CUDA Debugging Tools
A case study with jax-finufft
Lehman Garrison
SCC Group Meeting
January 30, 2024



The Setup
- Want to do high-dimensional inference, sampling, and optimization of non-uniform FFT problems
- Period fitting for astronomical time series
- MRI reconstruction
- Any model-fitting in Fourier space to unevenly sampled data
- Gradients of the likelihood enable greatly accelerated inference (e.g. Hamiltonian Monte Carlo)
- JAX JIT-compiles the Python model to arch-specific binary using LLVM via XLA -- including gradients
- Might want to include custom compiled code (e.g. finufft) rather than relying on Python JIT
The Problem
- Sporadic test failures on the GPU
- One possibility: JAX provides a CUDA stream that all operations are supposed to use. Is something accidentally using the default stream?
- CUDA streams
- Logical queue of operations for the GPU to execute in order
- Streams may execute asynchronously with respect to other streams (and host code), but operations in a stream are strictly sequential
(venv-23) scclin021:~/jax-finufft$ python -m pytest -v tests/
=============================================== test session starts ===============================================
platform linux -- Python 3.10.12, pytest-7.4.2, pluggy-1.3.0 -- /mnt/home/lgarrison/jax-finufft/venv-23/bin/python
cachedir: .pytest_cache
rootdir: /mnt/home/lgarrison/jax-finufft
collected 54 items
tests/ops_test.py::test_nufft1_forward[1-False-50-75--1] SKIPPED (1D transforms not implemented on GPU) [ 1%]
tests/ops_test.py::test_nufft1_forward[1-False-50-75-1] SKIPPED (1D transforms not implemented on GPU) [ 3%]
tests/ops_test.py::test_nufft1_forward[1-True-50-75--1] SKIPPED (1D transforms not implemented on GPU) [ 5%]
tests/ops_test.py::test_nufft1_forward[1-True-50-75-1] SKIPPED (1D transforms not implemented on GPU) [ 7%]
tests/ops_test.py::test_nufft1_forward[2-False-50-75--1] FAILED [ 9%]
tests/ops_test.py::test_nufft1_forward[2-False-50-75-1] FAILED [ 11%]
tests/ops_test.py::test_nufft1_forward[2-True-50-75--1] FAILED [ 12%]
tests/ops_test.py::test_nufft1_forward[2-True-50-75-1] FAILED [ 14%]
tests/ops_test.py::test_nufft1_forward[3-False-50-75--1] PASSED [ 16%]
tests/ops_test.py::test_nufft1_forward[3-False-50-75-1] PASSED [ 18%]
