Methods of Data Collection and Production
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Text Data
What is Text Data?
Text data refer to any documents or corpus in text forms.
-
Structured data refers to text with a high degree of organization, such that inclusion in a relational database is seamless and readily searchable.
-
Unstructured data do not have a predefined data model or is not organized in a predefined manner.
The TEXT data type stores any kind of text data. It can contain both single-byte and multibyte characters that the locale supports.
- IBM
What is Text Data?
Corpus (plural Corpora) - A set of multiple similar documents is called a corpus.
Corpus
-
The Brown University Standard Corpus of Present-Day American English, or just the Brown Corpus, is a collection of processed documents from works published in the United States in 1961.
-
The Brown Corpus was a historical milestone: it was a machine-readable collection of a million words across 15 balanced genres with each word tagged with its part of speech (e.g., noun, verb, preposition).
Corpus Example: Brown Corpus
-
The British National Corpus (BNC) is a 100 million word collection of samples of written and spoken language from a wide range of sources, designed to represent a wide cross-section of British English from the later part of the 20th century, both spoken and written.
-
The latest edition is the BNC XML Edition, released in 2007.
Corpus example: BNC
-
Monolingual: It deals with modern British English, not other languages used in Britain. However non-British English and foreign language words do occur in the corpus.
-
Synchronic: It covers British English of the late twentieth century, rather than the historical development which produced it.
Corpus example: BNC
-
General: It includes many different styles and varieties, and is not limited to any particular subject field, genre or register, containing both spoken and written language examples.
Corpus example: BNC
-
Sample: For written sources, samples of 45,000 words are taken from various parts of single-author texts. Shorter texts up to a maximum of 45,000 words, or multi-author texts such as magazines and newspapers, are included in full. Sampling allows for a wider coverage of texts within the 100 million limit, and avoids over-representing idiosyncratic texts.
Corpus example: BNC
-
The number and scope of documents determine the range of questions that one can ask and the quality of the answers.
-
Too few documents result in a lack of coverage, too many of the wrong kind of documents invite confusing noise.
-
Example: BNC Word Frequencies
Corpus analysis
The first step in processing text is deciding what terms and phrases are meaningful. Tokenization separates sentences and terms from each other.
Tokenization
Term frequency–inverse document frequency (TFIDF)

-
Stop words are a category of words that have limited semantic meaning regardless of the document contents.
-
Such words can be prepositions, articles, common nouns, etc.
-
For example, the words “the”, “to” and “of”, which could account for more than 10 percent of the text.
Stop words
Terminology - stop words
Can you identify other stop words manually?
-
a contiguous sequence of n items from a given sequence of text or speech.
-
These phrases often appear together in fixed patterns such as “systems of innovation,” “cease and desist,” or “commander in chief.”
-
These combinations of phrases are also called collocations, as their overall meaning is more than the sum of their parts.
N-grams
-
rectangular data structure with terms as the rows and documents as the columns
-
Sparsity: zero cells
-
Document feature matrix in quanteda
Term Document Matrix
Computer-aided Text Analysis
-
Searches and information retrieval
-
Clustering and text categorization
-
Text summarization
-
Machine translation
Computer-aided Text Analysis
-
Searches and information retrieval
-
Systematic literature review
-
Retrieve relevant publications
-
Computer-aided Text Analysis
-
Clustering and text categorization
-
Topic modeling
-
Discovering most important words and phrases
-
Computer-aided Text Analysis
-
Text summarization
-
produce category-sensitive text summaries and annotations on large-scale document collections.
-
Computer-aided Text Analysis
-
Machine translation
-
provides quick insights into docu- ments written in other languages.
-
Text Mining
Text mining refers to the practice of extracting useful analytic information from corpora of text.
- Saltz and Stanton 2018
Natural language processing (NLP)
Natural language processing (NLP) combines linguistics and artificial intel- ligence (AI) to enable computers to understand human or natural language input.
- Krish Krishnan and Shawn P. Rogers 2015
Text Mining vs. NLP
Text mining looks for patterns in large data sets. Natural Language Processing (NLP) is more sophisticated on studying how machines can be programmed to digest and make sense of human language.
Approaches in Text Mining
-
Bag of words
-
Topic modeling
-
automated classification and clustering
-
dimensionality reduction
Topic Modeling
-
Subfield of natural language processing and machine learning
-
Topics are distributions over words
Topic Modeling

