Working with Bytes
Binary Serialization & Elm

Core Idea
Sacrifice readability for compactness and speed
Bytes 101
- A bit is a 0 or 1
- A byte is 8 consecutive bits e.g. 01101100
Conversion between decimal and binary
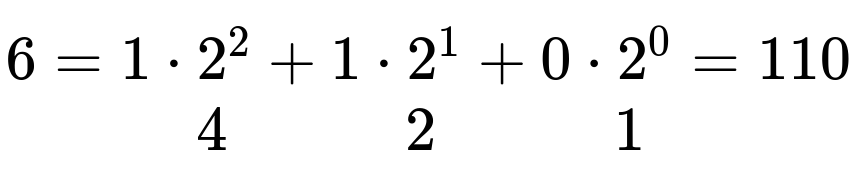
Bytes 101
| JSON | "2019" | 4 bytes |
| bytes | 0000 0111 1110 0011 | 2 bytes |
Bytes are more compact
And faster to decode
| JSON | "2019" | parse 4 digits; arithmetic |
| bytes | 0000 0111 1110 0011 | just put it in memory |
API Overview
decodeVec3 : Decoder Vec3
decodeVec3 =
Decode.succeed vec3
|> andMap (Decode.float32 LE)
|> andMap (Decode.float32 LE)
|> andMap (Decode.float32 LE)
API Overview
type Bytes
Encode.unsignedInt8 : Int -> Encoder
Encode.string : String -> Encoder
Decode.unsignedInt8 : Decoder Int
Decode.string : Int -> Decoder String
Decode.decode : Bytes -> Decoder a -> Maybe aCompaction by
extracting structure
{
"title": "foo",
"subject": "spam"
}
Compaction by
extracting structure
3 f o o 4 s p a m
03 666f6f 04 7370616d| Field | # of bytes | type |
|---|---|---|
| titleLength | 1 | uint8 |
| title | variable | string |
| subjectLength | 1 | uint8 |
| subject | variable | string |
An API Response
type alias Item =
{ title : String
, link : String
, media : String
, dateTaken : Int
, description : String
, published : Int
, author : String
, authorId : String
, tags : List String
}Compaction by
extracting structure
| raw bytes | zipped bytes | |
|---|---|---|
| JSON | 864 | 437 |
| Bytes | 732 | 363 |
| 15% less | 17% less |
But, decoding is slower
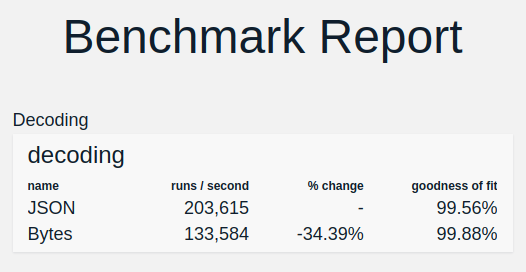
List of 100 floats
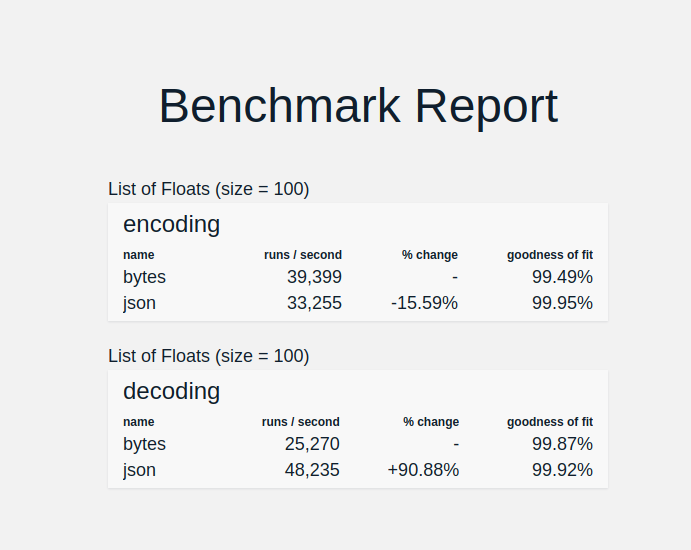
List of 1000 floats
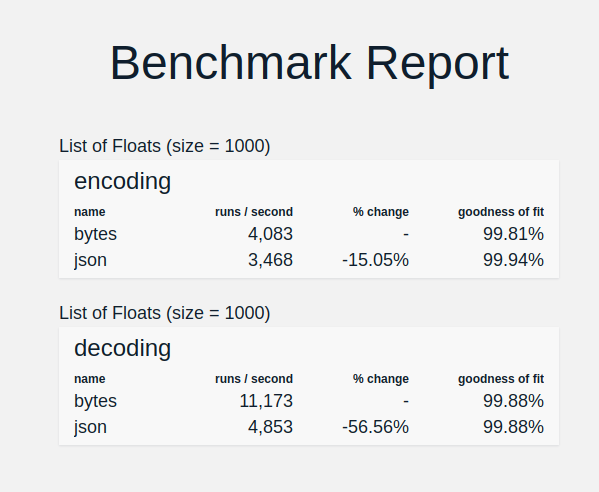
Results
Compaction and speed depend heavily on the specific data
consider the maintenance cost of binary serialization
schema technologies (like protobuf) still run into these issues
Case 2: Base64
data:text/plain;base64,SGVsbG8sIFdvcmxkIQ%3D%3DA binary-to-text conversion method
used for
- inlining small files in stylesheets
- creating images in elm
Case 2: Base64
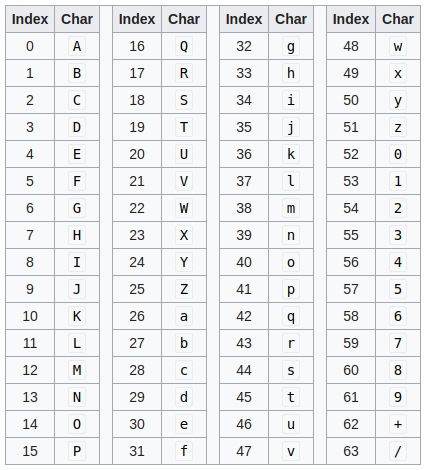
Compaction through cleverness
6 bits are enough to store 64 distinct characters
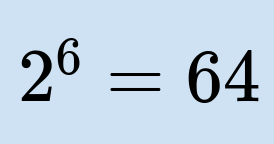
Compaction through cleverness
but we can only write/read whole bytes (8 bits)
we will not waste 2 bits per character!
Encode.unsignedInt8 : Int -> Encoder
Compaction through cleverness
solution: store 4 digits in 3 bytes
| E | 4 | 00 0100 |
| V | 21 | 01 0101 |
| A | 0 | 00 0000 |
| N | 13 | 00 1101 |
Compaction through cleverness
use bit shifts to line up
| E | 00000000 00000000 00000100 | |
| V | 00000000 00000101 01000000 | |
| A | 00000000 00000000 00000000 | |
| N | 00110100 00000000 00000000 |
then bitwise or to combine
| 00110100 00000101 01000100 |
Efficiency by Benchmark
You are responsible for performance
why I like bytes
learning while writing meaningful code
and you should too
- Bytes enable new things
- A nice way to learn some fundamental CS
- Lots of low-hanging fruit
Thank You
Folkert de Vries
@folkertdev