LLMs selbst auf Deutsch trainieren

Slides: https://slides.com/johann-peterhartmann/
Warum überhaupt?
Das geht doch mit GPT-4o.

SML - Small Language
Models
- Zugänglichkeit: jeder kann sie verwenden
- Spezialisierung: Gut für spezielle Aufgaben
- RAG
- Summarization
- Tool Calling & Agent Reasoning
- Bei hohem Read/Write-Quotienten statt RAG
- Ressourcenbedarf : Training und Inferenz
- Kosten & Sustainability


Ressourcenbedarf in $
Privacy & Security
- Microsoft ist so mittel in Cloud Security
- Offline Access
- Datensouveränität
- Unabhängigkeit
- Vendor Control
- GDPR ist kein Argument!

Schwere Sprache
- Sprach-Corpora der LLMS sind 🇬🇧
- Chinesisch folgt langsam mit Qwen & Co
- Resultat:
- Reasoning in einer anderen Sprache
- Komplexe und englische Strukturen im Reasoning
- Grammatikfehler

German NLG/GermEval 🇩🇪



https://medium.com/@lars.chr.wiik/claude-opus-vs-gpt-4o-vs-gemini-1-5-multilingual-performance-1b092b920a40
Multilingual Performance 🇩🇪
Multilingual Performance 🇩🇪

https://ellamind.com/de/
Selbst trainieren:
Eigentlich sind wir zu arm.
- GPT-4: 63.000.000$
- Llama3 Hardware costs: 720.000.000$
-
6.400.000 GPU-Stunden H100 80GB
- ... für die kleinen LLama3-Modelle
400B kommt noch.

Pretraining
-
Die Grundlage eines jeden Sprachmodells
-
(meist) next-token-Training für Text Generation
-
Unsupervised
-
Früher galten die Chinchilla-Laws
-
optimale Zahl Token für das Trainung zur Parameterzahl
-
Bei LLama3-8b Faktor 75 über Chinchilla
-

Daten fürs
Pretraining
-
Aktuell: meist Common-Crawl-basiert
-
Im Fall von GPT-3.5ff, Gemini, LLama, ...:
-
dazugekaufte Daten von Verlägen etc
-
-
sehr ausführliche Daten-Aufbereitungs und -filtrierstrecken
-
Seit 3 Wochen:
-
Hugging Face fineweb
-
Deutsch
- Corpora anreichern für deutsches "Sprachgefühl"
- LeoLM 65B aus OSCAR-2301-Korpus
- Analog dazu DiscoLM und OcciGlot-Modelle
- Eigenes Dataset:
https://huggingface.co/datasets/occiglot/occiglot-fineweb-v0.5

Deutsches Pretraining
- Tokenizer vs Deutsch
- Oft sind Tokenizer ineffizient für deutsche Texte
- Oft sind Tokenizer ineffizient für deutsche Texte
- Foundation Models mit deutschen Pre-Training
- Mistral/Mixtral
- LLama3
- Gemma
- Aber: LLama 2
- Platz 1: 89,7% Englisch
- Platz 2: 0.17% Deutsch
OK, es spricht Deutsch.
Aber es macht nicht, was ich ihm sage.

| Instruction | Du bist ein hilfreicher Assistent. |
|---|---|
| Input | Was ist 5+5? |
| Output | Die Addition von 5 und 5 ergibt 10. |
<|im_start|>system Du bist ein hilfreicher Assistent.
<|im_end|> <|im_start|>user Was ist 5+5?
<|im_end|> <|im_start|>assistant Die Addition von 5 und 5 ergibt 10. <|im_end|>
Instruction Tuning/SFT
Instruction Tuning/SFT
Supervised Fine-Tuning
Full Finetuning
- Instruction Tuning mit Propagation über das ganze Modell
- Teuer!

https://cobusgreyling.medium.com/catastrophic-forgetting-in-llms-bf345760e6e2

https://pub.towardsai.net/parameter-efficient-fine-tuning-peft-inference-and-evaluation-of-llm-model-using-lora-03cf9f027c34
Parameter Efficient Finetuning
- Freeze des Original-Models
- Finetuning nur weniger Parameter
- Faktor 3 weniger Speicher
- Faktor 10.000 weniger trainierte Parameter
- Gemeinsame Inference