tests/ops_test.py::test_nufft1_forward[3-True-50-75--1] FAILED [ 20%]
tests/ops_test.py::test_nufft1_forward[3-True-50-75-1] FAILED [ 22%]
tests/ops_test.py::test_nufft2_forward[1-False-50-75--1] SKIPPED (1D transforms not implemented on GPU) [ 24%]
tests/ops_test.py::test_nufft2_forward[1-False-50-75-1] SKIPPED (1D transforms not implemented on GPU) [ 25%]
tests/ops_test.py::test_nufft2_forward[1-True-50-75--1] SKIPPED (1D transforms not implemented on GPU) [ 27%]
tests/ops_test.py::test_nufft2_forward[1-True-50-75-1] SKIPPED (1D transforms not implemented on GPU) [ 29%]
tests/ops_test.py::test_nufft2_forward[2-False-50-75--1] PASSED [ 31%]
tests/ops_test.py::test_nufft2_forward[2-False-50-75-1] PASSED [ 33%]
tests/ops_test.py::test_nufft2_forward[2-True-50-75--1] FAILED [ 35%]
tests/ops_test.py::test_nufft2_forward[2-True-50-75-1] FAILED [ 37%]
tests/ops_test.py::test_nufft2_forward[3-False-50-75--1] PASSED [ 38%]
tests/ops_test.py::test_nufft2_forward[3-False-50-75-1] PASSED [ 40%]
tests/ops_test.py::test_nufft2_forward[3-True-50-75--1] FAILED [ 42%]
tests/ops_test.py::test_nufft2_forward[3-True-50-75-1] FAILED [ 44%]
