Methods of Data Collection and Production
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Introduction
Learning objectives
At completion of this course, students will be able to:
-
Understand Data theory
-
Be familiar with data methods by tasks and modes
-
Develop instruments and schemes for data collection
Overview
This is a data method course introducing the theory, practices and issues of data collection and production. It aims at providing a comprehensive framework in understanding data, and how data scientists conduct research starting from the data generation process. We will cover data methods, data management, big data trends and how to prepare data for next phrases of research including modeling and reporting.
Overview (continued)
This survey course is designed to equip data scientists with data generation concepts, tools and best practices. Topics on new developments and tools of big data in data science research will also be covered.
Readings
There will be a lot of readings in this class. You will advance from general understanding of data to scientist level of understanding data.
Policy on using generative AI
There are generally three policies on governing using generative AI in course setup:
-
Prohibiting AI Use
-
Allowing AI Use Without Restrictions
-
Permitting AI Use with Disclosur
Policy on using generative AI
- Michigan
"In principle you may submit AI-generated code, or code that is based on or derived from AI-generated code, as long as this use is properly documented in the comments: you need to include the prompt and the significant parts of the response. AI tools may help you avoid syntax errors, but there is no guarantee that the generated code is correct. It is your responsibility to identify errors in program logic through comprehensive, documented testing. Moreover, generated code, even if syntactically correct, may have significant scope for improvement, in particular regarding separation of concerns and avoiding repetitions. The submission itself should meet our standards of attribution and validation.
Policy on using generative AI
2. Harvard
Certain assignments in this course will permit or even encourage the use of generative artificial intelligence (AI) tools, such as ChatGPT. When AI use is permissible, it will be clearly stated in the assignment prompt posted in Canvas. Otherwise, the default is that use of generative AI is disallowed. In assignments where generative AI tools are allowed, their use must be appropriately acknowledged and cited. For instance, if you generated the whole document through ChatGPT and edited it for accuracy, your submitted work would need to include a note such as “I generated this work through Chat GPT and edited the content for accuracy.” Paraphrasing or quoting smaller samples of AI generated content must be appropriately acknowledged and cited, following the guidelines established by the APA Style Guide. It is each student’s responsibility to assess the validity and applicability of any AI output that is submitted. You may not earn full credit if inaccurate on invalid information is found in your work. Deviations from the guidelines above will be considered violations of CMU’s academic integrity policy. Note that expectations for “plagiarism, cheating, and acceptable assistance” on student work may vary across your courses and instructors. Please email me if you have questions regarding what is permissible and not for a particular course or assignment.
Policy on using generative AI
3. Carnegie Mellon University
You are welcome to use generative AI programs (ChatGPT, DALL-E, etc.) in this course. These programs can be powerful tools for learning and other productive pursuits, including completing some assignments in less time, helping you generate new ideas, or serving as a personalized learning tool.
However, your ethical responsibilities as a student remain the same. You must follow CMU’s academic integrity policy. Note that this policy applies to all uncited or improperly cited use of content, whether that work is created by human beings alone or in collaboration with a generative AI. If you use a generative AI tool to develop content for an assignment, you are required to cite the tool’s contribution to your work. In practice, cutting and pasting content from any source without citation is plagiarism. Likewise, paraphrasing content from a generative AI without citation is plagiarism. Similarly, using any generative AI tool without appropriate acknowledgement will be treated as plagiarism.
Policy on using generative AI
4. UTD (some courses)
Cheating and plagiarism will not be tolerated.
The emergence of generative AI tools (such as ChatGPT and DALL-E) has sparked large interest among many students and researchers. The use of these tools for brainstorming ideas, exploring possible responses to questions or problems, and creative engagement with the materials may be useful for you as you craft responses to class assignments. While there is no substitute for working directly with your instructor, the potential for generative AI tools to provide automatic feedback, assistive technology and language assistance is clearly developing. Course assignments may use Generative AI tools if indicated in the syllabus. AI-generated content can only be presented as your own work with the instructor’s written permission. Include an acknowledgment of how generative AI has been used after your reference or Works Cited page. TurnItIn or other methods may be used to detect the use of AI. Under UTD rules about due process, referrals may
be made to the Office of Community Standards and Conduct (OCSC). Inappropriate use of AI may result in penalties, including a 0 on an assignment.
Policy on using generative AI
Using generative AI may not save time, but will improve quality and deepen thought process.
Course structure
-
Data Production
- Survey
- Experiments
- Qualitative data
Focus group
-
Data Collection
- Spatial data
- Complex data
- Text data
- Web data
- Social media data
- Record Linkage
- Event data
- Sir Francis Bacon
ipsa scientia potestas est"
"Knowledge itself is Power."
