafka bash"
Ops
TALKS
Knowledge worth sharing
By Florian