SRO - XML and TEI
James Cummings
@jamescummings
http://slides.com/jamescummings/sro-tei
Thanks as ever to many members of the TEI Community
About XML
Why use markup?
Markup is used in many different fields, for many different purposes: storing data, relating information, encoding understanding, preserving metadata
- Markup is a way of making our knowledge or understanding about a text explicit
- Markup makes strives to make explicit (to a machine) what is implicit (to a person)
- Markup assists us in facilitating re-use of the same material:
- in different formats
- in different contexts
- by different sorts of users
Types of Markup
Procedural Markup:
RED INK ON; print "-£1000"; RED INK OFF
Presentational Markup:
\textcolor{red}{-£1000}
Descriptive Markup:
<measure unit="pounds" value="-1000">
One thousand pounds in debt
</measure>
About XML
XML is structured data represented as strings of text
XML looks like HTML, except that:
- XML is extensible
- XML must be well-formed
- XML can be validated
- XML is application-, platform-, and vendor- independent
- XML empowers the content provider and facilitates data integration and migration
- It is one of the best plain text long-term preservation formats for textual data that we have
About XML
<element> Text </element>
<element attribute="value">
Text or child elements here
</element>
<element attribute="value"/>
About XML
<?xml version="1.0" ?>
<root xmlns="http://namespace/">
<element attribute="value">
content
<childElement type="empty"/>
content
</element>
<!-- comment -->
</root>More About XML
- An XML document is encoded as a linear string of characters
- It begins with a special processing instruction
- Element occurrences are marked by start and end-tags
- The characters < and & are Magic and must always be "escaped" using < or & if you want to use them as themselves
- Comments are delimited by <!-- and -->
- Attribute name/value pairs are supplied on the start-tag and may be given in any order
- Attribute values are always quoted
- Everything is case-sensitive
Being Well-Formed
- There is a single root node containing the whole of an XML document
- Each subtree is properly nested within the root node
- Element/attribute names and values are always case sensitive
- Start-tags and end-tags are always mandatory (except there are combined start-and-end tags called 'empty elements' <pb/> <gap/>)
- Attribute values are always quoted
You can also be 'valid' which means you obey additional rules about elements and attributes and where they can go.
XML Test
- <seg>some text</seg>
-
<seg> <w>some</w> <hi>text</hi> </seg>
- <seg> <w>some <hi></w> text</hi> </seg>
- <seg type="text">some text</seg>
- <seg type=text>some text</seg>
- <seg type="text"> some text <seg/>
- <seg type="text"> some text<gap/> </seg>
- <seg type="text">some text</Seg>


About The TEI
The TEI (The Text Encoding Initiative) is:
- An international consortium of institutions, projects and individual members
- A community of users and volunteers
- A freely available manual of set of regularly maintained and updated recommendations: 'The Guidelines' with definitions, examples, and discussion of over 560 markup distinctions
- A mechanism for producing customized schemas for validating your project's digital texts
- A set of free and openly licensed, customizable tools and stylesheets for transformations to many formats (e.g. HTML, Word, PDF, Databases, RDF/LinkedData, Slides, ePub, etc.)
- A simple consensus-based way of organizing and structuring textual (and other) resources
- An archival, well-understood, format for long-term preservation of digital data and metadata
- Whatever you make it! It is a community-driven standard


TEI Structure



Global Attributes
Some features (potentially) apply to everything, therefore members of the attribute class att.global can appear in every TEI element:
- @xml:id provides a unique identifier for any element
- @n provides a number or name for an element (not unique)
- @xml:lang specifies the language of any element, using an ISO standard code (e.g. ISO 639-1)
- @rend provides a way of specifying the visual appearance (rendition) of any element
- @resp points to the agency responsible; @cert for certainty
- @n gives a way to give a name or number for that element
Inside the <body>
Hierarchical grouping of text sequences into textual divisions and subdivisions by means of nested <div> elements.
- Use of the @type attribute to distinguish different kinds of divisions
- Epic, Bible → book
- Report → part, section
- Novel → chapter
- Drama → acts, scenes
- Reference book → sections
- Diary → entries
- Newspaper → sections, issues
- and possibly @n to provide a name or number of any kind:

Components of a <div>
What do devisions contain (apart from other divisions)?
-
Headings, tagged with <head>
-
Prose, which may be organized as a sequence of
paragraphs <p> -
Poetry, divided into metrical lines <l>, optionally grouped into stanzas <lg>
-
Drama, divided into speeches <sp>, containing an
optional speaker label <speaker>, followed by a mix of <p> or <l> elements, optionally mixed up with stage directions <stage>
Original Layout Information
Within the <text> element the logical view is privileged, but the physical view can be encoded as well through 'empty' elements:
-
<pb /> marks the start of a new page
-
<cb /> marks the start of a new column
-
<lb /> marks the start of a new line
-
<gb/> marks the start of a new gathering
and for other forms of milestone:
- <milestone/> marks to the beginning of a boundary point.
Basic Core Components
Paragraphs
A paragraph is a significant organizational unit for all prose texts
- <p> marks paragraphs in prose
- <p> can contain all the phrase-level elements in the core module
- Phrase-level elements must be entirely contained within a paragraph
- Inter-level elements can appear either within a paragraph or between
- paragraphs (e.g. list, bibiographic citations, etc.)
- Chunks (eg. paragraphs, anonymous block)


