LLMs trainieren for
the GPU poor

Warum
überhaupt?

SLM - Small Language
Models
- Zugänglichkeit: jeder kann sie verwenden
-
Anpassbarkeit: selbst trainierbar
-
Spezialisierung: Gut für spezielle Aufgaben
- RAG
- Summarization
- Tool Calling & Agent Reasoning
- Bei hohem Read/Write-Quotienten statt RAG
- Ressourcenbedarf : Training und Inferenz
- Kosten & Sustainability


Ressourcenbedarf in $



Privacy & Security
- Microsoft ist so mittel in Cloud Security
- Offline Access
- Datensouveränität
- Unabhängigkeit
- Vendor Control

Wann sollte ich
das nicht tun?
Wenn ich die DSGVo
einhalten will.
Praktisch jeder grössere LLM-SAAS bietet inzwischen GDPR-compliant an.
Weil ich möchte, dass auf meinen Daten nicht trainiert wird.
Das ist in praktisch allen kostenpflichtigen Angeboten konfigurierbar.
Weil ich PII-Daten
verarbeite.
Die meisten größeren LLM-Libraries bieten reversible data anonymization an.
Selbst trainieren:
Eigentlich sind wir zu arm.
- GPT-4: 63.000.000$
- Llama3 Hardware costs: 720.000.000$
-
6.400.000 GPU-Stunden H100 80GB
- ... für die kleinen LLama3-Modelle
400B kommt noch.

Pretraining
-
Die Grundlage eines jeden Sprachmodells
-
(meist) next-token-Training für Text Generation
-
Unsupervised
-
Früher galten die Chinchilla-Laws
-
optimale Zahl Token für das Trainung zur Parameterzahl
-
Bei LLama3-8b Faktor 75 über Chinchilla
-

Daten fürs
Pretraining
-
Aktuell: meist Common-Crawl-basiert
-
Im Fall von GPT-3.5ff, Gemini, LLama, ...:
-
dazugekaufte Daten von Verlägen etc
-
-
sehr ausführliche Daten-Aufbereitungs und -filtrierstrecken
-
Freie Datasets: RedPajama und Hugging Face fineweb
LLäMmlein 1B / 120M

