Knowledge Mining
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Introduction
Illustration: Dimensionality of data
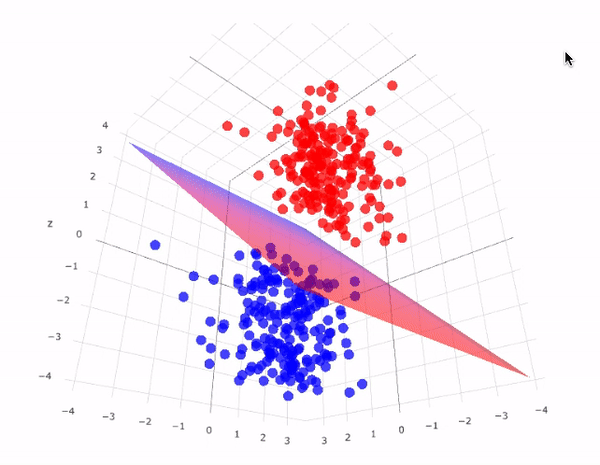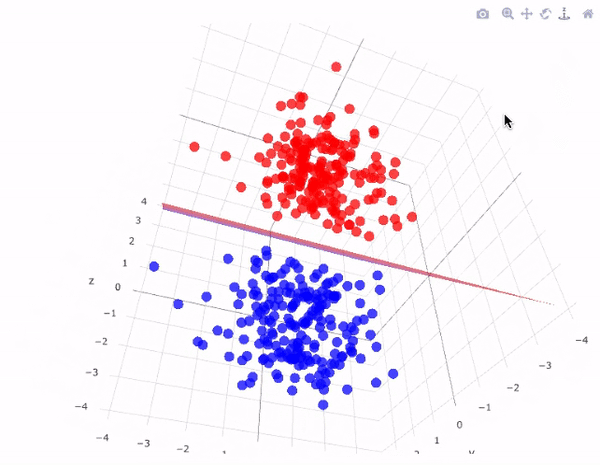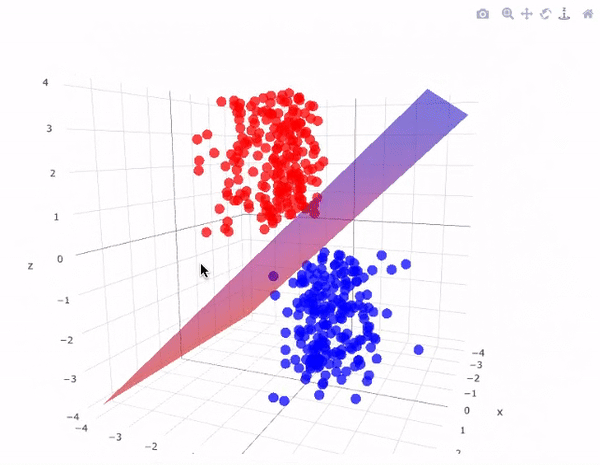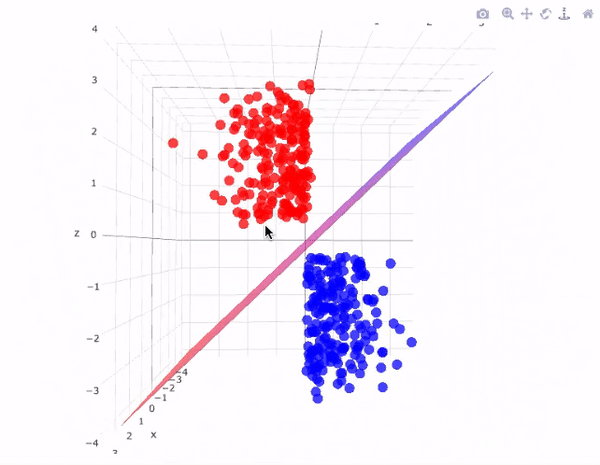
Illustration: Support Vector Machines
Overview
-
What is Knowledge Mining?
-
Knowledge Discovery + Data Mining
-
Statistics and Machine Learning
-
AI Knowledge Mining
-
-
Statistical modeling: the two cultures
-
Conventional statistical methods and machine learning
-
Statistical/Machine Learning methods
What is Knowledge?
Knowledge is experience. Everything else is just information.
