聊天機器人應用實務
OpenAI API
Outline
- 申請OpenAI API金鑰
OpenAI API定價2023/10
GPT-4

GPT-3.5 Turbo 旗艦模型

Token? 比word(單字)更小粒度的wordpieces (字根,字尾)

wordpieces
OpenAI API定價2023/10
Fine-tuning(微調) models

Fine-tuning?

特定領域知識
微調(監督式學習)
原始訓練資料
預訓練
基礎模型
微調模型
OpenAI API Key


前往 https://openai.com/ 登入 或 註冊後登入
登入
註冊後登入
OpenAI API Key

前往 https://openai.com/ 登入 或 註冊後登入
OpenAI API Key
產生API Key

OpenAI API Key

建立密鑰Create new secret key
為密鑰取名字
提供信用卡號碼
if necessary
OpenAI API Key
前往 https://openai.com/ 登入 或 註冊後登入

OpenAI API Key
API KEY應妥善保存?怎麼做?

角色
指令

在開始之前
- ChatGPT參數
GPT-3.5的可調參數

百分比

機率分佈
輸出
輸入1
GPT運作原理:預測下一個token的機率分佈
編碼
輸入2
程式開發前置作業(1/2)
python -m venv openai-env➊ 創建「虛擬環境」(optional, 可選)
openai-env\Scripts\activate
source openai-env/bin/activate➋ 啟動虛擬環境: 後續套件僅安裝在此環境內
Windows
Unix / macOS
程式開發前置作業(2/2)
set OPENAI_API_KEY "你的API_KEY"❸ 設定「環境變數」OPENAI_API_KEY
一次性作法: 開啟cmd,或VSCode的終端機輸入:

一次性作法: 開啟cmd,或VSCode的終端機輸入:
永久作法: 新增「環境變數」OPENAI_API_KEY
echo %OPENAI_API_KEY%確認設定值。重新開啟cmd,輸入:
程式開發前置作業(3/3)
❸ 設定「環境變數」OPENAI_API_KEY
export OPENAI_API_KEY='你的API_KEY'編輯環境變數:開啟Terminal
nano ~/.bash_profile 或 nano ~/.zshrc

存檔後,source ~/.bash_profile 或 source ~/.zshrc
echo $OPENAI_API_KEY確認設定值
from openai import OpenAI
import os
client = OpenAI(
# 預設是抓取環境變數 os.environ.get("OPENAI_API_KEY")
api_key= "你的API_KEY" # 申請來的API_KEY
)
response = client.completions.create(
model = "text-davinci-002", # 使用的模型
prompt = "將英文翻譯成法文:'Hello, how are you?'",
max_tokens = 50, # 控制生成文本的最大令牌數
temperature=0.7 # 調整多樣性,較高的值會產生更多變化的輸出
)
print(response.choices[0].text) # 印出GPT的回應範例1: 設定溫度與token
pip install --upgrade openaifrom openai import OpenAI
import os
client = OpenAI(
# 預設是抓取環境變數 os.environ.get("OPENAI_API_KEY")
api_key= "你的API_KEY" # 申請來的API_KEY
)
response_top_p = client.completions.create(
model="text-davinci-002",
prompt="將英文翻譯成法文: 'Hello, how are you?'",
max_tokens=50,
temperature=0.7,
top_p=0.8 # 控制選擇性,模型將考慮前80%的詞彙
)
print("Response with top_p:")
print(response_top_p.choices[0].text)
範例2:top_p 設定
from openai import OpenAI
client = OpenAI(
# 預設是抓取環境變數 os.environ.get("OPENAI_API_KEY")
api_key= "你的API_KEY" # 申請來的API_KEY
)
response_top_p = client.completions.create(
model="text-davinci-002",
prompt="將英文翻譯成法文: 'Hello, how are you?'",
max_tokens=50,
temperature=0.7,
frequency_penalty=0.5 #透過增加頻率懲罰來減少生成文本中常見詞彙的出現
)
print(response_top_p.choices[0].text)
範例3:frequency_penalty
from openai import OpenAI
import os
client = OpenAI(
# 預設是抓取環境變數 os.environ.get("OPENAI_API_KEY")
api_key= "你的API_KEY" # 申請來的API_KEY
)
response_top_p = client.completions.create(
model="text-davinci-002",
prompt="將英文翻譯成法文: 'Hello, how are you?'",
max_tokens=50,
temperature=0.7,
presence_penalty=0.5 #透過增加存在懲罰,增加特定詞彙在生成文本中的出現頻率
)
print(response_top_p.choices[0].text)
範例4:presence_penalty
API比較
client = OpenAI()
client.chat.completions
vs
client.completions
單一訊息
多則訊息
需搭配特定格式
更多範例練習
GPT之預訓練pretrained
遷移學習:預訓練 + 目標領域資料集收集、訓練

