class Foo
def bar
puts "Foobar"
end
endPlease make sure you're sitting where you can read this slide

Learning language models with Ruby

Gavin Morrice
twitter: @morriceGavin
bsky: @morriceGavin
bodacious

We're hiring!

that man should not be expected in a few minutes,
and i was left drifting on a large and luxurious city called Paris,
surrounded by mountains of ice, which was to be the hellish triumph;
clapping my hands, and in the morning, however, lay scattered on the ground.
"the cat sat..."
"...on the mat"
"...on the hat"
"...on the rug"
🤖
📚
➡️
💬
🧮
🎲
What well cover today
- Training
- Context
- Tokenization
- Sampling
- Temperature
- Build a simple language model
- Discuss RNNs and LLMs
Part 1
Part 2
A simple example
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
tokens = DOCUMENT.split
token_counts = tokens.tally
# => { 'the' => 2, 'cat' => 1, => 'sat' => 1, 'on' => 1, 'mat' => 1}
total_token_count = token_counts.values.sum
probability_distribution = token_counts.transform_values do |count|
count / total_token_count.to_f
end
# => { "the" => 0.3333333333333333, "cat" => 0.16666666666666666, ... }
def generate_next_token(probability_distribution)
probability_distribution.max_by(&:last).first
end
sequence = []
DEFAULT_SEQUENCE_LENGTH.times do
sequence.push(generate_next_token(probability_distribution))
end
puts sequence.join(" ")"the the the the the the the the the the"...let's refactor
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
def initialize
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
Array.new(sequence_length) { generate_next_token }.join(" ")
end
protected
def generate_next_token
@probability_distribution.max_by(&:last).first
end
def calculate_probability_distribution
token_counts = DOCUMENT.split.tally
total_token_count = token_counts.values.sum
token_counts.transform_values do |count|
count / total_token_count.to_f
end
end
end
...let's refactor
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = Array.new(sequence_length) { generate_next_token }
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token
@probability_distribution.max_by(&:last).first
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
token_counts = tokens.tally
total_token_count = token_counts.values.sum
token_counts.transform_values do |count|
count / total_token_count.to_f
end
end
end
...let's refactor
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = Array.new(sequence_length) { generate_next_token }
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token
@probability_distribution.max_by(&:last).first
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
token_counts = NGramCounter.new(tokens: tokens).ngram_counts
total_token_count = token_counts.values.sum
token_counts.transform_values do |count|
count / total_token_count.to_f
end
end
end...let's refactor
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = Array.new(sequence_length) { generate_next_token }
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token
@probability_distribution.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
token_counts = NGramCounter.new(tokens: tokens).ngram_counts
ProbabilityDistribution.new(ngram_counts: token_counts).distribution
end
end"the the the the the the the the the the"the cat sat on the mat
50%
50%
the cat sat on the mat
100%
the cat sat on the mat
"the" => { "cat" => 50%, "mat" => 50% }
"cat" => { "sat" => 100% }
Bigram Example
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = Array.new(sequence_length) { generate_next_token }
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token
@probability_distribution.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
token_counts = NGramCounter.new(tokens: tokens).ngram_counts
ProbabilityDistribution.new(ngram_counts: token_counts).distribution
end
endBigram Example
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = ["the"]
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
Conditional probability
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = ["the"]
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
class ProbabilityDistribution
TokenProbability = Data.define(:token, :probability)
def initialize(ngram_counts: {})
@ngram_counts = ngram_counts
end
def distribution
return @distribution if defined?(@distribution)
total = @ngram_counts.values.sum
@distribution = @ngram_counts.map do |token, count|
TokenProbability[token, count / total.to_f]
end
end
end
Conditional probability
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = ["the"]
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
class ProbabilityDistribution
TokenProbability = Data.define(:token, :probability)
def initialize(ngram_counts: {})
@ngram_counts = ngram_counts
end
def [](context)
distribution.fetch(context, [])
end
def distribution
return @distribution if defined?(@distribution)
@distribution = @ngram_counts.to_h do |context, target_counts|
total = target_counts.values.sum
target_probabilities = target_counts.map do |token, count|
TokenProbability[token, count / total.to_f]
end
[context, target_probabilities]
end
end
end
Conditional probability
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = ["the"]
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
# BEFORE
#
token: "the", probability: 0.3333333333333333,
token:"cat", probability: 0.16666666666666666,
token:"sat", probability: 0.16666666666666666,
...