CAIDAS JMU Würzburg
TinyLLama mit RedPajama Dataset
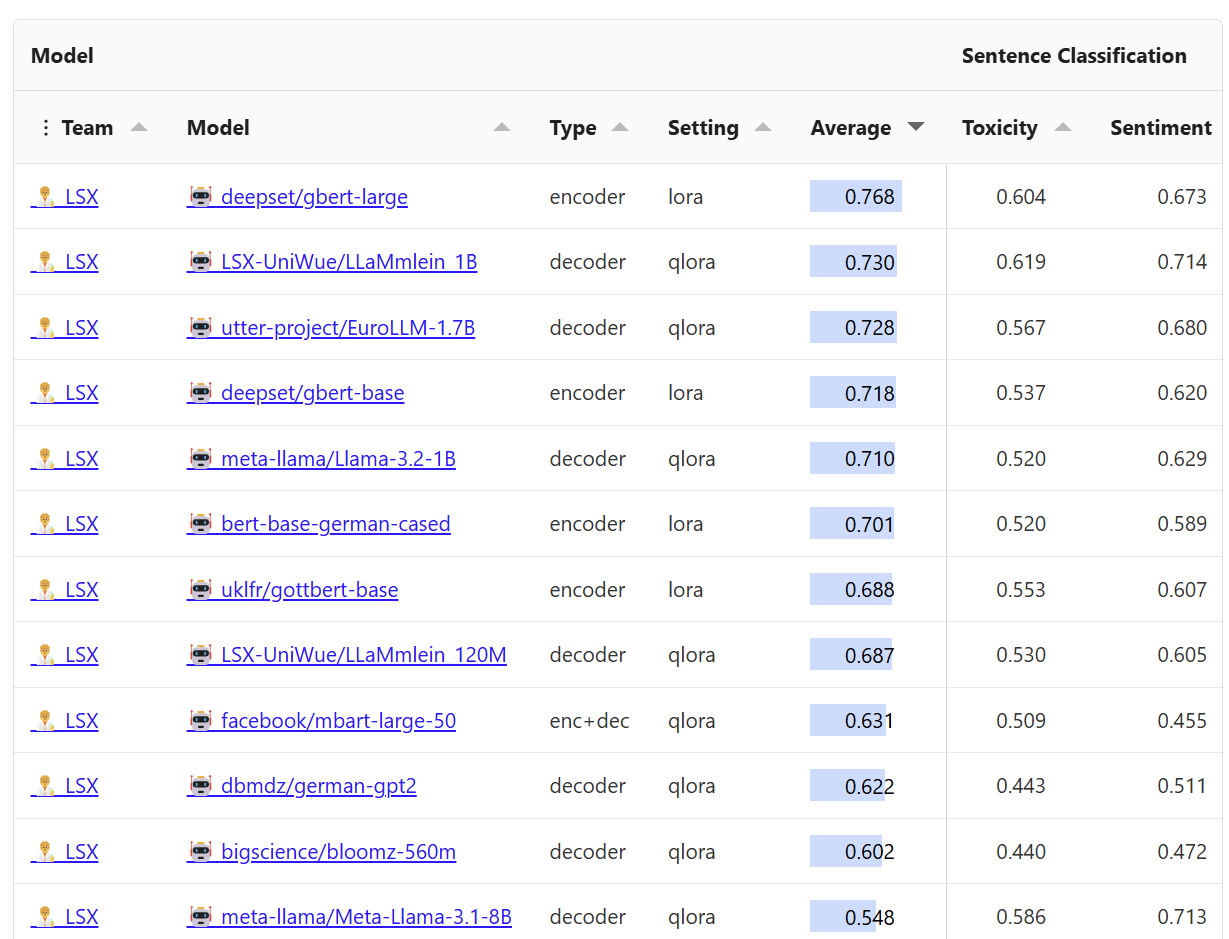
LLäMmlein 1B / 120M
Im eigenen
Benchmark
"SuperGLEBer"
sehr gut
Fokus:
- Classification
- Tagging
- Sentence Similarity
- Question Answering
LLäMmlein 1B / 120M
Trainiert auf "Helma"
NHR@FAU Erlangen, 384 H100/94G
36.096 GB H100 Memory.
Soviel hab ich gerade nicht da.
Vielleicht doch nicht
bei 0 beginnen?
Offene LLMs
Aber auf welchem aufsetzen?
LMSYS Chatbot Arena Leaderboard
https://lmarena.ai/
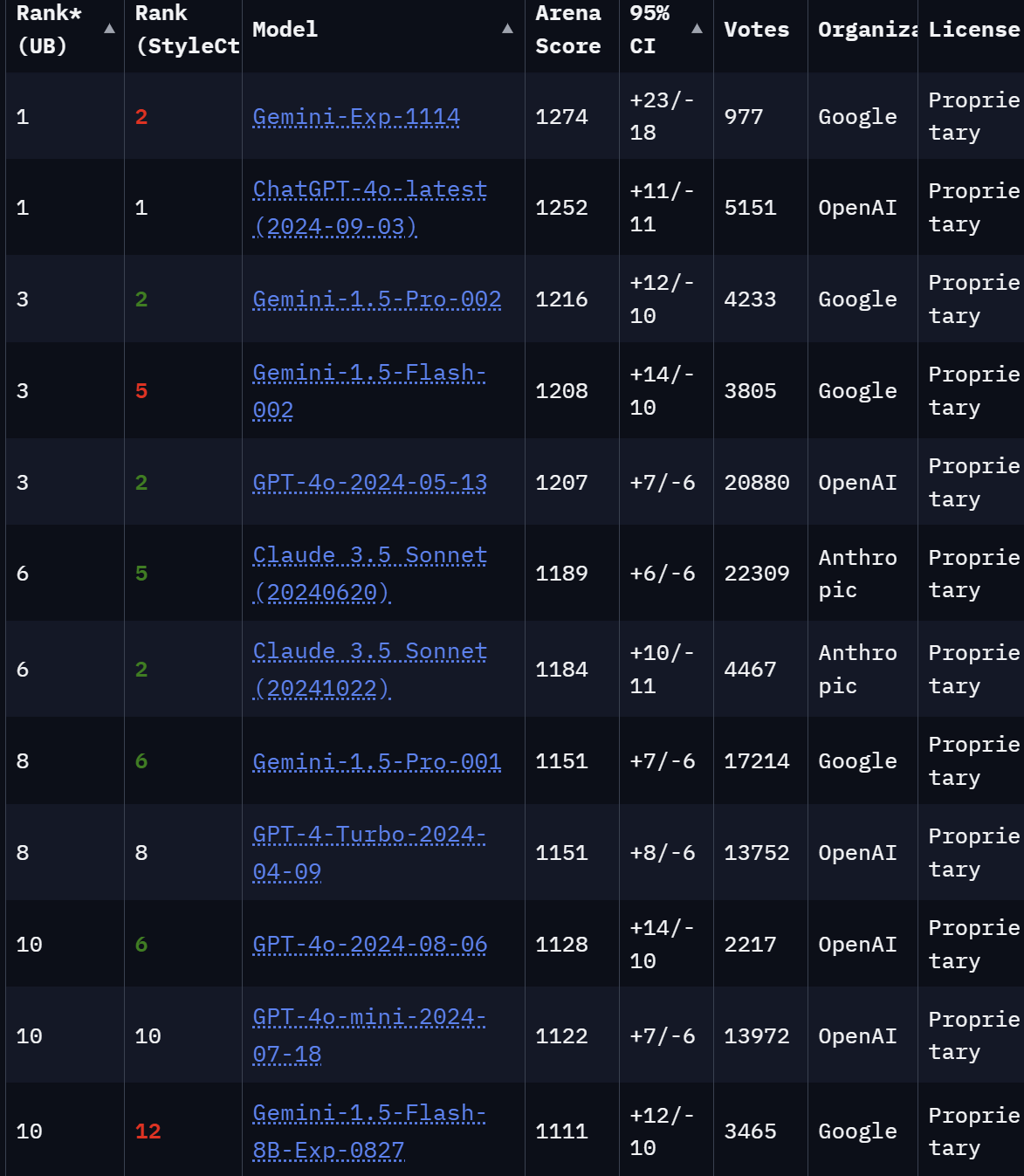
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
| Gemini-Exp-1114 | 1344 | ? |
| Llama-3.1-Nemotron-70B-Instruct | 1269 | 70 |
| Meta-Llama-3.1-405B-Instruct-fp8 | 1187 | 405 |
| Qwen2.5-72B-Instruct | 1259 | 110 |
| Jamba-1.5-Large | 1221 | 94 |
| Gemma-2-27B-it | 1219 | 27 |
| Gemma-2-9B-it-SimPO | 1216 | 9 |
| Llama-3.1-Nemotron-51B-Instruct | 1212 | 51 |
| Deepseek-Coder-v2-0724 | 1214 | 236 |
| Jamba-1.5-Mini | 1176 | 51 |
| Llama-3-8B-Instruct | 1152 | 8 |
| GPT-3.5-Turbo-0314 | 1106 | 178 |
Die offenen Top-Modelle laut Chatbot Arena
Super, dann nehme ich
doch das kleine Gemma
fürs Finetuning
| Instruction | Du bist ein hilfreicher Assistent. |
|---|---|
| Input | Was ist 5+5? |
| Output | Die Addition von 5 und 5 ergibt 10. |
<|im_start|>system Du bist ein hilfreicher Assistent.
