OpenAI vs Offene AI

Wer setzt OpenAI ein?

Wer hat sich am vergangenen Wochenende über Alternativen informiert?



-
Broadly distributed benefits
- long-term-safety
- technical leadership
- cooperative orientation


Prinzipiell ganz geil, aber ...


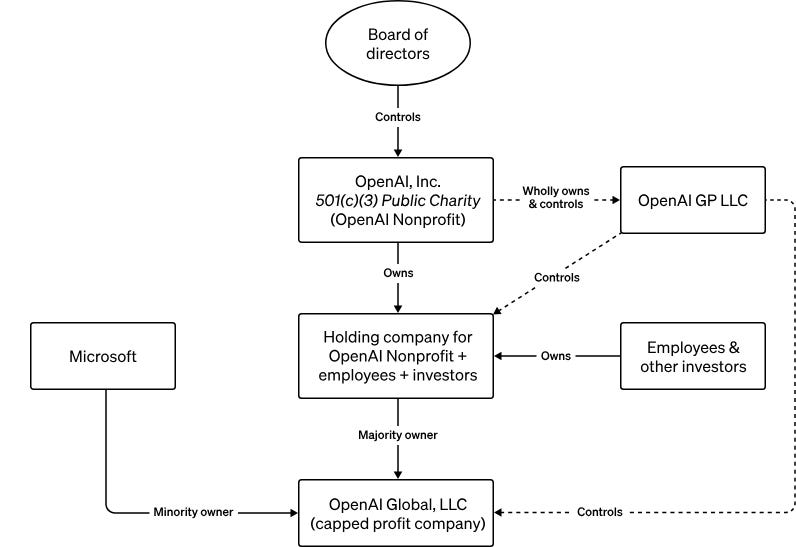


Ein Microsoft-Monopol.
What could possibly go wrong?


Wie haben wir es das letzte Mal repariert?



Open for Research only!
Open for Research only?