- Albert Einstein
What is Knowledge?
Knowledge is considered as a collection of experience, appropriate information and skilled insight
which offers a structure for estimating and integrating new experiences and information.
What is Knowledge?
Knowledge's dynamic nature and relationship with experience and information go beyond mere facts, incorporating understanding, context, and the ability to apply information.
What is Knowledge in Epistemiology?
| Type of Knowledge | Description | Example |
|---|---|---|
| Propositional Knowledge (knowledge-that) | Theoretical knowledge of facts that can be expressed in declarative sentences | "The Earth orbits the Sun" |
| Procedural Knowledge (knowledge-how) | Practical skills or abilities | Knowing how to ride a bicycle |
| Knowledge by Acquaintance | Direct familiarity or awareness gained through experience | Knowing what the taste of chocolate is like |
| Logical Knowledge | Understanding of logical principles and relations | Knowing that if A implies B, and B implies C, then A implies C |
| Semantic Knowledge | Knowledge of the meanings of words and concepts | Understanding what the word "democracy" means |
| Empirical Knowledge | Knowledge derived from sensory experience and observation | Knowing that water boils at 100°C at sea level |
What is Knowledge Mining?
Knowledge mining is an emerging discipline in artificial intelligence (AI) that uses a combination of intelligent services to quickly learn from vast amounts of information. It allows organizations to deeply understand and easily explore information, uncover hidden insights, and find relationships and patterns at scale.
What is Knowledge Mining?
-
Knowledge Discovery + Data Mining
-
Wei et al. (2003):
-
Knowledge discovery refers to the overall process of discovering useful knowledge from data
-
