Simulation-Efficient Implicit Inference with Differentiable Simulators
Justine Zeghal, François Lanusse, Alexandre Boucaud, Denise Lanzieri
Cosmic Connections: A ML X Astrophysics Symposium at Simons Foundation
May 22 - 24, New York City, United States






Cosmological context
Cosmological context
Cosmological context
Cosmological context
Cosmological context
Cosmological context
Cosmological context
Cosmological context
Cosmological context
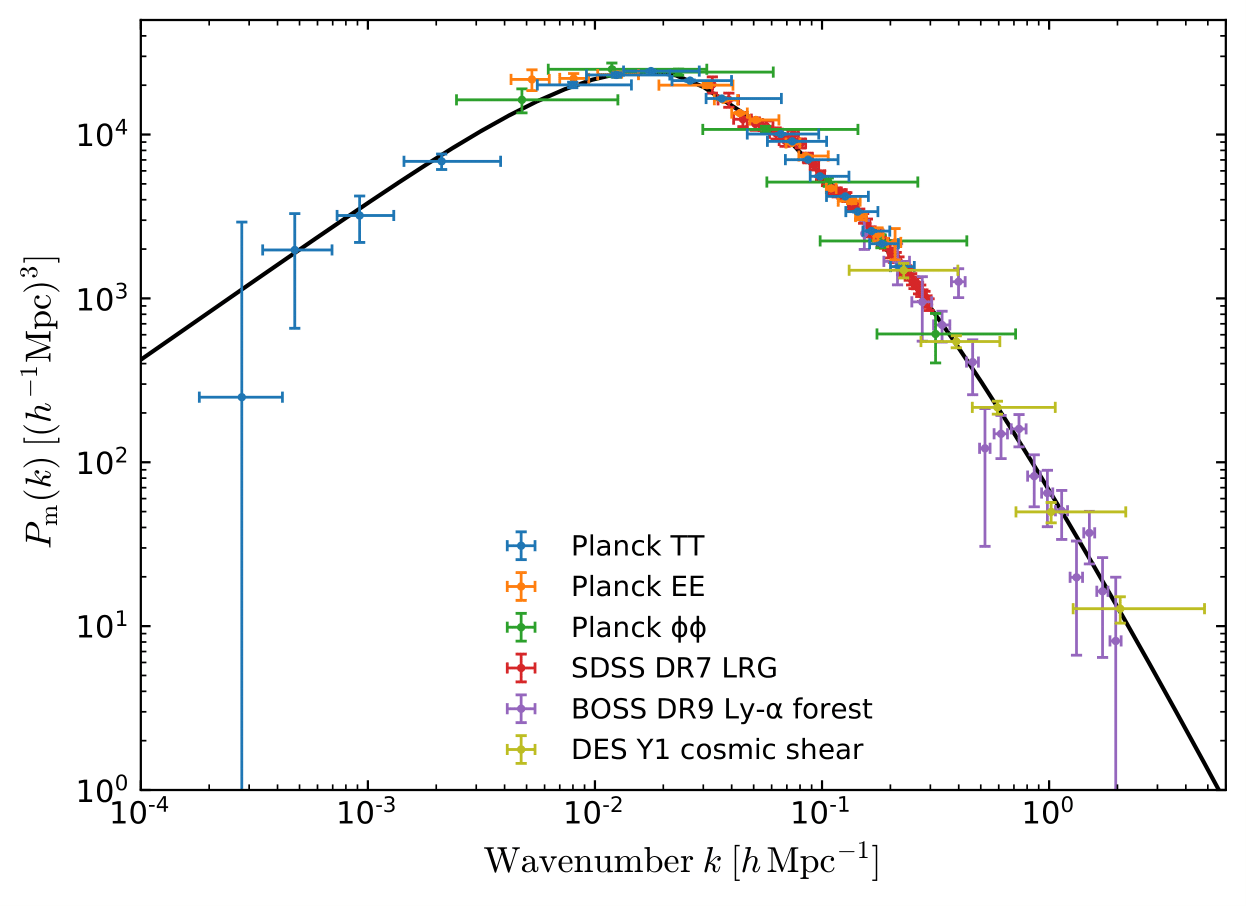
ESA and the Planck Collaboration, 2018
Cosmological context
Cosmological context
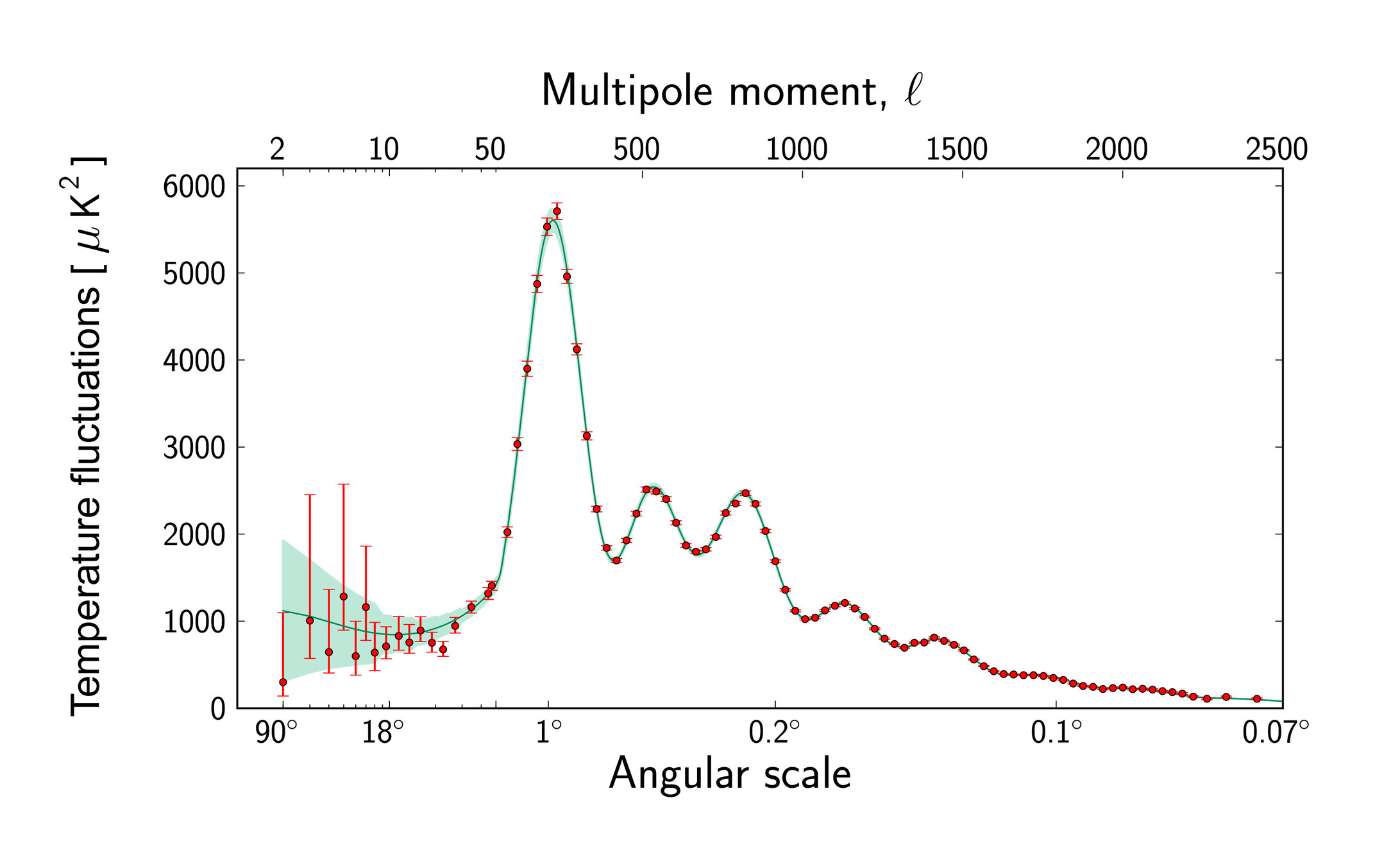
How to extract all the information embedded in our data?
Full-Field Inference
working at the pixel level
Downsides:
-
Computationally expensive (HMC)
Our Goal: doing Neural Posterior Estimation (Implicit Inference) with a minimum number of simulations.
