引力波数据探索:编程与分析实战训练营
第 2 部分 基于 Python 的数据分析基础


主讲老师:王赫
2023/12/03
ICTP-AP, UCAS



数据分析实训之 Pandas
关于上一讲的学员反馈
# Response
- 授课主要面向的是国科大以引力波数据处理为主要研究方向的研究生和高年级本科生。
- 不管“包学包会”,但会尽可能弥补和完善听课体验和授课内容。





- (上次选做作业的问题)windows在搭载gpu的容器构建中碰到问题是nvidia的相关工具是仅在linux上搭载的,为此必须装wsl2,装完,整体搭载完之后碰到问题是是否需要在容器内再安装docker,(因为nvidia教程中包含docker命令)但是这有种双层嵌套的感觉,像是在wsl2中的container中的container
- 能否别一节课时间太长,因为课业压力确实很重,只能分段学习……
- Pandas 中的数据结构:Series 和 DataFrame
- DataFrame 的增删改查
- DataFrame 的组合与聚合&透视表
- 实例:GW Catalog 数据分析案例
- 实例:股票数据分析案例 (optional)
数据分析实训之 Pandas



# Pandas
Ndarray \(\rightarrow\) Series/DataFrame (Pandas)
- Pandas 是基于 Numpy 的强大的分析结构化数据的工具集
- Pandas 官方网址:https://pandas.pydata.org
- Pandas 官方中文文档:https://www.pypandas.cn
-
从 Numpy 的 Ndarray 到 Pandas 的 Series / DataFrame
-
(Numpy) 1-dimensional array \(\Leftrightarrow\) Series (Pandas)
-
(Numpy) 2-dimensional array \(\Leftrightarrow\) DataFrame (Pandas)
-