Data mining refers to the extraction of patterns from data.
-
What is Knowledge Mining?
-
Knowledge discovery can be performed on structured databases
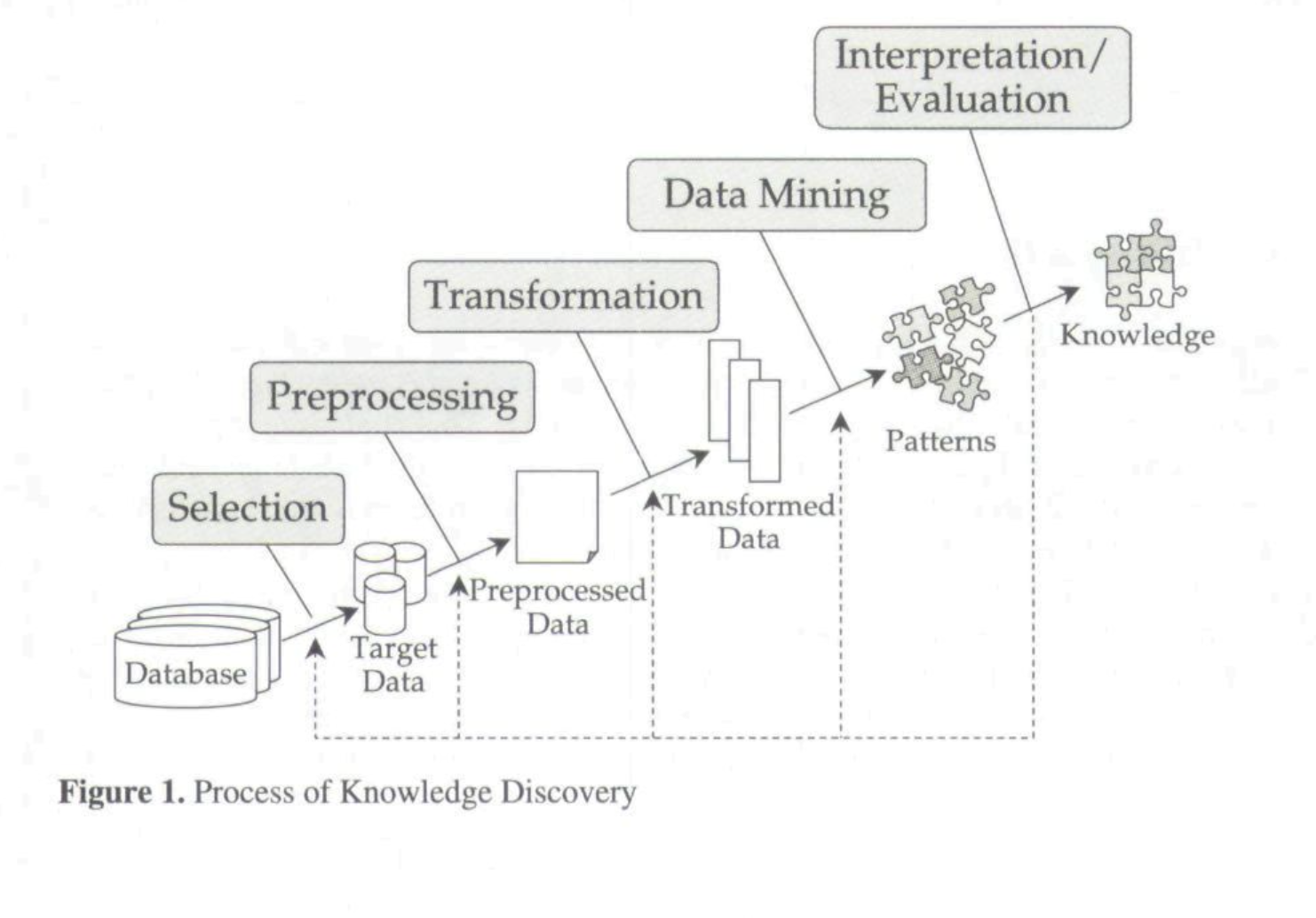
Source: Wei, Chih-Ping, Selwyn Piramuthu, and Michael J. Shaw. "Knowledge discovery and data mining." In Handbook on Knowledge Management, pp. 157-189. Springer, Berlin, Heidelberg, 2003.
What is Knowledge Mining?
-
Data mining generally refers to the methods or techniques used to identify the patterns in data,
-
It can be broadly structured into several categories:
-
classification
-
clustering
-
dependency analysis
-
text mining
-
What is Knowledge Mining?
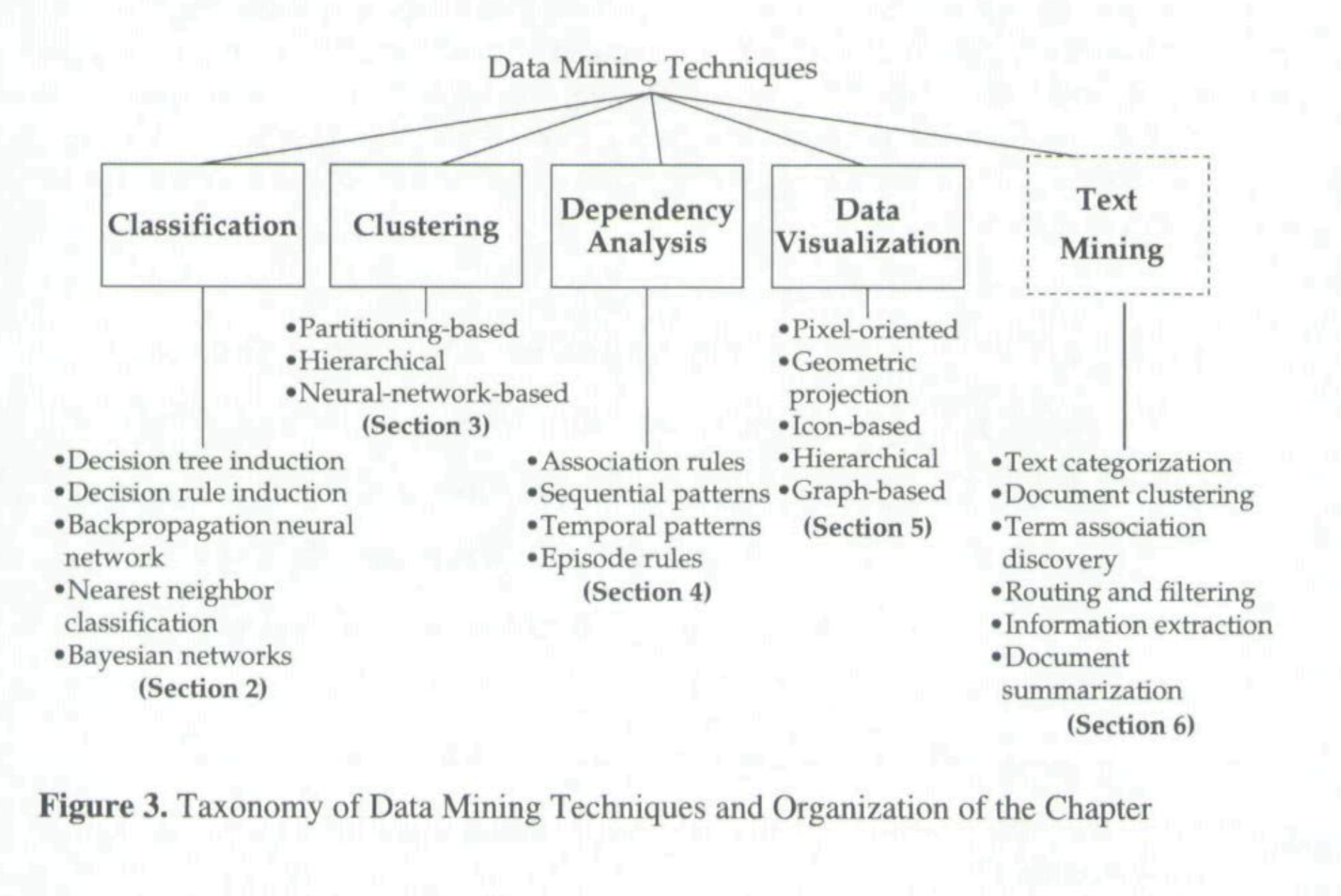
Source: Wei, Chih-Ping, Selwyn Piramuthu, and Michael J. Shaw. "Knowledge discovery and data mining." In Handbook on Knowledge Management, pp. 157-189. Springer, Berlin, Heidelberg, 2003.
What is Knowledge Mining?
-
Both classes of methods are subsumed under Machine Learning now
-
More generally under Unsupervised Machine Learning
-
Pattern recognition
-
Group/class identication
-
Hypothesis formation (vs. Hypothesis confirmation)
-
Key milestones in the evolution of knowledge mining
1990s: Emergence of data mining and knowledge discovery in databases (KDD)
2000s: Integration of text mining and natural language processing techniques
2010s: Rise of big data analytics and scalable machine learning algorithms
2020s: Incorporation of deep learning and large language models
Key aspects of knowledge mining
Content extraction and understanding from various data types (text, images, audio, video)
Application of advanced natural language processing and machine learning techniques
Emphasis on discovering actionable knowledge rather than just patterns
Integration with knowledge representation systems like ontologies and knowledge graphs
Bonferroni's principle