-
Require a large number of simulations

-
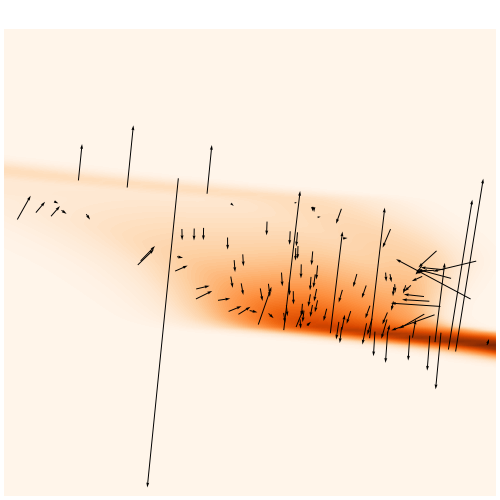
We developed a differentiable (JAX) log-normal mass maps simulator
Differentiable Mass Maps Simulator
-
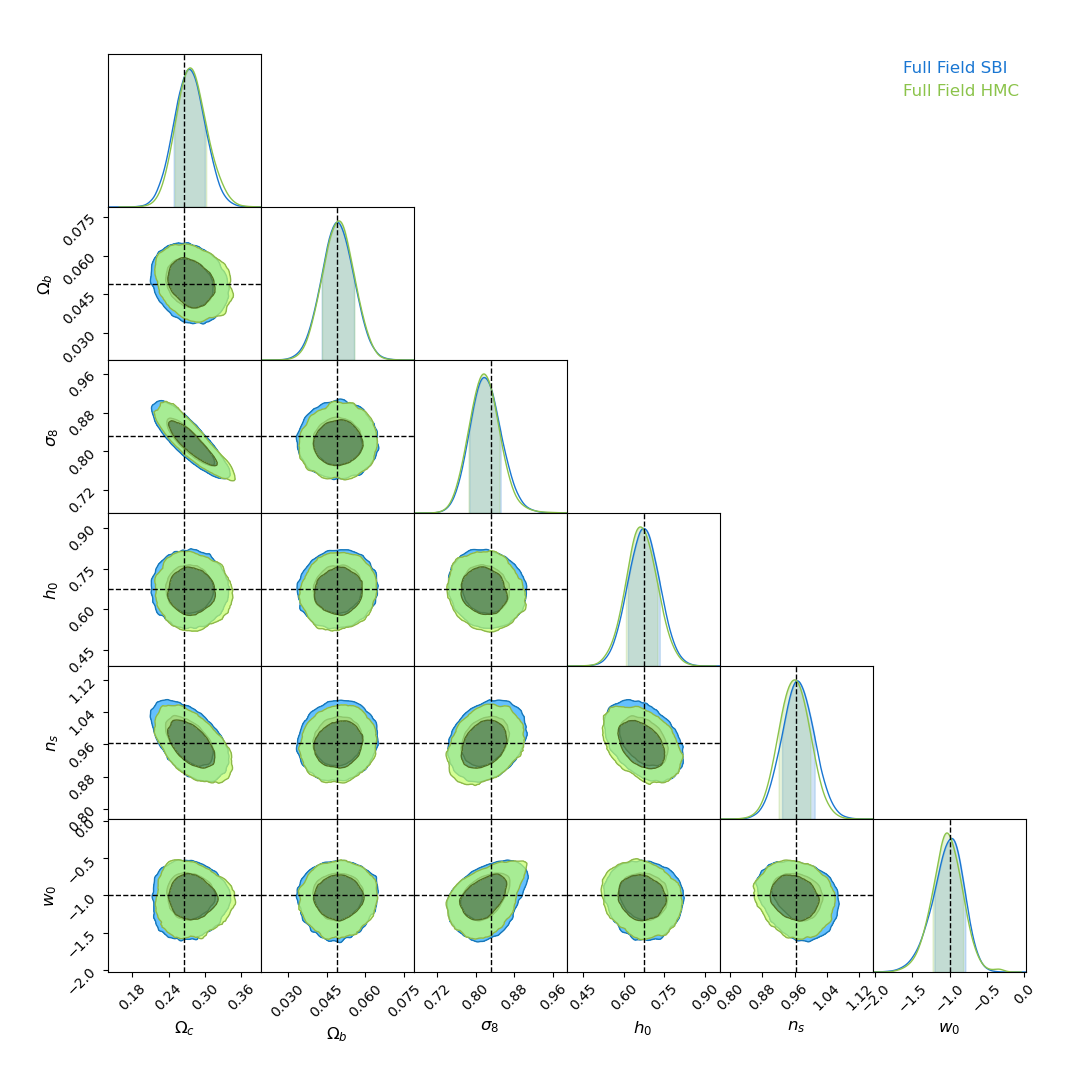
There is indeed more information to extract!
