引力波数据探索:编程与分析实战训练营
第 4 部分 深度学习基础


主讲老师:王赫
2023/12/27
ICTP-AP, UCAS



深度学习技术概述与神经网络基础
- 深度学习技术的起源
- 一切的开始:感知器
- 深度学习技术的应用
- 深度学习技术的特点
深度学习技术:概述

深度学习技术的起源
# GW: DL
- 机器学习: 人工智能的一个重要学科分支,多领域交叉学科
- 数据驱动: 在数据上通过算法总结规律模式,应用在新数据上
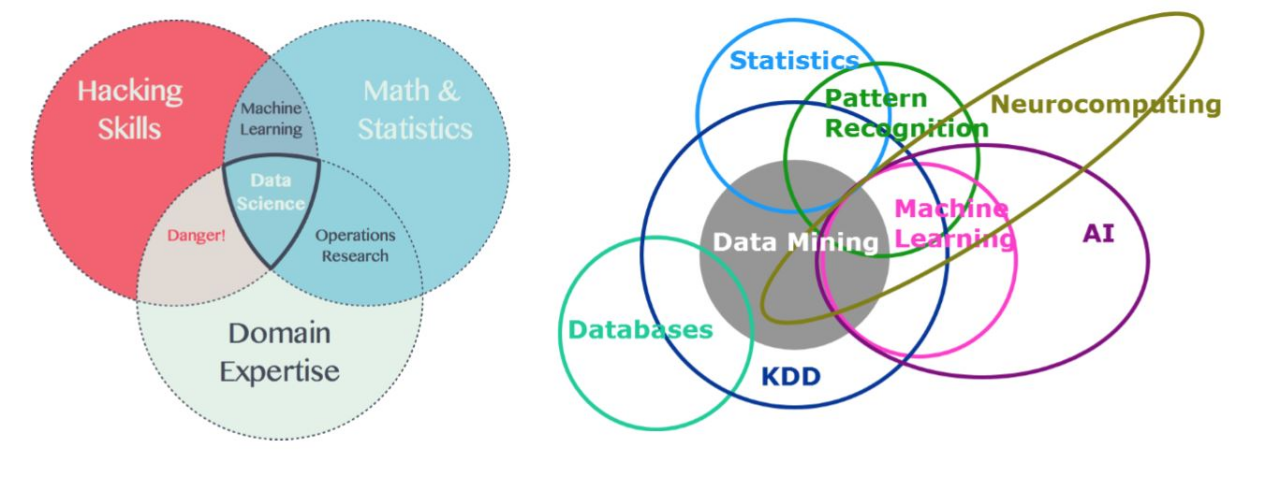
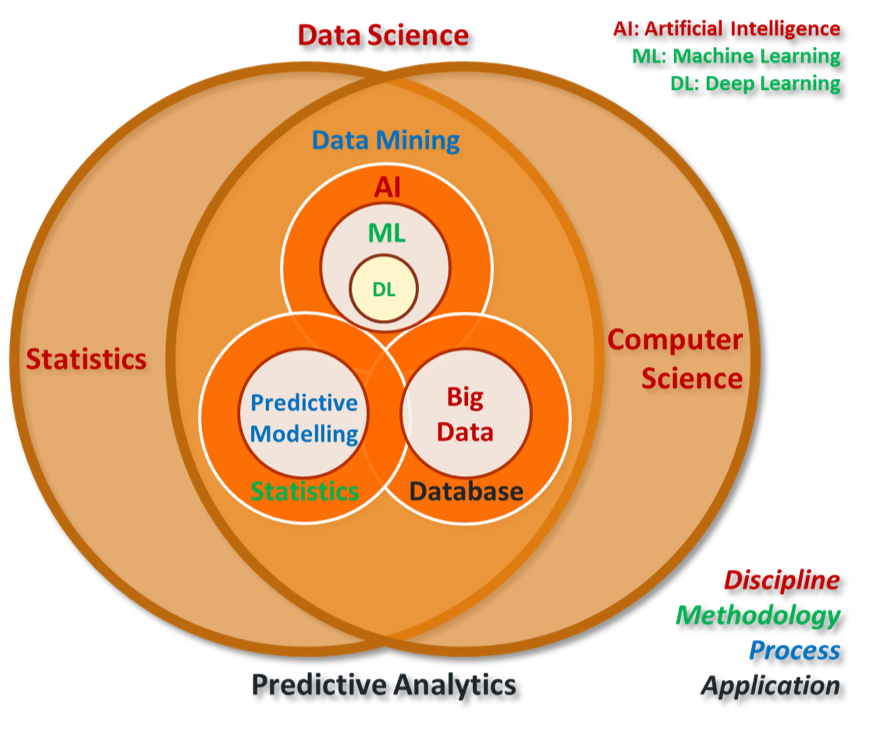
Knowledge Discovery in Database, KDD
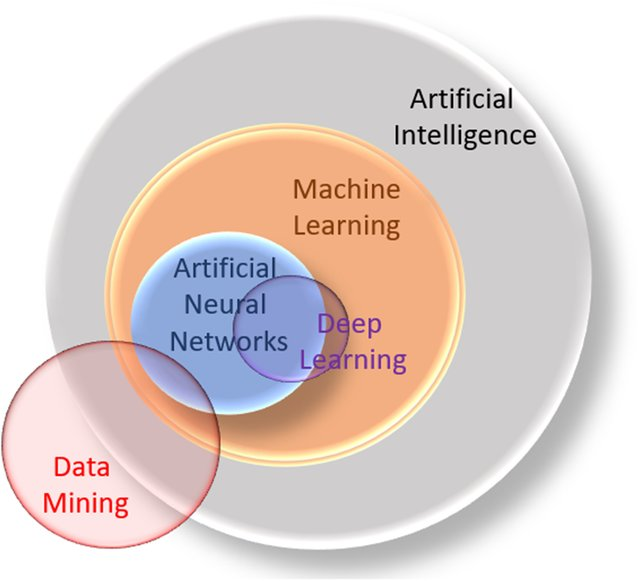
深度学习技术的起源
# GW: DL
- 人工智能发展标志事件 (Before 2017~)
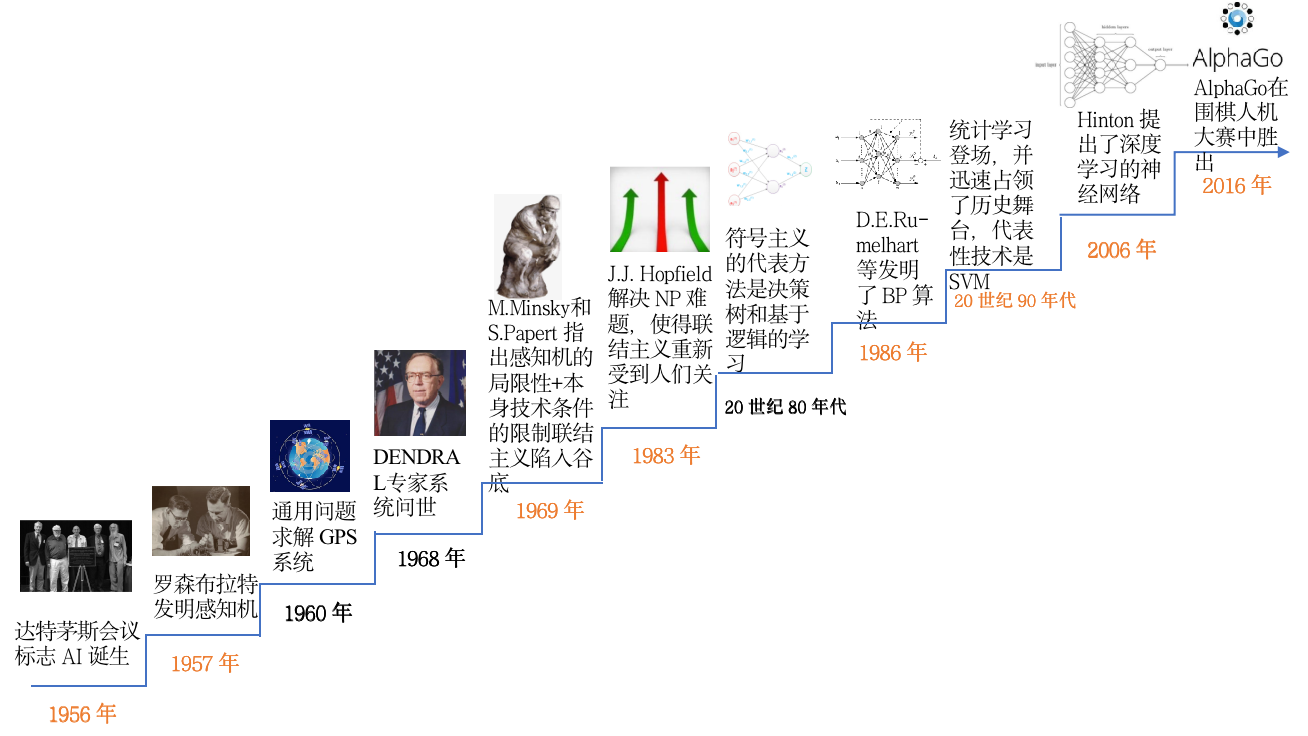
人工智能(Artificial Intelligence) 使一部机器像人一样进行感知、认知、决策、执行的人工程序或系统。
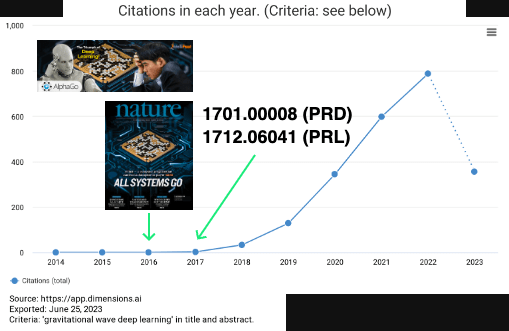
深度学习技术的起源
# GW: DL
- 人工智能发展标志事件 (Before 2017~)

深度学习技术的起源
# GW: DL
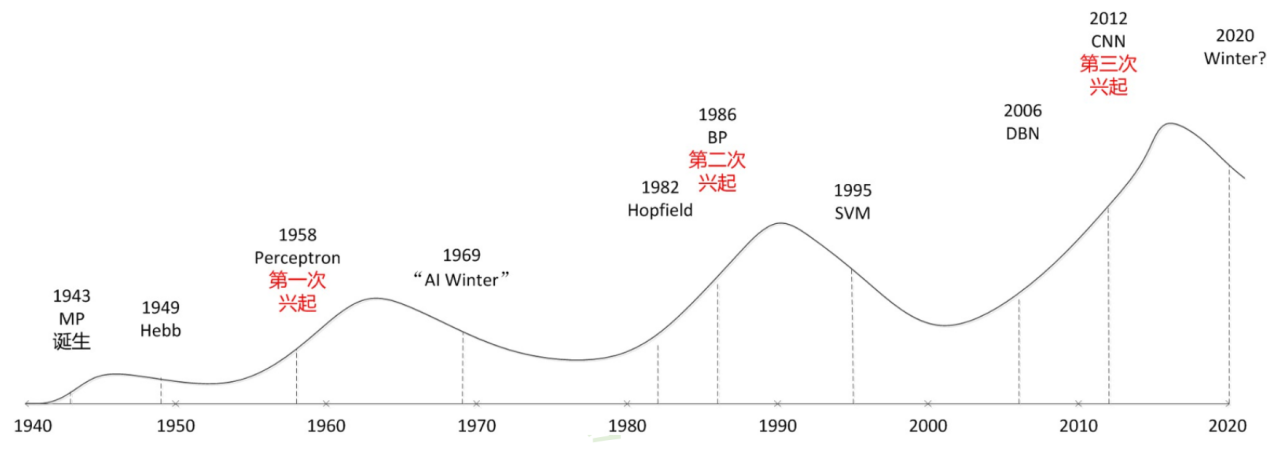
- 神经网络的三起两落
- 深度学习的起源可以追溯到神经网络的发展历程,这个过程经历了三次兴起和两次衰落。
- 第一次兴起发生在20世纪50-60年代,当时研究者们提出了感知机模型,这是最早的神经网络模型之一。然而,由于感知机模型无法解决异或(XOR)问题,神经网络进入了第一次衰落期。
- 第二次兴起发生在80年代,当时研究者们提出了反向传播算法,使得神经网络能够学习到更复杂的模式。然而,由于计算能力的限制和过拟合问题,神经网络在90年代再次进入衰落期。
- 第三次兴起发生在21世纪初,这次兴起主要得益于计算能力的大幅提升和大数据的出现。这使得研究者们能够训练出更深层次的神经网络,也就是我们现在所说的深度学习模型。此外,新的优化算法和正则化技术的出现也帮助解决了过拟合问题,使得深度学习在各种任务上都取得了显著的效果。至今,深度学习仍在持续发展中,正在推动着人工智能领域的进步。
深度学习技术的起源
# GW: DL
- 神经网络的三起两落
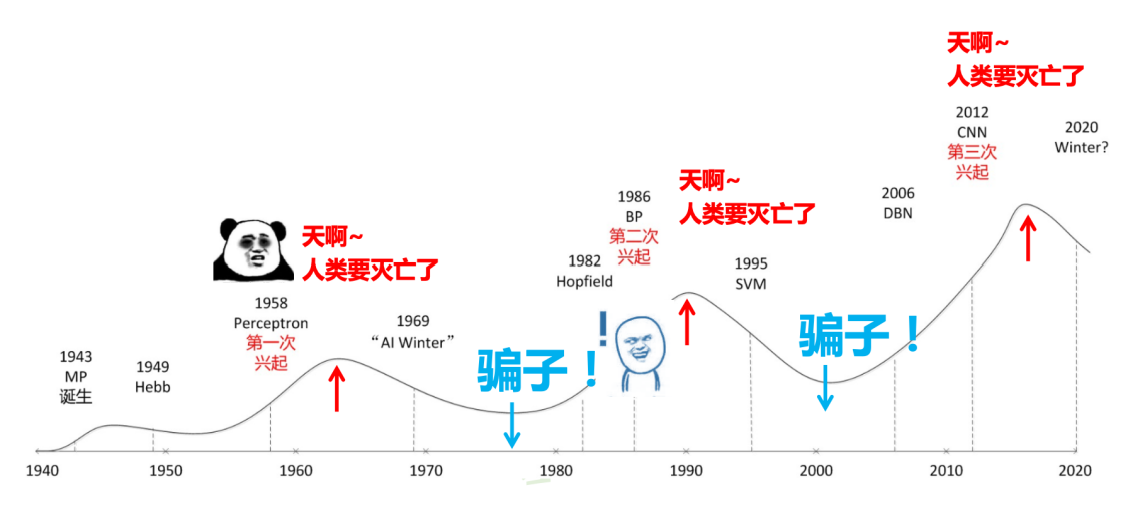
- 第一次兴起发生在20世纪50-60年代,当时研究者们提出了感知机模型,这是最早的神经网络模型之一。然而,由于感知机模型无法解决异或(XOR)问题,神经网络进入了第一次衰落期。
- 第二次兴起发生在80年代,当时研究者们提出了反向传播算法,使得神经网络能够学习到更复杂的模式。然而,由于计算能力的限制和过拟合问题,神经网络在90年代再次进入衰落期。
- 第三次兴起发生在21世纪初,这次兴起主要得益于计算能力的大幅提升和大数据的出现。这使得研究者们能够训练出更深层次的神经网络,也就是我们现在所说的深度学习模型。此外,新的优化算法和正则化技术的出现也帮助解决了过拟合问题,使得深度学习在各种任务上都取得了显著的效果。至今,深度学习仍在持续发展中,正在推动着人工智能领域的进步。
一切的开始:感知器
# GW: DL
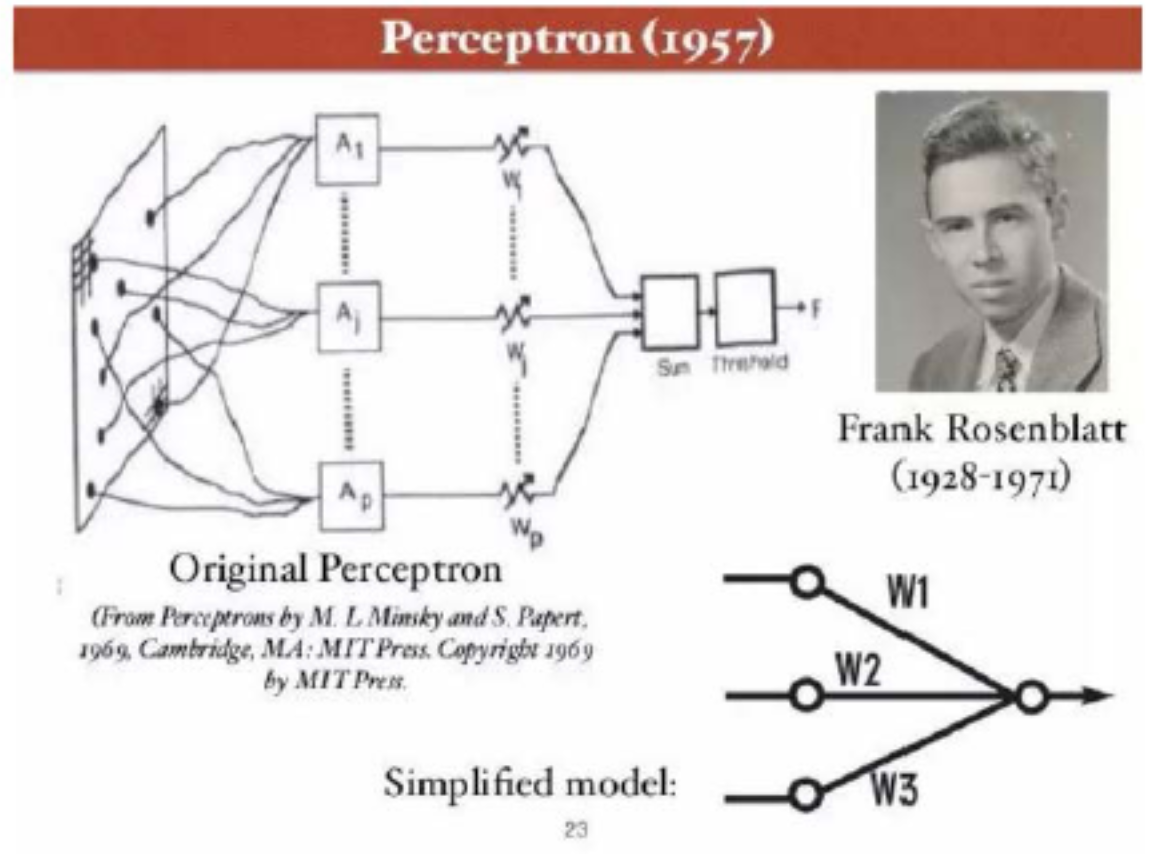
- Rosenblatt & Perceptron (感知器)
- 计算模型:1943 年最初由 Warren McCulloch 和Walter Pitts 提出,称为MP模型。他们通过MP模型提出了神经元的形式化数学描述和网络结构方法,证明了单个神经元能执行逻辑功能,从而开创了人工神经网络研究的时代。
-
1949年,心理学家提出了突触联系强度可变的设想。
- 康奈尔大学 Frank Rosenblatt 1957年提出,解决二分类问题,利用梯度下降法, 自动更新权值。1962年,改方法被证明收敛。
- Perceptron 是第一个具有自组织自学习能力的数学模型
- Rosenblatt 乐观预测:感知器最终可以“学习,做决定,翻译语言”
- 感知器技术六十年代一度走红,美国海军曾出自支持,期望它“以后可以自己走,说活看,读,自我复制,甚至拥有自我意识”