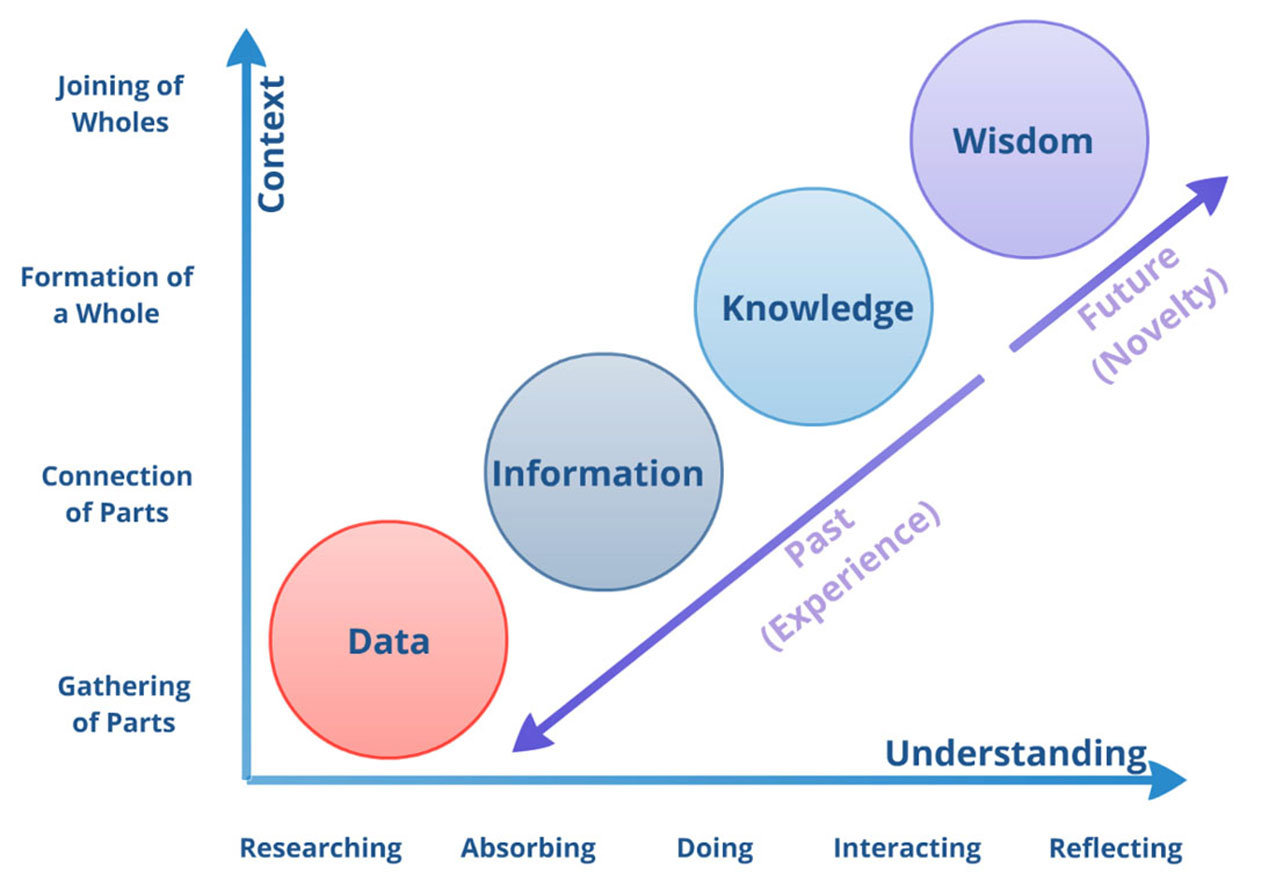
Ackoff, R.L., 1989. From data to wisdom. Journal of applied systems analysis, 16(1), pp.3-9.
"Knowledge is data."
"Data is power."
-
1700s Agricultural Revolution
-
1780 Industrial Revolution
-
1940 Information Revolution
-
1950s Digital Revolution
-
Knowledge Revolution
-
Data Revolution
What is Data?
facts and statistics collected together for reference or analysis"
- Oxford dictionary
- fundamental component in the process of analysis,
- where it serves as the raw input that can be processed to generate information and insights.
the representation of facts, concepts, or instructions in a formalized manner suitable for communication, interpretation, or processing by humans or by automatic means"
- McGraw-Hill Dictionary of Scientific and Technical Terms, 2003
- structured and communicable
- can be interpreted and processed for various applications.
a reinterpretable representation of information in a formalized manner suitable for communication, interpretation, or processing"
- ISO/IEC 2382-1:1993
- reinterpretable
- can be reanalyzed or reused in different contexts to extract new information.
a set of values of qualitative or quantitative variables"
- Mark A.Beyer, 2014
the basis for:
- modeling
- inference.
Beyer, M. A. 2014. "Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data." Gartner Research.
What is Data?
