Flexible uncertainty quantification in medical imaging
12th CVPR Workshop on Medical Computer Vision
2026



Jeremias Sulam
50 years ago ...
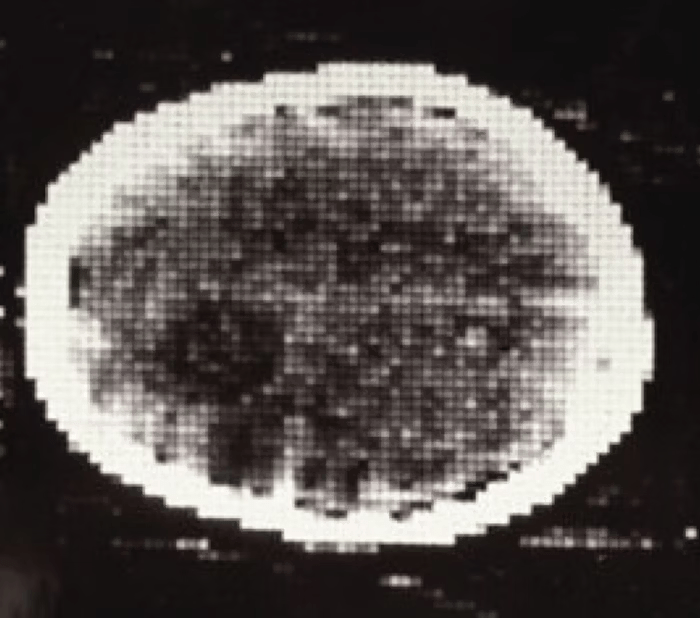
first CT scan


ELECTRIC & MUSICAL INDUSTRIES
50 years ago ...
imaging
diagnostics
complete hardware & software description
human expert diagnosis and recommendations

imaging was "simple"
... 50 years forward

Data

Compute & Hardware



Sensors & Connectivity







Research & Engineering
... 50 years forward


data-driven imaging
automatic analysis and rec.
societal implicationsData
Compute & Hardware
Sensors & Connectivity
Research & Engineering

data-driven imagingautomatic analysis and rec.societal implicationsProblems in trustworthy biomedical imaging
inverse problems
uncertainty quantification
robustness
generalization
demographic fairness
hardware & protocol optimization
model-agnostic interpretability
policy & regulation
monitoring & auditing
data-driven imagingautomatic analysis and rec.societal implicationsProblems in trustworthy biomedical imaging
inverse problems
uncertainty quantification
robustness
generalization
demographic fairness
hardware & protocol optimization
model-agnostic interpretability
policy & regulation
monitoring & auditing

in a box
Denoiser
Measurements
Reconstruction
Uncertainty Quantification in Inverse Problems
(point predictors)
What is the uncertainty in the guess ?
How do we report uncertainty rigorously?
Measurements
Uncertainty Quantification in Inverse Problems
Sampling
in a box
Denoiser
(predictive distribution)
What is the uncertainty in the guess ?
How do we report uncertainty rigorously?
Mathematical tractability vs Complexity
in a box
simpler models
more assumptions
any model
no assumptions
Denoiser
Linear models
Linear networks
Shallow
ReLU Networks
Just ask GPT
Conformal guarantees
Bayesian
MC Dropout
Uncertainty through Prediction Sets
How do we construct them?
- pixel-wise mean standard deviation
- Quantile regression
- MC-dropout (Gal & Ghahramani, 2016)
- any other heuristics...
Conformal Risk Control (CRC)
Uncertainty through Prediction Sets
ground truth!
controls risk at level if
"On average, no more than pixels are outside the sets"
\(x_j\)
Conformal Risk Control (CRC)
Given cal. set , let
Lemma
[Angelopoulos et al, 2024]
Then, .
Conformal Risk Control (CRC)
Given cal. set , let
Then, .