<|im_end|> <|im_start|>user Was ist 5+5?
<|im_end|> <|im_start|>assistant Die Addition von 5 und 5 ergibt 10. <|im_end|>
Instruction Tuning/SFT
Speicherbedarf bei Inference
https://llm-system-requirements.streamlit.app/
| Faktor | Beschreibung | Größe |
|---|---|---|
| Parameterzahl | Das eigentliche Model | 9B |
| Model Weights | In bfloat16 | 16,76GB |
| KVCache | Key-Value-Cache für die bisherigen Token für die Berechnung der Attention | 1,31GB |
| Activation Memory | "Zwischenergebnisse" jedes Layers im Forward | 2,18GB |
| Inference | 20,26 |
Speicherbedarf bei Training
https://llm-system-requirements.streamlit.app/
| Faktor | Beschreibung | Größe |
|---|---|---|
| Parameterzahl | Das eigentliche Model | 9B |
| Mode Weights | Bei bfloat16 | 16,76 GB |
| KVCache | Key-Value-Cache für die bisherigen Token für die Berechnung der Attention | 1,31 GB |
| Activation Memory | "Zwischenergebnisse" jedes Layers im Forward | 2,18 GB |
| Inference | 20,26GB | |
| Optimizer Memory | Die Lernzustände im Training | 67,06GB |
| Gradients Memory | Gradienten für die Backward Propagation | 33,53GB |
| Training | 120,84 |
GPU-Poor: Hardwarekosten
| Device | Speicher | Cuda Cores | Kosten/Devices |
|---|---|---|---|
| RTX6000 | 48GB | 18176 | 7.245,- |
| H100 PCIe | 80GB | 14592 | 29.354,- |
| RTX4090 | 24GB | 16384 | 1.769,- |
| Ampere A16 | 64G | 5120 | 3.100,- |

