Python程式設計
Lesson 5: 串列
Outline
- 資料儲存型態
- 串列 Part 1: 簡介
- 串列 Part 2: 功能函式
- 元組 (Tuple)
'王小明'
name ➞
記憶體空間
37
y ➞
2.35
w ➞
變數
字串 string: 一串文字
整數 int: 正負整數
浮點數 float: 正負實數
資料型態
資料儲存型態 (1/3)
- 變數與資料型態
變數儲存的內容 決定該變數的「資料型態」
兩個不同「資料型態」的變數:可能無法直接運算(需強制轉換型態)
資料儲存型態 (2/3)
需要大量變數的問題:
- 儲存50位學生的期中考, 期末考, 平時成績
- 50 * 3 = 150 個變數 ?
Ans: 使用「容器」類型的資料型態
- Container(容器):
一個變數名稱,搭配索引值(從o開始的整數)
用以儲存類型重複的都個資料,例score[0], score[1]...
score1 = 100 # 第一位學生
score2 = 79
score3 = 60
score4 = 75 # 第二位學生
....
score150 = 88 # 第五十位學生資料儲存型態 (3/3)
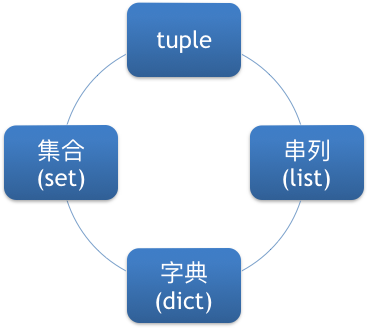
Python 的4種資料儲存型態
內含多個項目
可修改
內含多個項目
不可修改
元組
內含多個內容相異的項目
無先後次序
內含多個key-value對
可修改
有先後次序
串列 Part 1
認識串列
串列 宣告(1/15)
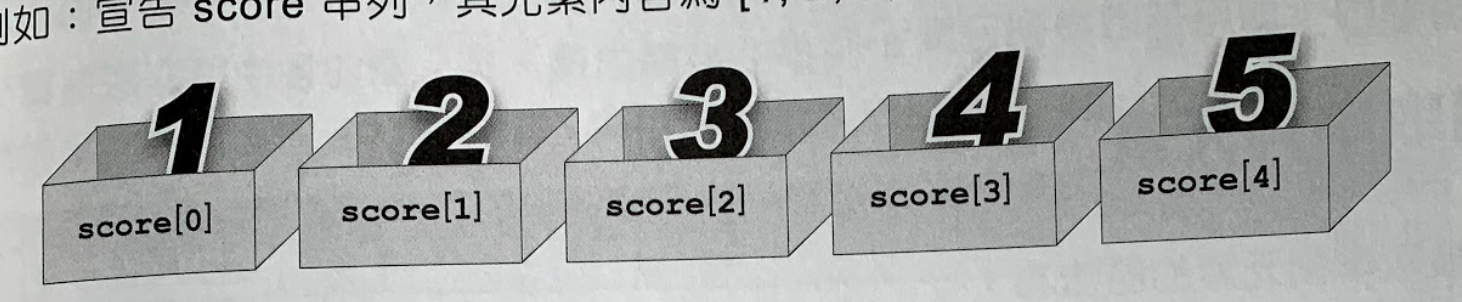
scores = [1, 2, 3, 4, 5] # 建立5個元素串列
print(scores) # 印出所有元素
print(scores[3]) # 印出第4個元素串列 (list) 宣告:
串列名稱 = [元素1, 元素2, 元素3..., 元素N]- 串列:以[ ]包含所有項目, 逗點分隔
- 讀取個別元素:串列名稱[索引值]
- 元素1~N依序為:串列名稱[0],...串列名稱[N-1] (索引值從0起算)
範例
[1, 2, 3, 4, 5]
4
執行結果
串列宣告(2/15)
串列 (list) 建立初值:
scores = [1, 2, 3, 4, 5] # 整數串列
menu = ['拿鐵', '美式', '卡布奇諾'] # 字串串列
cart = ['Python筆記本', 500.0, 3 ] # 混合各種型別
enroll = [] # 空串列, 例如活動報名一開始未有名單範例
建立初值
串列宣告(3/15)
# ch6_1.py
james = [23, 19, 22, 31, 18] # 定義james串列
print("列印james串列", james)
James = ['Lebron James',23, 19, 22, 31, 18] # 定義James串列
print("列印James串列", James)
fruits = ['apple', 'banana', 'orange'] # 定義fruits串列
print("列印fruits串列", fruits)
cfruits = ['蘋果', '香蕉', '橘子'] # 定義cfruits串列
print("列印cfruits串列", cfruits)
ielts = [5.5, 6.0, 6.5] # 定義IELTS成績串列
print("列印IELTS成績", ielts)
# 列出串列資料型態
print("串列james資料型態是: ",type(james))
範例
列印james串列 [23, 19, 22, 31, 18]
列印James串列 ['Lebron James', 23, 19, 22, 31, 18]
列印fruits串列 ['apple', 'banana', 'orange']
列印cfruits串列 ['蘋果', '香蕉', '橘子']
列印IELTS成績 [5.5, 6.0, 6.5]
串列james資料型態是: <class 'list'>
執行結果
串列讀取串列元素(4/15)
範例
name_list = [23, 18, 22, 31, 18]
print(name_list[0]) # 印出第一個元素(編號0)menu = ['拿鐵', '美式', '卡布奇諾'] # 字串串列
cart = ['Python筆記本', 500.0, 3 ] # 混合各種型別
print(menu[-1]) # 從後算起第1個
print(cart[-2]) # 從後算起第2個 範例
元素序號可指定負數:由後算起
卡布奇諾
500.0
執行結果
讀取元素
讀取串列個別元素的方式: 串列名稱[i]
i: 從0開始算起
串列讀取串列元素(5/15)
# ch6_2.py
james = [23, 19, 22, 31, 18] # 定義james串列
print("列印james第1場得分", james[0])
print("列印james第2場得分", james[1])
print("列印james第3場得分", james[2])
print("列印james第4場得分", james[3])
print("列印james第5場得分", james[4])範例
列印james第1場得分 23
列印james第2場得分 19
列印james第3場得分 22
列印james第4場得分 31
列印james第5場得分 18
執行結果
串列串列切片(6/15)
取出部分元素:
取出從start到end-1位置的內容
其他用法:
串列名稱[start:end]# name_list為某串列變數名稱
name_list[start:end] # 從start到n-1
name_list[:n] # 取得前n個(0~n-1)
name_list[n:] # 取得n到串列最後
name_list[-n:] # 取得串列後n個
name_list[:] # 取得所有元素(複製)# ch6_2_2.py
james = [23, 19, 22, 31, 18] # 定義james串列
print("列印james第1-3場得分", james[0:3])
print("列印james第2-4場得分", james[1:4])
print("列印james第1,3,5場得分", james[0:6:2])串列串列切片(7/15)
範例
# ch6_3.py
warriors = ['Curry', 'Durant', 'Iquodala', 'Bell', 'Thompson']
first3 = warriors[:3]
print("前3名球員",first3)
n_to_last = warriors[1:]
print("球員索引1到最後",n_to_last)
last3 = warriors[-3:]
print("後3名球員",last3)前3名球員 ['Curry', 'Durant', 'Iquodala']
球員索引1到最後 ['Durant', 'Iquodala', 'Bell', 'Thompson']
後3名球員 ['Iquodala', 'Bell', 'Thompson']
執行結果
列出球隊(1)前三名球員、(2) 從索引1到最後隊員、以及(3) 後3名隊員的子串列
串列串列切片(8/15)
範例
# ch6_4.py
warriors = ['Curry', 'Durant', 'Iquodala', 'Bell', 'Thompson']