(roughly) if you look in more places for interesting patterns than your amount of data will support, you are bound to find crap.
- Rajaraman A., Leskovec J. and Ullman J. Mining of Massive Datasets
Today we live in a data rich, information driven, knowledge strained, and wisdom scant world.
- Graham Williams 2021
- Rajaraman A., Leskovec J. and Ullman J. Mining of Massive Datasets
Data mining overlaps with:
- Databases: Large-scale data, simple queries
- Machine learning: Small data, Complex models
- CS Theory: (Randomized) Algorithms
Different cultures:
- To a Database person, data mining is an extreme form of analytic processing – queries that examine large amounts of data
- Result is the query answer
- To a Machine Learning person, data-mining is the inference of models
- Result is the parameters of the model
Data Mining and Machine Learning
- association rules
- recursive partitioning or decision trees, including CART (classification and regression trees) and CHAID (chi-squared automatic interaction detection), boosted trees, forests, and bootstrap forests
- multi-layer neural network models and “deep learning” methods
- naive Bayes classifiers and Bayesian networks
- clustering methods, including hierarchical, k-means, nearest neighbor, linearand nonlinear manifold clustering
- support vector machines
- “soft modeling” or partial least squares latent variable modeling
Data Mining methods
What is machine learning?
Field of study that gives computers the ability to learn without being explicitly programmed.
- Arthur Samuel 1959

A computer can be programmed so that it will learn to play a better game of checkers than can be played by the person who wrote the program.
Programming computers to learn from experience should eventually eliminate the need for much of this detailed programming effort.
What is machine learning?