Lemma
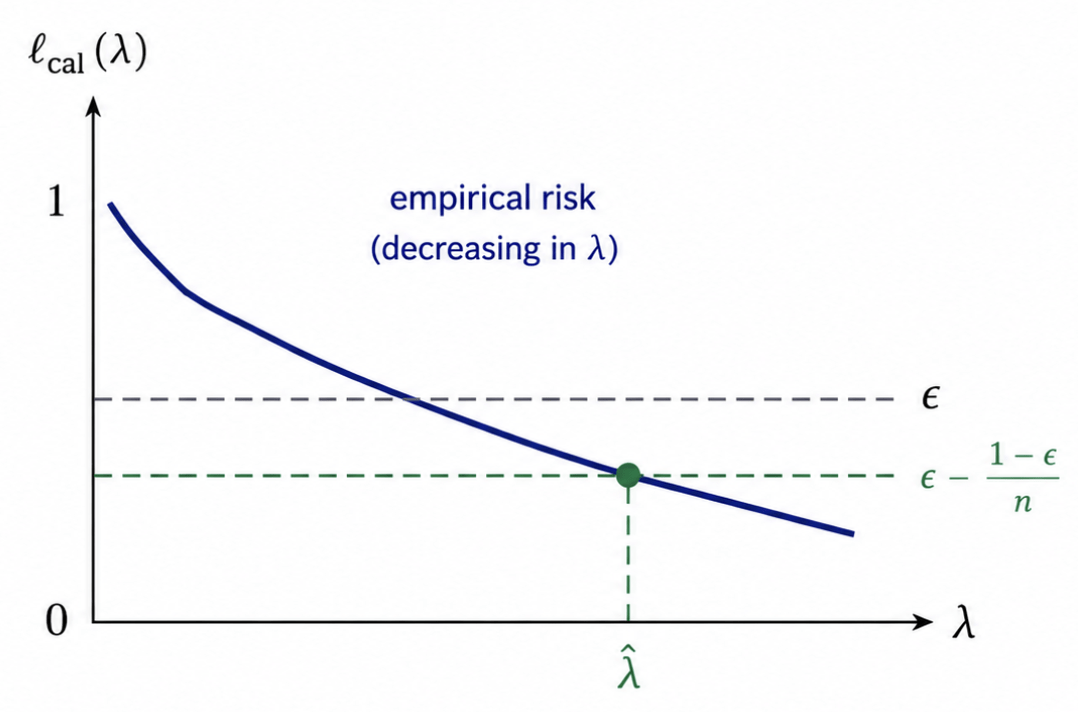
[Angelopoulos et al, 2024]
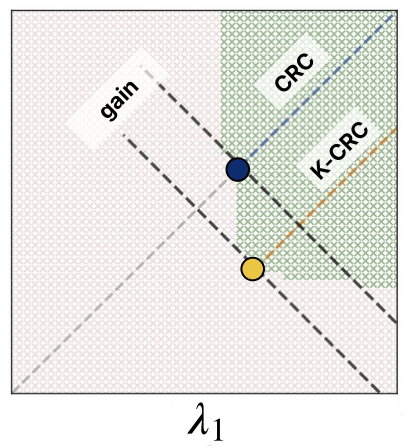
High Dimensional Risk Control
Observation 1: Single for all dimensions... suboptimal
High dimensional alternative
Goal: minimize the mean interval length
[Teneggi et al, 2023]
Semantic Risk Control
Observation 2: High-dim data is heterogenous
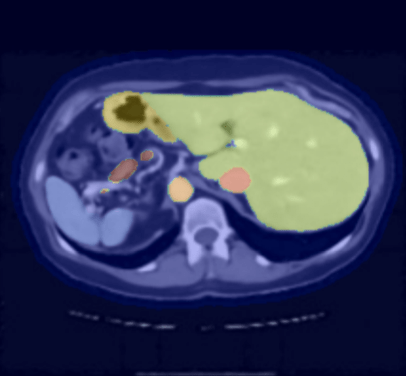
