Practical Applications of Chatbot
Introduction to RAG
Revolution of LLM
Representation of Words
Training Paradigm

word embedding
向量長度 =詞彙數量(e.g. length: 10000)

Network Architecture

輸入層
隱藏層
輸出層
Transformer, 2017/06
Word2Vec, 2013/01
Pre-trained, 2010/10
Novel Network Architecture: Transformer(1/3)
Sutskever, I., Vinyals, O., & Le, Q.V. (2014). Sequence to Sequence Learning with Neural Networks. ArXiv, abs/1409.3215.
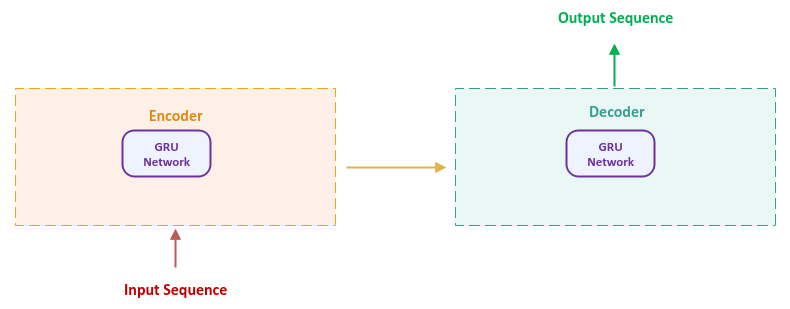
seq2seq model, 2014/09
Encoder-Decoder Model for NLP tasks
文字型任務
編碼器
解碼器
Novel Network Architecture: Transformer(2/3)
attention, 2014/09
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. CoRR, abs/1409.0473.

seq2seq model, 2014/09
Attention: focus on specific parts of input while generating output
認知科學:選擇性注意力
Novel Network Architecture: Transformer(3/3)

Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł. & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems (p./pp. 5998--6008), .
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06

Self-Attention: input interact with each other
上下文context
Transformer-based Language Models BERT(1/5)
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. North American Chapter of the Association for Computational Linguistics.
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
BERT, 2018/10

token
embedding
(Encoder-only)
(BERT base)
預訓練pre-training
prediction (probability)
下游任務downstream task
FNN
(微調, Fine-tuning)


dim: 768
Training Paradigm Shifting Pre-trained + fine-tuning
遷移學習:預訓練(pre-trained) + 目標領域資料集收集、訓練(fine-tune)

機器學習傳統做法
資料集1
資料集2
資料集3
任務1
任務2
任務3
兩階段: 非監督式、監督式
不同任務、不同資料集
Transfer Learning
來源領域任務
資料集S
目標領域任務
大量
資料集T
小量
預訓練unsupervised
微調supervised
Pan, S.J., & Yang, Q. (2010). A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering, 22, 1345-1359.
pre-trained, 2010
Representation of Words one-hot encoding(1/3)

One-hot encoding
1
2
3
4
5
6
7
8
編碼:以向量表示
編號
詞彙
<SOS>
編號
0 0 0 0 0 0 0 0
<SOS> I played the piano
編碼
輸入層
隱藏層
輸出層
Word Embedding(詞嵌入)
字彙語意相近,編碼必須給予比較近的「距離」

Representation of Words word embedding(2/3)
Mikolov, T., Chen, K., Corrado, G.S., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. International Conference on Learning Representations.
Word2Vec, 2013/01

Word Embedding
詞彙
維度
Word2Vec
Representation of Words word embedding: word2vec(3/3)
Word2Vec學習大量詞彙,將字詞對應到100-300維度的空間。
Transformer-based Language Models GPT-2 (2/5)
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners.
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019

BERT, 2018/10
decoder-only

117M Parameters

1,542M Parameters

Transformer-based LM Pre-trained + Fine-tune (3/5)
預訓練
預訓練
預訓練
預訓練
微調
微調
微調
微調
微調
Transformer-based LM You Never Know What They Really Do (4/5)
Transform-based Model



●●●
pre-trained data sets
NN1
Task 1
NN2
Task 2
NNn
Task N
target domain data sets
●●●
●●●
●●●
LLM
Transformer-based LM What happened to embedding? (5/5)

Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024
Transformer-based LM What happened to embedding? (5/5)

Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024
Transformer-based LM What happened to embedding? (5/5)
Nathan Bos, Ph.D,Embeddings Are Kind of Shallow, 2024

難以捕捉更高層次的語義概念
難以進行邏輯運算和因果推理
缺乏情境理解
Retrieval Augmented Generation
檢索增強生成
LLMs are More Than You Think, but also Lower Than Expected

Capabilities of Pattern Matching
Mirzadeh, I., Alizadeh-Vahid, K., Shahrokhi, H., Tuzel, O., Bengio, S., & Farajtabar, M. (2024). GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models.

One of the solutions: RAG
Hallucination
Prompt Engineering
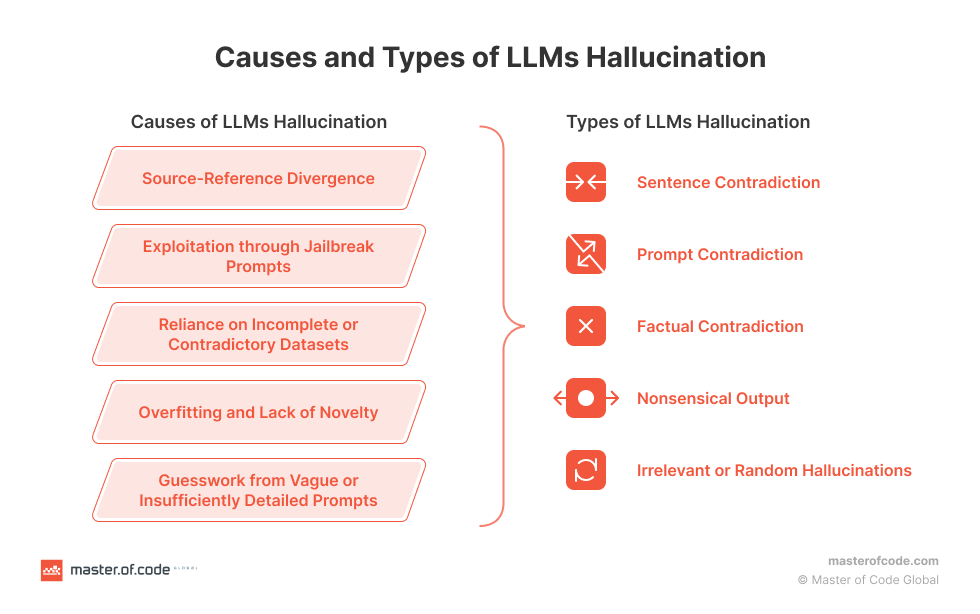
Hallucination(1/4)
Maleki, N., Padmanabhan, B., & Dutta, K. (2024, June). AI hallucinations: a misnomer worth clarifying. In 2024 IEEE conference on artificial intelligence (CAI) (pp. 133-138). IEEE.
- 電腦視覺領域:錯誤標示不存在的物件、將物件錯誤定位
- NLP領域:機器翻譯中可能產生「流暢但無關的輸出」,或生成看似合理但缺乏事實依據的內容(2017)
- 醫學領域:部分學者認為 AI 並不具備感官知覺,因此「幻覺」一詞並不適用
定義分歧!
Hallucination(2/4)
Maleki, N., Padmanabhan, B., & Dutta, K. (2024, June). AI hallucinations: a misnomer worth clarifying. In 2024 IEEE conference on artificial intelligence (CAI) (pp. 133-138). IEEE.
- 機器翻譯:「流暢但無關的翻譯」或「流暢但內容不足的輸出」
- 文本摘要:「與原始文件不一致的內容」
- 「內在幻覺(Intrinsic Hallucination)」
- 「外在幻覺(Extrinsic Hallucination)」
- 醫療領域:「脫離已知醫學知識的錯誤資訊」,可能影響診斷與決策。
- 法律與倫理領域:可能導致「不準確或誤導性的法律建議」,影響法務工作的可靠性。
Hallucination(3/4)
Maleki, N., Padmanabhan, B., & Dutta, K. (2024, June). AI hallucinations: a misnomer worth clarifying. In 2024 IEEE conference on artificial intelligence (CAI) (pp. 133-138). IEEE.
- 虛構(Fabrication):指 AI 生成的內容看似合理,但實際上不存在於訓練數據中。
- 錯誤資訊(Misinformation):指 AI 生成的內容錯誤或不符事實。
- 隨機鸚鵡效應(Stochastic Parroting):指 AI 只是機械式地重組訓練數據,並非真正理解資訊。
- 事實捏造(Fact Fabrication):指 AI 生成未經驗證的「新事實」。
部份研究建議的替代用語:
Hallucination(4/4)
Maleki, N., Padmanabhan, B., & Dutta, K. (2024, June). AI hallucinations: a misnomer worth clarifying. In 2024 IEEE conference on artificial intelligence (CAI) (pp. 133-138). IEEE.
- 建立標準化定義:不同領域應達成共識,以便更準確地描述 AI 的錯誤輸出。
- 採用更精確的術語:避免使用「幻覺」等可能引發誤解的詞彙,改用「事實捏造」、「錯誤資訊」等更貼近 AI 行為的詞彙。
- 提高 AI 透明度:AI 開發者應提供更明確的機制,以標示 AI 產生內容的可信度,並減少錯誤資訊的傳播。
結論與建議
Retrieval Augmented Generation RAG (1/5)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
RAG, 2020/05