print("最後一名球員",warriors[-1])
james = [23, 19, 22, 31, 18]
print("最後一場得分",james[-1])
mixs = [9, 20.5, 'DeepStone']
print("最後一筆元素",mixs[-1])最後一名球員 Thompson
最後一場得分 18
最後一筆元素 DeepStone
執行結果
串列索引值是-1:代表最後一個元素
列出各串列最後一個元素
串列max()、min()與sum() (9/15)
Python內建統計運算函數:適用於全是數值內容的串列
最高得分 = 31
最低得分 = 18
得分總計 = 113
執行結果
範例
# ch6_5.py
james = [23, 19, 22, 31, 18] # 定義james的5場比賽得分
print("最高得分 = ", max(james))
print("最低得分 = ", min(james))
print("得分總計 = ", sum(james))列出五場比賽中最高、最低、以及總得分
串列串列元素個數(10/15)
範例
# ch6_7.py
james = [23, 19, 22, 31, 18] # 定義james的5場比賽得分
games = len(james) # 獲得場次數據
print("經過 %d 比賽最高得分 = " % games, max(james))
print("經過 %d 比賽最低得分 = " % games, min(james))
print("經過 %d 比賽得分總計 = " % games, sum(james))經過 5 比賽最高得分 = 31
經過 5 比賽最低得分 = 18
經過 5 比賽得分總計 = 113
執行結果
len()函式: 回傳串列元素個數
列出多場比賽中最高、最低、以及總得分,並加列總場數
串列更改串列元素的內容(11/15)
scores = [1, 2, 3, 4, 5] # 整數串列
print('修改前', scores[2]) # 指定元素序號2(第3個元素)
scores[2] = 100
print('修改後', scores[2])
修改前 3
修改後 100
執行結果
修改元素內容
使用 串列名稱[索引值] 即可更改串列元素內容
# ch6_8.py
james = [23, 19, 22, 31, 18] # 定義james的5場比賽得分
print("舊的James比賽分數", james)
james[4] = 28
print("新的James比賽分數", james)# ch6_9.py
cars = ['Toyota', 'Nissan', 'Honda']
print("舊汽車銷售品牌", cars)
cars[1] = 'Ford' # 更改第二筆元素內容
print("新汽車銷售品牌", cars)串列串列相加(12/15)
# ch6_10.py
cars1 = ['Toyota', 'Nissan', 'Honda']
print("舊汽車銷售品牌", cars1)
cars2 = ['Audi', 'BMW']
cars1 += cars2
print("新汽車銷售品牌", cars1) 舊汽車銷售品牌 ['Toyota', 'Nissan', 'Honda']
新汽車銷售品牌 ['Toyota', 'Nissan', 'Honda', 'Audi', 'BMW']
執行結果
串列相加:串列串接起來
# ch6_11.py
num1 = [1, 3, 5]
num2 = [2, 4, 6]
num3 = num1 + num2 # 字串為主的串列相加
print(num3)[1, 3, 5, 2, 4, 6]
執行結果
串列串列乘以數字(13/15)
# ch6_12.py
cars = ['toyota', 'nissan', 'honda']
nums = [1, 3, 5]
carslist = cars * 3 # 串列乘以數字
print(carslist)
numslist = nums * 5 # 串列乘以數字
print(numslist) ['toyota', 'nissan', 'honda', 'toyota', 'nissan', 'honda', 'toyota', 'nissan', 'honda']
[1, 3, 5, 1, 3, 5, 1, 3, 5, 1, 3, 5, 1, 3, 5]
執行結果
串列乘以數字:重複串接串列內容
串列刪除串列元素(14/15)
# name_list是某串列變數
del name_list[i] # 刪除索引i的串列元素
del name_list[start:end] # 刪除start到end-1的串列元素
del name_list[start:end:step] # 刪除start到end-1之間,每隔step位置的元素
del name_list # 刪除整個串列 2018年初NBA勇士隊主將陣容 ['Curry', 'Durant', 'Iquodala', 'Bell', 'Thompson']
2018年末NBA勇士隊主將陣容 ['Curry', 'Durant', 'Iquodala', 'Thompson']
執行結果
刪除某個串列元素: del 串列名稱[索引值]
刪除整個串列: del 串列名稱
# ch6_14.py
warriors = ['Curry', 'Durant', 'Iquodala', 'Bell', 'Thompson']
print("2018年初NBA勇士隊主將陣容", warriors)
del warriors[3] # 不明原因離隊
print("2018年末NBA勇士隊主將陣容", warriors)範例
隊員Bell離隊,列出離隊前後的隊員名字
串列判斷空串列(15/15)
建立空串列的方式: 串列變數 = []
# ch6_16.py
cars = ['Toyota', 'Nissan', 'Honda']
print("cars串列長度是 = %d" % len(cars))
if len(cars) != 0:
del cars[0]
print("刪除cars串列元素成功")
print("cars串列長度是 = %d" % len(cars))
else:
print("cars串列內沒有元素資料")
nums = []
print("nums串列長度是 = %d" % len(nums))
if len(nums) != 0:
del nums[0]
print("刪除nums串列元素成功")
else:
print("nums串列內沒有元素資料")範例
逐一刪除串列最開頭的元素,直到沒有內容時,則刪除之
提示:使用len()判斷串列是否還有元素
串列練習
練習1:設定三科分數,並逐一印出
scores = [60, 70, 80] # 整數串列
print(scores[0])
print(scores[1])
print(scores[2]) 練習2:呈上題, 修改第2個分數為85分
練習3:算出3科的平均分數
scores = [60, 70, 80] # 整數串列
print((scores[0] + scores[1] + scores[2]) / 3)scores = [60, 70, 80] # 整數串列
print( (scores[0]+scores[1]+ scores[2]) / len(scores) )len(串列): 串列元素個數
或
Q: 若元素個數很多?