# AFTER
#
"the"
token:"cat", probability: 0.5
token:"mat", probability: 0.5
"cat"
token:"sat", probability: 1.0
"sat"
token:"on", probability: 1.0
...Bigram Example
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
"the cat sat on the cat sat on the cat sat"the cat sat on the
cat
mat
"the cat sat on the cat sat on the cat sat"the cat sat on the
cat
mat
Trigram Example
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the cat")
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last(N - 1))
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
Trigram example
class LanguageModel
DOCUMENT = "the cat sat on the mat"
DEFAULT_SEQUENCE_LENGTH = 10
N = 2
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = ["the"]
Array.new(sequence_length) do
next_token = generate_next_token(context: sequence.last)
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(DOCUMENT)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
# BEFORE
#
"the"
token:"cat", probability: 0.5
token:"mat", probability: 0.5
"cat"
token:"sat", probability: 1.0
"sat"
token:"on", probability: 1.0
...
# After
#
["the", "cat"]
token:"sat", probability: 1.0
["cat", "sat"]
token:"on", probability: 1.0
["sat", "on"]
token:"the", probability: 1.0
..."the cat sat on the mat '' '' '' ''"the cat sat on the mat
???
END
BOS the cat sat on the mat EOS
"the cat sat on the mat '' '' '' ''"BOS/EOS Example
class LanguageModel
DOCUMENT = "BOS the cat sat on the mat EOS"
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("BOS the")
until sequence.length >= sequence_length
break if sequence.last == "EOS"
next_token = generate_next_token(context: sequence.last(N - 1))
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return "EOS" if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
document = DOCUMENT
tokens = @tokenizer.tokenize(document)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end"the cat sat on the mat"BOS/EOS Example
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")[0..-2]
until sequence.length >= sequence_length
break if sequence.last == Tokenizer::EOS
next_token = generate_next_token(context: sequence.last(N - 1))
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return Tokenizer::EOS if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endBOS/EOS Example
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")[0..-2]
until sequence.last == Tokenizer::EOS
break if sequence.length >= sequence_length
next_token = generate_next_token(context: sequence.last(N - 1))
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return Tokenizer::EOS if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endclass Tokenizer
BOS = "BOS"
EOS = "EOS"
def tokenize(*samples)
samples.flat_map do |sample|
"#{bos_token} #{sample.to_s.downcase} #{eos_token}".split
end
end
def bos_token = BOS
def eos_token = EOS
def detokenize(tokens)
tokens.delete(bos_token)
tokens.delete(eos_token)
tokens.join(" ")
end
endBOS/EOS Example
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")[0..-2]
until sequence.last == Tokenizer::EOS
break if sequence.length >= sequence_length
next_token = generate_next_token(context: sequence.last(N - 1))
sequence << next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return Tokenizer::EOS if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endclass Document
attr_reader :samples
def initialize
@samples = [
"The cat sat on the mat"
]
end
endTokenisation
Breaking text down into numbers to represent words and sub-word units
the cat sat on the mat
279
279
5634
389
7731
8415
polymorphic
41969
1631
10097
Tokenisation
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endTokenisation
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize("the")[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endclass Tokenizer
require "pycall/import"
include PyCall::Import
BOS = "!!!"
EOS = " ``"
def initialize(encoding: "cl100k_base")
pyimport :tiktoken
@encoder = tiktoken.get_encoding(encoding)
end
def bos_token = @encoder.encode(BOS).first
def eos_token = @encoder.encode(EOS).first
def tokenize(*samples)
text = samples.map { |s| "#{BOS} #{s.downcase.strip}#{EOS}" }.join
Array(@encoder.encode(text))
end
def detokenize(tokens)
tokens.delete(bos_token)
tokens.delete(eos_token)
@encoder.decode(tokens)
end
end"the cat sat on the mat""where did the dog sit?"Input prompt
Input prompt
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end$ "the cat"
# => "the cat sat on the mat"
$ "sat on"
# => "sat on the mat"
$ "i want to"
# => "i want to"Training data
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endTraining data
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endclass Document
IGNORED_PUNCTUATION_REGEXP = /(\[|\]"|“|”|’|\r?\n)/
WORD_REGEX = /
(?:
[[:alnum:]]+
(?:['-][[:alnum:]]+)*
)
|
(?:[.!])