# Pandas
Series vs DataFrame
-
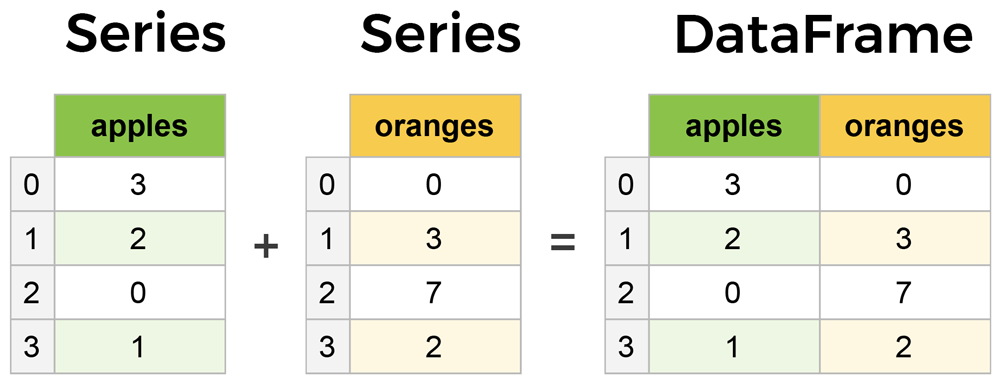
Series 是一种类似于一维数组的对象,是由一组数据 (各种 NumPy 数据类型) 以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的 Series 对象。
- DataFrame 是 Pandas 中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由 Series 组成的字典。
# Pandas
Excel vs DataFrame
-
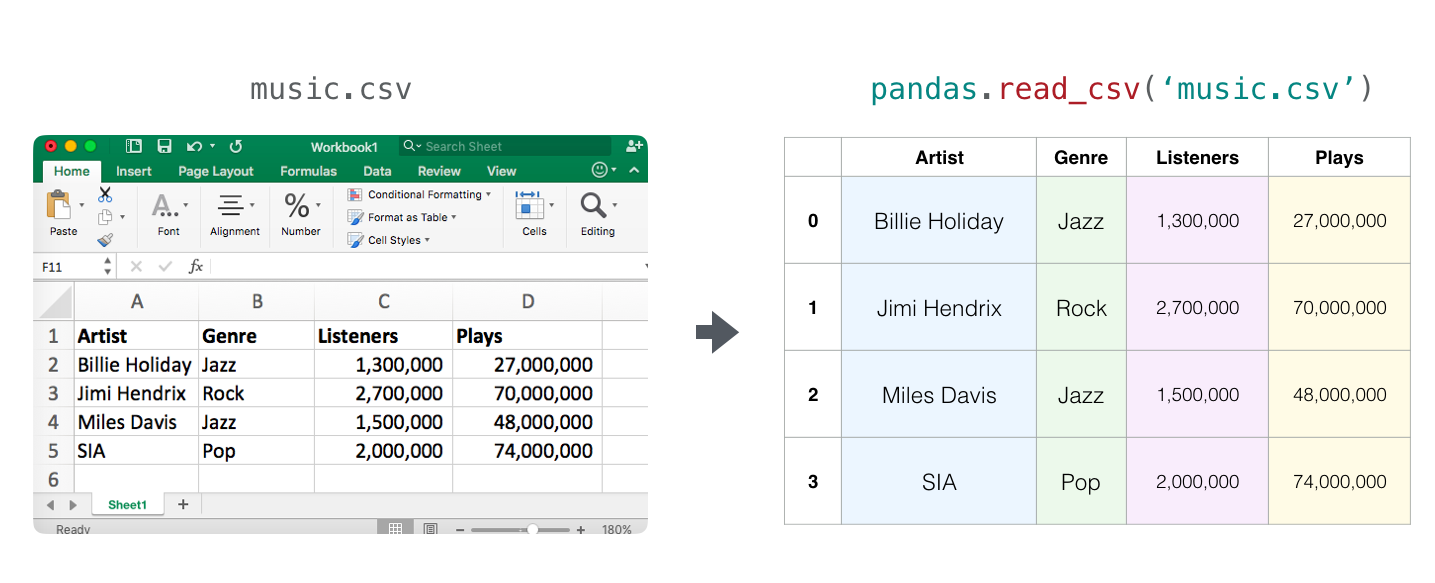
Series 是一种类似于一维数组的对象,是由一组数据 (各种 NumPy 数据类型) 以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的 Series 对象。
- DataFrame 是 Pandas 中的一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame 即有行索引也有列索引,可以被看做是由 Series 组成的字典。
# Pandas
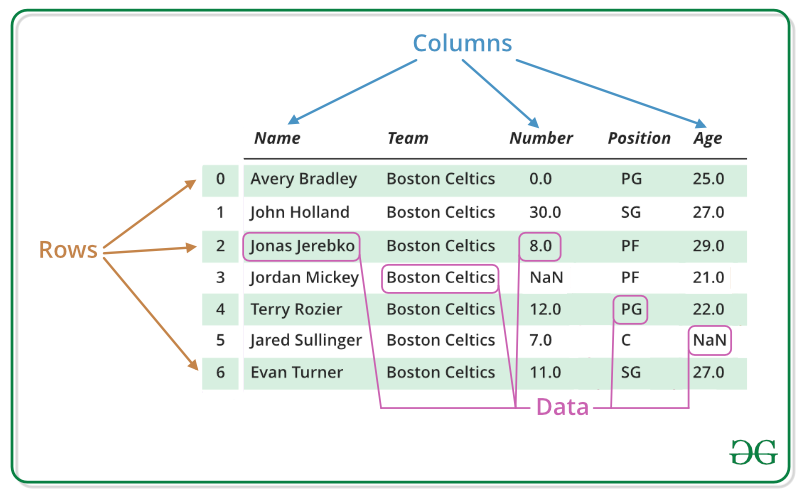
DataFrame 的“增删改查”
- DataFrame 构建与初始化:1. 按列构建 2. 按行构建