Alpaca
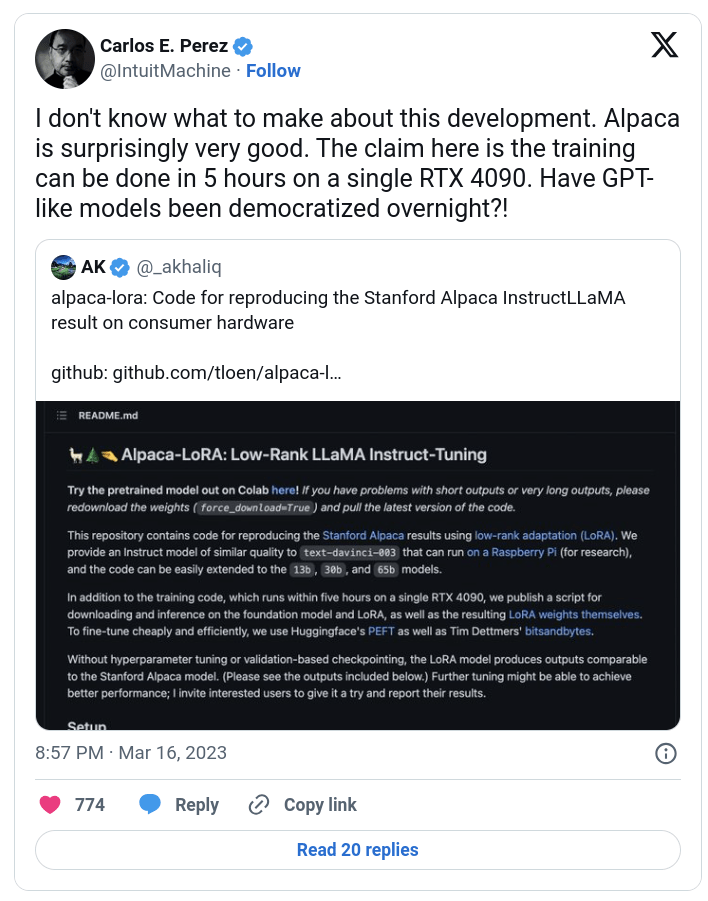
Alpaca
Vicuna


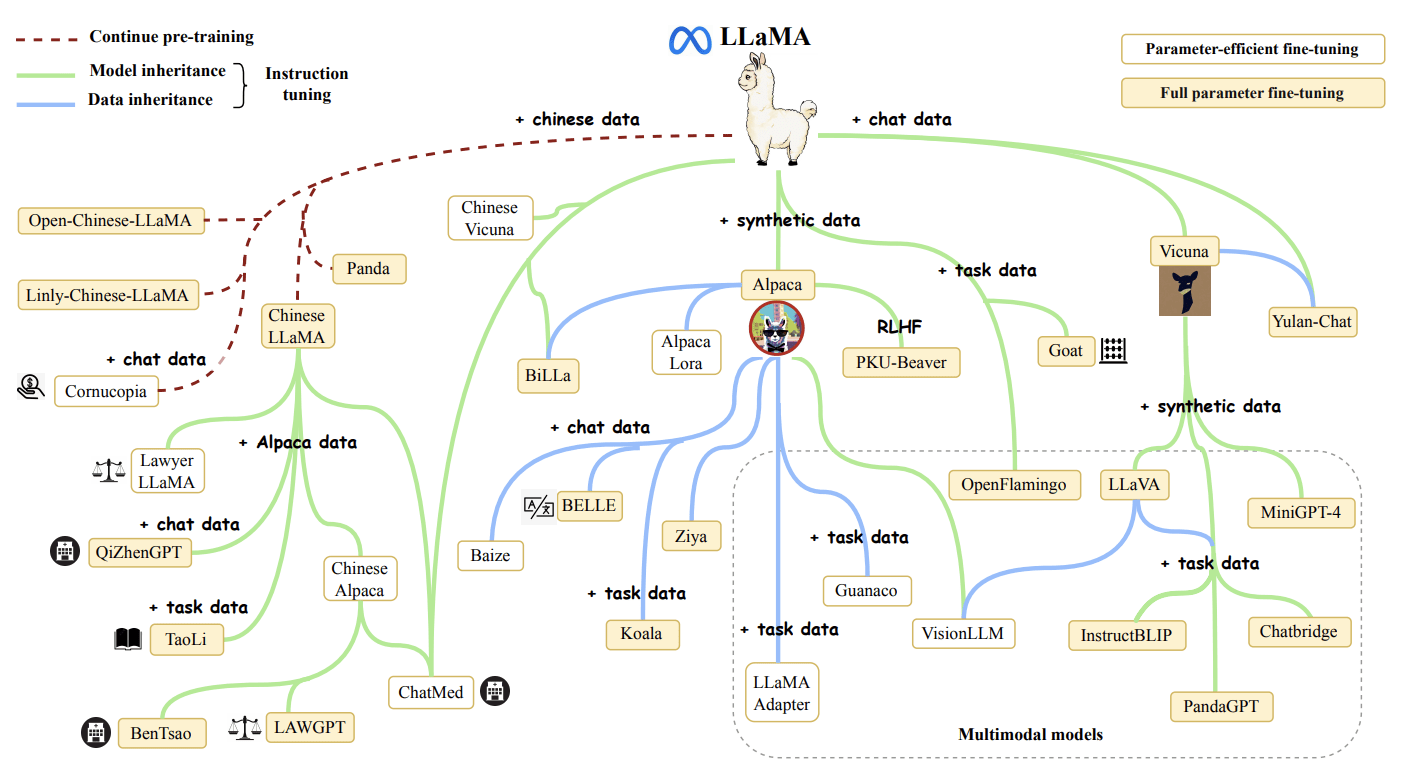
LLamas. Die Kaninchen der LLMs
Ouch:
Memory Usage by default
| Model | GPU-RAM |
|---|---|
| GPT-3 | 350 GB |
| Bloom | 352 GB |
| Llama-2-70b | 140GB |
| Falcon-40B | 80G |
| starcoder | 31GB |
Quantization