一切的开始:感知器
# GW: DL

- Rosenblatt & Minsky
- Rosenblatt 和 Minsky 是间隔一级的高中校友。但是六十年代,两个人在感知器的问题上展开了长时间的激辩:R 认为感知器将无所不能,M 则认为它应用有限
- 1969 年,Marvin Minsky 和 Seymour Papert 出版了新书:《感知器:计算几何简介》。
书中论证了感知器模型的两个关键问题:- 第一,单层的神经网络无法解决不可线性划分的问题,典型例子如异或门
- 第二,更致命的问题是:当时的电脑完全没有能力完成神经网络模型所需的超大计算量
- 此后的十几年,以神经网络为基础的人工智能研究进入低潮(业界的核冬天:约20年停滞发展期)
深度学习技术的发展
# GW: DL
-
Geoffrey Hinton & Neural Networks
- 1970 年,当神经网络研究的第一个寒冬降临时,在英国的爱丁堡大学,一位 23 岁的年轻人 Geoffrey Hinton,刚刚获得心理学的学士学位。
- Hinton 六十年代还是中学生就对脑科学着迷。当时一个同学给他介绍关于大脑记忆的理论是:大脑对于事物和概念的记忆,不是存储在某个单一的地点,而是像全息照片一样,分布式地存在于一个巨大的神经元的网络里。
-
分布式表征(Distributed Rep.)和传统的局部表征(Localized Rep.)相比:
- 存储效率高:线性增加的神经元数目,可以表达指数级增加的大量不同概念。
- 鲁棒性好:即使局部出现硬件故障,信息的表达不会受到根本性的破坏。
-
这个理念让 Hinton 顿悟,使他 40 多年来一致在神经网络研究的领域内坚持。
- 本科毕业后,Hinton 选择继续在爱丁堡大学读研,把人工智能作为自己的博士研究方向。
- 1978 年,Hinton 在爱丁堡获得博士学位后,来到美国继续他的研究工作。

深度学习技术的发展
# GW: DL
-
D. Rumelhart & BP Algorithm
- 神经网络被 Minsky 诟病的问题:巨大的计算量;XOR 问题;
- 传统的感知器用所谓“梯度下降”的算法纠错时,耗费的计算量和神经元数目的平方成正比,当神经元数目增多,庞大的计算量是当时的硬件无法胜任的。
- 1982年,美国加州理工物理学家J.J.Hopfield提出了Hopfield神经网格模型,引入了“计算能量”概念,给出了网络稳定性判断。
- 1986 年 7 月,Hinton 和 David Rumelhart 合作在 Nature 杂志上发表论文:Learning Representations by Back-propagating Errors. 第一次系统简洁地阐述 BP 算法及其应用:
- 反向传播算法把纠错的运算量下降到只和神经元数目本身成正比;
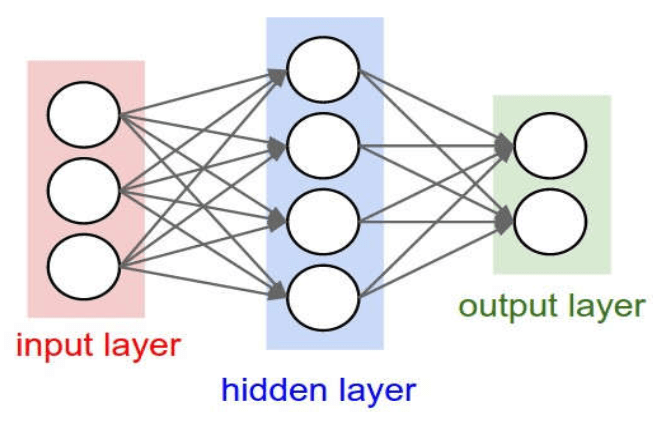
- BP 算法通过在神经网络里增加一个所谓隐层(hidden layer),解决了 XOR 难题
- 使用了 BP 算法的神经网络在做如形状识别之类的简单工作时,效率比感知器大大提高,八十年代末计算机的运行速度,也比二十年前高了几个数量级;
- 神经网络及其应用的研究开始复苏!



深度学习技术的发展
# GW: DL
-
Yann Lecun (杨立昆) & CNN
- Yann Lecun 于 1960 年出生于巴黎。
- 1987 年在法国获得博士学位后,他曾追随 Hinton 教授到多伦多大学做了一年博士后的工作,随后搬到新泽西州的 Bell Lab 继续研究工作。
- 在 Bell Lab, Lecun 1989 年发表了论文,“反向传播算法在手写邮政编码上的作用”。他用美国邮政系统提供的近万个手写数字的样本来训练神经网络系统,训练好的系统在独立的测试样本中,错误率只有 5%。
- Lecun 进一步运用一种叫做“卷积神经网络”(Convolutional Neural Networks, CNN)的技术,开发出商业软件,用于读取银行支票上的手写数字,这个支票识别系统在九十年代末占据了美国接近 20% 的市场。




2003 年,Yann LeCun 等人在 NEC 实验室的使用CNN进行人脸检测。
深度学习技术的发展
# GW: DL
-
Yann Lecun (杨立昆) & CNN
- Yann Lecun 于 1960 年出生于巴黎。
- 1987 年在法国获得博士学位后,他曾追随 Hinton 教授到多伦多大学做了一年博士后的工作,随后搬到新泽西州的 Bell Lab 继续研究工作。
- 在 Bell Lab, Lecun 1989 年发表了论文,“反向传播算法在手写邮政编码上的作用”。他用美国邮政系统提供的近万个手写数字的样本来训练神经网络系统,训练好的系统在独立的测试样本中,错误率只有 5%。
- Lecun 进一步运用一种叫做“卷积神经网络”(Convolutional Neural Networks, CNN)的技术,开发出商业软件,用于读取银行支票上的手写数字,这个支票识别系统在九十年代末占据了美国接近 20% 的市场。
- 此时就在 Bell Lab,Yann Lecun 临近办公室的一个同事 Vladimir Vapnik 的工作,又把神经网络研究带入第二个寒冬!
在90年代,人工神经网络缺少严格的数学理论支撑,统计学习大发展。 Vapnik提出支持向量机(SVM),改进了感知器的一些缺陷(例如创建灵活的特征而不是手编的非适应的特征)。它同样解决了线性不可分问题,但是对比神经网络有全方位优势:
- 高效,可以快速训练;
- 无需调参,没有梯度消失问题;
- 高效泛化,全局最优解,不存在过拟合问题。



SVM (support vector machines)
深度学习技术的发展
# GW: DL
-
Hinton & Deep Learning
- 2003年,Geoffrey Hinton 还在多伦多大学,在神经网络的领域苦苦坚守。
- 2003 年在温哥华大都会酒店,以 Hinton 为首的十五名来自各地的不同专业的科学家,和加拿大先进研究员(Canadian Institute of Advanced Research, CIFAR)的基金管理负责人 Melvin Silverman 交谈。
- Silverman 问大家,为什么 CIFAR 要支持他们的研究项目。
- 计算神经科学研究者,Sebastian Sung(现为普林斯顿大学教授)回答道:“喔,因为我们有点古怪。如果 CIFAR 要跳出自己的舒适区,寻找一个高风险,极具探索性的团体,就应当资助我们了!”
- 最终 CIFAR 同意从 2004 年开始资助这个团体十年,总额一千万加元。CIFAR 成为当时世界上唯一支持神经网络研究的机构。


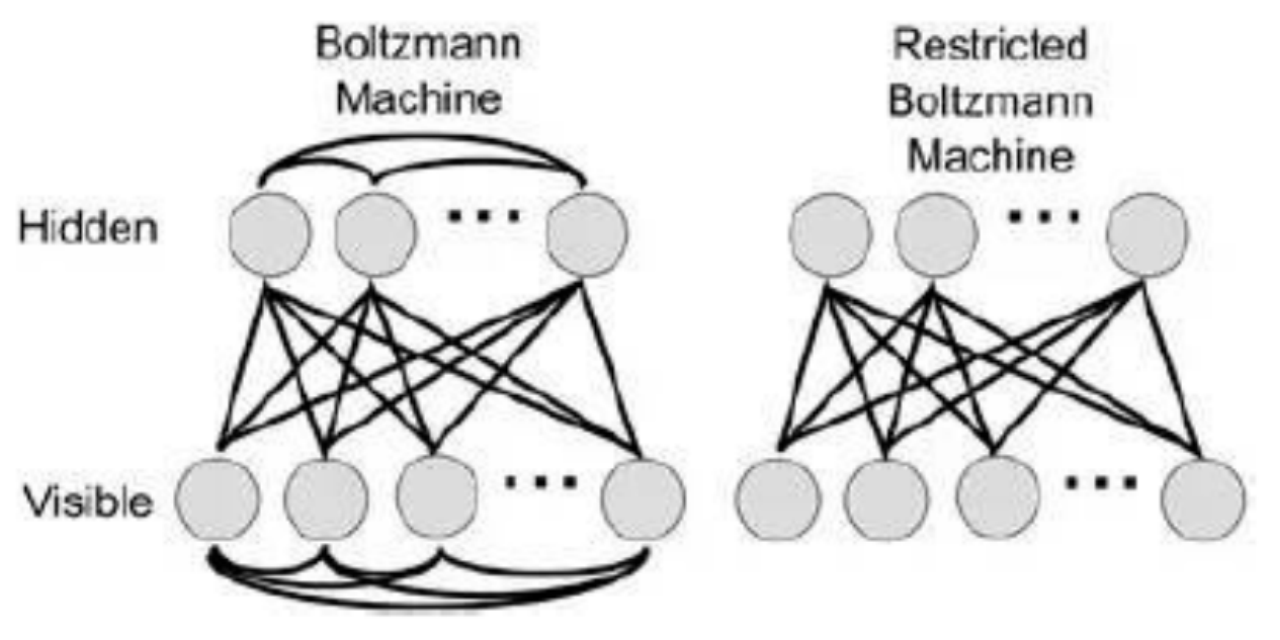
- Hinton 拿到资金支持不久做的第一件事,就是把“神经网络”改名换姓为“深度学习”。
- 此后,Hinton 的同时不时会听到他突然在办公室大叫:“我知道人脑是如何工作的了!”
- 2006 年 Hinton 和合作者发表革命性的论文:A Fast Learning Algorithm for Deep Belief Nets .

- 逐层初始化(layer-wise pre-training)
- 预训练(pre-training)
- 微调(fine-tuning)
被 Hinton 首次定义为深度学习过程
深度学习技术的发展
# GW: DL
-
Andrew Y. Ng & GPU
- 2007 年之前,用 GPU 编程缺乏一个简单的软件接口,编程繁琐,Debug 困难。2007 年 NVIDIA 推出 CUDA 的 GPU 软件接口后才真正改善。
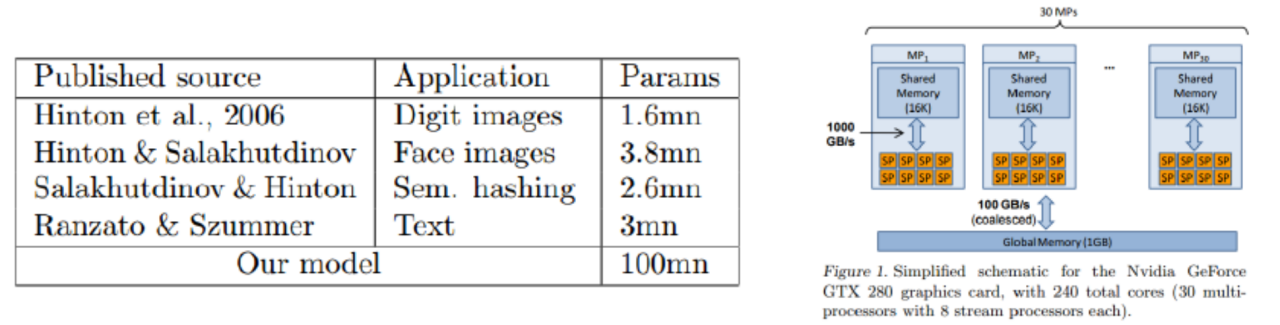
- 2009 年 6 月,斯坦福大学的 Rajat Raina 和吴恩达合作发表论文:Large-scale Deep Unsupervised Learning using Graphic Processors (ICML09);论文采用 DBNs 模型和稀疏编码(Sparse Coding),模型参数达到一亿(与 Hinton 模型参数的对比见下表)。
- 结论结果显示:使用 GPU 运行速度和用传统双核 CPU 相比,最快时要快近 70 倍。在一个四层,一亿个参数的 DBN 网络上使用 GPU 把程序运行时间从几周降到一天。

深度学习技术的发展
# GW: DL
-
Jen-Hsun Huang & GPU
- 黄仁轩,1963 年出生于台湾。1993 年斯坦福大学硕士毕业后不久创立了 NVIDIA。
- NVIDIA 起家时做的是图像处理的芯片,主要面对电脑游戏市场。1999 年 NVIDIA 推销自己的 Geforce 256 芯片时,发明了 GPU(Graphics Processing Unit)这个名词。
- GPU 的主要任务,是要在最短时间内显示上百万、千万甚至更多的像素。这在电脑游戏中是最核心的需求。这个计算工作的核心特点,是要同时并行处理海量的数据。
- 传统的 CPU 芯片架构,关注点不在并行处理,一次只能同时做一两个加减法运算。而 GPU 在最底层的算术逻辑单元(ALU,Arithmetic Logic Unit),是基于所谓的 Single Instruction Multiple Data(单指令多数据流)的架构,擅长对于大批量数据并行处理。
- 一个 GPU,往往包含几百个 ALU,并行计算能力极高。所以尽管 GPU 内核的时钟速度往往比 CPU 的还要慢,但对大规模并行处理的计算工作,速度比 CPU 快许多。
- 神经网络的计算工作,本质上就是大量的矩阵计算的操作,因此特别适合于使用 GPU。


深度学习技术的发展
# GW: DL
-
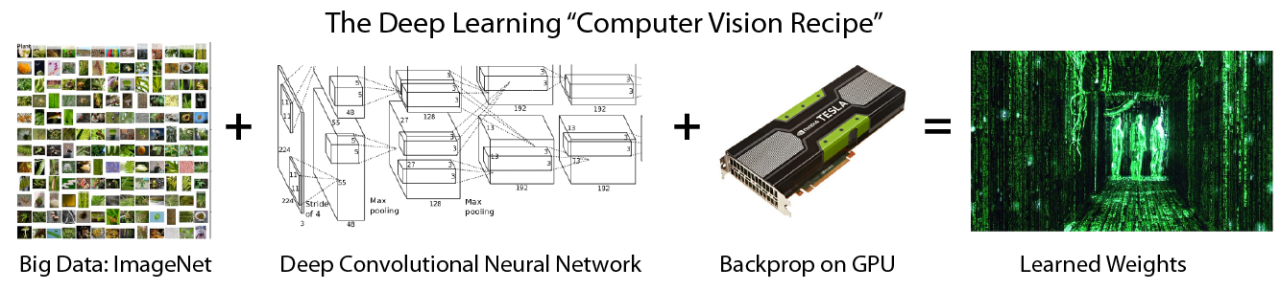
Big Data:ImageNet
- 2009 年,一群普林斯顿大学计算机系的华人学者(李飞飞教授领衔)发表了论文:ImageNet:A large scale hierarchical image database,宣布建立了第一个超大型图像数据库供计算机视觉研究者使用。
- 数据库建立之初,包含了 320 万个图像。它的目的,是要把英文里的 8 万个名词,每个词收集到五百到一千个高清图片,存放到数据库里,最终达到五千万以上的图像。
- 2010 年,以 ImageNet 为基础的大型图像识别竞赛,ImageNet Large Scale Visual Recognition Challenge 2010 (ILSVRC2010) 第一次举办。 [http://www.image-net.org/ ]
- 竞赛最初的规则:以数据库内 120 万个图像为训练样本,这些图像从属于一千多个不同的类别,都被手工标记。经过训练的程序,再用于 5 万个测试图像评估分类准确率。



深度学习技术的发展
# GW: DL
- Image Classification: ILSVRC 竞赛
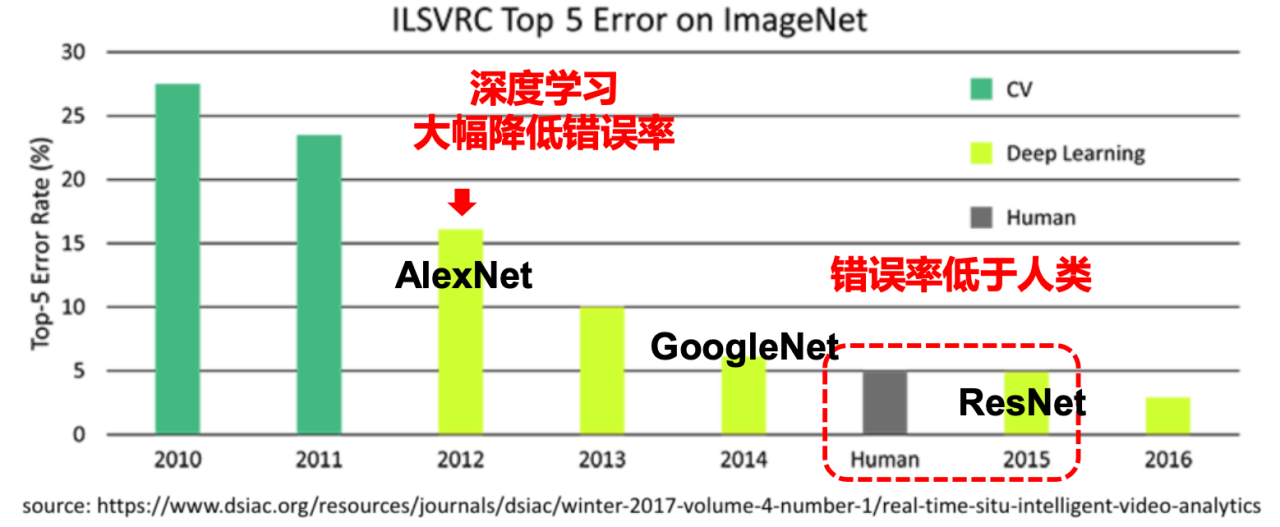
- 2010 年冠军:NEC 和伊利诺伊大学香槟分校的联合团队,用支持向量机(SVM)的技术识别分类的错误率 28%。
- 2011 年冠军:用 Fisher Vector 的计算方法(类似 SVM),将错误率降到了 25.7%。
-
2012 年冠军:Hinton 和两个 Alex Krizhevsky,Illya Sutskever,利用 CNN+Dropout 算法+RELU 激励函数,用了两个 NVIDIA 的 GTX580 GPU(内存 3GB,计算速度 1.6 TFLOPS),花了接近 6 天时间,错误率只有 15.3%。
- 2012 年 10 月 13 日,当竞赛结果公布后,学术界沸腾了。这是神经网络二十多年来,第一次在图像识别领域,毫无疑义的,大幅度挫败了别的技术。
- 这是人工智能技术突破的一个重要转折点!