機器學習傳統做法
資料集1
資料集2
資料集3
任務1
任務2
任務3
兩階段: 非監督式、監督式
不同任務、不同資料集
Transfer Learning
來源領域任務
資料集S
目標領域任務
大量
資料集T
小量
預訓練unsupervised
微調supervised


GPT
PaLM
哪些可能的預訓練任務?(tasks)
哪些可能的任務?
情感分析 (Sentiment Analysis)
主題分析 (Topic Analysis/ Thematic Analysis)
新聞分類 (News Categorization)
多標籤分類(Multilabel Classification)
問答 (Question Answering)
自然語言推論 (Natural Language Inference )
自動摘要 (automatic Abstracting)
機器翻譯 (Machine Translation)
文本生成 (Text Generation)
文本分析常見任務

情感分析(Sentiment Analysis)
負面評價Negative
這家店的售後服務完全不行
餐點還不錯啦,但是還有改進空間
中性評價neutral
中性評價neutral
正面評價positive
很讚喔,超喜歡你們家的產品
分類問題
情感分析
文本分析常見任務



編碼
輸入層
隱藏層
輸出層
輸出結果分類
真實
政治宣傳
惡搞
反諷
假新聞
帶風向
片面資訊
新聞分類
分類問題
文本分析常見任務

機器翻譯
迴歸問題
Transformer
輸入英文: milk drink I
輸出法文: Je bois du lait <eos>
編碼器
解碼器
編碼器輸出
解碼器輸入
<sos>: 開始符號
<eos>: 結束符號
文本分析常見任務
文本生成