# Pandas
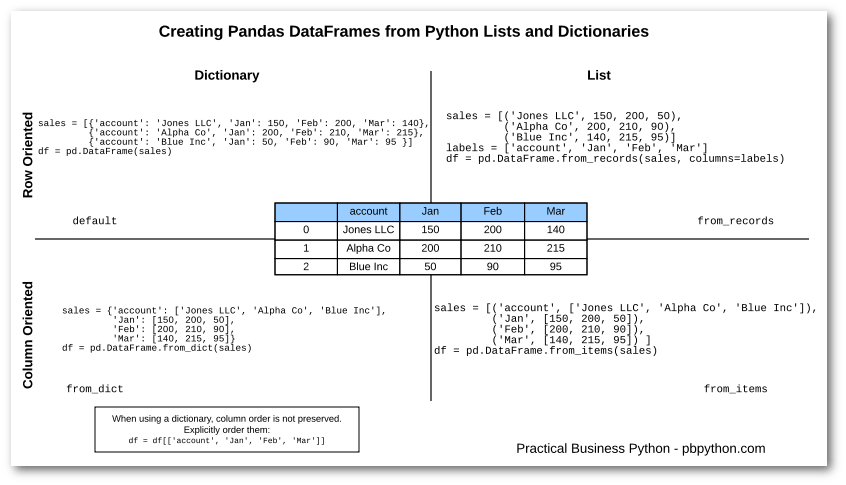
DataFrame 的“增删改查”
- DataFrame 的构建与初始化:1. 按列构建 2. 按行构建


# Pandas
DataFrame 的“增删改查”
- DataFrame 的索引与切片:

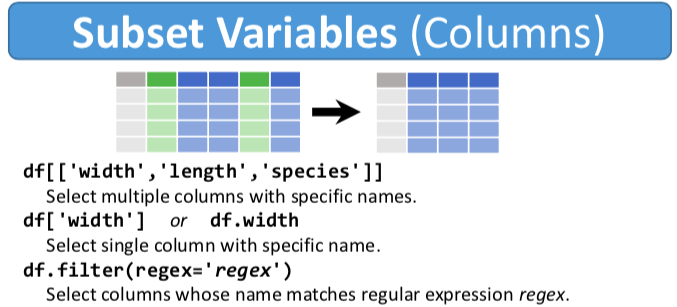

\(\Rightarrow\) Series
\(\Rightarrow\) DataFrame
Just like ndarray ...
df.drop(['length','species'], axis=1)# Pandas
DataFrame 的“增删改查”
- DataFrame 的改造与合并:
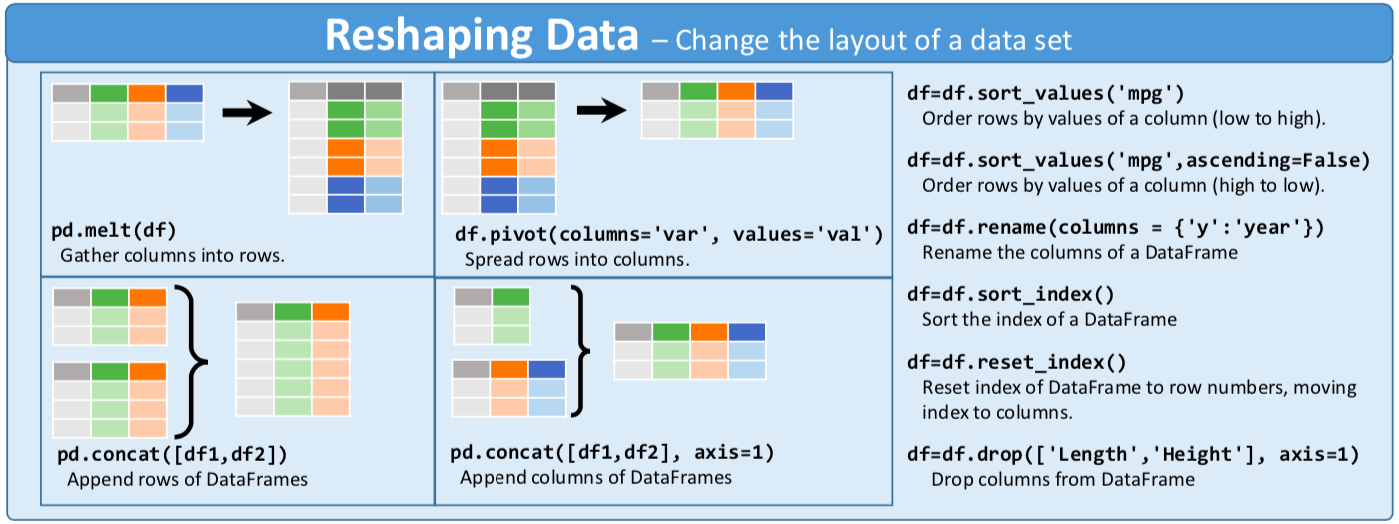
# Pandas
DataFrame 的“增删改查”
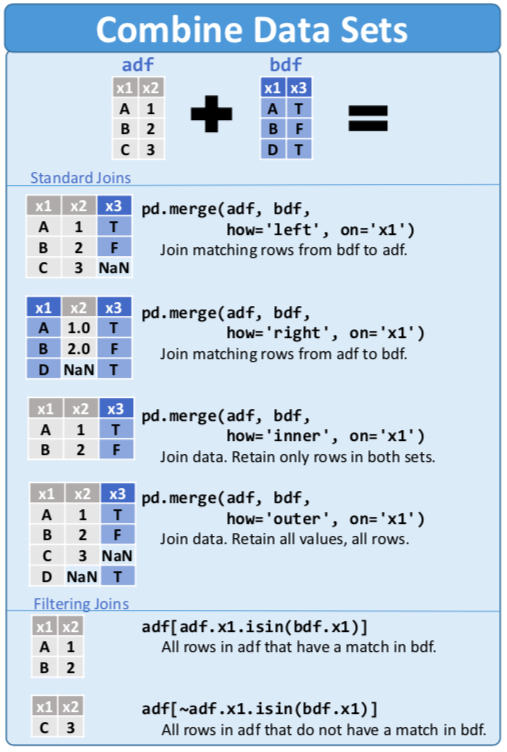
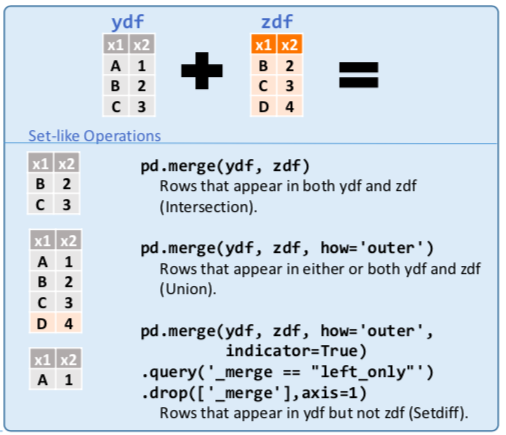
# Pandas
DataFrame 的“增删改查”
-
Series / DataFrame 常用的属性与方法
-
shape / size / index / dtype / astype() / ...
-
head() / tail() / describe() / values
-
max() / min() / mean() / median() / ...
-
