Data Science For All: New Visions in Data Science Revolution
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Data Science For All: New Visions in Data Science Revolution
-
Introduction to course
-
Data Science Fundamentals
-
Two cultures of Statistics
-
Big data and small data: actions, transactions and interactions
-
Data Made, Data Found
-
Open data and API
Introduction to course
Objectives:
By the end of this module, students will be able to:
- Be familiar with the scope and methods in Data Science
- Understand statistical concepts in small data and big data research
- Be knowledgeable about data collection, data production and open data
- Recognize the limitations of Data Science
- Be introduced to the latest trends in Data Science Revolution
- Sir Francis Bacon
"ipsa scientia potestas est"
"Knowledge itself is Power."
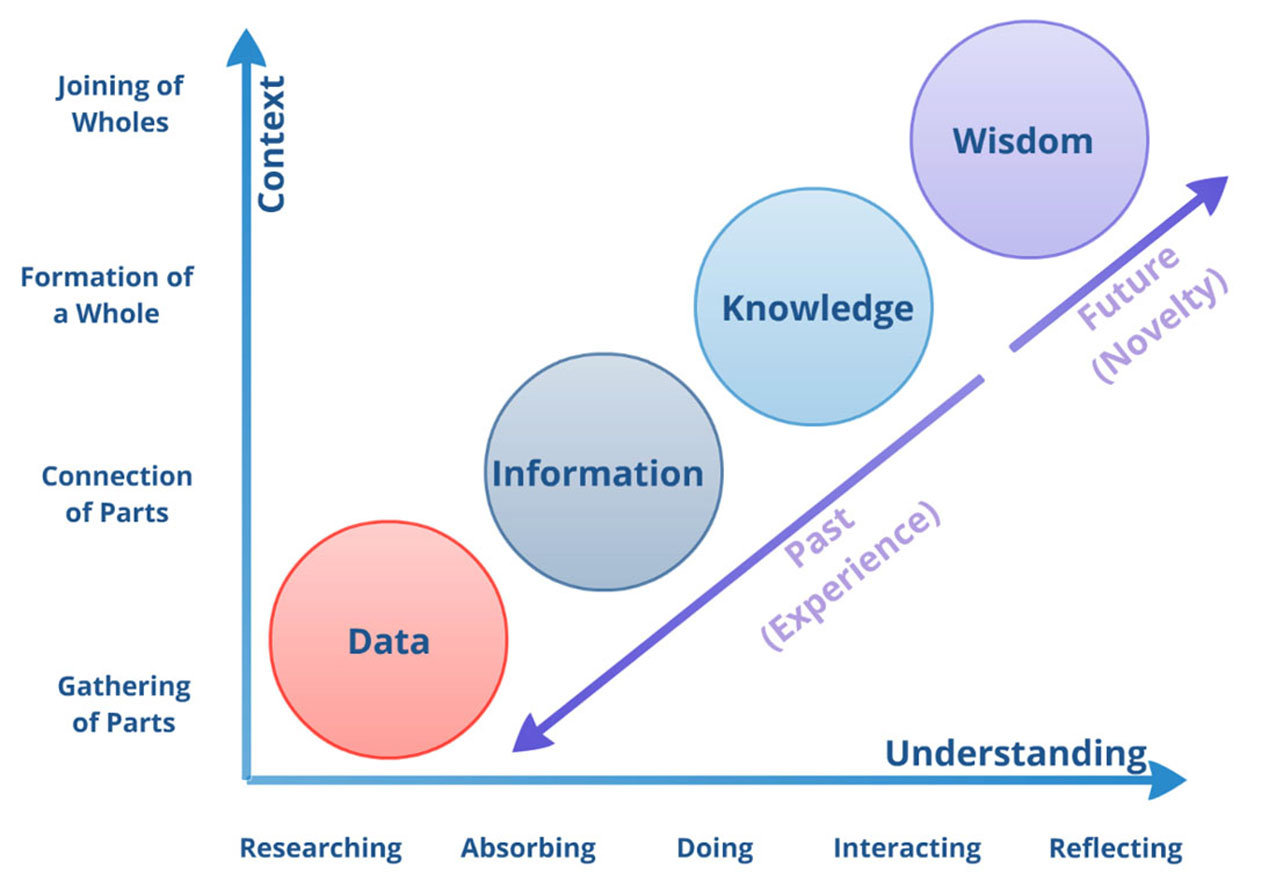
Ackoff, R.L., 1989. From data to wisdom. Journal of applied systems analysis, 16(1), pp.3-9.
