Gentle Introduction to Machine Learning
Karl Ho
School of Economic, Political and Policy Sciences
University of Texas at Dallas
Workshop prepared for International Society for Data Science and Analytics (ISDSA) Annual Meeting, Notre Dame University, June 2nd, 2022.
Introduction
-
Karl Ho is:
- Associate Professor of Instruction at University of Texas at Dallas (UTD) School of Economic, Political and Policy Sciences (EPPS)
- Co-founder of the UTD Social Data Analytics and Research program (SDAR)
- Founder of DataGeneration.org
- Author of Data Programming
- Co-Principal Investigator of the Hong Kong Election Study project
- Website: karlho.com (talks, lecture, publications)
Speaker bio.
Overview
-
What is Machine Learning?
-
Statistics and Machine Learning
-
Statistical modeling: the two cultures
-
Conventional statistical methods and machine learning
-
Statistical/Machine Learning methods
- Supervised Learning
- Unsupervised Learning
- Deep Learning
What is machine learning?
The ultimate goal of data modeling is to explain and predict the variable of interest using data. Machine learning is to achieve this goal using computer algorithms in particular to make the prediction and solve the problem.
According to Carnegie Mellon Computer Science professor,
"Machine learning is the study of computer algorithms that allow computer programs to automatically improve through experience."

What is machine learning?
-
To statisticians, the “improve through experience” part is the process of validation or cross validation. Learning can be done through repeated exercises to understand data.
What is machine learning?
-
Machine learning involves having computer or statistics programs do repeated estimations, like human learns from experience and improve actions and decisions. This is called the training process in machine learning.
Statistics and Machine Learning
Statistics refresher
Statistics:
- Find and test data (data production and collection)
- Made data (surveys, experiments, interviews) based on theory and hypotheses
- Found data (web data, social data, machine generated data) from all sources
- Make data ready for analysis (data management)
- Explore data (means, variances, distribution) - Descriptive statistics
- Explain data (correlation, cross-tabulation, regression) - Inferential statistics
Parametric vs. Non-parametric models
-
Sample and population
-
Generalization
-
Representation
Leo Breiman

1928 – 2005
-
Statistical Modeling: The Two Cultures
-
CART (Classification and Regression Trees)
Statistical Modeling:
The Two Cultures
Leo Breiman 2001: Statistical Science
| One assumes that the data are generated by a given stochastic data model. |
|---|
| The other uses algorithmic models and treats the data mechanism as unknown. |
|---|
| Data Model |
|---|
| Algorithmic Model |
|---|
| Small data |
|---|
| Complex, big data |
|---|
Theory:
Data Generation Process
Data are generated in many fashions. Picture this: independent variable \(x\) goes in one side of the box-- we call it nature for now-- and dependent variable \(y\) come out from the other side.