Memory als Kostentreiber
| Model | Batchsize | Mem bf16 | A16 | H100 |
|---|---|---|---|---|
| LLaMa3-70B-Instruct | 1 | 239 | 12.400,- | 88.062,- |
| LLaMa3-70B-Instruct | 5 | 673 | 34.100,- | 264.186,- |
| LLaMa3-70B-Instruct | 50 | 5430 | 263.500,- | 1.996.072,- |
| LLaMa3-8B-Instruct | 50 | 243 | 12.400,- | 117,416,- |
Aber:
- A16 sind deutlich langsamer, für die gleichen token/s braucht mal also deutlich mehr Geräte
- LlaMa3-8B ist deutlich schneller, sprich viel mehr token/s parallel
- NVidia NIM sieht auf einmal gar nicht mehr so teuer aus
Zwei 80GB-Karten, um mit Batch-Size 6 zu trainieren?

Hey, dann quantisieren wir das doch einfach!
Quantization
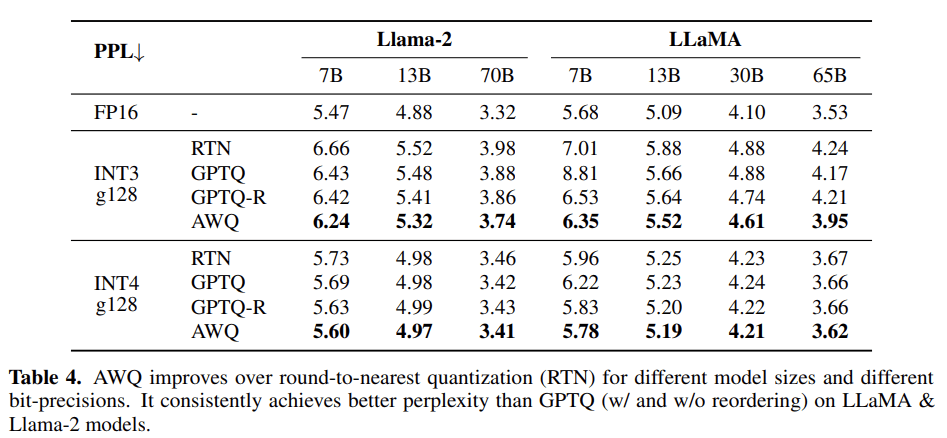
GPTQ, AWQ, GGUF, EXL2 ....

