Designing a Flexible UI Architecture
with React and GraphQL
@kamranayub bit.ly/NDCFlexibleUI
background by saragnzalez
@kamranayub

I'm the kind of person That
seeks TO LEARN AND SOLVE PROBLEMS
@kamranayub
Speaking of problems...
Let me paint a picture
or better yet, show you one...
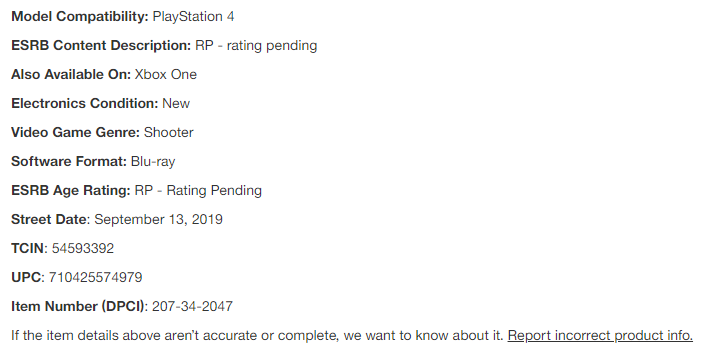
Item data
Item data is complex


How do we manage that data?
Carefully.
Once upon a time...
Challenges
complex ui state
Dynamic business rules
two different editing modes
scale to manage 200+ items at once
Disclaimer
Any resemblance to actual UI, legacy or modern,
is purely coincidental. These views are my own.


Source: Threadless
Horst Rittel and Melvin Webber defined a "wicked" problem as one that could be clearly defined only by solving it, or by solving part of it. This paradox implies, essentially, that you have to "solve" the problem once in order to clearly define it and then solve it again to create a solution that works.
Code Complete, Steve McConnell

Starting from the ux
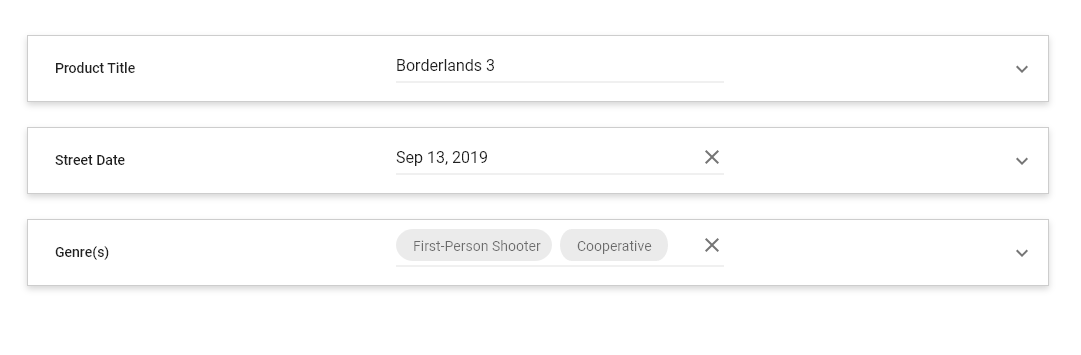
rethinking item data
item
product_title
street_date
rethinking item data
{
"product_title": "Borderlands 3 Super Deluxe Edition",
"street_date": "2019-09-13T00:00:00Z"
}This is a "consumer" way of thinking
How do we describe data?