"Knowledge is data."
"Data is power."
-
1700s Agricultural Revolution
-
1780 Industrial Revolution
-
1940 Information Revolution
-
1950s Digital Revolution
-
Knowledge Revolution
-
Data Revolution
Data Science Fundamentals
-
What is data?
-
What is data science?
-
How data is generated?
-
Data literacy
What is Data?
Data is everything.
-
Data is ever growing......
-
Moore's Law
-
Parkinson's Law
-
What is Big Data?
The Big data is about data that has huge volume, cannot be on one computer. Has a lot of variety in data types, locations, formats and form. It is also getting created very very fast (velocity) (Doug Laney 2001).
The Big data is about data that has huge volume, cannot be on one computer. Has a lot of variety in data types, locations, formats and form. It is also getting created very very fast (velocity) (Doug Laney 2001).
What is Big Data?
Burt Monroe (2012)
5Vs of Big data
-
Volume
-
Variety
-
Velocity
-
Vinculation
-
Validity
-
Prediction-explanation gap
-
Induction-deduction gap
-
Bigness-representativeness gap
-
Data access gap
What is Data Science?
What is Data Science?
-
Science of Data
-
Understand Data Scientifically
Data Science Keywords

-
Data management
-
Data analytics
-
Data scientists
-
Data curation
-
Modeling
-
CRMs
How Data are generated?
-
Computers
-
Web
-
Mobile devices
-
IoT (Internet of Things)
-
Further extension of human users (e.g. AI, avatars)
How Data are generated?
The size of the digital universe will double every two years at least.
- InsideBigdata.com
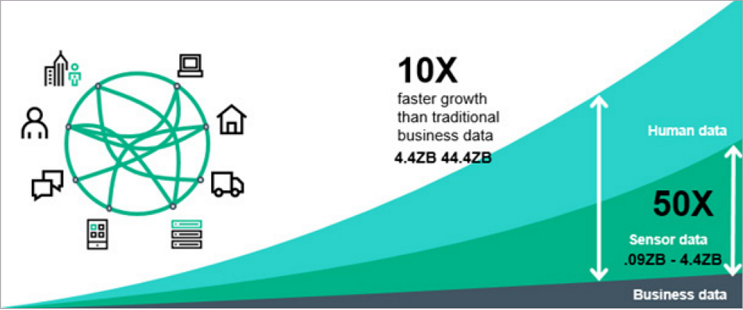
How Data are generated?
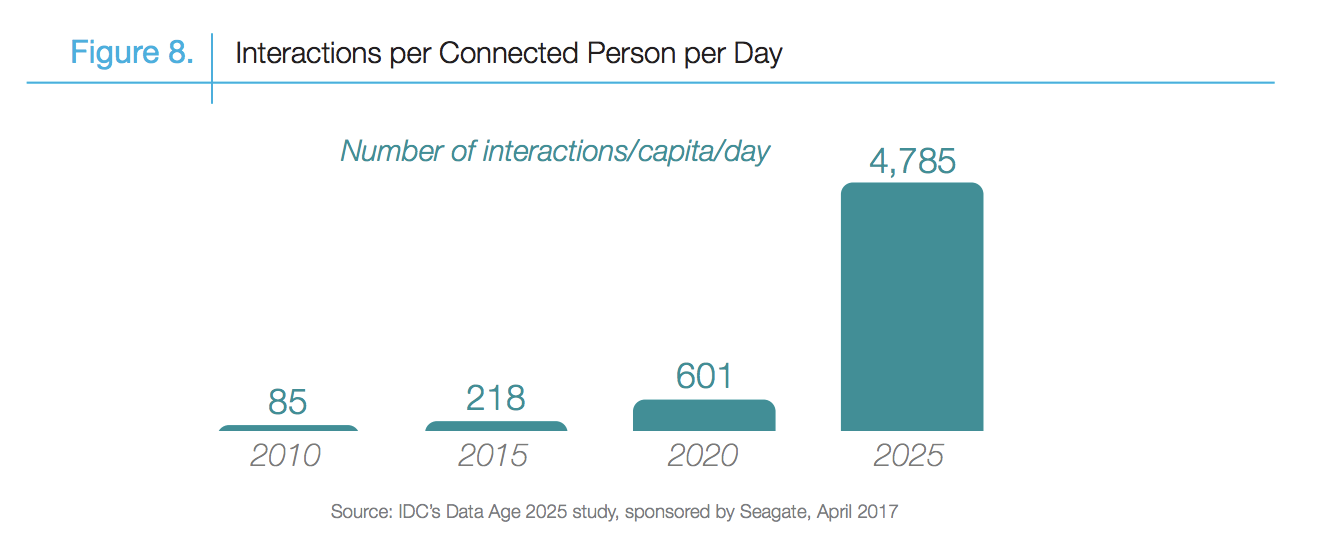
"Data Lake" Ubiquitous
Massive raw data repository in its rawest form pending processing.