LLama-30B:
18G statt 65G GPU RAM

Quantization
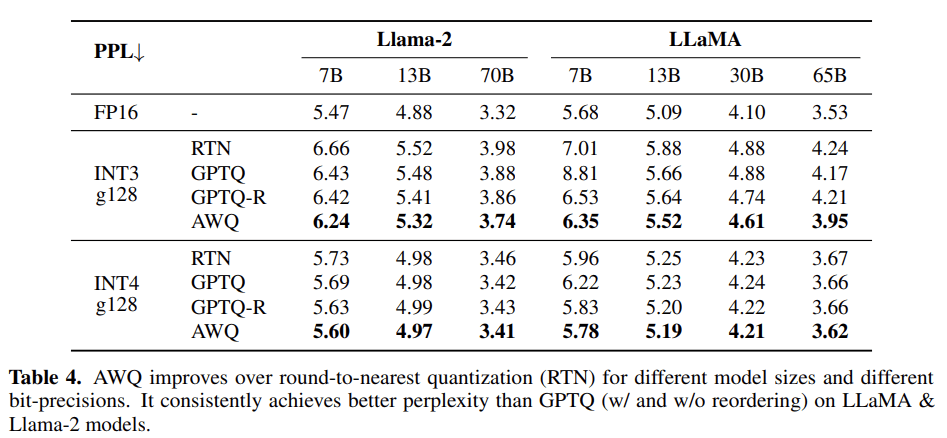
GPTQ, AWQ, GGUF, EXL2 ....


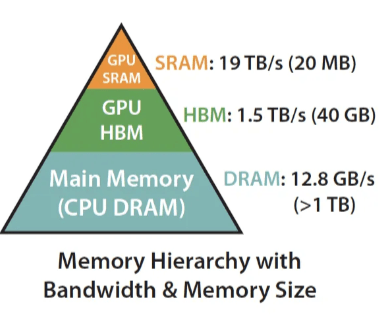
Flash-Attention
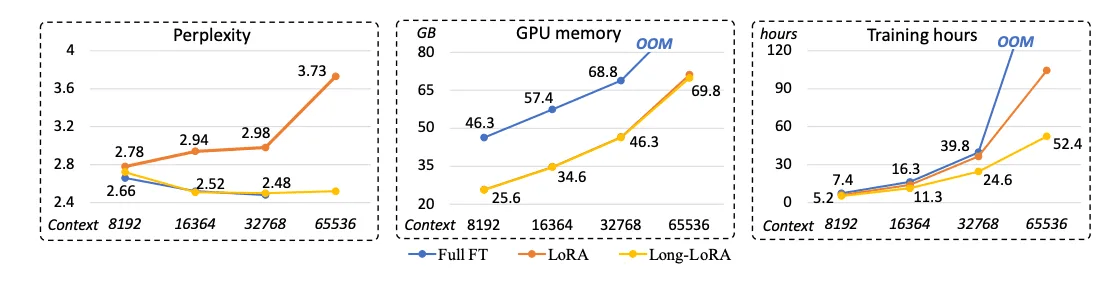
Finetuning for Context Length
OpenSource FTW


Aber, wir können uns das nicht leisten.



Falcon7B & 40B, Apache2
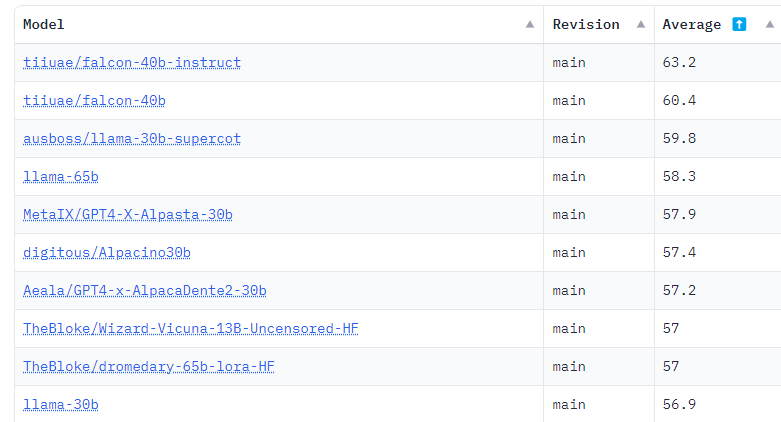
Meta.ai: Wer hat Feigling gesagt?