Let vary according to content/semantics (e.g. per organ via a segmentation model)
Segmentation model
Semantic uncertainty
Semantic Risk Control
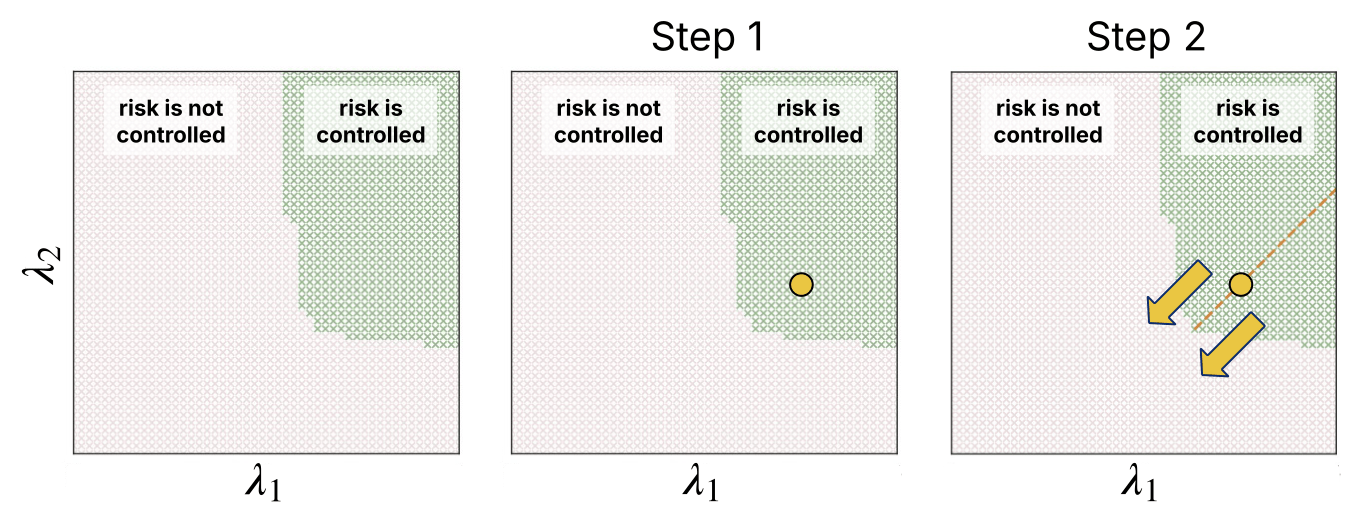
1. Find an anchor :
: convex upper bound to
2. Calibrate
\(s_k:\) expected size of organ \(k\)
Semantic Risk Control
2. Calibrate
1. Find an anchor :
Guarantee
For any segmentation model \(s(Y)\in[K]\), any \(\epsilon > 0\) and exchangeable and independent calibration samples,