|
(?:[,;])
|
(?:\s+)
/x
attr_reader :samples
def initialize(name = "simple_text")
@samples = File.readlines("documents/#{name}.txt").lazy.map do |line|
line.gsub!(IGNORED_PUNCTUATION_REGEXP, "")
line.strip!
line.scan(WORD_REGEX).join
end.reject(&:empty?)
end
endTraining data
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = 10
N = 3
def initialize
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.length >= sequence_length
break if sequence.last == @tokenizer.eos_token
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
candidates.max_by(&:probability).token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*Document.new('frankenstein_text').samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end$ "in my pain, I felt"
# => "in my pain, i felt the greatest attention"
$ "i want to walk"
# => "i want to walk in fear and agitation."Sampling
Applying a degree of randomness when choosing the next token, instead of always picking the most likely one.
Sampling
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = (ARGV[1] || 10).to_i
N = 3
def initialize
@document = Document.new("frankenstein_text")
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.last == @tokenizer.eos_token
break if sequence.length >= sequence_length
next_token = generate_next_token(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def generate_next_token(context:)
candidates = @probability_distribution[context]
return @tokenizer.eos_token if Array(candidates).empty?
total = candidates.sum(&:probability)
pick = rand * total
cumulative = 0.0
candidates.each do |tp|
cumulative += tp.probability
return tp.token if cumulative >= pick
end
candidates.last.token
end
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*@document.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
endSampling
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = (ARGV[1] || 10).to_i
N = 3
def initialize
@document = Document.new("frankenstein_text")
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
@next_token_generator = NextTokenGenerator.new(
probability_distribution: @probability_distribution,
eos_token: @tokenizer.eos_token,
n: N
)
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.last == @tokenizer.eos_token
break if sequence.length >= sequence_length
next_token = @next_token_generator.generate(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*@document.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
Sampling
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = (ARGV[1] || 10).to_i
N = 3
def initialize
@document = Document.new("frankenstein_text")
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
@next_token_generator = NextTokenGenerator.new(
probability_distribution: @probability_distribution,
eos_token: @tokenizer.eos_token,
n: N
)
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.last == @tokenizer.eos_token
break if sequence.length >= sequence_length
next_token = @next_token_generator.generate(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*@document.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
class NextTokenGenerator
def initialize(probability_distribution:, eos_token:, n:)
@probability_distribution = probability_distribution
@eos_token = eos_token
@n = n
end
def generate(context:)
candidates = @probability_distribution[context]
return @eos_token if Array(candidates).empty?
pick = rand
cumulative = 0.0
candidates.each do |c|
cumulative += c.probability
return c.token if pick <= cumulative
end
candidates.last.token
end
endWeighted random sampling
Randomly selecting, based on the assigned probability of each item
Temperature scaling
Adjusting the probability weights to be more or less pronounced
Temperature scaling
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = (ARGV[1] || 10).to_i
TEMPERATURE = (ARGV[2] || 1.0).to_f
N = 3
def initialize(temperature: TEMPERATURE)
@document = Document.new("frankenstein_text")
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
@next_token_generator = NextTokenGenerator.new(
probability_distribution: @probability_distribution,
eos_token: @tokenizer.eos_token,
temperature: temperature,
n: N
)
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.last == @tokenizer.eos_token
break if sequence.length >= sequence_length
next_token = @next_token_generator.generate(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*@document.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
Temperature scaling
class LanguageModel
DEFAULT_SEQUENCE_LENGTH = (ARGV[1] || 10).to_i
TEMPERATURE = (ARGV[2] || 1.0).to_f
N = 3
def initialize(temperature: TEMPERATURE)
@document = Document.new("frankenstein_text")
@tokenizer = Tokenizer.new
@probability_distribution = calculate_probability_distribution
@next_token_generator = NextTokenGenerator.new(
probability_distribution: @probability_distribution,
eos_token: @tokenizer.eos_token,
temperature: temperature,
n: N
)
end
def generate(prompt: ARGV[0], sequence_length: DEFAULT_SEQUENCE_LENGTH)
sequence = @tokenizer.tokenize(prompt)[0..-2]
until sequence.last == @tokenizer.eos_token
break if sequence.length >= sequence_length
next_token = @next_token_generator.generate(context: sequence.last(N - 1))
sequence.push next_token
end
@tokenizer.detokenize(sequence)
end
protected
def calculate_probability_distribution
tokens = @tokenizer.tokenize(*@document.samples)
counts = NGramCounter.new(tokens: tokens, n: N).ngram_counts
ProbabilityDistribution.new(ngram_counts: counts).distribution
end
end
class NextTokenGenerator
def initialize(probability_distribution:, eos_token:, temperature:, n:)
raise ArgumentError, "temperature must be > 0" unless temperature.positive?