"Modifizierte Apache2"
mit 8 A100 Hardwarebedarf


oobabooga?
- Linux, OSX, Windows, WSL
- Multi-Backend
- LORA-Support
- MultiModal Models
- Playground-Chat-Frontend
- OpenAI compatible API
- FineTuning

https://github.com/oobabooga/text-generation-webui
Demo Llama 13B
Transformers lokal
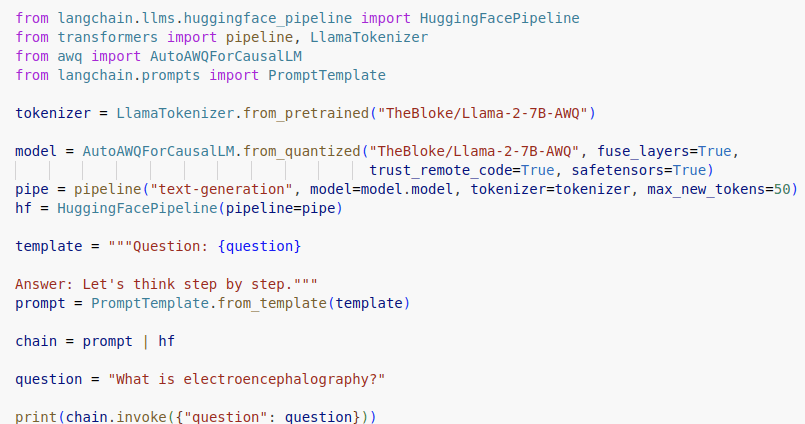
Llama ohne FAANG
2. Additional Commercial Terms. If, on the Llama 2 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.

Falcon ohne Hosting
9.4. Where TII grants permission for You to make Hosting Use of the relevant Work, then for that purpose You shall be considered a Hosting User, and your use of Falcon 180B, the Work or Derivative Works shall be subject to the separate license granted by TII relating to that use.