to_*() / sort_index() / sort_values() / ...
-
apply() / drop() / drop_duplicates() / ...
-
isin() / isna() / isnull() / fillna() / ...
-
\(\Rightarrow\) ndarray (Numpy)
-
Series 的常用属性与方法
-
unique()
-
tolist() -
value_counts() -
map()
-
is_unique() / is_monotonic()
-
-
DataFrame 的常用属性与方法
-
columns
-
info() -
stack()
-
insert()
- ...
-
# Pandas
DataFrame 的组合与聚合&透视表
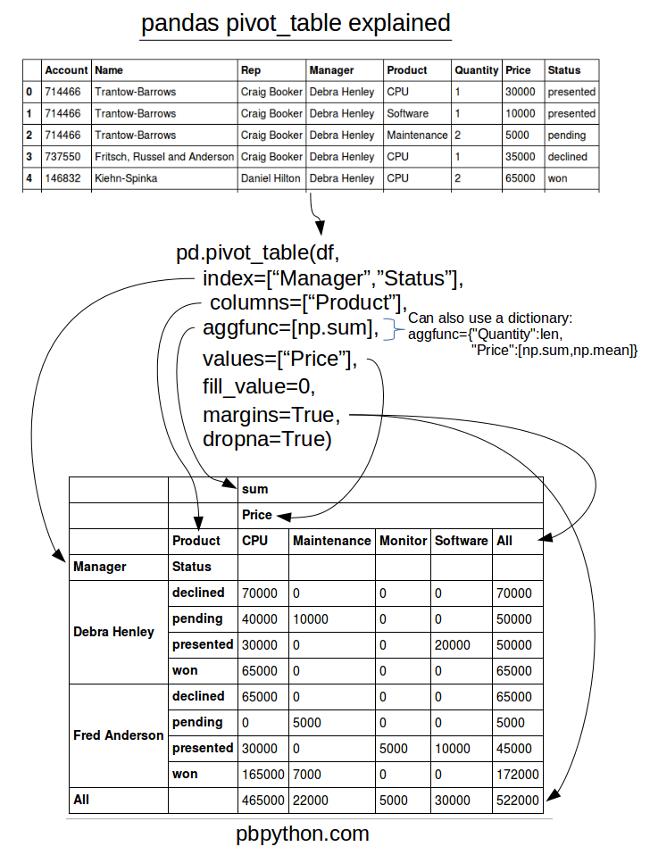
—— 数据高级统计分析
pivoted = pd.pivot_table(s4g, index=['Symbol', 'Year'],
values=['Open','Close'], aggfunc='mean',
columns=['Month'], fill_value = 0)\(\Leftrightarrow\)
table = s4g.groupby(['Symbol', 'Year', 'Month'])['Open', 'Close'].mean()
table = table.unstack('Month')
table = table.fillna(0)