Freeze des Basismodels
Trainieren von zusätzlichen, kleineren Parametern


LoRA vs Model
model.embed_tokens.weight
model.layers.0.self_attn.q_proj.weight
model.layers.0.self_attn.k_proj.weight
model.layers.0.self_attn.v_proj.weight
model.layers.0.self_attn.o_proj.weight
model.layers.0.mlp.gate_proj.weight
model.layers.0.mlp.up_proj.weight
model.layers.0.mlp.down_proj.weight
model.layers.0.input_layernorm.weight
model.layers.0.post_attention_layernorm.weight
...
model.layers.31.post_attention_layernorm.weight
model.norm.weight
lm_head.weight
LoRA targets

q_proj, k_proj
"systematically identify and eliminate less important components in the model's layers"
LaserRMT / Spectrum
-
dort ändern, wo redundantes Wissen vorliegt.
-
Iterativ Trainieren ohne Einbußen

Current State
-
Faktor 3 weniger Speicher
-
Faktor 10.000 weniger Parameter
-
Aber: ca 4-6% Verlust der Akkuratheit vs. Full Fine-Tune.
Mistral 7B vorher: 112 GB
Mit LoRA: ca 40 GB
QLoRA "Quantized LoRA"

https://towardsdatascience.com/qlora-fine-tune-a-large-language-model-on-your-gpu-27bed5a03e2b
QLoRA-Outcome
-
7B ist bequem auf 24G trainierbar
-
70B ist auf 48G trainierbar(!)
-
Ergebnis: das gleiche LoRA-Safetensors-File
-
(Fast) kein Effekt auf die Performance

Title Text


Und weiter: Unsloth.AI
1 GPU Apache licensed
warnings.warn(
f"Unsloth: 'CUDA_VISIBLE_DEVICES' is currently {devices} \n"\
"Multiple CUDA devices detected but we require a single device.\n"\
f"We will override CUDA_VISIBLE_DEVICES to first device: {first_id}."
)
Aber :Llama-3 8B auf 16G trainierbar.
GaLore
- Full Parameter Finetuning
- Memoryeffizienz wie LoRA
- eigene Gradient-Projection
DoRA/QDoRA
- Modifizierter LoRA
- plus Magnitude-Vektoren
- ein wenig mehr Speicher
- Wir bekommen die 4-6% wieder

https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
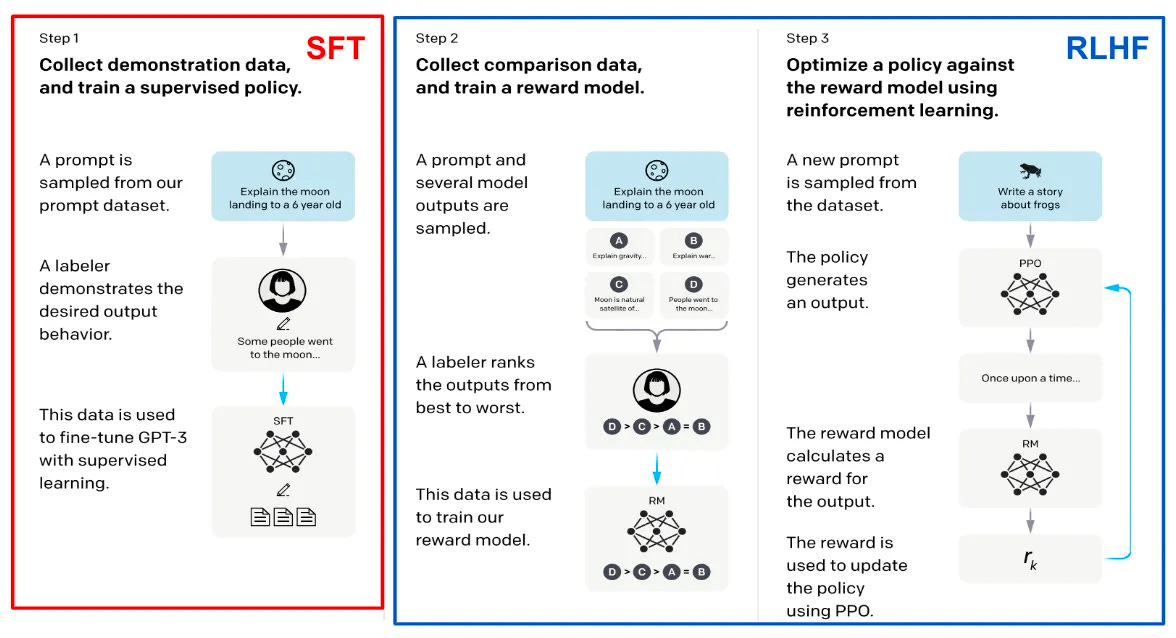
https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
- Basis von GPT-3.5 etc
- Viel Personaleinsatz
-
Komplex durch
Reward-Model
Reward Model