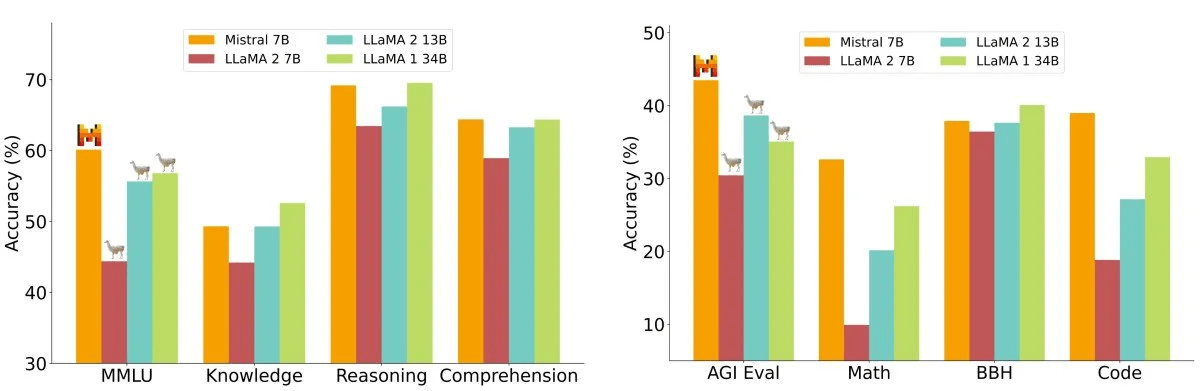
Mistral: klein, aber o-ho
... und Apache2-zertifiziert.
Mistral: klein, aber 128k
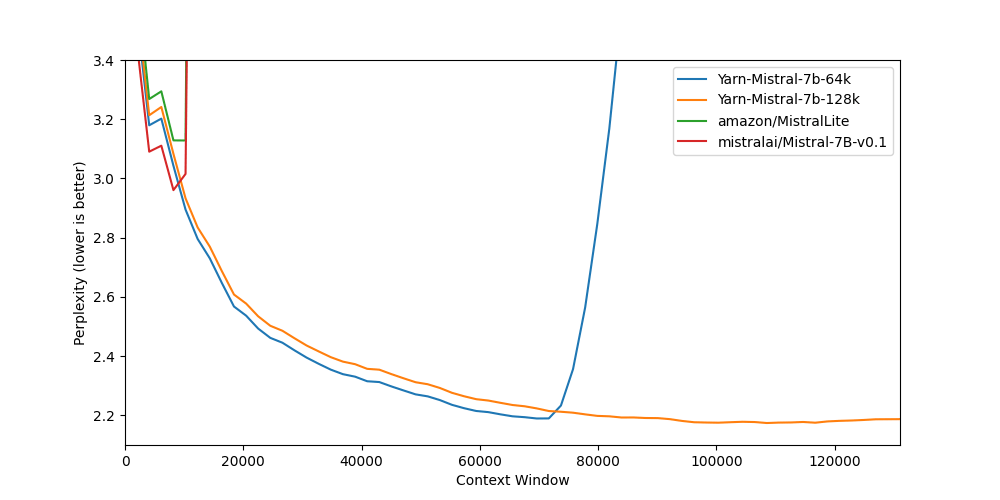
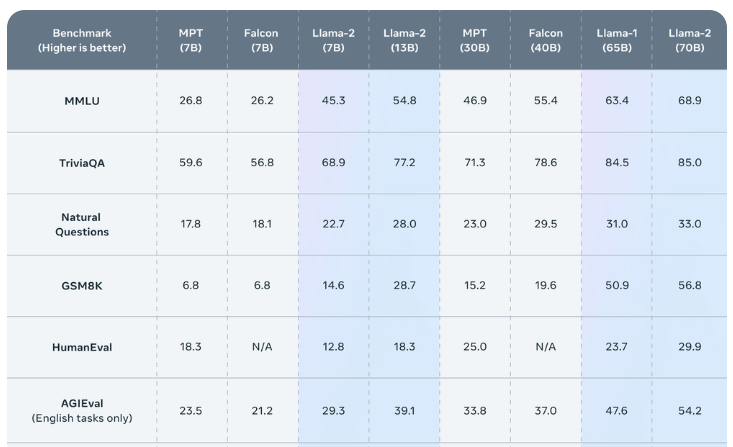
Und was macht der Rest so?
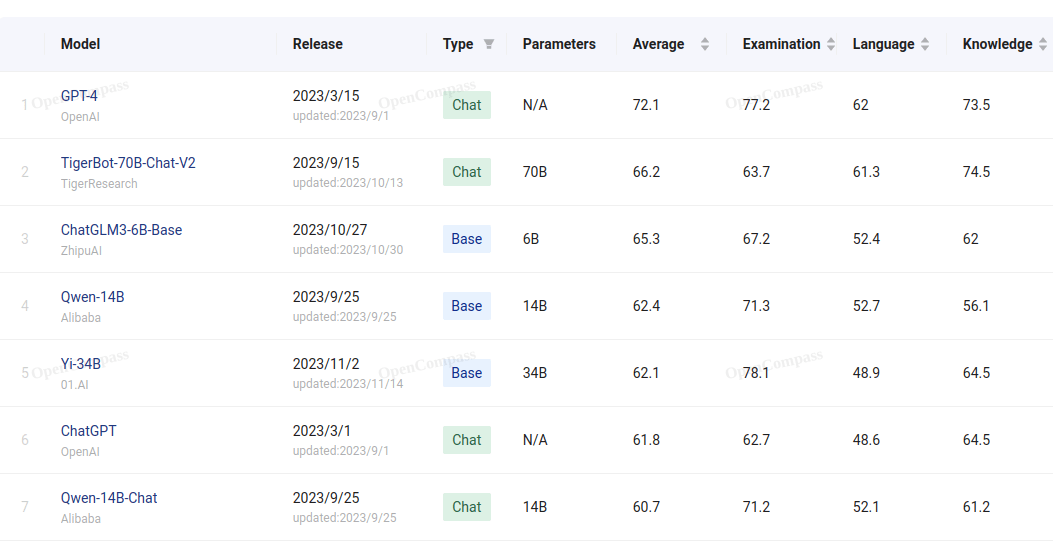