-
Data is measured.
-
Data is perceived.
-
Data is produced.
-
Data is collected.
What is Data?
Data is everything.
-
Data is ever growing......
-
Moore's Law
-
Parkinson's Law
-
Moore's Law
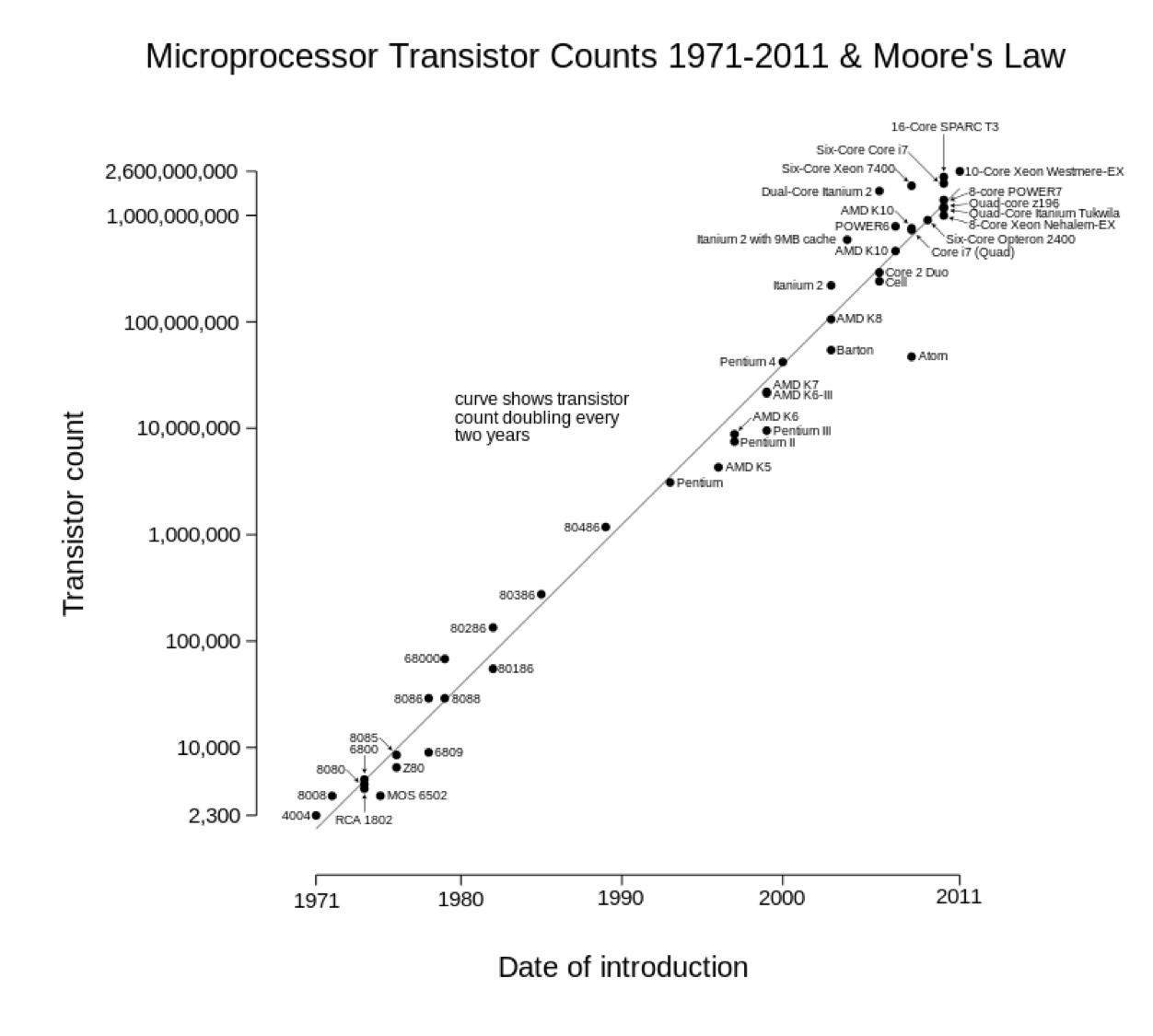
Moore's Law
Moore's Law
General-purpose computing capacity grew at an annual rate of 58%.
Computing power doubles every 18 months.
Telecommunication
The world's capacity for bidirectional telecommunication grew at 28% per year, closely followed by the increase in globally stored information (23%)
Hilbert, M. and López, P., 2011. The world's technological capacity to store, communicate, and compute information. science, p.1200970.
Digital Revolution
Humankind's capacity for unidirectional information diffusion through broadcasting channels has experienced comparatively modest annual growth (6%). Telecommunication has been dominated by digital technologies since 1990 (99.9% in digital format in 2007), and the majority of our technological memory has been in digital format since 2000s.
Parkinson's Law of Data
“Data expands to fill the space available for storage.”
Quick note about size
Bits: 8 bits = 1 byte
Bytes: 1024 bytes = 1 KB (1 to 3 digits)
Kilobytes: 1024 KB = 1 MB (4 to 6 digits)
Megabytes: 1024 MB = 1 GB (7 to 9 digits)
Gigabytes: 1024 GB = 1 TB (10 to 12 digits)
Terabytes: 1024 TB = 1 PB (13 to 15 digits)