Data Literacy
- Data generating process
- Graphic grammar
- Statistical judgement
Data Literacy
-
Data generating process
- How data are generated
- Distribution
- Missing values
- Wrong data
Data Literacy
- Graphic grammar
- Bad charts deliver incorrect message
- Poor design
- Color
- Label
- Scale
Data Literacy
- Statistical understanding
- Size does (not) matter
- Representativeness does
- Forecast/prediction minded
- Explanation
Data Literacy
- Why we need numeric data?
- History of data
Darkest hour: Churchill and typist

Two cultures of Statistics
-
Data model
-
Algorithm model
Statistical Modeling:
The Two Cultures
Leo Breiman 2001: Statistical Science
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
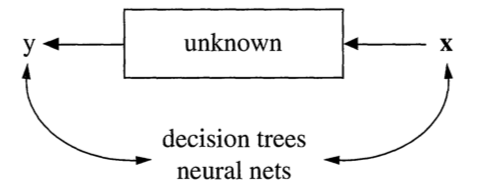
Theory:
Data Generation Process
Data are generated in many fashions. Picture this: independent variable x goes in one side of the box-- we call it nature for now-- and dependent variable y come out from the other side.

Theory:
Data Generation Process
Data Model
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
Response Variable= f(Predictor variables, random noise, parameters)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
Theory:
Data Generation Process
Data Model
The values of the parameters are estimated from the data and the model then used for information and/or prediction.

Theory:
Data Generation Process
Algorithmic Modeling
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function f(x)-an algorithm that operates on x to predict the responses y.
The goal is to find algorithm that accurately predicts y.
Theory:
Data Generation Process
Algorithmic Modeling
Unsupervised Learning
Supervised Learning vs.
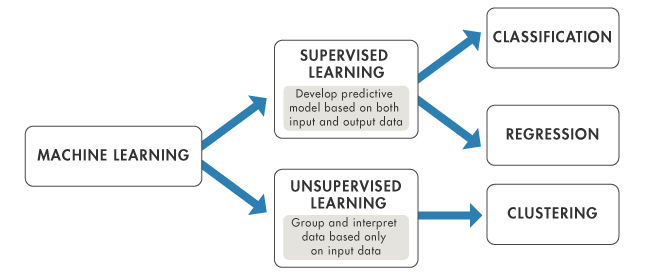
Source: https://www.mathworks.com
Let the dataset change your mindset.
- Hans Rosling
Hans Rosling
- Founded Gapminder Foundation
- Visualize historical data on public health and poverty
- Hal Varian
The ability to take data—to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it—that’s going to be a hugely important skill in the next decades.
Data Made, Data Found
-
Small data
-
Big data
Big data and small data:
actions
individuals
interactions
transactions
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals
individuals

Open data and API
-
What is open data?