https://opencompass.org.cn/leaderboard-llm
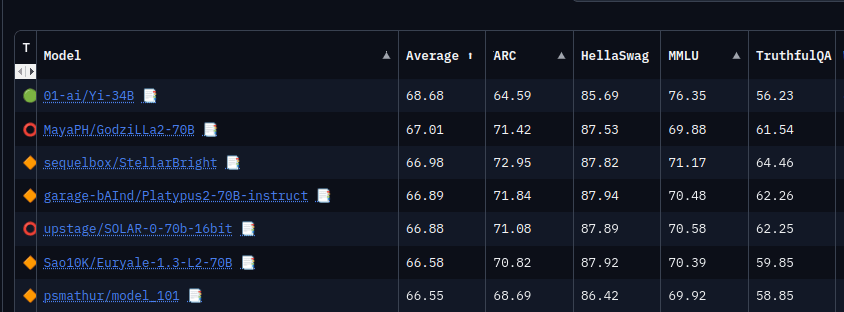
Leader of the free World
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any military, or illegal purposes.
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
If you are commercially using the Materials, and your product or service has more than 100 million monthly active users, You shall request a license from Us. You cannot exercise your rights under this Agreement without our express authorization.
If you plan to use the Yi Series Models and Derivatives for Commercial Purposes, you should contact the Licensor in advance as specified in Section 7 of this Agreement named "Updates to the Agreement and Contact Information" and obtain written authorization from the Licensor.