-
With infinite number of simulations, our Implicit Inference contours are as good as the Full-Field contours obtained through HMC
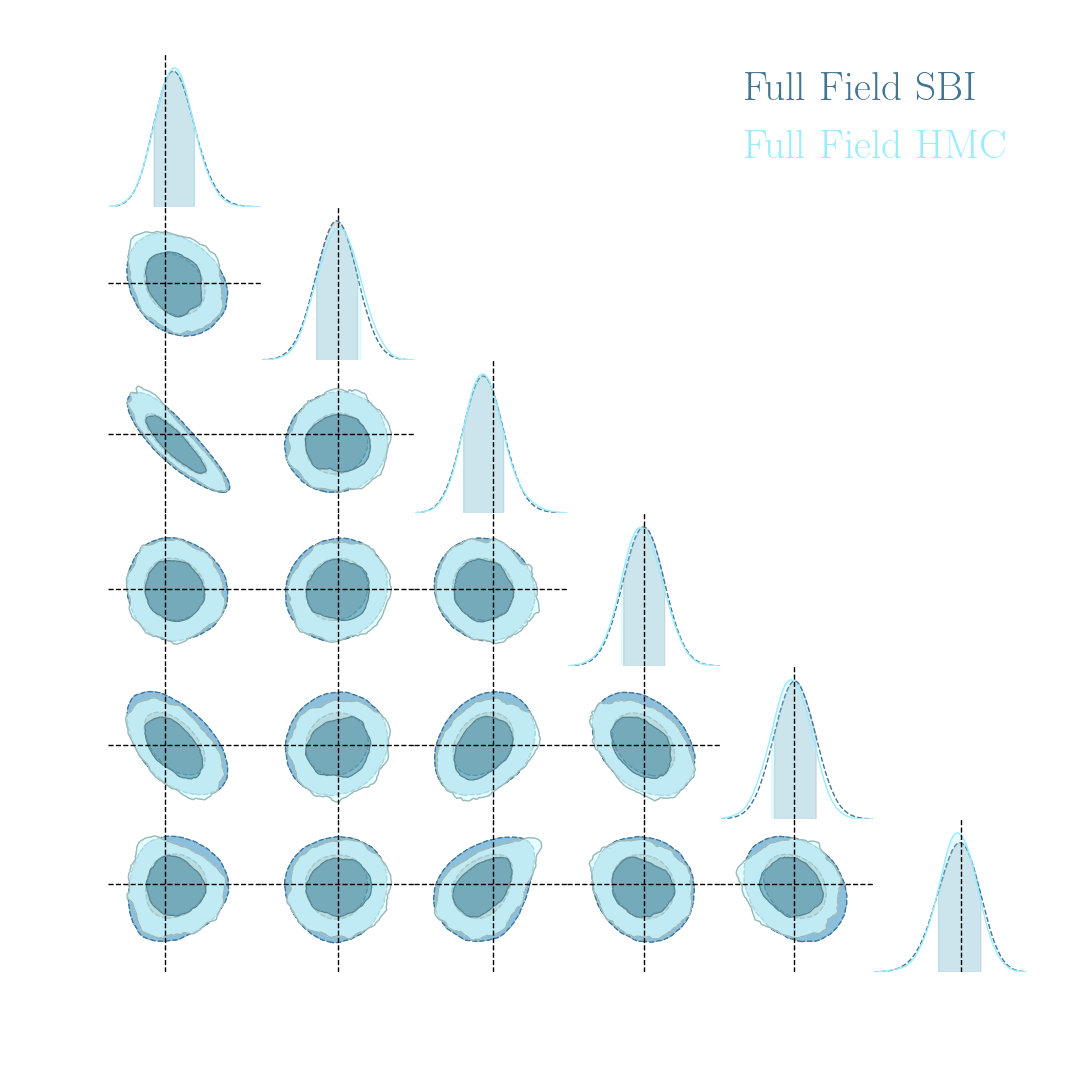
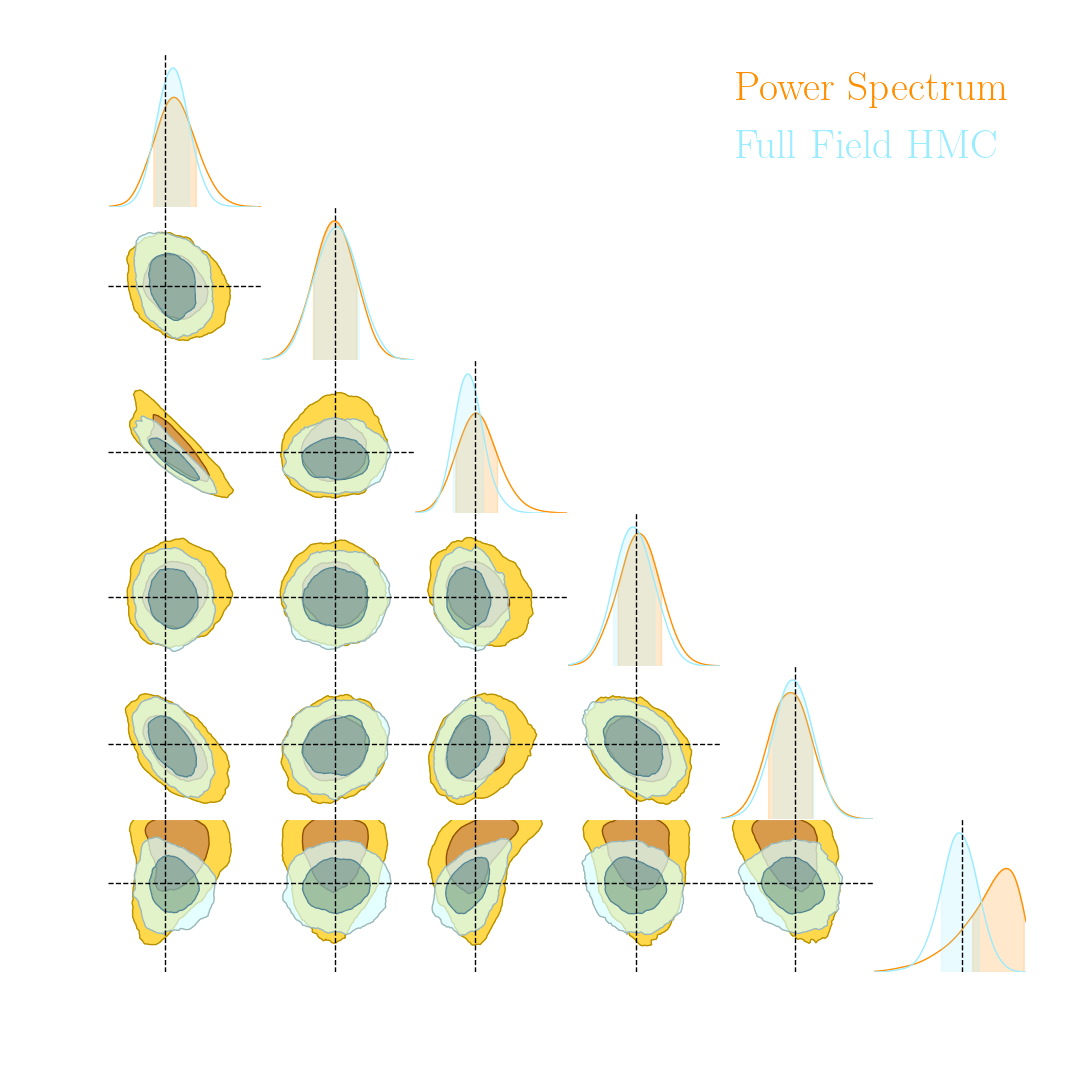