A: 使用迴圈!
串列的物件導向觀念
- 物件(Object): 所有資料皆是物件
- 供物件使用的函數:方法(method)
# 呼叫供物件使用的函數
物件.方法() 字串物件的方法(1/2)
# ch6_17.py
strN = "DeepStone" # strN為「字串物件」
strU = strN.upper( ) # 改成大寫
strL = strN.lower( ) # 改成小寫
strT = strN.title( ) # 改成第一個字母大寫其他小寫
print("大寫輸出:",strU,"\n小寫輸出:",strL,"\n第一字母大寫:",strT)字串物件擁有的功能:轉大寫、轉小寫、第一個字母轉大寫
大寫輸出: DEEPSTONE
小寫輸出: deepstone
第一字母大寫: Deepstone
執行結果
字串物件的方法(2/2)
# ch6_18.py
strN = " DeepStone "
strL = strN.lstrip( ) # 刪除字串左邊多餘空白
strR = strN.rstrip( ) # 刪除字串右邊多餘空白
strB = strN.lstrip( ) # 先刪除字串左邊多餘空白
strB = strB.rstrip( ) # 再刪除字串右邊多餘空白
strO = strN.strip( ) # 一次刪除頭尾端多餘空白
print("/%s/" % strN)
print("/%s/" % strL)
print("/%s/" % strR)
print("/%s/" % strB)
print("/%s/" % strO)字串物件擁有的功能:刪除開頭或結尾多餘的空白字元
/ DeepStone /
/DeepStone /
/ DeepStone/
/DeepStone/
/DeepStone/
執行結果
獲取系統內建方法的函式:dir()
# 列出物件有哪些方法可以使用
dir(物件名稱)
進入python環境後,建立字串變數string
dir(string) → 列出string變數可用的方法
練習:列出串列可用的方法
串列功能
- 搜尋: index()
- 計數: count()
- 新增: append(), insert()
- 刪除: remove(), pop(), del
- 排序: sort(), sorted()
- 反轉: reverse()
串列功能 搜尋與計數(1/11)
搜尋:某個元素是否出現?
- 回傳串列的索引值
- 串列.index(s),其中s ←要找的元素值
subjects = ['國文', '英文', '數學']
index = subjects.index('國文') # '國文'在串列第一次出現的位置,從0起算
print(index)0
執行結果
第2次以後出現的位置,無法直接用index()找出
index()
# ch6_29.py
cars = ['toyota', 'nissan', 'honda']
search_str = 'nissan'
i = cars.index(search_str)
print("所搜尋元素 %s 第一次出現位置索引是 %d" % (search_str, i))
nums = [7, 12, 30, 12, 30, 9, 8]
search_val = 30
j = nums.index(search_val)
print("所搜尋元素 %s 第一次出現位置索引是 %d" % (search_val, j))串列功能 搜尋與計數(2/11)
scores = [80, 78, 60, 83, 60]
print(scores.count(60))
print(scores.count(90))2
0
執行結果
計數:某個元素是否出現?
- 回傳串列中某元素總共出現多少次
- 串列.count(s),其中s ←要找的元素值
count()
# ch6_31.py
cars = ['toyota', 'nissan', 'honda']
search_str = 'nissan'
num1 = cars.count(search_str)
print("所搜尋元素 %s 出現 %d 次" % (search_str, num1))
nums = [7, 12, 30, 12, 30, 9, 8]
search_val = 30
num2 = nums.count(search_val)
print("所搜尋元素 %s 出現 %d 次" % (search_val, num2))所搜尋元素 nissan 出現 1 次
所搜尋元素 30 出現 2 次
執行結果
串列功能 元素新增/刪除(3/11)
list1 = [1,2,3,4,5,6] # 元素0~5
list1.append("新元素") # 加在串列最後
print(list1[6]) # 印出"新元素"
print(len(list1)) # list1的長度: 7新元素
7
執行結果
增加串列元素?
- scores串列: 儲存所有測驗分數
- 每當多一次測驗分數: 加入scores串列
元素值: 加在串列最後
insert(): 加在指定位置
串列.append(元素值)串列.insert(索引值,元素值)list1 = [1,2,3,4,5,6] # 元素0~5
list1.insert(3, "新元素")# 加在索引值位置
print(list1[3]) # 印出"新元素"
print(len(list1)) # list1的長度: 7新元素
7
執行結果
串列功能 元素新增/刪除(4/11)
# ch6_20.py
cars = []
print("目前串列內容 = ",cars)
cars.append('Honda')
print("目前串列內容 = ",cars)
cars.append('Toyota')
print("目前串列內容 = ",cars)
cars.append('Ford')
print("目前串列內容 = ",cars)執行結果
範例:使用append()增加3筆元素內容
目前串列內容 = []
目前串列內容 = ['Honda']
目前串列內容 = ['Honda', 'Toyota']
目前串列內容 = ['Honda', 'Toyota', 'Ford']
串列功能 元素新增/刪除(5/11)
# ch6_21.py
cars = ['Honda','Toyota','Ford']
print("目前串列內容 = ",cars)
print("在索引1位置插入Nissan")
cars.insert(1,'Nissan')
print("新的串列內容 = ",cars)
print("在索引0位置插入BMW")
cars.insert(0,'BMW')
print("最新串列內容 = ",cars)
執行結果
範例:使用insert()插入元素
目前串列內容 = ['Honda', 'Toyota', 'Ford']
在索引1位置插入Nissan
新的串列內容 = ['Honda', 'Nissan', 'Toyota', 'Ford']
在索引0位置插入BMW
最新串列內容 = ['BMW', 'Honda', 'Nissan', 'Toyota', 'Ford']
串列功能 元素新增/刪除(6/11)
list1 = [1,2,3,4,5,6] # 元素0~5
n = list1.pop(2) # list1=[1,2,4,5,6]
n = list1.pop() # list1=[1,2,,4,5]刪除串列元素?