RAG for knowledge intensive tasks
1. parametric memory: a pre-trained seq2seq model
2. non-parametric memory: a dense vector index of Wikipedia
e.g. word embedding
embedding of x
向量搜尋
embedding of 文件zi
向量搜尋前n名
RAG for Knowledge Intensive Tasks
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
1. Temperature(以OpenAI為例)
介於 0至2之間,數值越高生成結果越隨機。
語言模型生成內容時可調參數(非所有模型都支援):兼具正確性與創造性
2. Top-P (Nucleus Sampling, 以OpenAI為例)
p介於0.1至1之間,以0.1為例,代表生成「下一個token時」只考慮排序後,前10%的tokens。
3. Top-K (Top-K Sampling)
k為一正整數,以32為例,代表生成「下一個token時」只考慮排序後,前32名的tokens。
RAG for Knowledge Intensive Tasks
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
non-parametric memory: a dense vector index of Wikipedia
內部知識
外部知識

語言模型
vector embedding
或
graph embedding
問題
解答
parametric memory: a pre-trained seq2seq model
實作方式
RAG ReAct Reasoning and Action (2/5)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
RAG, 2020/05
ReAct, 2022/10

Chain-of-Thought + Act
Act 1: Search [Q]
Act 2: Search [Obs 1]
Act 3: Search [Obs 2]
Act 4: Finish [answer]
context
ReAct Reasoning and Action
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
Chain-of-Thought(CoT)
- 「逐步推理」,避免直接猜測答案,提高準確度。
- 適用於數學計算、邏輯推理、常識推理、或問答系統
問題:如果今天是星期二,那麼 3 天後是星期幾?
一般模型回答(無推理):
星期五(如果沒有推理過程,可能會答錯)
CoT 推理過程:
今天是星期二。
過 1 天是星期三。
過 2 天是星期四。
過 3 天是星期五。
答案是星期五。
CoT 最終回答:
星期五
範例: 邏輯推理
ReAct Reasoning and Action
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
讓模型交錯生成「推理」(reasoning)與「行動」(act),以便在決策過程中動態更新計畫、適應變化、並獲取外部資訊。
- 「推理 → 行動 → 觀察」的迴圈來處理任務
- 適用:互動式決策任務(選購商品、尋找物品)
- 適用:知識密集型推理任務(問答、事實驗證)
-
推理驅動行動(Reason to Act):根據推理結果決定下一步行動。
- 例:透過檢索獲取更多資訊。
- 行動支持推理(Act to Reason):互動獲取外部回饋(觀察回饋),以此修正或強化推理過程。
ReAct方法
ReAct Reasoning and Action
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
「推理 → 行動 → 觀察」的迴圈來進行決策,每個步驟的推理與行動都是基於當前觀察到的結果:
ReAct 的推理與調整機制
-
推理驅動行動(Reason to Act):根據推理結果決定下一步行動。
- 例:透過檢索獲取更多資訊。
- 行動支持推理(Act to Reason):互動獲取外部回饋(觀察回饋),以此修正或強化推理過程。
-
根據結果動態調整推理與行動(Adjust Reasoning & Actions)
- 結果符合預期:基於此資訊進一步推理,執行下一步行動
-
結果不符預期
- 修改推理方向:例如換個關鍵字搜尋
- 改變行動策略:例如廚房找不到胡椒罐,該去餐桌看看
ReAct Reasoning and Action
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
| 調整策略 | 示例 |
|---|---|
| 變更檢索策略 | 若搜尋「Apple Remote」無結果,則改搜尋「Apple TV 遙控器」 |
| 修正推理過程 | 若模型推理「A 是 B 的創辦人」,但查無資料,則改為「A 可能參與了 B 的早期發展」 |
| 重新規劃行動順序 | 若計畫「先檢查抽屜再看桌面」失敗,則改為「先檢查桌面再看抽屜」 |
| 嘗試不同的知識來源 | 若維基百科無法提供答案,則改用 Google 搜尋(若環境允許) |
調整策略
ReAct Reasoning and Action