tests/ops_test.py::test_nufft1_grad[1-50-35--1] SKIPPED (1D transforms not implemented on GPU) [ 46%]
tests/ops_test.py::test_nufft1_grad[1-50-35-1] SKIPPED (1D transforms not implemented on GPU) [ 48%]
tests/ops_test.py::test_nufft1_grad[2-50-35--1] FAILED [ 50%]
tests/ops_test.py::test_nufft1_grad[2-50-35-1] FAILED [ 51%]
tests/ops_test.py::test_nufft1_grad[3-50-35--1] FAILED [ 53%]
tests/ops_test.py::test_nufft1_grad[3-50-35-1] FAILED [ 55%]
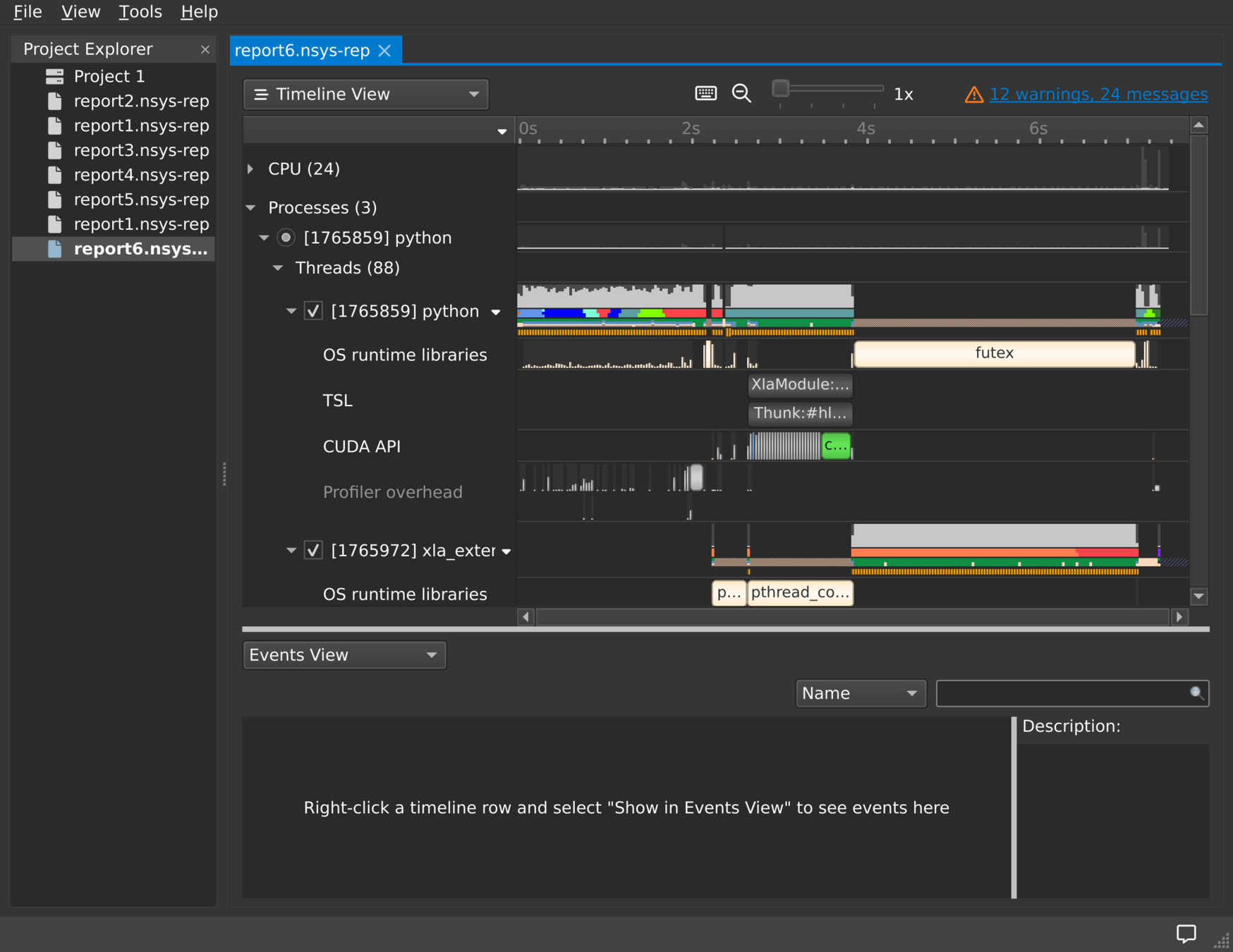
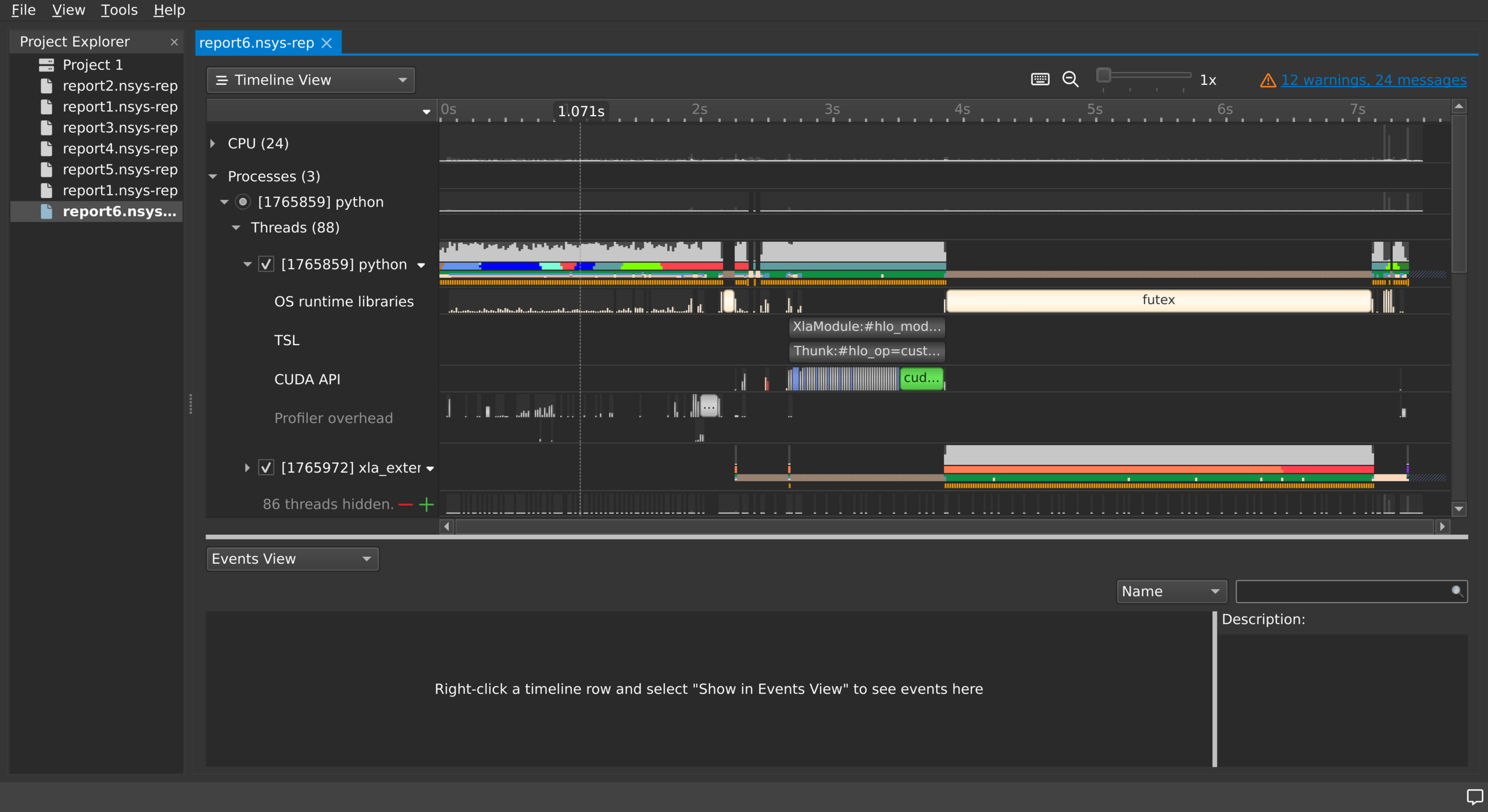
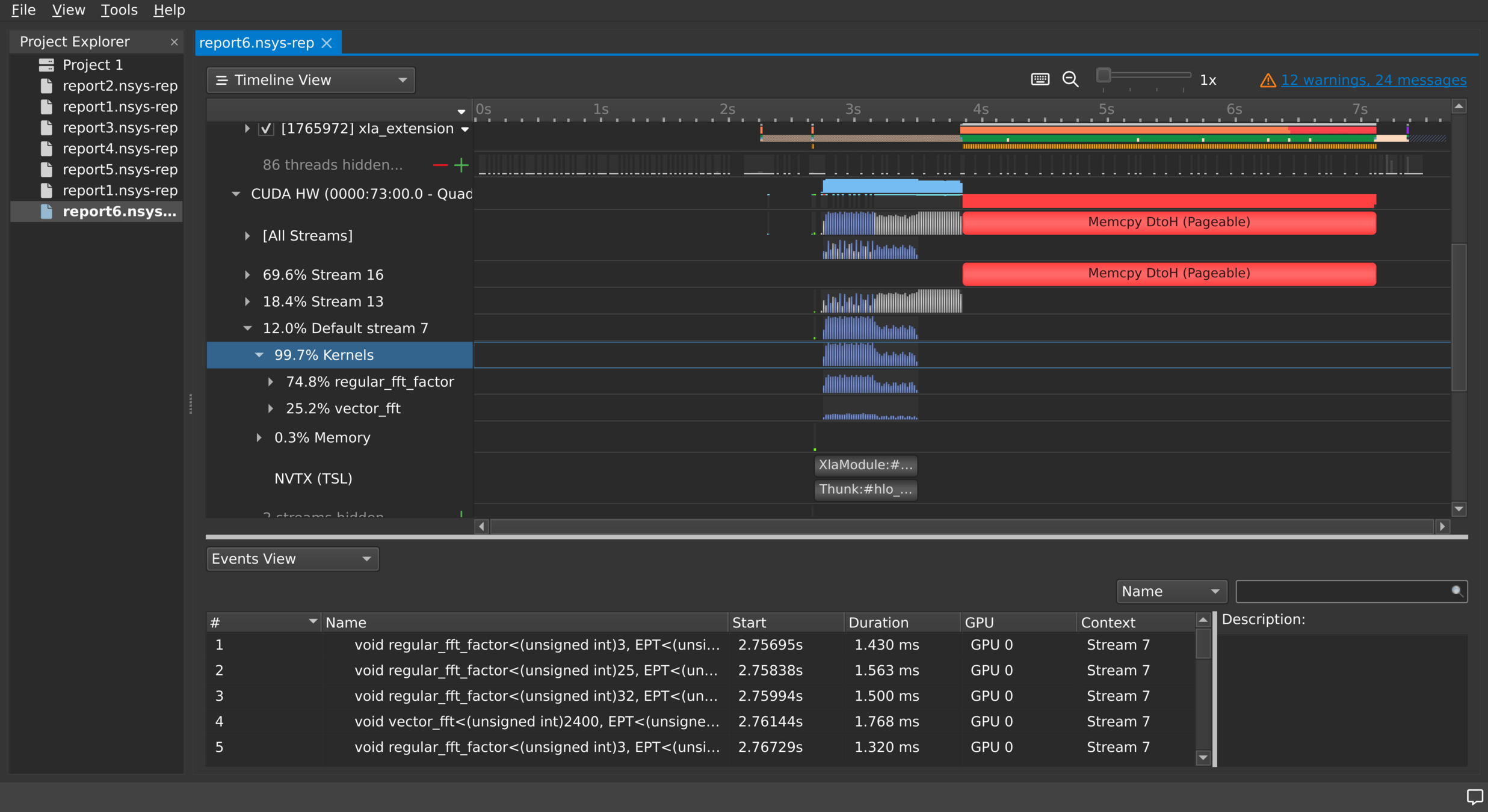
NVIDIA Nsight Systems
- We can systematically examine which operations are using which CUDA streams using NVIDIA Nsight Systems
- Nsight Systems is the successor to the NVIDIA Visual Profiler (nvvp)
- Collect information in CLI, analyze in GUI:
-
nsys profile python script.py
-
nsys-ui report1.nsys-rep
-
-
Works out of the box on FI Linux workstations
- https://docs.nvidia.com/nsight-systems/UserGuide/index.html
Fixing the CUDA Stream Usage
- cuFFT lets us set the stream a certain FFT plan should be executed on
- But it has to be set after plan creation, not before!