Petabytes: 1024 PB = 1 EB (16 to 18 digits)
Exabytes: 1024 EB = 1 ZB (19 to 21 digits)
Zettabytes: 1024 ZB = 1 YB (22 to 24 digits)
Yottabytes: more than enough... (25 to 27 digits)
A Taxonomy of Data
-
Numbers
-
Text
-
Images
-
Audio
-
Video
-
Signals
-
Data of data: Metadata and Paradata
Categories of Data
(by method)
-
Survey
-
Experiments
-
Qualitative Data
-
Text Data
-
Web Data
-
Complex Data
-
Network Data
-
Multiple-source linked Data
-
What is Big Data?
The Big data is about data that has huge volume, cannot be on one computer. Has a lot of variety in data types, locations, formats and form. It is also getting created very very fast (velocity) (Doug Laney 2001).
The Big data is about data that has huge volume, cannot be on one computer. Has a lot of variety in data types, locations, formats and form. It is also getting created very very fast (velocity) (Doug Laney 2001).
What is Big Data?
Burt Monroe (2012)
5Vs of Big data
-
Volume
-
Variety
-
Velocity
-
Vinculation
-
Validity
Big Data Research
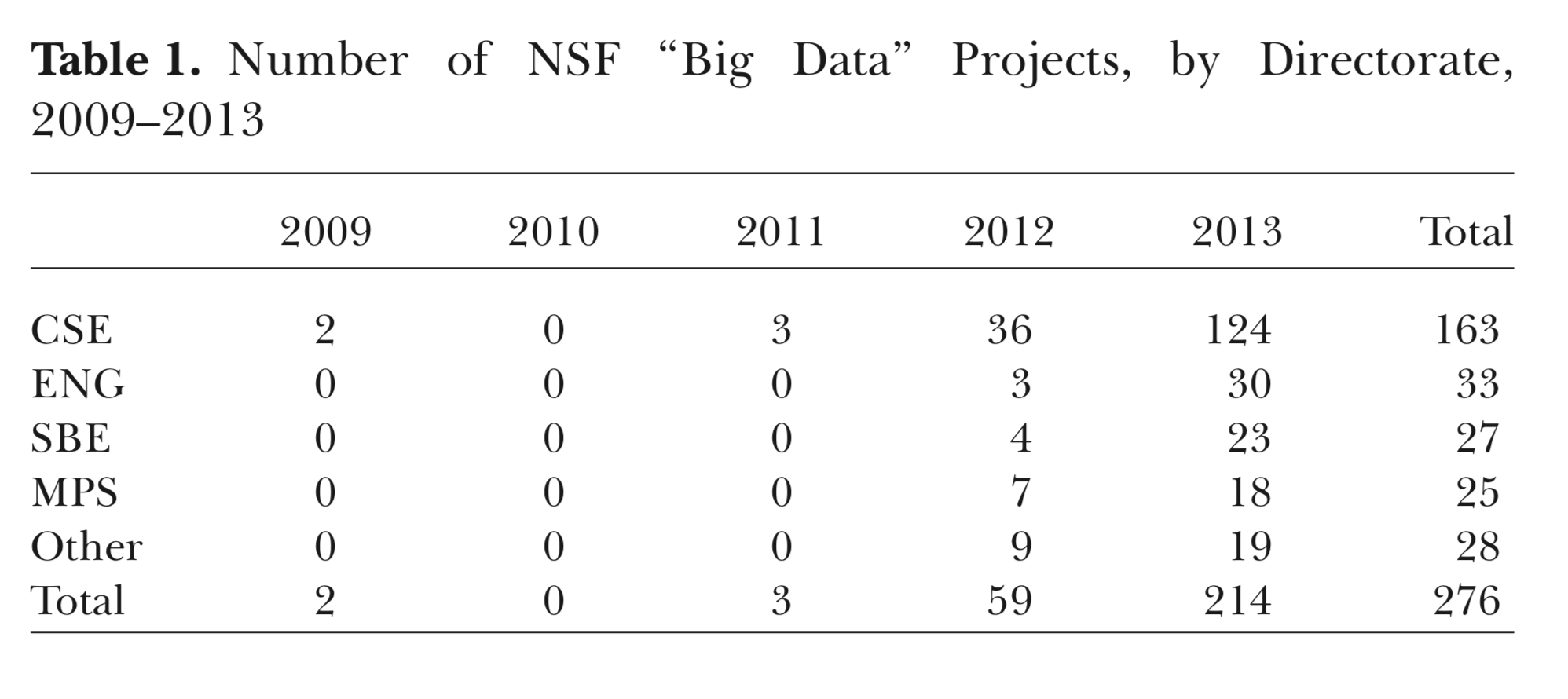
CSE - Computer and Information Science and Engineering
ENG - Engineering
SBE - Social Behavioral and Economic Sciences
Mathematics and Physical Science
National Institutes of Health (NIH)
Office of Behavioral and Social Sciences (OBSSR)
The National Archive of Computerized Data on Aging (NACDA)