- 購物車串列: 去除不想買的項目
- 財產管理: 報廢項目從串列中去除
pop(): 取出元素後, 再移除
終止: 不包含
串列.pop(索引值)
串列.pop() # 移除最後元素del 串列[索引值]
del 串列[開始,終止,間隔]list1 = [1,2,3,4,5,6] # 元素0~5
del list1[1]
print(list1) # [1, 3, 4, 5, 6]
list2 = [1,2,3,4,5,6] # 元素0~5
del list2[1:5:2] # 刪除索引值1,3
print(list2) # [1, 3, 5, 6][1, 3, 4, 5, 6]
[1, 3, 5, 6]
執行結果
串列功能 元素新增/刪除(7/11)
# ch6_23.py
cars = ['Honda','bmw','Toyota','Ford','bmw']
print("目前串列內容 = ",cars)
print("使用remove( )刪除串列元素")
expensive = 'bmw'
cars.remove(expensive) # 刪除第一次出現的元素bmw
print("所刪除的內容是: " + expensive.upper( ) + " 因為太貴了" )
print("新的串列內容",cars)執行結果
目前串列內容 = ['Honda', 'bmw', 'Toyota', 'Ford', 'bmw']
使用remove( )刪除串列元素
所刪除的內容是: BMW 因為太貴了
新的串列內容 ['Honda', 'Toyota', 'Ford', 'bmw']
串列.remove(元素值)刪除串列元素?
移除串列中「第一個」與「元素值」相同的元素
串列功能 元素新增/刪除(8/11)
# ch6_22.py
cars = ['Honda','Toyota','Ford','BMW']
print("目前串列內容 = ",cars)
print("使用pop( )刪除串列元素")
popped_car = cars.pop( ) # 刪除串列末端值
print("所刪除的串列內容是 : ", popped_car)
print("新的串列內容 = ",cars)
print("使用pop(1)刪除串列元素")
popped_car = cars.pop(1) # 刪除串列索引為1的值
print("所刪除的串列內容是 : ", popped_car)
print("新的串列內容 = ",cars)執行結果
範例:使用pop()刪除元素
目前串列內容 = ['Honda', 'Toyota', 'Ford', 'BMW']
使用pop( )刪除串列元素
所刪除的串列內容是 : BMW
新的串列內容 = ['Honda', 'Toyota', 'Ford']
使用pop(1)刪除串列元素
所刪除的串列內容是 : Toyota
新的串列內容 = ['Honda', 'Ford']
串列功能 排序與反轉(9/11)
list1 = [40, 30, 80, 70, 50]
list1.sort()
print(list1)串列元素排序?
- 成績由高到低排列
- 姓名依第一個字母排列
串列.sort() #由小到大串列.reverse() #順序反轉list1 = [40, 30, 80, 70, 50]
list1.reverse()
print(list1)[50, 70, 80, 30, 40]
執行結果
排序:升冪/降冪
由低到高/由高到低
反轉
低到高➡
➡高到低
[30, 40, 50, 70, 80]
執行結果
串列功能 排序與反轉(10/11)
串列.sort() #由小到大
串列.reverse() #反轉由大到小排序?
list1 = [40, 30, 80, 70, 50]
list1.sort()
list1.reverse()
print(list1)[80, 70, 50, 40, 30]
執行結果
sort()會重排列內容, 函式sorted(串列): 保留原串列, 另產生新串列
串列2 = sorted(串列1, reverse=True)由大到小: reverse=True
list1 = [40, 30, 80, 70, 50]
list2=sorted(list1, reverse=True)
print(list2)
print(list1)[80, 70, 50, 40, 30]
[40, 30, 80, 70, 50]
執行結果
串列功能 排序與反轉(11/11)
# ch6_25.py
cars = ['honda','bmw','toyota','ford']
print("目前串列內容 = ",cars)
print("使用sort( )由小排到大")
cars.sort( )
print("排序串列結果 = ",cars)
nums = [5, 3, 9, 2]
print("目前串列內容 = ",nums)
print("使用sort( )由小排到大")
nums.sort( )
print("排序串列結果 = ",nums)執行結果
目前串列內容 = ['honda', 'bmw', 'toyota', 'ford']
使用sort( )由小排到大
排序串列結果 = ['bmw', 'ford', 'honda', 'toyota']
目前串列內容 = [5, 3, 9, 2]
使用sort( )由小排到大
排序串列結果 = [2, 3, 5, 9]
範例:數字與英文字元元素排序的應用
串列功能 其他範例
範例:重新設計範例6-25,將串列元素由大排到小
# ch6_26.py
cars = ['honda','bmw','toyota','ford']
print("目前串列內容 = ",cars)
print("使用sort( )由大排到小")
cars.sort(reverse=True)
print("排序串列結果 = ",cars)
nums = [5, 3, 9, 2]
print("目前串列內容 = ",nums)
print("使用sort( )由大排到小")
nums.sort(reverse=True)
print("排序串列結果 = ",nums)執行結果
目前串列內容 = ['honda', 'bmw', 'toyota', 'ford']
使用sort( )由大排到小
排序串列結果 = ['toyota', 'honda', 'ford', 'bmw']
目前串列內容 = [5, 3, 9, 2]
使用sort( )由大排到小
排序串列結果 = [9, 5, 3, 2]
串列功能 串列內含串列
範例
# ch6_32.py
James = [['Lebron James','SF','12/30/84'],23,19,22,31,18] # 定義James串列
games = len(James) # 求元素數量
score_Max = max(James[1:games]) # 最高得分
i = James.index(score_Max) # 場次
name = James[0][0]
position = James[0][1]
born = James[0][2]
print("姓名 : ", name)
print("位置 : ", position)
print("出生日期 : ", born)
print("在第 %d 場得最高分 %d" % (i, score_Max))執行結果
姓名 : Lebron James
位置 : SF
出生日期 : 12/30/84
在第 4 場得最高分 31
num = [1, 2, 3, 4, 5, [6, 7, 8]] #前5個元素是整數,第6個元素是串列
景點 = ['牛津學堂', '新北市', [25.17602,121.4322963]] # 第三個元素經緯度串列內含串列
串列功能 再談append()
# ch6_33.py
cars1 = ['toyota', 'nissan', 'honda']
cars2 = ['ford', 'audi']
print("原先cars1串列內容 = ", cars1)
print("原先cars2串列內容 = ", cars2)
cars1.append(cars2)
print("執行append( )後串列cars1內容 = ", cars1)
print("執行append( )後串列cars2內容 = ", cars2)執行結果
原先cars1串列內容 = ['toyota', 'nissan', 'honda']
原先cars2串列內容 = ['ford', 'audi']
執行append( )後串列cars1內容 = ['toyota', 'nissan', 'honda', ['ford', 'audi']]
執行append( )後串列cars2內容 = ['ford', 'audi']
串列A.append(串列B) # 將串列B接在串列A最後使用append()將串列加到另一串列中
串列功能 extend()
# ch6_34.py
cars1 = ['toyota', 'nissan', 'honda']
cars2 = ['ford', 'audi']
print("原先cars1串列內容 = ", cars1)
print("原先cars2串列內容 = ", cars2)
cars1.extend(cars2)
print("執行extend( )後串列cars1內容 = ", cars1)
print("執行extend( )後串列cars2內容 = ", cars2)執行結果
原先cars1串列內容 = ['toyota', 'nissan', 'honda']
原先cars2串列內容 = ['ford', 'audi']
執行extend( )後串列cars1內容 = ['toyota', 'nissan', 'honda', 'ford', 'audi']
執行extend( )後串列cars2內容 = ['ford', 'audi']
串列A.extend(串列B) # 將串列B的元素依序接在串列A最後extend(): 擴充串列內容。留意與append()的差別!
