Tensor Types & Categories
James B. Wilson, Colorado State University



Follow the slides at your own pace.
Open your smartphone camera and point at this QR Code. Or type in the url directly
https://slides.com/jameswilson-3/tensor-types-cats/#/

Major credit is owed to...


Uriya First
U. Haifa
Joshua Maglione,
Bielefeld
Peter Brooksbank
Bucknell
- The National Science Foundation Grant DMS-1620454
- The Simons Foundation support for Magma CAS
- National Secturity Agency Grants Mathematical Sciences Program
- U. Colorado Dept. Computer Science
- Colorado State U. Dept. Mathematics

Why care about categories?
Problem: how to intersect large classical groups.
Quadratic equations in d^2 variables.
Genercially quadratic equations are as hard as all polynomial equations.
Obvious solution is Groebner basis which is impossibly hard even for d=4.

Isometry is equivalence in this cateogry (columns are objects.)
But what if we look at a different category?
The Adjoint category:
- The adjoint category is abelian.
- Endomorphisms form a ring (computable).
- Isomorphisms are units of a ring (computable).
Isomorphism in Isometry category is THE SAME as isomorphism in adjoint category
Just flip the arrow -- legal because with isomorphism arrows are invertible.
Categories matter because they let us change the question, and see something different to try.
They also are critically helpful in making useful programs.
Objectives
- All the right types
- Noether's Isomorphisms
- Functors
- A representation theory
Notation Choices
Below we explain in more detail.
Notation Motives
Mathematics Computation
Vect[K,a] = [1..a] -> K
$ v:Vect[Float,4] = [3.14,2.7,-4,9]
$ v(2) = 2.7
*:Vect[K,a] -> Vect[K,a] -> K
u * v = ( (i:[1..a]) -> u(i)*v(i) ).fold(_+_)
Matrix[K,a,b] = [1..b] -> Vect[K,a]
$ M:Matrix[Float,2,3] = [[1,2,3],[4,5,6]]
$ M(2)(1) = 4
*:Matrix[K,a,b] -> Vect[K,b] -> Vect[K,a]
M * v = (i:[1..a]) -> M(i) * v
Difference? Math has sets, computation has types.
But types are math invention (B. Russell); lets use types too.
A type for Tensors
Definition. A tensor space is a linear map from a vector space into a space of multilinear maps.
Tensors are elements of a tensor space.
The frame is
The axes are the
The valence is the the size of the frame.
Naïve Tensors: Lists of lists
You type this:
t = [[ 3, 1, 0 ],[ 0, 3, 1 ],[ 0, 0, 3 ]]
You're thinking of:
But your program plans for:
Effect: your program stores your data all-over in memory heap and slows down to double-check your instructions.
Details.
Memory Layout Problems
In a garbage collected systems (Java/Python/GAP/Magma
/Sage...) objects are stored on a heap - e.g. a balanced (red/black) tree.
Separate data like rows in a list of lists are therefore placed into the heap in the place that balances the tree.
While lookups are logarithmic, because your data is spread out but only ever used together, you add slow down.
Memory Access Problems
The more structured your data structure the more complex the lookup.
In a list of lists what you actually have is a pointer/reference to on address in memory for each row.
Within a list you can just add 1, 2, etc. to step the counter through the row.
However, if you intend to step through columns you jump around memory -- may force machine to load data in and out of cache.
Index bounds
Languages like Java/Python/GAP/Magma etc. need to confirm that you never access an entry outside the list.
So A[i][j][k] is in principal checking that i, j, and k are each in the right bounds.
As a list of lists, many systems cannot confirm that j is in range until it has the correct row (recall the computer prepares for uneven rows!) This is true even for most compiled languages.
Result: bounds are checked at runtime, even if you know they are not needed.

