Does Misinformation Erode Political Trust in Autocracy? –
Evidence from the Shuanghuanglian Incident
Yang Zhang
Bin Yu
Prepared for discussion at the MPSA Annual Meeting, April 5th, 2024.
Discussion:
Discussant:
Karl Ho
University of Texas at Dallas
Summary
This study examines the impact of misinformation on political trust in an authoritarian regime, using China's response to the COVID-19 pandemic as a case study. Specifically, it focuses on the Shuanghuanglian (SHL, in Chinese 双黄连) incident, where a traditional Chinese remedy was mistakenly promoted as effective against COVID-19 by state media. The research findings are primarily based on the analysis of 1,420 posts and 386,000 reposts on Sina Weibo and comparison of human coded data with some classification algorithms.
Summary
The study discovered two significant behavioral patterns among Chinese netizens:
- Credibility of Government Information: Approximately 40% of netizens initially believed in the efficacy of SHL following the government's endorsement. However, another 40% were skeptical, indicating a population of critical citizens alongside the gullible "xiao fenhong 小粉紅" or "Little Pinks."
- Blame Allocation: Despite the involvement of state media in spreading misinformation, many netizens did not blame the government. Instead, they attributed the spread of misinformation to experts, businesses, commercial interests, and the media.
Summary
These findings suggest that misinformation can affect political trust in an autocracy, but the public's reaction and attribution of blame can be complex and varied.
- Apprehension of criticism of government in Weibo is understandable. Yet, the skepticism of government endorsed agencies like media, pharmaceutical companies can be used as proxy of erosion of trust.
- The findings challenge the notion that misinformation uniformly decreases trust in government in authoritarian contexts. The existence of a significant number of critical citizens suggests a nuanced public perception of governmental trustworthiness.
Summary
- Additionally, the tendency to blame actors other than the state for misinformation highlights the complexity of trust dynamics and the potential for the government to deflect accountability.
Suggestions
Contextualize with comparison: Cite comparative data from another similar studies can validate the findings, helping to understand the COVID effect and variable of interests in public health domain.
Usually the original text qualitative analysis is among the most interesting parts in social media analysis. Google translate some selected text for illustration?
More analyses in works in appendix? I believe the authors have done more than reported in findings and conclusion.
-
How to improve human coded classification?
Build dictionary to prepare machine assisted coding
GPT? Program prompts to have ChatGPT or Copilot to help classify (Argyle et al 2023 Political Analysis).
Suggestions
-
Include more implications and observations in conclusion. How much future research can be done in understanding netizen (or citizen indirectly) behaviors when responding to misinformation on one hand and government information/policies on the other.
Suggestions
-
Go beyond unsupervised learning methods. Estimate models of reposts data and if possible sentiments, which could be very illuminating. Unsupervised learning is very informative in hypothesis seeking process. How much this research will inform:
-
Better data collection or measurement (topics (e.g. how homogeneous), sentiments, government supported weibo activism (i.e. little pinks), civilian opinion (e.g. check out singletons)
-
Next stage of social media analysis using comparative approach (topics and temporal)
-
Substantive analysis of public trust on government and other organization (e.g. media, pharma companies) endorsed by governments.