- Contrast with FFTW, where planning itself involves FFT execution
cufftHandle fftplan; cufftResult_t cufft_status; - cufftSetStream(fftplan, stream); cufft_status = cufftPlanMany(& fftplan, 1, n, inembed, 1, inembed[0], inembed, 1, inembed[0], cufft_type<T>(), maxbatchsize ); + cufftSetStream(fftplan, stream);
Debugging CUDA Illegal Memory Access
- Next test failure: a CUDA illegal memory access
-
cudaErrorIllegalAddress: an illegal memory access was encountered
- Looks like reading off the end of a device array
(venv-23) scclin021:~/jax-finufft$ python -m pytest -v tests/ops_test.py::test_issue37 ============================================= test session starts ============================================= platform linux -- Python 3.10.12, pytest-7.4.2, pluggy-1.3.0 -- /mnt/home/lgarrison/jax-finufft/venv-23/bin/python cachedir: .pytest_cache rootdir: /mnt/home/lgarrison/jax-finufft collected 1 item tests/ops_test.py::test_issue37 FAILED [100%] ================================================== FAILURES =================================================== ________________________________________________ test_issue37 _________________________________________________ jax.errors.SimplifiedTraceback: For simplicity, JAX has removed its internal frames from the traceback of the following exc eption. Set JAX_TRACEBACK_FILTERING=off to include these. The above exception was the direct cause of the following exception: def test_issue37():
@partial(jax.vmap, in_axes=(0, 0, None)) def cconv_test(f, xs, kernel): # f.shape = (n_grid, in_features) # x.shape = (n_grid, ndim) # kernel.shape = (*k_grid, in_features, out_features) ndim = xs.shape[-1] k_grid_shape = kernel.shape[:-2] f_ = f.astype( {np.float32: np.complex64, np.float64: np.complex128}[f.dtype.type] ).transpose() coords = [xs[..., i] for i in range(ndim)] f_hat = nufft1(k_grid_shape, f_, *coords, iflag=-1) c_hat = jnp.einsum("a...,...ab->b...", f_hat, kernel) return nufft2(c_hat, *coords, iflag=1) kernel = jnp.array(np.random.randn(32, 32, 32, 16, 16)) f = jnp.array(np.random.randn(8, 100, 16)) x = jnp.array(np.random.uniform(low=-np.pi, high=np.pi, size=(8, 100, 3))) a = cconv_test(f, x, kernel) > b = jax.jit(cconv_test)(f, x, kernel) E jaxlib.xla_extension.XlaRuntimeError: INTERNAL: Failed to execute XLA Runtime executable: run time error: custom call 'xla.gpu.custom_call' failed: nufft3d1f XLA extension have thrown an exception: inclusive_scan failed to synchronize: cudaErrorIllegalAddress: an illegal memory access was encountered; current tracing scope: custom-call.2; current profiling annotation: XlaModule:#hlo_module=jit_cconv_test,program_id=12#.