Abacus Tensors
Solution: separate the data from the grid.
Tensors are any element of a tensor space so as long as they can be interpreted as multilinear they are indeed tensors. No grids needed.
Abacus Tensor Contraction
Math is this:
See how we often access entire regions contiguously or by arithmetic progression.
Bad idea: perform arithmetic for each index lookup!
Quickly that work costs more than the actual tensor contraction.
Indices of abacus tensors
Math is this:
Step through indices with an "abacus machine", e.g. Minsky Annals Math, 1960.
These are Turing complete computational models that are based on numbers -- not symbols -- so arithmetic is the program.
Never heard of one? Oh, its simply the registers AX, BX, ... with on x86 compatible microprocessor!
Safe Index Lookup
Problem: Checking bounds required only if computer cannot prove (before run-time) that we are in range.
Solution: don't give an index, give a proof!
t:Tensor 10 20 = ...
t[i+j=10][1<=k<=20]
t:Tensor a b = ...
t[i+j=a][1<=k<=b]"=" and "<=" are data, proofs are data!
Even data based on variables allowed -- says when values are given they will conform to the stated structure.
The computer (compiler) can then safely remove all checks.
But requires a dependent type system.
Taste of Types
Terms of types store object plus how it got made
Implications become functions
hypothesis (domain) to conclusion (codomain)
(Union, Or) becomes "+" of types
(Intersection,And) becomes dependent type
Types are honest about "="
Sets are the same if they have the same elements.
Are these sets the same?
We cannot always answer this, both because of practical limits of computation, but also some problems like these are undecidable (say over the integers).
In types the above need not be a set.
Sets are types where a=b only by reducing b to a explicitly.
Do types slow down my code?
Quite the opposite: despite adding potentially more lines to your code, think of those as instructions to the compiler on how to remove any unnecessary steps at runtime. (The axioms of unique choice implies you can remove all the line-by-line proofs in process known as "erasure".)
Bonus: programming this way means when it works, you have a rigorous math proof that your code is what you claim.
Other Primitives
Stacking/Slicing an Abacus Tensor
To stack: add a wire and move right number of beads. Do vice-versa to slice.

Shuffle an Abacus Tensor
Swap the wires.
Tensor Product
Take the disjoint union of axes abaci!

Avoids writing to memory what in the end is just a bunch of repeated information. Less information to move/store, and easy to recompute.
Other types of tensors
- Formulas: e.g. associator or commutator of an algebra.
- Polarization of polynomials.
- Commutation in a group.
- Sparse linear combinations of tensors
Main Point
Tensor as elements of tensor spaces can therefore be represented by any data structure appropriate to your task. Use that to your advantage.
Tensor Categories
Versors
1. An abliean group constructor (perhaps just an additive category?)
2. Together we a distributive "evaluation" function
3. Universal Mapping Property
Versors: an introduction
Why the notation? Nice consequences to come, like...
Context: finite-dimensional vector spaces
Actually, versors can be defined categorically
Bilinear maps (bimaps)
Rewrite how we evaluate ("uncurry"):
Practice
Practice with Notation
Multilinear maps (multimaps)
Evaluation
Thesis:
Every concept in nonassociative algebra has a tensor analog.





Homotopisms
Recognizing the complexity of nonassociatie algebra, A. A. Albert introduced "isotope" as coarser equivalence:
Algebra isomorphism:
Category theory made all things "-isms" so now "isotopism", and more generally "homotopism".
Homotopisms of tensors
In want of term for tensors we use Albert's.
Compose pointwise
Homotopisms include
- Algebra homomorphisms.
- Linear maps
- Isometries

Linear
Isometry
Yet not everything

Degeneracy
Most theorems fail/harder if we include tensors with degeneracy "all zero rows/columns".
Easy to remove.
But, that removal is not by a homotopism!
Adjoints
Isometries are immensely facilitated by considering adjoints instead.
But, adjoints are not homotopisms!
Further Categories
For tensors of valence n there are 2^n "self-evident" categories.
- Are we missing any?
- When are these equivalent?
- How to compute within them?
- Is this actually a single larger 2 or n-category?
- What kind of categories? Abelian when? Products? Projectives? Simples? Representation theory?
Classifying the Categories
Idea: endomorphisms in a category are monoids.
- Use our polynomial traits to classify all transverse operators that support monoids.
- Then check if any of those traits support categories.
Claim
Kernel is the annihilator of the operator.
Theorem. A Groebner basis for this annihilator can be computed in polynomial time.
Annihilators General

Sets of the Correspondence
Akin to eigen spaces:
Akin to characteristic/minimal polynomial:
Akin to weights:

The Correspondence Theorem (First-Maglione-W.)
This is a ternary Galois connection.
Summary of Trait Theorems (First-Maglione-W.)
- Linear traits correspond to derivations.
- Monomial traits correspond to singularities
- Binomial traits are only way to support groups.
For trinomial ideals, all geometries can arise so classification beyond this point is essentially impossible.
Derivations & Densors
Treating 0 as contra-variant the natural hyperplane is:
That is, the generic linear trait is simply to say that operators are derivations!
However, the schemes Z(S,P) are not the same as Z(P), so generic here is not the same as generic there...work required.
Derivations are Universal Linear Operators
Theorem (FMW). If
Then
(If 1. fails extend the field; if 2. is affine, shift; if 3 fails, then result holds over support of P.)
Tensor products are naturally over Lie algebras
Theorem (FMW). If
Then in all but at most 2 values of a
In particular, to be an associative algebra we are limited to at most 2 coordinates. Whitney's definition is a fluke.