Speicherbedarf mit Quantisierung
https://llm-system-requirements.streamlit.app/
| Faktor | Beschreibung | Größe |
|---|---|---|
| Parameterzahl | Das eigentliche Model | 9B |
| Model weights | int4 | 4,19GB |
| KVCache | Key-Value-Cache für die bisherigen Token für die Berechnung der Attention | 0,3 GB |
| Activation Memory | "Zwischenergebnisse" jedes Layers im Forward | 2,18 GB |
| Inference | 6,70 GB |
Trainieren: Trotzdem groß
https://llm-system-requirements.streamlit.app/
| Faktor | Beschreibung | Größe |
|---|---|---|
| Parameterzahl | Das eigentliche Model | 9B |
| Model weights | int4 | 4,19GB |
| KVCache | Key-Value-Cache für die bisherigen Token für die Berechnung der Attention | 0,3 GB |
| Activation Memory | "Zwischenergebnisse" jedes Layers im Forward | 2,18 GB |
| Inference | 6,70 GB | |
| Optimizer Memory | Die Lernzustände im Training | 67,06 GB |
| Gradients Memory | Gradienten für die Backward Propagation | 33,53 GB |
| Training | 107,28 GB |
Müssen wir wirklich
alle Parameter anfassen?

https://cobusgreyling.medium.com/catastrophic-forgetting-in-llms-bf345760e6e2

https://pub.towardsai.net/parameter-efficient-fine-tuning-peft-inference-and-evaluation-of-llm-model-using-lora-03cf9f027c34
Parameter Efficient Finetuning
- Freeze des Original-Models
- Finetuning nur weniger Parameter
- Faktor 3 weniger Speicher
- Faktor 10.000 weniger trainierte Parameter
- Gemeinsame Inference

Freeze des Basismodels
Trainieren von zusätzlichen, kleineren Parametern


LoRA vs Model
model.embed_tokens.weight
model.layers.0.self_attn.q_proj.weight
model.layers.0.self_attn.k_proj.weight
model.layers.0.self_attn.v_proj.weight
model.layers.0.self_attn.o_proj.weight
model.layers.0.mlp.gate_proj.weight
model.layers.0.mlp.up_proj.weight
model.layers.0.mlp.down_proj.weight
model.layers.0.input_layernorm.weight
model.layers.0.post_attention_layernorm.weight
...
model.layers.31.post_attention_layernorm.weight
model.norm.weight
lm_head.weight
LoRA targets

q_proj, k_proj
"systematically identify and eliminate less important components in the model's layers"
LaserRMT / Spectrum
-
dort ändern, wo redundantes Wissen vorliegt.
-
Iterativ Trainieren ohne Einbußen

Current State
-
Faktor 3 weniger Speicher
-
Faktor 10.000 weniger Parameter
-
Aber: ca 4-6% Verlust der Akkuratheit vs. Full Fine-Tune.
Mistral 7B vorher: 112 GB
Mit LoRA: ca 40 GB
Hmm, wenn ich da schon
Low Rank Adapters habe,
kann ich da nicht quantisieren?
QLoRA "Quantized LoRA"

https://towardsdatascience.com/qlora-fine-tune-a-large-language-model-on-your-gpu-27bed5a03e2b
QLoRA-Outcome
-
9B ist auf 24G trainierbar
-
32B ist auf 48G trainierbar(!)
-
Ergebnis: das gleiche LoRA-Safetensors-File
-
(Fast) kein Effekt auf die Performance