program advances research on aging by helping researchers to profit from the under-exploited potential of a broad range of
datasets. NACD preserves and makes available the largest library of electronic data on aging in the United States
Data Sharing for Demographic Research (DSDR) provides data archiving, preservation, dissemination and other data infrastructure services. DSDR works toward a unified legal,
technical and substantive framework in which to share re
search data in the population sciences.
UNITED STATES GEOLOGICAL SURVEY (USGS)
The USGS John Wesley Powell Center for Analysis and Synthesis
just announced eight new research projects for transforming big data sets and big ideas about earth science theories into
scientific discoveries. At the Center, scientists collaborate to perform state of the art synthesis to leverage comprehensive, long-term data.
Public Policy and Big Data
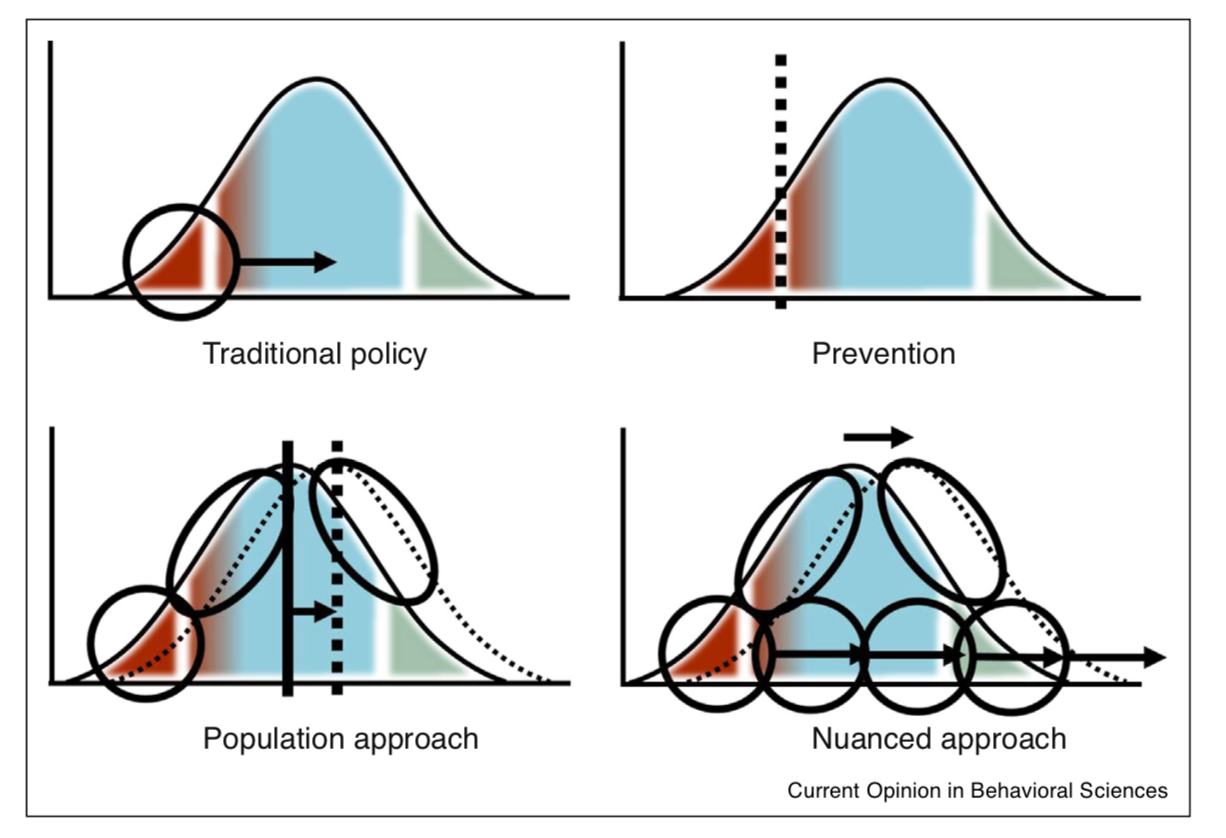
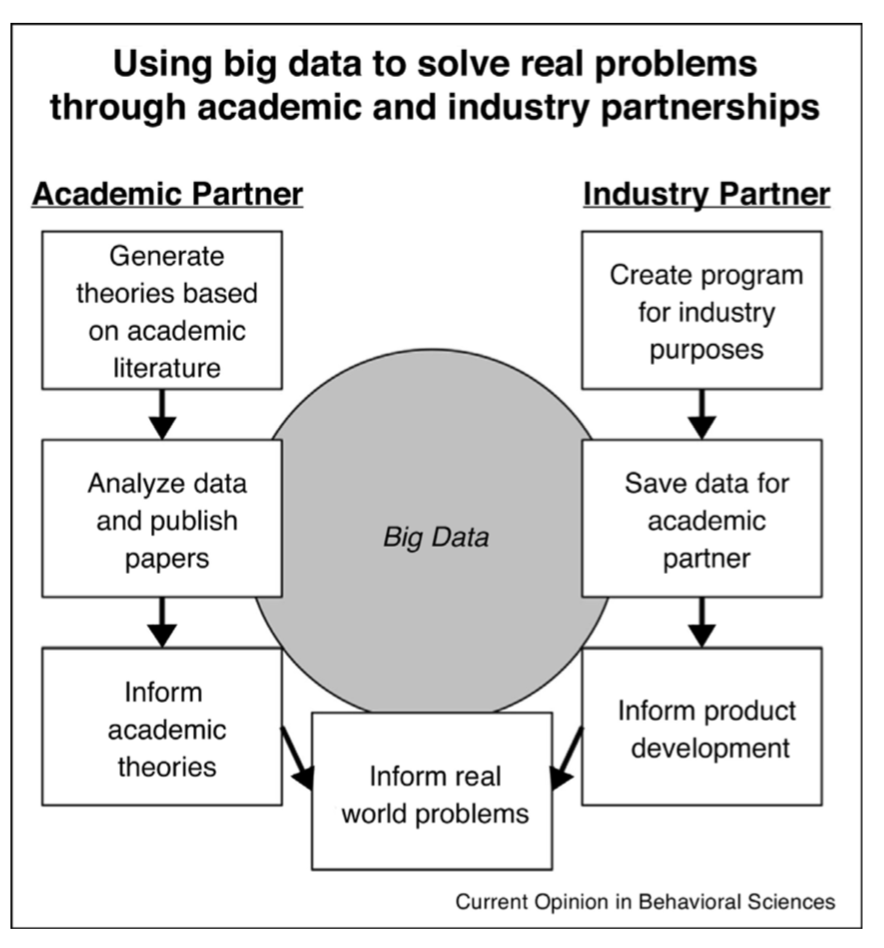
Mitroff, S.R. and Sharpe, B., 2017. Using big data to solve real problems through academic and industry partnerships. Current Opinion in Behavioral Sciences, 18, pp.91-96.
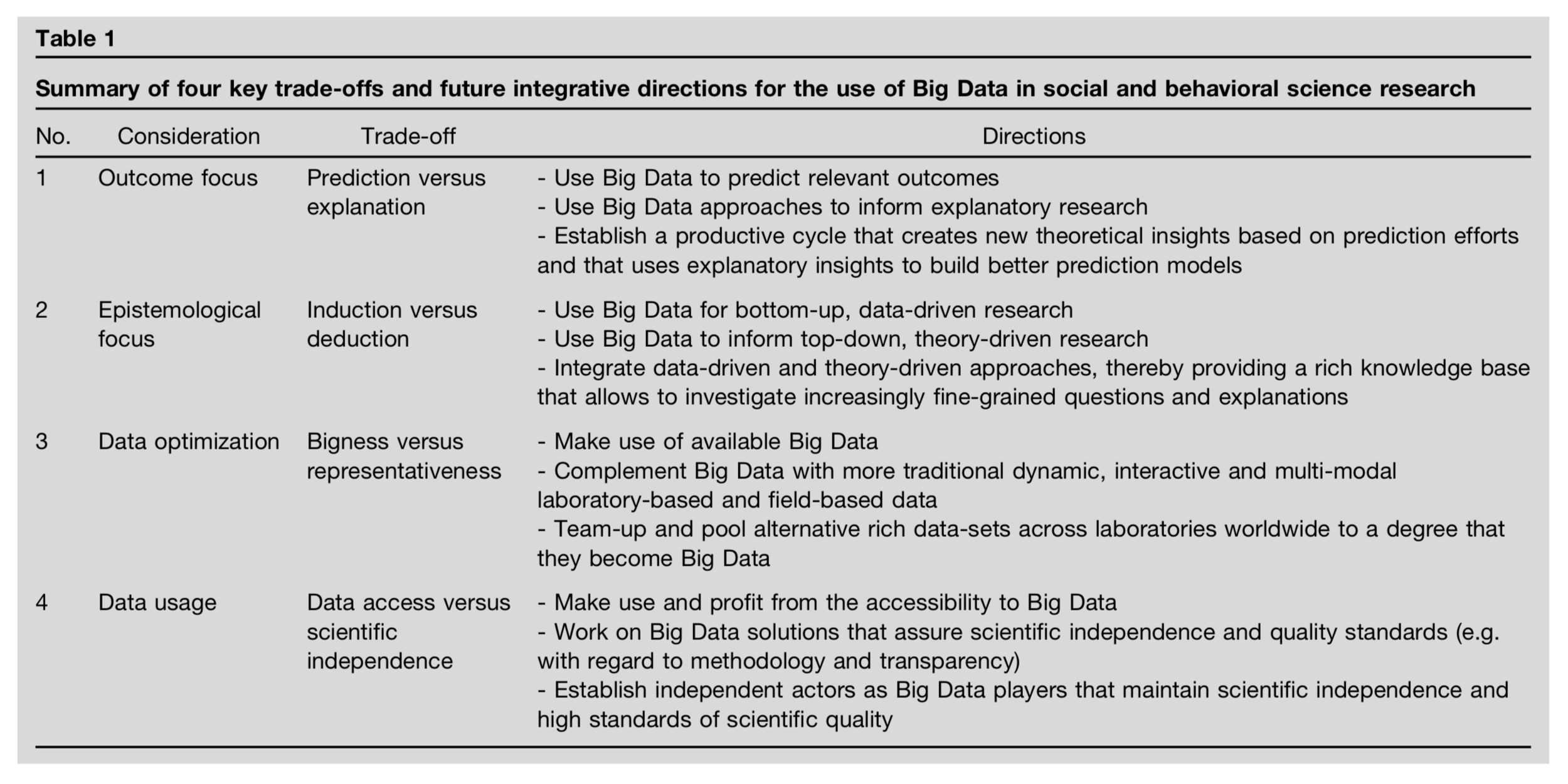
Mahmoodi, J., Leckelt, M., van Zalk, M.W., Geukes, K. and Back, M.D., 2017. Big Data approaches in social and behavioral science: four key trade-offs and a call for integration. Current Opinion in Behavioral Sciences, 18, pp.57-62.
