引力波数据探索:编程与分析实战训练营
第 4 部分 深度学习基础


主讲老师:王赫
2023/12/29
ICTP-AP, UCAS



卷积神经网络与引力波信号探测
- 卷积(一维)
- 卷积(二维)
- 传统神经网络 vs 卷积神经网络
- Vanilla CNN
- ResNet
深度学习:卷积神经网络

深度学习:卷积神经网络
# GW: DL
- 无处不在的卷积神经网络




Gebru et al. ICCV (2017)
Zhou et al. CVPR (2018)
Shen et al. CVPR (2018)
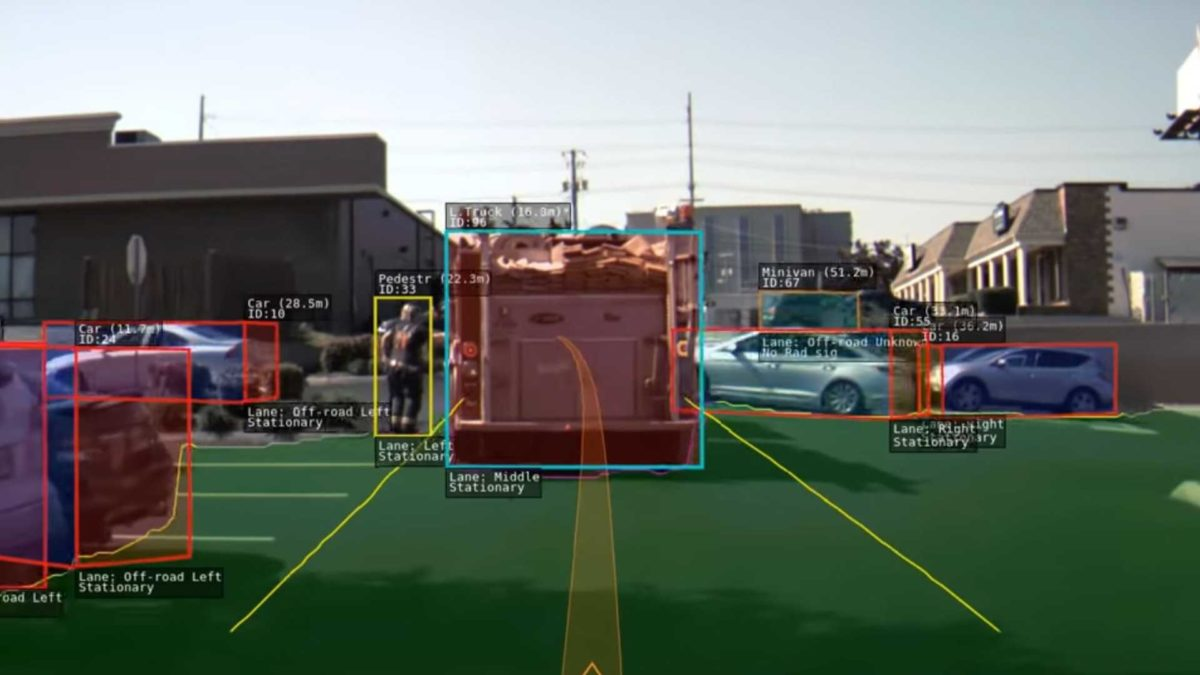
Image courtesy of Tesla (2020)
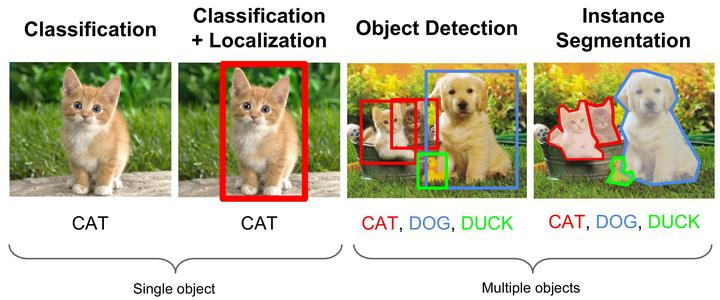
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- Integral Form
- Discrete Form
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- Flip-and-slide Form
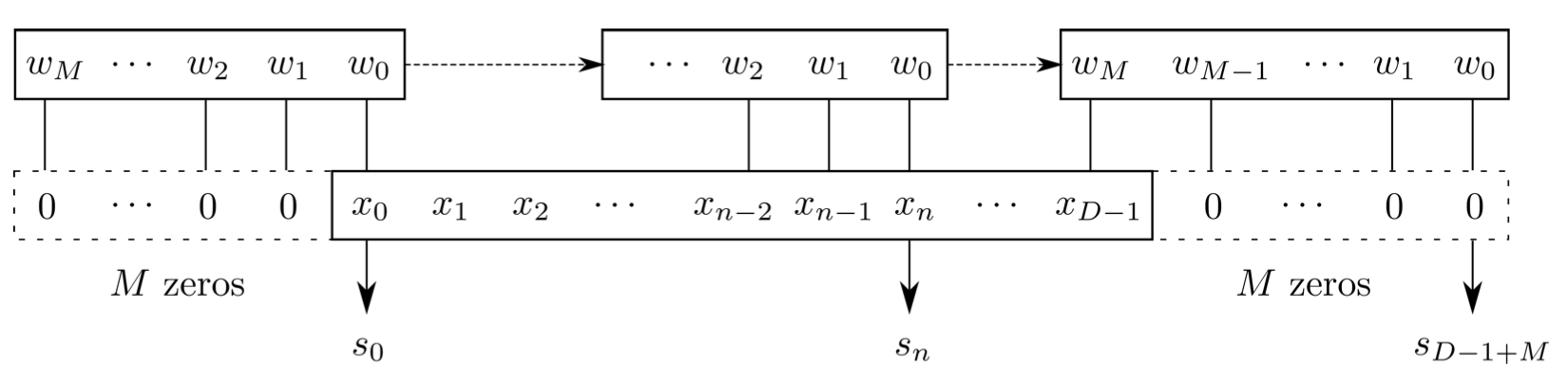
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- Matrix Form :
- It corresponds to a convolutional layer in deep learning with one kernel (channel);
- kernel size (K) of 4; padding (P) is 3; stride (S) is 1.
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- Matrix Form :
- It corresponds to a convolutional layer in deep learning with one kernel (channel);
- kernel size (K) of 3; padding (P) is 2; stride (S) is 1.
- 卷积层
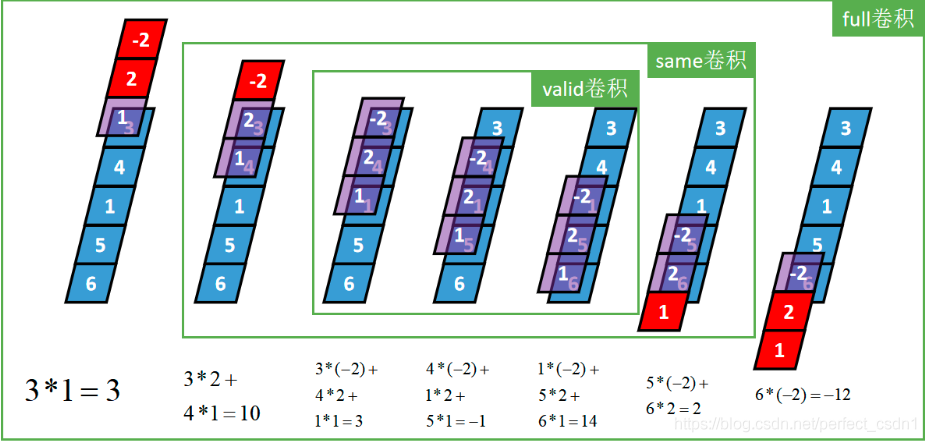
[1,1,5] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- 卷积层
[1,1,5] \(\star\) [1,1,3] \(\rightarrow\) [1,1,3/5/7]
样本个数
“深度”维度
卷积核个数
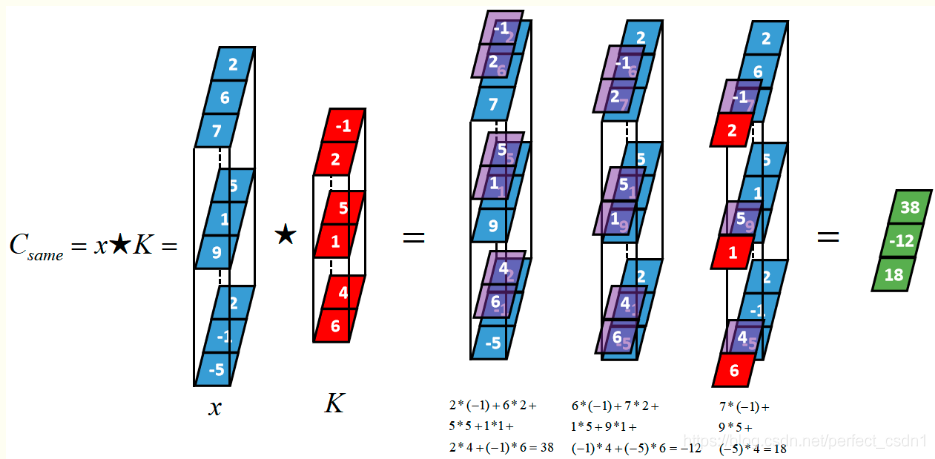
- 具备“深度”维度的输入序列
- 输入张量的深度和卷积核的深度是相等的
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
深度学习:卷积神经网络
# GW: DL
- 卷积(一维)
- 具备“深度”维度的输入序列
- 输入张量的深度和卷积核的深度是相等的
[1,3,3] \(\star\) [1,3,2] \(\rightarrow\) [1,1,3]
“深度”维度
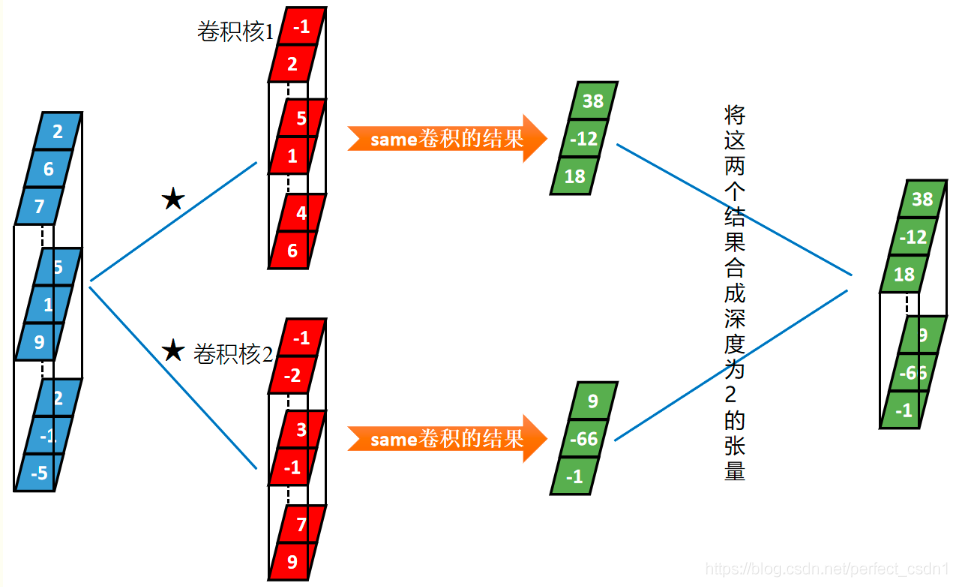
- 具备深度的张量与多个卷积核的卷积
- 同一个张量与多个卷积核本质上是该张量分别于每一个卷积核卷积,然后将每一个卷积结果在深度方向连接起来.
[1,3,3] \(\star\) [2,3,2] \(\rightarrow\) [1,2,3]
“深度”维度
样本个数
卷积核个数
深度学习:卷积神经网络
# GW: DL
- 卷积(二维)
- 深度 \(\rightarrow\) channel
- 卷积的本质
- 有效提取相邻像素间的相关特征
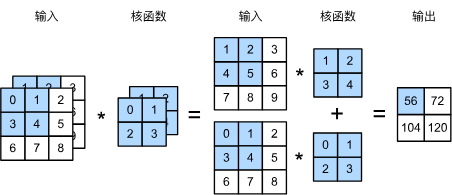
[1,2,3,3] \(\star\) [1,2,2,2] \(\rightarrow\) [1,1,2,2]
样本个数
channel
卷积核个数
长和宽
深度学习:卷积神经网络
# GW: DL
- 卷积(二维)
- 深度 \(\rightarrow\) channel
- \(1\times1\) 卷积层
- 唯一计算发生在channel上
[1,3,3,3] \(\star\) [2,3,1,1] \(\rightarrow\) [1,2,3,3]
样本个数
channel
卷积核个数
长和宽