@probability_distribution = probability_distribution
@eos_token = eos_token
@temperature = temperature
@n = n
end
def generate(context:)
candidates = @probability_distribution[context]
return @eos_token if Array(candidates).empty?
scaled = candidates.to_h do |c|
scaled_value = Math.exp(Math.log(c.probability) / @temperature)
[c.token, scaled_value]
end
total = scaled.values.sum
normalized = scaled.transform_values { |v| v / total }
pick = rand
cumulative = 0.0
normalized.each do |token, prob|
cumulative += prob
return token if pick <= cumulative
end
candidates.last.token
end
endToken B
Token A
25%
75%
1.0
Token B
Token A
1%
99%
0.5
Token B
Token A
33.6%
63.3%
2
$ "and as I walked" (high temp)
# => "and as i walked on, while, with"
$ "and as I walked" (low temp)
# => "and as i walked up and down the passages"
"the cat sat on"
The cat sat on the coffin of henry
"the cat sat on"
The cat sat on the point of rest; we are enemies
"I pray that one day"
i pray that one day, but i was, indeed, i was unable to solve these questions continually recurred to the house of mourning, and the well, and i was a little uneasy that they would be disgusted, until i had been the favourite dream of pleasure
Recap
- We can use existing text to build a statistical model of how words relate
- By giving the model some context, it can be taught to predict what the next word should be
- Words or subwords are converted into numerical tokens for faster computation
- Special tokens (like BOS and EOS) are used to provide the model with more information
- Sampling introduces randomness so each generated sequence can differ
- Temperature adjusts the randomness, so output is more or less creative
"the cat sat on the mat"Recurrent Neural Networks
279
8415
7731
389
5634
the
cat
sat
on
mat
| d1 | d2 | d3 | d4 | ... |
|---|---|---|---|---|
| 0.04 | -0.25 | 0.24 | 0.831 | ... |
| 0.98 | 0.7 | -0.85 | 0.4 | ... |
| 0.24 | -0.124 | -0.3 | 0.341 | ... |
| -0.45 | 0.2 | 0.12 | 0.91 | ... |
| -0.56 | 0.45 | 0.24 | 0.831 | ... |
279
8415
7731
389
5634
the
cat
sat
on
mat
Embedding matrix
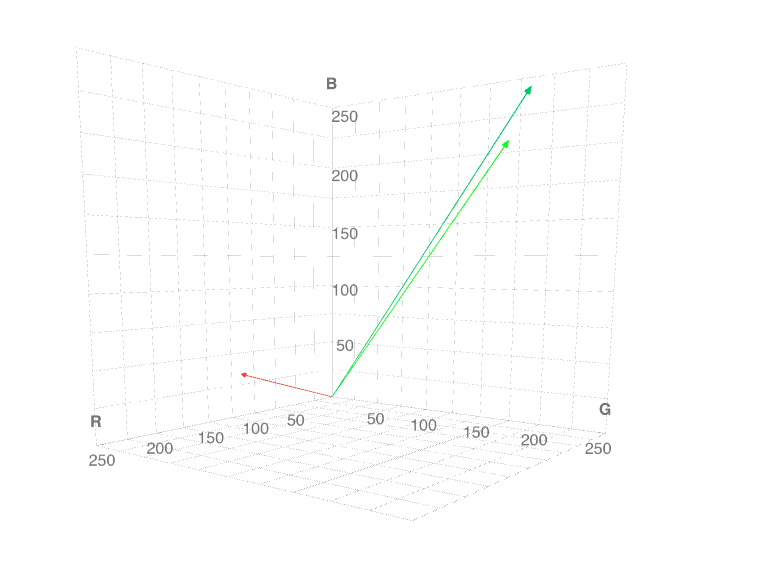
rgb(133, 250, 220)
rgb(107, 224, 196)
rgb(122, 5, 35)
| d1 | d2 | d3 | d4 | ... |
|---|---|---|---|---|
| 0.04 | -0.25 | 0.24 | 0.831 | ... |
| 0.98 | 0.7 | -0.85 | 0.4 | ... |
| 0.24 | -0.124 | -0.3 | 0.341 | ... |
| -0.45 | 0.2 | 0.12 | 0.91 | ... |
| -0.56 | 0.45 | 0.24 | 0.831 | ... |
279
8415
7731
389
5634
the
cat
sat
on
mat
| d1 | d2 | d3 | d4 | ... |
|---|---|---|---|---|
| 0.04 | -0.25 | 0.24 | 0.831 | ... |
| 0.98 | 0.7 | -0.85 | 0.4 | ... |
| 0.24 | -0.124 | -0.3 | 0.341 | ... |
| -0.45 | 0.2 | 0.12 | 0.91 | ... |
| -0.56 | 0.45 | 0.24 | 0.831 | ... |
279
8415
7731
389
5634
the
cat
sat
on
mat
Embedding matrix
Token Vector
Hidden state
&
Embedding matrix
Output weight matrix
Embedding matrix
Output weight matrix
Token Vector
Hidden state
&
| 0.78 | -0.23 | 0.45 | 0.33 | -0.34 |
|---|
Hidden state
Token Vector
Hidden state
&
Embedding matrix
Output weight matrix
EMBEDDINGS = {
"A" => [0.1, 0.5, 0.9],
"B" => [0.3, 0.7, 0.2],
"C" => [0.9, 0.1, 0.4],