-
Application Program Interface (API)
-
Google
-
Twitter
-
Government
-
Data Generation
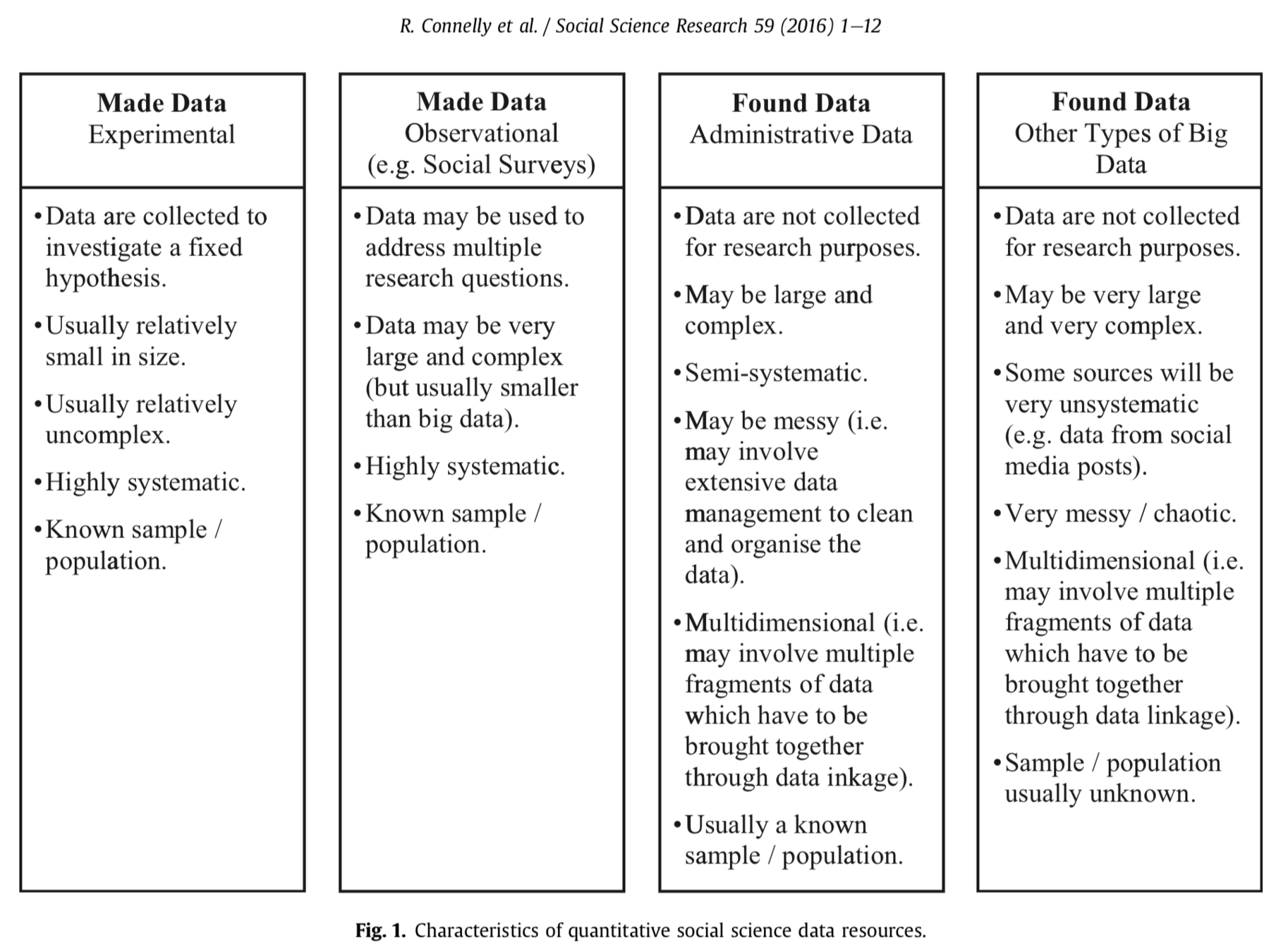
Data Methods
-
Survey
-
Experiments
-
Qualitative Data
-
Text Data
-
Web Data
-