深度学习:卷积神经网络
# GW: DL
- 卷积(二维)
- 深度 \(\rightarrow\) channel
- 池化层 (Pooling layer)
- 池化层的提出是为了缓解卷积层对位置的过度敏感性。
- 在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各通道的输入按通道相加。
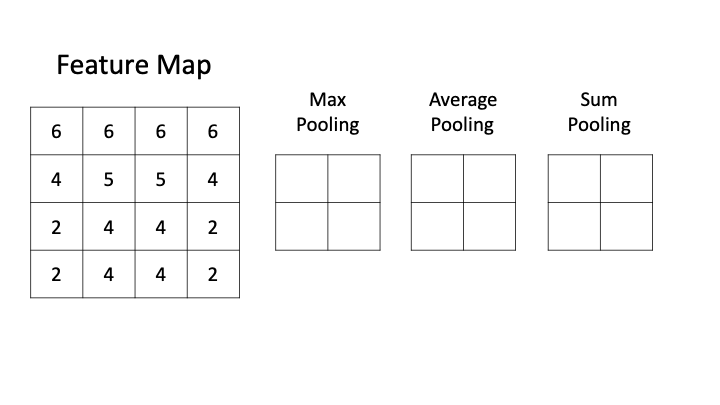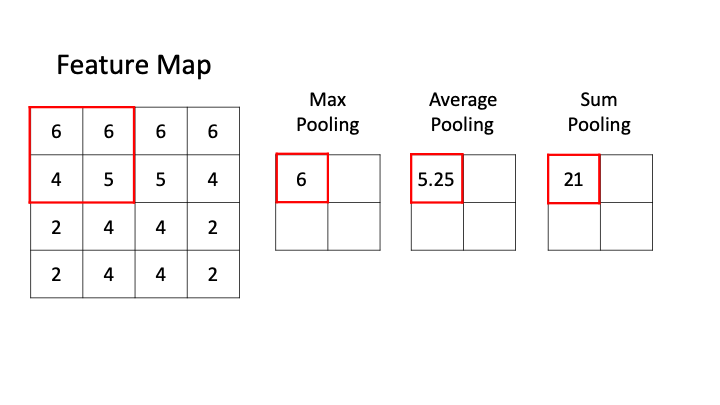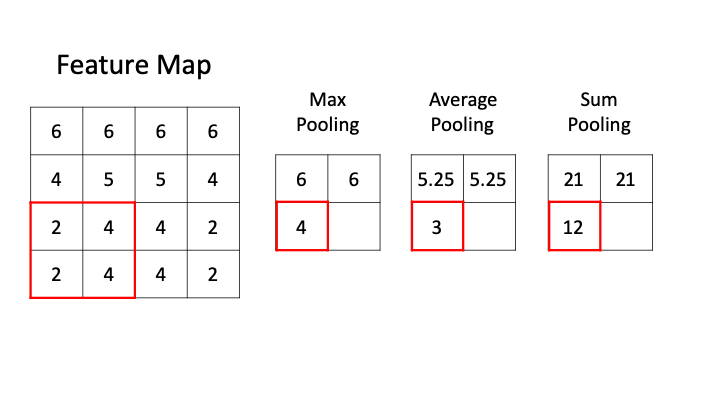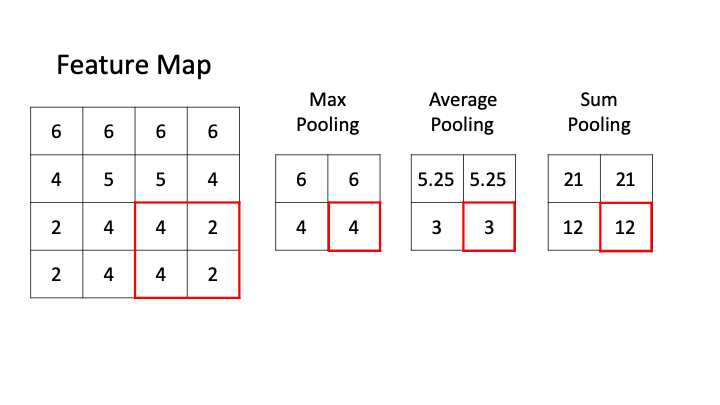
深度学习:卷积神经网络
# GW: DL
- 传统神经网络 vs 卷积神经网络
- 卷积层是全连接层的一种特例
- 全连接层:参数太多,易过拟合
- 卷积层:
- 稀疏连接 (sparse connectivity)
- 权重参数共享 (parameter sharing)
- 卷积层是全连接层的一种特例
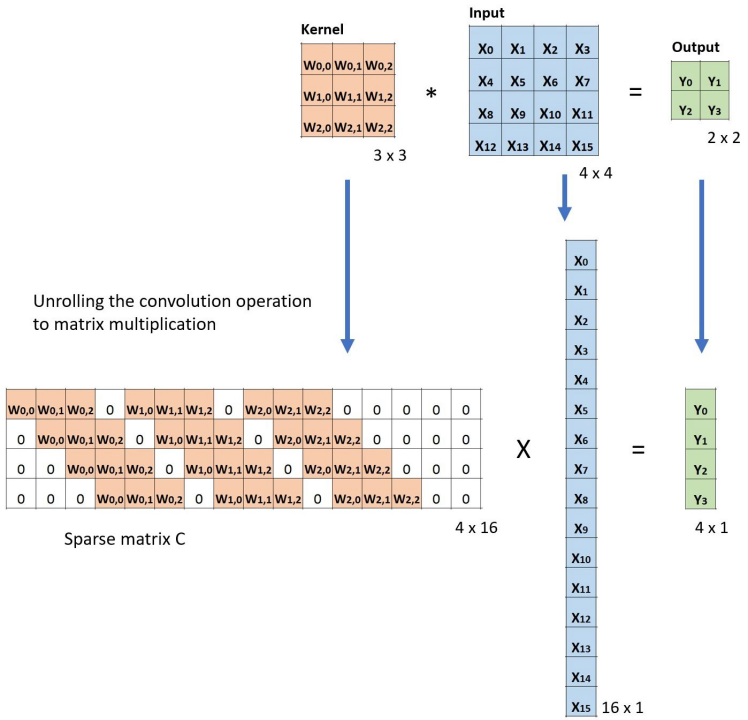
深度学习:卷积神经网络
# GW: DL
- 传统神经网络 vs 卷积神经网络
- 卷积层是全连接层的一种特例
- 全连接层:参数太多,易过拟合
- 卷积层:
- 稀疏连接 (sparse connectivity)
- 权重参数共享 (parameter sharing)
- 卷积层是全连接层的一种特例
CNN Explainer:https://poloclub.github.io/cnn-explainer/
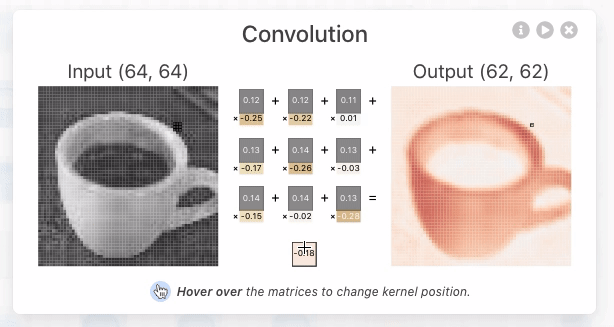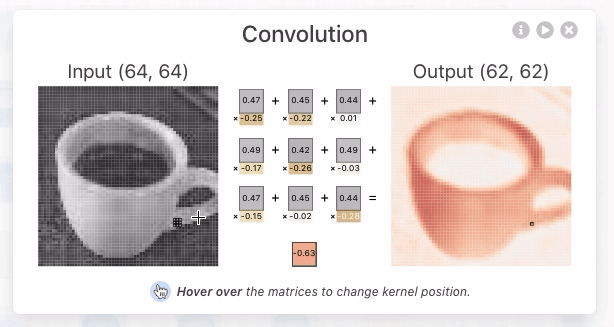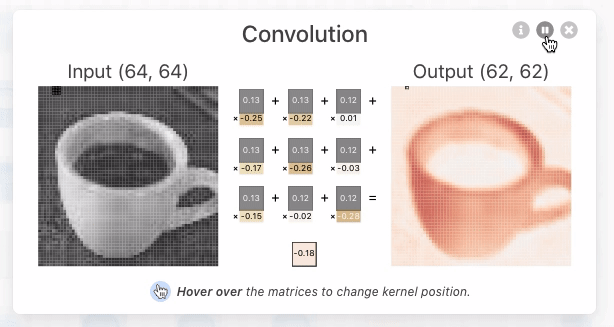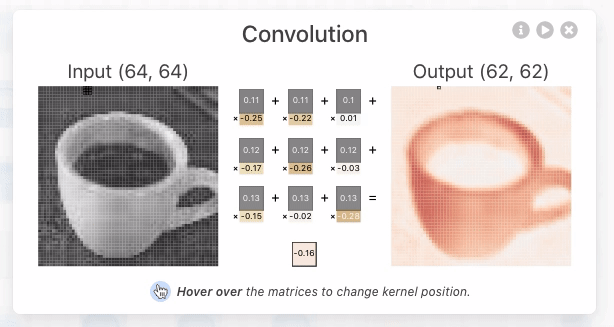
深度学习:卷积神经网络
# GW: DL
- Vanilla CNN
- 卷积神经网络 (Convolutional Neural Network, CNN) 就是含卷积层的网络。这里介绍一个早期用来识别手写数字图像的卷积神经网络:LeNet。这个名字来源于 LeNet 论文的第一作者 Yann LeCun。LeNet展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当时最先进的结果。这个奠基性的工作第一次将卷积神经网络推上舞台,为世人所知。LeNet 的网络结构如下图所示。
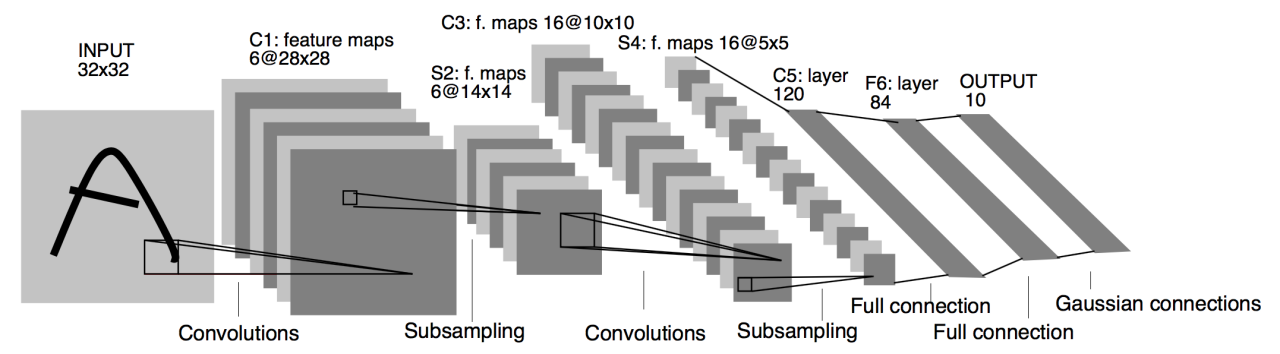
深度学习:卷积神经网络
# GW: DL
- Vanilla CNN
- LeNet 分为两个部分组成:
- 卷积层块:由两个卷积层块组成;
- 全连接层块:由三个全连接层组成。
- 每个卷积块中的基本单元是一个卷积层、一个 sigmoid 激活函数和平均池化层。
- 请注意,虽然 ReLU 和最大池化层更有效,但它们在20世纪90年代还没有出现。每个卷积层使用 5×5 卷积核,这些层将输入映射到多个二维特征输出,通常同时增加通道的数量。第一卷积层有 6 个输出通道,而第二个卷积层有 16 个输出通道。每个 2×2 池化操作通过空间下采样将维数减少 4 倍。卷积的输出形状由批量大小、通道数、高度、宽度决定。
- 为了将卷积层块的输出传递给全连接层块,我们必须在小批量中展平 (flatten) 每个样本。换言之,我们将这个四维输入转换成全连接层所期望的二维输入。这里的二维表示的第一个维度索引小批量中的样本,第二个维度给出每个样本的平面向量表示。LeNet 有三个全连接层,分别有 120、84 和 10 个输出。因为我们仍在执行分类,所以输出层的 10 维对应于最后输出结果的数量。
- LeNet 分为两个部分组成:
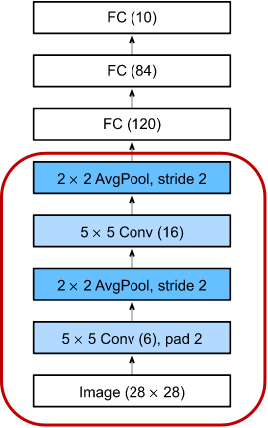
深度学习:卷积神经网络
# GW: DL
- ResNet
- 残差学习网络 (deep residual learning network)
-
残差的思想: 去掉相同的主体部分,从而突出微小的变化。
-
可以被用来训练非常深的网络
He K, Zhang X, Ren S, et al. Deep residual learning for image recognition. CVPR (2016)