Theory:
Data Generation Process
Data Model
The analysis in this culture starts with assuming a stochastic data model for the inside of the black box. For example, a common data model is that data are generated by independent draws from response variables.
\(Response Variable= f(Predictor variables, random noise, parameters) \)
Reading the response variable is a function of a series of predictor/independent variables, plus random noise (normally distributed errors) and other parameters.
Theory:
Data Generation Process
Data Model
The values of the parameters are estimated from the data and the model then used for information and/or prediction.
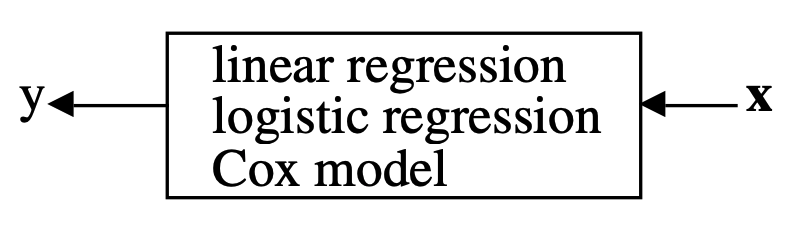
Theory:
Data Generation Process
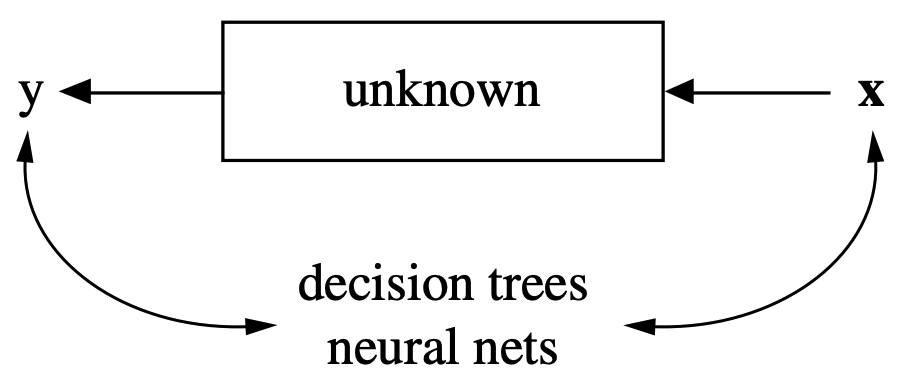
Algorithmic Modeling
The analysis in this approach considers the inside of the box complex and unknown. Their approach is to find a function \(f(x)\)-an algorithm that operates on \(x\) to predict the responses \(y\).
The goal is to find algorithm that accurately predicts y.
Theory:
Data Generation Process
Algorithmic Modeling
Unsupervised Learning
Supervised Learning vs.
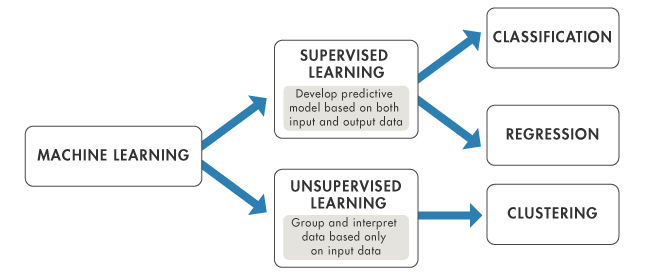
Source: https://www.mathworks.com
What can Machine Learning do and do better?
Machine Learning can do:
- Prediction
- Classification
- Give useful information for problem solving and decision making

Trevor Hastie and Robert Tibshirani




Andrew Ng

- One of the most cited and viewed Machine Learning lecture series on YouTube.
Machine Learning vs. Conventional statistical methods

