LLM vs Ops
How to provide AI to your colleagues

Large Language Models
"What ChatGPT does"






- Generate Texts
- Summarization
- Classification
- Question Answering
Actual plan
- Follow Instructions
- Reasoning
- Decision making
- evaluate Results
Emergent...
How to use LLMs
How do i write an LLM Solution?

THE LLM Stack
-
Mostly Web, API,WebSockets
-
Streaming
-
Python/NodeJS
-
Tasks
-
Prompt Generation
-
Authentification
-
Input Filtering
-
PII Scrubbing/Replacing
-
-
Existing Operations
Website/Chatbot
-
Just Inference, no training
-
Selection of the right model(s)
-
Text Generation
-
Token Streaming
-
Watermarking
-
"pip install" APIs
Large Language Model

| Factor | Relevance |
|---|---|
| Speed | Responsivity token per second |
| Costs | Costs dollar /1000 Token |
| Instruction Following | How well does it follow instructions? |
| Reasoning | How reliable does it understand logical dependencies |
| Size | What does the Model know /size |
| Context Size | How large is the working input? |
Attributes of LLMs
GPT-3.5-Turbo
Context-Size 4k-16k
500.000 token/$
GTP-4
Context-Size 4k-32k
17.000 token/$
Strategie
Default zu GPT-3.5-turbo
Bei komplexen Tasks GPT-4
OpenAI LLMS


Available as OpenAI-Service @ Azure
Claude Instant
Context-Size 100k!
180.000 token/$
Claude v1
Context-Size 100k!
28.000 token/$
Strategie
Default zu Instant
Bei komplexen Tasks V1
Antrophic LLMS


Available as BEDROCK-Service @ AWS
Google PALM2
Context-Size 8k
Pricing ?
Cohere CORAL
Context-Size 2k
250.000 token/$
AI21 J1
Focus on training
Multiple Models available
Focus on training
Multiple Models available
Additional LLMs
Since there is a lot of VC involved, one new multimillion startup per month

Context-Size 8k
66.666 token/$


LLAMA-Family
Falcon
Mosaic MPT
Completely free
Small
Completely free
A bit slow
Emirates financed open source Model
Open Source LLMS
"Leaked" at Meta
Very fast and innovative community
Improved instructions, quality, context length
Redpajama/OpenLLama-Efforts
Finetuning++


DEMO
Oder warum viele AI-Experten über "Oobabooga" reden...

Training


... Deshalb ist meist Finetuning gemeint, wenn von Training geredet wird ...
Fine-Tuning

Dank der OpenSource-Community inzwischen auf Consumer-Hardware möglich.
Fine-Tuning
-
Prompting statt Fine-Tuning
-
Hochdimensional semantisch abgelegt
-
Suche über Next-Neighbor
-
Auswahl relevanter Information geschieht im Prompt
VEkTORDatenbank
Vector-DBs
Vector-DBs

OpenAI-Embeddings zB 1526 Dimensionen
Vector-DBs
Embeddings wandeln von Text zu Vektoren. Sie können lokal oder remote passieren.

Vector-DBs

OpenSource, SAAS, remote, lokal, Cloud, Kubernetes, hybrid, mit Fulltext uvm - es gibt heute Auswahl.
Vector-DBs

Die ganzen "Talk to with your documents", und praktisch alle QA-Lösungen beruhen auf Vektordatenbanken.
Training, Finetuning, VectorDB
Tra
Bei bis zu 6-stelliger Anzahl von Informationen, die integriert oder nachgeschlagen werden sollen.
Finetuning
Bei umfangreichen, spezialisierten Daten - firmenintern oder extern.
Training
Selbst Foundation-Anbieter sein und sehr umfangreiches Wissen mitbringen - wie Bloomberg AI auf Basis von Bloom
Prompting
Technische Prompts, nicht Content und Marketing-Magie :-)
〞
Text-Generation möchte nur statistisch sinnvoll Text fortsetzen.
Halluzinationen
Statistisch korrekt, sachlich falsch.
Was kann man da machen?


Chain of Thought Prompting
Transformer stellen über Attention Worte in Bezug zueinander. Das kann man ausnutzen, indem man explizit wird und damit den Möglichkeitsraum reduziert.
"Think Step by Step"
Few Shot Prompting
A "whatpu" is a small, furry animal native to Tanzania. An example of a sentence that uses the word whatpu is:
We were traveling in Africa and we saw these very cute whatpus.
To do a "farduddle" means to jump up and down really fast. An example of a sentence that uses the word farduddle is:
Prompt Engineering
Teenage Sex Level: Alle reden darüber, die wenigsten machen es, und dann nur schlecht.
Trial and Error
Der Prompt hat einmal funktioniert, also wird er deployed. Bei Fehlern wird korrigiert.
Tracking
Prompts und Antworten werden gespeichert und kontrolliert.
RLHF
Der Nutzer gibt Feedback über das Ergebnis, falsch oder schlecht markierte Ergebnisse werden kontrolliert und als Regression genutzt.
Prompt Injection