cuda compute sanitizer
- CUDA Compute Sanitizer is a suite of tools for runtime correctness checking
- memcheck, racecheck, initcheck, synccheck, etc
- Although the name invokes modern compiler sanitizers, behaves much more like Valgrind
- Don't need to recompile or instrument the executable
- Identifies the jax-finufft problem as a read off the end of an array
- Compute Sanitizer docs
(venv-23) scclin021:~/jax-finufft/scripts$ compute-sanitizer python jittest.py ========= COMPUTE-SANITIZER ========= Invalid __global__ read of size 4 bytes ========= at 0x31f0 in void cufinufft::spreadinterp::calc_inverse_of_global_sort_index_3d<float>(int, int, int, int, int, int, int, const int *, const int *, const T1 *, const T1 *, const T1 *, int *, int, int, int, int) ========= by thread (58,0,0) in block (0,0,0) ========= Address 0xed2002048 is out of bounds ========= and is 69 bytes after the nearest allocation at 0xed2001800 of size 2,052 bytes ========= Saved host backtrace up to driver entry point at kernel launch time ========= Host Frame: [0x3304e0] ========= in /lib64/libcuda.so.1 ========= Host Frame: [0x16987e] ========= in /mnt/home/lgarrison/jax-finufft/venv-23/lib/python3.10/site-packages/jax_finufft/jax_finufft_gpu.cpython-310-x86_64-linux-gnu.so ========= Host Frame: [0x1c9a8e] ========= in /mnt/home/lgarrison/jax-finufft/venv-23/lib/python3.10/site-packages/jax_finufft/jax_finufft_gpu.cpython-310-x86_64-linux-gnu.so ========= Host Frame:void cufinufft::spreadinterp::calc_inverse_of_global_sort_index_3d<float>(int, int, int, int, int, int, int, int const*, int const*, float const*, float const*, float const*, int*, int, int, int, int) [0x14dcc8] ========= in /mnt/home/lgarrison/jax-finufft/venv-23/lib/python3.10/site-packages/jax_finufft/jax_finufft_gpu.cpython-310-x86_64-linux-gnu.so ========= Host Frame:int cufinufft::spreadinterp::cuspread3d_subprob_prop<float>(int, int, int, int, cufinufft_plan_t<float>*) [0x150428] ========= in /mnt/home/lgarrison/jax-finufft/venv-23/lib/python3.10/site-packages/jax_finufft/jax_finufft_gpu.cpython-310-x86_64-linux-gnu.so ========= Host Frame:cufinufftf_setpts [0x15e2c7] ========= in /mnt/home/lgarrison/jax-finufft/venv-23/lib/python3.10/site-packages/jax_finufft/jax_finufft_gpu.cpython-310-x86_64-linux-gnu.so