串列的拷貝淺拷貝(1/4)
# ch6_35.py
mysports = ['basketball', 'baseball'] # 我喜歡的運動
friendsports = mysports # 指定運算: 設定朋友喜歡的運動
print("我喜歡的運動 = ", mysports)
print("我朋友喜歡的運動 = ", friendsports)執行結果
原我喜歡的運動 = ['basketball', 'baseball']
我朋友喜歡的運動 = ['basketball', 'baseball']
我喜歡的最新運動 = ['basketball', 'baseball', 'football', 'soccer']
我朋友喜歡的最新運動 = ['basketball', 'baseball', 'football', 'soccer']
我與朋友有共同喜歡的運動
但兩人喜歡的項目略有差異:
# ch6_36.py
mysports = ['basketball', 'baseball']
friendsports = mysports
print("我喜歡的運動 = ", mysports)
print("我朋友喜歡的運動 = ", friendsports)
mysports.append('football') # 各自加上喜歡的項目
friendsports.append('soccer') # 各自加上喜歡的項目
print("我喜歡的最新運動 = ", mysports)
print("我朋友喜歡的最新運動 = ", friendsports)結果卻同時增加兩項?
串列的拷貝淺拷貝(2/4)
mysports = ['basketball', 'baseball'] # 我喜歡的運動
friendsports = mysports # 指定運算: 設定朋友喜歡的運動原因在於:指定運算拷貝的是「變數位址」,而非「內容」
| basketball | baseball | ||
mysports
位址:49861976
位址:49862008
位址:49862040
....
49861976
friendsports
49861976
串列的拷貝淺拷貝(3/4)
執行結果
列出mysports位址 = 1891867255432
列出friendsports位址 = 1891867255432
我喜歡的運動 = ['basketball', 'baseball']
我朋友喜歡的運動 = ['basketball', 'baseball']
-- 新增運動項目後 --
列出mysports位址 = 1891867255432
列出friendsports位址 = 1891867255432
我喜歡的最新運動 = ['basketball', 'baseball', 'football', 'soccer']
我朋友喜歡的最新運動 = ['basketball', 'baseball', 'football', 'soccer']
id(變數名稱): 可獲得變數的位址,藉此可檢查變數是否指向相同位址
# ch6_37.py
mysports = ['basketball', 'baseball']
friendsports = mysports
print("列出mysports位址 = ", id(mysports))
print("列出friendsports位址 = ", id(friendsports))
print("我喜歡的運動 = ", mysports)
print("我朋友喜歡的運動 = ", friendsports)
mysports.append('football')
friendsports.append('soccer')
print(" -- 新增運動項目後 -- ")
print("列出mysports位址 = ", id(mysports))
print("列出friendsports位址 = ", id(friendsports))
print("我喜歡的最新運動 = ", mysports)
print("我朋友喜歡的最新運動 = ", friendsports)串列的拷貝淺拷貝(4/4)
淺拷貝(shallow copy): 拷貝內容,而非位址
# ch6_38.py
mysports = ['basketball', 'baseball']
friendsports = mysports[:]
print("列出mysports位址 = ", id(mysports))
print("列出friendsports位址 = ", id(friendsports))
print("我喜歡的運動 = ", mysports)
print("我朋友喜歡的運動 = ", friendsports)
mysports.append('football')
friendsports.append('soccer')
print(" -- 新增運動項目後 -- ")
print("列出mysports位址 = ", id(mysports))
print("列出friendsports位址 = ", id(friendsports))
print("我喜歡的最新運動 = ", mysports)
print("我朋友喜歡的最新運動 = ", friendsports)friendsports = mysports[:]字串與字元序列(1/5)
建立字串時,除了字串處理外,也可取得個別字元(character)
字串 = "Python"| P | y | t | h | o | n |
| 字串[0] | 字串[1] | 字串[2] | 字串[3] | 字串[4] | 字串[5] |
字串
"Python"
字串相當於字元序列
字串與字元序列(2/5)
淺拷貝(shallow copy): 拷貝內容,而非位址
# ch6_39.py
string = "Python"
# 正值索引
print(" string[0] = ", string[0],
"\n string[1] = ", string[1],
"\n string[2] = ", string[2],
"\n string[3] = ", string[3],
"\n string[4] = ", string[4],
"\n string[5] = ", string[5])
# 負值索引
print(" string[-1] = ", string[-1],
"\n string[-2] = ", string[-2],
"\n string[-3] = ", string[-3],
"\n string[-4] = ", string[-4],
"\n string[-5] = ", string[-5],
"\n string[-6] = ", string[-6])
# 多重指定觀念
s1, s2, s3, s4, s5, s6 = string
print("多重指定觀念的輸出測試 = ",s1,s2,s3,s4,s5,s6) string[0] = P
string[1] = y
string[2] = t
string[3] = h
string[4] = o
string[5] = n
string[-1] = n
string[-2] = o
string[-3] = h
string[-4] = t
string[-5] = y
string[-6] = P
多重指定觀念的輸出測試 = P y t h o n
執行結果
字串與字元序列(3/5)
範例:字串內容切片
# ch6_40.py
string = "Deep Learning" # 定義字串
print("列印string第1-3元素 = ", string[0:3])
print("列印string第2-4元素 = ", string[1:4])
print("列印string第2,4,6元素 = ", string[1:6:2])
print("列印string第1到最後元素 = ", string[1:])
print("列印string前3元素 = ", string[0:3])
print("列印string後3元素 = ", string[-3:])列印string第1-3元素 = Dee
列印string第2-4元素 = eep
列印string第2,4,6元素 = epL
列印string第1到最後元素 = eep Learning
列印string前3元素 = Dee