The ultimate goal of data modeling is to explain and predict the variable of interest using data. Machine learning is to achieve this goal using computer algorithms in particular to make the prediction and solve the problem.

Source: Tom Mitchell website
According to Carnegie Mellon Computer Science professor Tom M. Mitchell,
"Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience."
What is machine learning?
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”
Source: Tom Mitchell website
Study the past if you would define the future.
– Confucius
Tom Mitchell. 1997. Machine Learning, McGraw Hill.
What is machine learning?
Machine learning is a science of the artificial. The field's main objects of study are artifacts, specifically algorithms that improve their performance with experience.
- Langley, 1996
Machine learning is programming computers to optimize a performance criterion using example data or past experience.’
- Alpaydin, 2004
What is machine learning?
Machine learning is an area of artificial intelligence concerned with the study of computer algorithms that improve automatically through experience. In practice, this involves creating programs that optimize a performance criterion through the analysis of data.
- Sewell, 2006
What is machine learning?
To statisticians, the “improve through experience” part is the process of validation or cross validation. Learning can be done through repeated exercises to understand data.
What is machine learning?
Machine learning involves having computer or statistics programs do repeated estimations, like human learns from experience and improve actions and decisions. This is called the training process in machine learning.
Statistics, Knowledge Mining and Machine Learning
Statistics refresher
Statistics:
- Find and test data (data production and collection)
- Made data (surveys, experiments, interviews) based on theory and hypotheses
- Found data (web data, social data, machine generated data) from all sources
- Make data ready for analysis (data management)
- Explore data (means, variances, distribution) - Descriptive statistics
- Explain data (correlation, cross-tabulation, regression) - Inferential statistics
Thought exercise
Potential applications of knowledge mining in your field of study.
Consider:
-
What types of data sources could be mined?
-
What kind of knowledge or insights would be valuable to extract?
-
What challenges might arise in applying knowledge mining to your field?
Parametric vs. Non-parametric models
-
Sample and population
-
Generalization
-
Representation
Leo Breiman

1928 – 2005
-
Statistical Modeling: The Two Cultures
-
CART (Classification and Regression Trees)
What can Machine Learning do and do better?
Machine Learning can do:
- Prediction
- Classification
- Give useful information for problem solving and decision making

Machine Learning and Conventional statistical methods
-
Statistics: testing hypotheses
-
Machine learning: finding the right hypothesis
-
Overlap:
Decision trees (C4.5 and CART)
Nearest-neighbor methods -
Bridging the two:
Most machine learning algorithms employ statistical techniques
Statistical Modeling:
The Two Cultures
Leo Breiman 2001: Statistical Science
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
Theory:
Data Generation Process
Data are generated in many fashions. Picture this: independent variable x goes in one side of the box-- we call it nature for now-- and dependent variable y come out from the other side.

Theory:
Data Generation Process
Data Model
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
Response Variable= f(Predictor variables, random noise, parameters)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
Theory:
Data Generation Process
Data Model
The values of the parameters are estimated from the data and the model then used for information and/or prediction.

Theory:
Data Generation Process
Algorithmic Modeling
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function f(x)-an algorithm that operates on x to predict the responses y.
The goal is to find algorithm that accurately predicts y.
