Multi-CPU and Multi-GPU Parallelism with Dagger.jl
Julian Samaroo (MIT JuliaLab)
What Developers Want
Multi-Threaded Parallelism
Multi-GPU Parallelism
Easy, Intuitive Parallel APIs



- Shared memory - no copies required
- Almost every system has multiple CPUs
- Built-in to Julia, multiple nice APIs
Benefits
Challenges
- Shared memory - must serialize data access
- Limited by number of CPUs
- Existing APIs are hard to compose (bad performance)
Multi-Threaded Parallelism
- Inherently parallel
- High-throughput memory subsystem
- Strong Julia GPU ecosystem
- Many APIs "just work"
Benefits
Challenges
- Streams/contexts are difficult to manage
- Often requires copies to/from CPU RAM
- Slightly different APIs per device vendor
- Not all APIs "just work"
GPU Parallelism
- Well optimized for many problems
- Various APIs to suit various problem formulations
- Generic APIs support GPU parallelism
Benefits
Challenges
- Requires deep understanding to implement new algorithms
- Different APIs don't compose
- Generic APIs often miss multi-CPU and multi-GPU support
Existing APIs
But can we have all three?
- Multi-threaded parallelism
- Multi-GPU parallelism
- Cross-vendor GPU support
- Multi APIs, all built on simple heterogeneous task parallel core
Enter stage left: Dagger.jl


Philosophy
Don't reinvent the wheel - build simple, consistent APIs on a solid heterogeneous foundation, complete with a task runtime and scheduler, and...
Model Everything
What to model:
- Where is a task running?
- Where does data live?
- How many devices do I have?
- What's the speed of data transfer?
- How long do my tasks take to run?
- How much memory do I have?
- ...and much more
Model Everything?
What this gets us
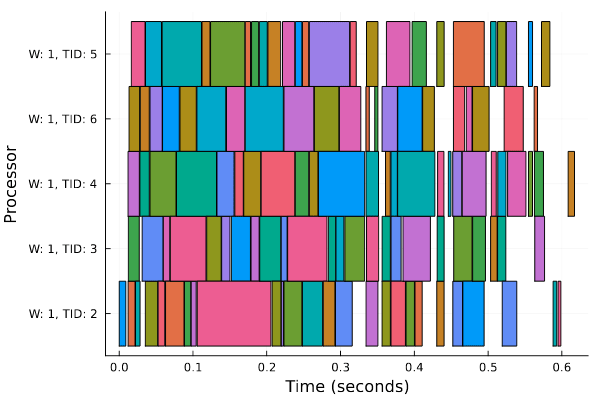
Lots of parallelism
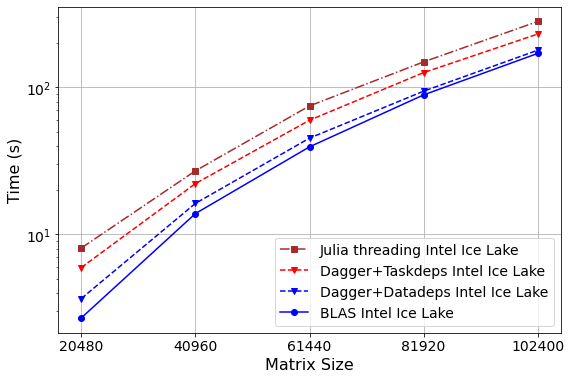
Performance Scalability
Show me the code!
# Cholesky
Dagger.spawn_datadeps() do
for k in range(1, mt)
Dagger.@spawn LAPACK.potrf!('L', ReadWrite(M[k, k]))
for m in range(k+1, mt)
Dagger.@spawn BLAS.trsm!('R', 'L', 'T', 'N', 1.0,
Read(M[k, k]), ReadWrite(M[m, k]))
end
for n in range(k+1, nt)
Dagger.@spawn BLAS.syrk!('L', 'N', -1.0,
Read(M[n, k]), 1.0,
ReadWrite(M[n, n]))
for m in range(n+1, mt)
Dagger.@spawn BLAS.gemm!('N', 'T', -1.0,
Read(M[m, k]), Read(M[n, k]),
1.0, ReadWrite(M[m, n]))
end
end
end
endShow me the code! (Explained)
# Start a "Datadeps region"
Dagger.spawn_datadeps() do
...
endShow me the code! (Explained)
Dagger.spawn_datadeps() do
# Launch some tasks
for k in range(1, mt)
Dagger.@spawn LAPACK.potrf!(...)
end
endShow me the code! (Explained)
# Specify our "data dependencies"
LAPACK.potrf!('L', ReadWrite(M[k, k]))
BLAS.gemm!('N', 'T', -1.0,
Read(M[m, k]), Read(M[n, k]),
1.0, ReadWrite(M[m, n]))Show me the code! (Explained)
# Use a single CUDA GPU
using DaggerGPU, CUDA
scope = Dagger.scope(cuda_gpu=1)
Dagger.with_options(;scope) do
Dagger.spawn_datadeps() do
...
end
endShow me the code! (Explained)
# Use two AMD GPUs
using DaggerGPU, AMDGPU
scope = Dagger.scope(rocm_gpus=[1,2])
Dagger.with_options(;scope) do
Dagger.spawn_datadeps() do
...
end
endShow me the code! (Explained)
# Call a GPU-parallel Cholesky
using Dagger, DaggerGPU, Metal
A = [...]
DA = view(A, AutoBlocks())::DArray
scope = Dagger.scope(;metal_gpu=1)
C = Dagger.with_options(;scope) do
# cholesky(::DArray) uses Datadeps internally
cholesky(DA)
endWhat Dagger generates

Upstream:
- Cholesky factorization
- Matrix-Matrix multiply
To be merged:
- LU decomposition
- QR factorization
- Triangular solve
- FFT/IFFT/etc.
More to come!