Machine Data
-
Complex Data
-
Network Data
-
Multiple-source linked Data
-
Made
Data
}
}
Found
Data
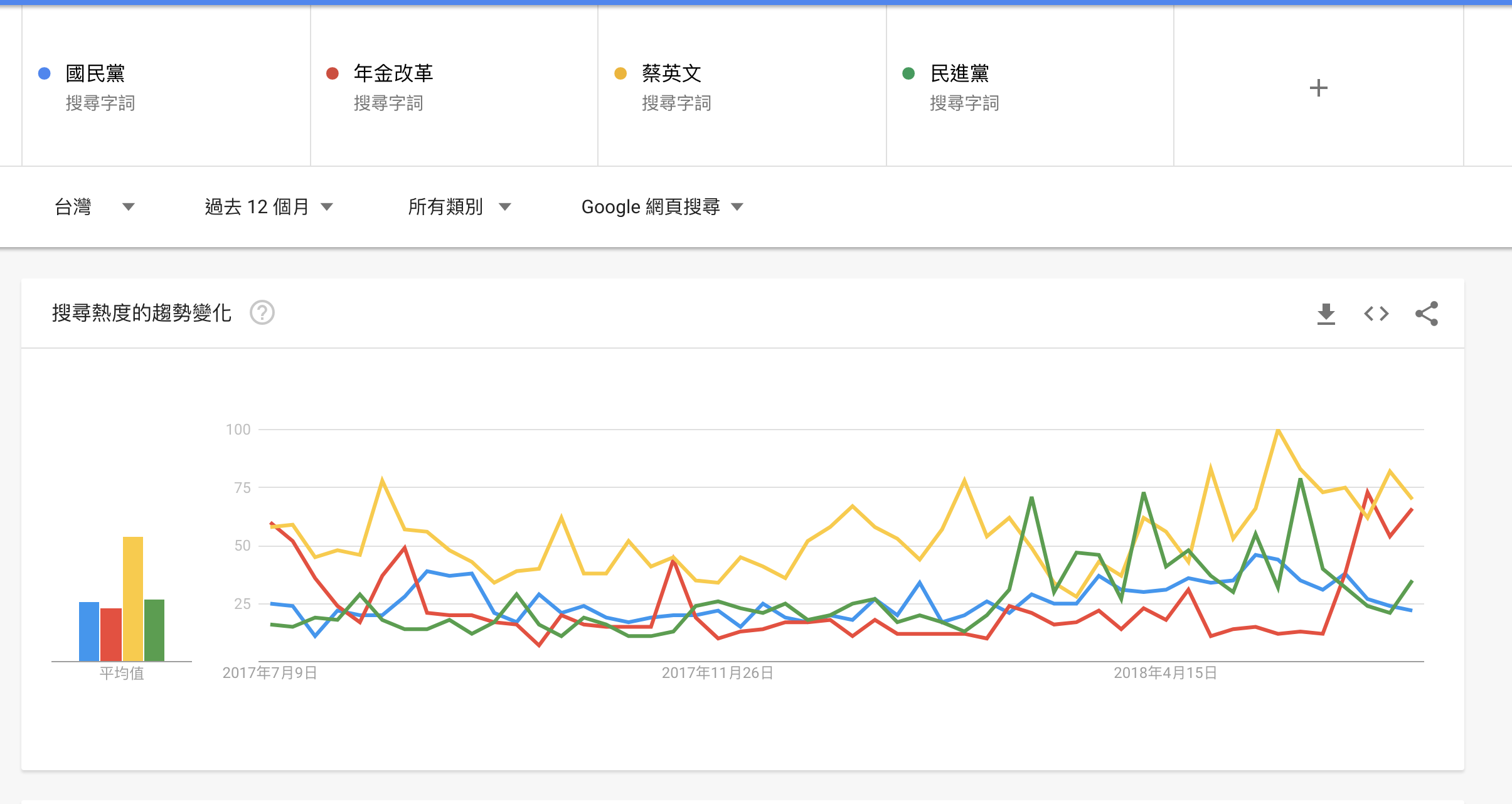
Quick Analytics:
Taiwan Climate

Quick Analytics:
Taiwan Climate