Mahmoodi, J., Leckelt, M., van Zalk, M.W., Geukes, K. and Back, M.D., 2017. Big Data approaches in social and behavioral science: four key trade-offs and a call for integration. Current Opinion in Behavioral Sciences, 18, pp.57-62.
-
Prediction-explanation gap
-
Induction-deduction gap
-
Bigness-representativeness gap
-
Data access gap
Three challenges facing data science
-
Generalization from samples to population
-
Generalization from the control group to the treatment group
-
Generalization from observed measurements to the underlying constructs of interest.
- Andrew Gelman
Data methods
Experimental design
Measurements
What is Data Science?
What is Data Science?
-
Science of Data
-
Understand Data Scientifically
The key word in "Data Science" is not Data....
- Jeff Leek
it is Science.
The long term impact of Data Science will be measured by the scientific questions we can answer with the data.
- Jeff Leek
Data Science Keywords

-
Data collection and production
-
Data mining
-
Web scraping
-
-
Data Visualization
-
Interactive charts
-
Dashboards
-
-
Data management
-
Database
-
SQL, NoSQL
-
-
Data analytics
-
Machine learning
-
Deep learning
-
-
CRMs
How Data are generated?
-
Computers
-
Web
-
Mobile devices
-
IoT (Internet of Things)
-
Further extension of human users (e.g. AI, avatars)
How Data are generated?
The size of the digital universe will double every two years at least.
- InsideBigdata.com
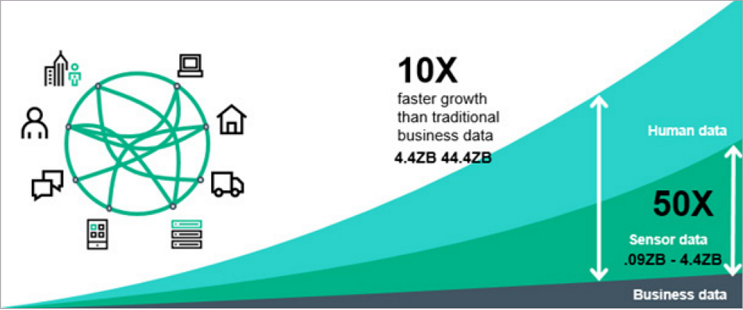
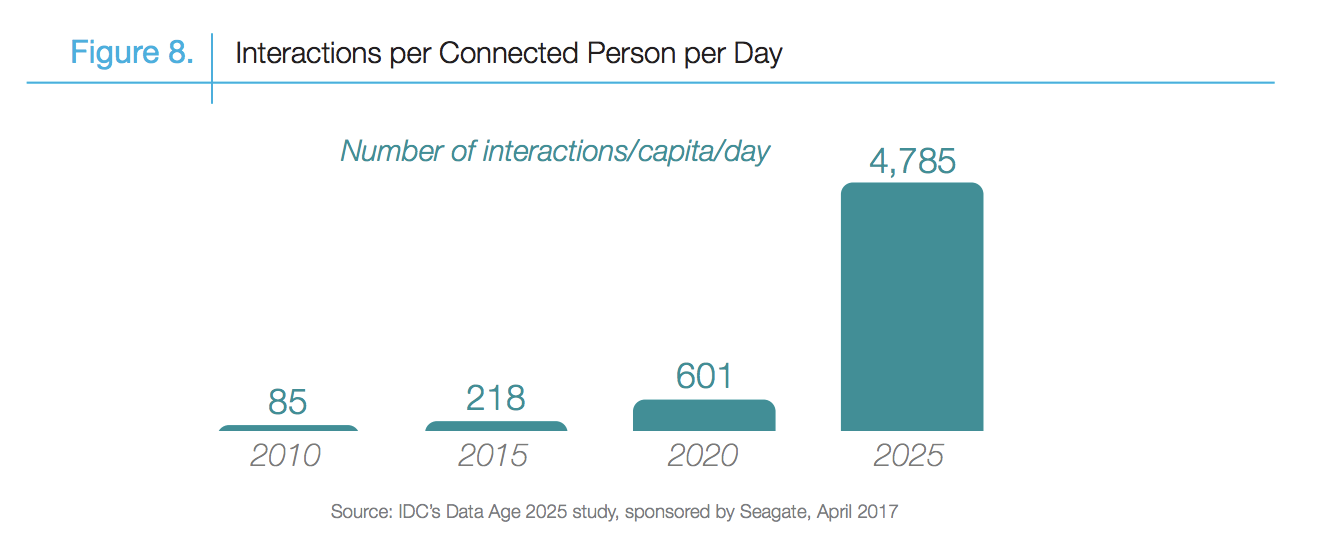
How Data are generated?