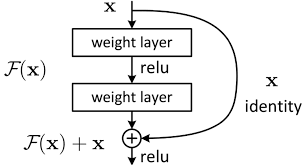
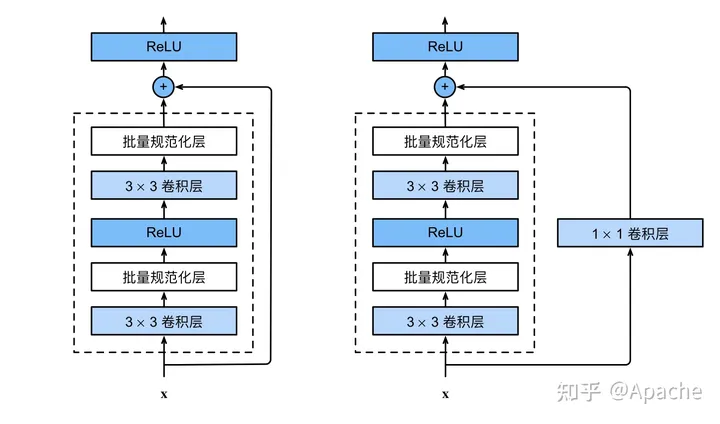
深度学习:卷积神经网络
# GW: DL
- ResNet
- 残差模块关于 GW + AI 的应用已经非常广泛
- 最普遍且直接的理解角度 CV \(\rightarrow\) GWDA:
- 像素点 \(\rightarrow\) 采样点
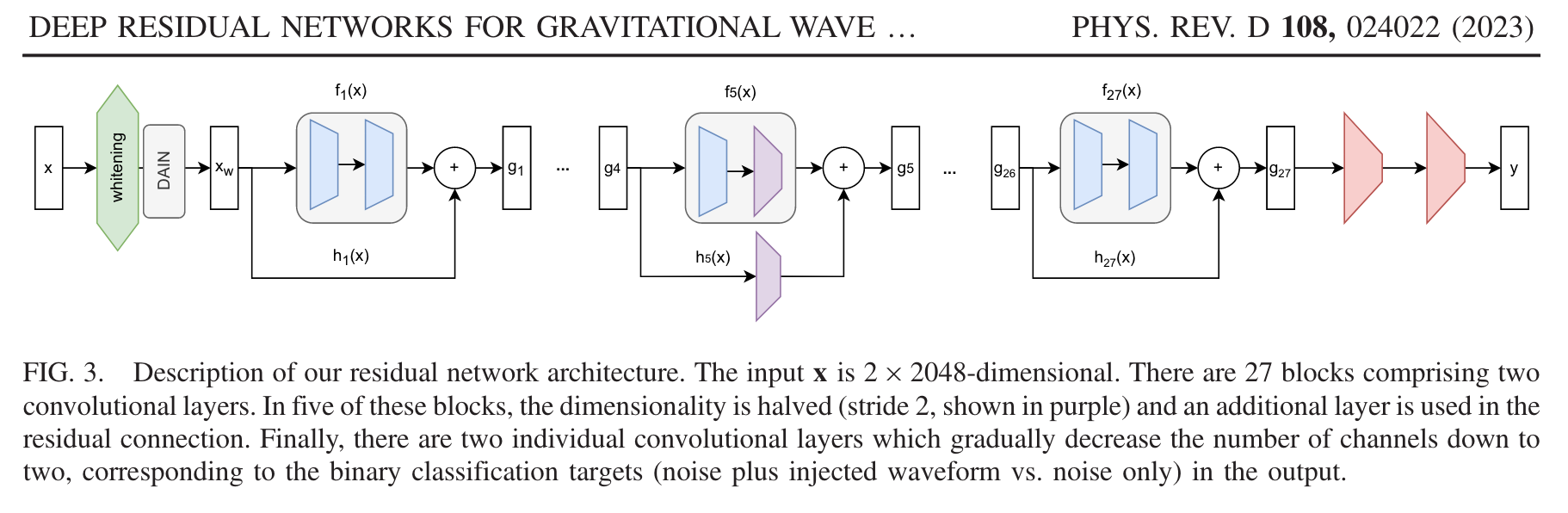
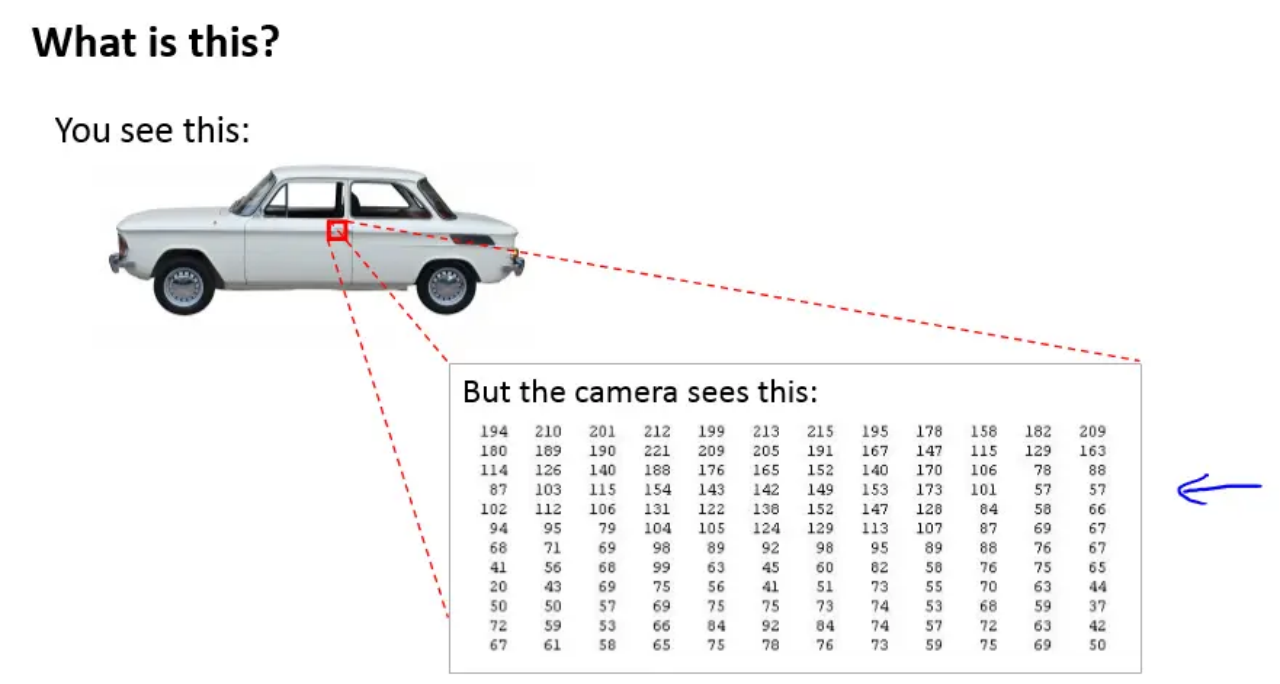
- 信号探测
引力波数据分析与深度学习