How can we reduce this number of simulations?

Gradient constraining power


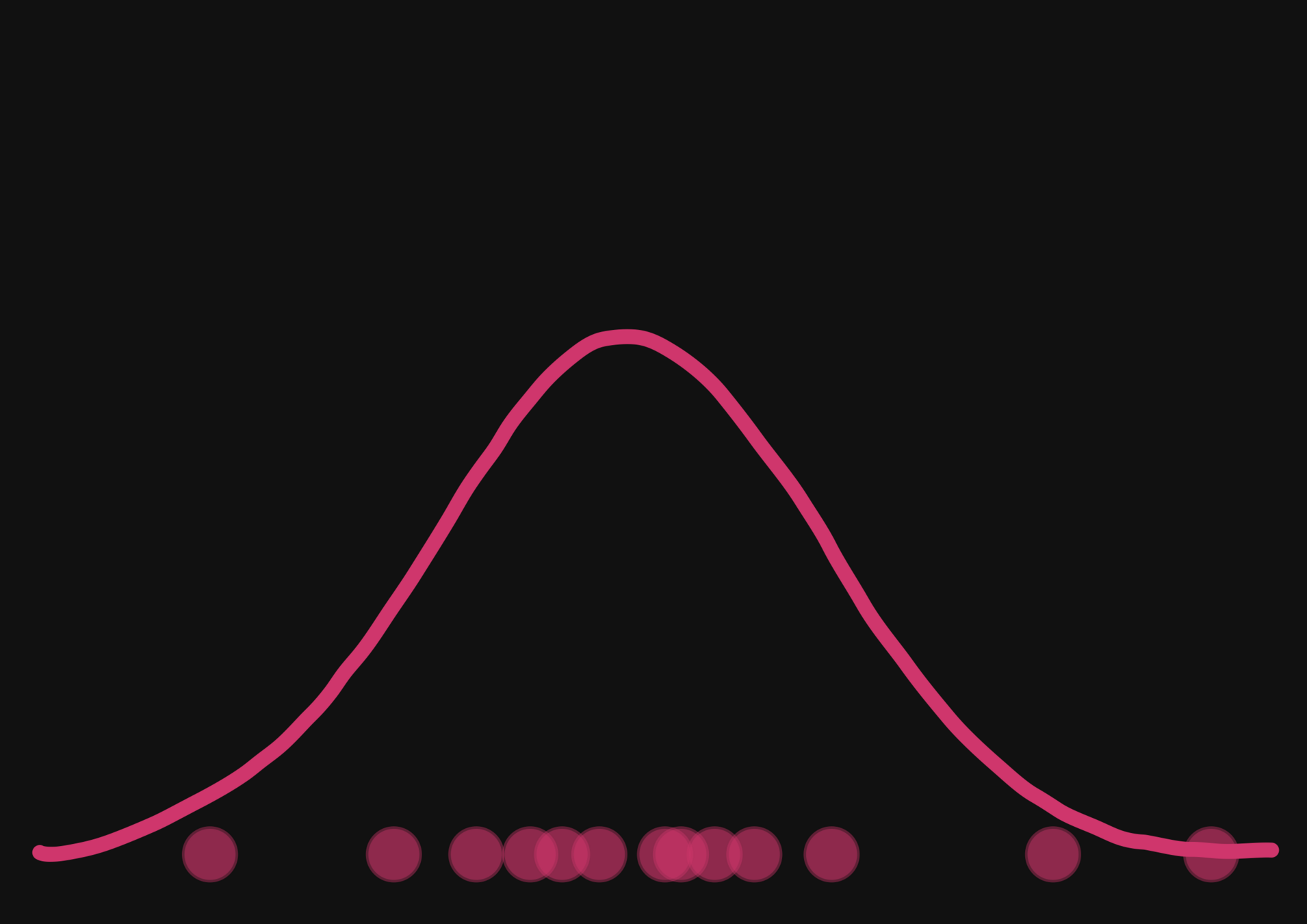
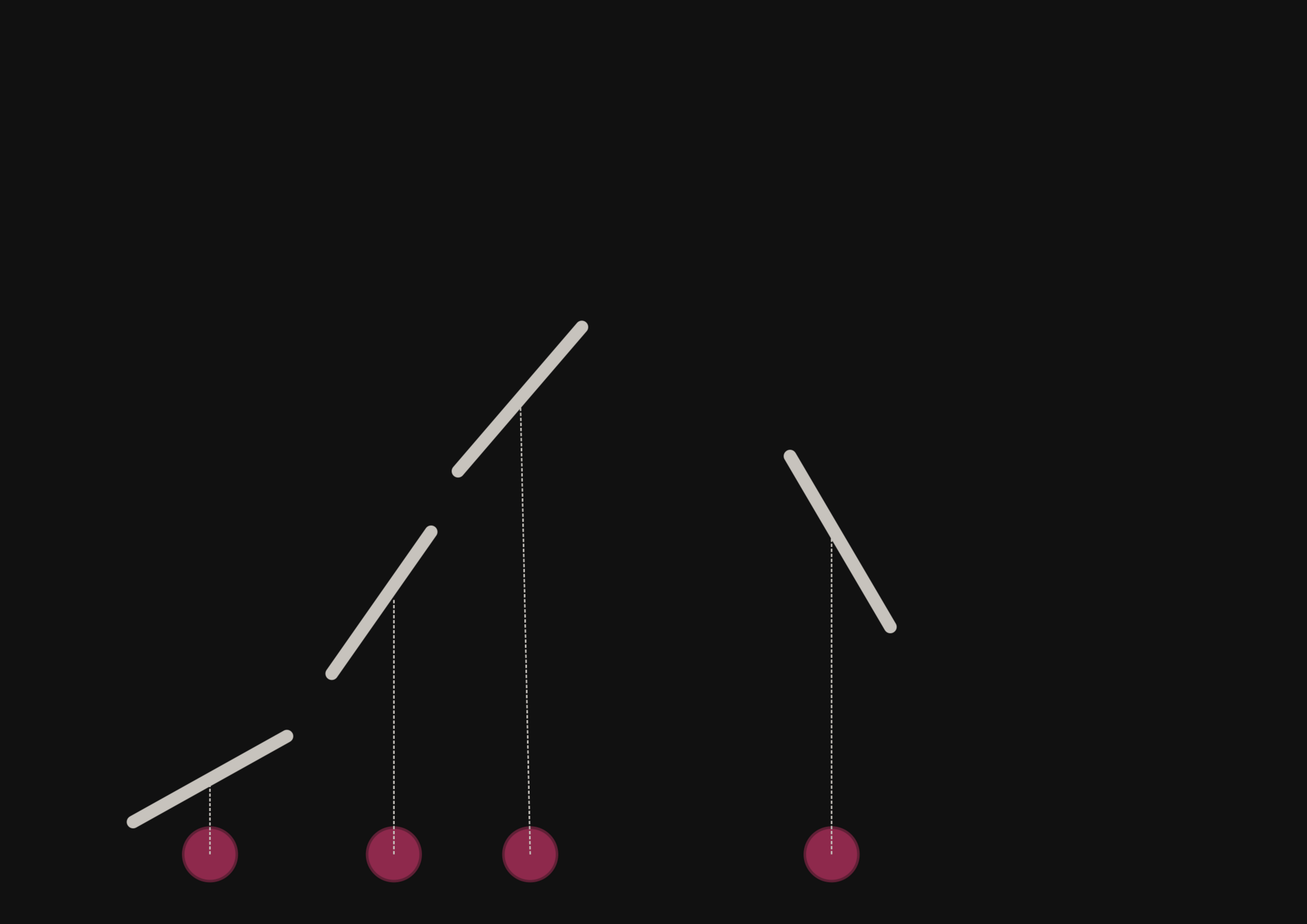
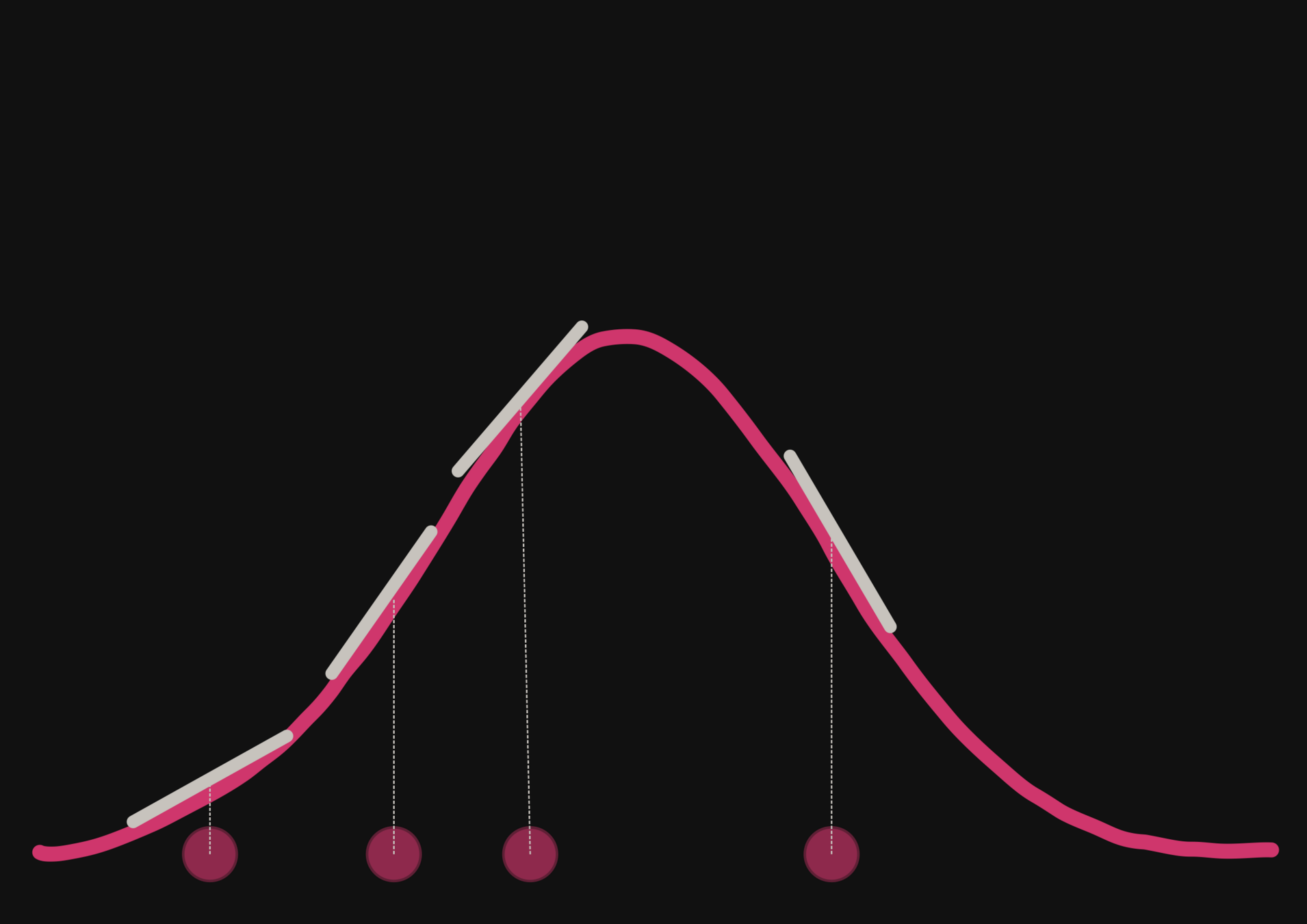
With a few simulations it's hard to approximate the posterior distribution.
→ we need more simulations
BUT if we have a few simulations
and the gradients
(also know as the score)
Following this idea from Brehmer et al. 2019 we add the gradients of joint log probability of the simulator with respect to input parameters in the process
then it's possible to have an idea of the shape of the distribution.