深度学习技术的应用
# GW: DL
- 深度学习的三个助推剂
大数据(海量)
算法(神经网络)
计算力(GPU硬件)
算法(神经网络)
人工智能
- 深度学习三巨头+粉丝


LeCun, Yann, Yoshua Bengio, and Geoffrey Hinton. “Deep Learning.” Nature 521, no. 7553 (May 1, 2015): 436–44. https://doi.org/10.1038/nature14539.

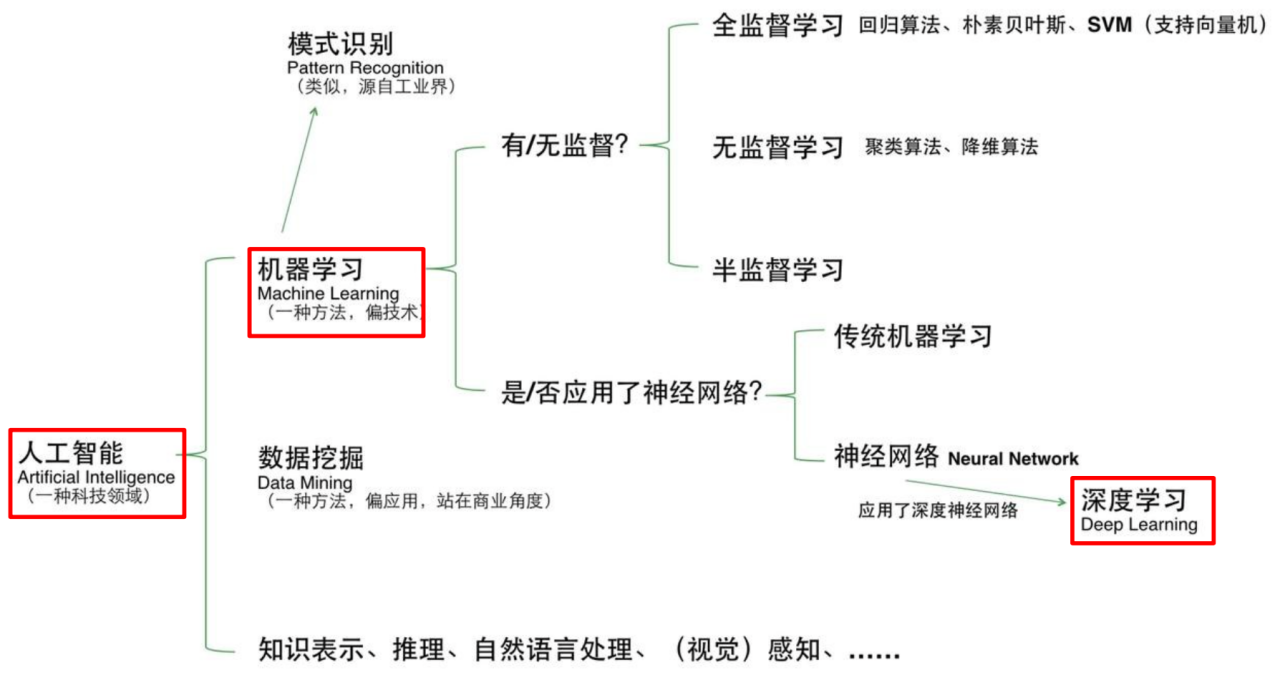
深度学习技术的特点
# GW: DL
- 人工智能 > 机器学习 > 深度学习
深度学习技术的特点
# GW: DL
-
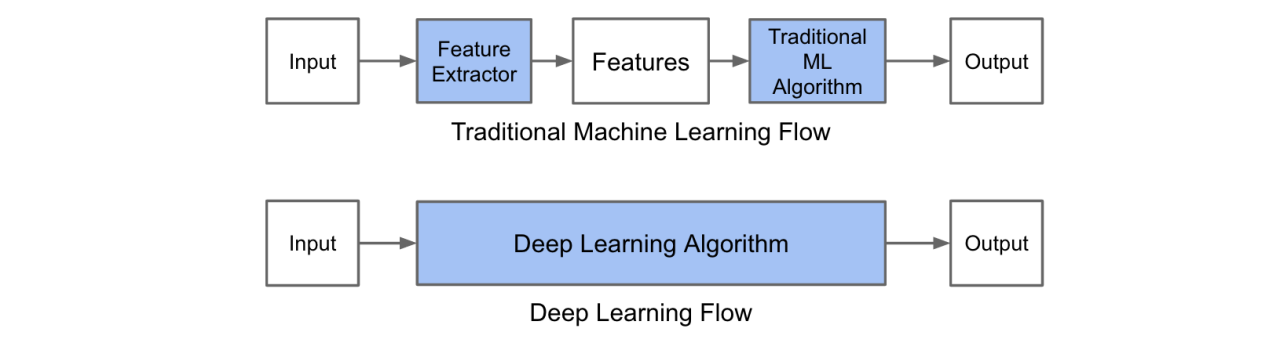
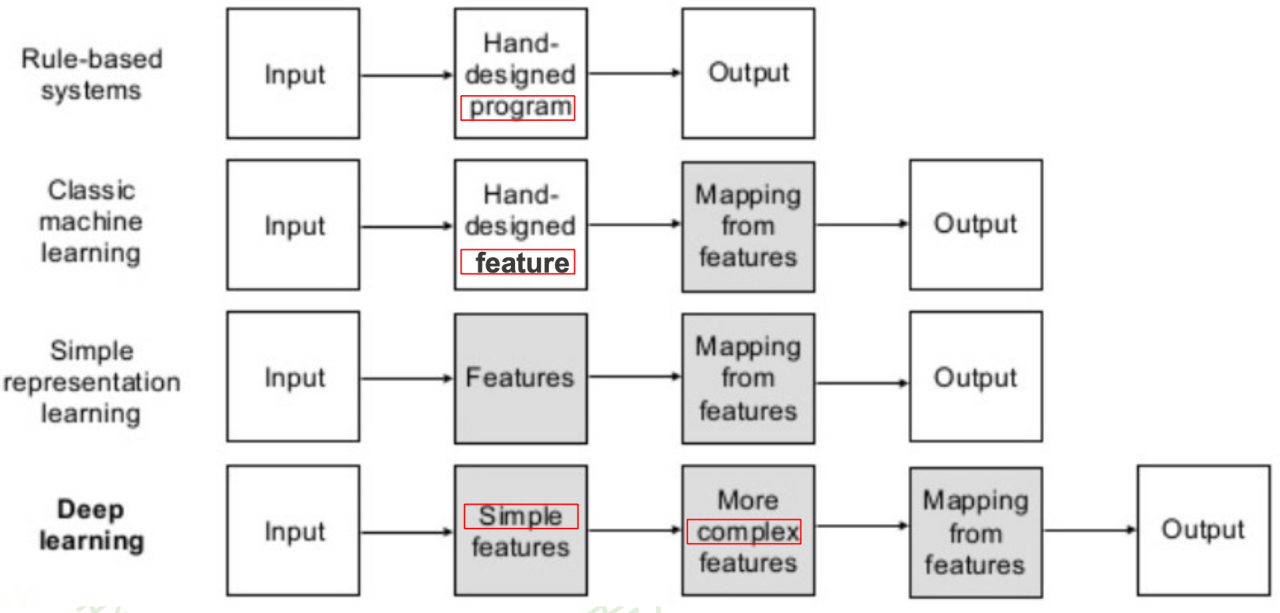
传统机器学习 vs 深度学习
- 传统机器学习:人工设计特征
- 在实际应用中,设计特征往往比分类器更重要
- 预处理:经过数据的预处理,如去除噪声等。比如在文本分类中,去除停用词等。
- 特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换特征等。
- 特征转换:对特征进行一定的加工,比如降维和升维。降维包括
- 特征抽取(Feature Extraction):PCA、SVD、LDA
- 特征选择(Feature Selection):互信息、TF-IDF
- 深度学习:一种端到端 [end-to-end] 的学习范式
- 推动了一大类 非线性映射函数学习问题 的解决
- 从人工编码知识 \(\rightarrow\) 从数据中学习知识
- 分而治之 \(\rightarrow\) 全盘考虑
- 重算法 \(\rightarrow\) 重数据
- 传统机器学习:人工设计特征
深度学习技术的特点
# GW: DL
-
传统机器学习 vs 深度学习
- 传统机器学习:人工设计特征
- 在实际应用中,设计特征往往比分类器更重要
- 预处理:经过数据的预处理,如去除噪声等。比如在文本分类中,去除停用词等。
- 特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换特征等。
- 特征转换:对特征进行一定的加工,比如降维和升维。降维包括
- 特征抽取(Feature Extraction):PCA、SVD、LDA
- 特征选择(Feature Selection):互信息、TF-IDF
- 深度学习:一种端到端 [end-to-end] 的学习范式
- 推动了一大类 非线性映射函数学习问题 的解决。
- 从人工编码知识 \(\rightarrow\) 从数据中学习知识
- 分而治之 \(\rightarrow\) 全盘考虑
- 重算法 \(\rightarrow\) 重数据
- 传统机器学习:人工设计特征
深度学习技术的特点
# GW: DL
- 深度学习:一种端到端 [end-to-end] 的学习范式
- 推动了一大类 非线性映射函数学习问题 的解决。
- 从人工编码知识 \(\rightarrow\) 从数据中学习知识
- 分而治之 \(\rightarrow\) 全盘考虑
- 重算法 \(\rightarrow\) 重数据
- End-to-end principle
深度学习技术的特点
# GW: DL
- 机器学习
- 依赖于人工设计的特征:在机器学习的过程中,我们通常需要依赖于专家知识或者经验规则来设计和选择特征。这些特征能够帮助模型从数据中学习到有用的信息,从而进行有效的预测或决策。





局部边缘特征
面部细节特征
面部全局特征
- 深度学习
- 端到端的学习范式:深度学习是一种自动化的特征学习方法,它能够自动地从原始数据中学习到有用的特征。这种端到端的学习范式避免了人工设计特征的需要,使得模型能够直接从数据中学习到解决问题所需的所有知识,大大提高了模型的学习能力和效率。
深度学习技术的本质
# GW: DL
-
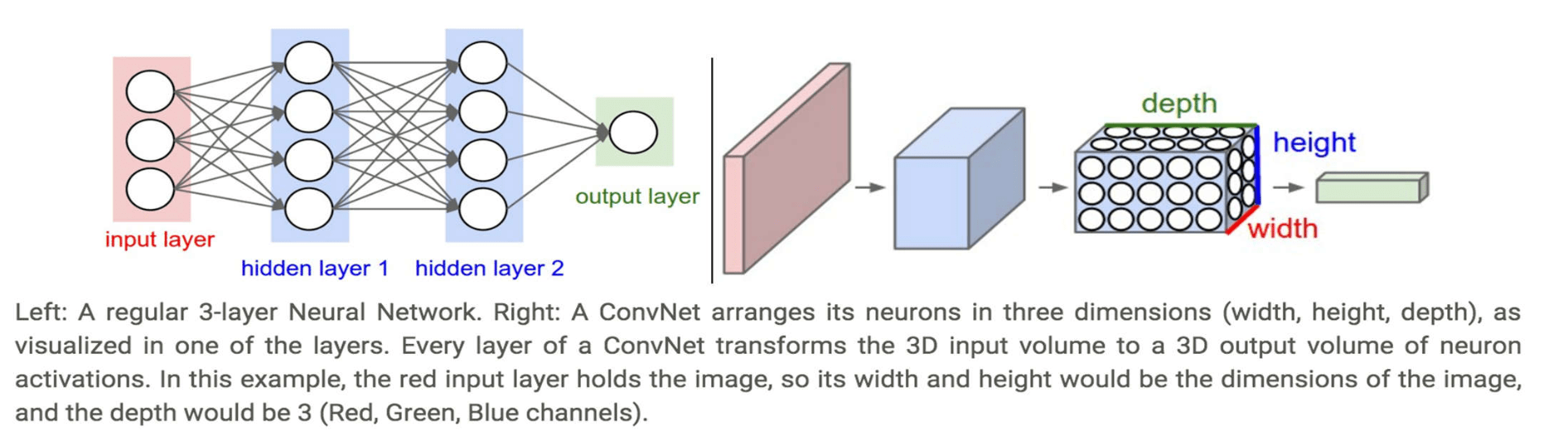
本质:通过构建多隐层的模型和海量训练数据(可为无标签数据),来学习更有用的特征,从而最终提升分类或预测的准确性。 “深度模型”是手段,“特征学习”是目的。
-
与浅层学习区别:
-
强调了模型结构的深度,通常有5-10多层的隐层节点;
-
明确突出了特征学习的重要性,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据的丰富内在信息。
-
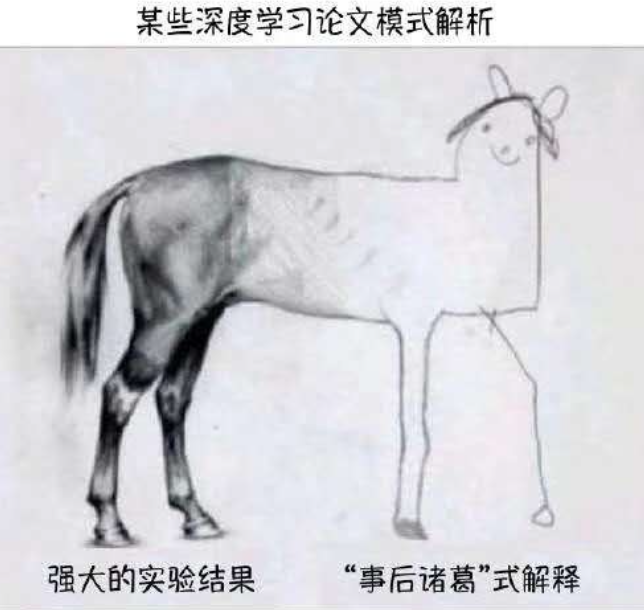
深度学习技术:工程技术 or 科学研究 ?
# GW: DL
- 工程低门槛 & 科研高门槛(门槛非常低 + 天花板非常高)
- "科学为技术的发展提供基础和支撑,而技术进步则不断地向科学研究提出新的课题,反过来激励科学发展。"
- "不应该简单地把发展技术的思路和措施直接搬过来为发展科学铺路,也不应该简单地套用管理技术发展的政策和方式来经营科学发展。"

- 经典书籍和专著
- 优秀课程资源
- 值得关注的公众号
人工智能技术自学材料推荐

机器学习与深度学习技术的学习材料
# GW: DL
书中例子多而形象,适合当做工具书

模型+策略+算法
(从概率角度)
机器学习
(公理化角度)
讲理论,不讲推导
经典,缺前沿
神书(从贝叶斯角度)
2k 多页,难啃,概率模型的角度出发
花书:DL 圣经
科普,培养直觉
机器学习与深度学习技术的学习材料
# GW: DL
工程角度,无需高等
数学背景
参数非参数
+频率贝叶
斯角度
统计角度
统计方法集大成的书

讲理论,
不会讲推导
贝叶斯角度
DL 应用角度
贝叶斯角度完整介绍
大量数学推导
机器学习与深度学习技术的学习材料
# GW: DL
优秀课程资源:
- CS231n(Stanford 李飞飞) / CS229 / CS230
- 吴恩达(ML / DL ...)
- 李宏毅(最佳中文课程,没有之一)
- 李沐-动手学深度学习(MXNet / PyTorch / TensorFlow)
- ... (多翻翻 Bilibili 就对了)
值得关注的公众号:
-
机器之心(顶流)
-
量子位(顶流)
-
新智元(顶流)
-
专知(偏学术)
-
微软亚洲研究院
-
将门创投
-
旷视研究院
-
DeepTech 深科技(麻省理工科技评论)
-
极市平台(技术分享)
- ...
-
爱可可-爱生活(微博、公众号、知乎、b站...)
-
陈光老师,北京邮电大学PRIS模式识别实验室
-

- 算法输出不稳定,容易被“攻击”
- 模型复杂度高,难以纠错和调试
- 模型层级复合程度高,参数不透明
- 端到端训练方式对数据依赖性很强,模型增量性差
- 专注直观感知累问题,对开放性推理问题无能为力
深度学习技术的“不能”