Highlighting
Typographic features in order to distinguish passages from its surroundings:
- distinct in some way (e.g. foreign, dialectal, technical, etc.)
- emphatic or stressed when spoken
- not part of the body of the text (e.g. title, head, label, etc.)
- distinct narrative stream (e.g. monologue, commentary, etc.)
- attributed by the narrator to some other agency (e.g. direct speech, quotation, etc.)
- set apart from the text in some other way (e.g. individual names in older texts, editorial corrections or additions, etc.)
Highlighting
<hi> word or phrase which is graphically distinct from the surrounding text
- @rend specifies the visual appearance; the values are defined by each project


Foreign Phrases
-
<foreign> word or phrase not written in the same
language than the surrounding text-
@xml:lang global attribute to specify the language, using an ISO standard code (e.g. ISO 639-1)
-

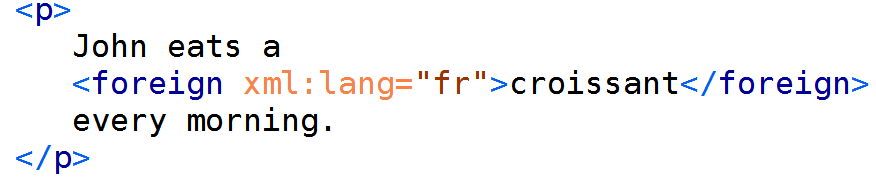
Simple Editorial Changes
- The core module provides some phrase-level elements which may be used to record simple editorial interventions.
- <choice> groups alternative encodings for the same point in a text
- Abbreviations:
- <abbr> abbreviated form
- <expan> expanded form
- Errors:
- <sic> apparent error
- <corr> corrected error
- Regularization:
- <orig> original form
- <reg> regularized form
- Abbreviations:
Abbreviation and Expansion



Emendation and Correction


Regularisation


Addition, Deletion, and Ommisions
-
<add> addition to the text
-
<del> letter, word or phrase marked as deleted in the text
-
<supplied> marks editorially supplied text
-
<gap> indicates a point where material is omitted
-
<unclear> marks where text is illegible, containing best guess

Names
- <persName> a personal name sometimes containing:
- <forename> a forename
- <surname> a surname
- <placeName> a place name
- <orgName> an organisational name
<persName role="stationer">
<forename>Thomas</forename>
<surname>marshe</surname>
</persName>Numbers
- <num> a number of any sort, written in any form
- @type and @value
<seg type="fee" rend="roman-numerals aligned-right">
<!--processing: iiijd-->
<num type="totalPence" value="4">
<!--orig: iiijd-->
<num type="pence" value="4">
iiij<hi rend="superscript">d</hi>
</num>
</num>
</seg> Dates and Times
- <date> contains a date in any format @when contains the regularized form; YYYY-MM-DD
- @notBefore / @notAfter: for circa dates
- @from / @to: for date ranges

<date from="1557-07-19" to="1558-07-09">19 July 1557–9 July 1558.</date>
<date notBefore="1559-07-14" notAfter="1560-07-05">14 July 1559–5 July 1560.</date>
<date when="1560-03-04">
iiij<hi rend="superscript">th</hi> Daye of marche
<note resp="#arber">1560</note>
</date>Lists
- <list> (a sequence of items forming a list)
- <item> (one component of a list)
- <label> (label associated with an item)
- <headLabel> (heading for a column of labels)
- <headItem> (heading for a column of items)

Metadata Block
SRO is being slightly unusual in embedding a metadata block (using the 'anonymous block' element <ab>) inside every entry.
<ab type="metadata">
<date notBefore="1565-07-22" notAfter="1566-07-22">
22 July 1565–22 July 1566.
</date>
<idno type="RegisterRef">Register A, f.132v</idno>
<idno type="ArberRef">I. 296</idno>
<idno type="RegisterID">?</idno>
<num type="works" value="0"/>
<note type="status" subtype="unknown"/>
</ab>Revision Description
In the header <revisionDesc> is used to store the major stages of modification/creation/revision of the electronic file:
<revisionDesc>
<change when="2017-01-29">
Metadata block created by JC; Arber's corrections made by IG
</change>
<change when="2017-01-22">
Material other than copy entries removed by Ian Gadd
</change>
<change from="2013-06" to="2013-10">Semi-automated changes based
on bodleian proofreading made to the SRO data after the initial
conversion (and up-conversion of roman numerals, fees, dates,
names, etc.) from abbreviated tei-corset schema by James Cummings
</change>
<change from="2012-12" to="2013-05"> Encoding reviewed, with
suggestions made for improvements, a random sample of names
checked, and spot-proofed by Pip Willcox. December 2012 - May 2013.
</change>
</revisionDesc>All SRO Elements
- core: p foreign hi desc gap unclear num date list item head note pb lb respStmt resp title choice abbr expan corr sic orig reg add
- header: teiHeader fileDesc titleStmt funder principal publicationStmt distributor availability licence sourceDesc encodingDesc projectDesc revisionDesc change idno
- linking: ab anchor seg
- namesdates: orgName persName surname forename placeName
- textstructure: TEI text body div
- transcr: fw space am ex supplied