引力波信号搜寻:深度学习技术
# GW: DL
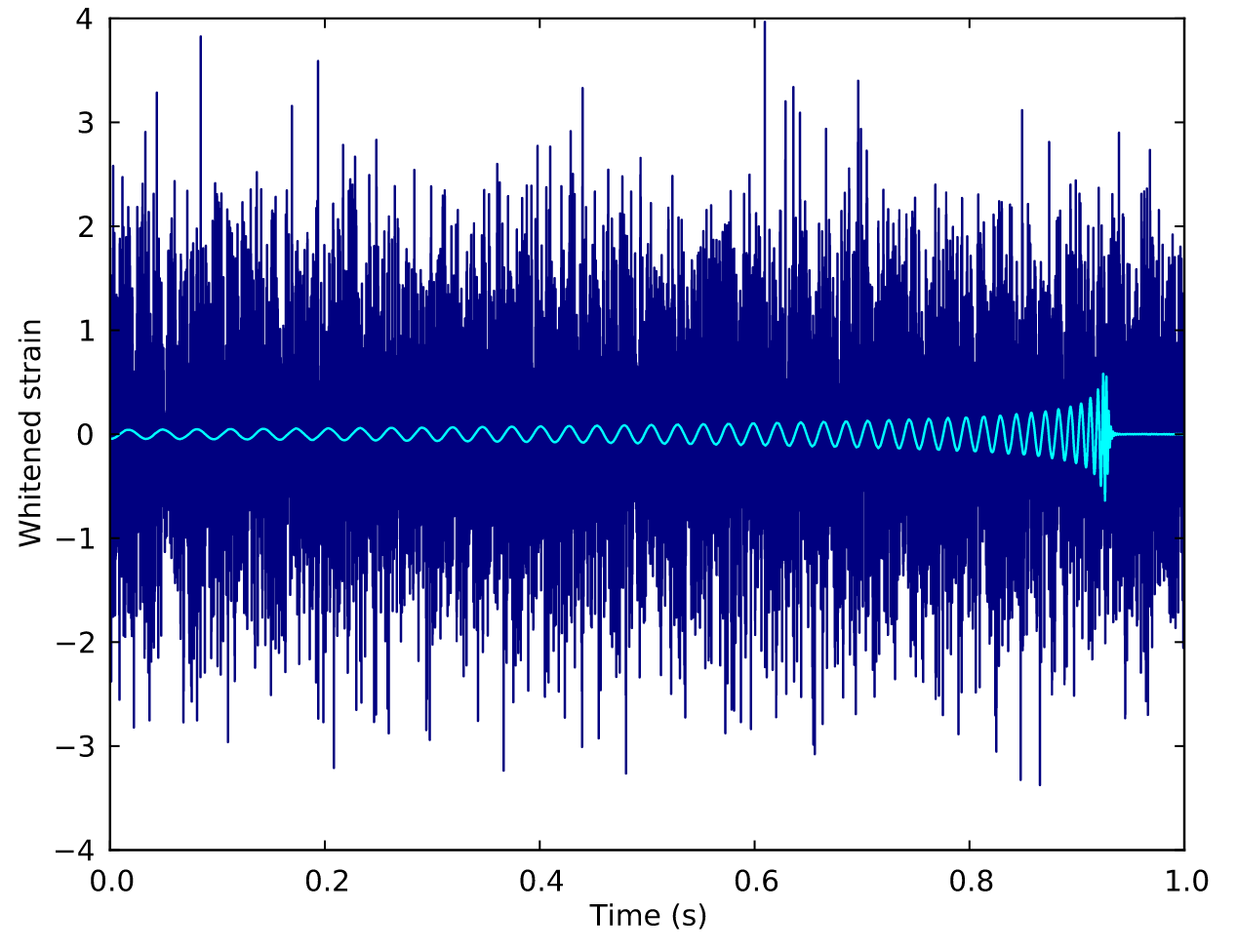
- Deep convolutional neural network to search for binary black hole gravitational-wave signals.
- Input is the whitened time series of measured gravitational- wave strain in Gaussian noise.
- Sensitivity comparable to match filtering.

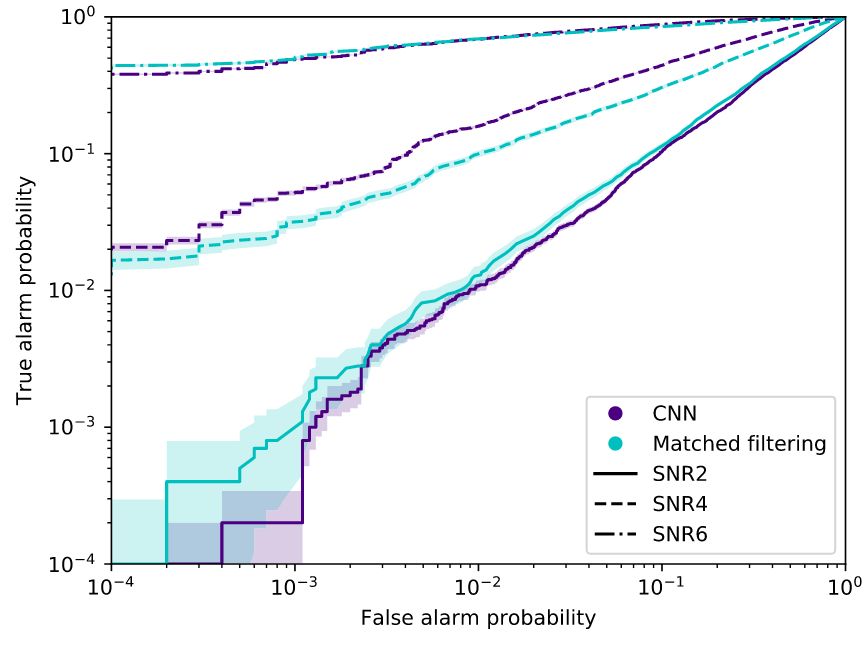
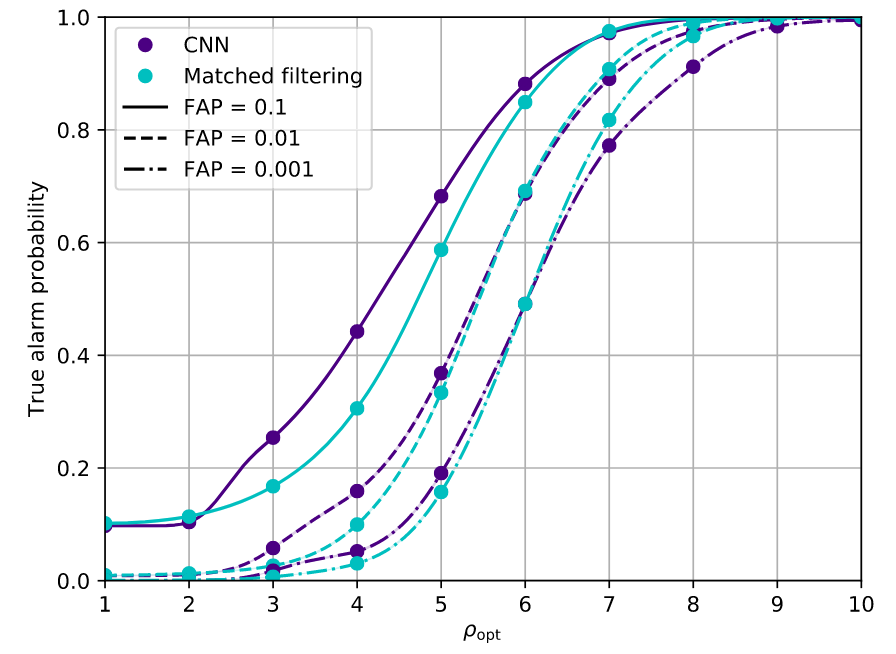
See also:
D. George and E.A. Huerta Phys. Lett. B 778 64–70 (2018)
What is ROC?
引力波信号搜寻:深度学习技术
# GW: DL