UPDATE COMING
Lokal selbst betreiben
| Backend | Beschreibung | Support |
|---|---|---|
| Transformers | Huggingface FOSS-Library | GPU via pytorch,jax,Tensorflow |
| llama.cpp | C++-implementierung von Transformern, eigene Quantifizierung | GPU Nvidia, Metal, ROCm |
| ctransformers | C++ | Nvidia, |
| exllama(v2) | Python, C++ und Cuda, rattenschnell | Nvidia, ROCm theoreitsch |
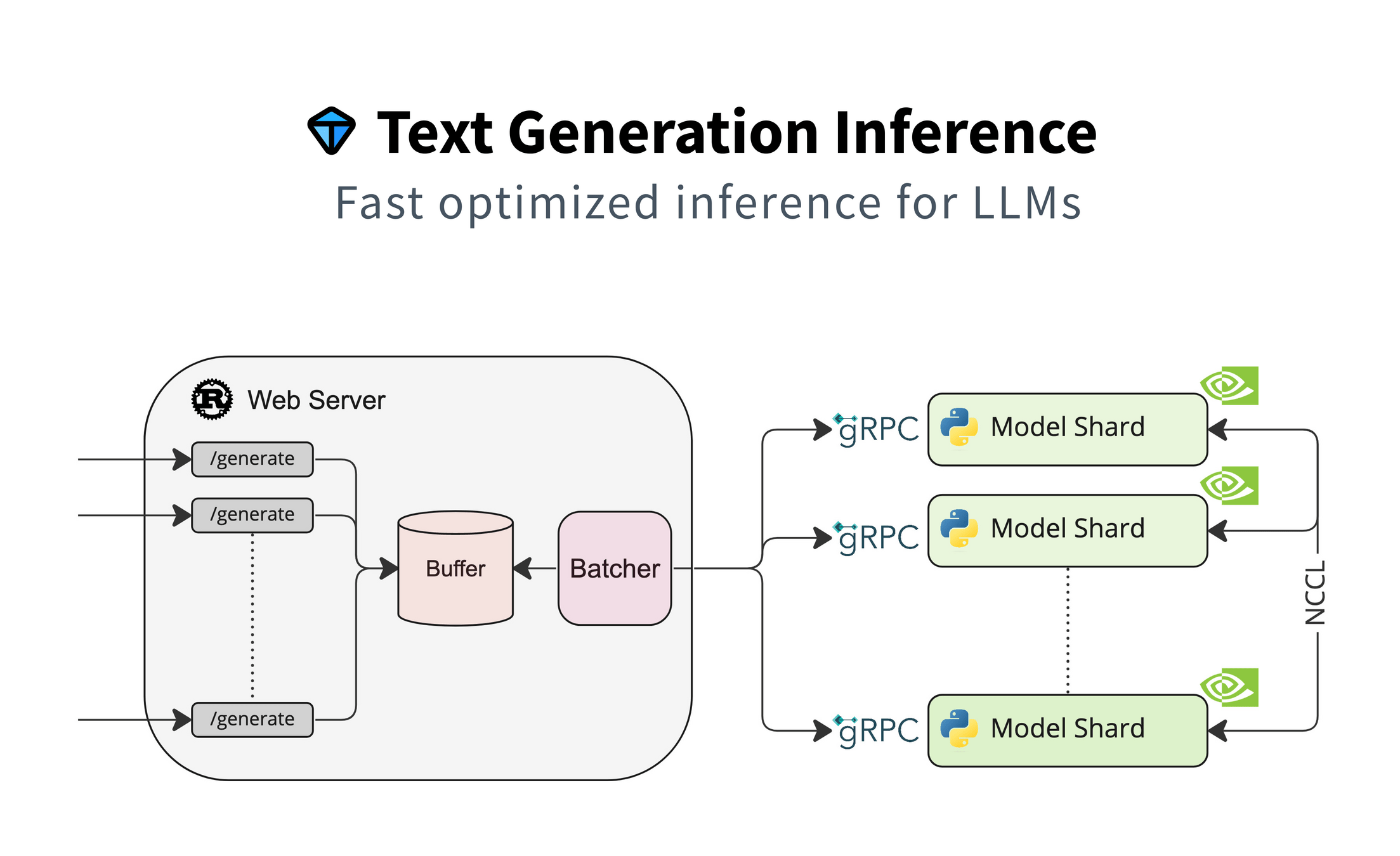
FOSS LLMOps: TGI

FOSS LLMOps: LoRAX


FOSS LLMOps: vLLM
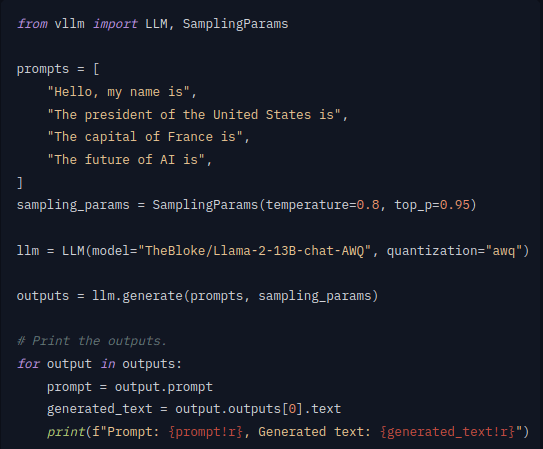
FOSS LLMOps: vLLM lokal