\[ \mathbb{E}\!\left[ \ell\!\left(\mathcal C_{\hat{\lambda}_{\mathrm{sem}}}(Y),X\right) \right] \le \epsilon . \]
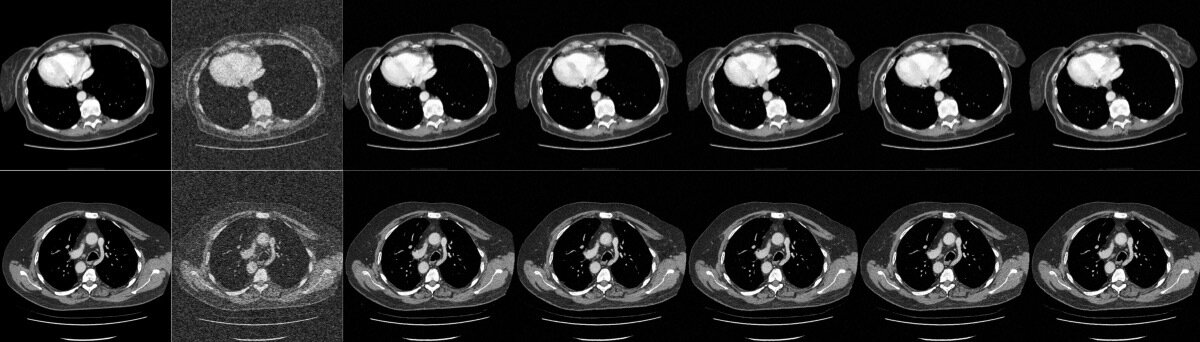
Experiments
- CT reconstruction on TotalSegmentor (Wasserthal et al. 2023)
- Quantile Regression (Unet) for heuristic and
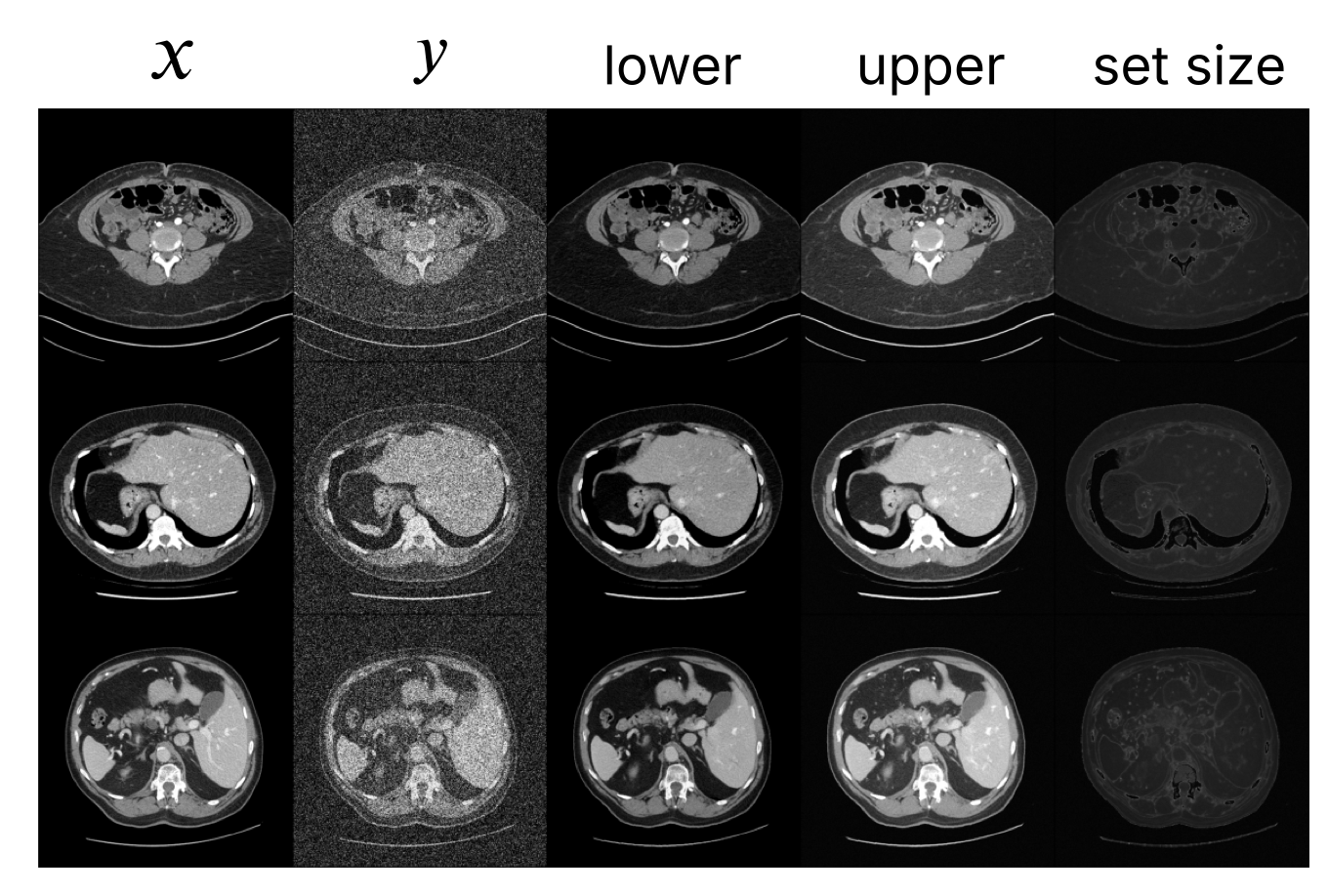
Experiments
- CT reconstruction on TotalSegmentor (Wasserthal et al. 2023)