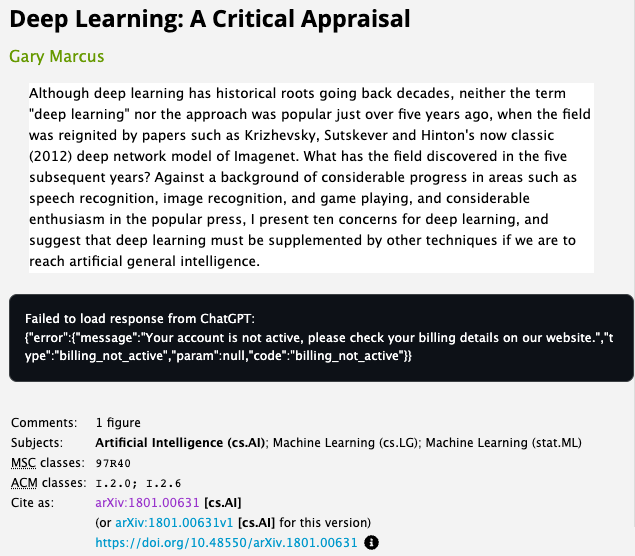
Deep Learning's Bottlenecks
- Deep learning thus far
- is data hungry
- is shallow & has limited capacity for transfer
- has no natural way to deal with hierarchical structure
- has struggled with open-ended inference
- is not sufficiently transparent
- has not been well integrated with prior knowledge
- cannot inherently distinguish causation from correlation
- presumes a largely stable world
- its answer often cannot be fully trusted
- is difficult to engineer with
Despite all of the problems I have sketched, I don't think that we need to abandon deep learning... Rather, we need to reconceptualize it: not as a universal solvent, but simply as one tool among many
# GW: DL
深度学习技术的“不能” (1/n)
- 算法输出不稳定,容易被“攻击”
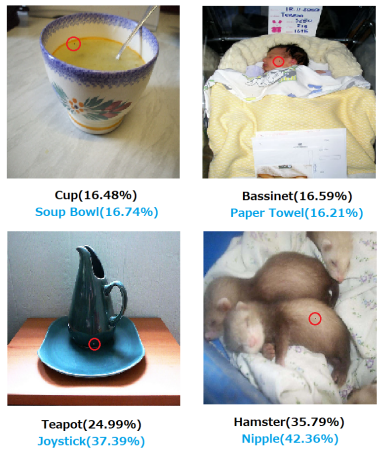
Su J, Vargas D V, Sakurai K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. (2019)

arXiv:1312.6199

vs
Jadhav et al. 2306.11797
# GW: DL
深度学习技术的“不能” (2/n)
- 模型复杂度高,难以纠错和调试




大众眼中的我们
工程师眼中的我们
数学家眼中的我们
我们眼中的自己

实际的我们

# GW: DL
深度学习技术的“不能” (3/n)
- 模型层级复合程度高,参数不透明
from stackexchange


on the top activated
neurals
Conv-1
Conv-2
Conv-3
Dense-1
# GW: DL
深度学习技术的“不能” (4/n)
- 端到端训练方式对数据依赖性很强,模型增量性差
- 当样本数据量小的时候,深度学习无法体现强大拟合能力
- 模型有效容量 (effective capacity) 的上界:参数 / VC 维/ Rademacher 复杂度
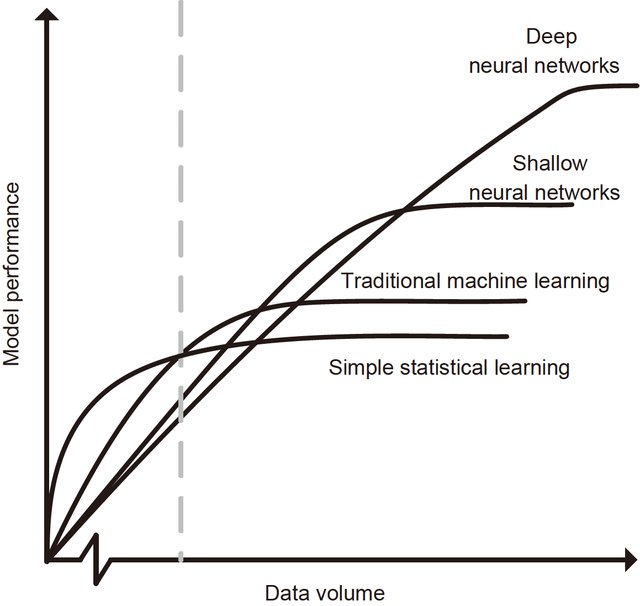
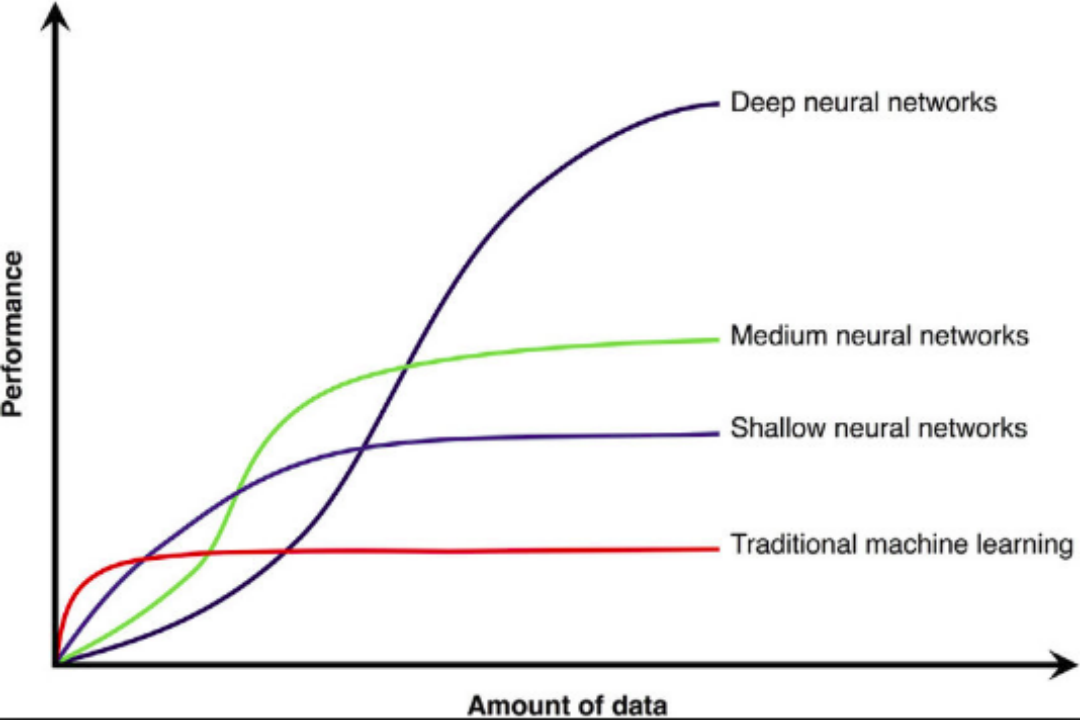
# GW: DL
深度学习技术的“不能” (4/n)
- 专注直观感知累问题,对开放性推理问题无能为力
- 乌鸦给我们的启示:
- 完全自主的智能
- 大数据非必须
- 海量计算非必须
- 乌鸦给我们的启示:



“鹦鹉”智能
“乌鸦”智能

# GW: DL
深度学习技术的“不能”与解释性
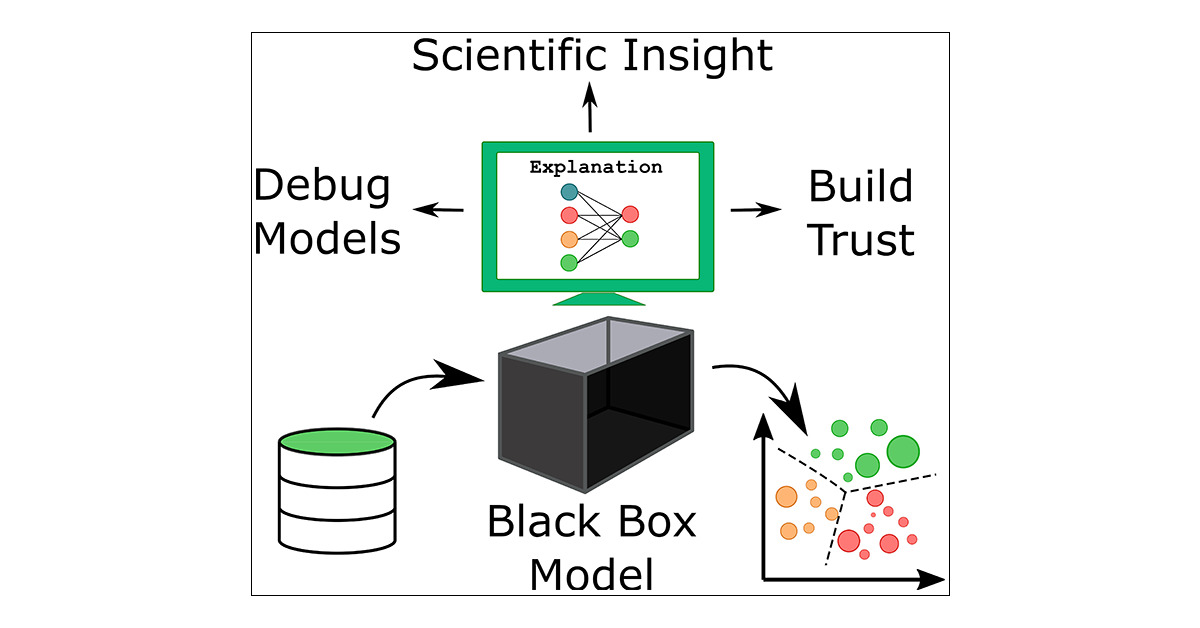
深度学习的“不能”
解释性的三个层次
“对症下药”(找得到)
知道那些特征输出有重要影响,出了问题准确快速纠错
不再“对牛弹琴”(看得懂)
双向:算法能被人的知识体系理解+利用和结合人类知识
稳定性低
可调试性差
参数不透明
机器偏见
增量性差
推理能力差
“站在巨人的肩膀上”(留得下)
知识得到有效存储、积累和复用
\(\rightarrow\) 越学越聪明
# GW: DL
- 神经元
- 万有逼近定理
- 神经网络的参数学习
深度学习:神经网络基础

深度学习:神经网络基础
# GW: DL
- 神经元
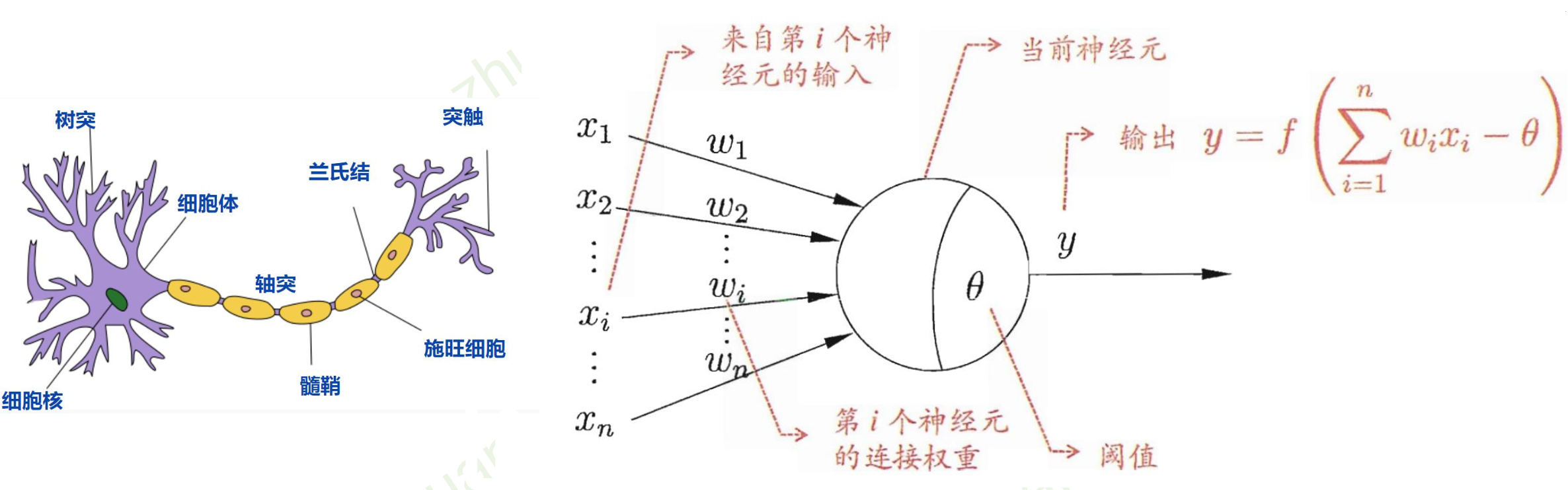
- 激活函数 \(f\)
-
没有激活函数的话,
相当于一维矩阵相乘:-
多层和一层一样
-
只能拟合线性函数
-
-
M-P神经元模型 [McCulloch and Pitts, 1943]
深度学习:神经网络基础
# GW: DL
- 激活函数 \(f\) 举例
- S 性函数(sigmoid)
- ReLU 修正线性单元
- 双性 S 性函数(tanh)
- Leaky ReLU
- ELU 指数线性单元
- ...

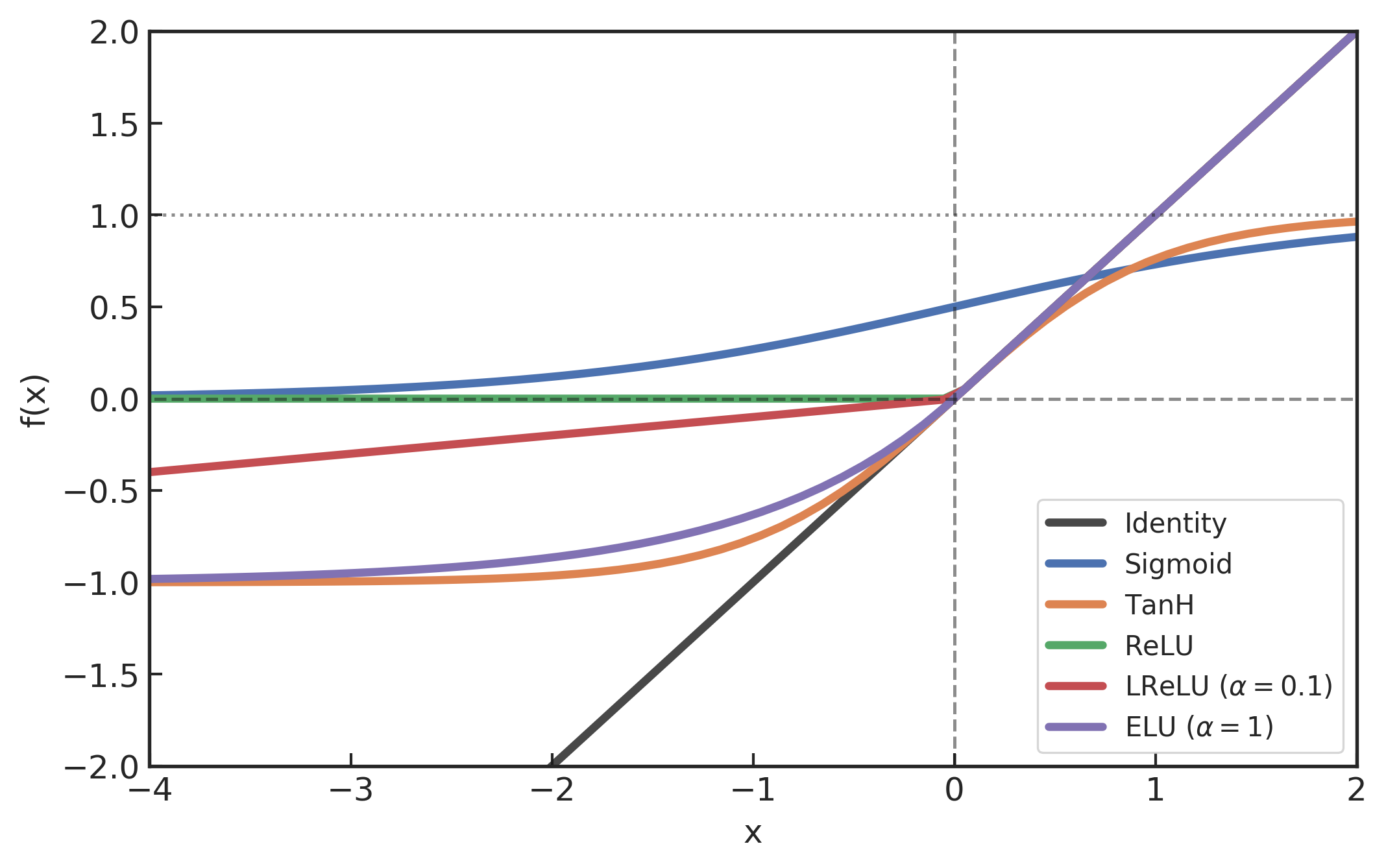
深度学习:神经网络基础
# GW: DL
- 一个神经元
- Input:一个样本
- Input:N 个样本
- 线性矩阵操作之后,会经过激活函数实现元素级操作,
使得神经元“非线性化”。
- Input:一个样本
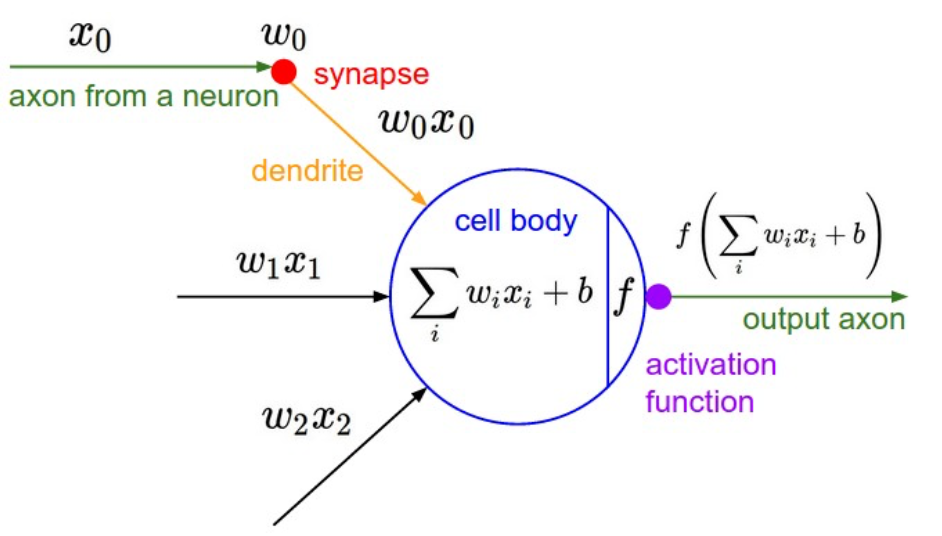
深度学习:神经网络基础
# GW: DL
- M 个神经元
- Input:一个样本
- Input:N 个样本 (with activation function)
- Input:一个样本
- 留意:
- 数据矩阵的行(样本数)、列(特征维度)
- 一个隐层的行(对应于数据特征维度)、列(神经元的个数)
- 每一层的非线性映射过程中,输入输出的数据矩阵行(样本数)保持不变
- 过参数化 (Over-parameterization) 的神经网络
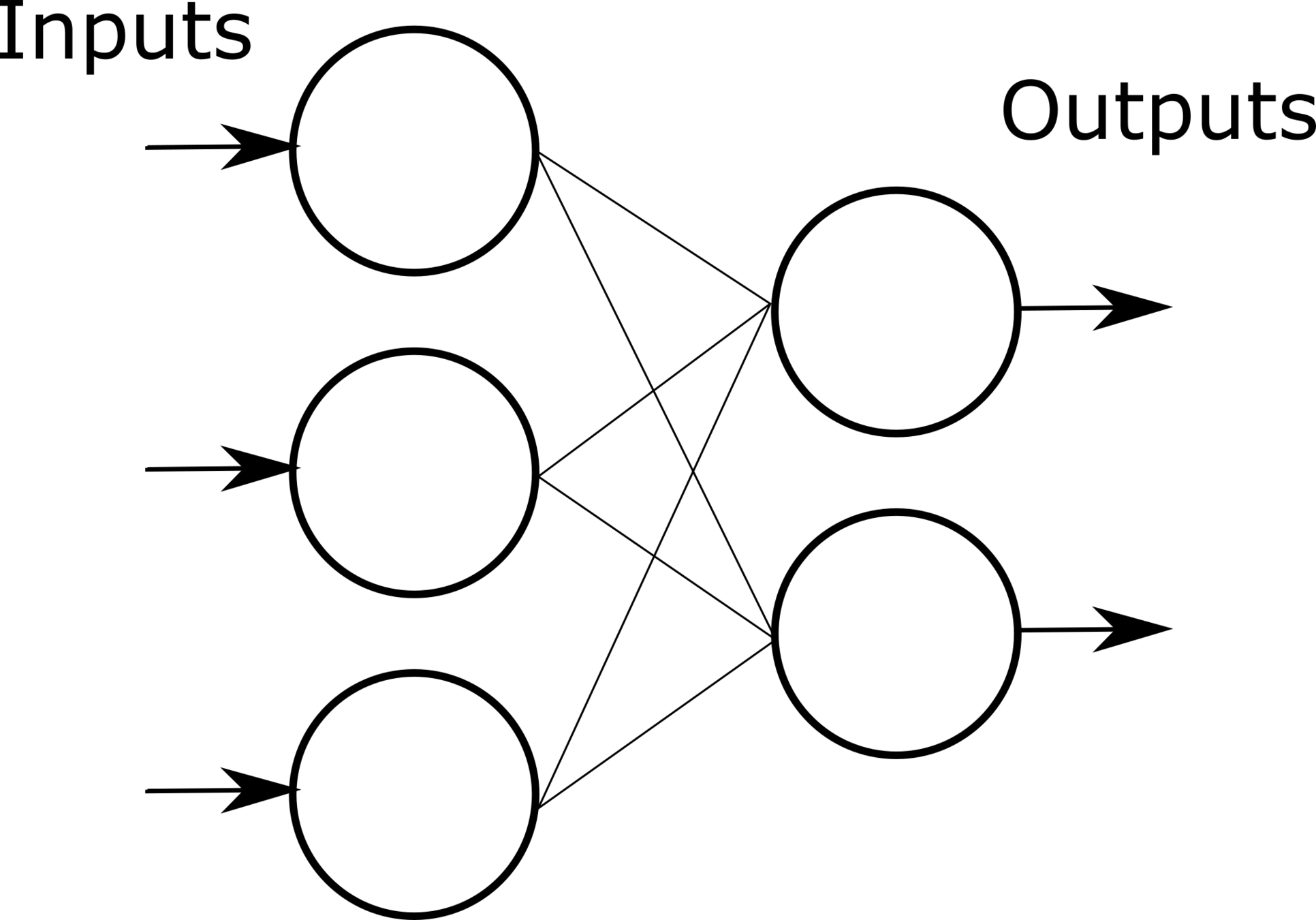
深度学习:神经网络基础
# GW: DL
-
万有逼近定理 (Universal Approximation Theorem)
- 只要函数 \(y=\varphi(x)\) 是连续的,就存在神经网络以任意精度逼近它。
- 如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。
- 注意:
- 上述定理只是给出了存在性结论,实际应用时\(n,N\)可能非常大,导致运算规模异常庞大。(70年代低谷)
- 神经网络相当于解决了最小二乘法拟合数据时“如何选取函数型”这一本质难点。但是因为参数过多,从神经网络中很难反映出数据背后的机理,所以不适用于机理建模。