- 目标:复现这个学习任务,搭建一个 Baseline
- 理解什么是 ROC?
- ELU? Dropout? Softmax?
- ...
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
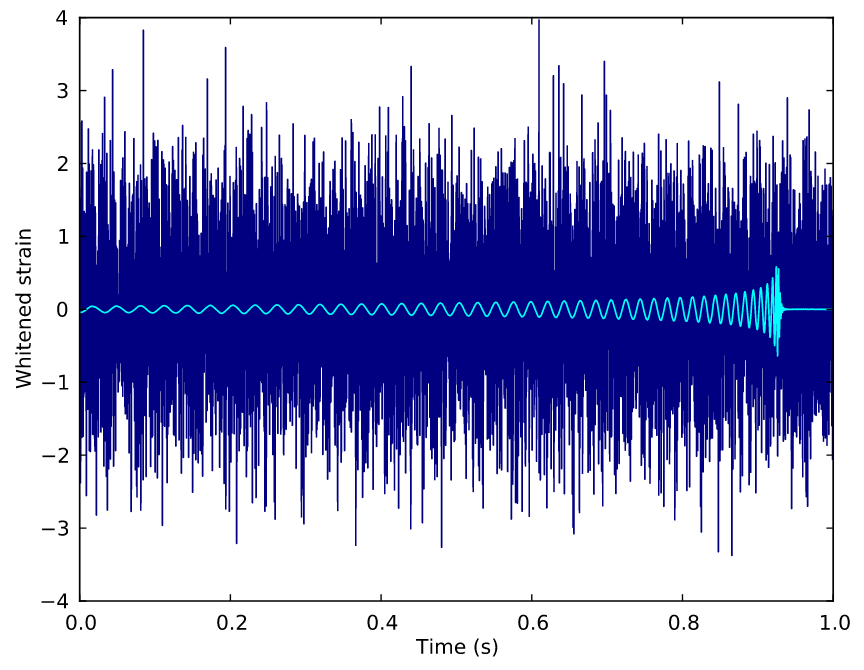
0.99
0.05
期望达到的效果(Evaluation):
H1
L1
CNN
引力波信号搜寻:卷积神经网络
# GW: DL
训练的过程(Train):
1
0
H1
L1
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
Labels
CNN
[6,2,16384][6,2]1
1
0
0
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
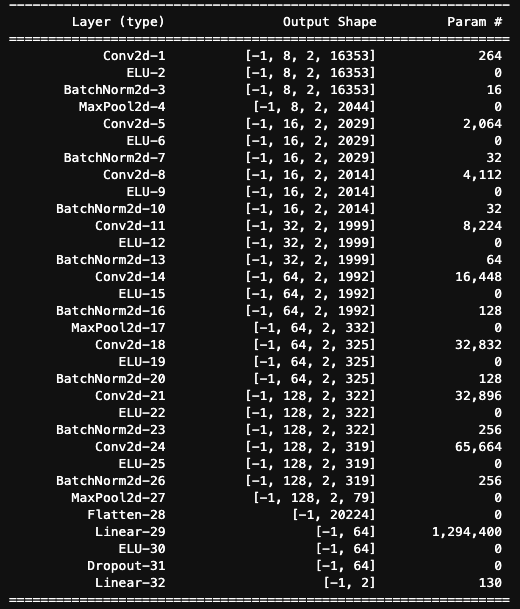
[6,2,16384] -> Reshape your input data:
[6,1,2,16384]样本个数
in channel
长和宽
Conv2D:
Conv2d(1, 8, kernel_size=(1, 32), stride=(1, 1))[8,1,1,32][6,8,2,16353]卷积核个数 / out channel
in channel
out channel
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
ELU activation
[6,8,2,16353][6,8,2,16353]ELU(alpha=0.01)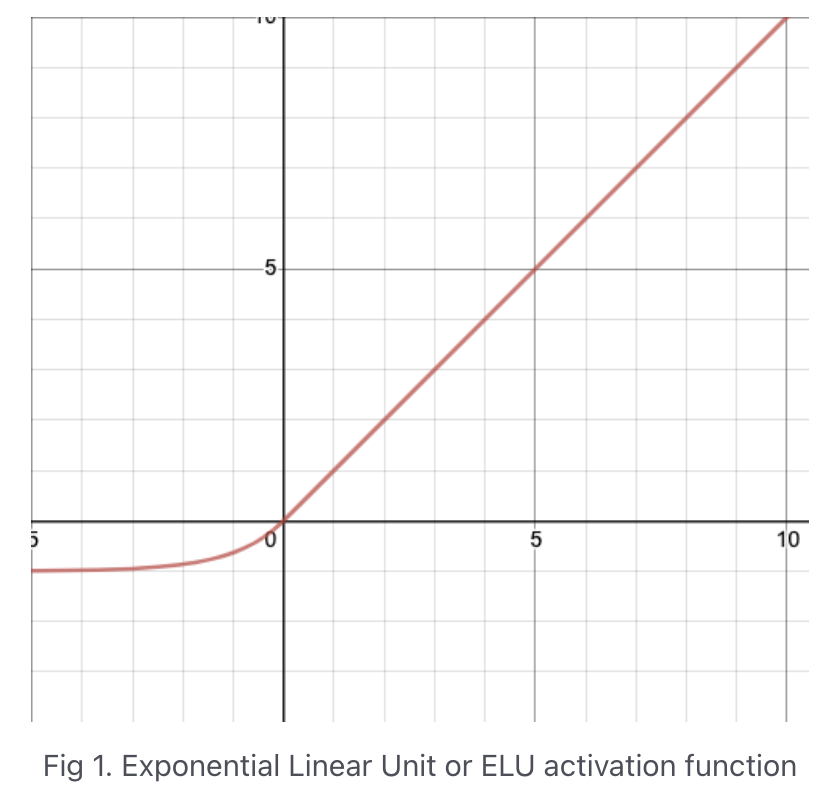
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
Batch Normalization
[6,8,2,16353][6,8,2,16353]BatchNorm2d(8, eps=1e-05, momentum=0.1)in channel
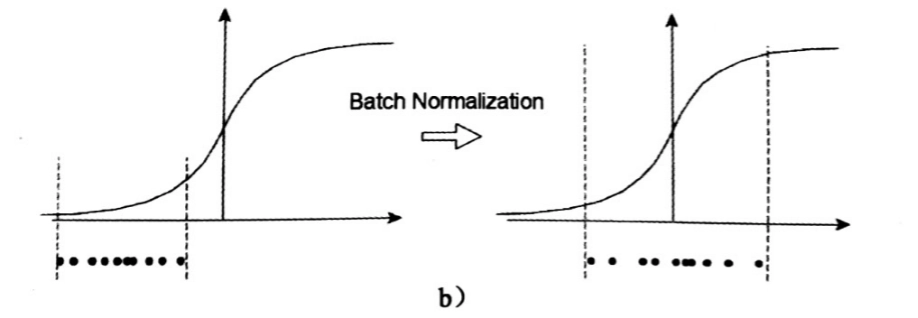
- BN 批归一化可以加快模型的收敛速度,缓解“梯度弥散”的问题
- See more
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
Max Pooling
[6,8,2,16353][6,8,2,2044]MaxPool2d(kernel_size=[1, 8],
stride=[1, 8],
padding=0)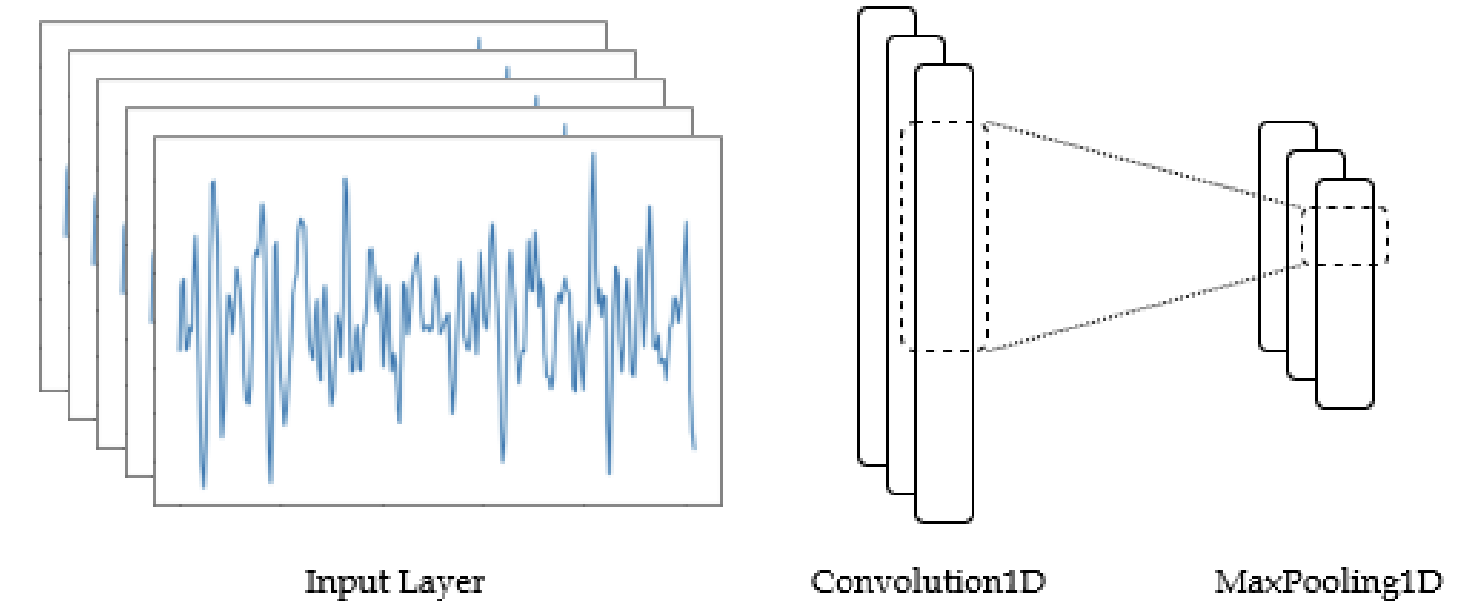
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
Flatten
[6,128,2,79][6,20224]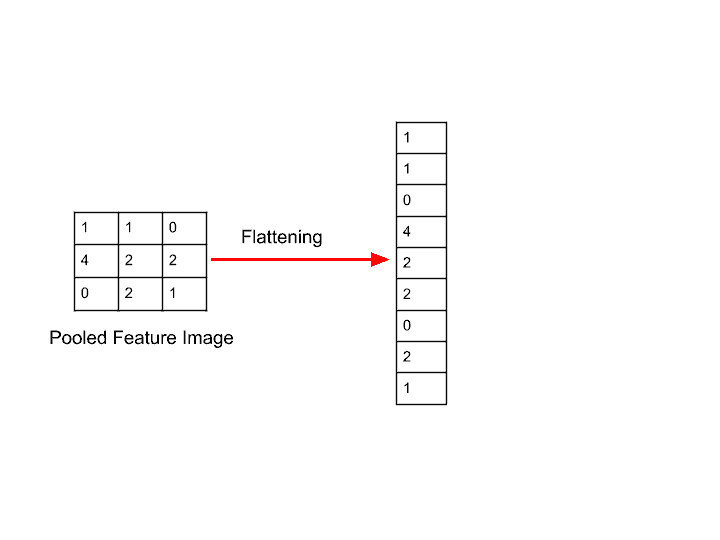
Linear
[6,20224][6,64][6,64][20224,64][64,2][6,2]引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
CNN
Dropout
[6,20224][6,64][20224,64]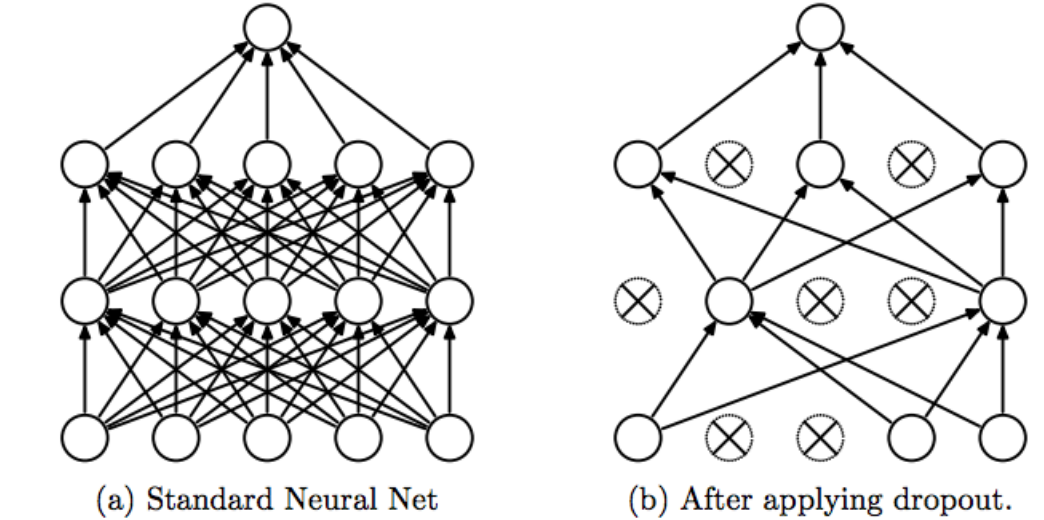
Dropout(p=0.5)- Dropout 随机失活: 以一定概率 p 要求中间层的部分神经元临时删除。
- 大部分实验表明,Dropout 可以有效地防止过拟合问题的发生。
- 机制:相当于对大量不同网络子模型的性能做了近似平均,不同的子网络会以不同的方式过度拟合,模型集成后就会减轻过度拟合的效果。
引力波信号搜寻:卷积神经网络
# GW: DL
训练的过程(Train):
1
0
H1
L1
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻:卷积神经网络
# GW: DL
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
引力波信号搜寻:卷积神经网络
# GW: DL
Dataset containing \(N\) examples sampling from true but unknown data generating distribution \(p_{\text {data }}(\mathbf{x})\):
with coressponding ground-truth labels:
Machine learning model is nothing but a map \(f\) from samples to labels:
where \(\mathbb{\Theta}\) is parameters of the model and the outputs are predicted labels:
described by \(p_{\text {model }}(\mathbf{y}|\mathbf{x} ; \boldsymbol{\Theta})\), a parametric family of probability distributions over the same space indexed by \(\Theta\).
Objective:
- For each sample,
- Find the best \(\Theta\) that
引力波信号搜寻:卷积神经网络
# GW: DL
Objective:
- For each sample,
- Find the best \(\Theta\) that
to construct cost function \(J(\Theta)\) (also called loss func. or error func.)
For classification problem, we always use maximum likelihood estimator for \(\Theta\)
- Minimizing the KL divergence corresponds exactly to minimizing the cross-entropy (negative log-likelihood of a Bernoulli/Softmax distribution) between the distributions.
引力波信号搜寻:卷积神经网络
# GW: DL
Objective:
- For each sample,
- Find the best \(\Theta\) that
在信息论中,可以通过某概率分布函数 \(p(x),x\in X\) 作为变量,定义一个关于 \(p(x)\) 的单调函数 \(h(x)\),称其为概率分布 \(p(x)\) 的信息量(measure of information): \(h(x) \equiv -\log p(x)\)
定义所有信息量的期望为随机变量 \(x\) 的 熵 (entropy):
若同一个随机变量 \(x\) 有两个独立的概率分布 \(p(x)\) 和 \(q(x)\),则可以定义这两个分布的相对熵 (relative entropy),也常称为 KL 散度 (Kullback-Leibler divergence),来衡量两个分布之间的差异:
可见 KL 越小,表示 \(p(x)\) 和 \(q(x)\) 两个分布越接近。上式中,我们已经定义了交叉熵 (cross entropy) 为
引力波信号搜寻:卷积神经网络
# GW: DL
Objective:
- For each sample,
- Find the best \(\Theta\) that
当对应到机器学习中最大似然估计方法时,训练集上的经验分布 \(\hat{p}_ \text{data}\) 和模型分布之间的差异程度可以用 KL 散度度量为:
由上式可知,等号右边第一项仅涉及数据的生成过程,和机器学习模型无关。这意味着当我们训练机器学习模型最小化 KL 散度时,我们只需要等价优化地最小化等号右边的第二项,即有
Recall:
由此可知,对于任何一个由负对数似然组成的代价函数都是定义在训练集上的经验分布和定义在模型上的概率分布之间的交叉熵。
引力波信号搜寻:卷积神经网络
# GW: DL
训练的过程(Train):
1
0
H1
L1
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻:卷积神经网络
# GW: DL
训练的过程(Train):
1
0
H1
L1
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻:卷积神经网络
# GW: DL
基于分类问题的网络模型里,我们都是用 softmax 函数作为模型最终输出数据时的非线性计算单元,其函数形式为:
1
0
Labels
1
1
0
0
[6,2]由于该函数的输出元素都介于 0 和 1 之间,且向量之和为 1,这使得其可以作为一个有效的“概率分布” \(p_\text{model}(y=k|\mathbf{x}^{(i)})\)。
由此,我们使用最大化条件对数似然输出某样本的目标分类 \(y\) 时,即等价于对下式最大化,
上式中的第一项表示模型的直接输出结果 \(\hat{y}_k\),对优化目标有着直接的贡献。在最大化对数似然时,当然是第一项越大越好,而第二项是鼓励越小越好。根据 \(\log\sum^N_j\exp(\hat{y}_ j)\sim\max_j\hat{y}_ j\) 近似关系,可以发现负对数似然代价函数总是强烈的想要惩罚最活跃的不正确预测。如果某样本的正确 label 对应了 softmax 的最大输入,那么 \(-{y}_k\) 项和 \(\log \sum_j^N \exp \left({y}_j\right)\sim\max_jy_j=y_j\) 项将大致抵消。
引力波信号搜寻:卷积神经网络
# GW: DL
对于二值型的分类学习任务,softmax 函数会退化到 sigmoid 函数:
1
0
Labels
1
1
0
0
[6,2]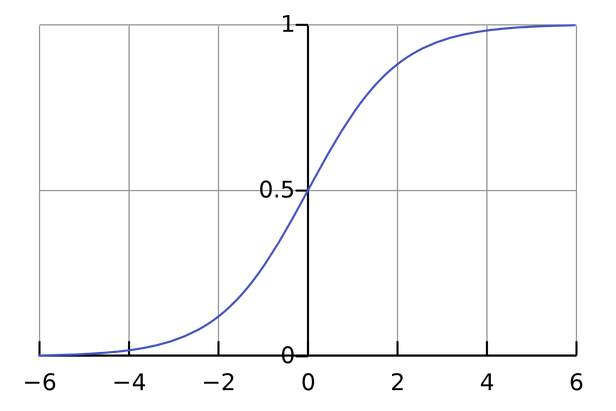
由此可以证明,cost funcion 可以表示为
引力波信号搜寻:卷积神经网络
# GW: DL
- 因此,单纯用 Softmax 函数代表 p-value 表示引力波信号是否存在,会造成在正负样本上 p-value 概率密度分布的不单调性。
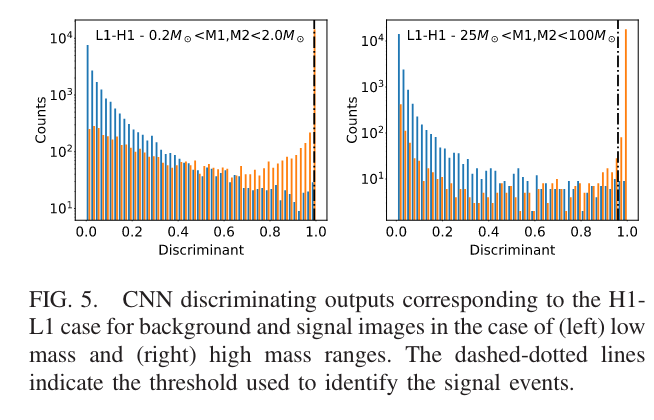
Menéndez-Vázquez A, et al.PRD 2021
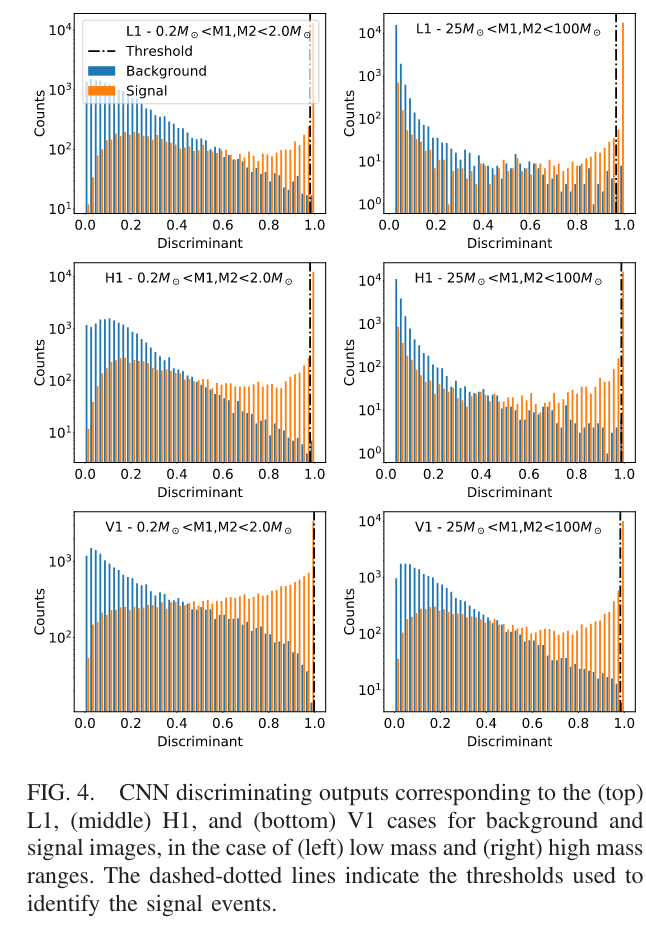
- 机器学习算法输出的信号存在与否的“概率” (p-value),不能作为探测统计量,其无法对疑似信号的统计显著性进行排序
- "The negative log-likelihood cost function always strongly penalizes the most active incorrect prediction.
And the correctly classified examples will contribute little to the overall training cost."
—— I. Goodfellow, Y. Bengio, A. Courville. Deep Learning. 2016.