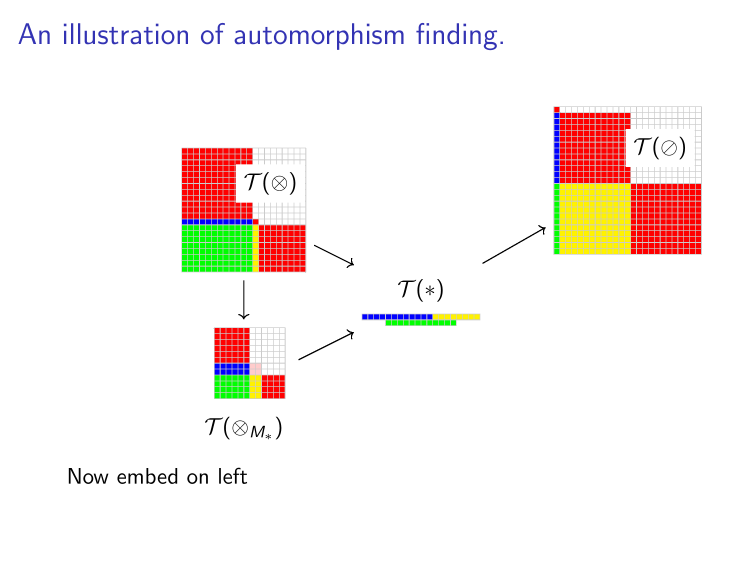
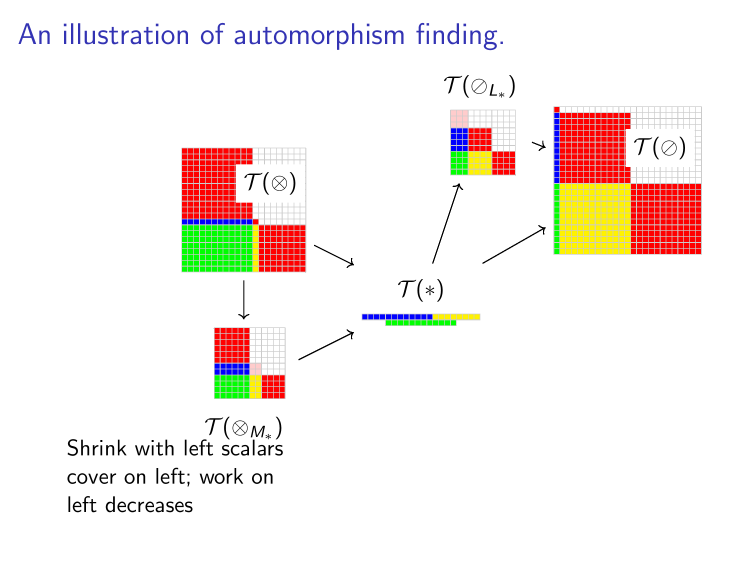




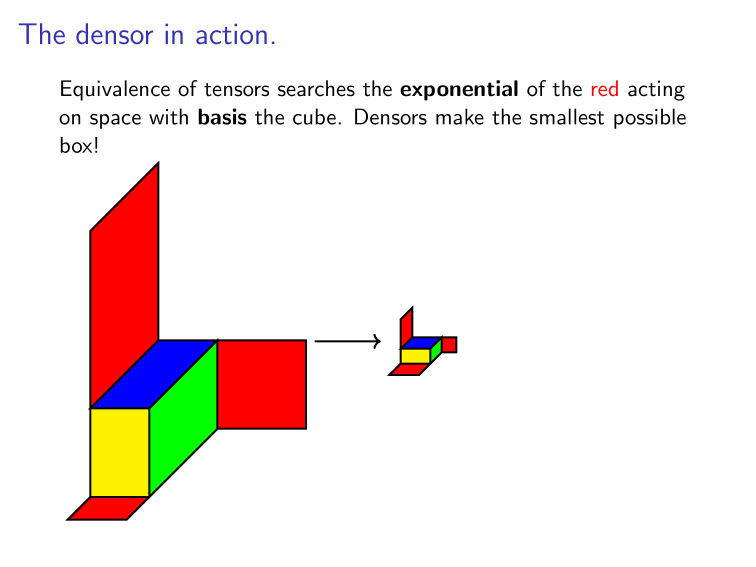
Binomials & Groups
Theorem (FMW). If for every S and P
then
If
then the converse holds.
(We speculate this is if, and only if.)
Binomial Tensor Categories.
Let operators act covariantly on support of e and contravariantly on support of f.





BUT this is rather forced and adds in way more operators than those needed.
Is there a better idea to just glue the natural categories together without introduction morphisms we don't want?
Shuffle the Frames
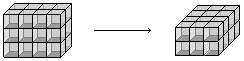

These are basis independent (in fact functors),
E.g.:
Rule: If shuffling through index 0, collect a dual.
And so duals applied in 0 and 1