Jemand™ müsste das mal machen.
https://github.com/RLHFlow/Online-RLHF
DPO
| Input | Erzähle, wie Angela Merkel die erste US-Präsidentin wurde. |
|---|---|
| Chosen | Angela Merkel war nie US-Präsidentin, soll ich eine fiktive Geschichte erstellen? |
| Rejected | Mit dem Wahlerfolg von Angela Merkel am 4. April 2018 hätte niemand gerechnet ... |
Direct Preference Optimization
Freeze, Score, Calculate Loss & Update

https://medium.com/@joaolages/direct-preference-optimization-dpo-622fc1f18707
ORPO
- Odds Ratio Preference Optimization
- Statt SFT plus DPO
- In einem Schritt
- Gleiche Daten wie DPO
SimPO
DPO ohne Referenz-Modell
Reward mit Length-Penalty und Margin


Und wo wir schon beim trainieren sind ...
RoPE-Scaling

Context-Length ist kein Differenzkriterium mehr.


Dank
-
peft/lora
-
qlora
-
unsloth
können wir 70B auf 24G.
Aber es dauert noch immer Stunden.


Das klassische 4chan-Problem:
- Bilder von Frauen generieren
- im Anime-Stil
- aber unglaublich realistisch
Lösung:
- Anime-Modell trainieren
- Realistisches Modell trainieren
- Mittelwerte bilden
Es funktionierte tatsächlich.
Eigenschaften in LLMs mergen
- Startpunkt: ein gemeinsames BaseModel
- Step 1: Task-Vektoren sind die Differenz zu Finetunes ausrechnen
- Step 2: Entfernen unnötiger Task-Vektoren
- Step 3: Conflict-Resolution/ Merging der Task-Vektoren
- Step 4: Addition der Vektoren zum Basismodell.



https://github.com/arcee-ai/mergekit
Viele Methoden
Beispiel Dare Ties
- Step 2: Reduktion der Task-Vektoren per Zufall
random pruning + rescaling - Step 3:
- Trim unveränderter Parameter
- Vorzeichendifferenzen nullen
- Merge der alignten Parameter
- Beispiel: Deutsches Modell und StarCoder mergen.
AutoMerger
- Einfach mal per Zufall mergen.
- Deutsche Experimente:
https://huggingface.co/cstr
- mergekit-evolve
Chat-Templates
Llama2/Mistral: <<SYS>> und [INST]
Llama3: <|start_header_id|> ...
Phi3/Zephyr: <|user|> ...
Gemma: <start_of_turn>...
ChatML: <|im_start|>assistant
Token
Es könnte so einfach sein ...
| Model | eos |
|---|---|
| Leo-Mistral | 2 |
| DiscoLM | 32000 |
| SauerkrautLM | 32000 |
| KafkaLM | 2 |
mergekit-tokensurgeon zur Anpassung


https://huggingface.co/blog/moe
Mixture of
Experts
- Ursprünglich MIT 1991
- Google 2022 für LLMs
- OpenAI GPT-4 als Kernidee
- n Experten mit Router
- m aus n aktiv
- Trainieren pro Experte
- Inference pro m Experten

- Mixture of Experts selbst bauen
- Mixture of LoRAs
- Support für
- Llama(3)
- Mistral
- Phi3
- Bert
- Wahlweise einfaches Routing
oder Training
- Kraken: Mixture of Experts in Software per trust_remote_code
- "Collection of Experts": trainierter Router auf einen Lora
- einfachst anzupassen
- Kraken-LoRA: Mixture of LoRAs
- 5 Tage alt