Indirect Prompt Injection

Prompt Leaking

-
IDS - wiederkennen bekannter Angriffe über
-
Heuristik
-
LLM-Validierung
-
Vektordatenbank
-
-
Canarys zur Leaking Detection.
Rebuff.io

-
Security über durch LLM ausgeführte DSL
-
Einbettung in LangChain
-
Beschränkungen für
-
Themen
-
Safety
-
Security
-
NVIDIA NeMo guardrails

Observability
"Mit der Einführung von OpenAI Functions
hat sich die Tokenzahl verfünffacht."
AIM: OSS-Tracing

https://aimstack.io/
Weights and Biases
SAAS: Alles von Ops bis Monitoring und Prompthandling
https://wandb.ai/site/solutions/llmops
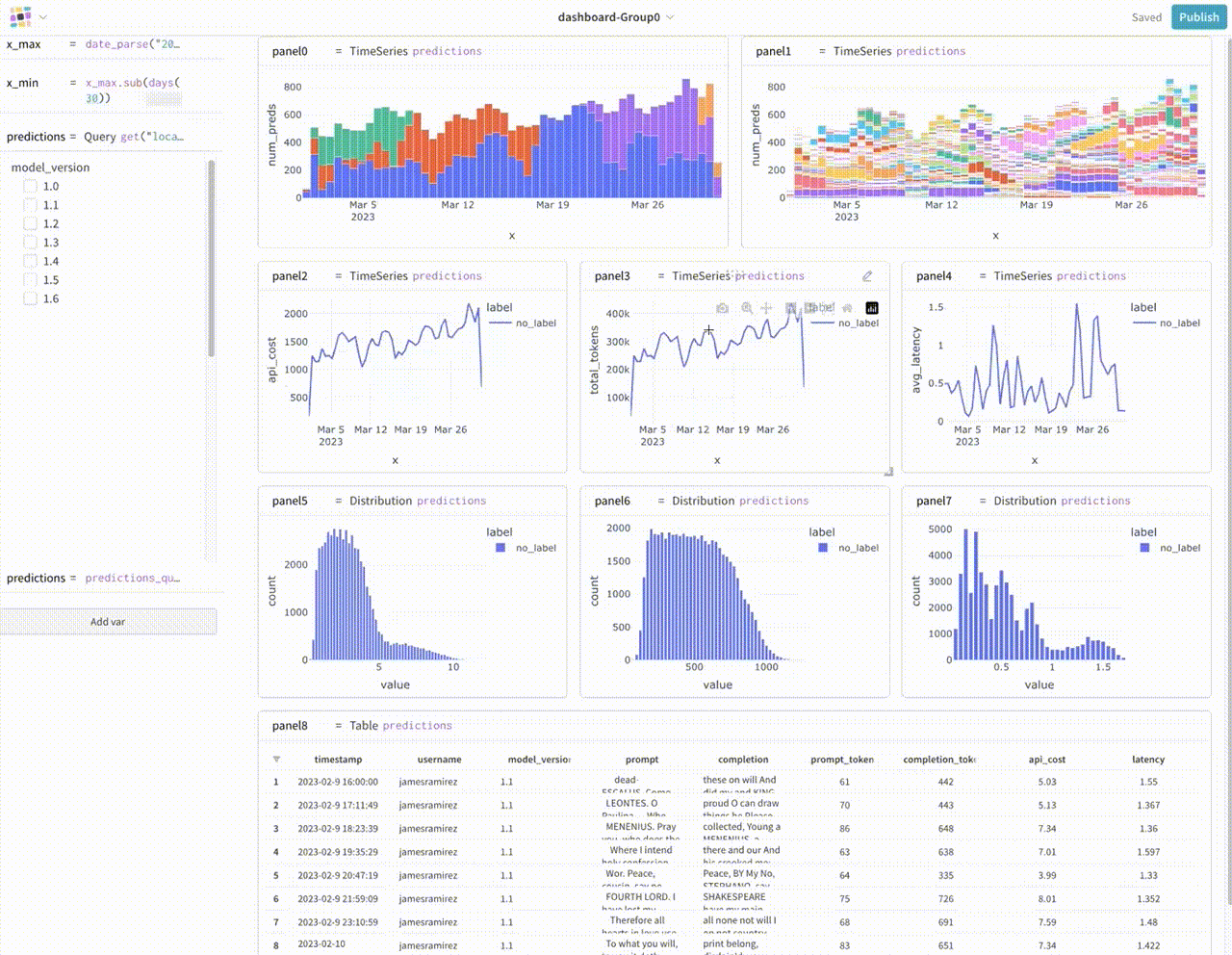
Graphsignal.com
SAAS: Tracing, Monitoring und Cost Monitoring https://graphsignal.com/

Open telemetry
Es gibt noch keine offizielle Integration, aber es lässt sich gut integrieren - siehe https://medium.com/@bocytko/opentelemetry-meets-openai-95f873aa2e41

TEsting / QA
Wie werden LLM-Apps und Prompts gut getestet?

Fazit: Einstieg in LLMS