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv, abs/2210.03629.
範例: ALFWorld(互動環境)
任務:「將胡椒罐放進抽屜」
初始推理:「胡椒罐可能在廚房的櫃子或餐桌上,我應該先去廚房。」
行動 1:「前往廚房」
觀察結果:「廚房內有一個櫃子。」
行動 2:「打開櫃子」
觀察結果:「櫃子裡沒有胡椒罐。」
調整推理:「胡椒罐可能在餐桌上,我應該去看看。」
行動 3:「前往餐桌」
觀察結果:「餐桌上有胡椒罐。」
行動 4:「拿起胡椒罐並放入抽屜」
最終結果:「任務完成!」
LangChain ReAct Design Pattern: High Level Abstraction (3/5)
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
RAG, 2020/05
ReAct, 2022/10


Setting, Resouces
Interactive UI for Work Flow Design

LlamaIndex For Efficient Indexing & Retrieval (4/5)


RAG Research Framework (5/5)

Context
Query
Prompt
LLM
Output

Vector DB
❶ Dataset
❸ Embedding
➍ Similarity
❷
➎ Reranking algorithm
➏

RAG
RAG
web crawler

Context
Query
Prompt
LLM
Output
Vector DB
RAG
關懷理論

Scenario: 法律扶助
問責 合規
來源 透明
專家審查
defining an appropriate workflow
pip install llama-indexLlamaIndex Hello world (1/6)
1. 安裝Python套件


●●●


2. 準備知識庫
支援各種檔案格式(參考官網文件)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (2/6)

2. 準備知識庫
data資料夾:5個PDF檔

範例程式
知識庫

3. 設定OpenAI API Key (可更換別的LLM)

LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)

LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (3/6)
3. 設定OpenAI API Key (可更換別的LLM)
LlamaIndex Hello world (3/6)

輸入申請之API KEY
import os
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,)
def setCurrentWD():
abspath = os.path.abspath(__file__)
dname = os.path.dirname(abspath)
os.chdir(dname)
setCurrentWD() # 設定工作目錄, 以免找不到data資料夾
# 1. Loading & Parsing
documents = SimpleDirectoryReader("data").load_data()
# 2. Indexing & vector store
index = VectorStoreIndex.from_documents(documents)
# 3. Query
query_engine = index.as_query_engine()
response = query_engine.query("Tell me about rag")
print(response)LlamaIndex Hello world (4/6)
response = query_engine.query("Tell me about rag")
LlamaIndex output (5/6)
RAG models leverage a retriever to retrieve text documents based on an input query and use them as additional context when generating a target sequence. These models have been shown to achieve state-of-the-art results on various tasks such as open Natural Questions, WebQuestions, CuratedTrec, MS-MARCO, Jeopardy question generation, and FEVER fact verification. RAG models generate responses that are more factual, specific, and diverse compared to baseline models like BART. The retrieval mechanism in RAG plays a key role in improving results across different tasks.
實際回應