列印string後3元素 = ing
執行結果
字串與字元序列(4/5)
字串函數或方法
# ch6_41.py
string = "Deep Learning" # 定義字串
strlen = len(string)
print("字串長度", strlen)
maxstr = max(string)
print("字串最大的unicode碼值和字元", ord(maxstr), maxstr)
minstr = min(string)
print("字串最小的unicode碼值和字元", ord(minstr), minstr)字串長度 13
字串最大的unicode碼值和字元 114 r
字串最小的unicode碼值和字元 32
執行結果
| 函數 | 說明 |
|---|---|
| len() | 計算字串長度 |
| max() | 最大值 |
| min() | 最小值 |
ord(字元): 回傳字元的unicode值
字串與字元序列(5/5)
split(): 將字串以空格為單位,拆分為串列
# ch6_41_1.py
str1 = "Silicon Stone Education"
str2 = "DeepStone"
str3 = "深石數位"
sList1 = str1.split() # 字串轉成串列
sList2 = str2.split() # 字串轉成串列
sList3 = str3.split() # 字串轉成串列
print(str1, " 串列內容是 ", sList1) # 列印串列
print(str1, " 串列字數是 ", len(sList1)) # 列印字數
print(str2, " 串列內容是 ", sList2) # 列印串列
print(str2, " 串列字數是 ", len(sList2)) # 列印字數
print(str3, " 串列內容是 ", sList3) # 列印串列
print(str3, " 串列字數是 ", len(sList3)) # 列印字數['You', 'are', 'a', 'good', 'student']
字串 = "You are a good student"
串列 = (字串.split()
print(串列)判斷是否存在於串列中in與not in(1/2)
範例:輸入字元,並判斷是否該字元出現在'deepstone'字串當中
# ch6_42.py
password = 'deepstone'
ch = input("請輸入字元 = ")
print("in運算式")
if ch in password:
print("輸入字元在密碼中")
else:
print("輸入字元不在密碼中")
print("not in運算式")
if ch not in password:
print("輸入字元不在密碼中")
else:
print("輸入字元在密碼中")請輸入字元 = a
in運算式
輸入字元不在密碼中
not in運算式
輸入字元不在密碼中
執行結果
判斷是否存在於串列中in與not in(2/2)
範例:輸入水果名稱,如未在串列中,則加入串列;如已在串列中,則印出提示訊息
# ch6_43.py
fruits = ['apple', 'banana', 'watermelon']
fruit = input("請輸入水果 = ")
if fruit in fruits:
print("這個水果已經有了")
else:
fruits.append(fruit)
print("謝謝提醒已經加入水果清單: ", fruits)判斷串列是否位址相同is與is not (1/2)
位址相同 vs 內容相同: is 用來判斷「位址相同」
x = 10
y = 10
if x == y:
print('內容相同')
else:
print('內容不同')
if x is y:
print('位址相同', id(x), id(y))
else:
print('位址不同', id(x), id(y))
y = 15
if x is y:
print('位址相同', id(x), id(y))
else:
print('位址不同', id(x), id(y))內容相同
位址相同 140703845573744 140703845573744
位址不同 140703845573744 140703845573904
執行結果
判斷串列是否位址相同is與is not (2/2)
位址相同 vs 內容相同
# ch6_46.py
mysports = ['basketball', 'baseball']
sports1 = mysports # 拷貝位址
sports2 = mysports[:] # 拷貝新串列
print("我喜歡的運動 = ", mysports, "位址是 = ", id(mysports))
print("運動 1 = ", sports1, "位址是 = ", id(sports1))
print("運動 2 = ", sports2, "位址是 = ", id(sports2))
boolean_value = mysports is sports1
print("我喜歡的運動 is 運動 1 = ", boolean_value)
boolean_value = mysports is sports2
print("我喜歡的運動 is 運動 2 = ", boolean_value)
boolean_value = mysports is not sports1
print("我喜歡的運動 is not 運動 1 = ", boolean_value)
boolean_value = mysports is not sports2
print("我喜歡的運動 is not 運動 2 = ", boolean_value)True
False
True
False
串列的運用
- 使用For迴圈讀取串列
Title Text
tuple1 = (1,2,3,4,5,6) # 元素0~5
print(tuple1[3]) # 印出4
tuple1[1] = 100 # 錯誤, 不能修改元素值
元組 Tuple
- 不能修改的串列
元組Tuple
tuple0 = () # 空元組
tuple1 = (1,2,3,4,5,6) # 相同型別
tuple2 = (1, "張三", True) # 不同型別元組(Tuple):不能修改內容的串列
- 不能修改:個數、元素值
元組: 使用小括弧
元組 = (元素1, 元素2, ....) tuple1 = (1,2,3,4,5,6) # 元素0~5
print(tuple1[3]) # 印出4
tuple1[1] = 100 # 錯誤, 不能修改元素值
範例
元組的優點:
- 執行速度比串列快
- 內容無法改變,資料較為安全
tuple1 = (20,30,40)
list1 = list(tuple1) # 元組轉串列
list2 = [20, 30, 40]
tuple2 = tuple(list2) # 串列轉元組
元組/串列互轉
字典(dict)
- 簡介
字典 簡介(1/6)
價目表 = {'香蕉': 20, '蘋果': 50, '鳳梨': 80}
print(價目表)
print(價目表['香蕉'])字典 (dict) 宣告:
字典名稱 = {鍵1: 值1, 鍵2: 值2, 鍵3: 值3..., 鍵N: 值N}- 字典:以{ }包含所有項目
- 每個項目:鍵: 值,逗點分隔
- 各個項目取值:字典名稱[鍵1],...字典名稱[鍵N]
- 以鍵取值
範例
{'香蕉': 20, '蘋果': 50, '鳳梨': 80}
20
執行結果
字典名稱[鍵N]字典 簡介(2/6)
字典
串列
自訂名稱(鍵)
索引值: 0~(N-1)
字典 簡介(3/6)
價目表 = {'香蕉': 20, '蘋果': 50, '香蕉': 80}
print(價目表['香蕉'])範例
字典建立函式dict():
價目表 = {'香蕉': 20, '蘋果': 50, '鳳梨': 80}
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
print(成績單)
print(成績單['王小明'])範例
80
執行結果
dict()函式中,「鍵」若為字串不能加引號
dict()
{'王小明': 80, '李小鳳': 70, '張小華': 75}
80
執行結果
以鍵取值
- 鍵重複?
- 鍵不存在?