[Hornik et al., 1989]
深度学习:神经网络基础
# GW: DL
- 更宽还是更深?更深!
- 在神经元总数相当的情况下,增加网络深度可以比增加宽度带来更强的网络表示能力。
- 深度和宽度对函数复杂度的贡献是不同的,深度的贡献是指数增长的,而宽度的贡献是线性的。

Seide F, Li G, Yu D. Conversational speech transcription using context-dependent deep neural networks[C] Interspeech. 2011.
深度学习:神经网络基础
# GW: DL
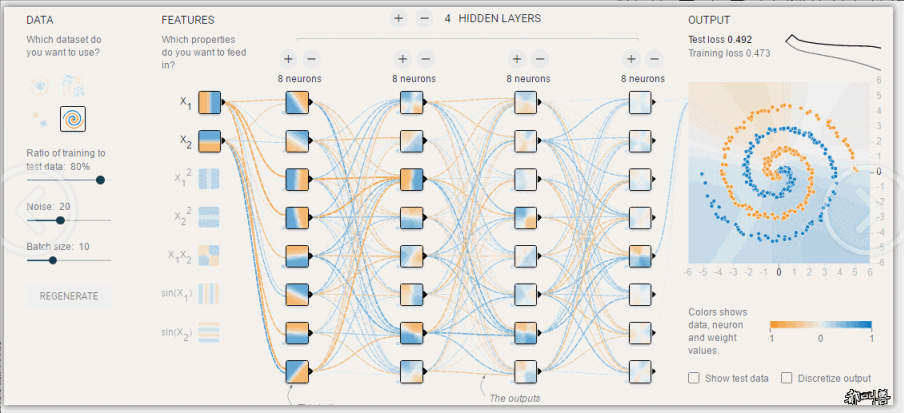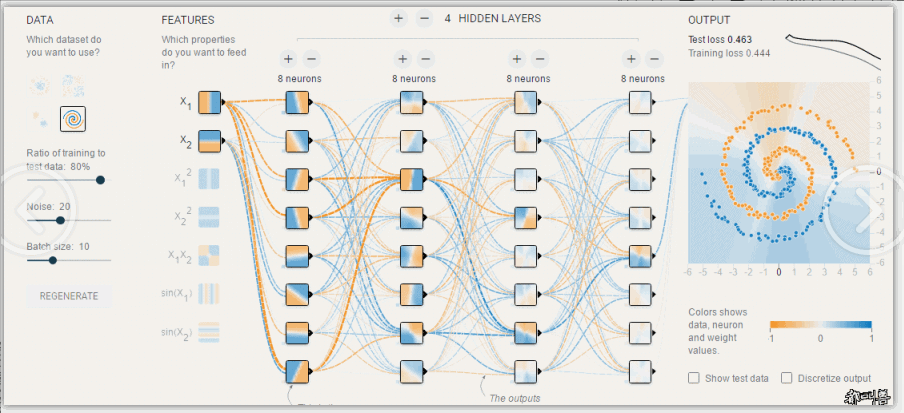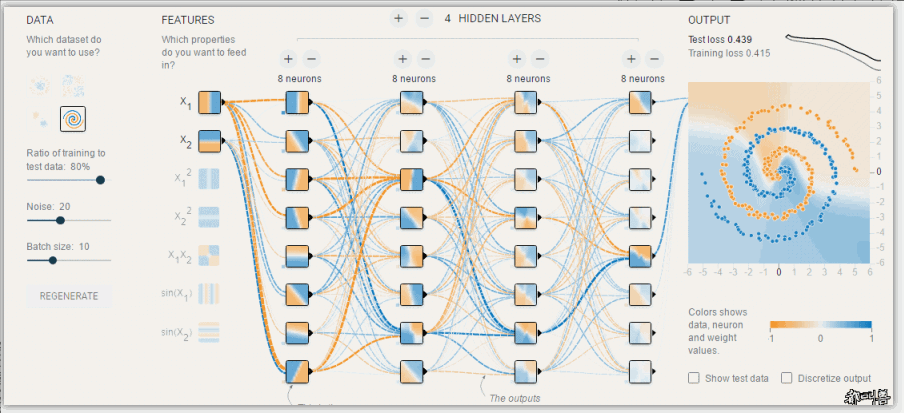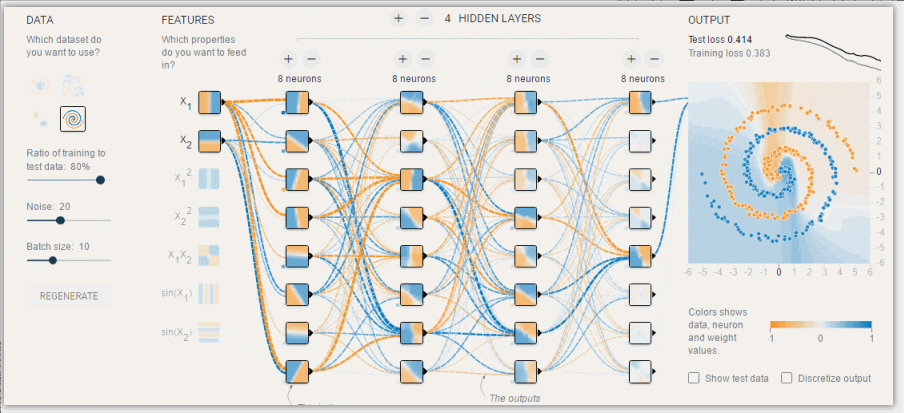
- 神经网络可视化 (https://playground.tensorflow.org/)
深度学习:神经网络基础
# GW: DL
- 神经网络的参数学习:误差反向传播
-
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
-
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小.
-
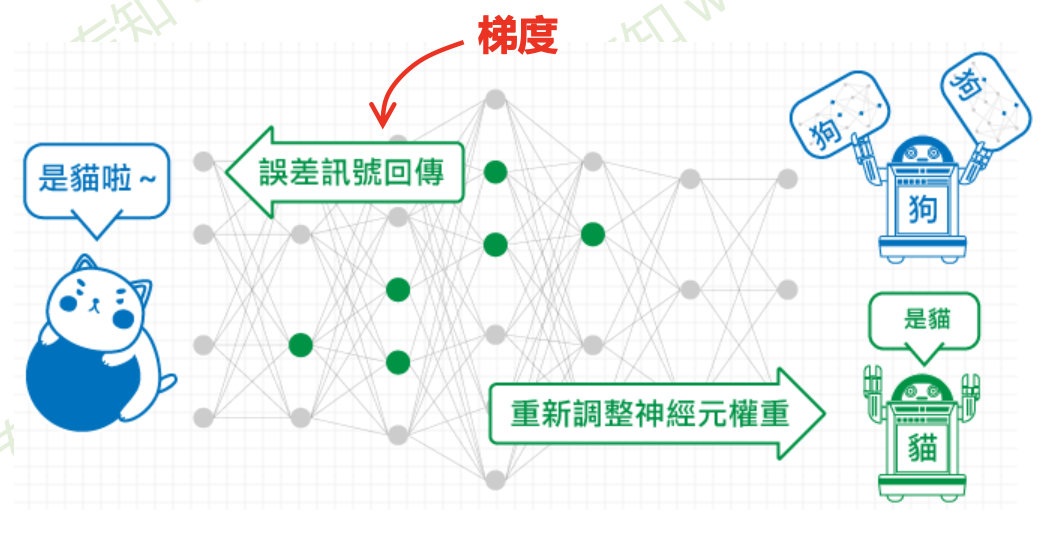
图片取自李宏毅老师《机器学习》课程
深度学习:神经网络基础
# GW: DL
- 优化算法的选择(略)
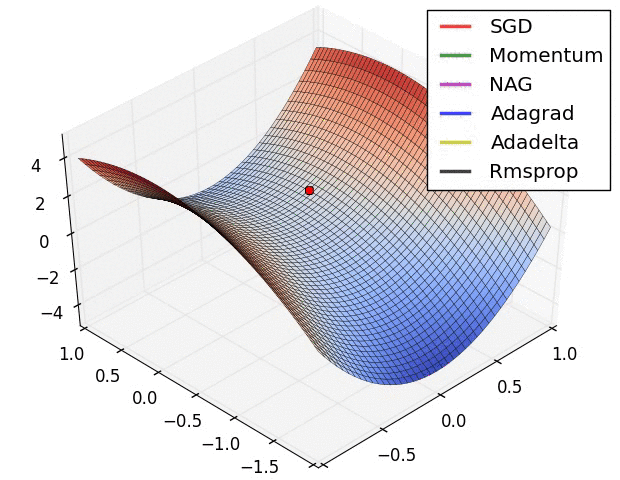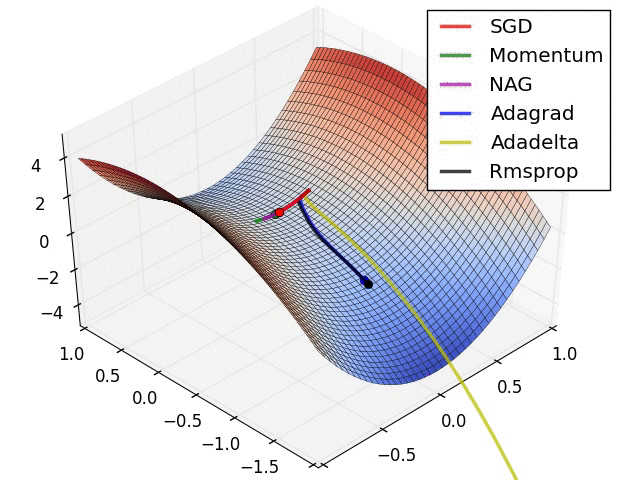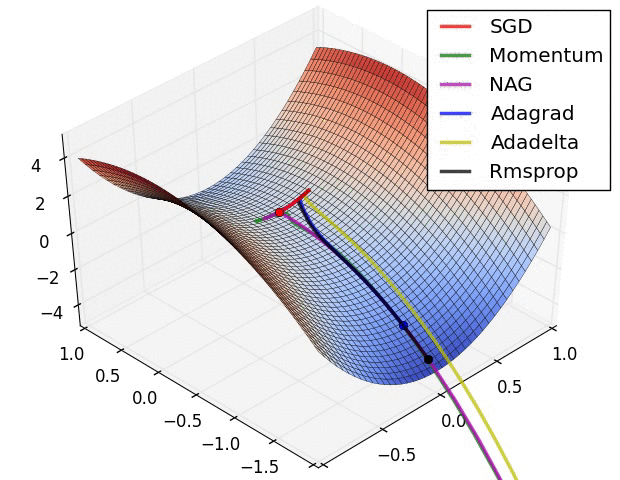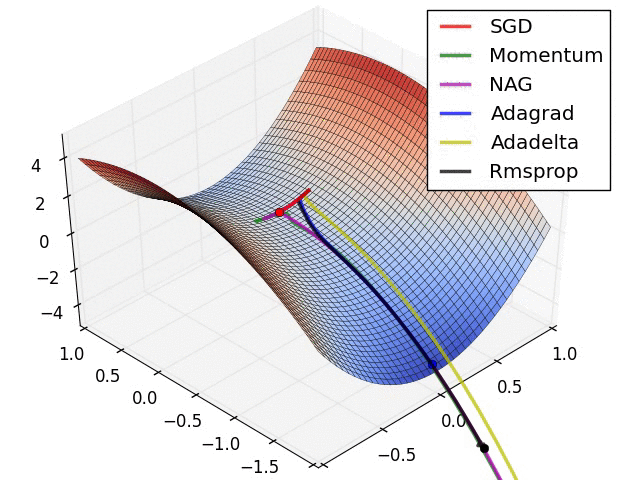
- 神经网络的参数学习:误差反向传播
-
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
-
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
-
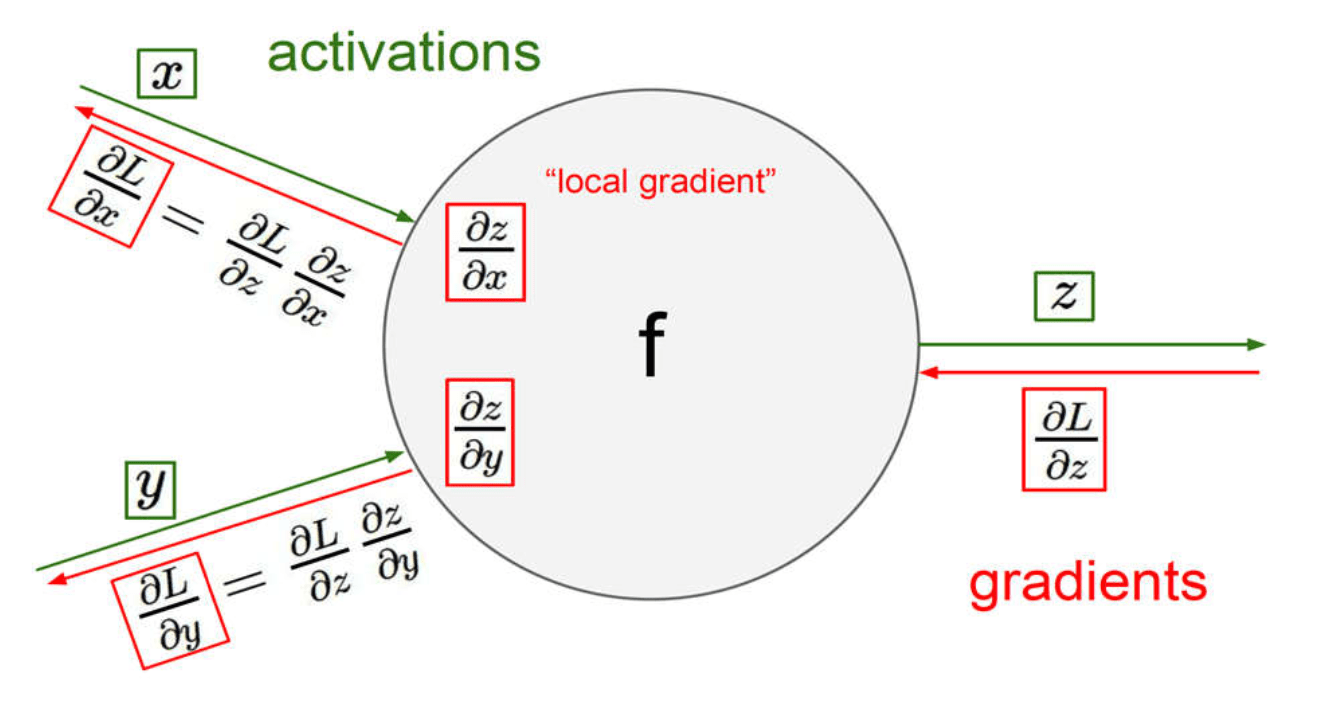
-
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
深度学习:神经网络基础
# GW: DL
- 神经网络的参数学习:误差反向传播
-
多层神经网络可看成是一个复合的非线性多元函数 \(\mathrm{F}(\cdot): X \rightarrow Y\)
-
给定训练数据 \(\left\{x^i, y^i\right\}_{i=1: N}\),希望损失 \(\sum_i \operatorname{loss}\left(F_w\left(x^i\right), y^i\right)\) 尽可能小
-
-
反向传播算法 (BP) 的目标是找损失函数关于神经网络中可学习参数 (\(w\)) 的偏导数(证明略)
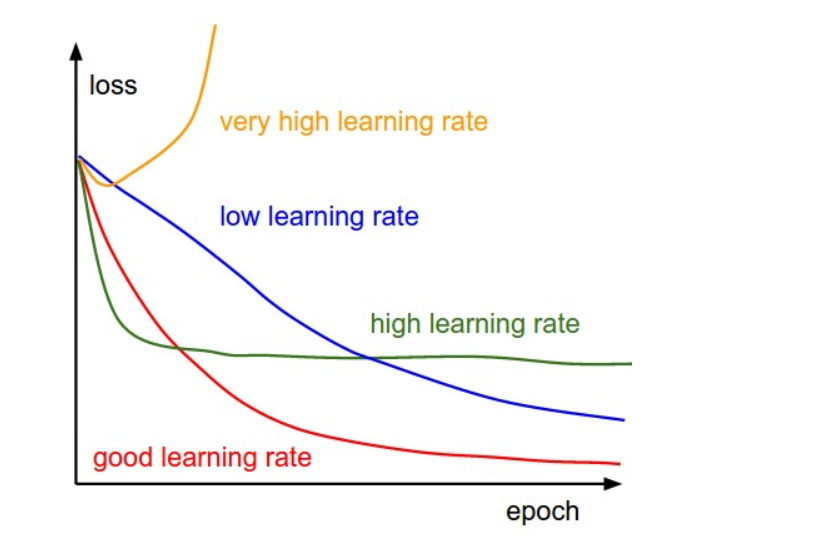
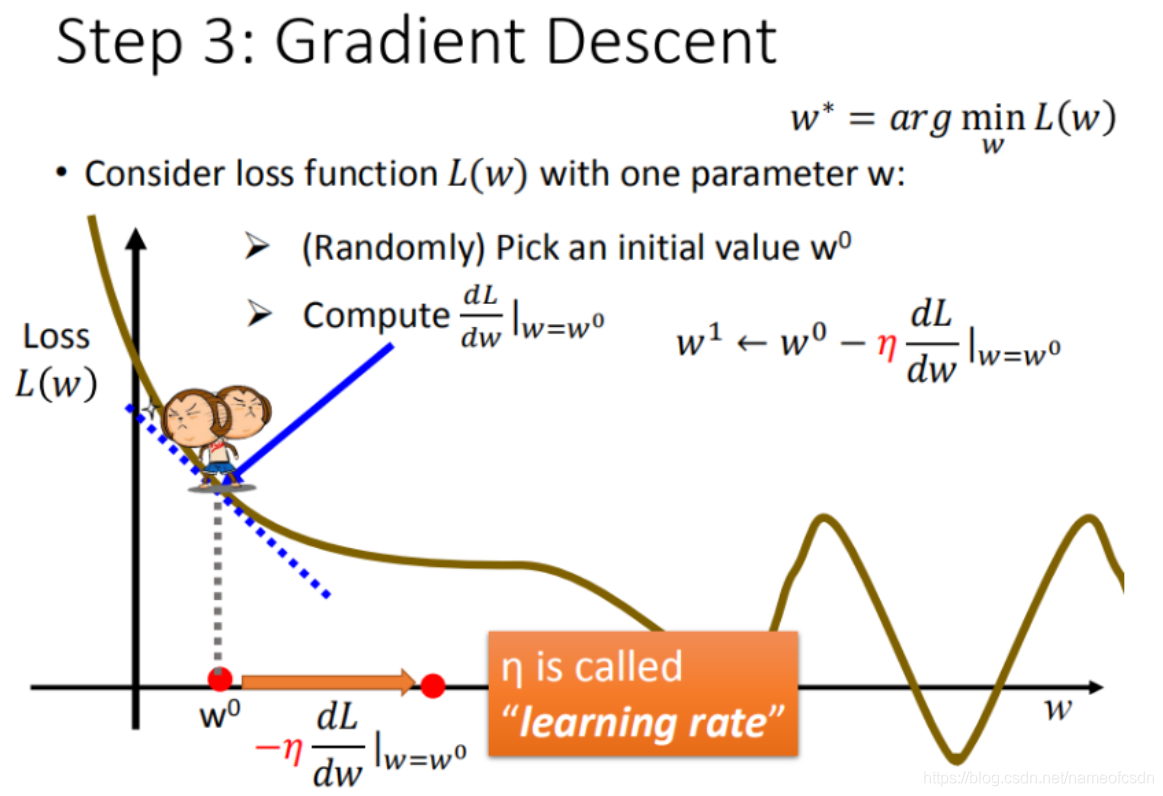
- 学习率 \(\eta\) 与学习率策略
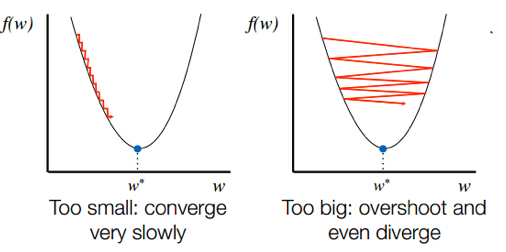
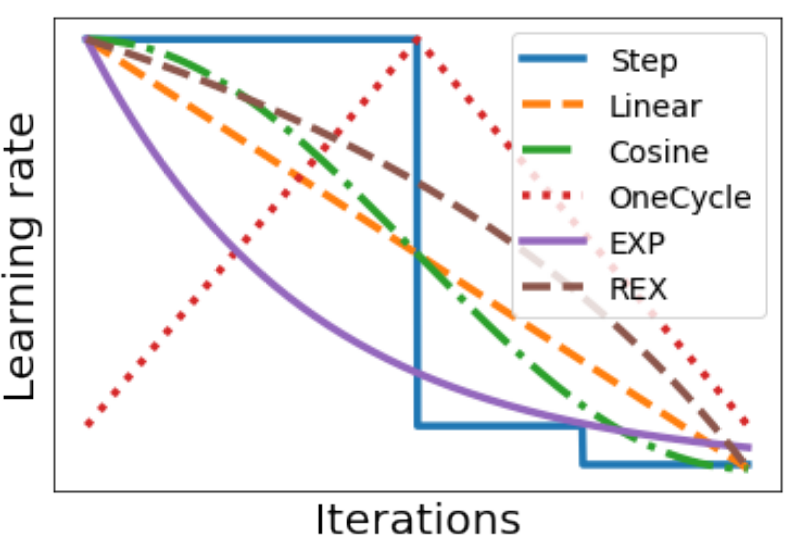
Credit: Cameron R. Wolfe
From here