出處

LlamaIndex Cost (6/6)
$0.12
<$0.01
Embedding (indexes) 可以只算一次
Embedding預訓練是不是MultiLingual?效果差很多!
LlamaIndex整合vLLM local models
# if not installed
pip install vllm前置準備
1. CUDA環境 GPU運算能力值, 驅動程式, CUDA Toolkit
2. Python環境 虛擬環境設定
3. Start the local model using vLLM
python -m vllm.entrypoints.openai.api_server --model=模型名稱可用模型
4. 啟動模型
部分模型需要token: 先註冊HuggingFace帳號

選用模型
選用模型
建立新token,注意開啟inference權限

選用模型
取名

建立token後,複製到剪貼簿供後續使用
選用模型

選用模型 以llama-3.2-1B為例
使用條件
選用模型 以llama-3.2-1B為例

模型資訊
選用模型 以llama-3.2-1B為例
於提示列貼上token
export HF_TOKEN=貼上TOKENpip install -U "huggingface_hub[cli]" # 如有必要
huggingface-cli login
或是設定HF_TOKEN環境變數
token貼於此
n
token合法
選用模型 以llama-3.2-1B為例
python -m vllm.entrypoints.openai.api_server --model=meta-llama/Llama-3.2-1B-Instruct --max_model_len 4096啟動模型

成功啟動於http://localhost:8000
# 範例:使用 Meta Llama 3 8B Instruct 模型
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--host 0.0.0.0 \ # 本機測試,用 localhost 或 127.0.0.1 也可以
--port 8000 \
--gpu-memory-utilization 0.90 # 可選:調整 GPU 內存使用率
# --tensor-parallel-size 1 # 可選:如果有多 GPU 可以設定
# --max-model-len 4096 # 可選:設定模型最大長度vLLM支援的選項
Python套件安裝 LlamaIndex, OpenAI等
pip install llama-index llama-index-llms-openai openaiLlamaIndex 核心及 OpenAI Client 整合套件(vLLM api與OpenAI API相容)
本地端Embedding模型以HuggingFace模型為例
pip install llama-index-embeddings-huggingface sentence-transformerspip install llama-index-embeddings-ollama
# 確保 Ollama 服務運行並已 pull embedding 模型,
# e.g., ollama pull nomic-embed-textpip install llama-index-embeddings-huggingface sentence-transformers本地端Embedding模型(optional)以ollama模型為例
範例程式碼
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="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",
)
completion = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=[
{"role": "system", "content": "一律以台灣繁體中文慣用語回覆"},
{"role": "user", "content": "什麼是語言模型"}
],
max_tokens=512
)練習:改用其他model, 如https://huggingface.co/facebook/m2m100_1.2B, 檢視結果
Vector Embeddings & Vector Database
向量嵌入與向量資料庫
Vector Embeddings
Central to many NLP, recommendation, and search algorithms.

數值
物件、文字、圖像...
Vector Embeddings semantic similarity
Vector Space: semantic similarity
Barančíková, P., & Bojar, O. (2019). In search for linear relations in sentence embedding spaces.

Vector Embeddings types
- Word embeddings
- used to represent words in NLP
- Word2Vec, GloVe, FastText
- Sentence and document embeddings
- semantic meaning of sentences and documents.
- BERT, Doc2Vec
- Graph embeddings
- nodes and edges of graphs in vector space
- link prediction, node classification.
- Image embeddings
- images in a compact vector form
- image recognition, image classification.
Pavan Belagatti, Vector Embeddings Explained for Developers!
Vector Embeddings creating embeddings using Huggingface
pip install -U transformers torchfrom transformers import AutoTokenizer, AutoModel
import torch
def get_huggingface_embedding(text,
model_name='sentence-transformers/all-MiniLM-L6-v2'):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
inputs = tokenizer(text, return_tensors="pt", padding=True,
truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
# You can choose how to derive the final embeddings, e.g., mean pooling
embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
return embeddings
# Example usage
text = "Pavan is a developer evangelist."
embedding_huggingface = get_huggingface_embedding(text)
print(embedding_huggingface)Ranking of Vector DBMS