Data Schema
product_title
rules
display
values
street_date
rules
display
values
Data schema
{
"product_title": {
"description": "A product's title",
"default_rules": {
"required": true,
"min_length": 1,
"max_length": 1337,
"read_only": false
},
"display": {
"component_type": "single_line_text",
"help_text": null
},
"item_values": [
{
"id": "item1",
"value_raw": "Borderlands 3",
"value_human": "Borderlands 3"
},
{
"id": "item2",
"value_raw": "Borderlands 3: Super Deluxe Edition",
"value_human": "Borderlands 3: Super Deluxe Edition",
"override_rules": {
"required": false,
"read_only": true
}
}
]
},
"street_date": {
"description": "The date this item will be available for purchase",
"default_rules": {
"required": true,
"min_date": 1555818103157,
"max_date": null,
},
"display": {
"component_type": "date",
"help_text": "Must be later than today's date"
},
"item_values": [
{
"id": "item1",
"value_raw": "2019-09-13T00:00:00Z",
"value_human": "Sep 13, 2019",
"override_rules": {
"min_date": null
}
}
]
}
}A "Schema-driven" UI
RULES
handles
RENDERING
VALIDATION
Semantics
primary
data
external data
caching layer
GraphQL Backend
schema
engine
data
resolution
React Frontend
state
management
client rule engine
High-level architecture
Data resolution
query {
itemData(attribute_ids: ["genres"]) {
attributes {
id
default_rules {
required
read_only
}
display {
component_type
}
values(item_ids: ["item1", "item2"]) {
item_id
raw_value
human_value
override_rules {
required
}
}
}
}
}AuthN / AuthZ
Default schema
Mapping (resolvers)
Load raw data
Load external data
Schema Engine
{
id: "genres",
default_rules: {
required: true,
read_only: false
},
display: {
component_type: "multi_select"
},
values: [
{
item_id: "item1",
raw_value: 2,
human_value: "First-Person Shooter",
override_rules: null
}
]
}Run rules
Modify schema
Merge resolved data
Return final schema
Schema Engine
{
id: "genres",
default_rules: {
required: true,
read_only: false
},
display: {
component_type: "multi_select"
},
values: [
{
item_id: "item1",
raw_value: 2,
human_value: "First-Person Shooter",
override_rules: null
}
]
}{
id: "genres",
default_rules: {
required: true,
read_only: false
},
display: {
component_type: "multi_select"
},
values: [
{
item_id: "item1",
raw_value: 2,
human_value: "First-Person Shooter",
override_rules: {
required: false,
read_only: true
}
}
]
}Schema Engine
Challenges
Business rules need (most) of the data loaded to work with
Human data needs to be cached within and across requests for performance
Not all attributes have the same performance profile
Resolve data before running rule engine
Introduce a caching layer (Redis, memcache, etc.)
Try to collate attributes from different data sources
Why graphql?
GraphQL is a specification
which provides
predictability
consistency
safety
Why graphql?
type ItemAttribute {
id: String!
display: AttributeDisplay
}
type AttributeDisplay {
component_type: ComponentType!
}
enum ComponentType {
single_line_text
multi_line_text
number
date
datetime
multi_option
}Static typing
Powerful query capabilities
query data($attribute_ids: [String!]!, $item_ids: [String!]!, hydrate: Boolean!) {
attributes(ids: $ids) {
id
title: description
default_rules {
max_length
}
values(items: $item_ids) {
raw_value
human_value @include(if: $hydrate)
override_rules {
max_length
}
}
}
item_metadata(ids: $item_ids) {
last_updated
}
}Why graphql?
type AttributeRules {
required: Boolean
read_only: Boolean
max_length: Int
max_chars: Int @deprecated(reason: "Use `max_length` instead")
}One version, field-level reporting
subscription item_updates(ids: ["item1"]) {
item_id
values {
raw_value
human_value
}
}Subscriptions
Why graphql?
Plus
Caching infrastructure
Field-level timing and analytics
Custom directives
Extensible architecture
But seriously,
you could totally use REST too

React UI
Dynamic rendering
undo / rollback values
relationship semantics
multi-item handling
Dynamic rendering