arXiv: 2307.09268
引力波信号搜寻:卷积神经网络
# GW: DL
训练的过程(Train):
1
0
H1
L1
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
Labels
CNN
[6,2,16384]1
1
0
0
[6,2]引力波信号搜寻:卷积神经网络
# GW: DL
- 从假设空间中 学习/选择 最优模型的准则?
-
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
-
所以,我们认定机器学习算法效果是否很好,两个学习目标:
-
降低训练误差。
-
缩小训练误差和测试误差的差距。
-
-
这两个目标分别对应了机器学习的两个重要挑战:
-
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
-
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
-
引力波信号搜寻:卷积神经网络
# GW: DL
- 从假设空间中 学习/选择 最优模型的准则?
-
“最合适”的模型:机器学习从有限的观测数据中学习出规律 [训练误差 (training error)],
并将总结的规律推广应用到未观测样本上 \(\rightarrow\) 追求泛化性能 [泛化误差 (generalization error)]。
-
所以,我们认定机器学习算法效果是否很好,两个学习目标:
-
降低训练误差。
-
缩小训练误差和测试误差的差距。
-
-
这两个目标分别对应了机器学习的两个重要挑战:
-
欠拟合 (underfitting):模型不能在训练集上获得足够低的误差。
-
过拟合 (overfitting):训练误差与测试误差之间的差距过大。
-
-
泛化性能 是由
-
学习算法的能力、
-
数据的充分性以及
-
学习任务本身的难度共同决定。
-
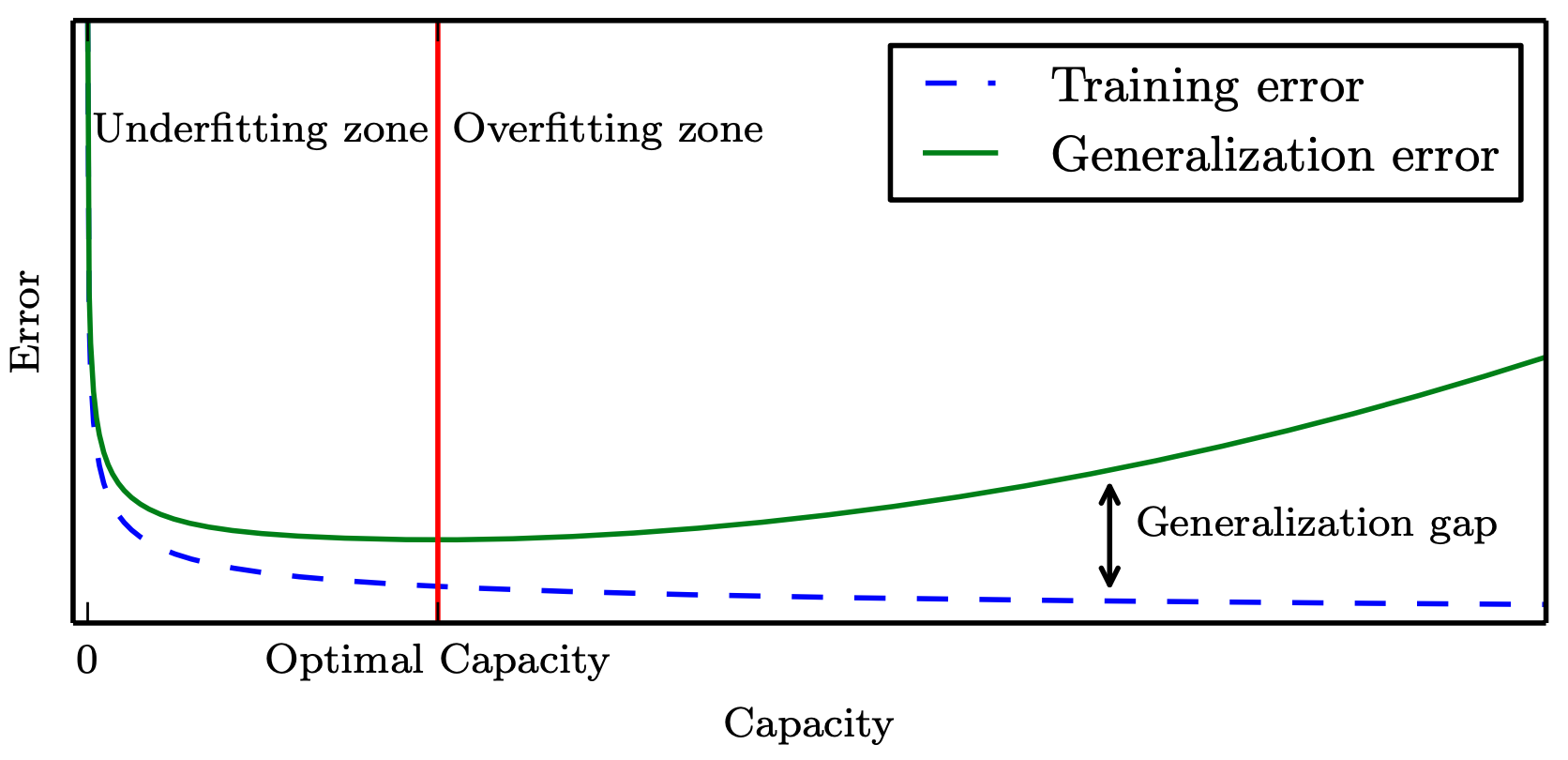
模型的容量 Capacity 是指其拟合各种函数的能力,一般也可以代表模型的复杂程度。(“计算学习理论”)
奥卡姆剃刀原理:
惩罚大模型复杂度
训练集的一般性质尚未被
学习器学好
学习器把训练集特点当做样本的 一般特点.
偏差-方差窘境(bias-variance dilemma)
引力波信号搜寻:卷积神经网络
# GW: DL
- 模型调优时,如何判断是否过拟合?
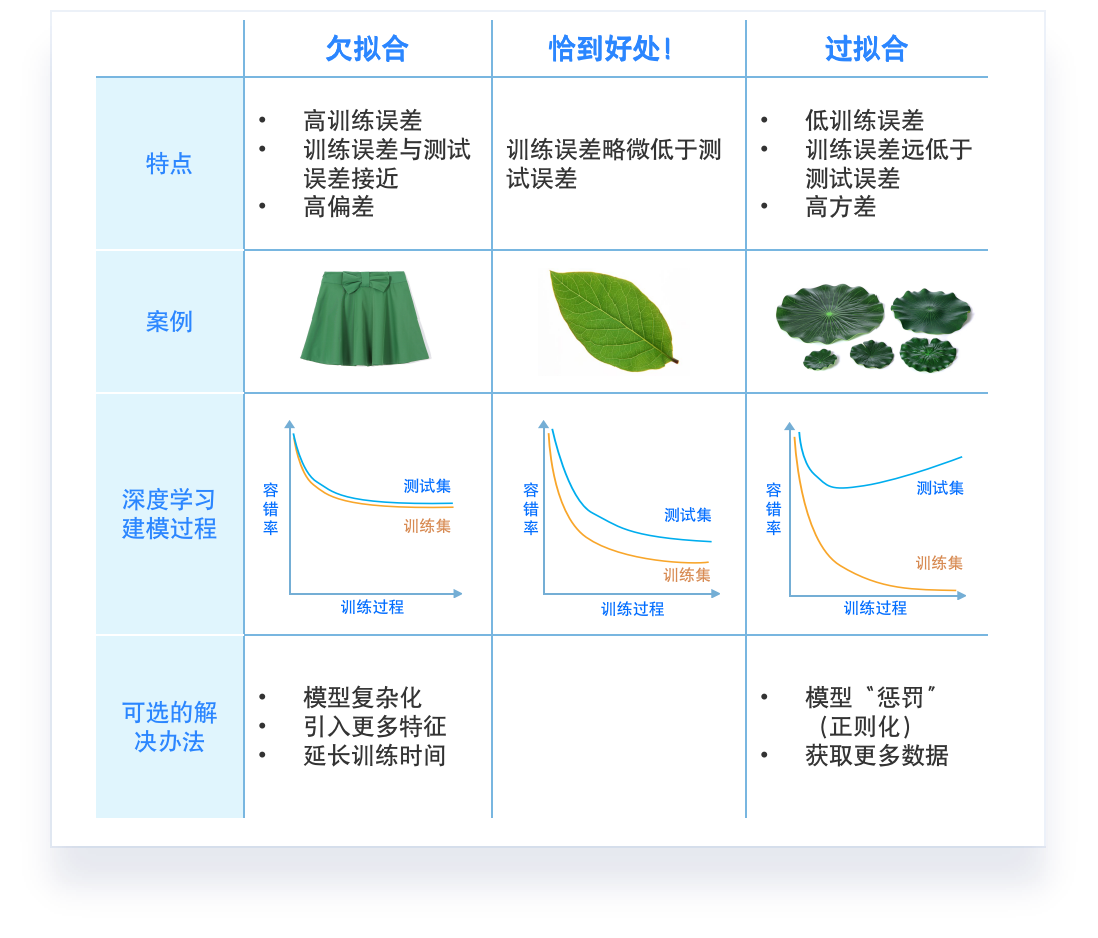
early stop、dropout