Source: Attewell, Paul A. & Monaghan, David B. 2015. Data Mining for the Social Sciences: an Introduction, Table 2.1, p. 27
-
Statistics: testing hypotheses
-
Machine learning: finding the right hypothesis
-
Overlap:
Decision trees (C4.5 and CART)
Nearest-neighbor methods -
Bridging the two:
Most machine learning algorithms employ statistical techniques
hypothesis confirmation
hypothesis formation
Machine Learning vs. Conventional statistical methods
Supervised vs. Unsupervised Machine Learning
-
With vs. without known \(y\)
-
From statistical point of view, unsupervised machine learning:
- Identify pattern about data
- Seek information about \(y\) or the dependent variable
Illustration: Dimensionality of data
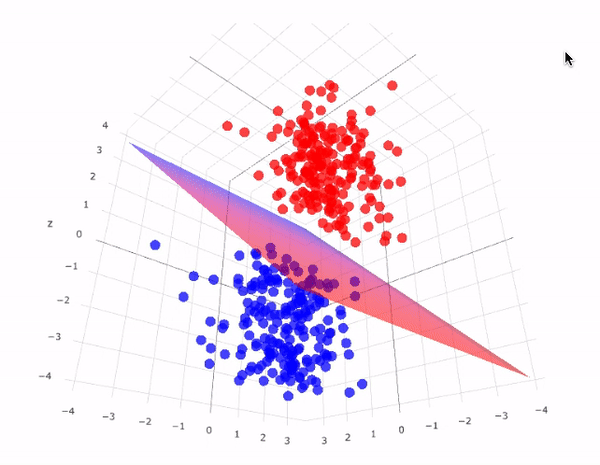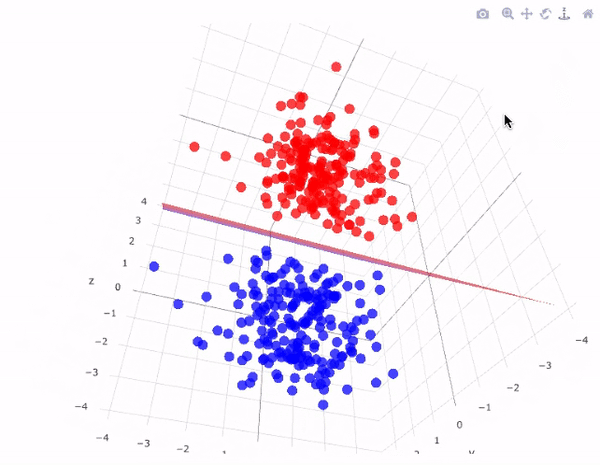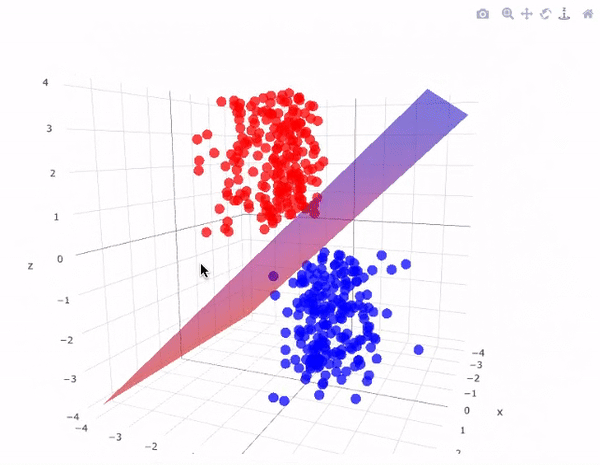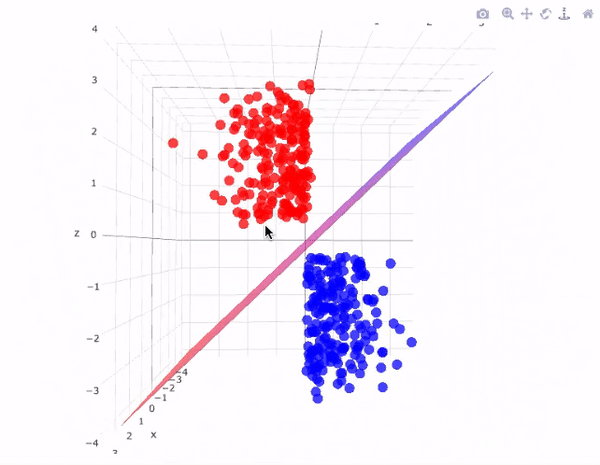
Illustration: Support Vector Machines
Machine learning methods
| Regression | Classification | Clustering | Q-Learning |
| Linear regression | Logistic regression | - K-Means Clustering | State Action Reward State Action (SARSA) |
| Polynomial regression | K-Nearest Neighbors | - Hierarchical Clustering | Deep Q-Network |
| Support vector regression | Support Vector Machines | Dimensionality Reduction | Markov Decision Processes |
| Ridge Regression | Kernal Support Vector Machines | Principal Component Analysis | Deep Deterministic Policy Gradient (DDPG) |
| Lasso | Naïve Bayes | Linear Discriminant Analysis | |
| ElasticNet | Decision Tree | Kernal PCA | |
| Decision tree | Random forest | ||
| Random forest |
| Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|
Machine learning methods
-
Text as data
-
Natural Language Processing (NLP)
-
e.g. Speech data, tweets, social media
-
-
Images and Videos
-
Spatial data via Remote sensing or Light Detection and Ranging (LIDAR)
-
Size and complexity of data generation process warrant machine assisted processing and analytics