- 分类任务的评价指标
- 模型调优,过拟合与欠拟合
- 没有免费午餐定理(No free lunch theorem)
模型性能评估与测试调优

模型性能评估与测试调优
# GW: DL
分类任务的评价指标
- 评价指标
- 评价指标的选择会影响如何测量和比较机器学习算法的性能,也会影响我们在如何权衡结果中不同特征的重要性以及您选择哪种算法的最终选择。
- 使用不同的性能度量往往会导致不同的评判结果。
- 模型的 泛化性
- 机器学习模型的学习目标是从目标领域内的训练数据到任意其他数据上的性能良好,由此可以在未来对模型没有见过的数据进行预测。
模型性能评估与测试调优
# GW: DL
分类任务的评价指标
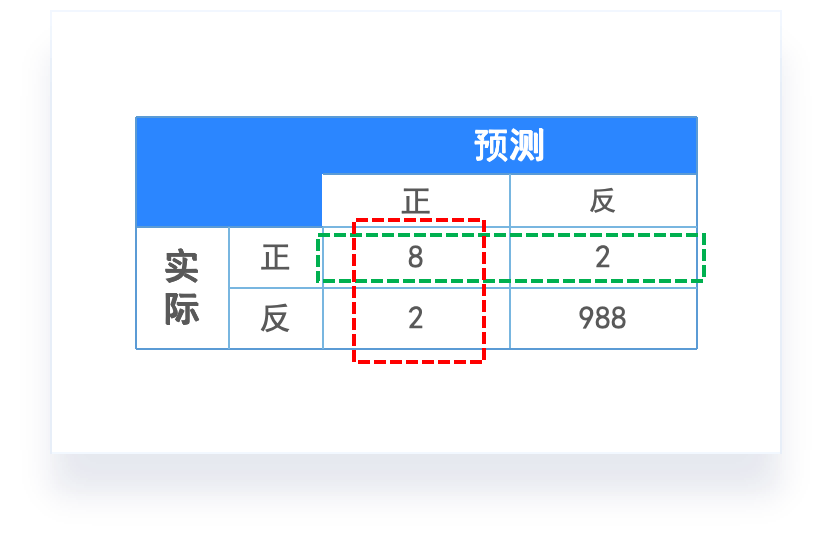
- 准确率(Accuracy):也就是正确分类的样本数占总样本数的比例。但这个指标对于不均衡数据而言,模型会有掉入“高准确率陷阱”。
- 举个例子:
- 如果有一种癌症,1000 个人中只有 1 个人会得,也就是患这个癌症的概率为 0.1%。那么这个时候,我们不用机器学习,给我 1000 个人预测是否患癌,我只要全部猜没有,那么我就只会有 1 个人判错,我的准确率达到了 99.9%。
- 那么如果我们用机器学习来训练出一个预测一个人是否患有这个癌症的模型,就算这个模型最后的准确率达到了 98%,那也是没有意义的。
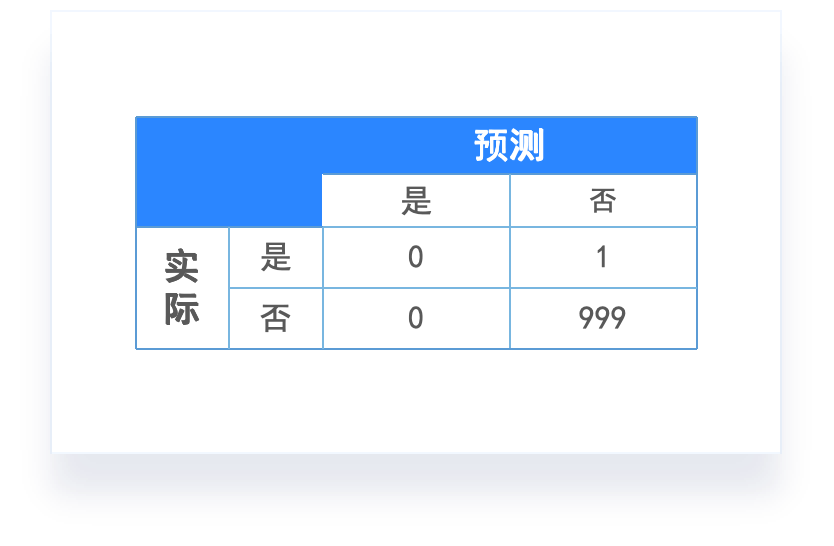

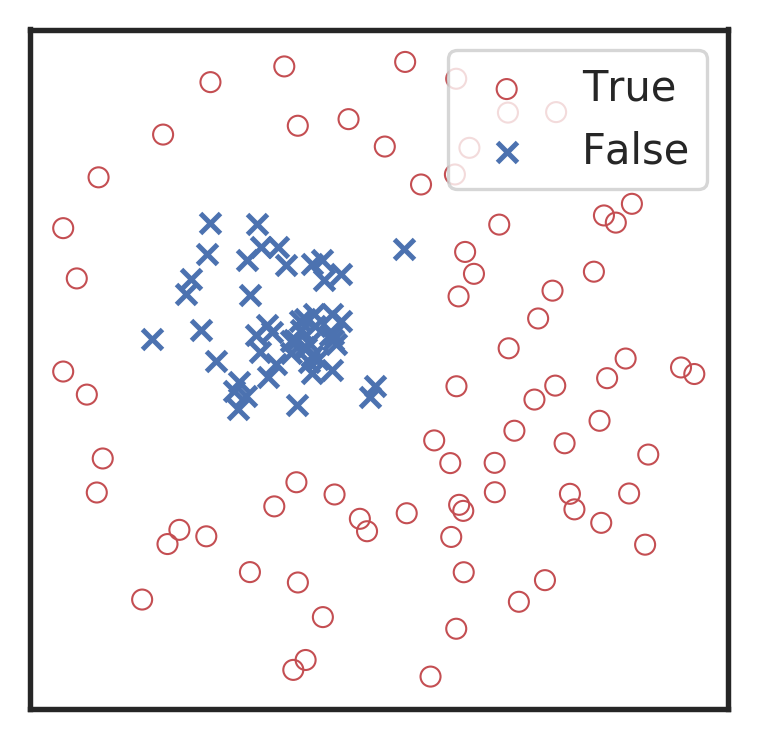
混淆矩阵
模型性能评估与测试调优
# GW: DL
分类任务的评价指标
混淆矩阵

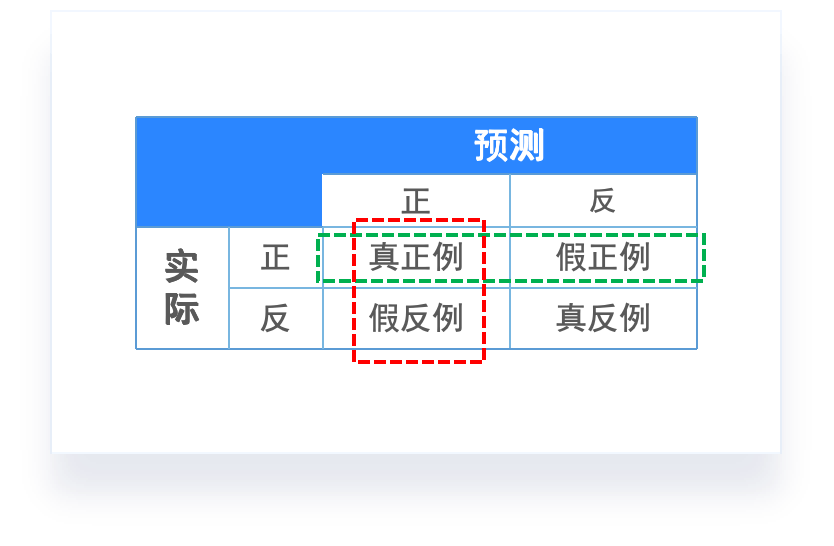
-
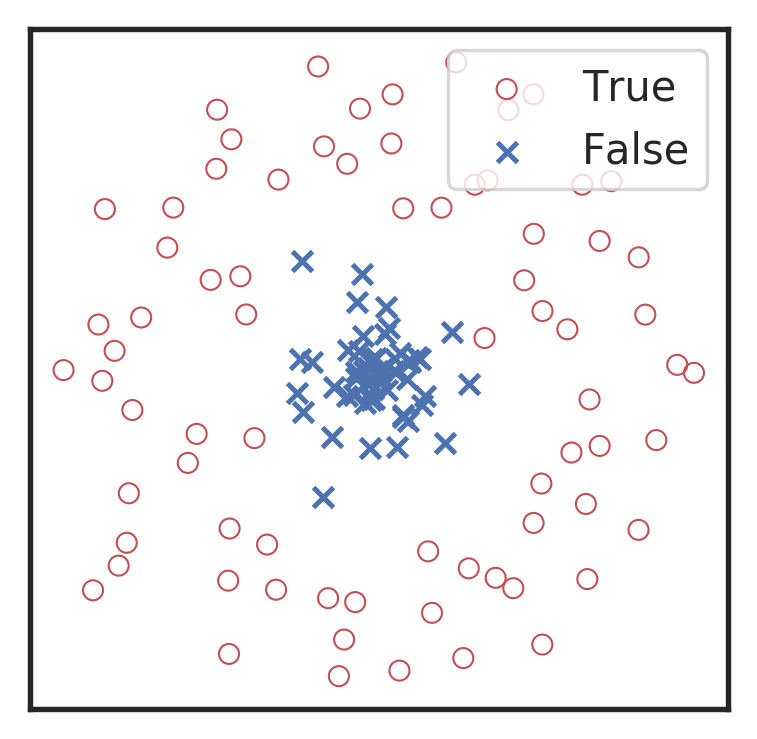
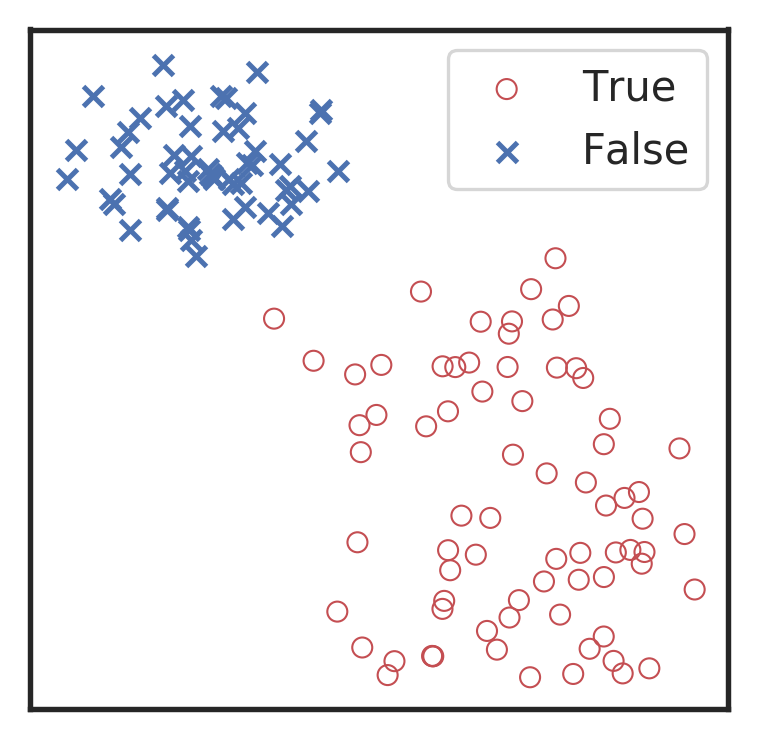
混淆矩阵(Confusion matrix):样本的真实分类值作为一个维度,把样本预测分类值作为一个维度。
- 真正例:预测为正,实际也为正。
- 真反例:预测为反,实际也为反。
- 假正例:预测为反,但实际为正。
- 假反例:预测为正,但实际为反。
模型性能评估与测试调优
# GW: DL
分类任务的评价指标
-
精确率(Precision):在所有预测的正类的样本中,预测正确的样本所占有的比例 。
- 召回率(Recall):在所有真实类别为正类的样本中,被正确预测为正的样本所占的比例。
- 精确率(查准率)评估预测的 准不准;
- 召回率(查全率)评估找的 全不全。
混淆矩阵