OpenSource
Embeddings
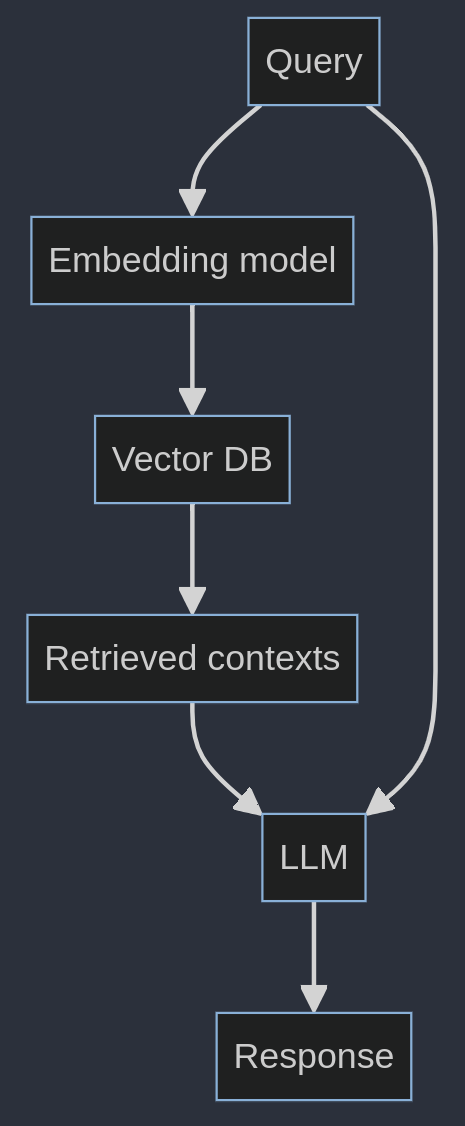
- Sehr lange Sequence-Length bei OpenAI mit 8191 Token
- Für Retrieval / RAG aber nicht gut geeignet
- Besser: multilingual-e5-large für internationale Dokumente
Ausblick
Die Modelle werden kleiner und
fähiger.

Ausblick
Multimodal wird zum Normalfall.
Beispiel: Qwen-VL

Ausblick
Multimodal wird zum Normalfall.
Und deutlich besser als GPT4-V

https://github.com/THUDM/CogVLM Apache Licence
Ausblick
Spezialsierungen wird üblich:
- Gorilla für APIs
- Code Generation
- Reranking
- Summarization
- Retrieval
Damit wird auch Finetuning normal.
https://github.com/THUDM/CogVLM Apache Licence
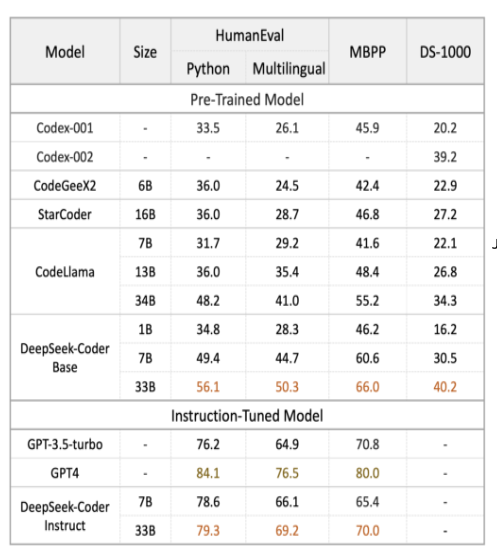
Lokale LLMs werden Commodity,
aber:
- Leistung selbst mit 70B oder 180B eher GPT-3.5 als GPT-4
- RAG, Summarization, Extraction, Code Generation: check.
- Verlässlichkeit ist hoch, Helpfulness auch
- Ökonomisch billiger wird es erst ab X.XXX.XXX Requests/Tag
- Viele Tools entstehen noch, es gibt viel Bleeding Edge.
- Komplexe AI-Lösungen/Agenten sind schwierig auf lokalen LLMs.
Wer Spaß an Unterhaltung hat - ihr findet mich auf dem Stand :-)
https://slides.com/johann-peterhartmann/offeneai/