輸入: 一句話
輸出: 一篇短文!
經過多個語言模型...
迴歸問題

擷取
生成
轉換
程式碼
自然語言
結構化資料
文本類型
from openai import OpenAI
import os
client = OpenAI(
api_key= "你的API_KEY"
)
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "你的任務是根據英文文法,修改英文句子"
},
{
"role": "user",
"content": "She no went to the market."
}
],
temperature=0, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=256 # 最多256個token
)
print(response.choices[0].message) # 訊息資料結構
print(response.choices[0].message.content) # 訊息範例:修正文法transform轉換
from openai import OpenAI
client = OpenAI(
api_key= "你的API_KEY"
)
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "你的任務是將一則推文做情感分析為正面、中性或負面。"
},
{
"role": "user",
"content": "I loved the new Batman movie!"
}
],
temperature=0, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=256 # 最多256個token
)
print(response.choices[0].message) # 訊息資料結構
print(response.choices[0].message.content) # 訊息範例:情感分析extract擷取
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "你的任務將給你的文章,為小學二年級學生摘錄重點"
},
{
"role": "user",
"content": "木星是距離太陽第五顆行星,也是太陽系中最大的行星。"+
"它是一顆氣態巨行星,質量是太陽的千分之一,但是太陽系中所有其他行星"+
"質量總和的兩倍半。木星是夜空中肉眼可見的最亮天體之一,早在有記載的"+
"歷史之前就為古代文明所知。它以羅馬神朱庇特命名。從地球上觀察時"+
",木星的亮度足以使其反射光投射出可見的陰影,並且平均而言,木星"+
"是夜空中第三亮的自然物體,僅次於月球和金星。"
}
],
temperature=0, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=1024 # 最多1024個token
)
print(response.choices[0].message.content) # 訊息範例:文本摘要extract擷取
from openai import OpenAI
import os
_path = os.path.dirname(__file__) #目前程式所在資料夾
file_path = _path + '/' + '05-Hello.py' # 替換成你的Python檔案路徑
with open(file_path, 'r', encoding="utf-8") as file: #檔案可能讀取失敗
code = file.read() # 使用read()讀取整個檔案內容
client = OpenAI()
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "您將獲得一段程式碼,您的任務是以簡潔的方式解釋它。"
},
{
"role": "user",
"content": code # 前面讀取的檔案內容
}
],
temperature=0, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=1024 # 最多256個token
)
print(response.choices[0].message.content) # 訊息範例:解釋程式碼extract擷取
from openai import OpenAI
client = OpenAI(
api_key= "你的API_KEY"
)
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": "您將獲得產品描述和種子詞,任務則是產生產品名稱。"
},
{
"role": "user",
"content": "產品描述: A home milkshake maker\n" +
"種子詞: fast, healthy, compact."
}
],
temperature=0.8, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=256 # 最多256個token
)
print(response.choices[0].message.content) # 訊息範例:產品名稱發想generation生成
from openai import OpenAI
client = OpenAI(
api_key= "你的API_KEY"
)
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "建立一個包含 8 個問題的清單,用於訪問一位科幻作家。"
}
],
temperature=0.5, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=1024 # 最多1024個token
)
print(response.choices[0].message.content) # 訊息範例:面試提問generation生成
from openai import OpenAI
client = OpenAI(
api_key= "你的API_KEY"
)
response = client.chat.completions.create(
model = "gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": "建立包含頂級科幻電影以及發行年份的兩列 CSV。"
}
],
temperature=0.5, # 回應變化的多樣性,0:變化最少, 1:變化最多
max_tokens=256 # 最多1024個token
)
print(response.choices[0].message.content) # 訊息範例:試算表生成器generation生成
更多應用之一
Q & A
圖片來源1
圖片來源2
範例說明
爬取OpenAI網站內容
2. 擷取內容
3. 輸出結果(至檔案)


1. 遍訪連結
建立待訪堆疊
取得HTML回應碼
解析超連結
資料輸出
資料清理
範例說明

title
text

Word Embedding
詞彙
維度

建立資料結構

Q-A範例

Q-A範例摘要
def answer_question(
df,
model="gpt-3.5-turbo",
question="Am I allowed to publish model outputs to Twitter, without a human review?",
max_len=1800,
size="ada",
debug=False,
max_tokens=150,
stop_sequence=None
):
"""
根據最近似的自訂文字內容的context來回答問題
"""
context = create_context(
question, # 問題指令
df, # 自訂文字內容的context
max_len=max_len,
size=size,
)
# If debug, print the raw model response
if debug:
print("Context:\n" + context)
print("\n\n")
try:
# Create a chat completion using the question and context
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "Answer the question based on the context below, and if the question can't be answered based on the context, say \"I don't know\"\n\n"},
{"role": "user", f"content": "Context: {context}\n\n---\n\nQuestion: {question}\nAnswer:"}
],
temperature=0,
max_tokens=max_tokens,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=stop_sequence,
)
return response.choices[0].message.strip()
except Exception as e:
print(e)
return ""Q-A範例摘要
answer_question(df, question="What day is it?", debug=False)
answer_question(df, question="What is our newest embeddings model?")
answer_question(df, question="What is ChatGPT?")"I don't know."
'The newest embeddings model is text-embedding-ada-002.'
'ChatGPT is a model trained to interact in a conversational way. It is able to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests.'訓練資料收集透過網路爬蟲

資料爬蟲
資料爬蟲
資料清理
來源領域任務
資料集S
目標領域任務
大量
資料集T
小量
預訓練unsupervised
微調supervised
PaLM
訓練資料收集目的微調模型
圖片來源1
圖片來源2
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理
訓練資料收集方式網路爬蟲
能力1: 取得HTML回應碼?了解HTTP協定