模型性能评估与测试调优
# GW: DL
分类任务的评价指标
-
精确率(Precision):在所有预测的正类的样本中,预测正确的样本所占有的比例 。
- 召回率(Recall):在所有真实类别为正类的样本中,被正确预测为正的样本所占的比例。
- 精确率(查准率)评估预测的 准不准;
- 召回率(查全率)评估找的 全不全。
混淆矩阵
模型性能评估与测试调优
# GW: DL
分类任务的评价指标
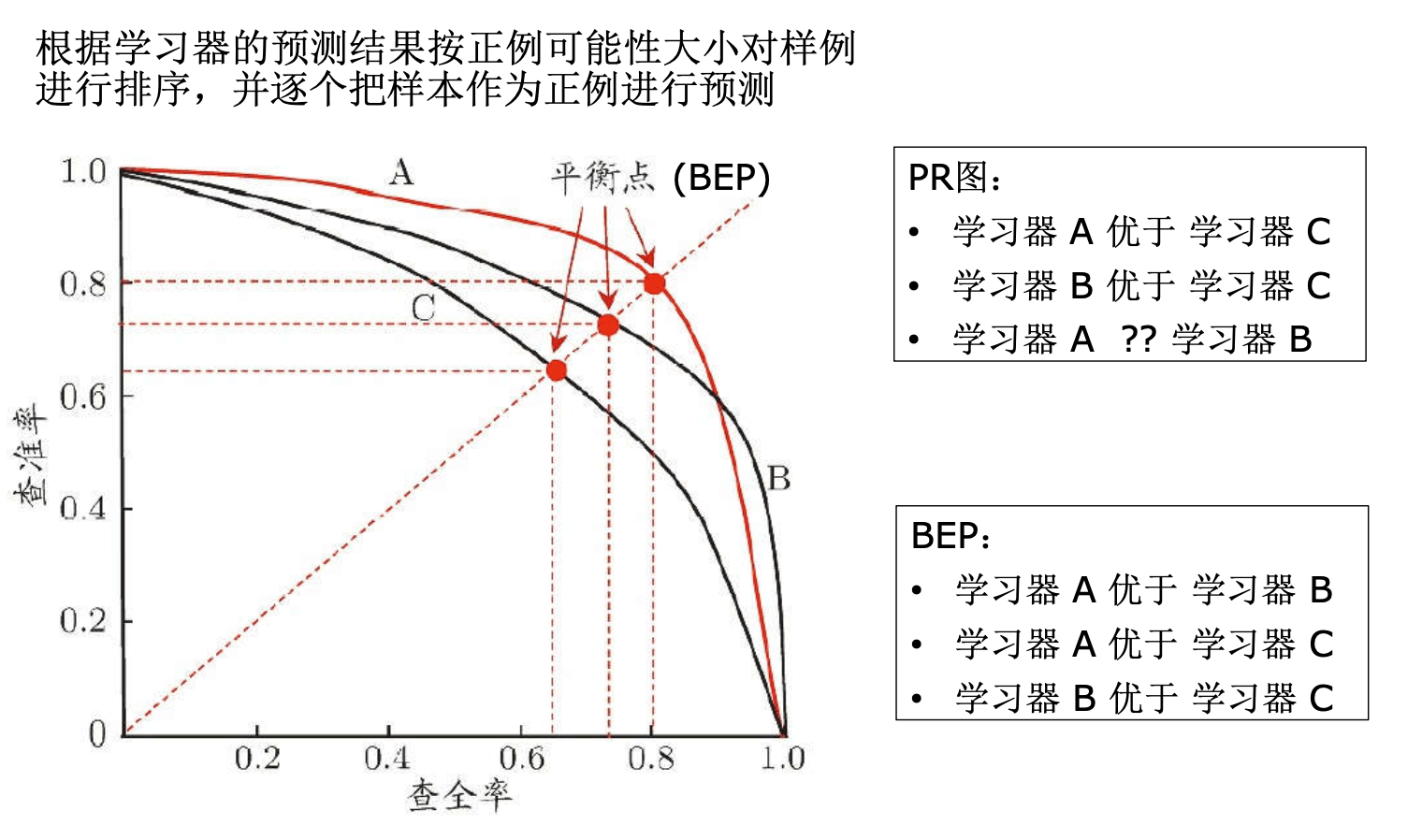
- F1调和平均
- 比 BEP 更常用的 F1 度量:
\(F 1=\frac{2 \times P \times R}{P+R}=\frac{2 \times T P}{\text { 样例总数 }+T P-T N}\) - F1:查准率与查全率的调和平均, 调和平均更注重较小值的影响
- 若对查准率/查全率有不同偏好:
\(F_\beta=\frac{\left(1+\beta^2\right) \times P \times R}{\left(\beta^2 \times P\right)+R} \)
\(\beta>1\) 时查全率有更大影响; \(\beta<1\) 时查准率有更大影响 - \(F_{\beta}\) : 查准率与查全率的加权调和平均
- 比 BEP 更常用的 F1 度量:
- ROC,AUC(下一讲)
模型性能评估与测试调优
# GW: DL
模型调优,过拟合与欠拟合
- 调参过程相似:先产生若干模型,然后基于某种评估。
- 算法的参数:一般由人工设定,亦称“超参数”
- 模型的参数:一般由学习确定
- 参数调得好不好,往往对最终性能有关键影响。

模型性能评估与测试调优
# GW: DL
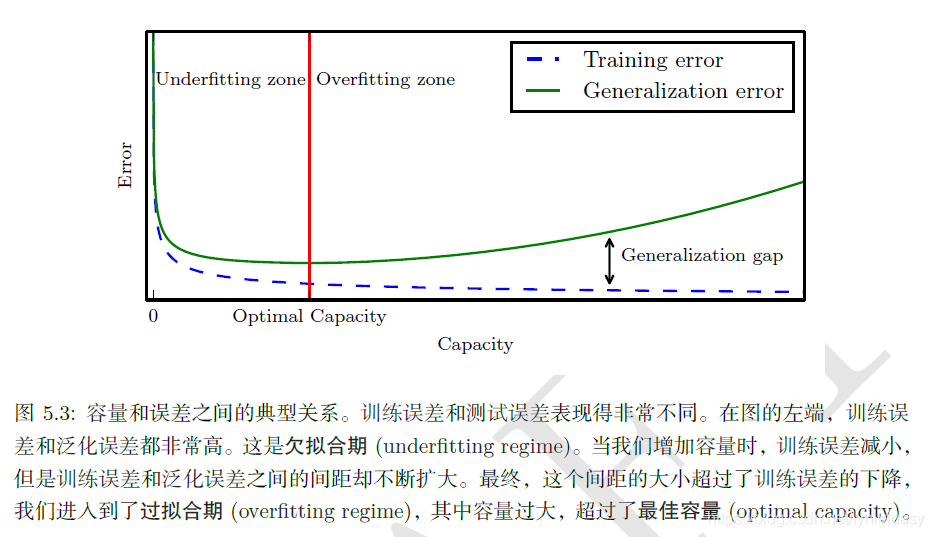
模型调优,过拟合与欠拟合
- 模型泛化性的评价:
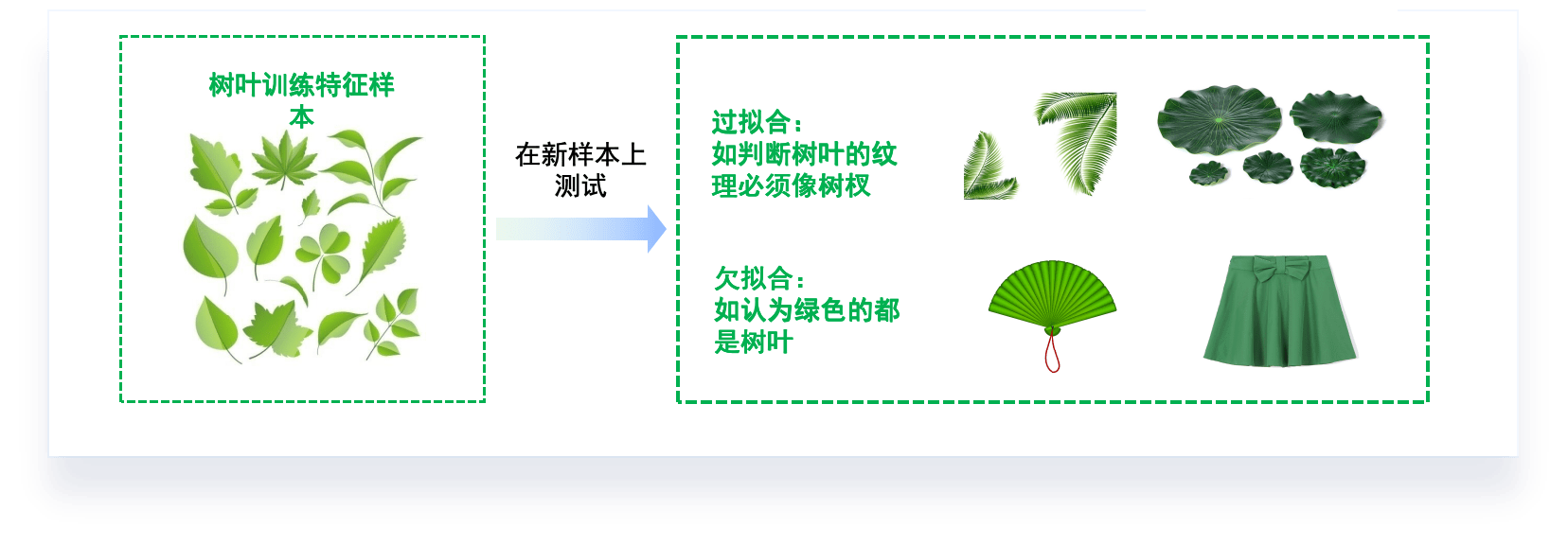
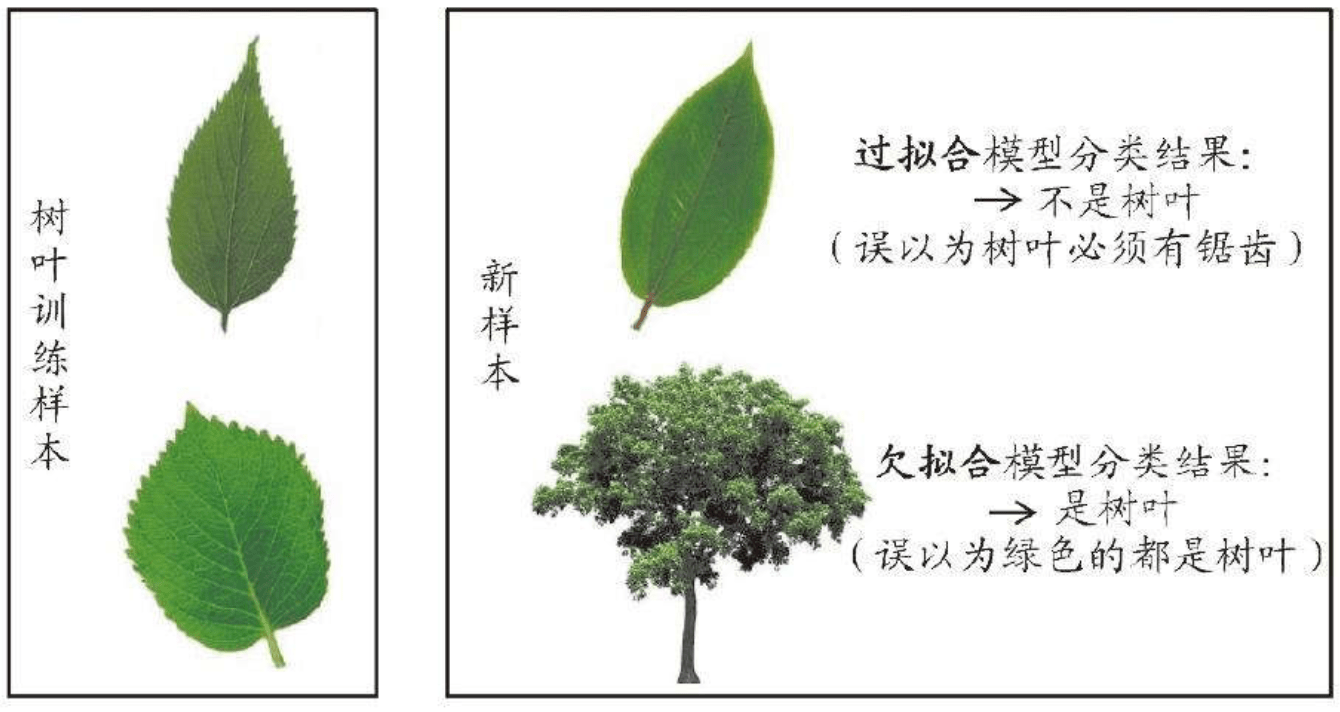
- 过拟合(over-fitting):在训练数据上表现良好,在未知数据上表现差。
- 欠拟合(under-fitting):在训练数据和未知数据上表现都很差。
- 解决办法:重新选数据,重新定模型
模型性能评估与测试调优
# GW: DL
模型调优,过拟合与欠拟合
- 讨论机器学习模型学习和泛化的好坏时,通常使用术语:过拟合和欠拟合。
- 模型泛化性的评价:
- 过拟合(over-fitting):在训练数据上表现良好,在未知数据上表现差。
- 欠拟合(under-fitting):在训练数据和未知数据上表现都很差。
- 解决办法:重新选数据,重新定模型
- 模型怎么定?
- 不同模型复杂度在评价指标上的表现
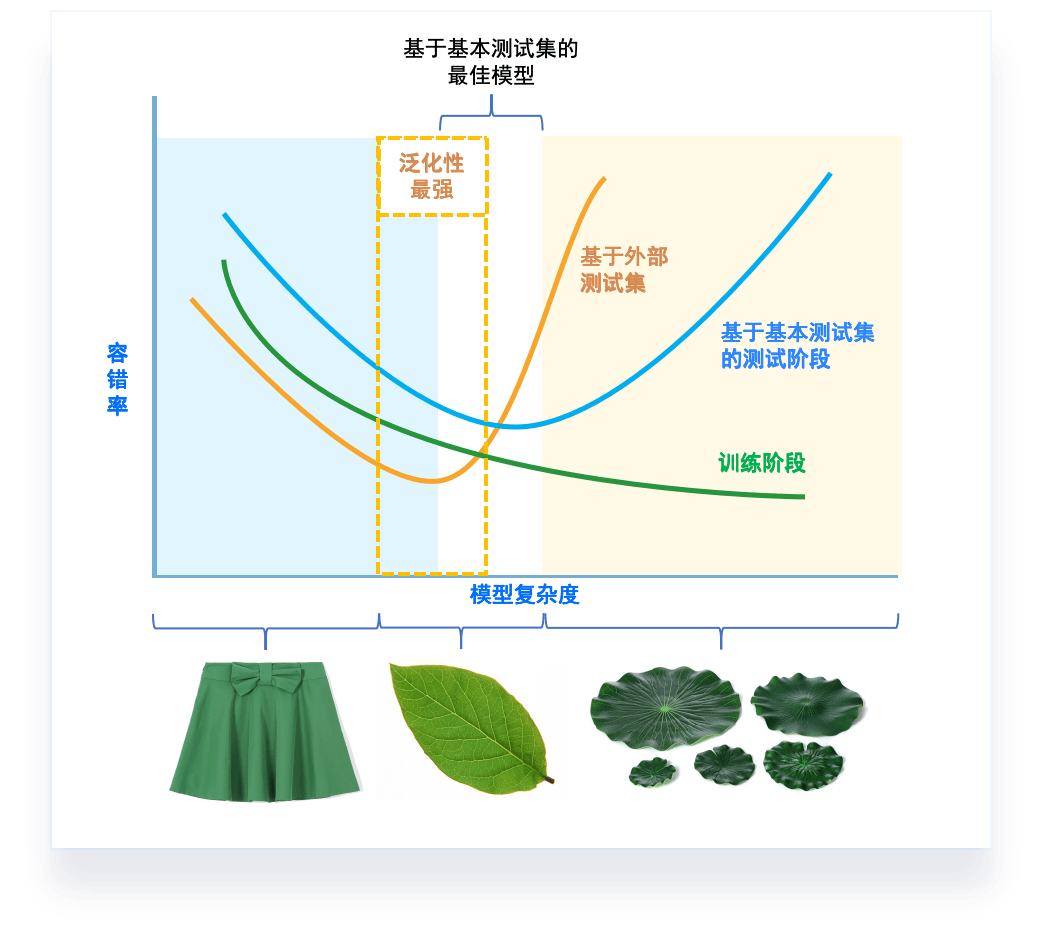
素材来源:DOI: 10.1177/2374289519873088
模型性能评估与测试调优
# GW: DL
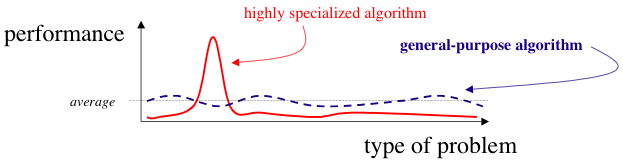
没有免费午餐定理(No free lunch theorem)
- 对于所有可能的域(所有可能的问题实例均来自均匀的概率分布),算法A和B的平均性能相同。
Wolpert D H. The lack of a priori distinctions between learning algorithms[J]. Neural computation, 1996, 8(7): 1341-1390.
没有免费午餐理论对于个人的指导
- 在依赖模型或搜索算法之前,请始终检查您的假设。
- 没有“超级算法”能完美适用于所有数据集。
- 这是因为几乎所有非死记硬背的(non-rote)机器学习算法或统计模型都需要对预测变量和目标变量之间的关系做出了一些假设,从而将 偏差 (bias)引入了模型,具体称为 归纳或学习偏差(inductive or learning bias)。
- 无偏差学习是徒劳的,因为没有先验假设的学习者在提供新的,看不见的输入数据时将没有合理的基础来创建估计。
- 这些假设使得某些算法在某些数据集上表现优秀,而在其他数据集上表现不佳。换句话说,一个算法的有效性取决于它的偏差(即假设)与数据的真实性质之间的匹配程度。这就意味着,对于任何给定的算法,总会存在一些它无法有效处理的数据集。
- 算法的假设适用于某些数据集,但不适用于其他数据集。该现象对于理解欠拟合 (underfitting)的概念 和 偏差/方差折衷(bias/variance tradeoff)至关重要 。