"Data Lake" Ubiquitous
Massive raw data repository in its rawest form pending processing.
Data Analytics vs.
Data Analysis
Data analytics refers to generation, acquisition, management, modeling and visualization of data.
Thomas Davenport and his colleagues (2007) emphasize the ability to "collect, analyze and act on data".
Davenport, Thomas H., and Jeanne G. Harris. 2007. Competing on analytics: The new science of winning. Harvard Business Press.
Data Analytics vs.
Data Analysis
Data analytics goes beyond only providing analysis of data but focuses on the action or decision making informed by data.
Social Data Analytics: A journey just set afoot
Social data was initially referred to data generated from social media. It is now not confined to that generation mode but is more generally data generated by people or users.
Social data analytics encompasses the generation, management, modeling and visualization of social data.
.... social science is beginning to shape the world of big data.
Much of big data is social data.... It is the responsibility of social scientists to assume their central place in the world of big data, to shape the questions we ask of big data, and to characterize what does and does not make for a convincing answer.
- Monroe, Pan, Roberts, Sen and Sinclair 2015
Social (Data) Scientist's mission
Two major areas to which social scientists can contribute, based on decades of experience and work with end users, are:
-
Inference
-
Data quality.
- Foster et al. 2016
Social (Data) Scientist's mission
Compared to computer scientists and business analytics researchers, we are distinct in not only our familiarity with data, statistical models and inference.
Social scientists pursue a good cause, something we can contribute: to make a difference, to bring public good and to shape a better society.
Social (Data) Scientist's mission
Grimmer, J., 2015. We are all social scientists now: how big data, machine learning, and causal inference work together. PS: Political Science & Politics, 48(1), pp.80-83.
Social scientists know that large amounts of data will not overcome the selection problems that make causal inference so difficult.
The story of Google Flu Trend
By using Big Data of search queries, Google Flu Trend (GFT) predicted the flu-like illness rate in a population.
However, the journal Nature where GFT published the findings on figured the GFT overestimated as much as twice than the actual data. Two political scientists helped fix and address the problem.
Lesson we learn:
Political Science can save the world!
The story of Google Flu Trend
Lazer, Kennedy, King and Vespignani (2014)
Traditional “small data” often offer information that is not contained (or containable) in big data, and the very factors that have enabled big data are enabling more traditional data collection (watch TED talk by Dr. Joel Selanikio). The Internet has opened the way for improving standard surveys, experiments, and health reporting. (Lazer et al. 2014 Science)
A Theory of Data: Understanding Data Generation
Data Generation
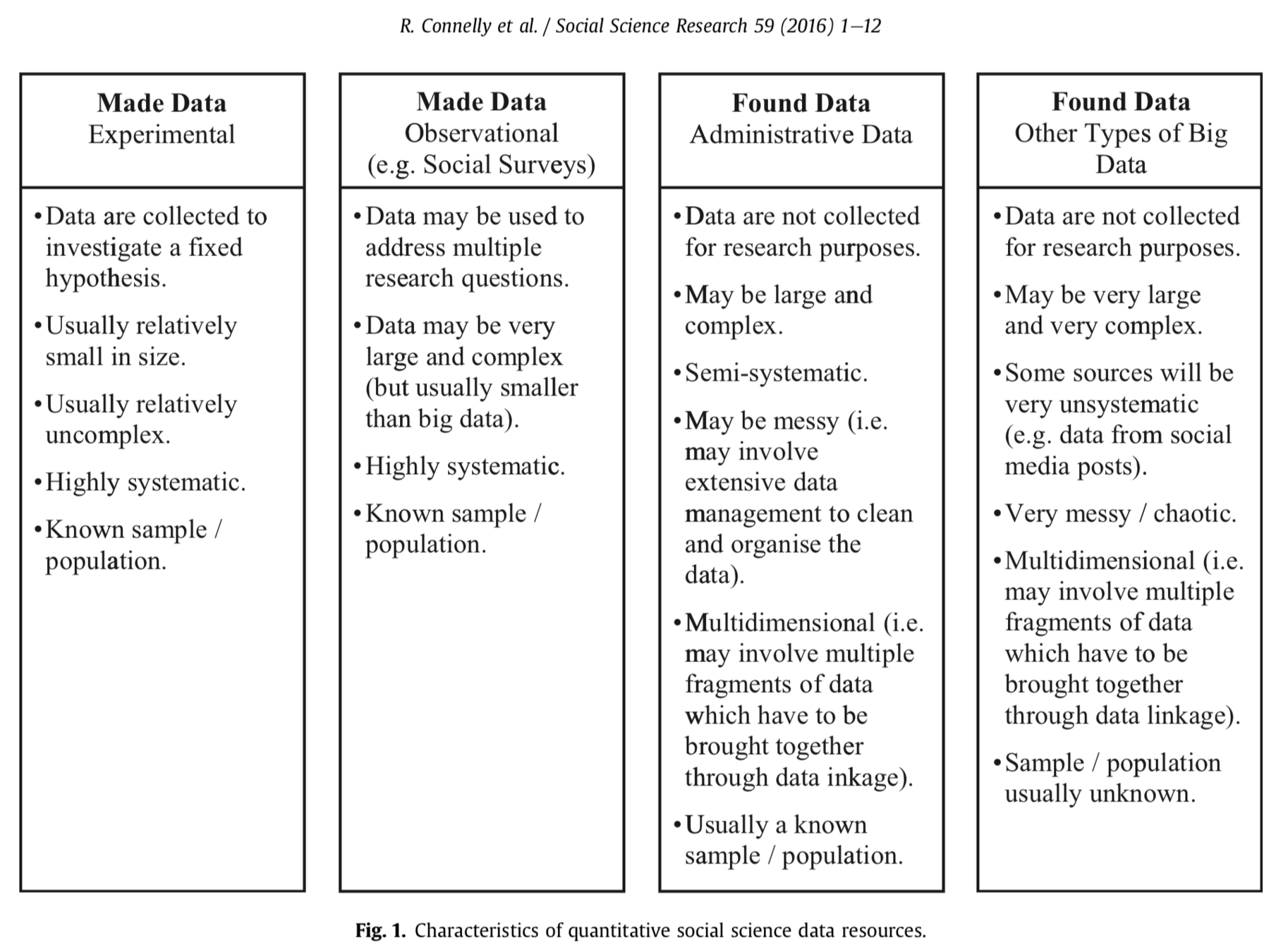
Administrative Data
Administrative data are defined as data which derive from the operation of administrative systems, typically by public sector agencies
- Connelly et al. 2016
Data Methods
-
Survey
-
Experiments
-
Qualitative Data
-
Text Data
-
Web Data
-
Machine Data
-
Complex Data
-
Network Data
-
Multiple-source linked Data
-
Made
Data
}
}
Found
Data
Statistical Modeling:
The Two Cultures
Leo Breiman 2001: Statistical Science
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
Theory:
Data Generation Process