}
W_OUTPUT = [
[0.2, 0.5, 0.3],
[0.1, 0.4, 0.2],
[0.7, 0.6, 0.5],
]
hidden_state = [0.0, 0.0, 0.0]
sequence = ["A"]
100.times do
current_token = sequence.last
next_token = get_next_token(current_token, hidden_state)
sequence << next_token
break if next_token == EOS
end
puts sequence.join(' ')
| 0.78 | -0.23 | 0.45 | 0.33 | -0.34 |
|---|
Hidden state
"he watched as the cat sat on the mat"RNNs have limited context
Recap
- We can use matrices to transform and represent how tokens relate to each other in high-dimensional space.
- High-dimensional space enables deeper context than simple n-gram sequences
- During training, tokens with similar contexts are positioned closer together in the embedding space.
- We can "do maths" ✨ to use these vectors to produce probability scores for the next token.
LLMs, transformers, and self-attention

Attention!

Attention means processing the entire context at once to determine which tokens are most relevant to the current position.
The model then uses this relevance map to weight information from the context before generating probabilities for the next word.
Attention means processing the entire context at once to determine which tokens are most relevant to the current position.
The model then uses this relevance map to weight information from the context before generating probabilities for the next word.
What does attention mean?
Attention means processing the entire context at once to determine which tokens are most relevant to the current position.
The model then uses this relevance map to weight information from the context before generating probabilities for the next word.
What does attention mean?
Attention means processing the entire context at once to determine which tokens are most relevant to the current position.
The model then uses this relevance map to weight information from the context before generating probabilities for the next word.
What does attention mean?
Token
Query Vector
Key Vector
Value Vector
K
Q
V
the
cat
sat
on
the
mat
K
Q
V
K
K
K
K
K
V
V
V
V
V
x0.6
x0.2
x0.6
x0.7
x0.1
x0.4
x0.5
the
cat
sat
on
the
mat
K
Q
V
K
K
K
K
K
V
V
V
V
V
V
context vector
Attention head 2
Attention head 1
Attention head 3
Token probabilities
| the | 0.01 |
| cat | 0.93 |
| sat | 0.01 |
| on | 0.01 |
| mat | 0.04 |
current token "the"
tokens.each do |token_a|
value = Vector.zero(5) # 5 dimensions
query = get_query(token_a)
tokens.each do |token_b|
next if token_a == token_b
key = get_key(token_b)
value += get_value(token_b) * similarity(query, key)
end
end
Recap
- Attention allows the model to focus on all tokens in the context at once, weighting them by relevance
- Token embeddings are trained on billions of text samples
- By comparing queries and keys for each token, the model computes how important each token is to every other one in the context
- Multiple attention heads perform this process in parallel, each capturing different types of relationship
- The combined output is used to provide probabilities for the next token

Information is not knowledge.
Knowledge is not wisdom.
Wisdom is not truth.