價目表 = {'香蕉': 20, '蘋果': 50, '香蕉': 80}
print(價目表['香蕉']) # 80
print(價目表['鳳梨']) # 錯誤
字典 簡介(4/6)
weather = dict(春='春雨綿綿',夏='颱風季節',秋='秋高氣爽',冬='東北季風')
season = input('輸入季節:')
print(weather.get(season))以鍵取值範例
- 輸入季節:春、夏、秋、冬
- 輸出季節特性:'春雨綿綿', '颱風季節', '秋高氣爽', '東北季風'
weather = dict(春='春雨綿綿',夏='颱風季節',秋='秋高氣爽',冬='東北季風')
while True:
season = input('輸入季節(春、夏、秋、冬任一,或直接按Enter結束):')
if season == '': # Enter
print('程式結束')
break
else:
result = weather.get(season)
if result != None:
print(result)
else:
print('請重新輸入春夏秋冬任一季節')測試
完整版
字典 簡介(5/6)
練習:
- 輸入血型:A、B、C、AB
- 輸出血型特性:'喜好平靜', '個性爽朗', '理智現實', '反復無常'
- 輸入a, A 皆可
blood = input('輸入血型:')
print(blood.upper()) # 小寫轉大寫提示:
字典 簡介(6/6)
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
成績單['王小明'] = 90 # 修改
成績單['春嬌'] = 88 # 鍵不存在:新增
print(成績單)
範例
{'王小明': 90, '李小鳳': 70, '張小華': 75, '春嬌': 88}
執行結果
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
del 成績單['王小明'] # 刪除王小明的成績
print(成績單)
成績單.clear() # 全部清除
print(成績單)範例
{'李小鳳': 70, '張小華': 75}
{}
執行結果
修改元素內容
刪除元素
字典 (dict) 修改與新增:
字典 (dict) 刪除
del 字典名稱 # 刪除字典字典進階功能
- 檢查:鍵是否存在
- 取所有鍵:.keys()
- 取所有值:.values()
- 取所有「鍵」-「值」對:.items()
- 取得字典內容個數: len(字典)
字典進階功能檢查鍵(1/11)
某個鍵是否存在?
- 回傳True(存在) / False(不存在)
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
print('春嬌' in 成績單)
print('王小明' in 成績單)True
False
執行結果
'鍵' in 字典
字典進階功能檢查鍵(2/11)
範例:成績查詢與新增
- 輸入姓名,如果已存在字典,則印出成績
- 如果姓名不存在,則輸入成績
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
name = input('輸入學生姓名:')
if name in 成績單:
print('%s的成績是: %3d' % (name,成績單.get(name)))
else:
score = int(input('輸入成績:'))
成績單[name] = score
print(成績單)輸入學生姓名:王小明
王小明的成績是: 80
執行結果
輸入學生姓名:志明
輸入成績:75
{'王小明': 80, '李小鳳': 70, '張小華': 75, '志明': 75}
字典進階功能檢查鍵(3/11)
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
while True:
name = input('輸入學生姓名:(直接按Enter結束)')
if name == '':
print('程式結束')
break
if name in 成績單:
print('%s的成績是: %3d' % (name,成績單.get(name)))
else:
score = int(input('輸入成績:'))
成績單[name] = score
print(成績單)執行結果
輸入學生姓名:(直接按Enter結束)志明
輸入成績:80
{'王小明': 80, '李小鳳': 70, '張小華': 75, '志明': 80}
輸入學生姓名:(直接按Enter結束)春嬌
輸入成績:90
{'王小明': 80, '李小鳳': 70, '張小華': 75, '志明': 80, '春嬌': 90}
輸入學生姓名:(直接按Enter結束)志明
志明的成績是: 80
輸入學生姓名:(直接按Enter結束)
程式結束
字典進階功能檢查鍵(4/11)
練習:新增價目表
- 建立飲料店價目表
- 飲料名為「鍵」,價格為「值」
- 直接按Enter結束後,印出價目表
字典進階功能取所有鍵(5/11)
取得所有鍵?
- 需搭配list()
{'王小明': 80, '李小鳳': 70, '張小華': 75}
dict_keys(['王小明', '李小鳳', '張小華'])
執行結果
字典.keys()
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
print(成績單) # 鍵/值對
print(成績單.keys()) # 只取得鍵兩者都無法用for迴圈處理
字典.keys(): 得到dict_keys型別資料
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
keys = 成績單.keys() # 所有鍵
names = list(keys) # 轉成串列
print(names)
for item in names:
print('%s的成績是%d' % (item, 成績單.get(item)))['王小明', '李小鳳', '張小華']
王小明的成績是80
李小鳳的成績是70
張小華的成績是75
執行結果
鍵轉成串列
字典進階功能取所有鍵(6/11)
範例:成績查詢與新增
- 修改之前輸入程式,但程式結束後印出所有人成績
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
while True:
name = input('輸入學生姓名:(直接按Enter結束)')
if name == '':
break
if name in 成績單:
print('%s的成績是: %3d' % (name,成績單.get(name)))
else:
score = int(input('輸入成績:'))
成績單[name] = score
print(成績單)
for item in list(成績單.keys()):
print('%s的成績是%d' % (item, 成績單.get(item)))字典進階功能取所有值(7/11)
取得所有值?
- 需搭配list()
{'王小明': 80, '李小鳳': 70, '張小華': 75}
dict_values([80, 70, 75])
執行結果
字典.values()
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
print(成績單) # 鍵/值對
print(成績單.values()) # 只取得值兩者都無法用for迴圈處理
字典.values(): 得到dict_values型別資料
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
values = 成績單.values() # 所有值
scores = list(values) # 轉成串列
avg = sum(scores) / len(scores)
print(avg)75.0
執行結果
鍵轉成串列
字典進階功能取所有值(8/11)
範例:成績查詢與新增
- 修改之前輸入程式,但程式結束後統計及格人數
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
while True:
name = input('輸入學生姓名:(直接按Enter結束)')
if name == '':
break
if name in 成績單:
print('%s的成績是: %3d' % (name,成績單.get(name)))
else:
score = int(input('輸入成績:'))
成績單[name] = score
print(成績單)
及格人數 = 0
for score in list(成績單.values()):
if score >= 60:
及格人數 += 1
print('及格人數:%d' % 及格人數)字典進階功能綜合練習(9/11)
練習:PM2.5 新增查詢
-
輸入六都的PM2.5數值(台北市, 新北市, 桃園市, 台中市, 台南市, 高雄市)
- 六都為「鍵」, PM2.5數值為「值」
- 輸入城市名稱
- 若城市屬於六都,則印出PM2.5值
- 否則印出該城市不屬於六都
- 輸入平均,則印出PM2.5平均值
- 直接輸入Enter,程式結束
字典進階功能取所有鍵-值組合(10/11)
取得所有鍵-值組合?