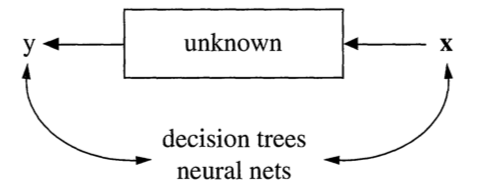
Data are generated in many fashions. Picture this: independent variable x goes in one side of the box-- we call it nature for now-- and dependent variable y come out from the other side.

Theory:
Data Generation Process
Data Model
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
Response Variable= f(Predictor variables, random noise, parameters)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
Theory:
Data Generation Process
Data Model
The values of the parameters are estimated from the data and the model then used for information and/or prediction.

Theory:
Data Generation Process
Algorithmic Modeling
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function f(x)-an algorithm that operates on x to predict the responses y.
The goal is to find algorithm that accurately predicts y.
Theory:
Data Generation Process
Algorithmic Modeling
Unsupervised Learning
Supervised Learning vs.
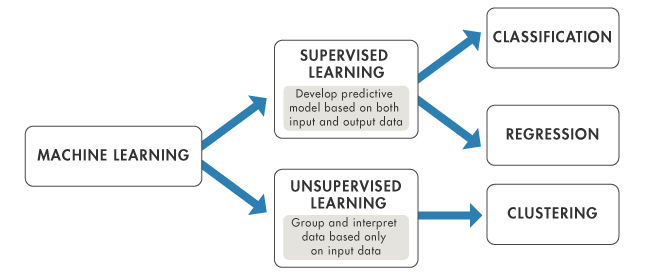
Source: https://www.mathworks.com
Let the dataset change your mindset.
- Hans Rosling
Hans Rosling
- Founded Gapminder Foundation
- Visualize historical data on public health and poverty
Hal Varian
Chief Economist, Google
Professor of Economics, University of California, Berkeley.
Big Data: New Tricks for Econometrics
Machine Learning and Econometrics

- Hal Varian
The ability to take data—to be able to understand it, to process it, to extract value from it, to visualize it, to communicate it—that’s going to be a hugely important skill in the next decades.
- Mike Driscoll
“The Three Sexy Skills of Data Geeks”: “…with the Age of Data upon us, those who can model, munge, and visually communicate data...
Data Science Roadmap
-
Introduction - Data theory
-
Data methods
-
Statistics
-
Programming
-
Data Visualization
-
Information Management
-
Data Curation
-
Spatial Models and Methods
-
Machine Learning
-
NLP/Text mining
Data Science Roadmap
-
Introduction - Data theory
-
Fundamentals
-
Data concepts
-
Data Generation Process (DGP)
-
-
Algorithm-based vs. Data-based approaches
-
Taxonomy
-
Data Science Roadmap
-
Data methods
-
Passive data
-
Data at will
-
Qualitative data
-
Complex data
-
Text data
-
Data Science Roadmap
-
Statistics
-
Sample and Population
-
Inference
-
Size and power
-
Representation
-
Data Science Roadmap
-
Programming
-
R
-
Python
-
HTML
-
Java script
-
Data Science Roadmap
-
Data Visualization
-
Tableau
-
ggplot2
-
Shiny
-
D3.js
-
Animation
-
Data Science Roadmap
-
Information Management
-
MapReduce
-
Hadoop
-
Cassandra
-
MongoDB
-
NoSQL
-
Data Science Roadmap
-
Data curation
-
Google OpenRefine
-
Sampling
-
Missing value concepts and management
-
Data Science Roadmap
-
Spatial Models and Methods
-
GIS
-
R/Leaflet
-
Python Map
-
Remote Sensing
-
Data Science Roadmap
-
Machine Learning
-
Supervised
-
Unsupervised
-
Regression methods
-
Neural Networks
-
Data Science Roadmap
-
NLP/Text Mining
-
Corpus
-
Text Analysis
-
Sentiment Analysis
-
Natural Language Processing
-
Data Literacy
- Data generating process
- Graphic grammar
- Statistical judgement
Data Literacy
-
Data generating process
- How data are generated
- Distribution
- Missing values
- Wrong data
Data Literacy
- Graphic grammar
- Bad charts deliver incorrect message
- Poor design
- Color
- Label
- Scale
Data Literacy
- Statistical understanding
- Size does (not) matter
- Representativeness does
- Forecast/prediction minded
- Explanation
Data Literacy
- Why we need numeric data?
- History of data
Darkest hour: Churchill and typist

-
Data Thinking
-
Multi-disciplinary Thinking
-
Computationally Thinking