Title Text


Und weiter: Unsloth.AI
1 GPU Apache licensed
warnings.warn(
f"Unsloth: 'CUDA_VISIBLE_DEVICES' is currently {devices} \n"\
"Multiple CUDA devices detected but we require a single device.\n"\
f"We will override CUDA_VISIBLE_DEVICES to first device: {first_id}."
)
Aber :Llama-3 8B auf 16G trainierbar.
GaLore
- Full Parameter Finetuning
- Memoryeffizienz wie LoRA
- eigene Gradient-Projection
DoRA/QDoRA
- Modifizierter LoRA
- plus Magnitude-Vektoren
- ein wenig mehr Speicher
- Wir bekommen die 4-6% wieder

https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
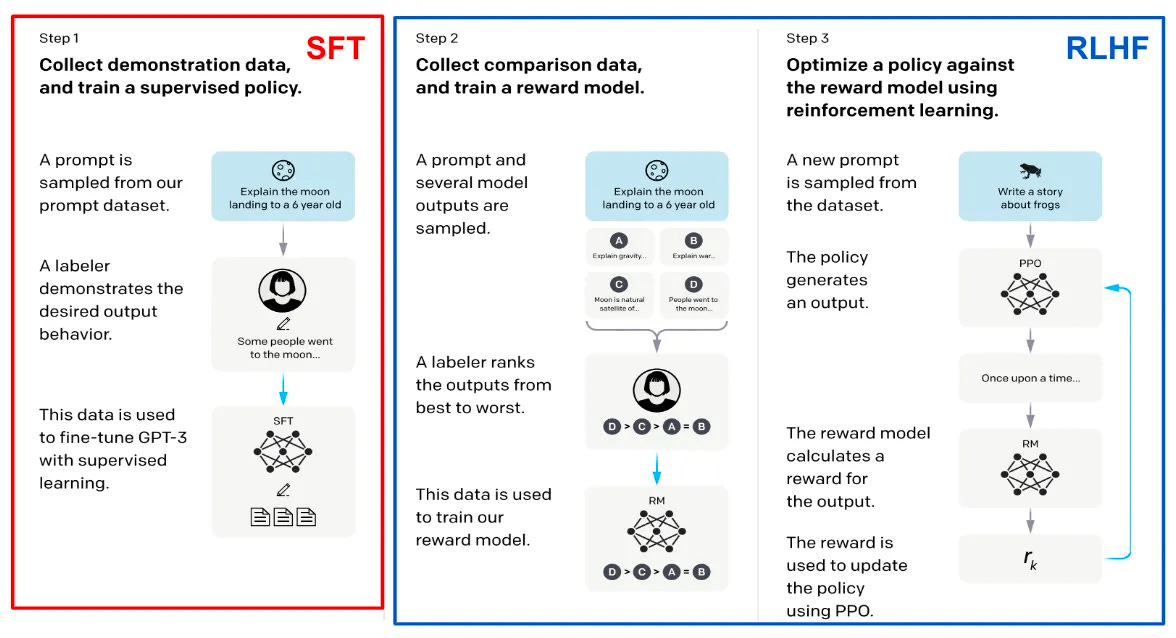
https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
- Basis von GPT-3.5 etc
- Viel Personaleinsatz
-
Komplex durch
Reward-Model
Reward Model

Jemand™ müsste das mal machen.
https://github.com/RLHFlow/Online-RLHF
DPO
| Input | Erzähle, wie Angela Merkel die erste US-Präsidentin wurde. |
|---|---|
| Chosen | Angela Merkel war nie US-Präsidentin, soll ich eine fiktive Geschichte erstellen? |
| Rejected | Mit dem Wahlerfolg von Angela Merkel am 4. April 2018 hätte niemand gerechnet ... |
Direct Preference Optimization
Freeze, Score, Calculate Loss & Update

https://medium.com/@joaolages/direct-preference-optimization-dpo-622fc1f18707
ORPO
- Odds Ratio Preference Optimization
- Statt SFT plus DPO
- In einem Schritt
- Gleiche Daten wie DPO
SimPO
DPO ohne Referenz-Modell
Reward mit Length-Penalty und Margin


Und wo wir schon beim trainieren sind ...
RoPE-Scaling

Context-Length ist kein Differenzkriterium mehr.