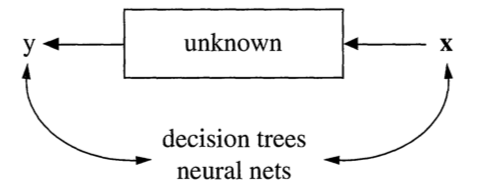
Theory:
Data Generation Process
Algorithmic Modeling
Source: https://www.mathworks.com
Machine Learning and Conventional statistical methods

Source: Attewell, Paul A. & Monaghan, David B. 2015. Data Mining for the Social Sciences: an Introduction, Table 2.1, p. 27
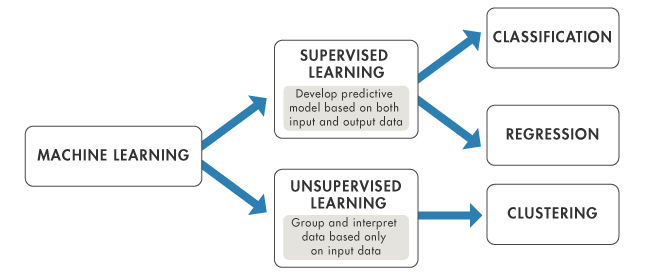
Machine learning methods
| Regression | Classification | Clustering | Q-Learning |
| Linear regression | Logistic regression | - K-Means Clustering | State Action Reward State Action (SARSA) |
| Polynomial regression | K-Nearest Neighbors | - Hierarchical Clustering | Deep Q-Network |
| Support vector regression | Support Vector Machines | Dimensionality Reduction | Markov Decision Processes |
| Ridge Regression | Kernal Support Vector Machines | Principal Component Analysis | Deep Deterministic Policy Gradient (DDPG) |
| Lasso | Naïve Bayes | Linear Discriminant Analysis | |
| ElasticNet | Decision Tree | Kernal PCA | |
| Decision tree | Random forest | ||
| Random forest |
| Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|
Data Mining vs. AI Knowledge Mining
| Aspect | Traditional Data Mining | AI Knowledge Mining |
|---|---|---|
| Data Handling | Primarily works with structured data, requiring preprocessing for unstructured formats. | Excels at processing both structured and unstructured data (e.g., text, images) using AI techniques like NLP and OCR[1][2]. |
| Techniques | Relies on statistical methods such as clustering, classification, and regression. | Employs advanced AI techniques like machine learning, deep learning, and neural networks for nuanced insights[1][4]. |
| Adaptability | Static models that do not evolve after deployment. | Dynamic models that adapt and improve over time through machine learning[3][5]. |
| Complexity of Insights | Identifies straightforward patterns and correlations in data. | Uncovers complex relationships and hidden patterns, offering deeper contextual understanding[1][4]. |
| Automation | Requires significant manual intervention in data preparation and analysis. | Automates many tasks, including knowledge extraction and modeling, reducing human effort[2][1]. |
| Interpretability | Outputs are often easier to interpret due to simpler methodologies. | Outputs can be harder to interpret due to the “black-box” nature of AI models[1][2]. |
Data Mining vs. AI Knowledge Mining
| Aspect | Data Mining | Machine Learning | Knowledge Mining |
|---|---|---|---|
| Purpose | Extracts patterns and insights from large datasets | Develops algorithms that learn from and make predictions on data | Synthesizes and contextualizes information to generate actionable insights |
| Scope | Focuses on discovering patterns and correlations | Emphasizes algorithm development and model training | Goes beyond pattern discovery to represent and apply knowledge |
| Techniques | Uses statistical models and database management tools | Employs various algorithms like neural networks and decision trees | Incorporates AI, NLP, and semantic technologies |
| Data Handling | Works primarily with structured, historical data | Can handle both structured and unstructured data, including real-time | Excels at processing unstructured data and integrating diverse sources |
| Automation | Requires significant human intervention for interpretation | Can automate decision-making processes with minimal oversight | Combines automation with human expertise for knowledge creation |
| Adaptability | Static process following pre-set rules | Algorithms can adapt and improve with new data | Dynamically updates and refines knowledge representations |
| Outcomes | Produces patterns, trends, and correlations | Generates predictive models and classifications | Delivers contextualized insights and strategic intelligence |
| Applications | Business intelligence, market analysis | Predictive analytics, image recognition | Strategic decision-making, innovation support |
Machine Learning and Conventional statistical methods
-
Statistics: testing hypotheses
-
Machine learning: finding the right hypothesis
-
Overlap:
Decision trees (C4.5 and CART)
Nearest-neighbor methods -
Bridging the two:
Most machine learning algorithms employ statistical techniques
WRG: Data analytics:
-
Hypothesis generation
-
Hypothesis confirmation
Which one goes first?
Deep Research (OpenAI) vs. DeepSeek
| Feature | Deep Research | DeepSeek |
|---|---|---|
| Real-time internet search | Can search and interpret information in real-time | Hybrid search engine and knowledge base |
| Processing time | 5 to 30 minutes | Efficient processing speed |
| Accuracy | 26.6% accuracy on 'Humanity's Last Exam' | Excels in mathematical and technical tasks |
| Citation and documentation | Clear citations and thinking process summary | Can self-correct and research sources |
| Accessibility | Limited to specific paid tiers with usage caps | Free and open-source, no prompt limitations |