Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Text Analytics Applications
Prepared for Statistics Seminar hosted at the Department of Mathematical Sciences, School of Natural Sciences & Mathematics, University of Texas at Dallas, October 22, 2021
-
Karl Ho is:
- Associate Professor of Instruction at University of Texas at Dallas (UTD) School of Economic, Political and Policy Sciences (EPPS)
- Co-founder of the UTD Social Data Analytics and Research program (SDAR)
- Founder of DataGeneration.org
- Author of Data Programming
- Co-Principal Investigator of the Hong Kong Election Study project
- Website: karlho.com (talks, lecture, publications)
Speaker bio.
-
What is text data? Why it matters?
-
Text Analytics Workflow
-
Unsupervised learning methods using text data including pattern detection and visualization
-
Supervised learning models using text data
-
Latest developments and applications using text data
-
Illustrations
Overview
What is Text Data?
Text data refer to any documents or corpus in text forms.
-
Structured data refers to text with a high degree of organization, such that inclusion in a relational database is seamless and readily searchable.
-
Unstructured data do not have a pre-defined data model or is not organized in a pre-defined manner.
The TEXT data type stores any kind of text data. It can contain both single-byte and multibyte characters that the locale supports.
- IBM
What is Text Data?
Why Text Data Matters?
Text data can provide information on:
- Individuals
- Grouping (Topic modeling)
- Preferences (Recommendation system)
- Positions (Social network analysis, Ideological scaling)
- Sentiments
- Organizations
- Organizational behaviors (e.g. party manifestos, company policies)
- Governments
- State strategy
- Policy shifts
- Administrations
Why Text Data Matters?
Data Generation: Text data are human records
- Explosive growth of text data in size
Source: BusinessWire
Why Text Data Matters?
Data Generation: Text data are human records
- Big data are more and more generated by machines but driven by human activities.
- Text data are multiplied by human languages via IoT.
- Human languages:
- Dialogues in:
- Text
- Speeches
- Gestures (body language)
- Movements
- Dialogues in:
Why Text Data Matters?
Data Generation: Text data are human records
- Because of size and growth, it is necessary to have computer aided reading, comprehension, organization and modeling.
- Imagine:
- how much time it takes to read decades of government report?
- how much it costs to misunderstand an important message by terrorist?
- how many lives can be risked by misreading a government's military action?
Text mining analytics: workflow
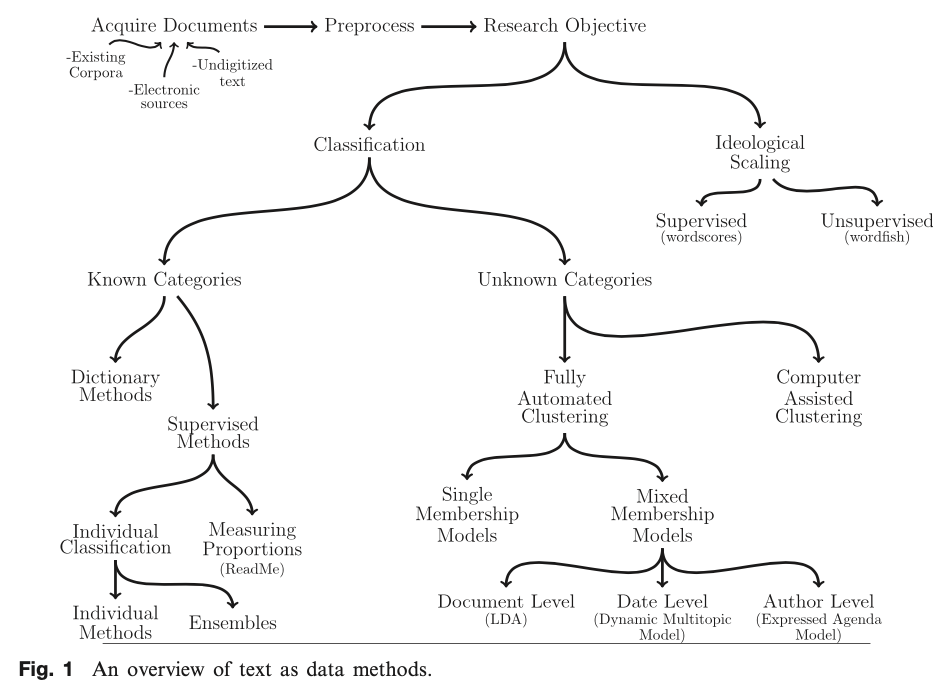
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Text mining analytics: workflow
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Text mining analytics: workflow
Grimmer, Justin, and Brandon M. Stewart. 2013. “Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts.” Political Analysis 21(3): 267–97.
Supervised
Unsupervised
-
Webpages
-
PDF
-
Social media:
-
Twitter
-
Reddit
-
YouTube
-
Collecting text data
-
API
- Social media API's
- Government organizations (e.g. Congress)
- Non-API
- search-based scraping
- twint
- web scraping
- search-based scraping
Methods collecting text data
Network structure (Legislative Yuan)
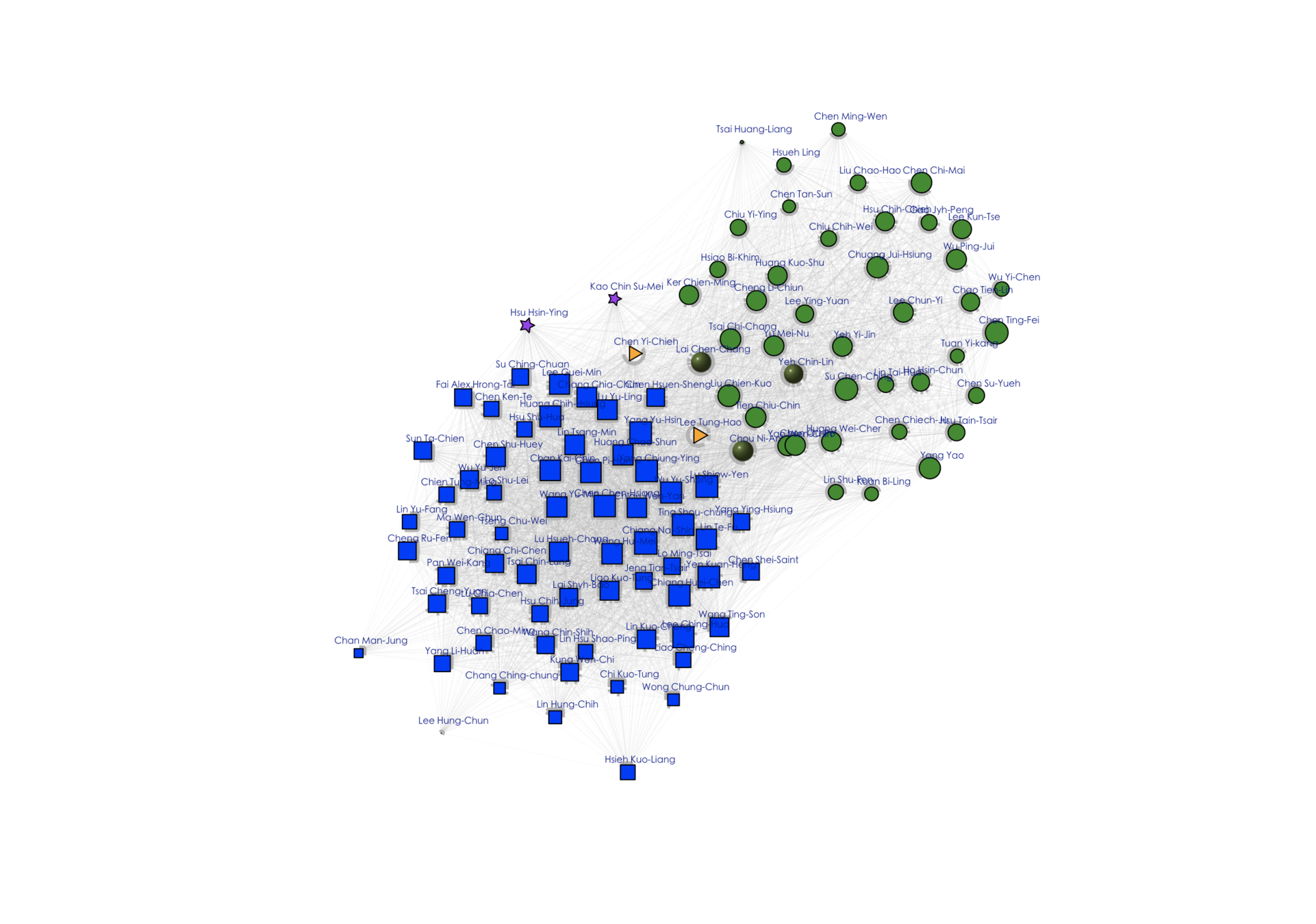
Network structure (Legislative Yuan)
- Colors and shapes represent members of parties.