cuda-gdb
- For interactive debugging, can use cuda-gdb
- Extends GDB to support device-side debugging
- Single-stepping execution
- Inspecting and modifying variables
- Jumping between host and device contexts
- Breakpoints and conditions
- Device hardware watchpoints *not* supported
- Can be slow to start sometimes
(venv-23) scclin021:~/jax-finufft/scripts$ cuda-gdb --args python jittest.py NVIDIA (R) CUDA Debugger CUDA Toolkit 12.2 release Portions Copyright (C) 2007-2023 NVIDIA Corporation GNU gdb (GDB) 12.1 [...] (cuda-gdb) start [...] CUDA Exception: Warp Illegal Address The exception was triggered at PC 0x7fff27d14a20 (spreadinterp3d.cuh:69) Thread 1 "python" received signal CUDA_EXCEPTION_14, Warp Illegal Address. [Switching focus to CUDA kernel 51, grid 860, block (0,0,0), thread (0,0,0), device 0, sm 0, warp 2, lane 0] 0x00007fff27d14ae0 in cufinufft::spreadinterp::calc_inverse_of_global_sort_index_3d<<<(1,1,1),(512,1,1)>>> (M=100, b in_size_x=16, bin_size_y=16, bin_size_z=2, nbinx=4, nbiny=4, nbinz=32, bin_startpts=0x302001000, sortidx=0x303002a00, x=0x7 ffaaa401980, y=0x7ffaaa402600, z=0x7ffaaa403280, index=0x303002800, pirange=1, nf1=64, nf2=64, nf3=64) at /mnt/home/lgarrison/jax-finufft/build/cp310-cp310-manylinux_2_28_x86_64/../../vendor/finufft/src/cuda/3d/spreadinterp3d.cuh:71 71 } (cuda-gdb)
Live cuda-gdb Demo
template <typename T> __global__ void calc_inverse_of_global_sort_index_3d( int M, int bin_size_x, int bin_size_y, int bin_size_z, int nbinx, int nbiny, int nbinz, const int *bin_startpts, const int *sortidx, const T *x, const T *y, const T *z, int *index, int pirange, int nf1, int nf2, int nf3 ) { int binx, biny, binz; int binidx; T x_rescaled, y_rescaled, z_rescaled; for (int i = threadIdx.x + blockIdx.x * blockDim.x; i < M; i += gridDim.x * blockDim.x) { x_rescaled = RESCALE(x[i], nf1, pirange); y_rescaled = RESCALE(y[i], nf2, pirange); z_rescaled = RESCALE(z[i], nf3, pirange); binx = floor(x_rescaled / bin_size_x); binx = binx >= nbinx ? binx - 1 : binx; binx = binx < 0 ? 