Technology Business Entertainment
Gibbs Sampling for Topic Models

Gibbs Sampling for Topic Models
-
Gibbs sampling works at the word level to discover the topics that best describe a document collection. Each word is associated with a single topic, explaining why that word appeared in a document.
-
Posterior inference
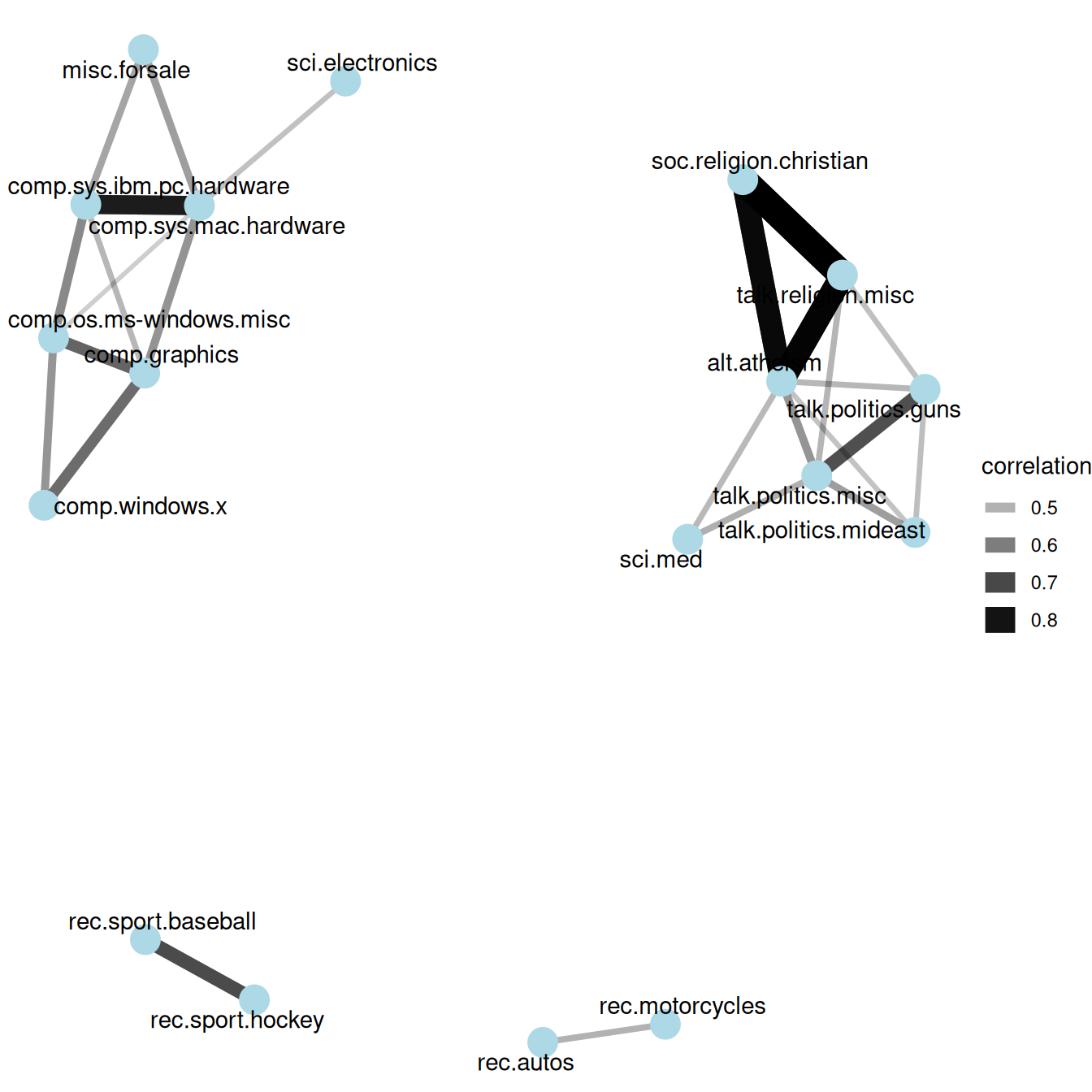
A network of Usenet groups based on the correlation of word counts between them
Silge, Julia. 2019. Text Mining in R
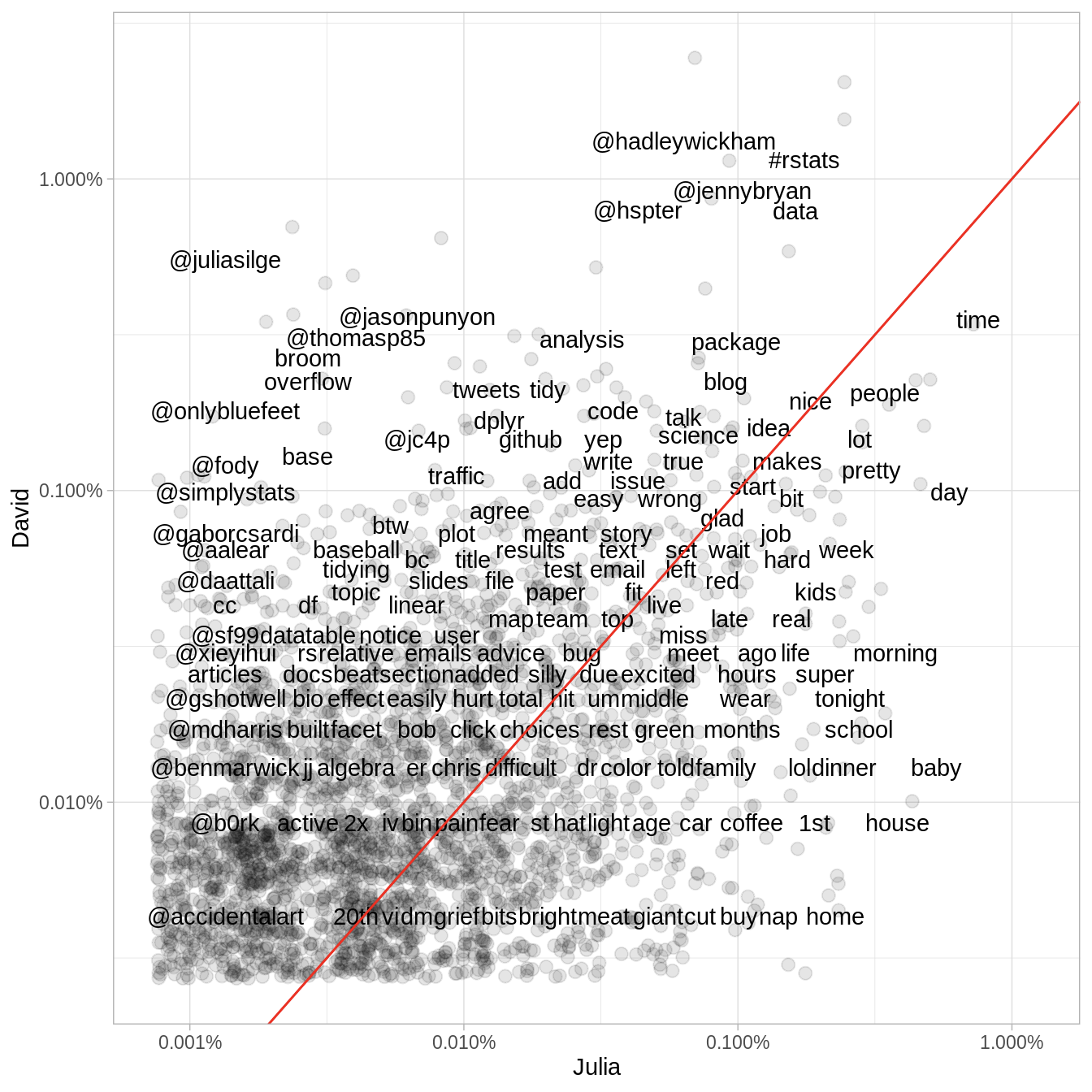
Comparing the frequency of words used by Twitter users
Silge, Julia. 2019. Text Mining in R
Further Reading

Aggarwal, C.C. and Zhai, C. eds., 2012. Mining text data. Springer Science & Business Media.
Ignatow, G. and Mihalcea, R., 2016. Text Mining: A Guidebook for the Social Sciences. Sage Publications.
Further Reading

Grimmer, Justin, Margaret E. Roberts, and Brandon M. Stewart. Text as data: A new framework for machine learning and the social sciences. Princeton University Press, 2022.
Workshop in RStudio
Objective:
-
Access and analyze unstructured data
-
Be familiar with word clouds
-
Apply R packages to do basic text mining
Workshop in RStudio
Workflow:
-
Text data
-
Text Preprocessing
-
Wordcloud
-
N-grams
Workshop in RStudio
R class:
-
Definition for the data object structure
-
Classes use basic data types (e.g. numbers) to build up more complex data structure
-
Classes reference functions
-
Examples: list, corpus, igraph