Dank
-
peft/lora
-
qlora
-
unsloth
können wir 70B auf 24G.
Aber es dauert noch immer Stunden.


Das klassische 4chan-Problem:
- Bilder von Frauen generieren
- im Anime-Stil
- aber wie Bikini-Modells
Lösung:
- Anime-Modell trainieren
- Realistisches Modell trainieren
- Mittelwerte bilden
Es funktionierte tatsächlich.
Eigenschaften in LLMs mergen
- Startpunkt: ein gemeinsames BaseModel
- Step 1: Task-Vektoren sind die Differenz zu Finetunes ausrechnen
- Step 2: Entfernen unnötiger Task-Vektoren
- Step 3: Conflict-Resolution/ Merging der Task-Vektoren
- Step 4: Addition der Vektoren zum Basismodell.



https://github.com/arcee-ai/mergekit
Viele Methoden
Beispiel Dare Ties
- Step 2: Reduktion der Task-Vektoren per Zufall
random pruning + rescaling - Step 3:
- Trim unveränderter Parameter
- Vorzeichendifferenzen nullen
- Merge der alignten Parameter
- Beispiel: Deutsches Modell und StarCoder mergen.
AutoMerger
- Einfach mal per Zufall mergen.
- Deutsche Experimente:
https://huggingface.co/cstr
- mergekit-evolve
Chat-Templates
Llama2/Mistral: <<SYS>> und [INST]
Llama3: <|start_header_id|> ...
Phi3/Zephyr: <|user|> ...
Gemma: <start_of_turn>...
ChatML: <|im_start|>assistant
Token
Es könnte so einfach sein ...
| Model | eos |
|---|---|
| Leo-Mistral | 2 |
| DiscoLM | 32000 |
| SauerkrautLM | 32000 |
| KafkaLM | 2 |
mergekit-tokensurgeon zur Anpassung


https://huggingface.co/blog/moe
Mixture of
Experts
- Ursprünglich MIT 1991
- Google 2022 für LLMs
- OpenAI GPT-4 als Kernidee
- n Experten mit Router
- m aus n aktiv
- Trainieren pro Experte
- Inference pro m Experten

- Mixture of Experts selbst bauen
- Mixture of LoRAs
- Support für
- Llama(3)
- Mistral
- Phi3
- Bert
- Wahlweise einfaches Routing
oder Training
Zum eigenen Modell
Daten
Sammeln
Dataset
erzeugen
Fine-
Tuning
Modelle
Mergen
DPO-
Alignment
Benchmark
Modelle
identifizieren
Daten Sammeln
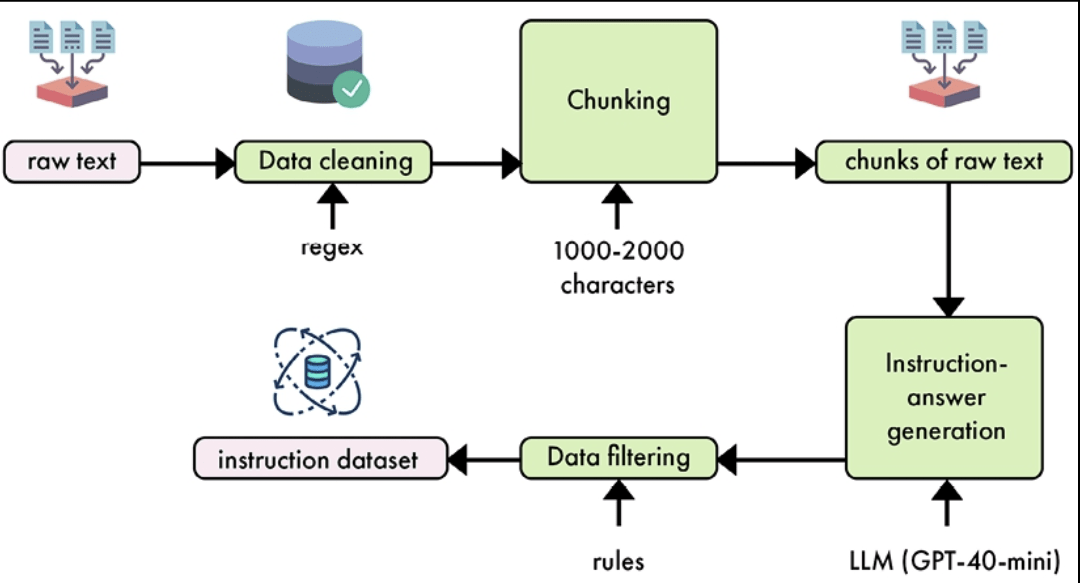
Wie RAG:
- ETL um Raw Text zu bekommen
- Semantisches Chunking
- Bereinigung und Qualitätssicherung