- Size indicates importance in terms of number of bills and mobilization of cosigners
- Positions indicate distances from other networks and within own network.
Network structure (Legislative Yuan)
Network structure (Community)
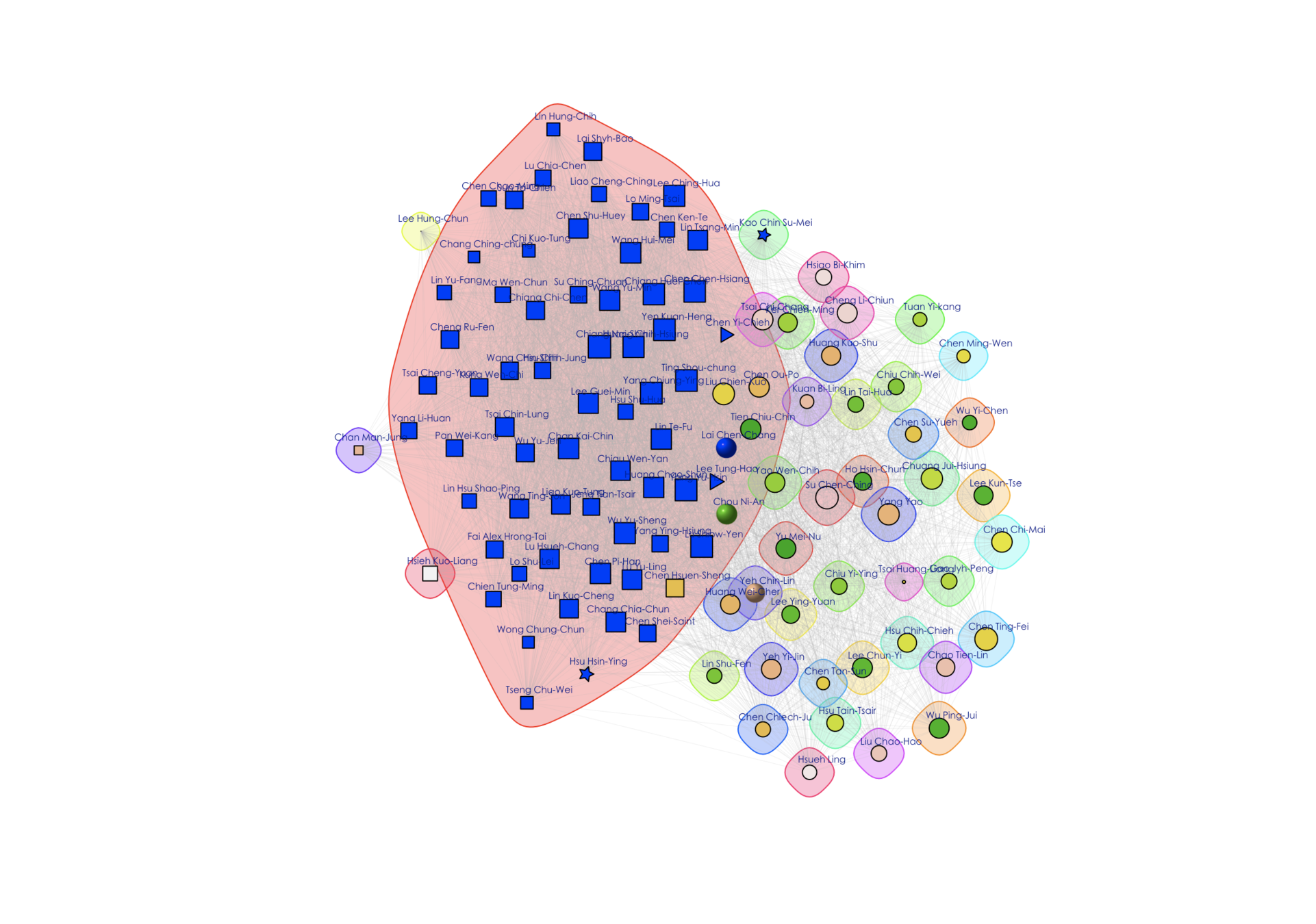
Network structure (Community)
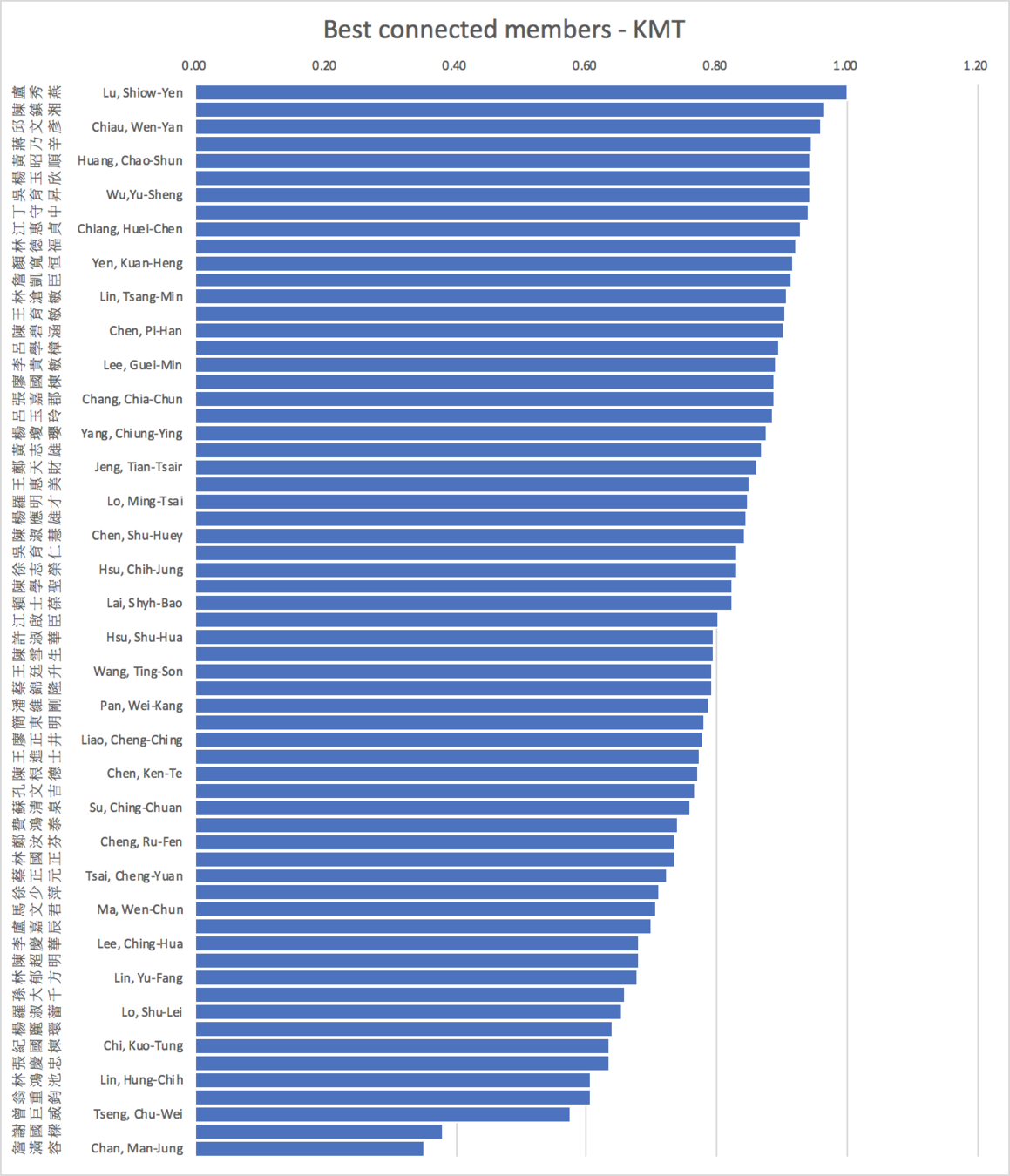
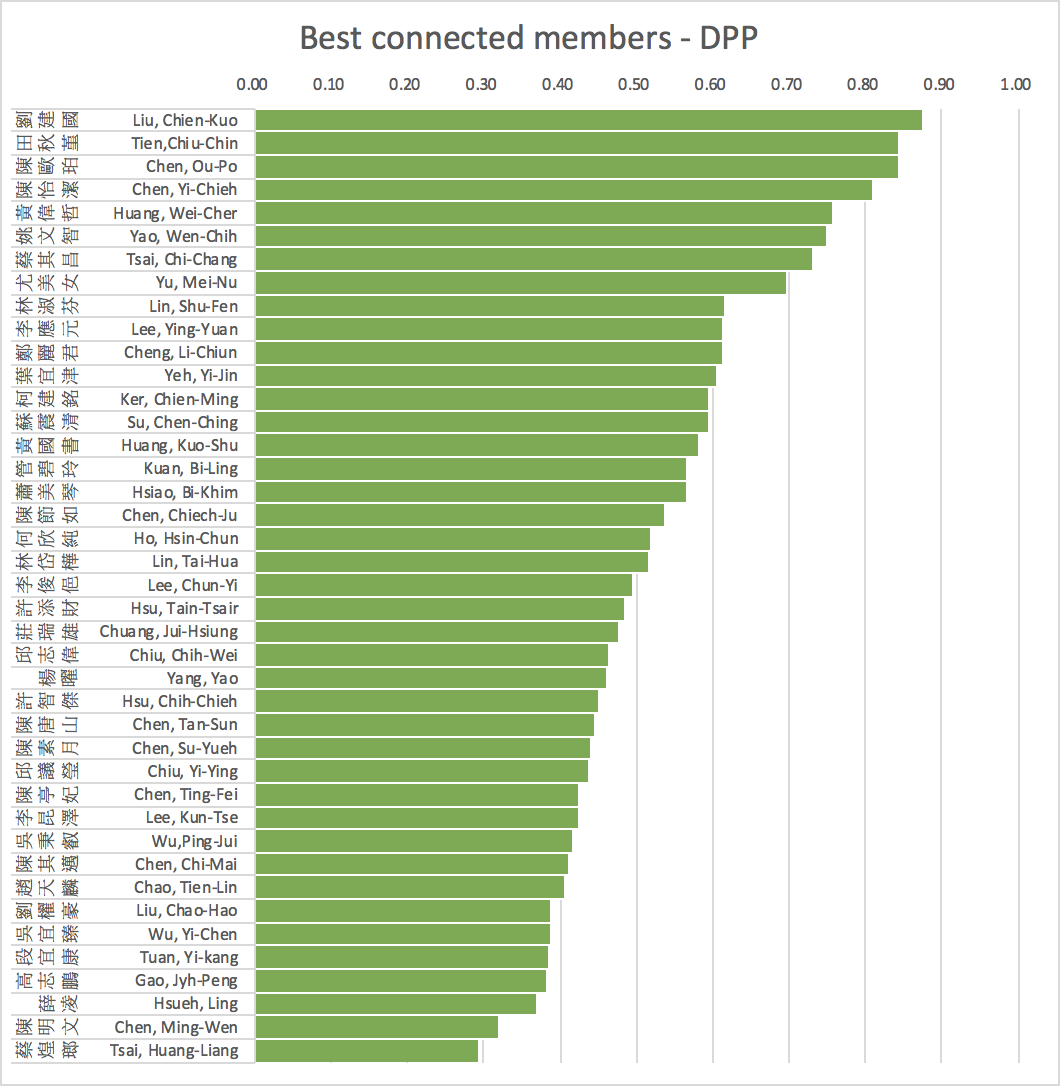
average=0.79 s.d.=0.13 skewness= -1.12
average=0.54 s.d.=0.15 skewness=0.72
Corpus (plural Corpora) - A set of multiple similar documents is called a corpus.
Corpus
-
The Brown University Standard Corpus of Present-Day American English, or just the Brown Corpus, is a collection of processed documents from works published in the United States in 1961.
-
The Brown Corpus was a historical milestone: it was a machine-readable collection of a million words across 15 balanced genres with each word tagged with its part of speech (e.g., noun, verb, preposition).
Corpus Example: Brown Corpus
-
The British National Corpus (BNC) is a 100 million word collection of samples of written and spoken language from a wide range of sources, designed to represent a wide cross-section of British English from the later part of the 20th century, both spoken and written.
-
The latest edition is the BNC XML Edition, released in 2007.
Corpus example: BNC
-
Monolingual: It deals with modern British English, not other languages used in Britain. However non-British English and foreign language words do occur in the corpus.
-
Synchronic: It covers British English of the late twentieth century, rather than the historical development which produced it.
Corpus example: BNC
-
General: It includes many different styles and varieties, and is not limited to any particular subject field, genre or register, containing both spoken and written language examples.
Corpus example: BNC
-
Sample: For written sources, samples of 45,000 words are taken from various parts of single-author texts. Shorter texts up to a maximum of 45,000 words, or multi-author texts such as magazines and newspapers, are included in full. Sampling allows for a wider coverage of texts within the 100 million limit, and avoids over-representing idiosyncratic texts.
Corpus example: BNC
-
The number and scope of documents determine the range of questions that one can ask and the quality of the answers.
-
Too few documents result in a lack of coverage, too many of the wrong kind of documents invite confusing noise.
-
Example: BNC Word Frequencies
Corpus analysis
-
The first step in processing text is deciding what terms and phrases are meaningful.
-
Tokenization separates sentences and terms from each other and creates a bag of words
-
Tokens can be individual word in a text, but also a sentence, paragraph or character.