- Quantile Regression (Unet) for heuristic and
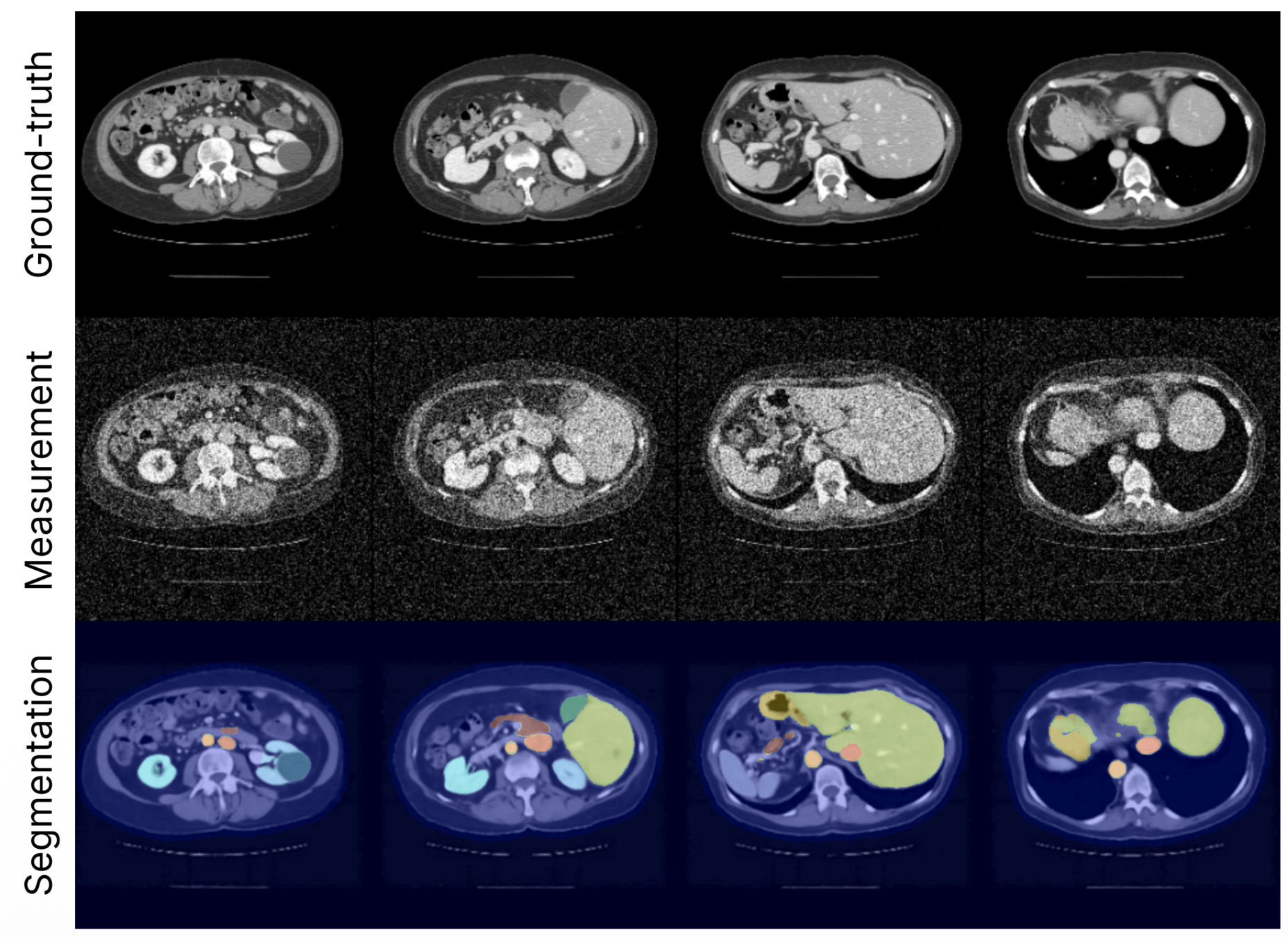
- Segmentation via SuPrem (Li, Yuille, and Zhou 2024)
spleen, kidneys, gallbladder, liver, stomach, aorta, inferior vena cava (IVC), pancreasSemantic risk control
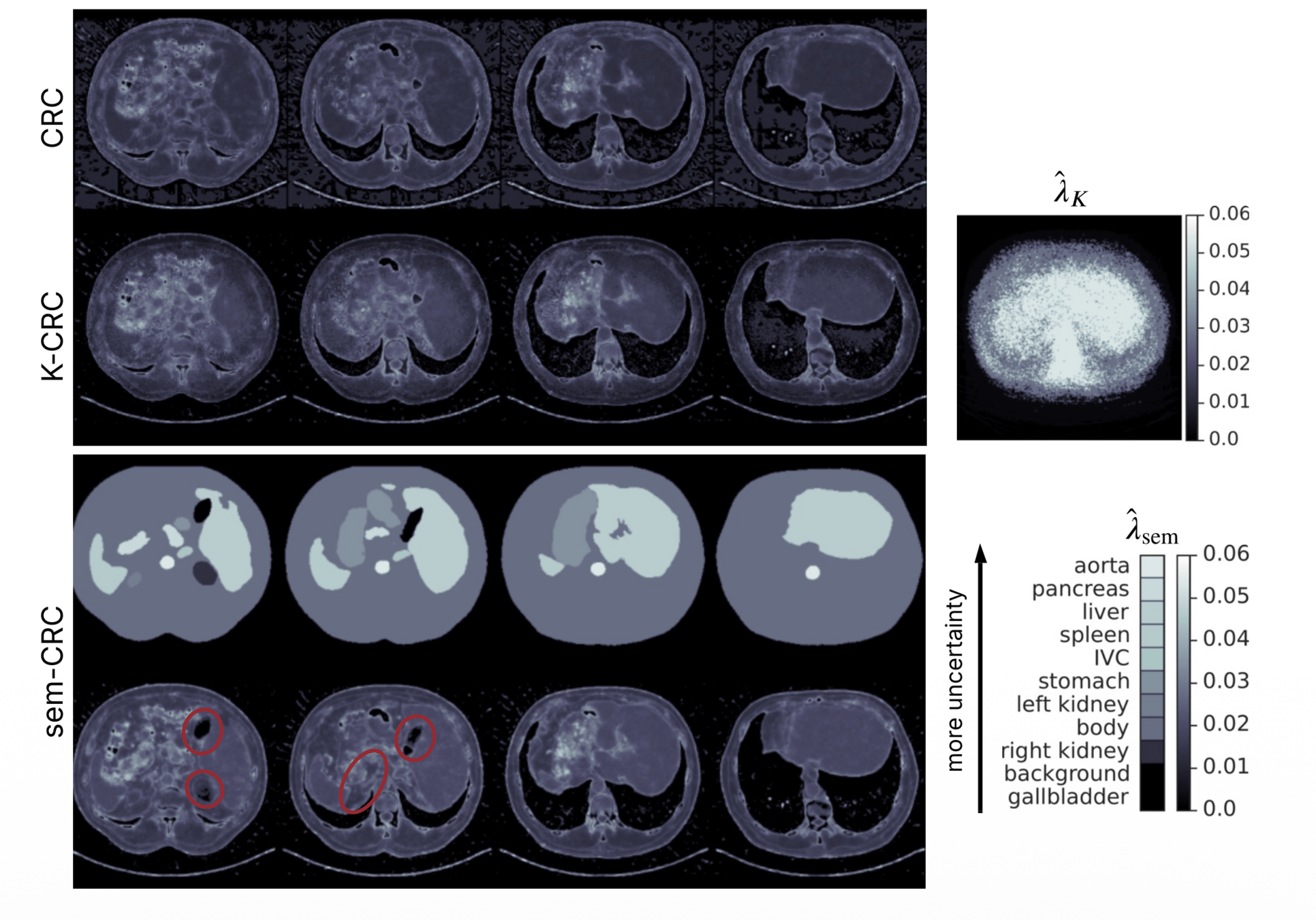
Semantic risk control
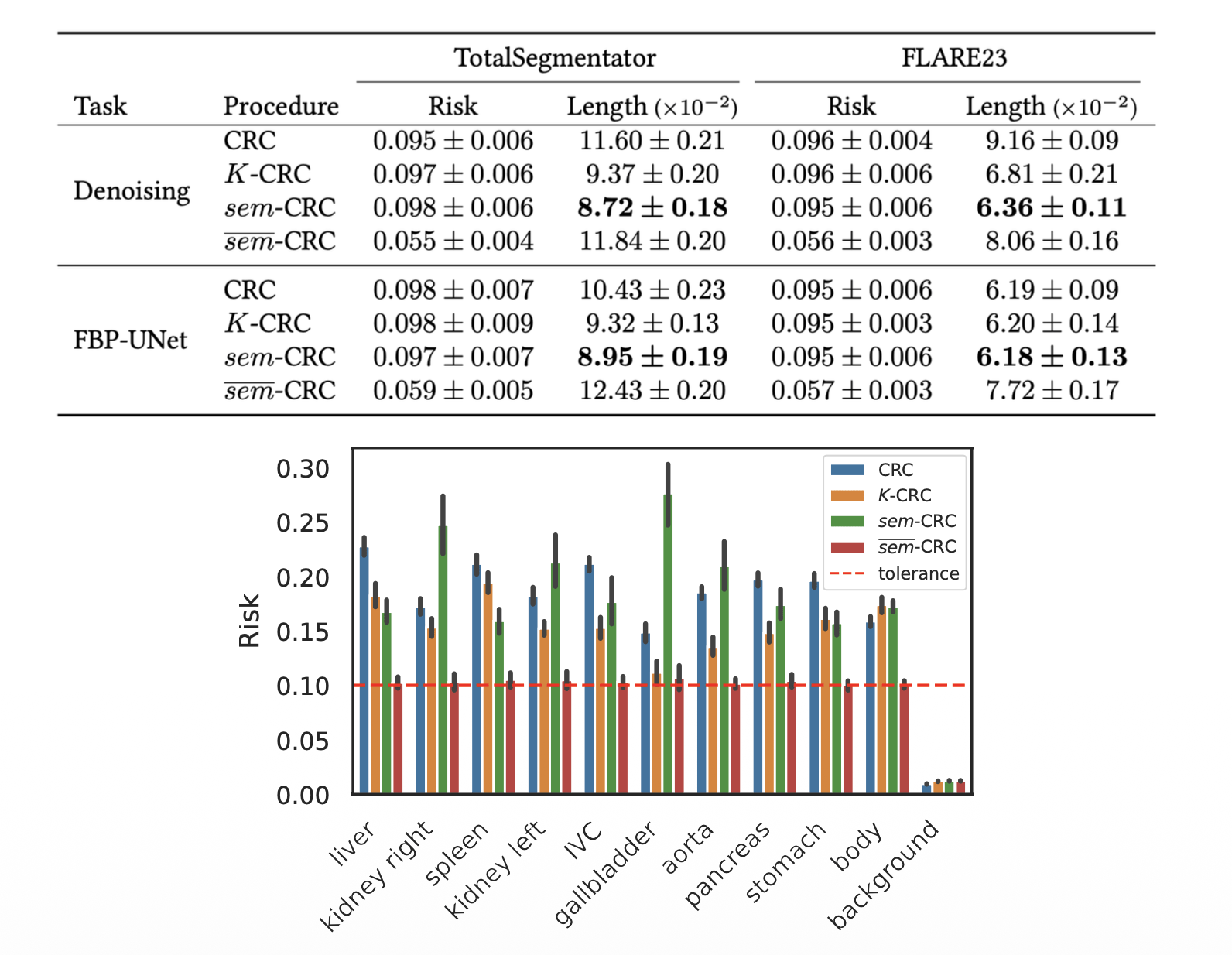
risk controlled uniformly for every organ
Recap
-
Conformal prediction allows for flexible UQ, with minimal assumptions
-
In high-dimensional settings, K-CRC allows for optimizing mean interval lengths
-
When samples are heterogeneous, semantic CRC allows for input-specific semantic calibration
Acknowledgements

Jacopo Teneggi
sem-CRC https://github.com/Sulam-Group/semantic_uq
K-CRC https://github.com/Sulam-Group/k-rcps
Funding: NSF CAREER Award CCF 2239787 and NIH R01CA287422


Teneggi, J., Tivnan, M., Stayman, W., & Sulam, J. How to trust your diffusion model: A convex optimization approach to conformal risk control. ICML 2023
Teneggi, J., Stayman, J. W., & Sulam, J. Conformal risk control for semantic uncertainty quantification in computed tomography. MICCAI 2025
policy & regulation
robustness
generalization
uncertainty quantification