0 : binx; biny = floor(y_rescaled / bin_size_y); biny = biny >= nbiny ? biny - 1 : biny; biny = biny < 0 ? 0 : biny; binz = floor(z_rescaled / bin_size_z); binz = binz >= nbinz ? binz - 1 : binz; binz = binz < 0 ? 0 : binz; binidx = common::calc_global_index_v2(binx, biny, binz, nbinx, nbiny, nbinz); index[bin_startpts[binidx] + sortidx[i]] = i; } }
(cuda-gdb) info args M = 100 bin_size_x = 16 bin_size_y = 16 bin_size_z = 2 nbinx = 4 nbiny = 4 nbinz = 32 bin_startpts = 0x302001000 sortidx = 0x303002a00 x = 0x7ff840401980 y = 0x7ff840402600 z = 0x7ff840403280 index = 0x303002800 pirange = 1 nf1 = 64 nf2 = 64 nf3 = 64 (cuda-gdb) info locals x_rescaled = 59.3145142 z_rescaled = 270.639923 biny = 24 binidx = 2243 y_rescaled = 415.313934 binx = 3 binz = 134 (cuda-gdb) p bin_startpts[binidx] $1 = -499364480
Fixing CUDA Illegal Memory Access
- Problem turned out to be a host code error in how the device arrays were indexed for batched transforms
diff --git a/lib/kernels.cc.cu b/lib/kernels.cc.cu index 38ee6fc..ef4fcf5 100644 --- a/lib/kernels.cc.cu +++ b/lib/kernels.cc.cu @@ -22,11 +22,10 @@ void run_nufft(int type, const NufftDescriptor *descriptor, T *x, T *y, T *z, makeplan(type, ndim, descriptor->n_k, descriptor->iflag, descriptor->n_transf, descriptor->eps, &plan, opts); for (int64_t index = 0; index < descriptor->n_tot; ++index) { + int64_t i = index * descriptor->n_j; int64_t j = index * descriptor->n_j * descriptor->n_transf; int64_t k = index * n_k * descriptor->n_transf; - setpts(plan, descriptor->n_j, &(x[j]), y_index(y, j), z_index(z, j), 0, + setpts(plan, descriptor->n_j, &(x[i]), y_index(y, i), z_index(z, i), 0, NULL, NULL, NULL);
Summary
- CUDA debugging experience is pretty good these days
- CUDA versions of debugger and sanitizer, two linchpin tools for software development, are useful and mature
- NVIDIA Systems useful for a bird's-eye view of streams, threads, processes, and communication
- Was able to find and fix several CUDA bugs in finufft and jax-finufft with these tools
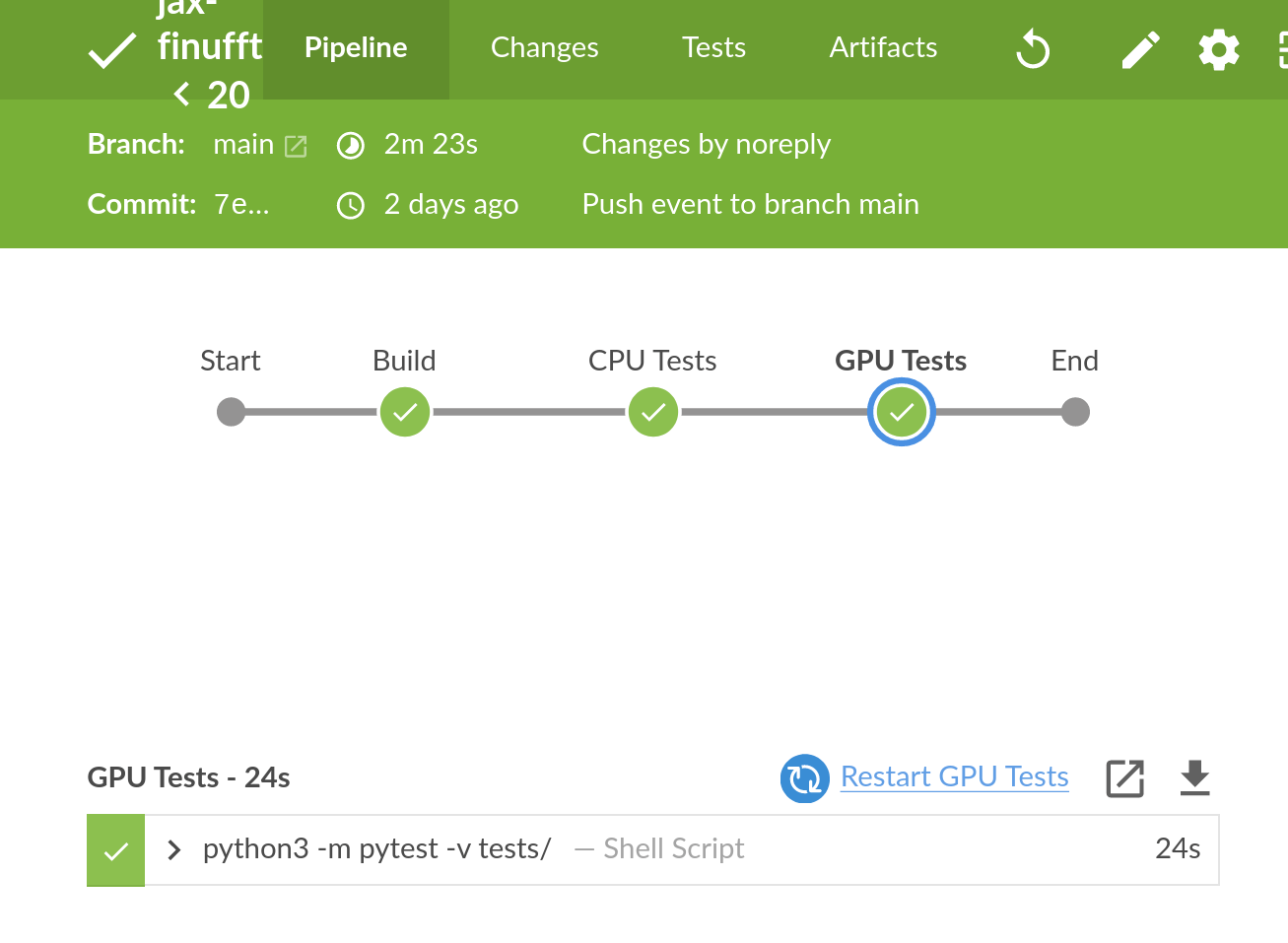
GPU tests passing on Jenkins!