Tokenization
Term frequency–inverse document frequency (TFIDF)

-
Stop words are a category of words that have limited semantic meaning regardless of the document contents.
-
Such words can be prepositions, articles, common nouns, etc.
-
For example, the words “the”, “to” and “of”, which could account for more than 10 percent of the text.
Stop words
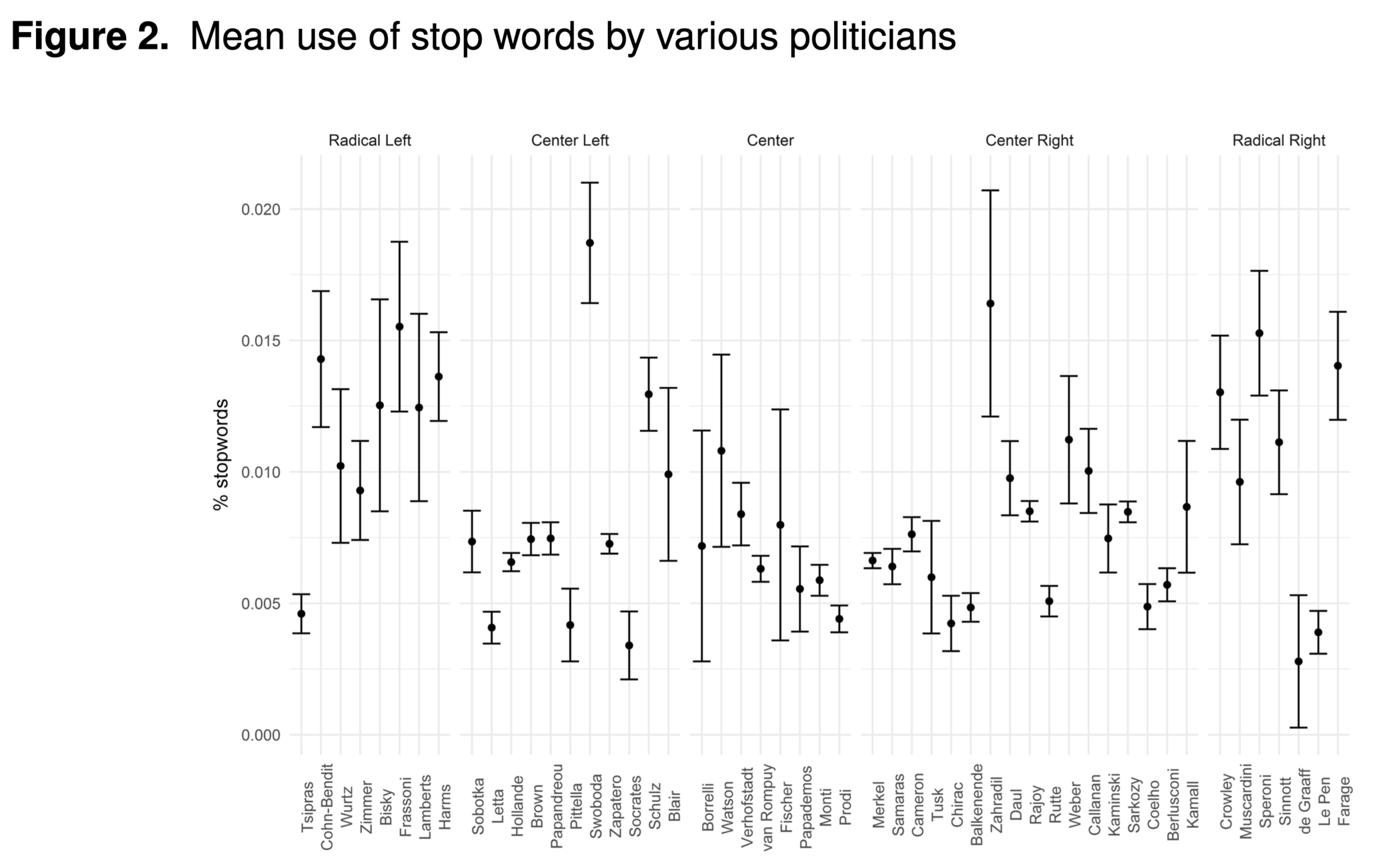
Schoonvelde et al. 2019: taking out stop words is not an ideologically neutral step.
-
Getting the stem of words
Stemming
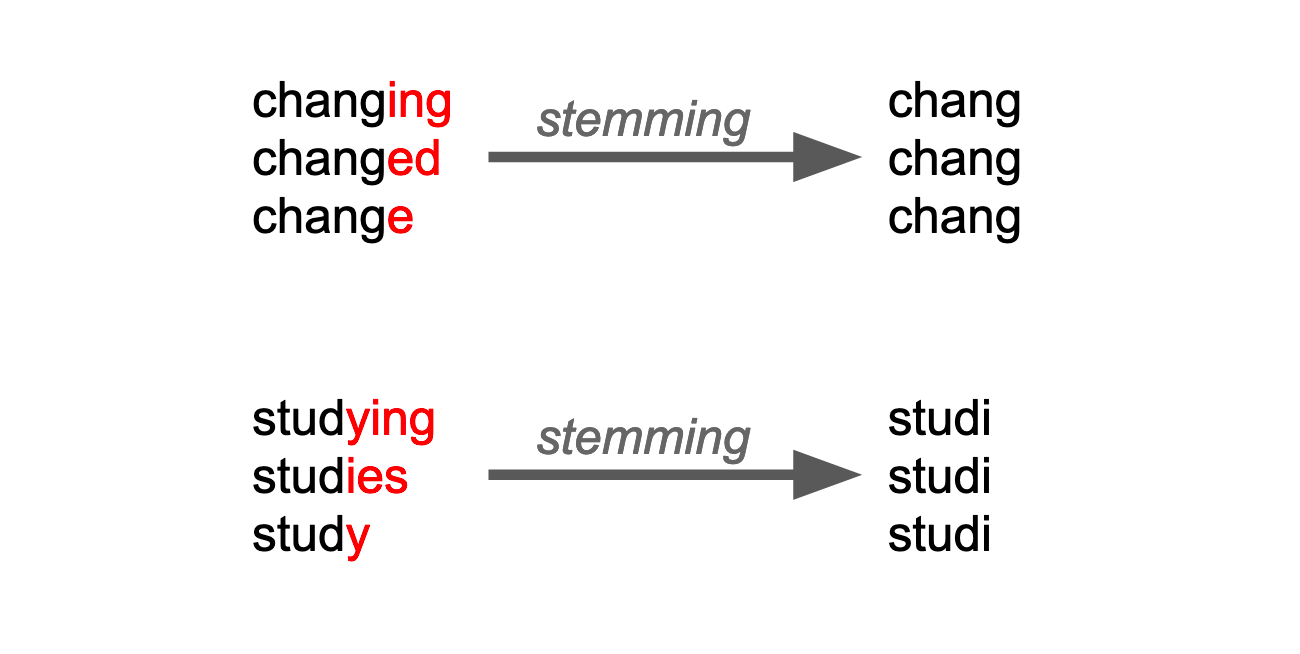
Source: Openclassrooms.com
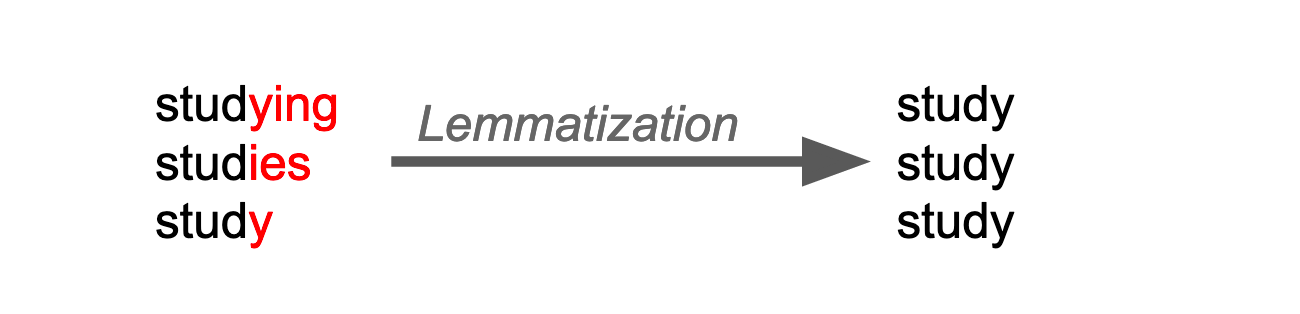
-
Getting the meaningful stem of words
Lemmatization
Source: Openclassrooms.com
-
a contiguous sequence of n items from a given sequence of text or speech.