参数调得好不好,往往对最终性能有关键影响。
引力波信号搜寻:卷积神经网络
# GW: DL
- 模型调优时,如何判断是否过拟合?
-
数据增广 (训练集越大,越不容易过拟合)
- 计算机视觉:图像旋转、缩放、剪切
- 自然语言处理:同义词替换
- 语音识别:添加随机噪声

SpecAugment
引力波信号搜寻:卷积神经网络
# GW: DL
- 模型调优时,如何判断是否过拟合?
-
数据增广 (训练集越大,越不容易过拟合)
- 计算机视觉:图像旋转、缩放、剪切
- 自然语言处理:同义词替换
- 语音识别:添加随机噪声
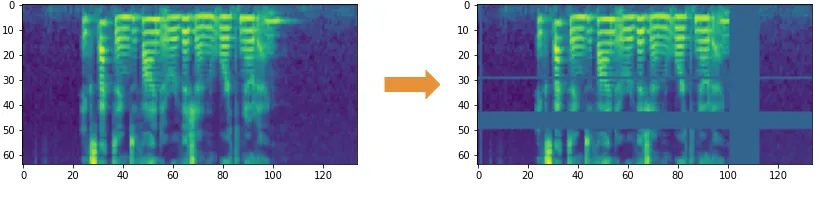
- 引力波数据处理:

1.
Source: X
PSD
2.
noise instance
...
...
waveform
...
...
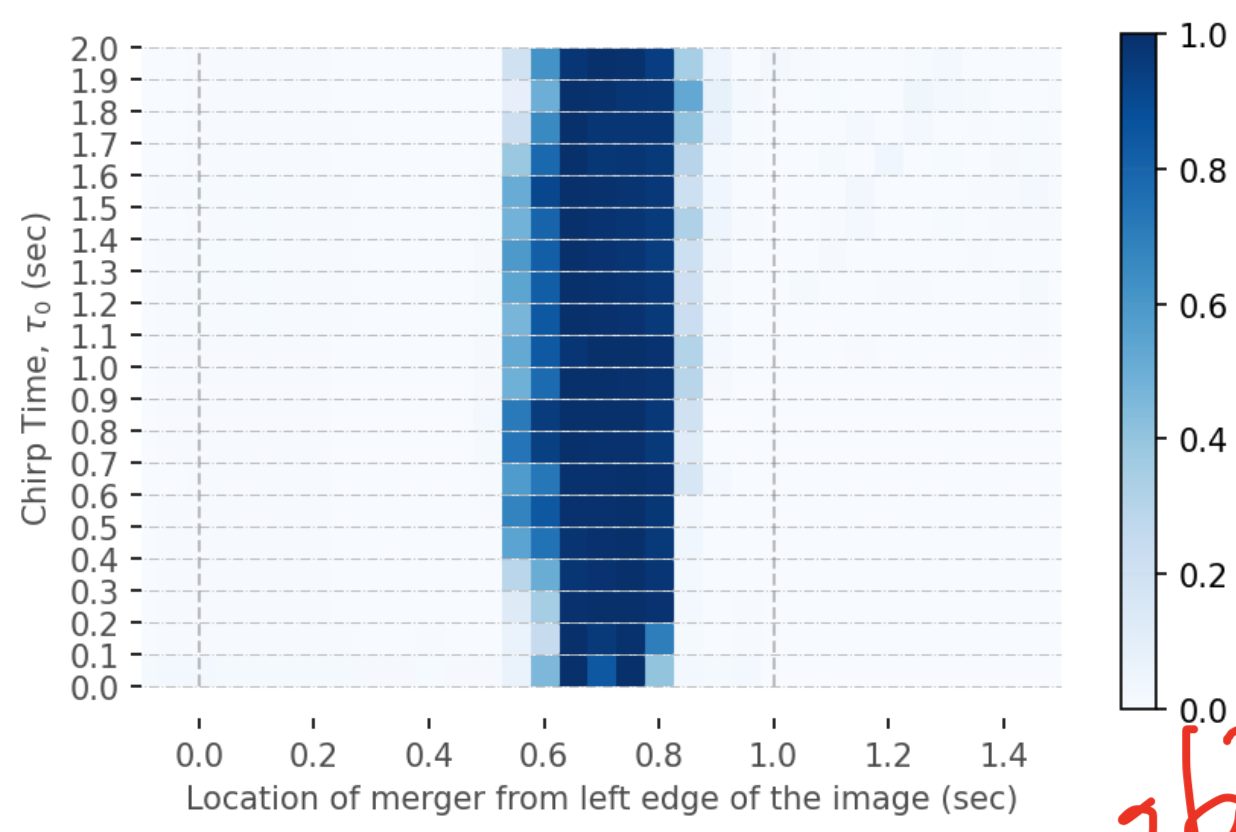
Jadhav et al. 2306.11797
merger location
...
...
引力波信号搜寻:卷积神经网络
# GW: DL
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
期望达到的效果(Evaluation):
H1
L1
CNN
0.99
0.05
引力波信号搜寻:卷积神经网络
# GW: DL
-
分类模型泛化性能评估:混淆矩阵/ROC/AUC
- 目标:复现这个学习任务,搭建一个 Baseline
- 任务:判断一段含有引力波信号的时序数据 (H1/L1),是否含有引力波信号(二分类问题)
期望达到的效果(Evaluation):
H1
L1
CNN
0.54
有信号?无信号?
引力波信号搜寻:卷积神经网络
# GW: DL
CNN
0.54
有信号?无信号?
-
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1

- 确定阈值(threshold),才能把分类模型真的确定确定下来。
- 0.5 阈值仅代表模型最大梯度更新的极值点,并没有理论上明确的理想分类阈值取法。
- 不过对于一个训练好的分类模型而言,分类阈值的选取会直接影响模型的泛化考量。
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
引力波信号搜寻:卷积神经网络
# GW: DL
CNN
0.54
有信号?无信号?
-
分类模型泛化性能评估:混淆矩阵/ROC/AUC
H1
L1
threshold = 0.5,这里有引力波信号!
threshold = 0.6,这里没有引力波信号!
- 性能度量 (performance measure):
- 在模型的训练过程中,一般会用错误率 (error rate) 和准确率 (accuracy) 来定量衡量分类模型的性能。准确率是指该模型输出分类正确的样本数占样本总数的比例,错误率是其补集。
- 对于引力波信号凑寻,我们更加关心是:
- “引力波信号中有多少是可以被探测到”
- “探测到的信号中有多少其实是假的引力波信号”
- 确定阈值(threshold),才能把分类模型真的确定确定下来。
- 0.5 阈值仅代表模型最大梯度更新的极值点,并没有理论上明确的理想分类阈值取法。
- 不过对于一个训练好的分类模型而言,分类阈值的选取会直接影响模型的泛化考量。
引力波信号搜寻:卷积神经网络
# GW: DL
- 构建分类结果的混淆矩阵 (confusion matrix)
- 对于某测试数据集中 + 取定某 threshold 的情况下
- 可以计算出真正例率 (True Positive Rate, TPR) 和假正例率 (False Positive Rate, FPR):
- 对于某测试数据集中 + 取定某 threshold 的情况下
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |

arXiv: 2302.00666
引力波信号搜寻:卷积神经网络
# GW: DL
- 构建分类结果的混淆矩阵 (confusion matrix)
- 对于某测试数据集中 + 取定某 threshold 的情况下
- 可以计算出真正例率 (True Positive Rate, TPR) 和假正例率 (False Positive Rate, FPR):
- 对于某测试数据集中 + 取定某 threshold 的情况下
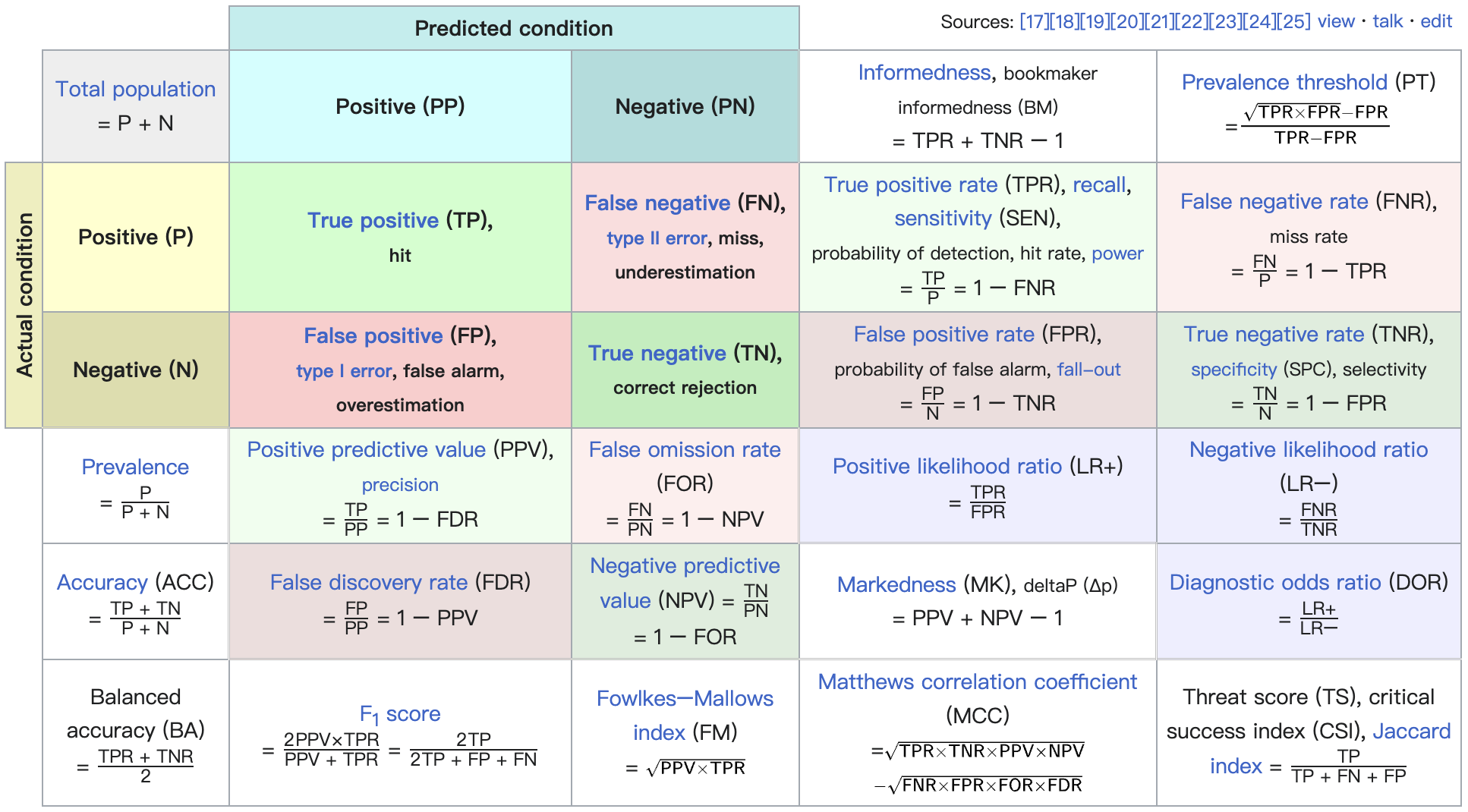
| 真实情况 | 正例(预测结果) | 反例(预测结果) |
|---|---|---|
| 正例 | TP (真正例) | FN (假反例) |
| 反例 | FP (假正例) | TN (真反例) |
arXiv: 2302.00666
Source: Wiki-en
引力波信号搜寻:卷积神经网络
# GW: DL
- 真正例率 (True Positive Rate, TPR) 和假正例率 (False Positive Rate, FPR)
- 在引力波数据处理中,TPR 和 FPR 可以分别与引力波信号预警模型在引力波数据上的探测灵敏度 (sensitivity) [或 \(P_{astro}\)] 和误报率 (false alarm rate, FAR) 相对应。
Source: Wiki-en
引力波信号搜寻:卷积神经网络
# GW: DL
- 在不同的阈值选取下,我们分别以 TPR 和 FPR 为纵、横轴作图,就得到了 ROC (Receiver Operating Characteristic, 受试者工作特征) 曲线。
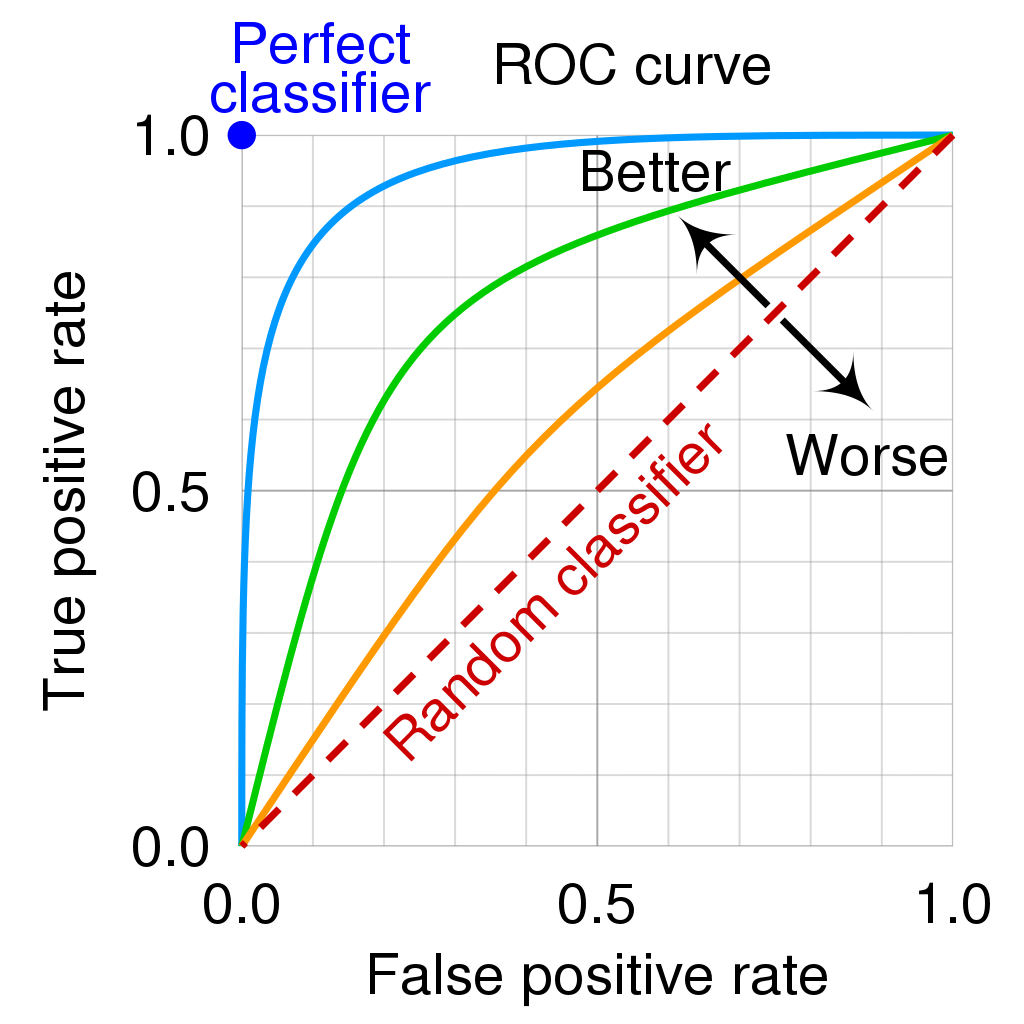
Source: Wiki-en
- 图上的每一点,都对应于一种阈值选取可能。
- 对角线对应于“随机猜测”模型,而过左上点 (0,1)的曲线就是预测最佳的“理想模型”。
- 阈值越大,对应于 ROC 的左下角方向,
- 阈值越小,对应于 ROC 右上角的方向。

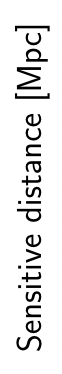
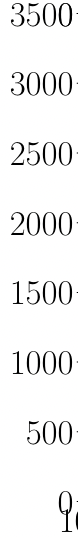
引力波信号搜寻:卷积神经网络
# GW: DL
- 在不同的阈值选取下,我们分别以 TPR 和 FPR 为纵、横轴作图,就得到了 ROC (Receiver Operating Characteristic, 受试者工作特征) 曲线。
- 对不同的机器学习模型进行比较时,若某模型的 ROC 曲线可以“包住”另一个模型的曲线,则可断言前者的性能优于后者。
- 为了能避免曲线交叉会带来的含糊,一个定量的合理判据就是比较 ROC 曲线下的面积,即 AUC (Area Under ROC Curve)

Source: Wiki-en
引力波信号搜寻:卷积神经网络
# GW: DL


很多其实很重要但没能讲到的内容:
- 网络权重初始化
输入数据的标准化- 感受野
正则化- 类别不均衡
K 折交叉验证模型的集成与融合- Fine-tune(迁移学习)
- ...
# GW: DL

Hackathon
Can you find the GW signals?

# GW: DL
Hackathon: Can you find the GW signals?
数据科学挑战:引力波信号搜寻
Home: https://www.kaggle.com/competitions/2023-gwdata-bootcamp
本竞赛将于北京时间 2023年12月29日22:00 开始,并于北京时间 2024年1月5日23:59 结束。
请确保在截止日期前提交你的解决方案。


# Homework
Homework
Repo of the course: https://github.com/iphysresearch/GWData-Bootcamp
- 基础及拓展作业:
- 一起来打怪之 Credit Scoring 练习:homework_credit_scoring_finetune_ensemble.ipynb
- 在 homework 分支上 PR。
- Kaggle是一个由Google所有的数据科学和机器学习竞赛平台。它为数据科学家和机器学习工程师提供了一个可以共享和协作的环境,用户可以在平台上找到并发布数据集,探索和构建模型,运行数据科学工作流,以及参加各种机器学习竞赛。https://www.kaggle.com
- Kaggle的主要特点包括:
- 竞赛:Kaggle举办了许多由企业和研究机构赞助的机器学习竞赛。这些竞赛涵盖了各种问题,从图像分类到自然语言处理,参赛者可以通过解决实际问题来提升自己的技能。
- 数据集:Kaggle拥有一个庞大的公开数据集库,用户可以在这里找到各种类型的数据集,并可以上传自己的数据集供他人使用。
- Kernels:Kaggle的Kernels是一种共享代码的方式,用户可以在Kernels中编写代码,进行数据分析和建模,并将其分享给其他用户。
- 社区:Kaggle有一个活跃的社区,用户可以在论坛上讨论问题,分享想法和经验,以及学习新的技术和方法。
- 学习:Kaggle还提供了一系列的数据科学和机器学习教程,帮助用户学习新的技能和知识。
- 总的来说,无论你是数据科学的新手,还是经验丰富的专家,Kaggle都是一个学习,实践,和分享知识的好地方。
通向自我实现之路:Kaggle
- 赞助单位
- 中科曙光