- 搭配list(), 即可使用for
{'王小明': 80, '李小鳳': 70, '張小華': 75}
dict_items([('王小明', 80), ('李小鳳', 70), ('張小華', 75)])
執行結果
字典.items()
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
print(成績單) # 鍵/值對
print(成績單.items()) # 只取得值兩者都無法用for迴圈處理
字典.items(): 得到dict_dict型別資料
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
items = list(成績單.items())
for key, val in items:
print("%s的成績是:%3d" % (key, val))王小明的成績是: 80
李小鳳的成績是: 70
張小華的成績是: 75
執行結果
鍵轉成串列
2個迴圈變數: 1st對應「鍵], 2nd對應「值」
字典進階功能取所有鍵-值組合(11/11)
字典.items()
- 用list()轉成串列後,相當於2維串列
成績單 = dict(王小明=80, 李小鳳=70, 張小華=75)
items = list(成績單.items())
print('第一個元組:', items[0])
for i in range(len(items)): # 一維元組
print(items[i])
print('第一個元組裡的第二個元素:',items[0][1])
for i in range(len(items)): # 二維串列
for j in range(len(items[i])):
print(items[i][j])第一個元組: ('王小明', 80) ('王小明', 80) ('李小鳳', 70) ('張小華', 75) 第一個元組裡的第二個元素: 80 王小明 80 李小鳳 70 張小華 75
執行結果
2維串列
字典進階功能練習
英漢字典 = dict(dog='狗', fish='魚', cat='貓', pig='豬')
print(英漢字典)
print(英漢字典.keys())
word = input('輸入英文單字?')
print(英漢字典.get(word, '找不到該單字')){'dog': '狗', 'fish': '魚', 'cat': '貓', 'pig': '豬'}
dict_keys(['dog', 'fish', 'cat', 'pig'])
輸入英文單字?white
找不到該單字
執行結果
練習:製作英翻中字典
- 輸入英文單字與中文解釋,建立字典
- 輸入英文單字,查詢對應的中文解釋
集合
- 簡介
集合 簡介(1/8)
s1 = {1,2,3,4,5} # 大括弧建立集合
s2 = set() # 空集合
print(s1)
print(s2)
print(type(s1))集合 (set) : 儲存沒有順序、不重複的資料
集合名稱 = {元素1, 元素2, 元素3,..., 元素N}- 集合:以{ }包含所有項目,或以set()建立集合
- 會自動刪除重複元素
- 每個項目:逗點分隔
- 因沒有順序:無索引值
- 判斷在集合裡:in, not in 運算子
建立
{1, 2, 3, 4, 5}
set()
<class 'set'>
執行結果
串列名稱[索引值]集合名稱[索引值]集合 簡介(2/8)
# 由 串列 建立集合
s3 = set([6,7,8,9,10])
print(s3)
# 由元組 (Tuple) 建立集合
s4 = set((11, 12, 13, 14, 15))
print(s4)
# 由 字典 建立集合
s5 = set({'早安': 'Good Morning', '你好': 'Hello'})
print(s5)
# 元素重複會自動刪除
s6 = set([40, 50, 60, 60, 80, 60])
print(s6)建立
{6, 7, 8, 9, 10}
{11, 12, 13, 14, 15}
{'早安', '你好'}
{40, 50, 80, 60}
執行結果
集合其他建立方式:串列, 元組
集合 簡介(3/8)
s3 = set([6,7,8,9,10])
s4 = set((11, 12, 13, 14, 15))
s3.add(50)
print(s3)
s4.remove(15)
print(s4)新增
{6, 7, 8, 9, 10, 50}
{11, 12, 13, 14}
執行結果
集合:新增函式 .add(), 移除函式 .remove()
移除
s4 = set((11, 12, 13, 14, 15))
s4.remove(10) # 錯誤!10不在集合裡
print(s4)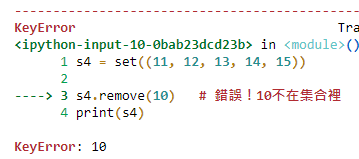
不能移除不在集合裡的元素
集合 簡介(4/8)
s3 = set([6,7,8,9,10])
num = 6
if num in s3:
print(num, '在集合裡')
else:
print(num, '不在集合裡')存在?
6 在集合裡
執行結果
判斷元素是否在集合裡: in , not in運算子
s4 = set((11, 12, 13, 14, 15))
print(10 not in s4) # 10不在s4集合裡?
print(11 not in s4) # 11不在s4集合裡?True
False
執行結果
不存在?
集合 簡介(5/8)
s3 = set([6,7,8,9,10])
print(len(s3))
print(sum(s3))
print(max(s3))
print(min(s3))5
40
10
6
執行結果
集合可使用的函式:
- len(): 集合元素個數
- sum(): 加總
- max(): 回傳最大值
- min(): 回傳最小值
集合 簡介(6/8)
s3 = set([6,7,8,9,10])
for item in s3:
print(item)6
7
8
9
10
執行結果
集合的處理方式: for迴圈
春曉 = '春眠不覺曉,處處聞啼鳥。夜來風雨聲,花落知多少?'
字集合 = set(春曉) # 字串轉集合: 每個不重複的字成為一個元素
print(字集合)
for word in 字集合:
print(word, end=","){'。', '處', '多', '少', '知', '曉', '不', '?', '春', '覺', '來', '風', '聲', '鳥', '夜', '花', '落', ',', '雨', '眠', '聞', '啼'}
。,處,多,少,知,曉,不,?,春,覺,來,風,聲,鳥,夜,花,落,,,雨,眠,聞,啼,
執行結果
集合 簡介(7/8)
集合運算子:
a={7, 9, 8, 4, 2, 6, 5, 7, 4};
b={6, 55, 4, 12, 1 ,5}
print('a集合:', a)
print('b集合:',b)
print('a,b交集', a & b)
print('a,b聯集', a | b)
print('a,b差集', a - b)a集合: {2, 4, 5, 6, 7, 8, 9} b集合: {1, 4, 5, 6, 12, 55} a,b交集 {4, 5, 6} a,b聯集 {1, 2, 4, 5, 6, 7, 8, 9, 12, 55} a,b差集 {8, 9, 2, 7}
執行結果
| 交集 | & |
| 聯集 | | |
| 差集 | - |
集合 簡介(8/8)
練習:找出及格的人
全班學生: John, Mary, Tina, Fiona, Claire, Eva, Ben, Bill, Bert
英文及格:John, Mary, Fiona, Claire, Ben, Bill
數學及格:Mary, Fiona, Claire, Eva, Ben
Q. 分別印出 (a) 兩科都及格 (b) 數學不及格 (c) 英文及格但數學不及格 的同學名字