-
These phrases often appear together in fixed patterns such as “systems of innovation,” “cease and desist,” or “commander in chief.”
-
These combinations of phrases are also called collocations, as their overall meaning is more than the sum of their parts.
N-grams
-
rectangular data structure with terms as the rows and documents as the columns
-
Sparsity: zero cells
Term Document Matrix
-
Rectangular data structure with terms as the rows and documents as the columns
-
TDM is a specific instance of a Document-Feature Matrix (DFM) where "features" may refer to other properties of a document besides terms (quanteda).
-
Sparsity: zero cells
Term Document Matrix
Computer-aided Text Analysis
-
Searches and information retrieval
-
Clustering and text categorization
-
Text summarization
-
Machine translation
Computer-aided Text Analysis
-
Searches and information retrieval
-
Systematic literature review
-
Retrieve relevant publications
-
Computer-aided Text Analysis
-
Clustering and text categorization
-
Topic modeling
-
Discovering most important words and phrases
-
Computer-aided Text Analysis
-
Text summarization
-
produce category-sensitive text summaries and annotations on large-scale document collections.
-
Computer-aided Text Analysis
-
Machine translation
-
provides quick insights into docu- ments written in other languages.
-
Text Mining
Text mining refers to the practice of extracting useful analytic information from corpora of text.
- Saltz and Stanton 2018
Natural language processing (NLP)
Natural language processing (NLP) combines linguistics and artificial intelligence (AI) to enable computers to understand human or natural language input.
- Krish Krishnan and Shawn P. Rogers 2015
Natural language processing (NLP)
NLP helps machines “read” different forms of language (e.g. text, speech) by simulating the human ability to understand a natural language.
Text Mining vs. NLP
Text mining looks for patterns in large data sets. Natural Language Processing (NLP) is more sophisticated on studying how machines can be programmed to digest and make sense of human language.
Approaches in Text Mining
-
Unsupervised
-
Topic modeling
-
Latent Dirichlet Allocation (LDA)
-
Structural Topic Modeling (STM)
-
-
Positional scaling
-
Wordfish
-
-
-
Supervised
-
Dictionary-based
-
Sentiment Analysis
-
Lexicon
-
Dictionary
-
-
Topic Modeling
-
Subfield of natural language processing and machine learning
-
Topics are distributions over words
Topic Modeling

Technology Business Entertainment
Gibbs Sampling for Topic Models

Gibbs Sampling for Topic Models
-
Gibbs sampling works at the word level to discover the topics that best describe a document collection. Each word is associated with a single topic, explaining why that word appeared in a document.
-