{
"attributes": [
{
"id": "product_title",
"display": {
"component_type": "single_line_text"
}
}
]
}Dynamic rendering
{
"attributes": [
{
"id": "product_title",
"default_rules": {
"read_only": true
},
"display": {
"component_type": "single_line_text"
}
}
]
}
Dynamic rendering
{
"attributes": [
{
"id": "product_title",
"default_rules": {
"read_only": true,
"max_length": 50
},
"display": {
"component_type": "single_line_text"
}
}
]
}
Dynamic rendering
{
"attributes": [
{
"id": "street_date",
"display": {
"component_type": "date"
}
}
]
}
Dynamic rendering
{
"attributes": [
{
"id": "genres",
"display": {
"component_type": "multi_select"
}
}
]
}
Dynamic rendering
query {
lookup(attribute_id: "genres") {
page_size
total
options(filter: "act") {
raw_value
human_value
}
}
}
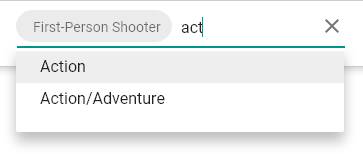
Dynamic rendering
different levels of customization
Attribute
Group
"Editor"
e.g. product_title
e.g. dimensions (WxHxD)
e.g. complex attributes
Undo / Rollback
Allow confirmation of values
Quick data entry
Batched save
Relationship semantics
Relationship semantics
prevent updates
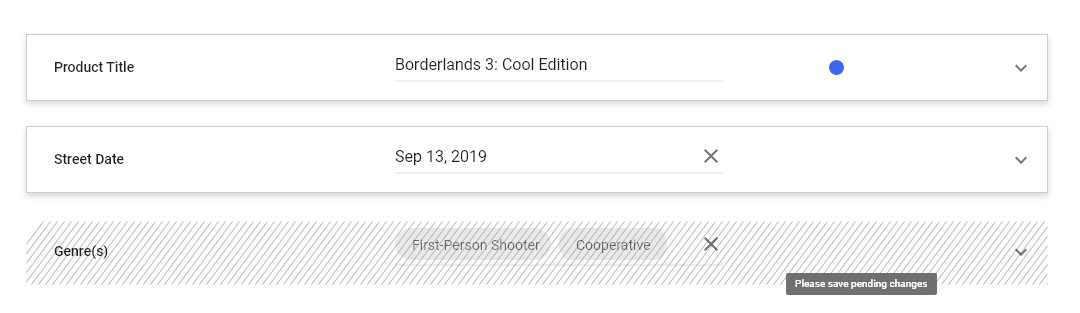
Relationship semantics
Hierarchical / Source
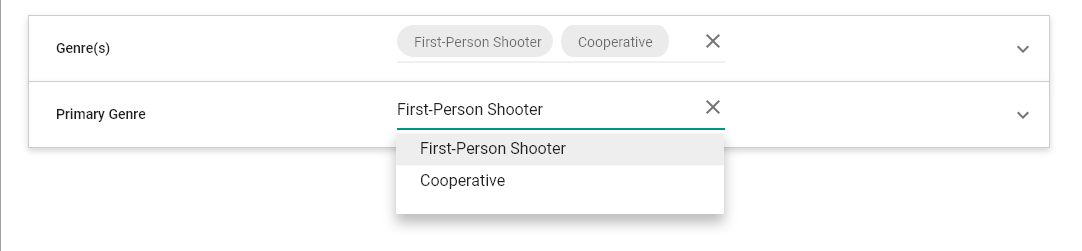
Relationship semantics
Conditional
Graph theory and math comes in handy!

multi-item handling
mixed edits
variedness
payload size
multi-item handling
mixed edits
multi-item handling
Variedness
multi-item handling
Payload size
What about saving data?
{
product_title: [
{ item_ids: ["item1", "item2"], value: "Borderlands 3" },
{ item_ids: ["item3"], value: "Borderlands 3 Super Deluxe Edition" }
],
street_date: [
{ item_ids: ["item1", "item2", "item3"], value: "2019-09-13T00:00:00Z" }
]
}Send
Compare
Validate
Persist
Publish
The save flow reuses much of the same schema infrastructure


Async and optimistic

Save challenges
dependent data
transaction boundaries
Async updates
Utilize the same schema relationships to load data
If one item succeeds but another fails, do you fail the entire request? Probably not.
Optimistic UI, exception-based corrections
This ain't easy
1000+ unit tests
100+ functional tests
Typescript / GraphQL types

if we could do it again
Do as i say
(not as I do)
Use the same stack
Isomorphic rendering
Shared state
Shared code
Isomorphic rule engine
run on server and client
Faster user feedback
less roundtrips
fully utilize graphql
not just a proxy
directives and robust queries
subscriptions with observables
Real-time database
live updates
async messaging
state sync
Where can you start?
First, decide whether this is something you'll find value from. Do you have dozens or hundreds of data points to support?
See if JSON schema will work for you!
If it doesn't, then roll your own schema
@kamranayub
kamranicus.com