# Homework
Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
-
Python、Numpy 和 Pandas 的基础作业题目(单选题)位于:-
2023/python/homework-python.* -
2023/python/homework-numpy.* -
2023/python/homework-pandas.* -
(分别有 ipynb, html, md 三种文档格式,以方便阅读)
-
-
将你完成的作业添加到你在上一步中创建的个人作业目录中。根据作业的类型,应将完成的作业分别命名为 python_submit.txt、numpy_submit.txt 和 pandas_submit.txt。其中每个 txt 文档的每行对应于 A,B,C,D,... 等选项当中的一个(注意:行号对应于题号) -
在 homework 分支上把你完成的作业 push 到你自己的关于本课程的远程仓库中,即:$ git push origin homework ;最后,在GitHub上你的远程仓库中,在 homework 分支下发起 Pull Request (PR) 至本课程远程仓库的 homework 分支。 -
GitHub Actions 工作流将自动检查你的提交,并将 modified 的python_submit.txt、numpy_submit.txt 和 pandas_submit.txt 与 solution 进行比较。 - 基础作业的最终成绩,根据PR的最新commit来定,记得到时候 @ 我记录成绩。
-
不要修改其他学员的作业目录和作业内容!
# Homework
Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
扩展作业
- 完成以下 Leetcode 中的算法题目:
- 把上面5道算法题目的结果 comment 在你完成的基础作业的PR里,要求:算法的每一行都写好中文说明注释。

Want more? see: Advent of Code