Posterior inference
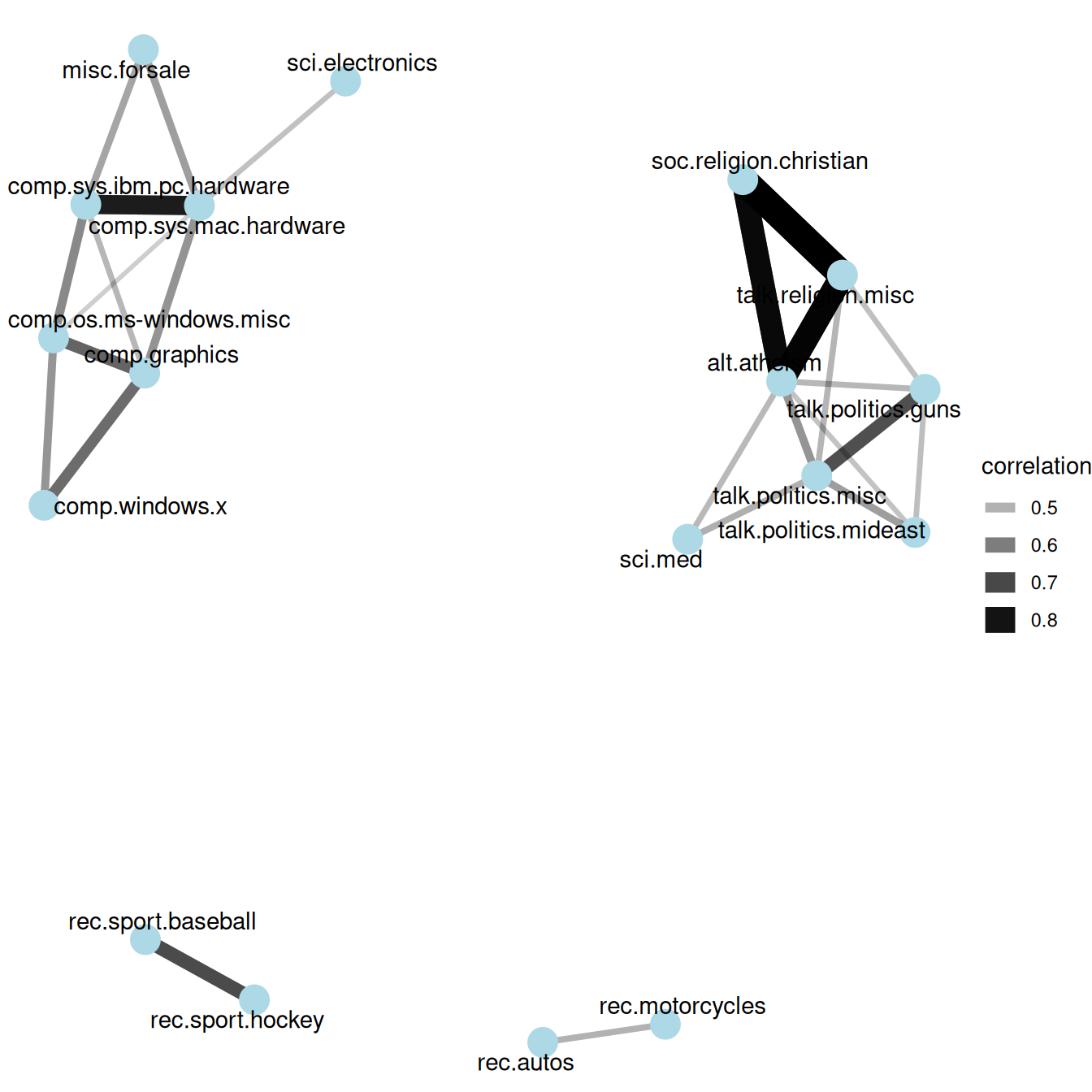
A network of Usenet groups based on the correlation of word counts between them
Silge, Julia. 2019. Text Mining in R
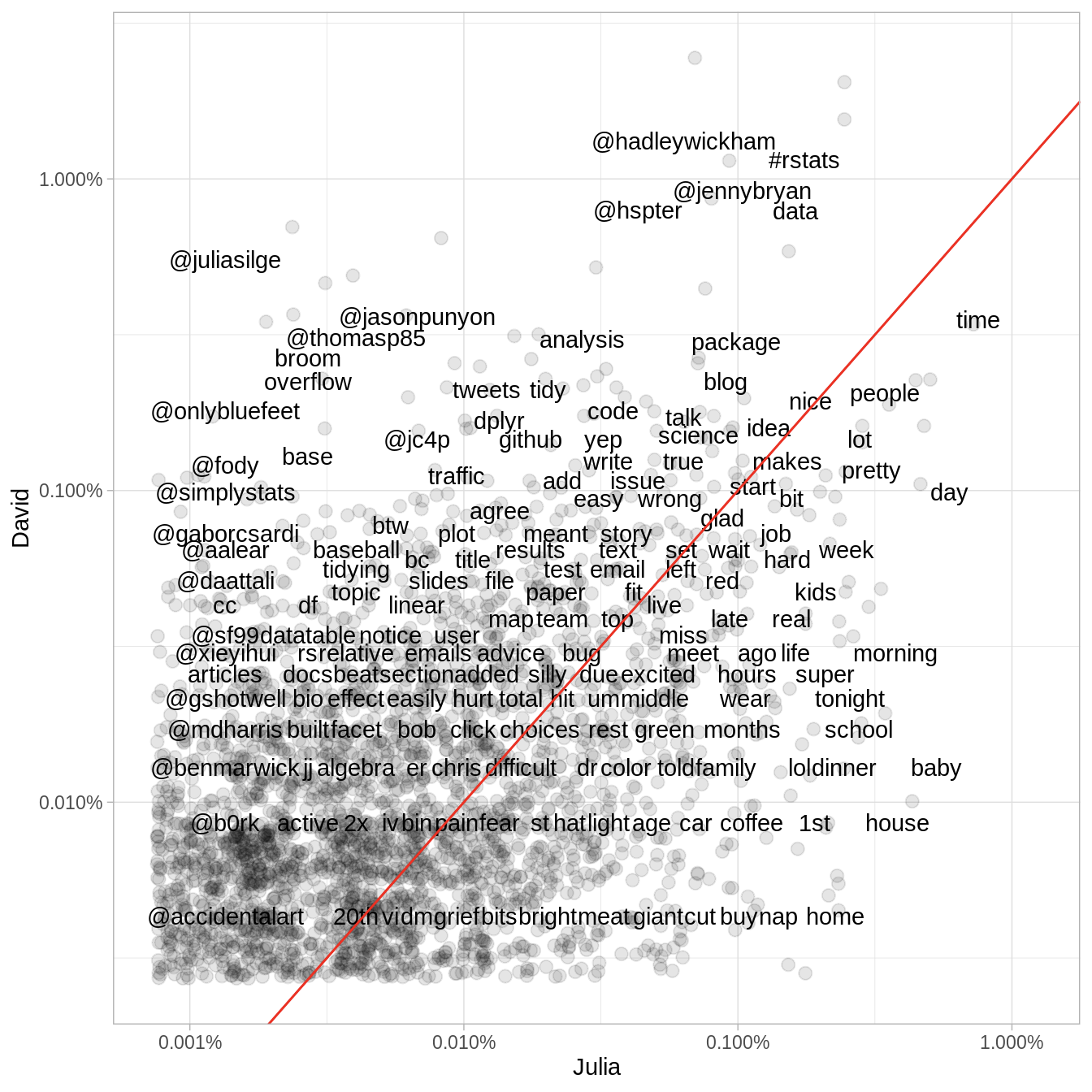
Comparing the frequency of words used by Twitter users
Silge, Julia. 2019. Text Mining in R
beta: per-topic-per-word probabilities

Topic modeling (LDA): China media CGTN's mention about Taiwan in Twitter
beta: per-topic-per-word probabilities
Topic modeling (LDA): China media CGTN's mention about Taiwan in Twitter
beta: per-topic-per-word probabilities
Topic modeling (LDA): China media CGTN's mention about Taiwan in Twitter

beta: per-topic-per-word probabilities
Topic modeling (LDA): China media CGTN's mention about Taiwan in Twitter
Sentiment Analysis
When human readers approach a text, we use our understanding of the emotional intent of words to infer whether a section of text is positive or negative, or perhaps characterized by some other more nuanced emotion like surprise or disgust.
- Silge and Robinson 2017
Sentiment Analysis
We can use the tools of text mining to approach the emotional content of text programmatically. A sentiment is also known as polar or opinion word associated with the sentiment orientation, that is, positive or negative.
Sentiment Analysis
One way to analyze the sentiment of a text is to consider the text as a combination of its individual words and the sentiment content of the whole text as the sum of the sentiment content of the individual words.
Sentiment Analysis
This isn’t the only way to approach sentiment analysis, but it is an often-used approach, and an approach that naturally takes advantage of the tidy tool ecosystem.
Lexicons
The three general-purpose lexicons are
-
AFINN from Finn Årup Nielsen,
-
bing from Bing Liu and collaborators, and
-
nrc from Saif Mohammad and Peter Turney.
Lexicons: AFINN
AFINN wordlist , which has 2477 words and phrases rated from -5 [very negative] to +5 [very positive]. AFINN words is divided into four categories :
-
Very Negative (rating -5 or -4)
-
Negative (rating -3, -2, or -1)
-
Positive (rating 1, 2, or 3)
-
Very Positive (rating 4 or 5 or 6)
Lexicons: Bing
Bing wordlist , named after one of the most cited article on opinion mining. The author is Bing Liu.
-
6,874 words
Hu, Minqing, and Bing Liu. "Mining opinion features in customer reviews." In AAAI, vol. 4, no. 4, pp. 755-760. 2004.
Liu, Bing. 2012. Sentiment analysis and opinion mining. Synthesis lectures on human language technologies, 5(1), pp.1-167.
Lexicons: nrc
NRC - The NRC Emotion Lexicon is a list of English words and their associations with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) and two sentiments (negative and positive). The annotations were manually done by crowdsourcing.