Spatial Data: United States
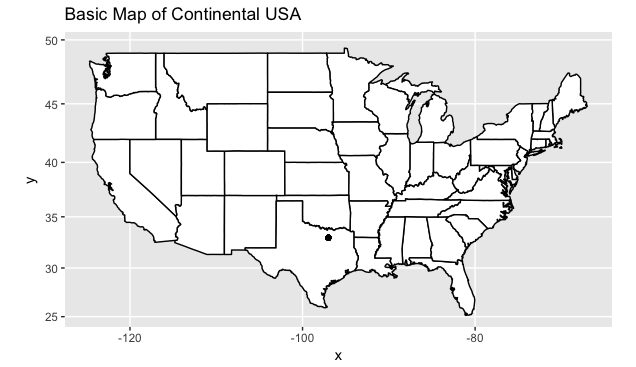
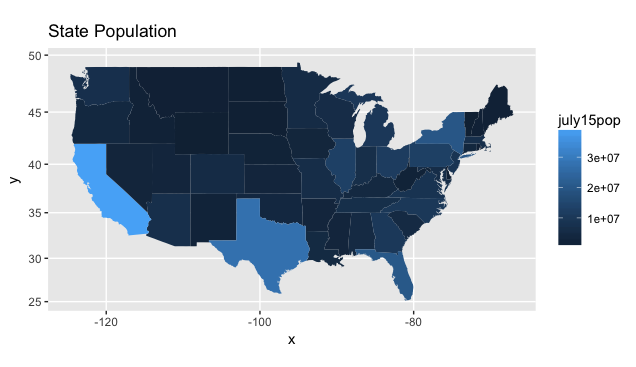
Spatial Data: United States
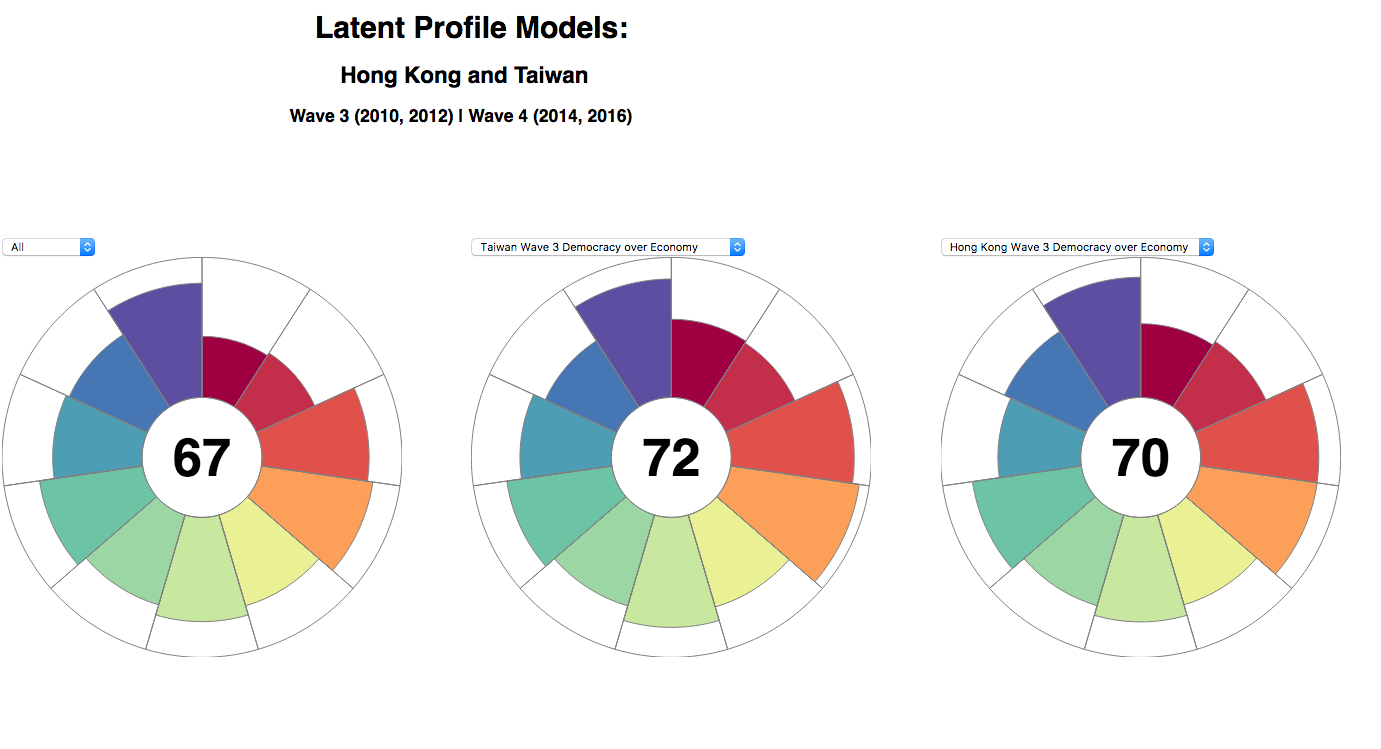
Java: D3 Library
Sentiment Analysis