Gute Modelle für den Start
- Direkt auf den Basismodellen von Mistral und LLama3, Gemma
Andere Modelle gehen, haben aber wenig deutsches Pretraining
- occiglot-Modelle von Occiglot :-)
Opensource, staatlich (europäisch) gefördert
- DiscoLM-Modelle von ellamind
Startup mit FOSS-Background
- SauerkrautLMs von VagoSolutions
Startup mit FOSS-Background
- KafkaLM von SeedboxAI


Datasets 1: einfach nutzen :-)
- PreTraining:
https://huggingface.co/datasets/occiglot/occiglot-fineweb-v0.5
- Meist automatisierte Übersetzungen existierender DataSets
- Zum Teil manuell nachbearbeitet
- https://t.ly/EsIT0

Datasets 2: selbst Übersetzen
- Übersetzung durch OpenSource-Modelle per Instruktion
- Übersetzung durch Services
- Übersetzung durch APIs wie GPT-4, Mistral, Claude
- Achtung: GPT-4 erlaubt den Einsatz für Konkurrenten nicht.
- Zum Teil etwas irreführend
"SME" zu "KMU" oder "Fachmann" übersetzen?

Datasets 3: Herstellen

- Auf Basis von existierenden Dokumenten / RAG
- Auf Basis synthetisch generierter Prompts zu Themen
- Auf Basis von Varianten existierender (englischer) Datasets
- Als normales SFT oder als DPO/ORPO/SimPO-Dataset
- Unter Nutzung von AI-Feedback und verschiedenen Modellen
- https://distilabel.argilla.io/

Trainingswerkzeuge
- 8,4 TRL von Huggingface
- 6,3 Axolotl vom OpenAI Collective
- 23,1 LLama_Factory von Yaowei Zheng
- Jeweils mit skypilot/dstack-Support



Hugging Face TRL
Features
- SFT, DPO, PPO, ORPO
- Unsloth-Support
- Eingebettet in HF-Stack

Axolotl
Features
- SFT, Lora, qlora, flashattn
- Config-Getrieben
- Viele Beispiele
- Gute Community

LLaMA-Factory
Features
- Sehr grosse Community ...
- ... in Asien
- adaptiert unglaublich schnell
- Web-Interface & Config
- praktisch alle Algorithmen enthalten, inkl. Unsloth
- Diverse deutsche Datasets enthalten

Evaluieren der Modelle
https://github.com/occiglot/euro-lm-evaluation-harness
Occiglot-Version des EleutherAI-Frameworks
Internationale Standard-Evals auf Deutsch
https://github.com/mayflower/FastEval
Deutsche Übersetzung vom mt-bench mit LLM-as-a-judge
https://github.com/ScandEval/ScandEval
Skandinavische Test-Suite mit Support für Deutsch
https://github.com/EQ-bench/EQ-Bench
Benchmark mit EQ und Kreativität im Fokus. Mit deutschem Translation-Support.
Wo Trainieren?
- Beste Variante: jemand spendet die GPU
- Zweitbeste Variante: Runpod, Vast.ai, Lambdalabs, AWS, ...
- Drittbeste Variante: Eigene Nvidia-Karten
- Viertbeste Variante: Merging
Beispiel
- Kurzzeitig das best-performende deutsche Modell der 7B-Klasse
-
DARE_TIES-Merge per Mergekit von 4 bekannten deutschen Modellen auf Mistral-7B-Basis
- "die Sprachkompetenz zusammenmergen"
- "die Sprachkompetenz zusammenmergen"
- Überarbeites DPO-Dataset auf Basis von Intel-Orca
- Übersetzt mit AzureML
- Chosen mit GPT-4 generiert
- Rejected mit Standard-Mistral-7B generiert

Where to start
Maxime Labonnes LLM-Kurs
https://github.com/mlabonne/llm-course
LazyMergekit
LazyAxolotl
Deutsche Community bei DiscoLM
https://discord.gg/S8W8B5nz3v
Englische Community bei Eric Hartford
https://discord.gg/2ZzR4X9F