-
5,468 words
Lexicons: Jockers
Matthew L. Jockers (Jockers 2017)
-
10,738 words
-
aims to incorporate emotional shifts in text
-
Classifications: polarity and intensity. scores range from -1 to +1 (continuous)
Lexicons: NRC
get_sentiments("nrc")
# A tibble: 13,901 x 2
word sentiment
<chr> <chr>
1 abacus trust
2 abandon fear
3 abandon negative
4 abandon sadness
5 abandoned anger
6 abandoned fear
7 abandoned negative
8 abandoned sadness
9 abandonment anger
10 abandonment fear
# … with 13,891 more rowsLexicons: bing
get_sentiments("bing")
# A tibble: 6,786 x 2
word sentiment
<chr> <chr>
1 2-faces negative
2 abnormal negative
3 abolish negative
4 abominable negative
5 abominably negative
6 abominate negative
7 abomination negative
8 abort negative
9 aborted negative
10 aborts negative
# … with 6,776 more rowsLexicons: AFINN
get_sentiments("afinn")
# A tibble: 2,477 x 2
word value
<chr> <dbl>
1 abandon -2
2 abandoned -2
3 abandons -2
4 abducted -2
5 abduction -2
6 abductions -2
7 abhor -3
8 abhorred -3
9 abhorrent -3
10 abhors -3
# … with 2,467 more rowsApplications
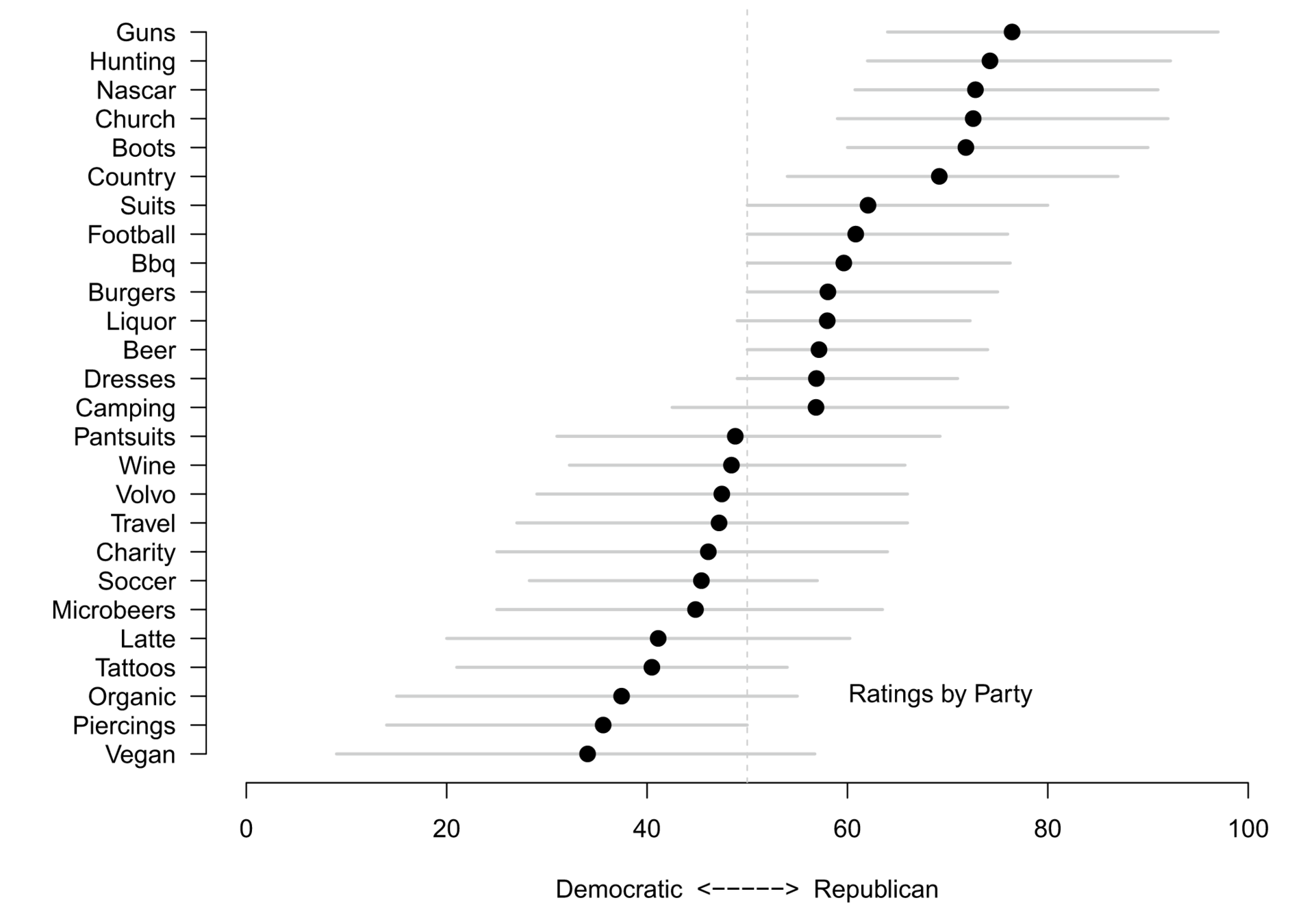
Illustration: use of words by partisans
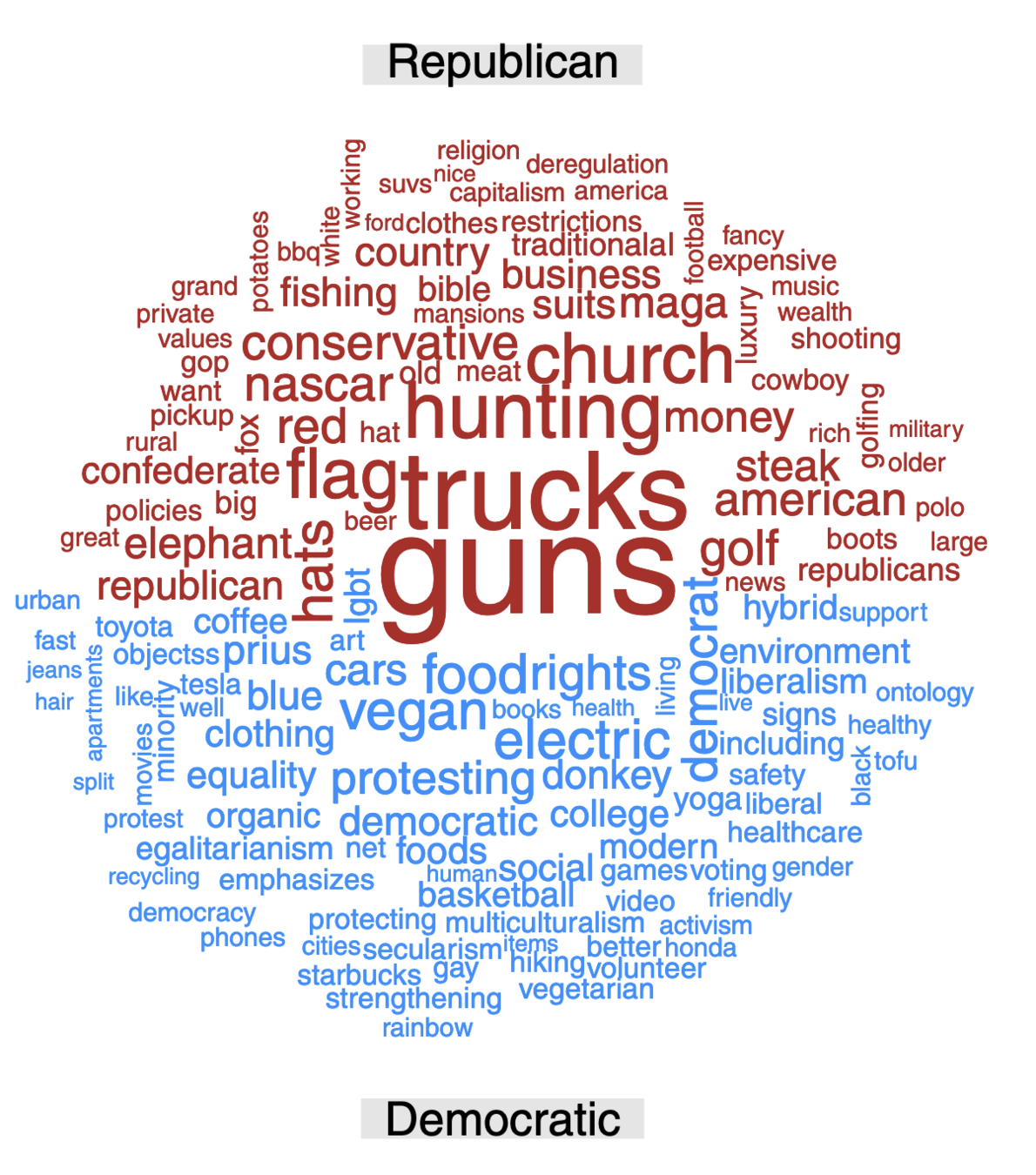
Illustration: use of words by partisans
Text Data Examples: Tweets
Text Data Examples: Tweets
Text Data Examples: Tweets
Trump is afraid of democracy. Following the G7 meeting I can tell you that we're all united against autocrats and that they should be afraid. No collusion like with the old psychotic man you are supporting.