Normalizing Flows (NFs) as Neural Density Estimators
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
Problem: the gradient of current NFs lack expressivity
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
Problem: the gradient of current NFs lack expressivity
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
Problem: the gradient of current NFs lack expressivity

But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
Problem: the gradient of current NFs lack expressivity
But to train the NF, we want to use both simulations and gradients
Nfs are usually trained by minimizing the negative log likelihood loss:
Normalizing Flows (NFs) as Neural Density Estimators
Problem: the gradient of current NFs lack expressivity

Results from our previous paper
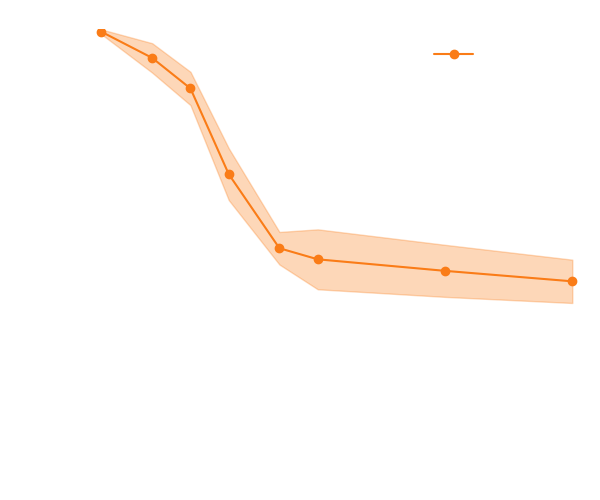
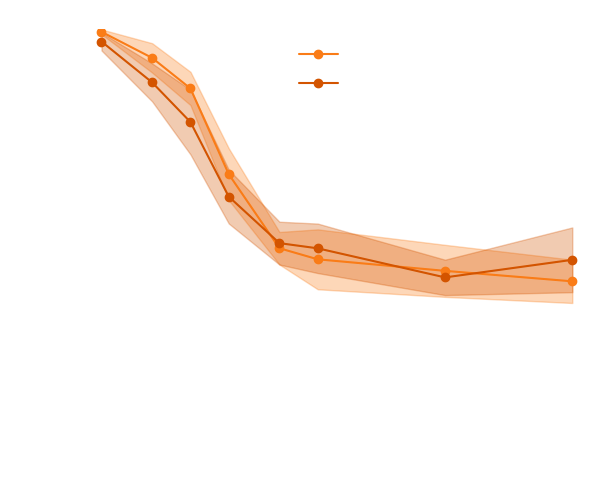
Wide proposal distribution
Narrow proposal distribution

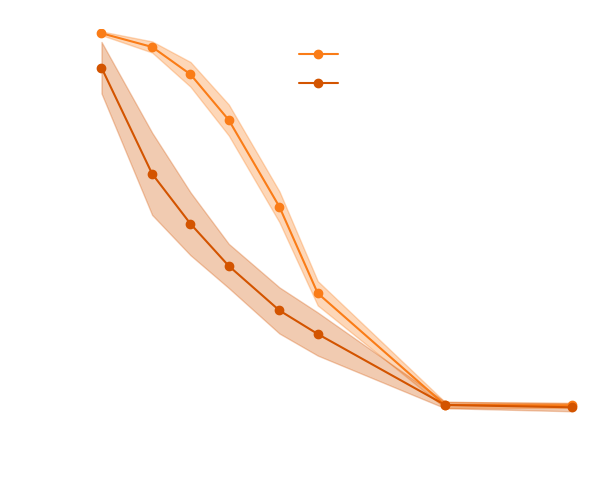
→ The score helps to constrain the distribution shape
Cosmological application
Since the score helps to constrain the shape, we start from the power spectrum posterior
Cosmological application
Since the score helps to constrain the shape, we start from the power spectrum posterior
Cosmological application
Since the score helps to constrain the shape, we start from the power spectrum posterior
We adapt the previous loss:
Cosmological application
Since the score helps to constrain the shape, we start from the power spectrum posterior
We adapt the previous loss:
Cosmological application
Since the score helps to constrain the shape, we start from the power spectrum posterior
We adapt the previous loss:
Preliminary
Summary
Summary
Goal: approximate the posterior
Summary
Problem: we don't have an analytic marginalized likelihood
Goal: approximate the posterior
Summary
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
Summary
→ need new methods to extract all informations
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
Summary
→ Full-Field Inference
→ need new methods to extract all informations
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
Summary
→ computationally expensive + large number of simulations
→ Full-Field Inference
→ need new methods to extract all informations
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
Summary
directly approximate the posterior (NPE): no need for MCMCs
→
→ computationally expensive + large number of simulations
→ Full-Field Inference
→ need new methods to extract all informations
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
directly approximate the posterior (NPE): no need for MCMCs
Summary
directly approximate the posterior (NPE): no need for MCMCs
→
→ computationally expensive + large number of simulations
→ Full-Field Inference
→ need new methods to extract all informations
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
directly approximate the posterior (NPE): no need for MCMCs
SBI with gradients
→
Summary
directly approximate the posterior (NPE): no need for MCMCs
→
→ computationally expensive + large number of simulations
→ Full-Field Inference
→ need new methods to extract all information
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
directly approximate the posterior (NPE): no need for MCMCs
SBI with gradients
→
⚠️ requirements: differentiable simulator + smooth NDE
Summary
directly approximate the posterior (NPE): no need for MCMCs
→
→ computationally expensive + large number of simulations
→ Full-Field Inference
→ need new methods to extract all information
Current methods: insufficient summary statistics + gaussian assumptions
Goal: approximate the posterior
Problem: we don't have an analytic marginalized likelihood
directly approximate the posterior (NPE): no need for MCMCs
Thank You!
⚠️ requirements: differentiable simulator + smooth NDE
SBI with gradients
→