-
Suggestions
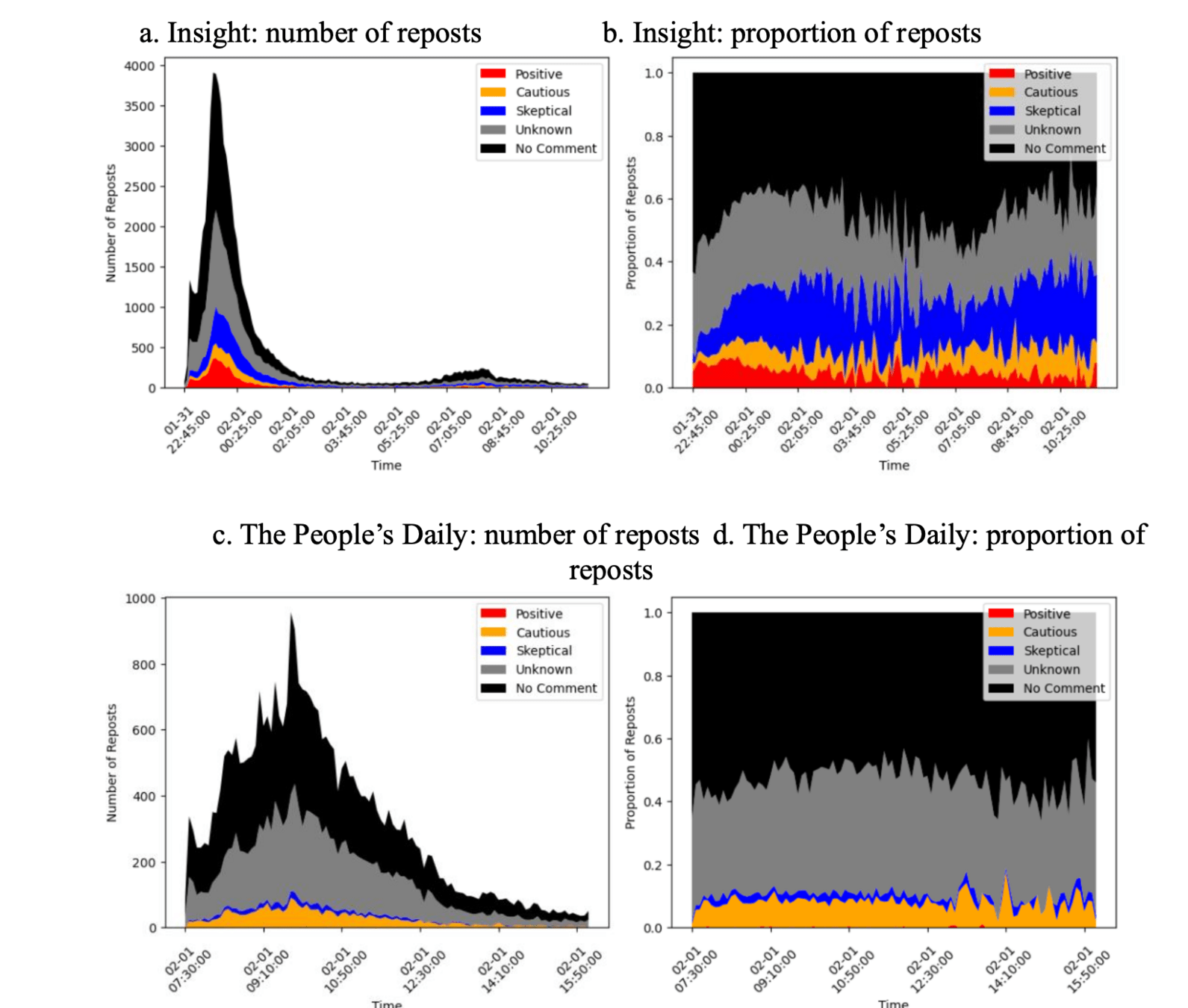
Suggestions
Suggestions
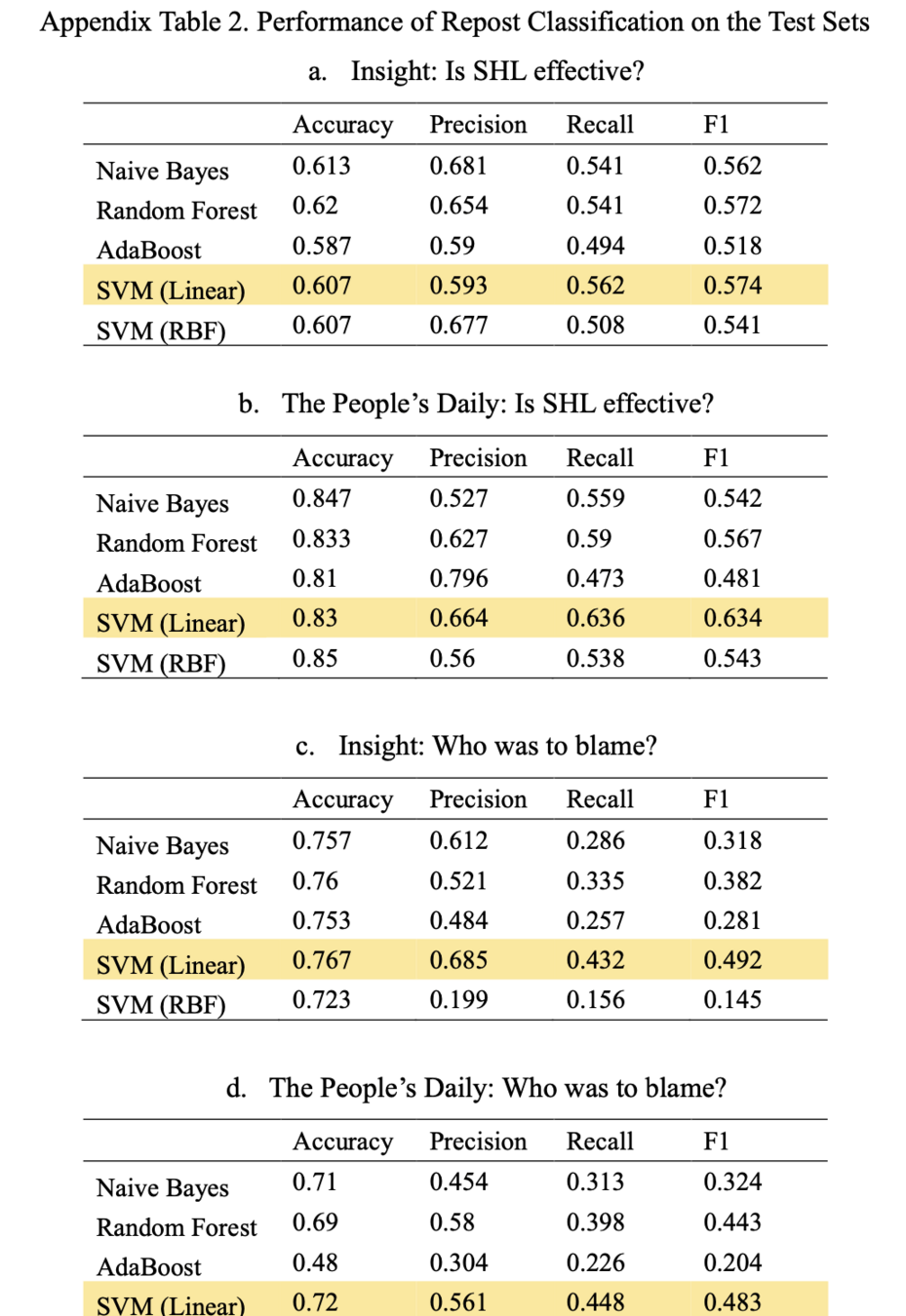
Suggestions
Notes: For every labelling task, the size of the training set is 1800, and the size of the test set is 300.
The ensemble classifiers of Random Forest and AdaBoost were trained with 100 estimators.
Unweighted means of performance metrics are reported.
Suggestions: Future research
-
Hypothesis seeking and building
-
Focus on one variable (e.g. skepticism)
-
How much skepticism can be further analyzed and modeled?
-
Time series models in the short-lived development (by hour or minutes)?
-
How skepticism develops over time?
-
Deletion of posts?
-
-
-
Much to be mined with the Weibo data.