Pipelines, um
- Aus Rohdaten Instruction-Datasets zu machen
- synthetische Datasets zu erstellen
- DPO-Datasets zu erstellen
- Qualität zu sichern/erhöhen

- Von Redhat/ IBM, um OpenSource zu "unterstützen"
- Grundidee:
- man liefert seine Trainingdaten in ein Repository,
- IBM trainiert darauf.
- Methode
- Frage und Antwort-Paare erzeugen
- Diese in Taxonomien einordnen und speichern
- InstructLab baut auf der Basis synthetische Daten
- Überraschend gute kleine Modelle sind das Resultat

Trainieren
- 8,4 TRL von Huggingface
- 6,3 Axolotl vom OpenAI Collective
- 23,1 LLama_Factory von Yaowei Zheng



Hugging Face TRL
Features
- SFT, DPO, PPO, ORPO
- Unsloth-Support
- Eingebettet in HF-Stack

Axolotl
Features
- SFT, Lora, qlora, flashattn
- Config-Getrieben
- Viele Beispiele
- Gute Community

LLaMA-Factory
Features
- Sehr grosse Community ...
- ... in Asien
- adaptiert unglaublich schnell
- Web-Interface & Config
- praktisch alle Algorithmen enthalten, inkl. Unsloth
- Diverse deutsche Datasets enthalten

Benchmarking
- Strategie 1: programmatisch
- mein LLM wählt aus einer Liste von Optionen
- die Distanz zur "richtigen" Antwort wird gemessen
- Strategie 2: "LLM as a Judge"
- Ein Teacher-LLM prüft das Ergebnis
- Sehr schnell und einfach

Benchmarking
https://github.com/occiglot/euro-lm-evaluation-harness
Programmatisch, Version des EleutherAI-Frameworks
Internationale Standard-Evals auf Deutsch
https://github.com/mayflower/FastEval
Einfache Implementierung von mt-bench mit LLM-as-a-judge
https://github.com/ScandEval/ScandEval
Programmatisch, Skandinavische Test-Suite mit Support für Deutsch
https://github.com/EQ-bench/EQ-Bench
Benchmark mit EQ und Kreativität im Fokus, LLM-as-a-judge.
Model
im Betrieb
Fazit - der volle Loop
Feedback
Collection
Dataset
Creation
Model
Training
Unternehmens-
Daten/Skills
vLLM
TGI
On-the-Edge
Argilla
LangSmith
LangFuse
Haystack
LangChain
Distilabel
InstructLab
Axolotl
LLaMa_Factory
Heute loslegen!
github.com/mlabonne/llm-course
LLM AutoEval
LazyMergeKit
LazyAxolotl

Vielen Dank!

Ich freue mich über Gespräche oder Fragen per Linked-In
Slides gibt es bei uns am Stand!