網址(http request)
瀏覽器
Web 伺服器
HTML回應碼(http response)
爬蟲程式撰寫 了解HTTP的能力
http連線功能
➠
能力2: 解析超連結、其他HTML元素、網頁內容 ➠
HTML Parser(解析器)
以p元素為例
找出超連結元素A,屬性href的值 ➠ 待訪網址

元素
內容
開始標籤
結束標籤
屬性名稱
屬性值
爬蟲程式撰寫 HTML解析器
能力2: 解析超連結、其他HTML元素、網頁內容
Parser(解析器)
能力1: 取得HTML回應碼?了解HTTP協定
http連線功能
➠

圖片來源1



爬蟲程式撰寫 工具組合
能力3: 資料清理、資料輸出 ➠
資料處理工具
資料清理能力 Data Cleaning
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
圖片來源1
圖片來源2
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理

➊ 用不到、不相關
➋ 資料闕漏
刪除一筆、刪除一欄、補遺
刪除欄位
➌ 資料型別錯誤
重填正確型別資料
資料清理使用pandas DataFrame與Numpy
讀取檔案
Web

●●●
建立資料結構
資料清理
輸出
●●●
資料庫

Data Frame

一張表格

Data Frame
欄位名稱
有無索引
資料闕漏

pip install pandas
pip install numpy
Pandas安裝
編碼問題
Fine-tune預訓練模型了解輸入輸出
96個Transformer解碼器
句子 ➠ 預測下一個字
需進行編碼:
深度學習文字任務編碼問題
訓練模型擅長直接處理數值資料

[編碼方法1] One-hot encoding: 一字一編號
<SOS> I played the piano
1
2
3
4
5
6
7
8
編碼
輸入層
隱藏層
輸出層
以向量表示
編號
詞彙
<SOS>
編號
0 0 0 0 0 0 0 0
One-hot encoding問題: 詞彙很多(資料稀疏)、編碼與語意無關...
dog

文本分析的詞彙很多

字詞編碼:向量很長、資料稀疏
向量長度 =詞彙數量(10000)
one-hot encoding
深度學習文字任務編碼問題
One-hot encoding問題: 詞彙很多(資料稀疏)、編碼與語意無關...
one-hot encoding
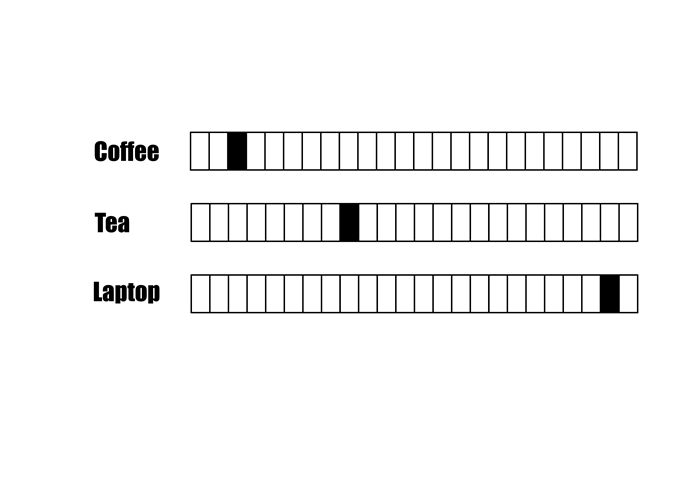
字彙語意相近,不一定有比較近的「距離」
近?
遠?
Coffee跟Laptop的距離比Tea近?
深度學習文字任務編碼問題
[編碼方法2]: Word Embedding(詞嵌入)
字彙語意相近,編碼必須給予比較近的「距離」

深度學習文字任務編碼問題
[編碼方法2]: 常見的Word Embedding方法—Word2Vec
Word2Vec學習大量詞彙,將字詞對應到100-300維度的空間

100-300
Word Embedding
深度學習文字任務編碼問題
文本分析任務Word Embedding演算法
Word Embedding
詞彙
7D to 2D
7D to 2D
維度
Word2Vec
Google Bard 免費
- MakerSuite