Ranking of Vector DBMS
Ranking of Vector DBMS
Source: Jayita Bhattacharyya, A Brief Comparison of Vector Databases


Source: Jayita Bhattacharyya, A Brief Comparison of Vector Databases
Ranking of Vector DBMS
Source: Jayita Bhattacharyya, A Brief Comparison of Vector Databases
- Open Source
- Hosted Solution
- Pricing
- Supported Vector Lengths
- Supported Distances: Similarity metrics
- Nearest Neighbor Search: speed and accuracy trade-offs.
- Clustering: useful for data exploration and analysis.
- Filtering & Aggregation: refine search results and summarize data patterns.
- Integrations: SDK, 支援的語言等等
- Cloud Providers
- Developer Experience
Ranking of Vector DBMS

向量資料庫: PostgreSQL + pgvector
安裝PostgreSQLWindows版

1. 下載安裝postgreSQL
安裝PostgreSQL WSL-Ubuntu
sudo apt updatesudo apt install postgresql postgresql-contrib -y1.1 更新套件列表
1.2 安裝postgreSQL
sudo systemctl start postgresql
sudo systemctl enable postgresql1.3 啟動並檢查 PostgreSQL 服務
管理PostgreSQL using pgAdmin4 (WSL-Ubuntu)
# 安裝repository的public key(if not done previously):
curl -fsS https://www.pgadmin.org/static/packages_pgadmin_org.pub | sudo gpg --dearmor -o /usr/share/keyrings/packages-pgadmin-org.gpg2.1 設定儲存庫(repository)
3. 啟動並檢查 PostgreSQL 服務
# 建立repository設定檔:
sudo sh -c 'echo "deb [signed-by=/usr/share/keyrings/packages-pgadmin-org.gpg] https://ftp.postgresql.org/pub/pgadmin/pgadmin4/apt/$(lsb_release -cs) pgadmin4 main" > /etc/apt/sources.list.d/pgadmin4.list && apt update'管理PostgreSQL using pgAdmin4 (WSL-Ubuntu)
# 安裝桌面版與webserver版
sudo apt install pgadmin42.2 安裝pgAdmin
# 設定webserver, 若有安裝pgadmin4-web:
sudo /usr/pgadmin4/bin/setup-web.sh
此帳號為資料庫之「超級管理員」
管理PostgreSQL using pgAdmin4 (WSL-Ubuntu)

輸入前頁設定之email與密碼
安裝PostgreSQLWindows版
1. 下載安裝postgreSQL

資料庫管理工具(GUI)
1. Stack Builder可取消
2. 預設已建立一個DB伺服器
3. 過程中可能要設定[超級管理員]密碼
管理PostgreSQL using pgAdmin4

也可另外新增伺服器
已安裝1伺服器
若未設定密碼,則點選後需設定[超級管理員
]的密碼
2. 開啟pgAdmin4,建立與管理伺服器
管理PostgreSQL using pgAdmin4
自訂名稱

管理PostgreSQL using pgAdmin4
網址

管理PostgreSQL using pgAdmin4
phAdmin的master password
2. 開啟pgAdmin4,建立與管理伺服器

管理PostgreSQL using pgAdmin4
輸入[超級管理員]的密碼

[超級管理員]: postgres
2. 開啟pgAdmin4,建立與管理伺服器
管理PostgreSQL using pgAdmin4
2. 開啟pgAdmin4,建立與管理伺服器

管理PostgreSQL using pgAdmin4
3. 建立使用者,設定相關權限

按右鍵建立使用者
管理PostgreSQL using pgAdmin4
3. 建立使用者,設定相關權限
設定帳號名稱

管理PostgreSQL using pgAdmin4
3. 建立使用者,設定相關權限
設定密碼

管理PostgreSQL using pgAdmin4
3. 建立使用者,設定相關權限
開啟此選項,保留其他預設值