@G7 leaders have failed to rise above national interests and tackle the global crises of COVID19 and Climate Change. They have simply repeated old promises (unfulfilled) for Climate Finance and inadequate supplies of vaccine without allowing patents for manufacture. @SaleemulHuq https://t.co/hkyTGKZvTW en [{'screen_name': 'saleemulhuq'
Text Data Examples: Military logs

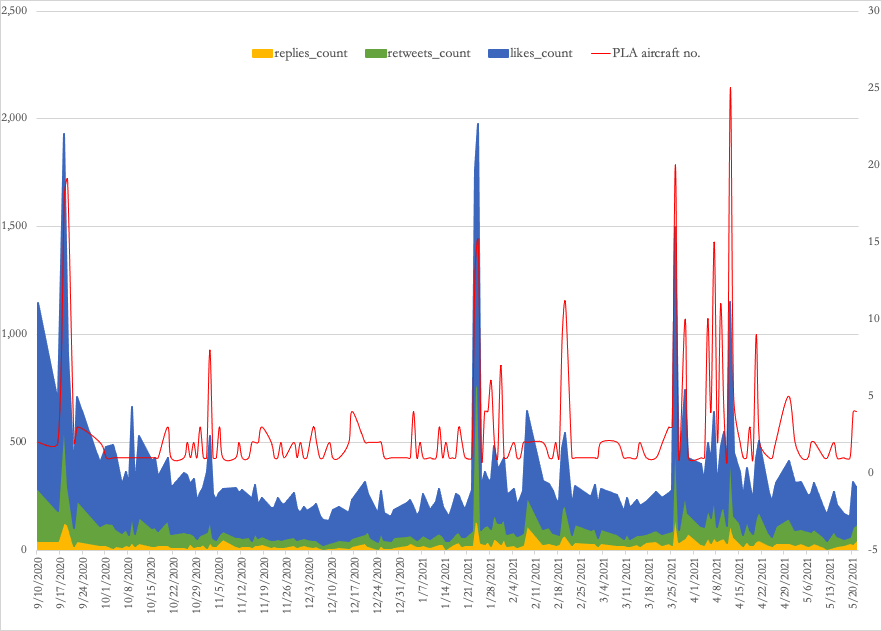
Figure 2. Sample tweet posted by Taiwan Ministry of Defense Official Twitter account
Figure 3. Taiwan public responses to PLA aircraft intrusions
-
20 reports from 2000 to 2020
-
Thousands of pages in PDF
Illustration:
U.S. Department of Defense reports, 2000-2020
Text Data Examples:
Government reports

DOD reports on China: Mentioning Taiwan
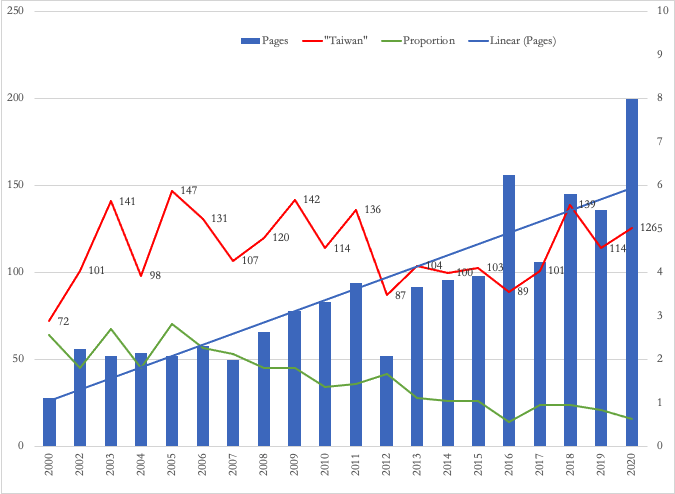
Figure 5. US Department of Defense Report on China’s Military Force: Mentions of “Taiwan”
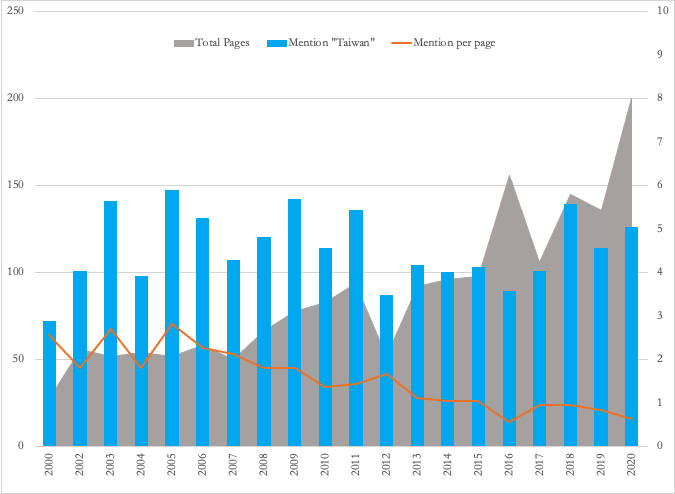
Figure 6. US Department of Defense Report on China’s Military Force: Keyword position of “Taiwan”
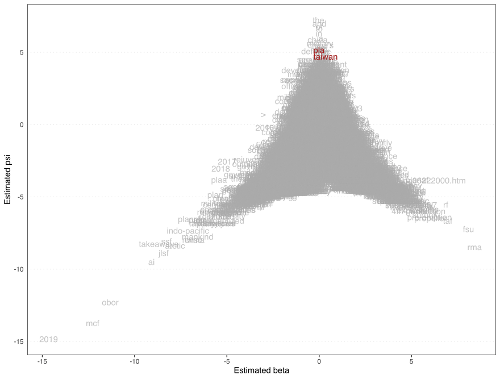
Figure 7. DOD Report: Poisson Scaling of favorability and position clarity on evaluating China’s military, 2000-2020

Aggarwal, C.C. and Zhai, C. eds., 2012. Mining text data. Springer Science & Business Media.
Chang, Jonathan, Jordan Boyd-Graber, Chong Wang, Sean Gerrish, and David M. Blei. 2009. Reading Tea Leaves: How Humans Interpret Topic Models. Neural Information Processing Systems.
Jockers, Matthew L. 2017. Syuzhet: An R package for the extraction of sentiment and sentiment-based plot arcs from text (GitHub).
Silge, Julia and Robinson, David. 2017. Text mining with R: A tidy approach. " O'Reilly Media, Inc." (https://www.tidytextmining.com/)
Cosima Meyer and Cornelius Puschmann: Advancing Text Mining with R and quanteda
Dan Jurafsky and James H. Martin: Speech and Language Processing
Reference
Resources
Further Reading

Ignatow, G. and Mihalcea, R., 2016. Text Mining: A Guidebook for the Social Sciences. Sage Publications.
Thank you!
Wait... are you sure you have no questions?