模型性能评估与测试调优
# GW: DL
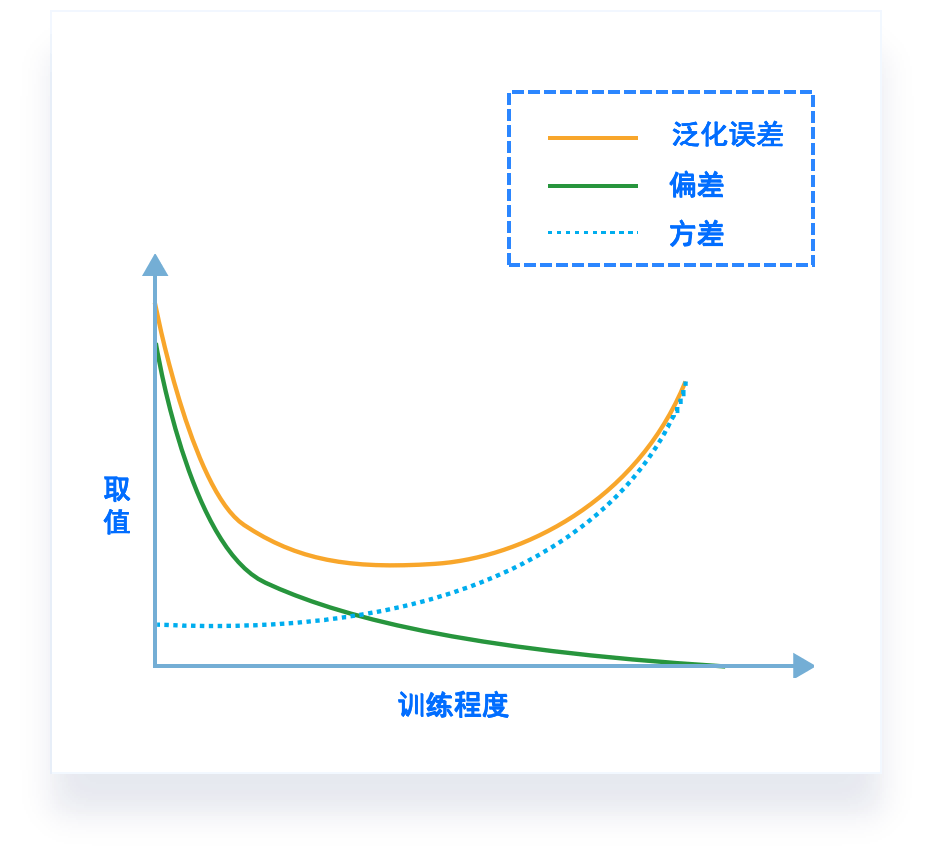
偏差-方差窘境(bias-variance dilemma)
- 一般而言,偏差与方差存在冲突:
- 训练不足时,学习器拟合学习能力不强,偏差主导
- 随着训练程度加深,学习器拟合能力逐渐增强,方差逐渐主导
- 训练充足后,学习器的拟合能力很强,方差主导
泛化性能 是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定。

模型性能评估与测试调优
# GW: DL
模型调优,过拟合与欠拟合
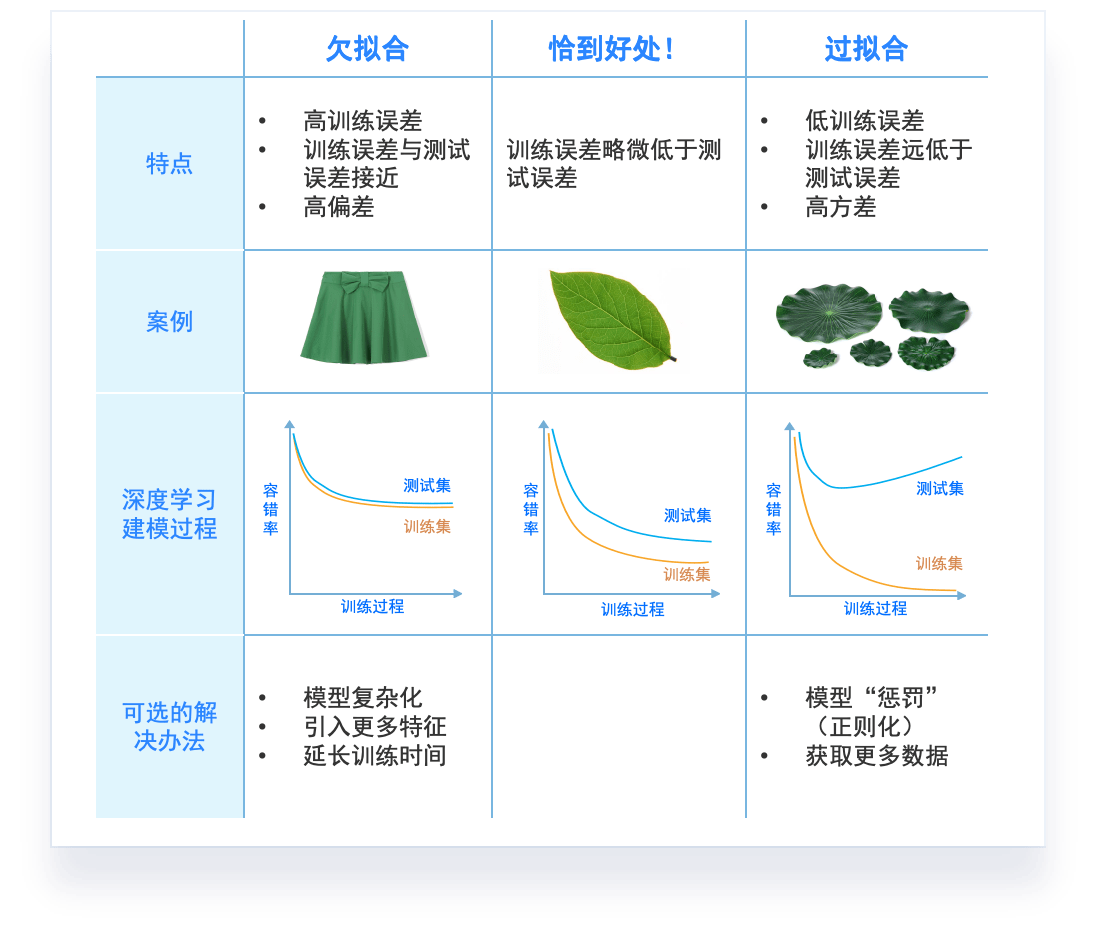
过拟合和欠拟合是机器学习中常见的两种问题。
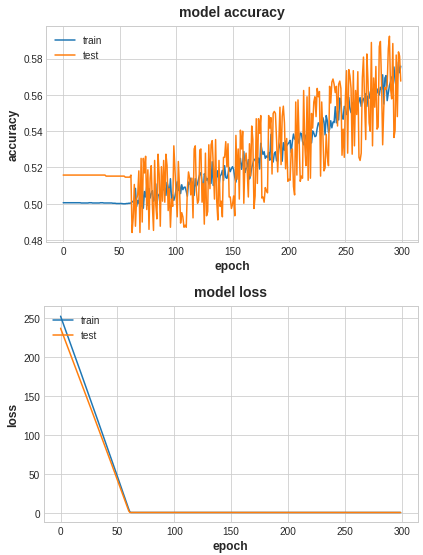
- 过拟合:当模型在训练数据上表现得过于优秀,但在测试数据或新数据上表现不佳时,我们称模型出现了过拟合。过拟合的模型过于复杂,以至于它甚至学习了训练数据中的噪声。在图表中,过拟合通常表现为训练误差持续降低,但验证误差开始上升。
- 解决过拟合的方法包括:
- 增加数据量:更多的数据可以帮助模型学习到更多的信息,减少过拟合的可能性。
- 正则化:正则化是一种添加惩罚项的技术,可以防止模型的权重过大,从而降低模型复杂度。
- 早停:在验证误差开始上升时停止训练,可以防止模型过度学习训练数据。
- 降低模型复杂度:简化模型,如减少神经网络的层数或神经元数量,可以降低模型的复杂度,减少过拟合的可能性。
- ...
- 欠拟合:当模型在训练数据和测试数据上的表现都不佳时,我们称模型出现了欠拟合。欠拟合的模型过于简单,无法捕捉到数据中的模式。在图表中,欠拟合表现为训练误差和验证误差都很高。
- 解决欠拟合的方法包括:
- 增加模型复杂度:增加更多的特征,或者使用更复杂的模型,如增加神经网络的层数或神经元数量,可以帮助模型捕捉到更复杂的模式。
- 减少正则化:如果模型过于简单,可能是正则化过度,可以尝试减少正则化的程度。
- 更换模型:如果当前模型无法很好地拟合数据,可以尝试更换其他类型的模型。
- ...
模型性能评估与测试调优
# GW: DL
模型评估与选择
- 比较检验:在某种度量下取得评估结果后,是否可以直接比较以评判优劣?
- No! 因为:
- 测试性能不等于泛化性能
- 测试性能随着测试集的变化而变化
- 很多机器学习算法本身有一定的随机性
- No! 因为:
- 机器学习任务 \(\rightarrow\) “概率近似正确”
-
统计假设检验 (hypothesis test) 为学习器性能比较提供了重要依据【应需要有统计显著性作为评判依据】
-
两学习器比较
-
交叉验证 t 检验(基于成对 t 检验)
-
McNemar 检验(基于列联表、卡方检验)
-
-
多学习器比较
-
Kolmogorv-Smirnov Test (K-S检验)
-
Friedman 检验 (基于序值,F检验;判断“是否相同”)
-
Nemenyi 后续检验(基于序值,进一步判断两两差别)
-
-
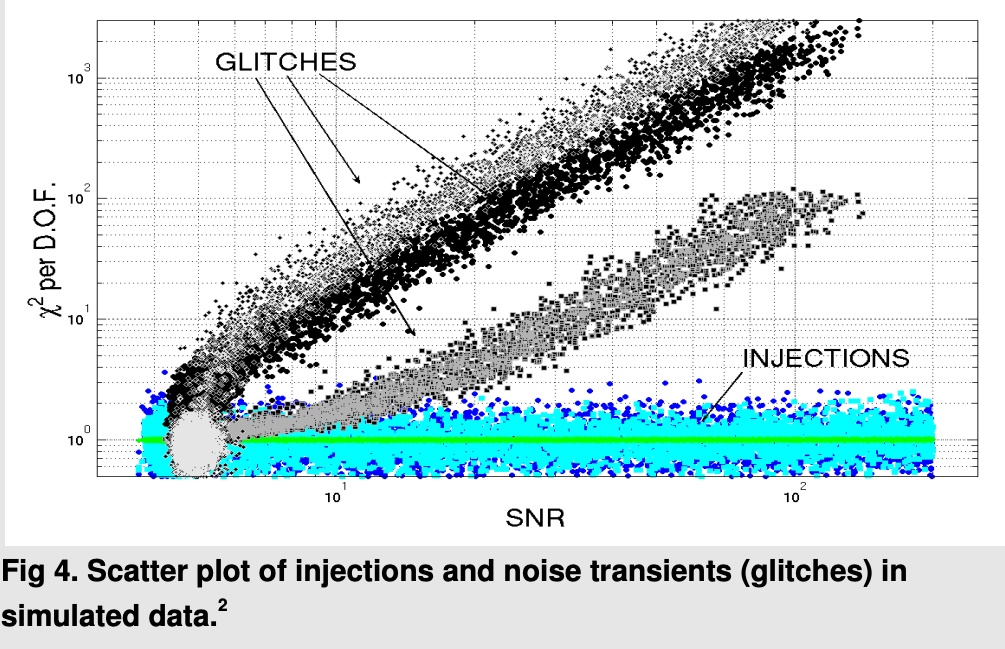
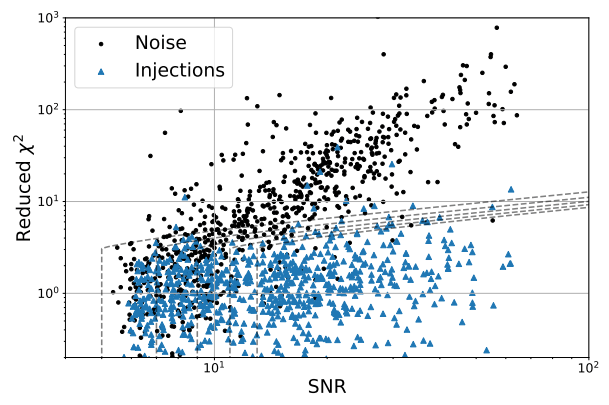
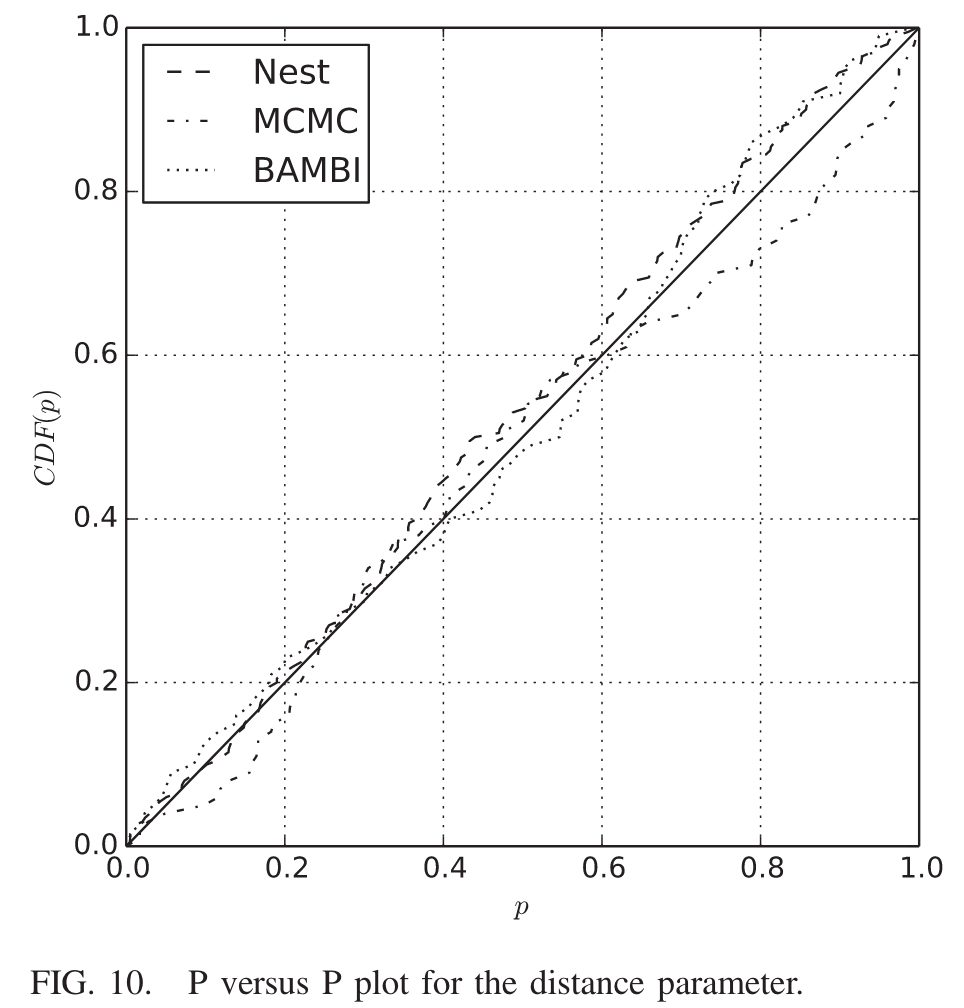
Veitch, J., et al. Physical Review D 91, no. 4 (February 2015): 042003. https://doi.org/10.1103/PhysRevD.91.042003.

# Homework
Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
- 基础及拓展作业:
- 一起来打怪之 Credit Scoring 练习:homework_credit_scoring_finetune_ensemble.ipynb
- 在 homework 分支上 PR。
- Kaggle是一个由Google所有的数据科学和机器学习竞赛平台。它为数据科学家和机器学习工程师提供了一个可以共享和协作的环境,用户可以在平台上找到并发布数据集,探索和构建模型,运行数据科学工作流,以及参加各种机器学习竞赛。https://www.kaggle.com
- Kaggle的主要特点包括:
- 竞赛:Kaggle举办了许多由企业和研究机构赞助的机器学习竞赛。这些竞赛涵盖了各种问题,从图像分类到自然语言处理,参赛者可以通过解决实际问题来提升自己的技能。
- 数据集:Kaggle拥有一个庞大的公开数据集库,用户可以在这里找到各种类型的数据集,并可以上传自己的数据集供他人使用。
- Kernels:Kaggle的Kernels是一种共享代码的方式,用户可以在Kernels中编写代码,进行数据分析和建模,并将其分享给其他用户。
- 社区:Kaggle有一个活跃的社区,用户可以在论坛上讨论问题,分享想法和经验,以及学习新的技术和方法。
- 学习:Kaggle还提供了一系列的数据科学和机器学习教程,帮助用户学习新的技能和知识。
- 总的来说,无论你是数据科学的新手,还是经验丰富的专家,Kaggle都是一个学习,实践,和分享知识的好地方。
通向自我实现之路:Kaggle
- 赞助单位
- 中科曙光
