


Machine Learning
Workshop: Part Two














Simple neural network trained for XOR logic

forward propagation
@KatharineCodes @JavaFXpert
Feedforward calculations with XOR example
For each layer:

Multiply inputs by weights:
(1 x 8.54) + (0 x 8.55) = 8.54
Add bias:
8.54 + (-3.99) = 4.55
Use sigmoid activation function:
1 / (1 + e
-4.55
) = 0.99
@KatharineCodes @JavaFXpert




















Simple neural network trained for XOR logic
back propagation (minimize cost function)
@KatharineCodes @JavaFXpert
Back propagation
(Uses gradient descent to iteratively minimize the cost function)

@KatharineCodes @JavaFXpert






Great website for data science / machine learning enthusiasts

@KatharineCodes @JavaFXpert
Let’s use a dataset from kaggle.com to train a neural net on speed dating

@KatharineCodes @JavaFXpert
Identify features and label we’ll use in the model
Let’s use 65% of the 8378 rows for training and 35% for testing

@KatharineCodes @JavaFXpert
Code that configures our speed dating neural net


@KatharineCodes @JavaFXpert
Trying our new speed dating neural net example
In this example, all features are continuous, and output is a one-hot vector
@KatharineCodes @JavaFXpert
Making predictions with our speed dating neural net
Note that input layer neuron values are normalized

@KatharineCodes @JavaFXpert
Output from training Speed Dating dataset
In iterationDone(), iteration: 0, score: 0.8100 In iterationDone(), iteration: 20, score: 0.5991 In iterationDone(), iteration: 40, score: 0.5414 In iterationDone(), iteration: 60, score: 0.5223 In iterationDone(), iteration: 80, score: 0.5154 Examples labeled as 0 classified by model as 0: 1356 times Examples labeled as 0 classified by model as 1: 354 times Examples labeled as 1 classified by model as 0: 413 times Examples labeled as 1 classified by model as 1: 800 times ==========================Scores======================== Accuracy: 0.7351 Precision: 0.7269 Recall: 0.7239 F1 Score: 0.7254
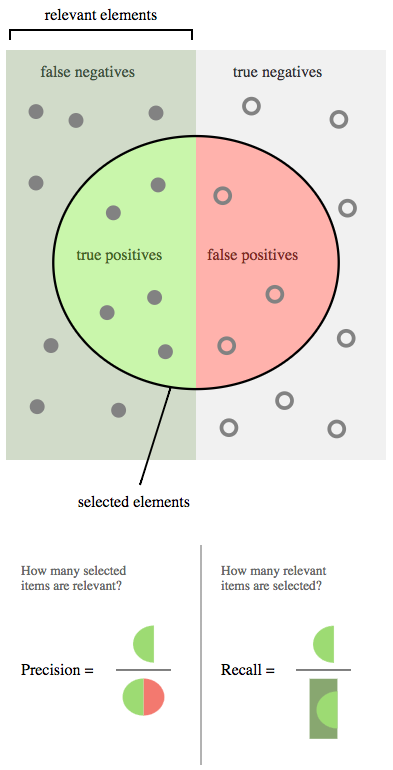
@KatharineCodes @JavaFXpert
}














Is Optimizing your Neural Network a Dark Art ?
Excellent article by Preetham V V on neural networks and choosing hyperparameters

@KatharineCodes @JavaFXpert
Regression Sum example
Features are continuous values, output is continuous value

@KatharineCodes @JavaFXpert
Training a neural network to play Tic-Tac-Toe

@KatharineCodes @JavaFXpert
Tic-Tac-Toe neural network architecture

Input layer: 9 one-hot vectors (27 nodes)
- 1,0,0 (empty cell)
- 0,1,0 (X in cell)
- 0,0,1 (O in cell)
Hidden layer: 54 sigmoid neurons
Output layer: One-hot vector (9 nodes)
Client developed in JavaFX with Gluon mobile
0
0
0
0
0
1
1
1
1
0
0
0
0
0
0
0
0
1
0
/player?gameBoard=XXOOXIIOI
&strategy=neuralNetwork
"gameBoard": "XXOOXXIOI",
{
}
...
Java/Spring REST microservice
@KatharineCodes @JavaFXpert
Tic-Tac-Toe training dataset
0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0
3, 0,1,0, 0,0,1, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0
3, 0,1,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0
1, 0,1,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0
1, 0,1,0, 1,0,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0, 1,0,0, 1,0,0
2, 0,1,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0, 1,0,0
1, 0,1,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0
2, 0,1,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0
2, 0,1,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 1,0,0, 0,0,1
4, 0,1,0, 0,0,1, 1,0,0, 0,1,0, 1,0,0, 1,0,0, 0,0,1, 1,0,0, 1,0,0
...
Play cell
Game board cell states before play
Leveraging the neural network as a function approximator
@KatharineCodes @JavaFXpert
Tic-Tac-Toe training dataset
Generated using game theory minimax algorithm
https://github.com/JavaFXpert/tic-tac-toe-minimax written in Java by @RoyVanRijn using guidance from the excellent Tic Tac Toe: Understanding The Minimax Algorithm article by @jasonrobertfox
@KatharineCodes @JavaFXpert
Taking Tic-Tac-Toe for a spin
@KatharineCodes @JavaFXpert
Summary of neural network links (1/2)
Andrew Ng video:
https://www.coursera.org/learn/machine-learning/lecture/zcAuT/welcome-to-machine-learning
Iris flower dataset:
https://en.wikipedia.org/wiki/Iris_flower_data_set
Visual neural net server:
http://github.com/JavaFXpert/visual-neural-net-server
Visual neural net client:
http://github.com/JavaFXpert/ng2-spring-websocket-client
Deep Learning for Java: http://deeplearning4j.org
Spring initializr: http://start.spring.io
Kaggle datasets: http://kaggle.com
@KatharineCodes @JavaFXpert
Summary of neural network links (2/2)
Tic-tac-toe client: https://github.com/JavaFXpert/tic-tac-toe-client
Gluon Mobile: http://gluonhq.com/products/mobile/
Tic-tac-toe REST service: https://github.com/JavaFXpert/tictactoe-player
Java app that generates tic-tac-toe training dataset:
https://github.com/JavaFXpert/tic-tac-toe-minimax
Understanding The Minimax Algorithm article:
http://neverstopbuilding.com/minimax
Optimizing neural networks article:
https://medium.com/autonomous-agents/is-optimizing-your-ann-a-dark-art-79dda77d103
A.I Duet application: http://aiexperiments.withgoogle.com/ai-duet/view/
@KatharineCodes @JavaFXpert
Summary of reinforcement learning links
BURLAP library: http://burlap.cs.brown.edu
BURLAP examples including BasicBehavior:
https://github.com/jmacglashan/burlap_examples
Markov Decision Process:
https://en.wikipedia.org/wiki/Markov_decision_process
Q-Learning table calculations: http://artint.info/html/ArtInt_265.html
Exploitation vs. exploration:
https://en.wikipedia.org/wiki/Multi-armed_bandit
Reinforcement Learning: An Introduction:
https://webdocs.cs.ualberta.ca/~sutton/book/bookdraft2016sep.pdf
Tic-tac-toe reinforcement learning app:
https://github.com/JavaFXpert/tic-tac-toe-rl
@KatharineCodes @JavaFXpert
Machine Learning